 為什么不能直接使用中文編程
為什么不能直接使用中文編程
一、背景介紹
很多剛接觸計算機的同學,可能會發出一個疑問, 為什么不能直接使用中文編程 ?
要了解這個問題,還得從計算機的起源說起!
在計算機軟件里面,一切的信息都可以用 1 和 0 來表示( 嚴格說連 0 和 1 都沒有,只有開和關 ),也被稱為 二進制位 ,英文簡稱: bit ,音譯為“ 比特 ”,比特是計算機內存中的最小單位(也稱原子單位),在計算機系統中,每 bit 可用 0 或 1 表示數位訊號。
在上篇文章中,我們了解到不管是磁盤還是網絡傳輸,最小的存儲單元都是字節。
有的同學可能又會發出疑問, 為什么不直接使用比特存儲?字節和比特又有什么關系呢 ?
雖然比特是硬件上的最小單元,但是光靠 1 和 0 很難知道是什么意思,比特就好比身體的細胞,由于顆粒度太細,很難知道這個細胞屬于哪個地方,于是就有了字節這個概念,字節就好比身體的某個器官,更便于識別。
簡單的說,從單位換算角度, 一個字節 = 8 個比特 !
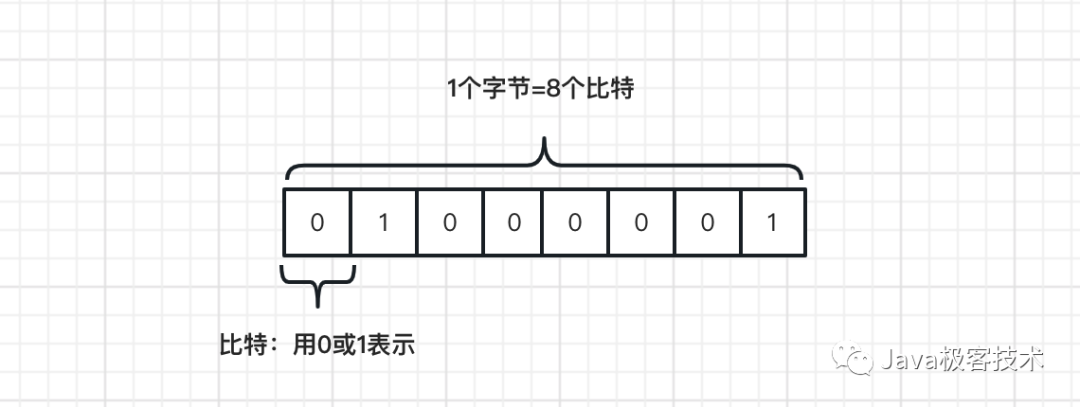
通過這一串的 8 個 1 和 0 的不同排列方式,可以表達出 256 個(2的8次方)不同的意思,這樣換算率在當時的美國科學家看來,已經足夠表達英文中全部字母大小寫及符號加控制符了,也就是下文我們要介紹的 ASCII 字母代碼表。
上個世紀 60 年代,為了更好的便于計算機傳輸字符信息,美國制定了一套字符編碼規則,對英語字符與二進制位之間的關系做了統一規定,這編碼規則被稱為 ASCII 編碼(美國標準信息交換碼),一直沿用至今。

ASCII 編碼一共規定了 128 個字符的編碼規則,這 128 個字符形成的集合就叫做ASCII 字符集。
在早期的 ASCII 編碼中,規定使用單字節中低位的 7 個比特去編碼所有的字符, 每個字符占用一個字節的后面7位,最前面的1位統一規定為 0 。
在這個編碼規則下,當你在鍵盤上輸入字母 A,計算機會根據 ASCII 字符代碼表,找到對應的十進制碼值 65,然后換算成二進制碼值 01000001,傳輸到目的地;接受端收到信號之后,會將二進制碼值 01000001 再換算成十進制碼值 65,然后再根據字符代碼表,將十進制碼值 65 解碼成字母 A,最后輸出到控制臺。
由此,整個計算機之間的信息傳輸交換完成!
在 ASCII 編碼中,編號 031 是控制字符如換行回車刪除等,32126 是可打印字符,可以通過鍵盤輸入并且能夠顯示出來,一個英文字符占用一個字節。
對于英語來說,用 128 個符號編碼就夠了,但是隨著計算機的快速發展,用來表示其他語言,128 個符號是遠遠不夠的。
所以當 ASCII 碼到歐洲的時候,一些歐洲國家就決定對 ASCII 編碼進行適當的 擴展和改造,現有的編碼規則維持不變,把字節中閑置的最高位也編入新的符號。比如,法語中的 é 的編碼為 130(二進制 10000010 )。這樣一來,這些歐洲國家使用的編碼體系,可以表示最多 256 個符號,這個編碼統稱為 EASCII(Extended ASCII)。
但是歐洲的語言體系有個特點:小國家特別多,每個國家可能都有自己的語言體系,語言環境十分復雜。因此即使 EASCII 可以表示 256 個字符,也不能統一歐洲的語言環境。
為了解決上面這個問題,歐洲的工程師們想出了一個折中的方案:在 EASCII 中表示的 256 個字符中,前 128 字符和 ASCII 編碼表示的字符完全一樣,后 128 個字符每個國家或地區都有自己的編碼標準。
比如,130 在法語編碼中代表了 é,但是在希伯來語編碼中代表字母 Gimel (?),在俄語編碼中又會代表另一個符號。但是不管怎樣,所有這些編碼方式中,0—127 表示的符號是一樣的,不一樣的只是 128—255 的這一段。
根據這個規則,就形成了很多子標準:ISO-8859-1、ISO-8859-2、ISO-8859-3、……、ISO-8859-16。這些子標準適用于歐洲不同的國家地區。具體關于 ISO-8859 的標準請參考這個鏈接地址。
到了亞洲國家,使用的文字符號就更多了,漢字就多達 10 萬多個。根據上面的信息,我們知道一個字節最多只能表示 256 種符號,這對于漢字來說肯定是不夠的,必須使用多個字節表達一個符號。因此才出現了后面的 GB2312、Unicode 等字符集,簡體中文常見的編碼方式是 GB2312,使用兩個字節表示一個漢字,所以理論上最多可以表示 65536 個符號;而 Unicode 字符集是一個很大的字符集合,最多可以使用 4 個字節來表示一個符號,可以容納 100 多萬個符號。
關于字符集的故事發展,我們在此不過深入的講解,有興趣的朋友可以看看這個鏈接地址!
下面我們重點介紹一下 Unicode 字符集!
二、Unicode 字符集
在上文的信息中,我們了解到不同的國家有不同的字符集,如果通過電子郵件把信息傳送到另外一個國家的計算機系統中, 看到的可能就不是那個原始發送的字符了,很有可能而是亂碼 !
因為計算機里面并沒有真正的字符,字符都是以數字的形式存在的,通過郵件傳送一個字符,實際上傳送的是這個字符對應的字符編碼,同一個數字在不同的國家和地區代表的很可能是不同的符號。
為了解決各個國家和地區之間各自使用不同的本地化字符編碼帶來的不便, 工程師們將全世界所有的符號進行了統一編碼,稱之為 Unicode,也被稱為統一碼、萬國碼 。
所有字符不再區分國家和地區,都是人類共有的符號,如" 中 "字在 Unicode 中不再是 GBK 中的 D6D0,而是在任何地方都是 4e2d,如果所有的計算機系統都使用這種編碼方式,那么 4e2d 這個字在任何地方都代表漢字中的" 中 "。
需要注意的是,Unicode 只是一個字符集,它只規定了符號的二進制代碼,卻沒有規定這個二進制代碼應該如何編碼如何存儲。這就造成了兩個問題:
- 問題1 :如何才能區別 Unicode 和 ASCII ?計算機怎么知道三個字節表示一個符號,而不是分別表示三個符號呢?
- 問題2 :我們知道,英文字母只用一個字節表示就夠了,如果 unicode 統一規定,每個符號用三個或四個字節表示,那么每個英文字母前都必然有二到三個字節是 0,這對于存儲來說是極大的浪費,文本文件的大小會因此大出二三倍,這對當時存儲器來說,是無法滿足的。
為了解決 Unicode 字符集中的一些問題,就出現了 UTF(Unicode Transformation Formats) 系列的編碼規則。UTF 編碼規則具體規定了 Unicode 字符集中的字符是如何編碼的。
下面我們就來看看 UTF 系列編碼的具體實現。
三、UTF 編碼規則
3.1、UTF-16
早期,Unicode 轉換格式規定不管什么字符都使用兩個字節表示,兩個字節其實就是 16 Bit,所以叫做 UTF-16。
UTF-16 編碼非常方便,每兩個字節表示一個字符,這個在字符串操作時大大簡化了操作,編碼效率也比較高,尤其適合在本地磁盤和內存之間操作,可以進行字符和字節之間的快速切換。
但是缺陷也很明顯,首先就是一個字符占用兩個字節,因為很大一部分字符用一個字節表示就夠了,現在需要用兩個字節,存儲空間放大了一倍;其次在網絡之間傳輸數據,容易因為大小端問題,傳輸后讀取的數據會出現亂碼。
3.2、UTF-8
隨著互聯網的普及,強烈要求出現一種統一的編碼方式,為了解決 UTF-16 中的缺陷,基于此又誕生了一種可變長度技術,每個編碼區域有不同的字節長度,不同類型的字符可以是由 1~4 個字節組成,這種編碼規則我們稱為 UTF-8,由 Ken Thompson 于1992年創建,用在網頁上可以統一展示頁面上的中文英文繁體及其它語言正常顯示。
UTF-8 最大的一個特點,就是它是一種變長的編碼方式。它使用 1~4 個字節表示一個符號,根據不同的符號而變化字節長度,UTF-8 編碼可以容納 2^21 個字符,總共 200 多萬個字符。
UTF-8的編碼規則很簡單,只有二條:
- 1.對于單字節的符號,字節的第一位設為0,后面7位為這個符號的 unicode碼。因此對于英語字母,UTF-8 編碼和 ASCII 碼是相同的,可以完全兼容過去的編碼規則
- 2.對于 n 字節的符號(n>1),第一個字節的前 n 位都設為1,第 n+1 位設為0,后面字節的前兩位一律設為 10。剩下的沒有提及的二進制位,全部為這個符號的 unicode 碼
對不同范圍的字符使用不同長度的編碼方式,詳細的規則如下,其中字母 x 表示可用編碼的二進制位。

比如『漢』這個字的 Unicode 編碼是 0x6C49。0x6C49 在 0x0800 ~ 0xFFFF 之間,使用 3 字節模板:1110xxxx 10xxxxxx 10xxxxxx。將 0x6C49 寫成二進制是:0110 1100 0100 1001, 用這個比特流依次代替模板中的x,得到:11100110 10110001 10001001。
關于 UTF-8 編碼技術更加詳細的解說,可以參考這個鏈接!
四、Java 與字符編碼
Java 語言內部使用的是 Unicode 字符集,采用 UTF-16 方式編碼字符。
但其實,Java 內部還實現了ASCII、LATIN1、ISO8859-1、UTF-8、GBK 等字符集的編碼規則,可以很容易實現這些編碼之間的相互轉換。
在保證跨平臺特性的前提下,也支持了全擴展的本地平臺字符集,默認顯示輸出和鍵盤輸入都是采用的本地編碼規則,因此,免不了二者的轉化問題。
以 windows 操作系統為例,我們看一個簡單的例子!
public static void main(String[] args) throws Exception {
// 我們采用 GBK 進行編碼
byte b[] = "我們一起來學習 Java 語言".getBytes("GBK");
File file = new File("encoding.txt");
OutputStream out = new FileOutputStream(file);
out.write(b);
out.close();
}
打開輸出的文件,內容如下:
我們一起來學習 Java 語言
正常情況下輸出,無編碼問題,但是如果改成這樣呢
public static void main(String[] args) throws Exception {
// 我們采用 ISO8859-1 進行編碼
byte b[] = "我們一起來學習 Java 語言".getBytes("ISO8859-1");
File file = new File("encoding.txt");
OutputStream out = new FileOutputStream(file);
out.write(b);
out.close();
}
輸出的文件,內容如下:
?????Java??
亂碼問題就出現了!
原因相信大家都知道了,就是字符編碼和解碼的規則不一樣導致的。
Java 中的各個類,對于英文字符的支持都非常好,可以正常地寫入文件中,但對于中文字符就未必了!
從 Java 源代碼到寫入文件正確的內容,要經過 Java 源代碼 -> Java 字節碼 -> 虛擬機 -> 文件幾個步驟,在上述過程中的每一步都必須正確地處理漢字的編碼,才能夠使最終有我們期望的結果。
其中 Java 源代碼 -> Java 字節碼這一步驟,Java 編譯器 Javac 使用的字符集是系統默認的字符集,比如在中文 Windows 操作系統上就是 GBK,而在 Linux 操作系統上是 ISO8859-1。所以經常有同學發出疑問,自己在本地的 windows 系統上運行的很正常,但是把代碼部署到了 Linux 操作系統上編譯的類中源文件中的中文字符就出現亂碼了。
解決辦法就是在編譯的時候添加 encoding 參數,并指定對應的編碼規則,比如 GBK 或者 UTF-8,這樣才能夠與平臺無關。
如果想要查詢 jdk 使用的是哪種編碼規則,可以通過如下方式查詢:
public static void main(String[] args) {
System.getProperties().list(System.out);
}
輸出的內容比較多,重點看下file.encoding變量值就可以,比如小編當前的電腦顯示結果如下:
file.encoding=GBK
表明了 JDK 使用的是 GBK 字符集,當對字符串進行操作時,都做了 Unicode 到 GBK 的轉換,既然 JDK 用的 GBK 編碼,那么用 ISO8859-1 字符集顯示 GBK 編碼出來的中文當然是有問題的。
因此在實際使用過程中, 推薦大家統一編碼規則,比如采用比較通用的 UTF-8 編碼規則,可以避免無端的文字亂碼問題 。
五、小結
本文主要圍繞計算機進行字符傳輸時碰到的問題,進行了一次簡單的知識梳理總結,內容難免有所遺漏,歡迎網友留言指出!
最近網上有傳聞說,采用中文來編程,大家可以試想一下,采用中文來編程會是個什么樣的結果?
通過上面的分析,我們可以得出一個結論,那就是采用中文編程,如果沒有統一編碼規則的情況下,會是個災難;其次也會增加程序員們的工作難度,因為從字節來看,一個漢字至少等于英文的兩個字符,所以使用漢字會更加占內存。
還有一點就是,英文最多也就 26 個字符,比較簡單,在所有的計算機上都非常通用,如果換成中文的話,截止目前, 中文的符號已經超過 10 萬個了,還沒有完全收集全 ,如果換成中文來編程,需要窮舉所有的中文字符,以防干擾程序的正常執行, 這在目前看來基本弊大于利 !
-
存儲單元
+關注
關注
1文章
63瀏覽量
16148 -
計算機
+關注
關注
19文章
7488瀏覽量
87858 -
編程
+關注
關注
88文章
3614瀏覽量
93686 -
編碼
+關注
關注
6文章
942瀏覽量
54814 -
網絡傳輸
+關注
關注
0文章
138瀏覽量
17395
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論