

作者:賈志剛英特爾邊緣計(jì)算創(chuàng)新大使
01OpenVINO場(chǎng)景文字檢測(cè)
OpenVINO是英特爾推出的深度學(xué)習(xí)模型部署框架,當(dāng)前最新版本是OpenVINO2023版本。OpenVINO2023自帶各種常見(jiàn)視覺(jué)任務(wù)支持的預(yù)訓(xùn)練模型庫(kù)Model Zoo,其中支持場(chǎng)景文字檢測(cè)的網(wǎng)絡(luò)模型是來(lái)自Model Zoo中名稱為:text-detection-0003的模型(基于PixelLink架構(gòu)的場(chǎng)景文字檢測(cè)網(wǎng)絡(luò))。
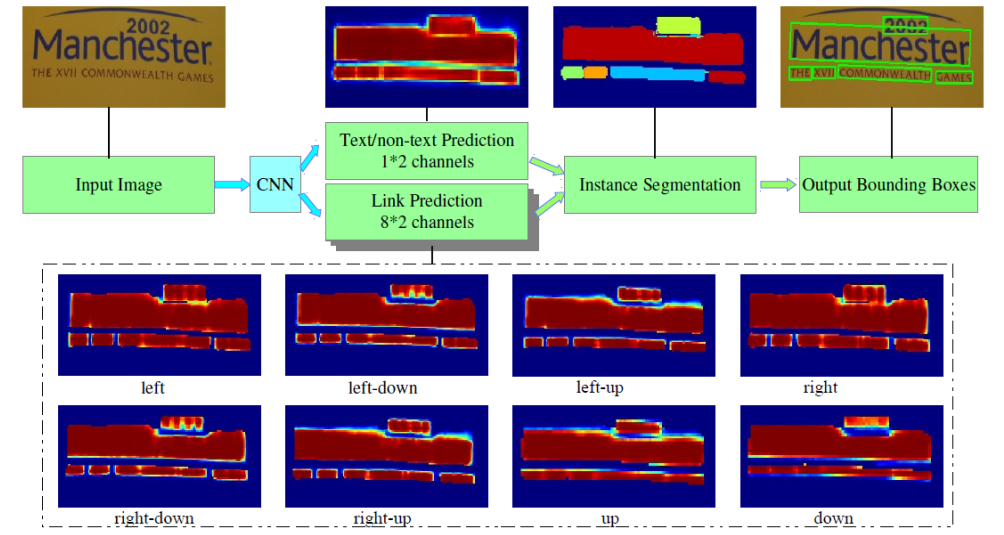
圖-1 PixelLink網(wǎng)絡(luò)模型架構(gòu)
圖-1中的PixelLink場(chǎng)景文字檢測(cè)模型的輸入與輸出格式說(shuō)明
輸入格式:
1x3x768x1280 BGR彩色圖像
輸出格式:
name: "model/link_logits_/add", [1x16x192x320] – pixelLink的輸出 name: "model/segm_logits/add", [1x2x192x320] – 像素分類text/no text
左滑查看更多
02OpenVINO文字識(shí)別
OpenVINO支持文字識(shí)別(數(shù)字與英文)的模型是來(lái)自Model Zoo中名稱為:text-recognition-0012d的模型,是典型的CRNN結(jié)構(gòu)模型。(基于類似VGG卷積結(jié)構(gòu)backbone與雙向LSTM編解碼頭的文字識(shí)別網(wǎng)絡(luò))
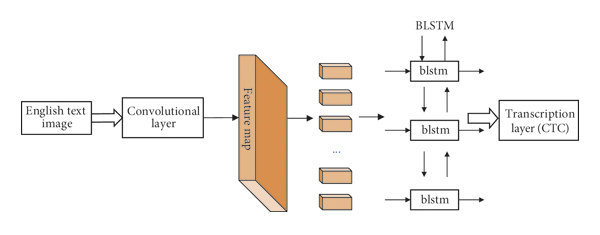
圖-2 CRNN網(wǎng)絡(luò)模型架構(gòu)
圖-2文本識(shí)別模型的輸入與輸出格式如下:
輸入格式:1x1x32x120
輸出格式:30, 1, 37
輸出解釋是基于CTC貪心解析方式,其中37字符集長(zhǎng)度,字符集為:0123456789abcdefghijklmnopqrstuvwxyz#
#表示空白。
03MediaPipe手勢(shì)識(shí)別
谷歌在2020年發(fā)布的mediapipe開(kāi)發(fā)包說(shuō)起,這個(gè)開(kāi)發(fā)包集成了包含手勢(shì)姿態(tài)等各種landmark檢測(cè)與跟蹤算法。其中支持手勢(shì)識(shí)別是通過(guò)兩個(gè)模型實(shí)現(xiàn),一個(gè)是模型是檢測(cè)手掌,另外一個(gè)模型是實(shí)現(xiàn)手掌的landmakr標(biāo)記。

圖-3手勢(shì)landmark點(diǎn)位說(shuō)明
04OpenVINO與MediaPipe庫(kù)的安裝
pip install openvino==2023.0.2 pip install mediapipe
左滑查看更多
請(qǐng)先安裝好OpenCV-Python開(kāi)發(fā)包依賴。
05應(yīng)用構(gòu)建說(shuō)明
首先基于OpenCV打開(kāi)USB攝像頭或者筆記本的web cam,讀取視頻幀,然后在每一幀中完成手勢(shì)landmark檢測(cè),根據(jù)檢測(cè)到手勢(shì)landmark數(shù)據(jù),分別獲取左右手的食指指尖位置坐標(biāo)(圖-3中的第八個(gè)點(diǎn)位),這樣就得到了手勢(shì)選擇的ROI區(qū)域,同時(shí)把當(dāng)前幀的圖像送入到OpenVINO場(chǎng)景文字識(shí)別模塊中,完成場(chǎng)景文字識(shí)別,最后對(duì)比手勢(shì)選擇的區(qū)域與場(chǎng)景文字識(shí)別結(jié)果每個(gè)區(qū)域,計(jì)算它們的并交比,并交比閾值大于0.5的,就返回該區(qū)域?qū)?yīng)的OCR識(shí)別結(jié)果,并顯示到界面上。整個(gè)流程如下:
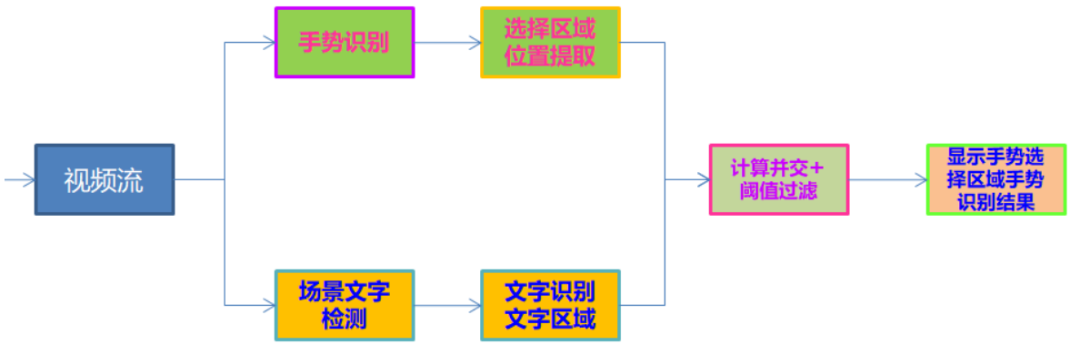
圖-4程序執(zhí)行流程圖
06代碼實(shí)現(xiàn)
根據(jù)圖-4的程序執(zhí)行流程圖,把場(chǎng)景文字檢測(cè)與識(shí)別部分封裝到了一個(gè)類TextDetectAndRecognizer,最終實(shí)現(xiàn)的主程序代碼如下:
import cv2 as cv
import numpy as np
import mediapipe as mp
from text_detector import TextDetectAndRecognizer
digit_nums = ['0','1', '2','3','4','5','6','7','8','9','a','b','c','d','e','f','g',
'h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','#']
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands
x0 = 0
y0 = 0
detector = TextDetectAndRecognizer()
# For webcam input:
cap = cv.VideoCapture(0)
cap.set(cv.CAP_PROP_FRAME_HEIGHT, 1080)
cap.set(cv.CAP_PROP_FRAME_WIDTH, 1920)
height = cap.get(cv.CAP_PROP_FRAME_HEIGHT)
width = cap.get(cv.CAP_PROP_FRAME_WIDTH)
# out = cv.VideoWriter("D:/test777.mp4", cv.VideoWriter_fourcc('D', 'I', 'V', 'X'), 15, (np.int(width), np.int(height)), True)
with mp_hands.Hands(
min_detection_confidence=0.75,
min_tracking_confidence=0.5) as hands:
while cap.isOpened():
success, image = cap.read()
if not success:
break
image.flags.writeable = False
h, w, c = image.shape
image = cv.cvtColor(image, cv.COLOR_BGR2RGB)
results = hands.process(image)
image = cv.cvtColor(image, cv.COLOR_RGB2BGR)
x1 = -1
y1 = -1
x2 = -1
y2 = -1
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(
image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS)
for idx, landmark in enumerate(hand_landmarks.landmark):
x0 = np.int(landmark.x * w)
y0 = np.int(landmark.y * h)
cv.circle(image, (x0, y0), 4, (0, 0, 255), 4, cv.LINE_AA)
if idx == 8 and x1 == -1 and y1 == -1:
x1 = x0
y1 = y0
cv.circle(image, (x1, y1), 4, (0, 255, 0), 4, cv.LINE_AA)
if idx == 8 and x1 > 0 and y1 > 0:
x2 = x0
y2 = y0
cv.circle(image, (x2, y2), 4, (0, 255, 0), 4, cv.LINE_AA)
if abs(x1-x2) > 10 and abs(y1-y2) > 10 and x1 > 0 and x2 > 0:
if x1 < x2:
? ? ? ?cv.rectangle(image, (x1, y1), (x2, y2), (255, 0, 0), 2, 8)
? ? ? ?text = detector.inference_image(image, (x1, y1, x2, y2))
? ? ? ?cv.putText(image, text, (x1, y1), cv.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 255), 2)
? ? ?else:
? ? ? ?cv.rectangle(image, (x2, y2), (x1, y1), (255, 0, 0), 2, 8)
? ? ? ?text = detector.inference_image(image, (x2, y2, x1, y1))
? ? ? ?cv.putText(image, text, (x2, y2), cv.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 255), 2)
? ?# Flip the image horizontally for a selfie-view display.
? ?cv.imshow('MediaPipe Hands', image)
? ?# out.write(image)
? ?if cv.waitKey(1) & 0xFF == 27:
? ? ?break
cap.release()
# out.release()
左滑查看更多
07移植到AlxBoard開(kāi)發(fā)板上
在愛(ài)克斯開(kāi)發(fā)板上安裝好MediaPipe即可,OpenVINO不用安裝了,因?yàn)閻?ài)克斯開(kāi)發(fā)板自帶OpenCV與OpenVINO,然后就可以直接把python代碼文件copy過(guò)去,插上USB攝像頭,直接使用命令行工具運(yùn)行對(duì)應(yīng)的python文件,就可以直接用了,這樣就在AlxBoard開(kāi)發(fā)板上實(shí)現(xiàn)了基于手勢(shì)選擇區(qū)域的場(chǎng)景文字識(shí)別應(yīng)用。
08后續(xù)指南
安裝語(yǔ)音播報(bào)支持包:
pip install pyttsx
AlxBorad開(kāi)發(fā)板是支持3.5mm耳機(jī)mic接口,支持語(yǔ)音播報(bào)的,如果把區(qū)域選擇識(shí)別的文字,通過(guò)pyttsx直接播報(bào)就可以實(shí)現(xiàn)從手勢(shì)識(shí)別到語(yǔ)音播報(bào)了,自動(dòng)跟讀卡片單詞啟蒙學(xué)英語(yǔ),后續(xù)實(shí)現(xiàn)一波,請(qǐng)繼續(xù)關(guān)注我們。
審核編輯:湯梓紅
-
英特爾
+關(guān)注
關(guān)注
61文章
10183瀏覽量
174198 -
開(kāi)發(fā)套件
+關(guān)注
關(guān)注
2文章
171瀏覽量
24625 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122597 -
OpenVINO
+關(guān)注
關(guān)注
0文章
114瀏覽量
435
原文標(biāo)題:在英特爾開(kāi)發(fā)套件上打造指哪識(shí)哪的OCR應(yīng)用|開(kāi)發(fā)者實(shí)戰(zhàn)
文章出處:【微信號(hào):英特爾物聯(lián)網(wǎng),微信公眾號(hào):英特爾物聯(lián)網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
首發(fā) | 告別手動(dòng)錄入,開(kāi)放平臺(tái)OCR上線印刷文字識(shí)別!
基于SnapDragonBoard410C文字識(shí)別
基于AI通用文字識(shí)別能力,檢測(cè)和識(shí)別文檔翻拍、街景翻拍等圖片中的文字
TH-OCR文字識(shí)別系統(tǒng)介紹
基于matlab的文字識(shí)別算法
基于FPGA的OCR文字識(shí)別技術(shù)的深度解析
如何提取和檢測(cè)視頻中的文字?數(shù)字視頻中文字的檢測(cè)提取技術(shù)的分析
如何在電腦中對(duì)圖片文字進(jìn)行局部識(shí)別
OCR文字識(shí)別視覺(jué)檢測(cè)系統(tǒng)應(yīng)用程序免費(fèi)下載
淺析HarmonyOS基于AI的通用文字識(shí)別技術(shù)
OpenVINO2021.4版本中場(chǎng)景文字檢測(cè)與識(shí)別模型的推理使用
圖片文字識(shí)別:揭開(kāi)數(shù)字世界的神秘面紗
基于OpenVINO+OpenCV的OCR處理流程化實(shí)現(xiàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論