


1. 前言
在上一篇文章里《如何使用UltraScale+芯片中UltraRam資源》,我們向大家介紹了在RTL設(shè)計中使用URAM的方法。其中,我們推薦大家使用Xilinx參數(shù)化宏(XPM)的方法來調(diào)用URAM。通過XPM調(diào)用的URAM的方法如下:
在模板中選擇“Verilog”->“Xilinx Parameterized Macros (XPM)”->“XPM”->“XPM_MEMORY” ->“Simple Dual Port Ram”
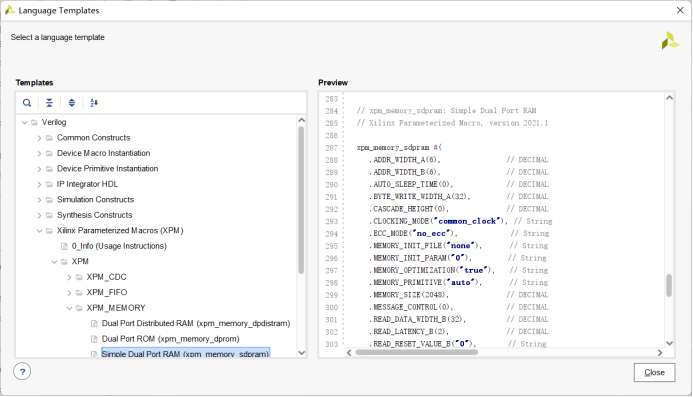
用戶必須在MEMORY_PRIMITIVE類屬上指定值 ”ultra”,以明確指示vivado 綜合使用 UltraRam。
那么問題來了,還有個參數(shù)“READ_LATENCY_A/B”該設(shè)多少?這個參數(shù)影響URAM的讀操作需要滯后多少時鐘周期才能將讀數(shù)據(jù)輸出。

2. 級聯(lián)URAM須知
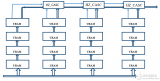
單個URAM器件的數(shù)據(jù)位寬為72bit,地址深度為4096,存儲容量為288Kb。因此,當(dāng)用戶需要大于288Kb存儲容量空間時,需要級聯(lián)多個URAM器件。在Kintex UltraScale+和Zynq UltraScale+器件中,級聯(lián)得到的RAM陣列可高達(dá)36Mb,在Virtex UltraScale+系列中,所有UltraRAM列都可通過光纖路由連接在一起,在最大器件中可構(gòu)成容量達(dá)360Mb的存儲器陣列。
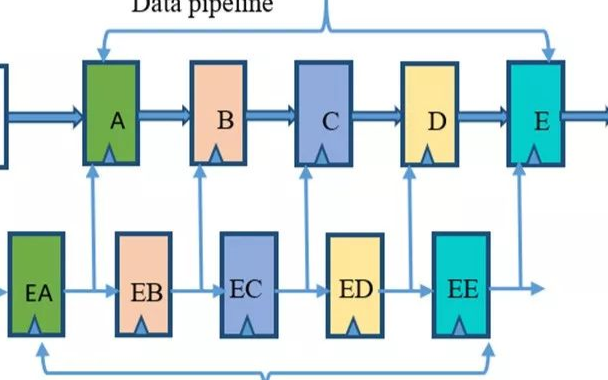
下圖展示了一個4 x 4的URAM陣列級聯(lián)結(jié)構(gòu),在縱向的一列中,每個URAM使用內(nèi)置級聯(lián)電路進(jìn)行級聯(lián)。在橫向多列之間,URAM通過外部級聯(lián)電路進(jìn)行互連,即水平級聯(lián)電路。

但是,URAM和Bram (block ram)不太一樣。在工作時鐘頻率不變情況下,深度級聯(lián)URAM陣列會使得數(shù)據(jù)輸出延遲越來越大,因為需要在級聯(lián)的URAM模塊中插入多級流水線,以保證模塊能時序收斂。
同樣,想保證輸出延遲固定,級聯(lián)越多的URAM會導(dǎo)致整個級聯(lián)的URAM可工作的時鐘頻率越低。
因此,我們需要謹(jǐn)慎的設(shè)置“READ_LATENCY_A/B”參數(shù),來保證級聯(lián)的URAM模塊能按自己的需求時序收斂并正常地工作。
注意: 如果使用XPM來調(diào)用URAM模塊,則URAM內(nèi)部可用的流水線階數(shù)是設(shè)定的LATENCY值減去2。例如,如果“READ_LATENCY_A/B”參數(shù)設(shè)為10,則允許8個寄存器階段用于流水線操作。
3. URAM性能估計
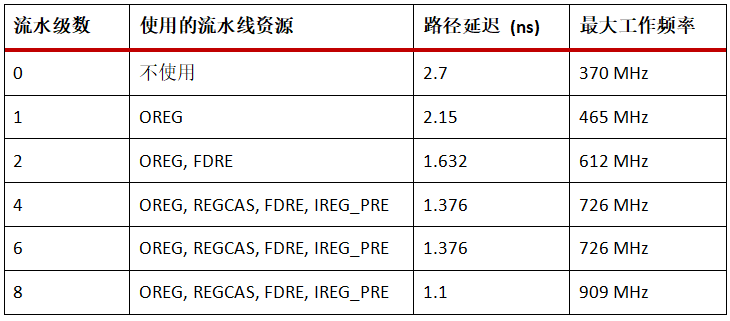
從上文,我們知道,LATENCY值的設(shè)置取決于URAM級聯(lián)的深度、工作頻率。下表以4x4的URAM矩陣為例,總結(jié)了流水線級數(shù)與可實現(xiàn)的最大工作頻率之間的關(guān)系。
注: 實際的延遲仍取決于設(shè)計中最終的布局布線結(jié)果。
注: 下表是基于Virtex UltraScale+ speed -2器件為基礎(chǔ)給的結(jié)果。
注: 該級聯(lián)的URAM陣列最大只支持8級流水線**。**
注: LATENCY取值為表中流水級數(shù)值加2。
4. 檢查設(shè)計是否達(dá)到最優(yōu)時序
第3節(jié)中的表只是一個參考,讓大家大致了解級聯(lián)的流水線級數(shù)、輸出延遲、工作頻率之間的關(guān)系。如果我已經(jīng)完成了設(shè)計,指定好了“READ_LATENCY_A/B”參數(shù)的值,如何確定該延遲值是否設(shè)置的最優(yōu)呢?
Vivado工具是提供了相應(yīng)的綜合報告來告知工程師級聯(lián)的URAM模塊是否能到達(dá)最優(yōu)時序。工程師在Vivado的GUI里,選中“Messages”一欄,查找有關(guān)URAM的提示。

一般提示如下,對應(yīng)的解決方法附在其后:

相信經(jīng)過這兩篇文章總結(jié),大家在如何使用URAM問題上應(yīng)該不會有太多的疑惑。
5.總結(jié)
本文向大家介紹了如何通過XPM調(diào)用URAM,并讓級聯(lián)URAM獲得最佳時序性能,如果覺得我們原創(chuàng)或引用的文章寫的還不錯,幫忙點贊和推薦吧,謝謝您的關(guān)注。
-
芯片
+關(guān)注
關(guān)注
460文章
52707瀏覽量
443832 -
Xilinx
+關(guān)注
關(guān)注
73文章
2185瀏覽量
127032 -
RTL
+關(guān)注
關(guān)注
1文章
390瀏覽量
61355 -
時序
+關(guān)注
關(guān)注
5文章
399瀏覽量
38193 -
UltraScale
+關(guān)注
關(guān)注
0文章
123瀏覽量
31967
發(fā)布評論請先 登錄
使用流水線寄存器實現(xiàn)最佳時序性能方案
應(yīng)該使用哪種策略來獲得最佳時序收斂?
URAM和BRAM的區(qū)別是什么
什么是調(diào)整電路板以獲得最佳性能的最佳方式?
級聯(lián)碼,什么是級聯(lián)碼

BRAM和URAM重要的片上存儲資源,兩者有顯著的區(qū)別
基于URAM原語創(chuàng)建容量更大的RAM
如何調(diào)整MLX75308的參數(shù)以獲得最佳性能的系統(tǒng)

URAM和BRAM有哪些區(qū)別
URAM和BRAM有什么區(qū)別
如何通過Vivado Synthesis中的URAM矩陣自動流水線化來實現(xiàn)最佳時序性能





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論