") 基于英特爾開發(fā)套件的AI字幕生成器設計
基于英特爾開發(fā)套件的AI字幕生成器設計
一、本文目的
市面上有很多自然語言處理模型,本文旨在幫助開發(fā)者快速將 OpenAI* 的熱門 NLP 模型 Whisper 部署至英特爾開發(fā)套件愛克斯開發(fā)板上,由于開發(fā)板內(nèi)存有限,所以我們選擇較輕量化的 Base Whisper 模型通過 OpenVINO 工具套件進行 AI 推理部署。由于聲音處理應用的廣泛性,開發(fā)者可以基于本項目繼續(xù)進行 AI 應用的頂層開發(fā)。
二、項目介紹
語音識別是人工智能中的一個領域,它允許計算機理解人類語音并將其轉換為文本。該技術用于 Alexa*和各種聊天機器人應用程序等設備。而我們最常見的就是語音轉錄,語音轉錄可以語音轉換為文字記錄或字幕。通過輸入音頻,通過 OpenVINO 優(yōu)化過的Whisper模型,將音頻進行 AI 處理,最后輸出音頻處理結果。此結果可以根據(jù)開發(fā)者不同的需求,繼續(xù)進行再次開發(fā)。
英特爾 開發(fā)套件——愛克斯開發(fā)板簡介
英特爾認證的開發(fā)套件 —— AIxBoard(愛克斯板*)開發(fā)板是專為支持入門級邊緣 AI 應用程序所設計的嵌入式硬件,它能夠滿足開發(fā)者對于人工智能學習、開發(fā)、實訓等應用場景的使用需求。
基于 x86 平臺所設計的開發(fā)板,可支持 Linux* Ubuntu*及完整版 Windows* 操作系統(tǒng),很方便開發(fā)者進行軟硬件開發(fā),以及嘗試所有 x86 平臺能夠應用的軟件功能。開發(fā)板搭載一顆英特爾賽揚N5105 4 核 4 線程處理器,睿頻可達 2.9GHz,且內(nèi)置英特爾超核芯顯卡,含有 24 個執(zhí)行單元,分辨率最大支持 4K 60 幀,同時支持英特爾 Quick Sync Video 技術可以快速轉換便攜式多媒體播放器的視頻。板載 64GB eMMC 存儲及 LPDDR4x 2933MHz(4GB/6GB/8GB),內(nèi)置藍牙和 Wi-Fi 模組,支持 USB 3.0、HDMI 視頻輸出、3.5mm 音頻接口,1000Mbps 以太網(wǎng)口。
此外, 其接口與 Jetson Nano 載板兼容,GPIO 與樹莓派兼容,能夠最大限度地復用樹莓派、Jetson Nano 等生態(tài)資源,無論是攝像頭物體識別,3D 打印,還是 CNC 實時插補控制都能穩(wěn)定運行。可作為邊緣計算引擎用于人工智能產(chǎn)品驗證、開發(fā);也可以作為域控核心用于機器人產(chǎn)品開發(fā)。
OpenVINO 工具套件介紹
OpenVINO 是一個開源工具包,可優(yōu)化和部署深度學習模型。它提供了針對視覺、音頻和語言模型的深度學習性能加速,支持流行框架如 TensorFlow、PyTorch 等。
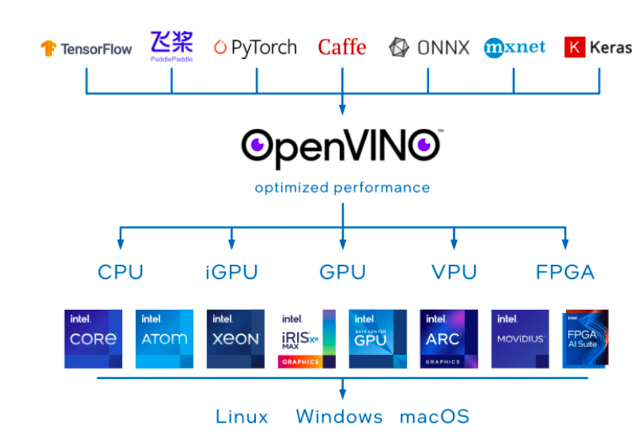
圖 3:OpenVINO 工具套件部署架構圖
OpenVINO 可以優(yōu)化幾乎任何框架的深度學習模型,并在各種英特爾處理器和其他硬件平臺上以最佳性能進行部署。OpenVINO Runtime 可以自動使用激進的圖形融合、內(nèi)存重用、負載平衡和跨 CPU、GPU、VPU 等進行集成并行處理,以優(yōu)化深度學習流水線。您可以集成和卸載加速器附加操作,以減少端到端延遲并提高吞吐量。通過 OpenVINO 的后訓練優(yōu)化工具和神經(jīng)網(wǎng)絡壓縮框架中提供的量化和其他最先進的壓縮技術,進一步提高模型的速度。這些技術還可以減少模型的大小和內(nèi)存需求,使其能夠部署在資源受限的邊緣硬件上。
Whisper 模型介紹
Whisper 來自于知名 AI 組織 OpenAI*,這個模型是一種通用的語音識別模型。它是在各種音頻的大型數(shù)據(jù)集上訓練的,也是一個多任務模型,可以執(zhí)行多語言語音識別、語音翻譯和語言識別。
wav2vec2、Conformer 和 Hubert 等最先進模型的最新發(fā)展極大地推動了語音識別領域的發(fā)展。這些模型采用無需人工標記數(shù)據(jù)即可從原始音頻中學習的技術,從而使它們能夠有效地使用未標記語音的大型數(shù)據(jù)集。它們還被擴展為使用多達 1,000,000小時的訓練數(shù)據(jù),遠遠超過學術監(jiān)督數(shù)據(jù)集中使用的傳統(tǒng) 1,000小時,但是以監(jiān)督方式跨多個數(shù)據(jù)集和領域預訓練的模型已被發(fā)現(xiàn)表現(xiàn)出更好的魯棒性和對持有數(shù)據(jù)集的泛化,所以執(zhí)行語音識別等任務仍然需要微調(diào),這限制了它們的全部潛力。為了解決這個問題 OpenAI 開發(fā)了 Whisper,一種利用弱監(jiān)督方法的模型。
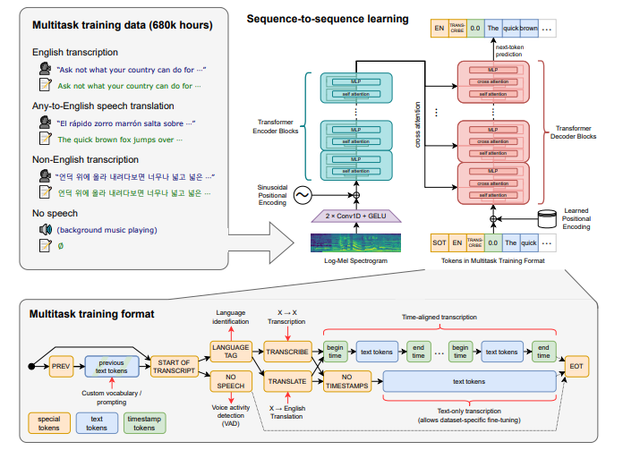
圖 4:Whisper 模型框圖
主要采用的結構是編碼器 - 解碼器結構。
模型的輸入音頻重采樣設為 16000 Hz,針對音頻的特征提取方法是使用 25 毫秒的窗口和 10 毫秒的步幅計算80通道的 log Mel 譜圖。最后對輸入特征進行歸一化,將輸入在全局內(nèi)縮放到 -1 到 1 之間,并且在預訓練數(shù)據(jù)集上具有近似為零的平均值。
編碼器/解碼器:
該模型的編碼器和解碼器采用 Transformers。
編碼器的過程:
編碼器首先使用一個包含兩個卷積層(濾波器寬度為 3)的詞干處理輸入表示,使用 GELU 激活函數(shù)。
第二個卷積層的步幅為 2,然后將正弦位置嵌入添加到詞干的輸出中,然后應用編碼器 Transformer 塊。
Transformers 使用預激活殘差塊,編碼器的輸出使用歸一化層進行歸一化。
解碼的過程:
在解碼器中,使用了學習位置嵌入和綁定輸入輸出標記表示。
編碼器和解碼器具有相同的寬度和數(shù)量的 Transformers 塊。
訓練:
為了改進模型的縮放屬性,它在不同的輸入大小上進行了訓練。
通過 FP16、動態(tài)損失縮放,并采用數(shù)據(jù)并行來訓練模型。
使用 AdamW 和梯度范數(shù)裁剪,在對前 2048 次更新進行預熱后,線性學習率衰減為零。
使用 256 個批大小,并訓練模型進行 220 次更新,這相當于對數(shù)據(jù)集進行兩到三次前向傳遞。
Whisper 在不同數(shù)據(jù)集上的對比結果,相比 wav2vec 取得了目前最低的詞錯誤率,如下表:
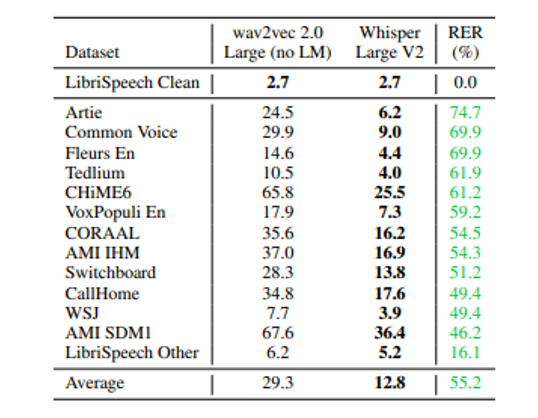
圖 5:Whisper 模型與 wav2vec 詞錯誤率對比表
三、項目流程
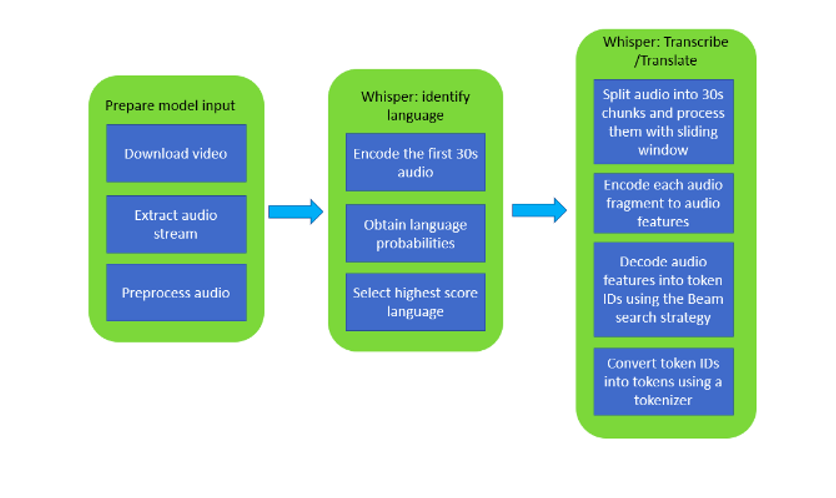
圖 6:Whisper 模型語音處理流程圖
利用 Whisper 模型進行視頻文字識別的流程如上,首先準備語音文件,常規(guī)操作是將語音流從視頻流中分離,然后通過 Whisper 模型編碼語音文件的前 30 秒,輸出該語音文件對于的語言種類的多種可能性,選擇可能性最高的一種語言繼續(xù)進行編碼。將整段語音文件分割成多個 30 秒的小段進行編碼,再通過 Beam 搜索算法將音頻特征都轉 為token ID, 最后將 token ID 翻譯成 tokens 就可以獲得識別到的文本了。
使用 OpenVINO 工具套件對 Whisper 模型進行推理加速,主要在 Encoder 和 Decoder 上使用 OpenVINO Runtime,對應到流程圖中,我們在不更改主體 pipeline 的前提下,OpenVINO 為流程中的“Positional Encoding”和“Cross attention”賦能,代碼實現(xiàn)層面就是使用 OpenVINO Runtime API 替換掉原先的 Encoder 和 Decoder,使得 OpenVINO 得以加入到這個音頻處理流程中,如下圖所示:
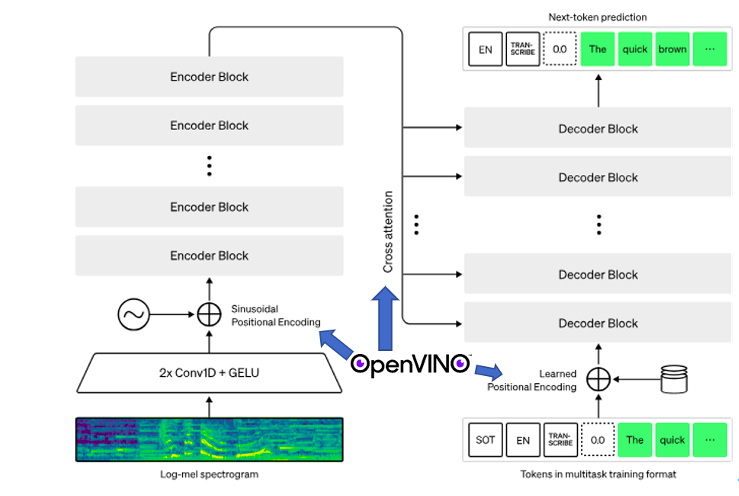
圖 7:OpenVINO 賦能 Whisper 模型項目示意圖
四、實驗流程
硬件:英特爾開發(fā)套件 —— 愛克斯開發(fā)板
OS:Ubuntu 20.04LTS
軟件:OpenVINO 2023.0,Whisper
由于 Whisper 預訓練模型根據(jù)參數(shù)量分為 Tiny, Base, Small, Medium, Large。本次實驗中選擇參數(shù)量為 74M 的 base 模型進行實驗,使用預訓練模型直接通過 OpenVINO 的模型優(yōu)化器 API 轉換為 IR 格式文件,將 Whisper 的編解碼器構建成流水線,便可對視頻進行語音轉文字的 AI 處理了。
安裝依賴:
為實現(xiàn)最快速的部署,我們直接下載 OpenVINO Open Model Zoo 里的現(xiàn)成 Notebook 進行實驗。
Git clone https://github.com/openvinotoolkit/ openvino_notebooks.git
左滑查看更多
構建虛擬環(huán)境,安裝 OpenVINO,Whisper 以及其他依賴:
python3 -m venv openvino_env source env/bin/activate
左滑查看更多
命令行中運行如下 pip 安裝指令:
pip install openvino pip install -q "python-ffmpeg<=1.0.16" moviepy transformers onnx python -m pip install pytube pip install -q -U gradio pip install git+https://github.com/openai/whisper.git
左滑查看更多
進入 notebooks/227-whisper-subtitles-generation/目錄中,安裝 Jupyter Notebook 并打開 227-whisper-convert.ipynb 文件:
pip install notebook jupyter notebook
下面進入 227-whisper-convert.ipynb 文件中運行代碼
首先,下載 Whisper 現(xiàn)成的預訓練模型,代號為“base”
import whisper
model = whisper.load_model("base")
model.to("cpu")
model.eval()
pass
左滑查看更多
模型主要是編碼器 - 解碼器的結構,所以我們先把 Encoder 部分被轉成 IR 模型,保存至本地:
import torch import openvino as ov mel = torch.zeros((1, 80, 3000)) audio_features = model.encoder(mel) encoder_model = ov.convert_model(model.encoder, example_input=mel) ov.save_model(encoder_model, WHISPER_ENCODER_OV)
左滑查看更多
然后把模型的 Decoder 部分也轉成 IR 模型,保存至本地:
tokens = torch.ones((5, 3), dtype=torch.int64) logits, kv_cache = model.decoder(tokens, audio_features, kv_cache=None) tokens = torch.ones((5, 1), dtype=torch.int64) decoder_model = ov.convert_model(model.decoder, example_input=(tokens, audio_features, kv_cache)) ov.save_model(decoder_model, WHISPER_DECODER_OV)
左滑查看更多
創(chuàng)建 core 對象,啟用 OpenVINO Runtime:
core = ov.Core()
推理設備選擇“AUTO”Plugin,表示自動選擇當前系統(tǒng)最優(yōu)的推理硬件:
device = widgets.Dropdown( options=core.available_devices + ["AUTO"], value='AUTO', description='Device:', disabled=False, )
左滑查看更多
我們的實驗將復用原生模型處理音頻的 pipeline,只需要將原來的編碼器和解碼器用 OpenVINO Runtime API 重寫,即可得到 OpenVINO 加速過的 pipeline。
當前文件目錄下包含“utils.py”,此腳本中集成了三個最重要的類,分別是:
patch_whisper_for_ov_inference,
OpenVINOAudioEncoder,
OpenVINOTextDecoder。
patch_whisper_for_ov_inference 主要提供了一些功能函數(shù),比如獲取音頻,增加時間戳,生成字幕文件等等。另外兩個類在這里的作用是使用 OpenVINO Runtime API 對原始模型 Encoder 和 Decoder 進行重寫,利用 OpenVINO Runtime 替換掉原始模型中的 Encoder 和 Decoder 以加速優(yōu)化模型運行的速度。
from utils import patch_whisper_for_ov_inference, OpenVINOAudioEncoder, OpenVINOTextDecoder patch_whisper_for_ov_inference(model) model.encoder = OpenVINOAudioEncoder(core, WHISPER_ENCODER_OV, device=device.value) model.decoder = OpenVINOTextDecoder(core, WHISPER_DECODER_OV, device=device.value)
左滑查看更多
最終,調(diào)用 model.transcribe 函數(shù),運行 AI 推理,并將生成的字幕文件保存為 srt 格式文件:
output_file = Path("downloaded_video.mp4")
from utils import get_audio
audio = get_audio(output_file)
task = widgets.Select(
options=["transcribe", "translate"],
value="translate",
description="Select task:",
disabled=False
)
task
transcription = model.transcribe(audio, task=task.value)
from utils import prepare_srt
srt_lines = prepare_srt(transcription)
# save transcription
with output_file.with_suffix(".srt").open("w") as f:
f.writelines(srt_lines)
左滑查看更多
注意,由于 Notebook 提供的視頻是 YTB 的視頻,可能遇到無法下載的情況,這里我們也提供了一小段英文視頻可供讀者自由下載
只需將下載視頻替換 notebook 里的視頻路徑即可體驗 AI 字幕的功能。
結果展示:
視頻播放軟件可以直接導入 SRT 字幕文件生成字幕
五、小結
英特爾認證的開發(fā)套件—— 愛克斯開發(fā)板以 Intel Celeron N5105 作為處理核心,在相同的功耗下獲得了優(yōu)秀的計算性能。在本次實驗中,它在 OpenVINO 工具套件的加持下可以輕松完成語音轉文字的任務,通過輕量化 AI 模型(Whisper)實現(xiàn)字幕實時生成的功能。回顧之前搭建流媒體服務器的文章,我們可以使用開發(fā)板搭建一個 RTMP 流媒體服務器,然后可以將它們結合,將輸入服務器的視頻流實時生成字幕之后進行輸出,這樣就可以獲得一個能給視頻加英文字幕的流媒體服務器。愛克斯板的 I/O 接口豐富,攝像頭,麥克風,傳感器都可以進行接入,并且開發(fā)板有著不錯的 CPU 處理性能,可以在 OpenVINO 工具套件的加持下處理一些常規(guī)的 AI 推理任務,開發(fā)者可以根據(jù)項目需求進行巧妙搭配,組合創(chuàng)新。作為英特爾認證的 DevKit,這塊小小的開發(fā)板卻蘊含著巨大的能量,可以兼容市面上大多數(shù)的擴展設備,也可以應用上英特爾提供的軟硬件技術,加上集成顯卡能為編解碼處理與 AI 推理賦能,這塊板子還是能創(chuàng)造出許多有趣的應用的。如果你對這塊開發(fā)板感興趣,那就趕快行動起來,開始你的開發(fā)創(chuàng)造之旅吧。
審核編輯:湯梓紅
-
英特爾
+關注
關注
61文章
9949瀏覽量
171692 -
AI
+關注
關注
87文章
30728瀏覽量
268886 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238245 -
開發(fā)套件
+關注
關注
2文章
154瀏覽量
24271 -
OpenVINO
+關注
關注
0文章
92瀏覽量
196
原文標題:如何使用英特爾開發(fā)套件部署 AI 字幕生成器 | 開發(fā)者實戰(zhàn)
文章出處:【微信號:英特爾物聯(lián)網(wǎng),微信公眾號:英特爾物聯(lián)網(wǎng)】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
英特爾82801HM IO控制器開發(fā)套件

英特爾QM57高速芯片組開發(fā)套件

英特爾酷睿2雙核處理器SL9380和英特爾3100芯片組開發(fā)套件

英特爾凌動N270處理器和移動式英特爾945GSE高速芯片組開發(fā)套件

英特爾BOOT Loader開發(fā)套件-高級嵌入式開發(fā)基礎

英特爾945GME高速芯片組開發(fā)套件

使用英特爾物聯(lián)網(wǎng)商業(yè)開發(fā)套件改變世界
最新版英特爾? SoC FPGA 嵌入式開發(fā)套件(SoC EDS)全面的工具套件
英特爾開源WebRTC開發(fā)套件OWT 帶來巨大的潛在商業(yè)回報
python生成器是什么
英特爾發(fā)布開源AI參考套件
英特爾通過AI參考套件加速AI發(fā)展

基于OpenVINO在英特爾開發(fā)套件上實現(xiàn)眼部追蹤
英特爾開發(fā)套件『哪吒』在Java環(huán)境實現(xiàn)ADAS道路識別演示 | 開發(fā)者實戰(zhàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論