 深度學習模型部署與優化:策略與實踐;L40S與A100、H100的對比分析
深度學習模型部署與優化:策略與實踐;L40S與A100、H100的對比分析
★深度學習、機器學習、生成式AI、深度神經網絡、抽象學習、Seq2Seq、VAE、GAN、GPT、BERT、預訓練語言模型、Transformer、ChatGPT、GenAI、多模態大模型、視覺大模型、TensorFlow、PyTorch、Batchnorm、Scale、Crop算子、L40S、A100、H100、A800、H800
隨著生成式AI應用的迅猛發展,我們正處在前所未有的大爆發時代。在這個時代,深度學習模型的部署成為一個亟待解決的問題。盡管GPU在訓練和推理中扮演著關鍵角色,但關于它在生成式AI領域的誤解仍然存在。近期英偉達L40S GPU架構成為了熱門話題,那么與A100和H100相比,L40S有哪些優勢呢?
生成式AI應用進入
大爆發時代
一、驅動因素:大模型、算力與生態的共振
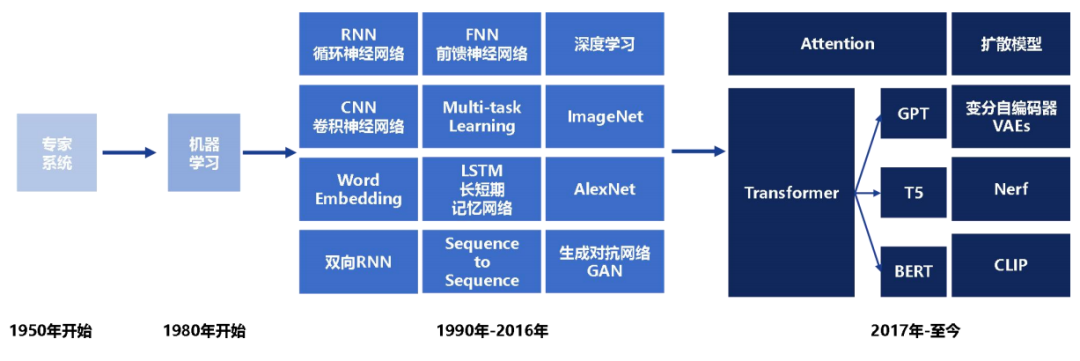
生成式AI起源于20世紀50年代Rule-based的專家系統,雖具備處理字符匹配、詞頻統計等簡單任務的能力,但詞匯量有限,上下文理解欠佳,生成創造性內容的能力非常薄弱。
80年代機器學習的興起為AI注入新動力,90年代神經網絡的出現使其開始模仿人腦,從數據中學習生成更真實內容的能力。當代生成式AI的核心技術起源于2012年后深度神經網絡結構的不斷深化,模型通過層層抽象學習任務的復雜特征表示,進而提高準確性和真實性。
隨后幾年,Seq2Seq、VAE、GAN等一系列算法的成熟,以及計算能力和數據規模的增長,使大模型訓練成為可能,讓生成式AI發展產生質的飛躍。特別是GPT、BERT等預訓練語言模型的誕生,標志著文本生成領域邁入新的階段。
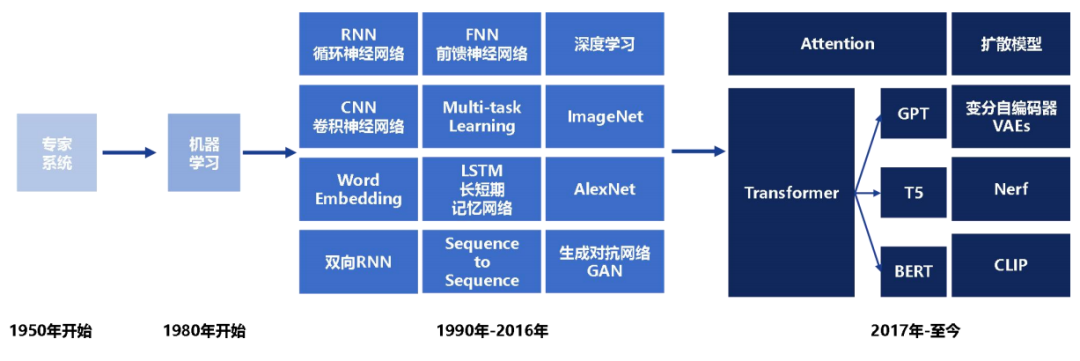
人工智能產業發展浪潮
1、模型、算力、生態推動 AI 應用進入大爆發時代
1)算法及模型的快速進步
GenAI在文本領域取得重大進展,隨著2017年Transformer模型的發布和2022年ChatGPT的推出,其多項能力已經超越人類基準。未來,更強大的語言大模型如GPT-5以及多模態大模型和視覺大模型的技術突破,將繼續推動AI應用的持續進化。
2)算力基礎設施將更快、更便宜
雖然短期內大模型訓練需求的激增導致算力成本的持續上漲,但是隨著英偉達算力芯片的不斷更新迭代,微軟、亞馬遜、谷歌等在 AI 云服務資本開支的不斷加大,AI 應用的發展將得到更加強有力的支撐。
3)AI 生態的逐漸成熟
AI 組件層(AI Stack)的完善和產業分工細化,為 AI 應用在模型訓練、數據整合、應用開發、應用部署等環節提供全生命周期的支撐。
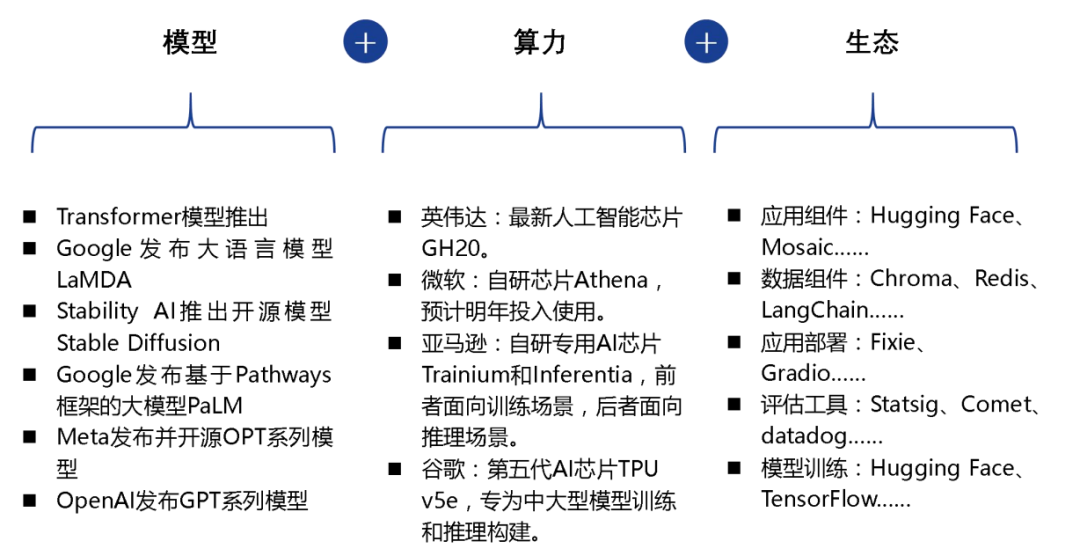
模型、算力、生態推動為 AI 應用進入大爆發時代
目前,GPT-4在推理、生成、對話等多個維度上已經超過人類水平。其強大不僅在于文本,更在于大模型框架本身就可適用于各種任務,成為包括圖像、代碼、音頻等在內的多模態生成的統一技術基礎。
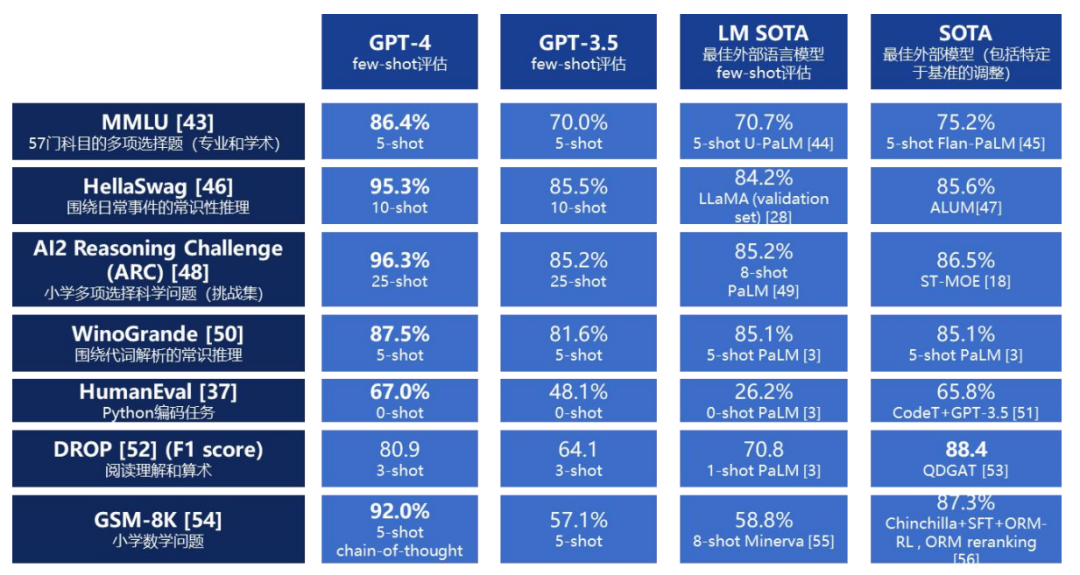
GPT-4 是目前最強大的大模型
二、產業現狀:一二級視角看 AI 應用的演進
生成式AI應用的發展經歷三個階段:
1、GPT-3催生期
GPT-3強大的語言生成能力,使第一批像Jasper AI的生成式AI應用得以在2021年誕生,并迅速增長用戶和收入。
2、2022年爆發期
這一年AI作畫應用層出不窮,代表作有MidJourney和Stable Diffusion等。同時ChatGPT的發布標志著文本生成進入新的高度。視頻、3D等其他模態的生成能力也在提升。
3、2023年商業化期
GPT-4進一步提升語言模型能力,而開源模型Llama提供低成本選擇。各行業的AI應用如雨后春筍般涌現,Microsoft和Salesforce等巨頭公布了AI產品的商業定價,預示著AI應用正式步入商業化。
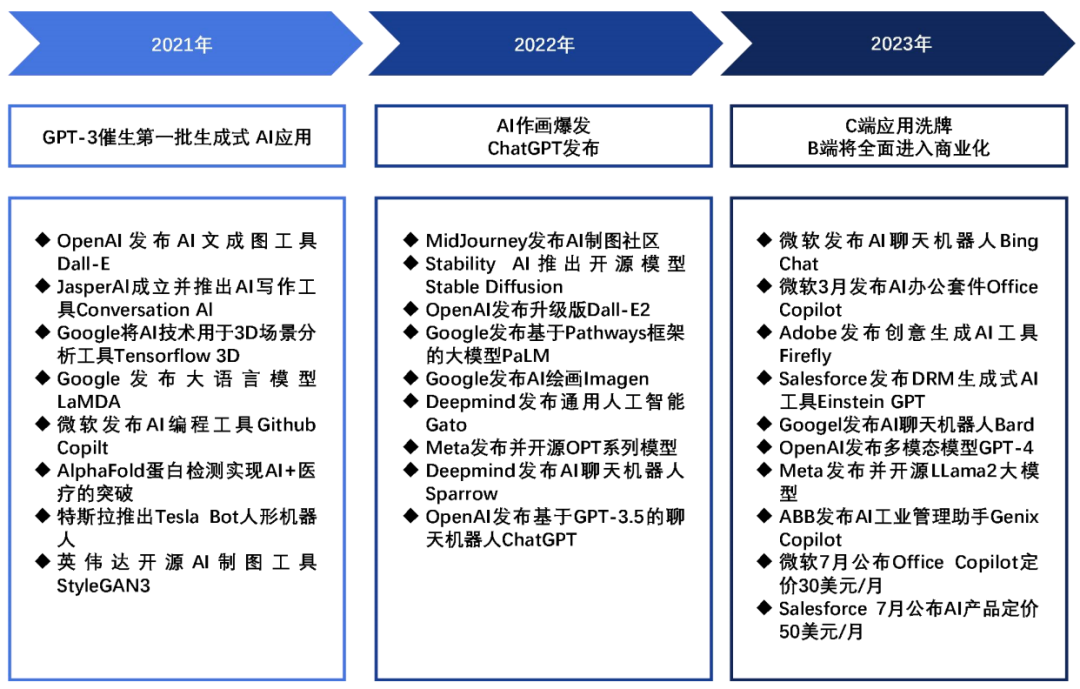
生成式 AI 應用的發展階段
三、應用框架:應用的四大賽道與產業邏輯
生成式AI應用可分為工具類、通用軟件類、行業軟件類和智能硬件類。工具類應用如聊天機器人主要服務C端,同質化嚴重,對底層模型高度依賴。通用軟件類應用如辦公軟件,標桿產品已經出現,將進入商業化階段。行業軟件類面向特定垂直領域,如金融和醫療,行業差異大,數據挖掘是核心競爭力。智能硬件類應用如自動駕駛,感知和決策是瓶頸,需要底層技術突破。從工具類到智能硬件類,應用呈現從通用到專業、從C端到B端的演進趨勢,競爭核心也從對模型依賴向數據應用和底層技術創新轉變。這標志著生成式AI應用正在朝著成熟和落地方向發展。
生成式 AI 應用產業地圖
生成式AI的三大底層元能力是感知、分析和生成。當前以文本理解為主,未來會延伸到圖像視覺感知。分析能力將從信息整合走向復雜推理。生成能力也會從文本拓展到圖片、視頻等多模態內容。通過這三大能力的協同提升,生成式AI將實現跨模態的統一感知、理解和創造,向著對真實世界的全面理解與創造性反應的方向演進,以達到更強大的智能水平。
生成式AI未來發展有四大方向:內容生成、知識洞察、智能助手和數字代理。內容生成是核心價值,通過提升大模型和多模態技術實現更廣泛內容的自動化生成。知識洞察利用大模型分析數據提供洞見,服務決策。智能助手將AI能力嵌入場景中主動協作。數字代理基于環境自主決策和行動達成目標。從被動服務到主動作為,生成式AI正朝著具備內容創造、洞悉世界、智能協作及自主行動的更高智能方向演進。
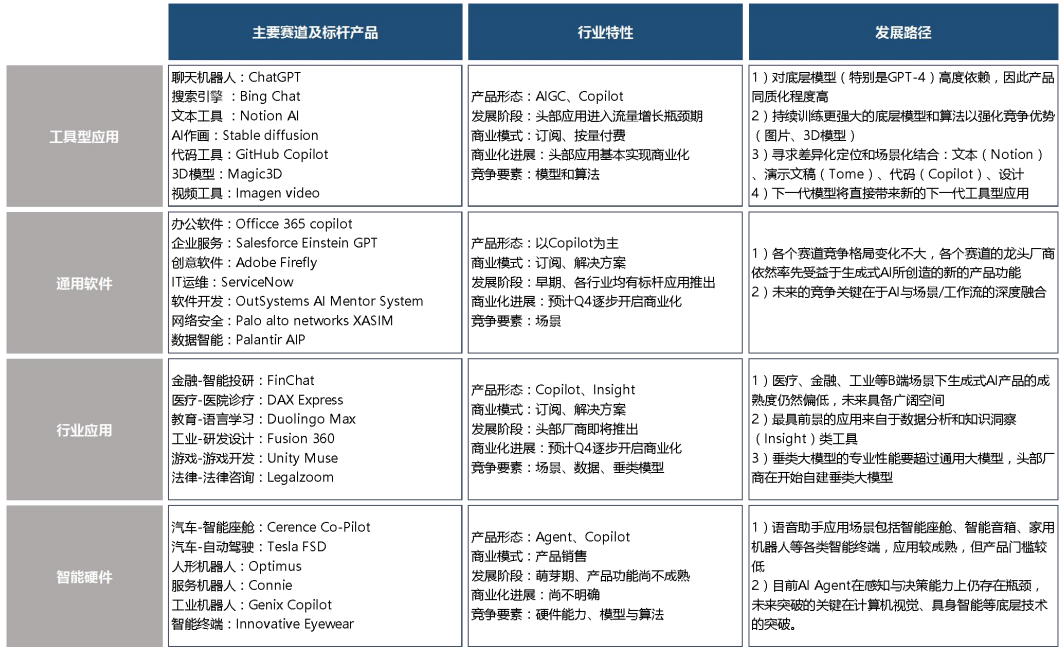
AI 細分應用的標桿產品與發展路徑
深度學習模型如何部署
訓練出的模型需要經過優化和調整,以轉化為標準格式的推理模型,以便在部署中使用。優化包括算子融合、常量折疊等操作,以提高推理性能。由于部署目標場景各異,需要根據硬件限制來選擇合適的模型格式。為了適應硬件限制,可能需要使用模型壓縮或降低精度等方法。模型部署后,推理時延和占用資源是關鍵指標,可以通過定制化芯片和軟硬協同優化等方式進行改進。在軟件優化中,需要考慮到數據布局、計算并行等因素,并針對CPU架構進行設計。模型是企業的重要資產,因此部署后必須確保其安全性。總之,模型從訓練到部署需要經歷多個過程,包括轉化優化、規模調整和軟硬協同等,以確保適應不同場景的資源限制、性能指標和安全要求,并充分發揮模型的價值。
針對上述模型部署時的挑戰,業界有一些常見的方法:
算子融合
通過表達式簡化、屬性融合等方式將多個算子合并為一個算子的技術,融合可以降低模型的計算復雜度及模型的體積。
常量折疊
將符合條件的算子在離線階段提前完成前向計算,從而降低模型的計算復雜度和模型的體積。
模型壓縮
通過量化、剪枝等手段減小模型體積以及計算復雜度的技術,可以分為需要重訓的壓縮技術和不需要重訓的壓縮技術兩類。
數據排布
根據后端算子庫支持程度和硬件限制,搜索網絡中每層的最優數據排布格式,并進行數據重排或者插入數據重排算子,從而降低部署時的推理時延。
模型混淆
對訓練好的模型進行混淆操作,主要包括新增網絡節點和分支、替換算子名的操作,攻擊者即使竊取到混淆后的模型也不能理解原模型的結構。此外,混淆后的模型可以直接在部署環境中以混淆態執行,保證模型在運行過程中的安全性。
一、訓練模型到推理模型的轉換及優化
1、模型轉換
不同的模型訓練框架如TensorFlow和PyTorch都有各自的數據結構定義,這給模型部署帶來了一定的不便。為解決這個問題,業界開發開放的神經網絡交換格式ONNX。它具有強大的表達能力,支持各種運算符,并提供不同框架到ONNX的轉換器。
模型轉換的本質是在不同的數據結構之間傳遞結構化信息。因此,需要分析兩種結構的異同點,對相似的結構部分進行直接映射,而對差異較大的部分則要根據語義找出合理的轉換方式。如果存在不兼容的情況,則無法進行轉換。
ONNX的優勢在于其強大的表達能力,大多數框架的模型都可以轉換到ONNX上,從而避免了不兼容的問題。作為中間表示格式,ONNX成為不同框架和部署環境之間的橋梁,實現模型的無縫遷移。
模型可以抽象為一種圖,從而模型的數據結構可以解構為以下兩個要點:
1)模型拓撲連接
從圖論角度看是圖的邊,對應模型中的數據流和控制流。決定子圖表達、輸入輸出以及控制流結構。不同框架對此有不同表示,需要進行等價轉換。如TensorFlow的循環控制流轉為ONNX的While、If算子,避免引入環。
2)算子原型定義
從圖論角度看是圖的頂點,對應模型的運算單元。包括算子類型、輸入輸出、屬性等。不同框架的算子雖然名稱相同,但語義不一致。因此需要解析語義等價性,進行適當映射。例如Caffe的Slice算子需要轉為ONNX的Split。沒有完全等價算子也需要組合表達。
模型轉換完成后,會進行各種優化來提前完成一些常量計算,合并相關的算子,用更強大的算子替換多個簡單算子,根據依賴關系重排算子等。這些算子融合、折疊、替換、重排的優化手段和編譯器進行的優化非常類似,目的都是提前計算,減少運算量,增強并行度。之所以只能在部署階段進行徹底優化是因為只有這個時段才能確定硬件后端和運行環境。模型部署階段的優化能夠有效壓縮模型大小,減少計算量,提升執行效率。與編譯優化思路一脈相承都遵循提前計算、融合運算、調整布局的策略,以更好地發揮硬件性能。
2、算子融合
算子融合是一種模型壓縮技術,其核心思想是合并多個相關的算子成一個算子。在深度學習模型中,大量重復的計算和頻繁的內存訪問會導致推理延遲和能耗問題。算子融合通過解析模型拓撲結構,找出可以合并的算子節點,按照一定規則將其“融合”為新的算子。這相當于在圖論中的“合同圖”,可以有效減少節點數量和邊數量。減少節點數量意味著運算步驟更少,減少邊數量意味著內存訪問更少。因此,算子融合技術可以減小模型的計算復雜度和存儲占用,從而降低模型推理時的時延和功耗。
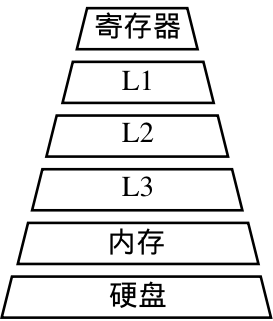
計算機分層存儲架構
算子融合的性能提升主要源自兩點:
1)充分利用緩存,減少內存訪問
CPU寄存器和多級緩存速度遠快于內存,融合后一次計算結果可暫存至高速緩存,供下一計算直接讀取,省去內存讀寫的開銷。
2)提前計算,消除冗余
多次相同計算可以預先完成,避免在前向推理時重復運算,特別是循環中的重復計算。CPU與內存之間存在巨大的速度鴻溝。靠近CPU的緩存越小且越快,內存越大越慢。算子融合通過合并操作,充分利用緩存加速重復計算,并消除冗余,減少內存訪問次數。這是其能明顯減小時延和功耗的根本原因。
3、算子替換
算子替換旨在將模型中的算子替換為計算邏輯相同但更適合在線部署的算子。該技術通過數學方法如合并同類項和提取公因式,簡化算子的計算公式,并將簡化后的公式映射到一類更高效的算子上。通過算子替換,可以實現降低計算量和模型大小的效果。
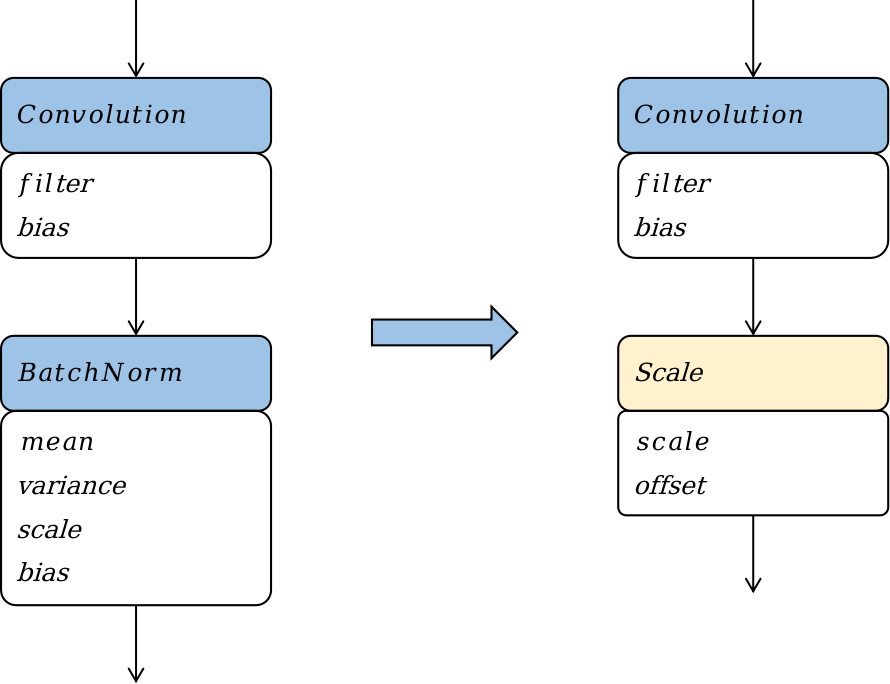
Batchnorm算子替換
通過將Batchnorm算子替換為Scale算子,可以在模型部署階段優化功耗和性能。然而需要注意的是,這種優化策略只適用于部署階段,因為在訓練階段,Batchnorm算子中的參數被視為變量而不是常量。此外,這種優化策略會改變模型的結構,降低模型的表達能力,并且可能影響模型在訓練過程中的收斂性和準確率。
4、算子重排
算子重排通過重新排布模型中算子的拓撲序來減少模型推理的計算量,同時保持推理精度不變。常見的算子重排技術包括將裁切類算子(如Slice、StrideSlice、Crop等)向前移動,對Reshape和Transpose算子進行重排,以及對BinaryOp算子進行重排。這些技術的目標是通過重新組織算子的計算順序,減少不必要的計算和數據傳輸,從而提高模型的推理效率。
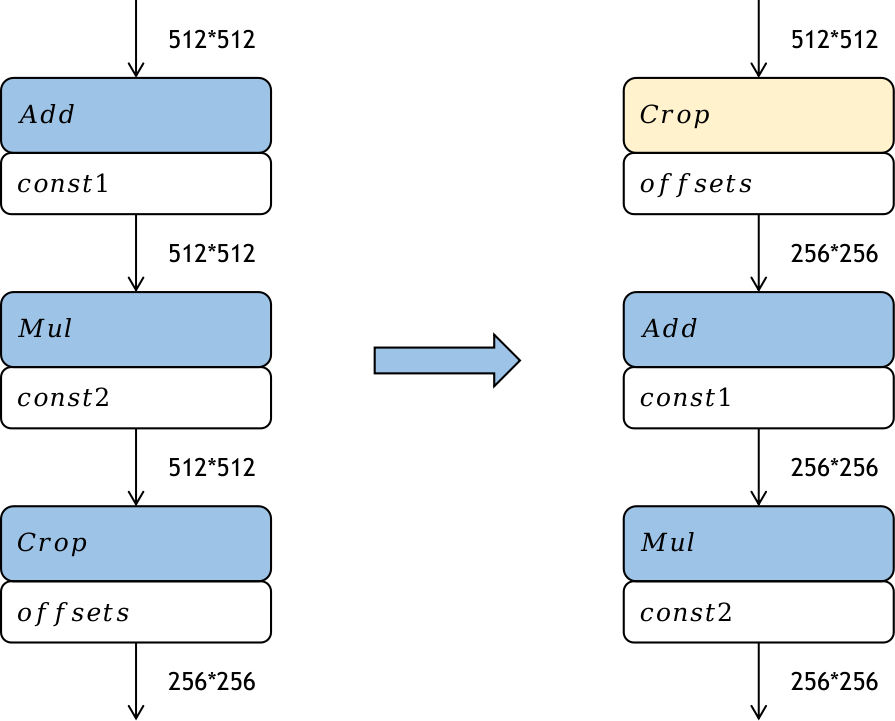
Crop算子重排
通過將Crop算子的裁切過程前移,即在模型中提前對特征圖進行裁切,可以降低后續算子的計算量,從而提高模型在部署階段的推理性能。這種優化策略的性能提升取決于Crop算子的參數設置。然而需要注意的是,只有element-wise類算子才能進行前移操作。根據之前的實驗數據,可以看出,在模型部署前進行優化可以顯著提升推理的時延、功耗和內存占用效果。
二、模型壓縮
針對不同硬件環境的需求差異,比如在手機等資源受限的設備上部署模型時,對模型大小通常有嚴格的要求,一般要求在幾兆字節的范圍內。因此,對于較大的模型,通常需要采用一些模型壓縮技術,以滿足不同計算硬件的需求。這些技術可以通過減少模型參數、降低模型復雜度或使用量化等方法來實現。通過模型壓縮,可以在保持模型性能的同時,減小模型的存儲空間和計算開銷,從而更好地適應不同的硬件平臺。
1、量化
模型量化通過以較低的推理精度損失來表示連續取值的浮點型權重。通過使用更少的位數來表示浮點數據,模型量化可以減小模型的尺寸,從而減少在推理過程中的內存消耗。此外,在一些支持低精度運算的處理器上,模型量化還可以提高推理速度。
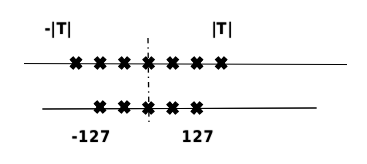
量化原理
在計算機中,不同數據類型的占用比特數和表示范圍不同。通過將模型的參數量化為不同位數的數據類型,可以根據實際需求來降低模型的存儲大小。一般來說,深度神經網絡中的參數使用單精度浮點數表示,但如果可以近似使用有符號整數來表示參數,那么量化后的權重參數存儲大小可以減少到原來的四分之一。量化位數越少,模型壓縮率越高。
此外,根據量化方法是否使用線性或非線性量化,可以進一步將量化方法分為線性量化和非線性量化。實際深度神經網絡中,權重和激活值通常是不均勻的,因此理論上,非線性量化可以更準確地表示這些值,從而減小精度損失。然而,在實際推理中,非線性量化的計算復雜度較高,因此通常使用線性量化來進行模型量化。
1)量化感知訓練
量化感知訓練是一種在訓練過程中模擬量化的方法,通過在模型中插入偽量化算子來模擬量化操作。在每次訓練迭代中,量化感知訓練會計算量化網絡層的權重和激活值的范圍,并將量化損失引入前向推理和反向傳播的過程中。通過這種方式,優化器可以在訓練過程中盡量減少量化誤差,從而獲得更高的模型精度。
具體而言,量化感知訓練的流程如下:
初始化:設置權重和激活值的范圍,并初始化網絡的權重和激活值。構建模擬量化網絡:在需要量化的權重和激活值后插入偽量化算子,以模擬實際量化操作。
量化訓練:重復以下步驟直到網絡收斂。a. 計算量化網絡層的權重和激活值的范圍。b. 根據范圍將量化損失帶入前向推理和反向傳播的過程中,以更新網絡的參數。
導出量化網絡:獲取量化網絡層的權重和激活值的范圍,并計算量化參數。將量化參數代入量化公式中,將網絡中的權重轉換為量化整數值。最后,刪除偽量化算子,并在量化網絡層前后分別插入量化和反量化算子,以得到最終的量化網絡。
通過量化感知訓練,可以在減小模型尺寸的同時,盡量保持模型的精度,并在低精度運算較快的處理器上獲得更快的推理速度。
2)訓練后量化
在訓練后的量化中,有兩種常見的方法:權重量化和全量化。
權重量化僅對模型的重進行量化,以減小模型的大小。在推理時,將量化后權重反量化為原始的float32數據,并使用普通的float32算子進行推理。權重量化的好處是不需要校準數據集,不需要實現量化算子,并且模型的精度誤差較小。然而,由于實際推理仍使用float32算子,推理性能不會提高。
全量化不僅量化模型權重,還量化模型激活值,通過執行量化算子來加速推理過程。為量化激活值,需要提供一定數量校準數據集,用于統計每一層激活值的分布,并對量化算子進行校準。校準數據集可以來自訓練數據集或真實場景的輸入數據,通常數量很小。
在量化激活值時,首先使用直方圖統計原始float32數據的分布。然后,在給定的搜索空間中選擇適當的量化參數,將激活值量化為量化后的數據。接下來,使用直方圖統計量化后的數據分布,并計算量化參數,以度量量化前后的分布差異。
此外,由于量化存在固有誤差,需要校正量化誤差。例如,在矩陣乘法中,需要校正量化后的均值和方差,以使其與float32算子一致。通過對量化后的數據進行校正,可以保持量化后的分布與量化前一致。
量化方法作為一種通用的模型壓縮方法,可以顯著提高神經網絡存儲和壓縮的效率,并已經被廣泛應用。
2、模型稀疏
稀疏模型是一種通過減少神經網絡中的組件來降低存儲和計算成本的方法。它是一種為了降低模型計算復雜度而引入的強歸納偏差,類似于模型權重量化、權重共享和池化等方法。
1)模型稀疏的動機
稀疏模型的合理性可以從兩個方面解釋。
現有的神經網絡模型通常存在過多的參數,這導致模型過于復雜和冗余。
對于許多視覺任務來說,激活值特征圖中有用的信息只占整個圖像的一小部分。
基于這些觀察,稀疏模型可以通過去除權重或激活值中弱連接來減少冗余。具體而言,稀疏模型會根據連接的強度(通常是權重或激活的絕對值大小)對一些較弱的連接進行剪枝,將它們置為零。這樣可以提高模型的稀疏度,并降低計算和存儲的需求。
然而,需要注意的是,稀疏模型的稀疏度越高,模型的準確率下降可能會越大。因此,稀疏模型的目標是在提高稀疏度的同時盡量減小準確率的損失。
2)結構與非結構化稀疏
權重稀疏可以分為結構化和非結構化稀疏。結構化稀疏通過在通道或卷積核層面對模型進行剪枝,得到規則且規模更小的權重矩陣。這種稀疏方式適合在CPU和GPU上進行加速計算,但準確率下降較大。非結構化稀疏可以對權重矩陣中任意位置的權重進行裁剪,準確率下降較小。然而,非結構化稀疏的不規則性導致難以利用硬件加速,并帶來指令層面和線程層面的并行度下降,以及訪存效率降低的問題。為了克服這些問題,最近的研究提出了結合結構化和非結構化稀疏的方法,以兼具兩者的優點并解決其缺點。
3)稀疏策略
稀疏模型的具體策略包括預訓練、剪枝和微調。預訓練是指首先訓練一個稠密模型,然后在此基礎上進行稀疏和微調。剪枝是指根據一定的規則或標準,去除模型中的冗余權重,使模型更加稀疏。剪枝可以一次性進行,也可以與訓練交替進行,逐步發現冗余的部分。微調是指在剪枝后對模型進行進一步的訓練,以恢復稀疏模型的準確性。
以Deep Compression為例,剪枝后的稀疏模型可以進一步進行量化,即使用更低比特的數據來表示權重。此外,結合霍夫曼編碼可以進一步減小模型的存儲空間。這些策略的綜合應用可以顯著降低模型的存儲需求,同時保持較高的準確性。
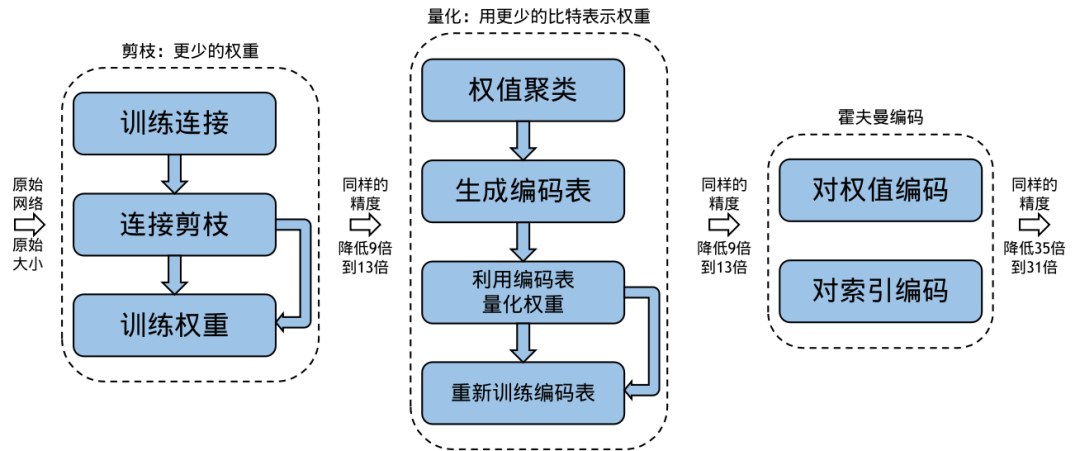
Deep Compression
除了直接去除冗余的神經元之外,還可以使用基于字典學習的方法來去除深度卷積神經網絡中無用的權值。這種方法通過學習一系列卷積核的基,將原始卷積核變換到系數域上,并且使其變得稀疏。例如,Bagherinezhad等人提出了一種方法,將原始卷積核分解成卷積核的基和稀疏系數的加權線性組合。通過這種方式,可以有效地去除網絡中不必要的權值,從而減少模型的存儲需求和計算復雜度。
3、知識蒸餾
教師-學生神經網絡學習算法,也稱為知識蒸餾。在實踐中,大型深度網絡通常能夠獲得出色的性能,因為過度參數化有助于提高模型的泛化能力。在知識蒸餾中,通常使用一個較大的神經網絡作為教師網絡,已經經過預訓練并具有較高的準確性。然后,將一個全新的、更深、更窄的神經網絡作為學生網絡,通過監督學習的方式將教師網絡的知識傳授給學生網絡。知識蒸餾的關鍵在于如何有效地將教師網絡的知識轉移到學生網絡中,從而提高學生網絡的性能和泛化能力。
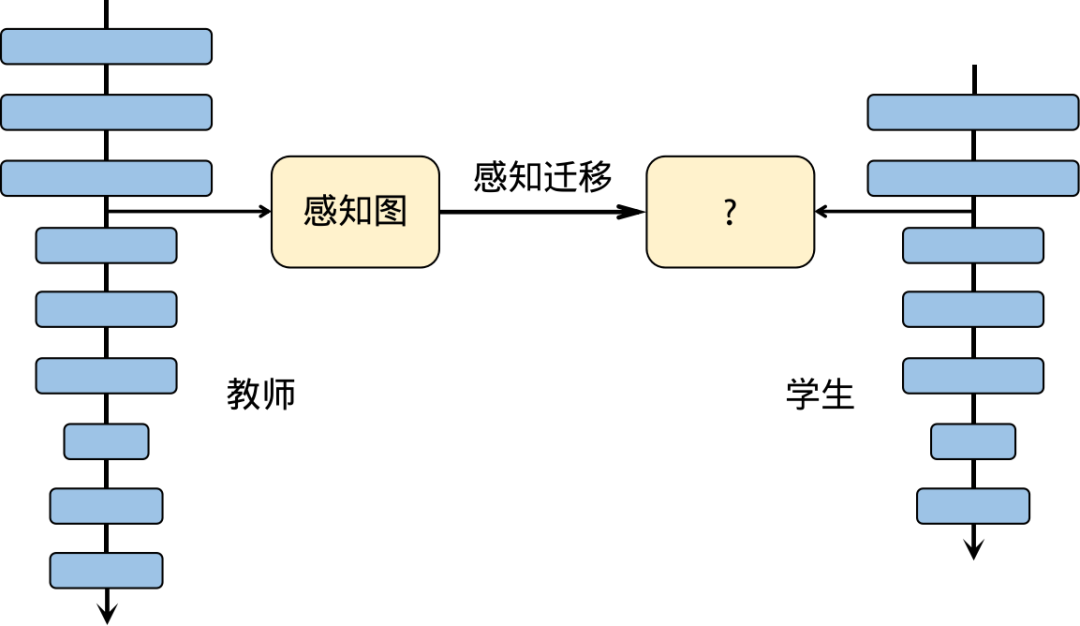
一種基于感知(attention)的教師神經網絡-學生神經網絡學習算法
知識蒸餾是一種有效的方法,可以幫助小網絡進行優化,并且可以與剪枝、量化等其他壓縮方法結合使用。通過知識蒸餾可以訓練出具有高精度和較小計算量的高效模型。這種綜合應用可以顯著減小模型的復雜性,同時保持較高的性能。
四、模型推理
將訓練好的模型部署到計算硬件上進行推理時,需要經歷幾個關鍵步驟:
前處理:將原始數據進行預處理,使其適合輸入到網絡中進行推理。
推理執行:將經過訓練和轉換的模型部署到設備上,通過輸入數據進行計算,得到輸出數據。
后處理:對模型的輸出結果進行進一步的處理,例如應用篩選閾值或其他后處理操作,以獲得最終的結果。
這些步驟是將訓練好的模型應用到實際場景中的關鍵環節,確保模型能夠正確地處理輸入數據并生成準確的輸出。
1、前處理與后處理
1)前處理
在機器學習中,數據預處理是一個關鍵的步驟,它的目的是將原始數據轉換為適合模型輸入的形式,并消除其中的噪聲和無關信息,以提高模型的性能和可靠性。
數據預處理通常包括以下幾個方面:
特征編碼:將原始數據轉換為機器學習模型可以處理的數字形式。這涉及到將不同類型的數據(如文本、圖像、音頻等)轉換為數值表示,例如使用獨熱編碼、序號編碼等方法。
數據歸一化:將數據進行標準化處理,使其具有相同的尺度和范圍,消除不同特征之間的量綱差異。常見的歸一化方法包括最小-最大縮放和Z-score標準化。
處理離群值:離群值是與其他數據點相比具有顯著不同的異常值,可能會對模型的性能產生負面影響。因此,可以通過檢測和處理離群值來提高模型的準確性和魯棒性。
通過數據預處理,我們可以提取和凸顯有價值的特征,同時去除無關信息和噪聲,為模型提供更好的輸入,從而改善模型的性能和泛化能力。
2)后處理
在模型推理完成后,通常需要對輸出數據進行后處理,以獲得更可靠和有用的結果。常見的數據后處理手段包括:
離散化連續數據:如果模型的輸出是連續值,但實際應用需要離散值,可以使用四舍五入、取閾值等方法將連續數據轉換為離散數據,以得到實際可用的結果。
數據可視化:通過將數據以圖形或表格的形式呈現,可以更直觀地理解數據之間的關系和趨勢,從而決定下一步的分析策略。
手動調整預測范圍:某些情況下,回歸模型可能無法準確預測極端值,而結果集中在中間范圍。在這種情況下,可以手動調整預測范圍,通過乘以一個系數來放大或縮小預測結果,以獲得更準確的預測結果。
這些后處理手段可以進一步優化模型的輸出結果,使其更符合實際應用需求,并提供更有用的信息供用戶決策和分析。
2、并行計算
為了提高推理性能,推理框架通常會使用多線程機制來利用多核處理器的能力。這種機制的主要思想是將輸入數據切分成多個小塊,并使用多個線程并行地執行算子計算。每個線程負責處理不同的數據塊,從而實現算子的并行計算,大大提高了計算性能。通過這種方式,可以充分利用多核處理器的計算能力,加速推理過程,提高系統的響應速度。
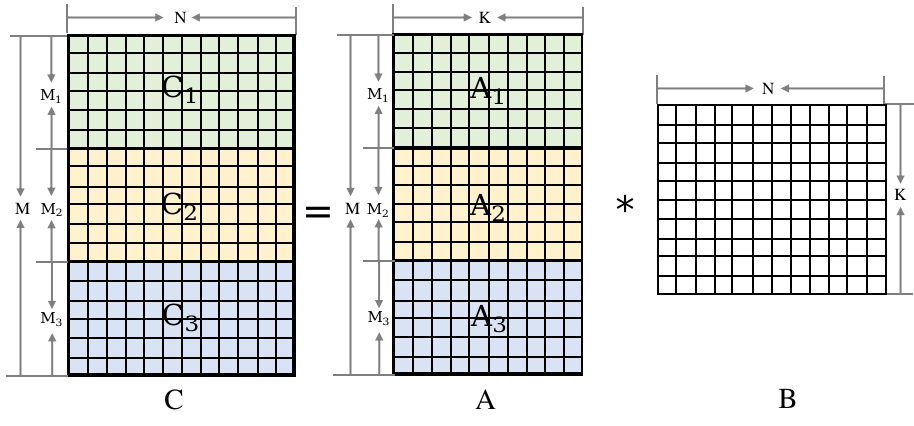
矩陣乘數據切分
為了實現矩陣乘的多線程并行計算,可以按照左矩陣的行進行切分,并使用線程池機制來方便地進行算子并行計算。在業界,有兩種常用的做法:
1)使用OpenMP編程接口,它提供了一套跨平臺的共享內存多線程并發編程API。通過使用OpenMP的"parallel for"接口,可以實現對for循環體的代碼進行多線程并行執行。
2)推理框架自己實現針對算子并行計算的線程池機制。相對于使用OpenMP接口,推理框架的線程池可以更加針對性地實現算子的并行計算,從而提供更高的性能和更輕量的實現。
3、算子優化
對于深度學習網絡而言,框架調度所占用的時間往往很少,性能的瓶頸通常出現在算子的執行過程中。為提高性能,可以從硬件指令和算法兩個角度對算子進行優化。
從硬件指令角度來看,可以利用特定的硬件指令集,例如SIMD(單指令多數據)指令集,來并行處理多個數據。這樣可以減少指令的執行次數,提高計算效率。另外,還可以使用硬件加速器,如GPU(圖形處理器)或TPU(張量處理器),來加速算子的執行。
從算法角度來看,可以通過優化算法的實現方式來提高性能。例如,可以使用更高效的矩陣乘法算法,減少乘法和加法的次數。還可以使用近似計算方法,如量化(將浮點數轉換為整數)或剪枝(刪除不重要的權重),來減少計算量和存儲需求。
1)硬件指令優化
絕大多數的設備上都有CPU,因此算子在CPU上的時間尤為重要。
匯編語言
高級編程語言通過編譯器將代碼轉換為機器指令碼序列,但其功能受限于編譯器能力。相比之下,匯編語言更接近機器語言,可以直接編寫特定的指令碼序列。匯編語言編寫的程序占用的存儲空間較少,執行速度更快,效率也更高。
在實際應用中,通常使用高級編程語言編寫大部分代碼,而對于性能要求較高的部分,可以使用匯編語言編寫,從而實現優勢互補。在深度學習中,卷積和矩陣乘等算子涉及大量計算,使用匯編語言編寫這些算子可以顯著提高模型訓練和推理的性能,通常能夠實現數十到數百倍的性能提升。
寄存器與NEON指令
在ARMv8系列的CPU上,有32個NEON寄存器,每個寄存器可以存放128位的數據。這意味著每個寄存器可以存儲4個float32數據、8個float16數據或16個int8數據。這些寄存器可以用于并行處理多個數據,從而提高計算效率。

ARMv8處理器NEON寄存器v0的結構
NEON指令集是針對ARMv8系列處理器的一種特殊指令集,允許同時對多個數據進行操作,從而提高數據存取和計算的速度。與傳統的單數據操作指令相比,NEON指令可以一次性處理多個數據。
例如,NEON的fmla指令可以同時對多個寄存器中的浮點數進行乘法和累加操作。指令的用法類似于"fmla v0.4s, v1.4s, v2.4s",其中v0、v1和v2分別表示NEON寄存器,".4s"表示每個寄存器中有4個float值。這條指令的作用是將v1和v2兩個寄存器中相應位置的float值相乘,并將結果累加到v0寄存器中的對應位置。
通過使用NEON指令集,開發者可以充分利用處理器的并行計算能力,以更高效的方式處理大量數據。這種并行計算的優勢可以在許多應用中得到體現,特別是在涉及大規模矩陣運算、圖像處理和信號處理等領域。

fmla指令計算功能
匯編語言優化
在編寫匯編語言程序時,可以采取一些優化策略來提高程序的性能,特別是通過提高緩存命中率來加速數據訪問。
一種常見的優化策略是循環展開,通過使用更多的寄存器來減少內存訪問,從而提高性能。另外,指令重排也是一種有效的優化方法,通過重新安排指令的執行順序,使得流水線能夠更充分地利用,減少延遲。
在使用NEON寄存器時,合理地分塊寄存器可以減少寄存器空閑時間,增加寄存器的復用率。此外,通過重排計算數據的存儲順序,可以提高緩存命中率,盡量保證讀寫指令訪問的內存是連續的。
最后,使用預取指令可以將即將使用的數據提前從主存加載到緩存中,以減少訪問延遲。這些優化策略的綜合應用可以顯著提高程序的性能,使其達到數十到數百倍的提升。
五、模型的安全保護
模型的安全保護可以分為靜態保護和動態保護兩個方面。靜態保護主要關注模型在傳輸和存儲時的安全性,目前常用的方法是對模型文件進行加密,以密文形式傳輸和存儲,并在內存中解密后進行推理。然而,這種方法存在內存中明文模型被竊取的風險。
動態保護則是在模型運行時進行保護,目前有三種常見的技術路線。一種是基于TEE(Trusted Execution Environment)的保護方案,通過可信硬件隔離出安全區域,在其中解密和運行模型。這種方案對推理時延影響較小,但需要特定的硬件支持,并且對大規模深度模型的保護有一定限制。另一種是基于密態計算的保護方案,利用密碼學方法保持模型在傳輸、存儲和運行過程中的密文狀態。
這種方案不依賴特定硬件,但會帶來較大的計算和通信開銷,并且無法保護模型的結構信息。第三種是基于混淆的保護方案,通過對模型的計算邏輯進行加擾,使得即使敵對方獲取到模型也無法理解其內部結構。相比前兩種方案,混淆方案的性能開銷較小,且精度損失較低,同時不依賴特定硬件,可以支持對大模型的保護。
模型混淆技術是一種能夠自動混淆明文AI模型計算邏輯的方法,使得攻擊者在傳輸和存儲過程中即使獲得了模型也無法理解其內部邏輯。同時,該技術還可以保證模型在運行時的機密性,并且不會影響模型原本的推理結果,只帶來較小的推理性能開銷。
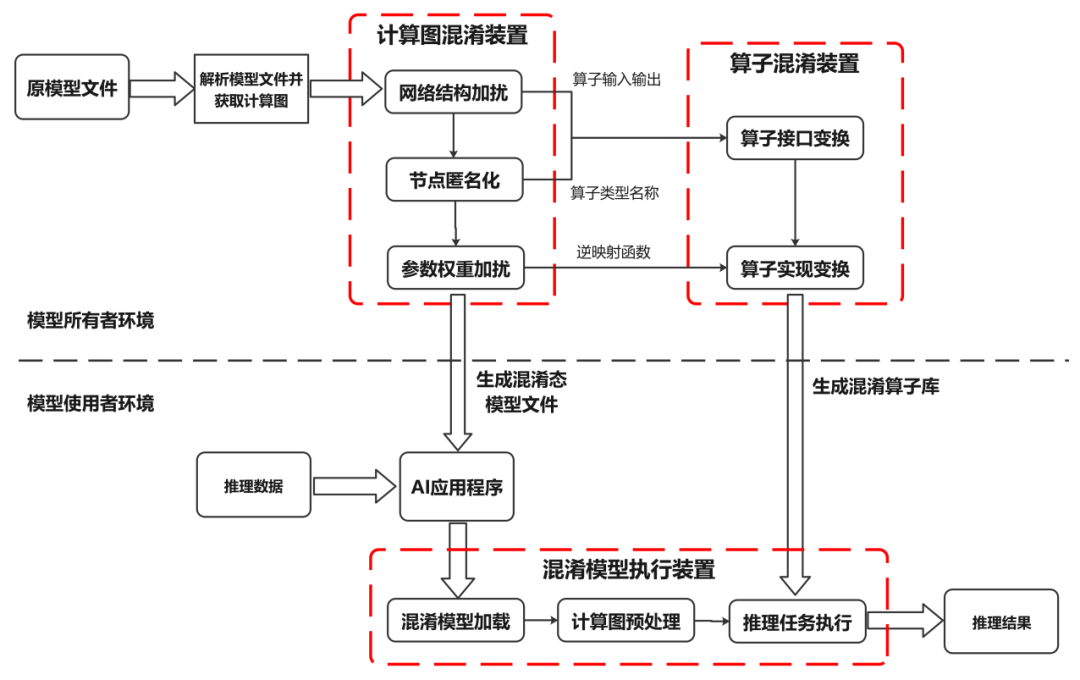
模型混淆實現步驟圖
結合上圖,詳細闡述模型混淆的執行步驟:
對于一個已經訓練好的模型,首先需要對其模型文件進行解析,并據此獲取模型計算邏輯的圖形表達形式(計算圖),以便進行后續操作。這個計算圖包括了節點標識符、節點運算符類型、節點參數權重以及網絡結構等信息。
在完成獲取計算圖之后,可以通過圖壓縮和圖擴展等技術,對計算圖中節點與節點之間的依賴關系進行混淆處理,以此隱藏模型真實的計算邏輯。圖壓縮主要是通過檢查整圖來匹配原始網絡中的關鍵子圖結構,并將這些子圖壓縮并替換為單個新的計算節點。在壓縮后的計算圖上,圖擴展通過在網絡結構中添加新的輸入/輸出邊,進一步隱藏節點間的真實依賴關系。這些新添加的輸入/輸出邊可以來源于/指向現有的節點,也可以來源于/指向本步驟新增的混淆節點。
接著,為了進一步達到模型混淆的效果,還可以對計算圖進行加擾處理。常用的加擾手段包括添加冗余的節點和邊、融合部分子圖等。這些操作都是為了達到模型混淆的目的。
然后,在完成上述步驟后,需要遍歷處理后的計算圖,篩選出需要保護的節點。對于這些節點,將節點標識符、節點運算符類型以及其他能夠描述節點計算邏輯的屬性替換為無語義信息的符號。對于節點標識符的匿名化處理,需要保證匿名化后的節點標識符仍然是唯一的,以便區分不同的節點。對于運算符類型的匿名化處理,為了避免大規模計算圖匿名化導致運算符類型的爆炸問題,可以將計算圖中同種運算符類型的節點劃分為若干不相交的集合,同一個集合中的節點的運算符類型替換為相同的匿名符號。這樣就能保證在節點匿名化后,模型仍然能夠被識別和執行。
之后,對于每個需要保護的權重,通過一個隨機噪聲和映射函數來對它們進行加擾處理。每個權重在加擾時都可以使用不同的隨機噪聲和映射函數,同時這些加擾操作需要保證不會影響到模型執行結果的正確性。
完成以上步驟后,將經過處理后的計算圖保存為模型文件以供后續使用。同時,對于每個需要保護的算子類型,需要對其進行形態變換并生成若干候選混淆算子。原本的算子與混淆算子之間是一對多的對應關系,而候選混淆算子的數量等于之前步驟中劃分的節點集合的數量。在此基礎上,根據之前步驟(2)(3)(4)得到的匿名化算子類型、算子輸入/輸出關系等信息,可以對相應的算子的接口進行變換。算子接口的變換方式包括但不限于輸入輸出變換、接口名稱變換。其中,輸入輸出變換主要通過修改原算子的輸入輸出數據實現,而接口名稱變換則是將原算子名稱替換為之前步驟中生成的匿名化算子名稱。這樣能保證在節點匿名化后,模型仍然能夠被識別和執行,同時算子的名稱也不會泄露其計算邏輯。
此外,還需要對算子的代碼實現進行變換。這種代碼實現的變換方式包括但不限于字符串加密、冗余代碼等軟件代碼混淆技術。這些混淆技術可以保證混淆算子與原算子實現語義相同的計算邏輯,但同時也會使得混淆后的算子難以閱讀和理解。需要注意的是,不同的算子可以采用不同組合的代碼混淆技術進行代碼變換。另外,在步驟(4)中提到的參數被加擾的算子,其混淆算子也需實現權重加擾的逆映射函數,以便在算子執行過程中動態消除噪聲擾動,并保證混淆后模型的計算結果與原模型一致。
之后,將生成的混淆算子保存為庫文件供后續使用。這些庫文件包含了所有需要的混淆算子和它們的代碼實現。
完成上述所有步驟后,將混淆態模型文件以及相應的混淆算子庫文件部署到目標設備上。這樣就可以準備執行模型推理任務了。
在執行推理任務前,首先需要根據模型結構解析混淆態模型文件以獲取模型計算邏輯的圖形表達(即混淆計算圖)。
然后需要對這個混淆計算圖進行初始化處理,生成執行任務序列。根據安全配置選項的要求,如果需要保護模型在運行時的安全,那么可以直接對這個混淆計算圖進行初始化處理;如果只需要保護模型在傳輸和存儲時的安全,那么可以先將內存中的混淆計算圖恢復為原計算圖,然后對原計算圖進行初始化處理生成執行任務序列。這個任務序列中的每個計算單元對應一個混淆算子或原算子的執行。這樣做可以進一步降低推理時的性能開銷。
最后,根據AI應用程序輸入的推理數據,遍歷執行任務序列中的每個計算單元并得到推理結果。如果當前計算單元對應的算子是混淆算子,那么就調用混淆算子庫;否則就調用原算子庫。這樣就可以完成整個推理任務。
GPU在生成式
AI領域的誤解
生成式AI激發了我們的想象力,在各領域從預測性維護、患者診斷到客戶支持等展現出了前所未有的潛力。這種潛力依賴于GPU提供的加速計算能力,使其能夠高效訓練復雜語言模型。然而,對GPU的過度簡化或盲目信仰可能導致預期之外的問題,延誤甚至失敗數據科學項目。下面是在構建AI項目時需要避免的五個關于GPU的誤解。
一、GPU正在提供最快的結果
在GPU之前,每個時間步驟大約有70%的時間被用于數據復制,以完成數據流程的各個階段。GPU可以通過實現大規模并行計算,顯著降低基礎設施成本,并為端到端數據科學工作流提供卓越性能。12個NVIDIA GPU可以提供相當于2000個現代CPU的深度學習性能。若向同一服務器添加8個額外的GPU,則可提供多達55000個額外的核心。盡管GPU加速了計算過程,但研究指出它們可能會花費一半的時間等待數據,這意味著最終需要等待結果。為充分運用GPU的計算能力,需要更強大的網絡與存儲支持。
二、帶寬為王,向帶寬致敬
雖然帶寬是優化GPU使用的關鍵指標,但并不能準確反映AI工作負載的所有特性。優化數據流程需要考慮更多,而不僅僅是傳輸大量數據到GPU,IOPs和元數據同樣重要。不同的數據流程步驟有不同的IO需求,可能導致傳統存儲無法滿足。
除了帶寬,還需要考慮IOPS、延遲和元數據操作等性能特性。某些步驟需要低延遲和隨機小IO,有些則需要大規模的流媒體帶寬,還有一些需要同時進行兩者的并發混合。多個數據流程同時運行,增加了同時處理不同IO配置文件的需求。
三、GPU驅動的AI工作負載在處理小文件時始終面臨挑戰
訓練大語言模型用于大多數生成式AI應用涉及大量小文件,如數百萬小圖片和每個IoT設備的日志等數據。ETL工作流程會規范數據并使用隨機梯度下降訓練模型,這導致大規模的元數據和隨機讀取問題,特別是在AI深度學習流程的第一部分中有許多小IO請求,許多存儲平臺無法有效處理。
四、存儲?GPU的重點在于計算能力
AI工作負載對性能、可用性和靈活性有特殊需求,傳統存儲平臺難以滿足。選擇適合AI工作負載的存儲解決方案對滿足業務需求有顯著影響。成功的AI項目在計算和存儲需求方面往往迅速增長,因此需要仔細考慮存儲選擇的影響。然而,大多數AI基礎設施的關注和投入集中在GPU和網絡上,存儲設備的預算所剩無幾。對于AI存儲來說,性能在大規模上同樣重要,不僅僅是滿足傳統的要求。
五、本地存儲才是GPU最快的存儲方式
隨著AI數據集不斷增大,數據加載時間成為工作負載性能瓶頸。從本地NVMe存儲中檢索數據可避免傳輸瓶頸和延遲,但服務器主機已無法滿足GPU速度增長需求。GPU受到慢速IO制約。
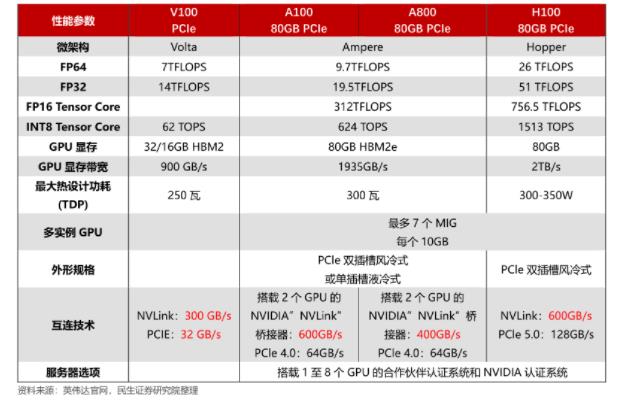
英偉達L40S GPU架構及A100、H100對比
在SIGGRAPH 2023上,NVIDIA推出全新的NVIDIA L40S GPU和搭載L40S的NVIDIA OVX服務器。這些產品主要針對生成式人工智能模型的訓練和推理,有望進一步提升生成式人工智能模型的訓練和推理場景的計算效率。
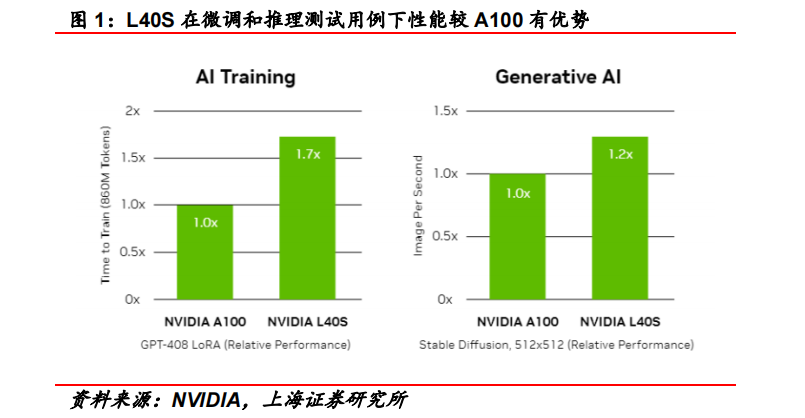
L40S基于Ada Lovelace架構,配備48GB的GDDR6顯存和846GB/s的帶寬。在第四代Tensor核心和FP8 Transformer引擎的支持下,可以提供超過1.45 PFLOPS的張量處理能力。根據NVIDIA給出的數據,在微調和推理場景的測試用例下,L40S的計算效率比A100有所提高。
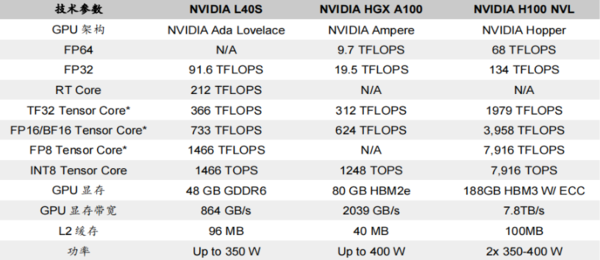
相較于A100 GPU,L40S在以下幾個方面存在差異:
一、顯存類型
L40S采用更為成熟的GDDR6顯存技術,與A100和H100使用的HBM顯存相比,雖然在顯存帶寬上有所降低,但技術成熟度高且市場供應充足。
二、算力表現
L40S在FP16算力(智能算力)方面較A100有所提高,而在FP32算力(通用算力)方面較A100有更為明顯的提升,使其更適應科學計算等場景的需求。
三、能耗表現
相較于A100,L40S在功率上有所降低,這有利于降低數據中心的相關能耗,提高能源效率。
四、性價比較
根據Super Micro的數據,L40S在性價比上相較于A100具有優勢,為希望部署高效且具有競爭力的生成式人工智能解決方案的用戶提供更多選擇。
L40S與A100、H100存在差異化設計
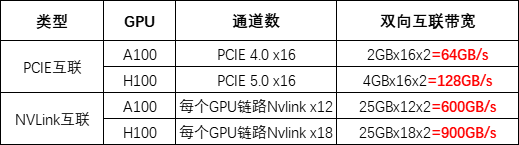
類似于A100,L40S通過16通道的PCIe Gen 4接口與CPU進行通信,最大雙向傳輸速率為64 GB/s。然而,與L40S不同的是,NVIDIA Grace Hopper采用NVLink-C2C技術將Hopper架構的GPU與Grace架構的CPU相連,實現CPU到GPU、GPU到GPU間總帶寬高達900 GB/s,比PCIe Gen 5快7倍。
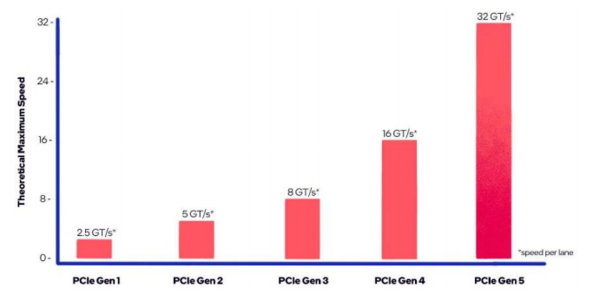
PCIe協議對L40S的通信寬帶有所限制
基于Ada Lovelace架構的L40S GPU,配備GDDR6顯存和846GB/s帶寬,并通過第四代Tensor核心和FP8 Transformer引擎提供超過1.45 PetaFLOPS的張量處理能力。針對計算密集型任務,L40S的18,176個CUDA核心可提供比A100高近5倍的單精度浮點性能,從而加速復雜計算和數據密集型分析。
此外,為支持專業視覺處理工作,如實時渲染、產品設計和3D內容創建,L40S還配備142個第三代RT核心,可提供212TFLOP的光線追蹤性能。功耗達到350瓦。對于生成式AI工作負載,L40S相較于A100可實現高達1.2倍的推理性能提升和高達1.7倍的訓練性能提升。在L40S GPU的加持下,英偉達還推出最多可搭載8張L40S的OVX服務器。英偉達方面宣布,對于擁有8.6億token的GPT3-40B模型,OVX服務器只需7個小時就能完成微調;對于Stable Diffusion XL模型,則可實現每分鐘80張的圖像生成。
藍海大腦大模型訓練平臺
藍海大腦大模型訓練平臺提供強大的算力支持,包括基于開放加速模組高速互聯的AI加速器。配置高速內存且支持全互聯拓撲,滿足大模型訓練中張量并行的通信需求。支持高性能I/O擴展,同時可以擴展至萬卡AI集群,滿足大模型流水線和數據并行的通信需求。強大的液冷系統熱插拔及智能電源管理技術,當BMC收到PSU故障或錯誤警告(如斷電、電涌,過熱),自動強制系統的CPU進入ULFM(超低頻模式,以實現最低功耗)。致力于通過“低碳節能”為客戶提供環保綠色的高性能計算解決方案。主要應用于深度學習、學術教育、生物醫藥、地球勘探、氣象海洋、超算中心、AI及大數據等領域。
一、為什么需要大模型?
1、模型效果更優
大模型在各場景上的效果均優于普通模型
2、創造能力更強
大模型能夠進行內容生成(AIGC),助力內容規模化生產
3、靈活定制場景
通過舉例子的方式,定制大模型海量的應用場景
4、標注數據更少
通過學習少量行業數據,大模型就能夠應對特定業務場景的需求
二、平臺特點
1、異構計算資源調度
一種基于通用服務器和專用硬件的綜合解決方案,用于調度和管理多種異構計算資源,包括CPU、GPU等。通過強大的虛擬化管理功能,能夠輕松部署底層計算資源,并高效運行各種模型。同時充分發揮不同異構資源的硬件加速能力,以加快模型的運行速度和生成速度。
2、穩定可靠的數據存儲
支持多存儲類型協議,包括塊、文件和對象存儲服務。將存儲資源池化實現模型和生成數據的自由流通,提高數據的利用率。同時采用多副本、多級故障域和故障自恢復等數據保護機制,確保模型和數據的安全穩定運行。
3、高性能分布式網絡
提供算力資源的網絡和存儲,并通過分布式網絡機制進行轉發,透傳物理網絡性能,顯著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用嚴格的權限管理機制,確保模型倉庫的安全性。在數據存儲方面,提供私有化部署和數據磁盤加密等措施,保證數據的安全可控性。同時,在模型分發和運行過程中,提供全面的賬號認證和日志審計功能,全方位保障模型和數據的安全性。
三、常用配置
1、處理器CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC? 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC? 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、顯卡GPU:
NVIDIA L40S GPU 48GB×8
NVIDIA NVLink-A100-SXM640GB
NVIDIA HGX A800 80GB×8
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW×8
審核編輯 黃宇
-
gpu
+關注
關注
28文章
4729瀏覽量
128890 -
AI
+關注
關注
87文章
30728瀏覽量
268888 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113 -
大模型
+關注
關注
2文章
2423瀏覽量
2643
發布評論請先 登錄
相關推薦
通往AGI之路:揭秘英偉達A100、A800、H800、V100在高性能計算與大模型訓練中的霸主地位

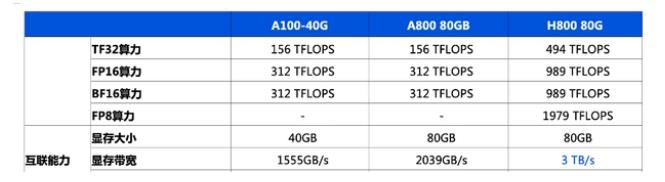
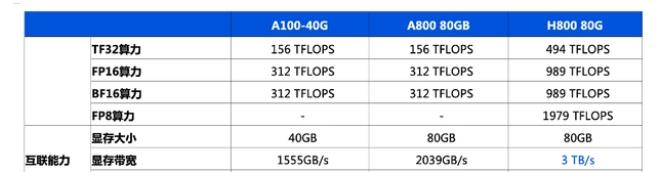
英偉達a100和h100哪個強?英偉達A100和H100的區別
英偉達a100和a800參數對比
英偉達A100和H100的區別
英偉達A100和A40的對比
英偉達A100的優勢分析
英偉達h800和a100參數對比
英偉達h800和a100的區別
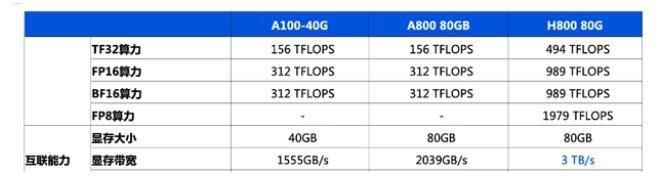
英偉達L40S GPU及A100、H100對比分析

深度學習模型部署與優化:策略與實踐;L40S與A100、H100的對比分析
瘋狂的H100:現代GPU體系結構淺析,從算力焦慮開始聊起

揭秘:英偉達H100最強替代者





 工商網監
工商網監
評論