 計算機視覺走向何方?參會ICCV的一些感想
計算機視覺走向何方?參會ICCV的一些感想
ICCV結束了。對我來說,這次的highlight就是第一天下午的"Quo vadis, computer vision“ workshop。“Quo vadis"是拉丁語,意思是“我們去向何方“。
四年前的CVPR,也有過一場類似的workshop(Computer Vision After 5 Years),今年這次workshop,主辦方也讓四年前也在的大佬們回顧了自己當年的predictions,看看誰是大預言家(spoiler: Jitendra Malik)。這場 workshop是我這幾年來參加的各種會議里最有意思的。可惜因為聽的太投入,并沒有很多的圖片記錄,現在我意識到似乎主辦方并不會上傳slides。所以這篇文章里我就簡單談談我自己的一些感想,而不是記錄這個會議。
Ignorance or faith on LLM?
今年最火的莫過于LLM。LLM的成功刺激了很多相關的vision research。然而許多的vision-language的研究其實都是基于一種對LLM的faith,而并沒有在深入思考這一切的合理性。David Forsyth問道:why would anyone believe that:
Visual knowledge is the same as linguistic knowledge
You can describe the world of an image properly in words
LLMs can do vision (anything)? if you ask nicely.
深入來看,這其實是一個關于vision和language區別的問題。但其實在我看來這些問題都很奇怪,可能因為我自己也覺得這些想法都很absurd。對我來說,更有意思的問題可能是:vision systems的什么knowledge是LLM做不了的,我們又該怎么做?在這里提一個idea,不知道未來有沒有機會去好好做:我們有沒有可能對稠密的vision空間進行一個approximate decomposition,分解成幾個子空間的積?(其中一個子空間就可以是離散的language空間)
Data over algorithms
這個主題是我非常認同的。四年前,我寫過一篇文章(Andre:思考無標注數據的可用極限),提出的也是我們要重視數據的研究,而不是算法的研究。今天依然適用。Alyosha Efros這次也再次強調了這個方向的本質性。
需要解釋的是,什么是"data research"。并不是說直接去做數據集才是data research,而是說從data層面開始思考模型的有效性,learning process,generalization ability,等等。從這個角度講,從data中學習知識 (self-supervised learning)是data research,研究如何克服data shift的影響(OOD, open-world)當然也是data research,這里不再贅述了。
Video與視覺大模型
這個主題是今年開始進入我的視野的。年初隨著stable diffusion, segment anything model的出現,我們不少人開始思考視覺大模型該是什么形態,我與組里不少同學聊天后的感受就是要做video。在五月份的ICLR時,我與Ben Poole還有3DGP的作者也交流了不少(順帶表示ICLR的參會體驗比ICCV好太多了),感受就是現在3D問題大概就是兩個思路:1. 希望隨著depth camera的引入,會有更多海量的3D data,直接訓出3D大模型;2. 希望video大模型直接繞開explicit 3D modeling的需求,建成vision大模型。這次ICCV另一個MMFM上,Vincent Sitzman也提出了一個類似的思路,但是他直接把video和3d modeling結合了起來(然而我并沒有特別跟上他講的東西,希望之后talk能有slides讓我再學習學習)。
講了上面這么多,我就是想說video很可能是我們走向視覺大模型的路。這次quo vadis workshop上,Jitendra的分享主要也是指出video的重要性。他指出:video有兩個用處:
Exteroception:建立對外部世界的認識。We build mental models of behavior (physical, social ...) and use them to interpret, predict, and control
Proprioception:建立對自己的認識。Helps produce an episodic memory situated in space and time, and guides action in a context-specific way。
他還給出了一個對video的思考框架,短video對應了movement/physical action,長video對應了goal/intention,而一個完整的action就是movement + goal。
當然,這些都是比較高屋建瓴的觀點了。但對于我們這些正在地上爬的人當然還是有好處的。(另外,Jitendra還認為token-based LLM可能不是最終的模型,因為它不能很好地capture 4D world,同時complexity也太高)。
Embodied AI?
最后,可能大家從上面一段論述中也已經能感覺出來了,許多大佬們正把embodied AI作為一個最終的目標。Antonio Torralba給了一個很有意思的talk,說我們是時候要返璞歸真,從focus on performance on benchmarks回到"the original goal"。對他來說,這個goal就是embodied AI。有意思的是, Antonio提出的設想是 small network, big sensing,他稱作embodied perception。他舉了個例子:人光光味蕾上的傳感器就比我們現在最先進的機器人身上全部的傳感器要多。然而就在第二天的BRAVO workshop上,Wayve的Jamie Shotton給出了完全相反的框架:lightweight sensors + big model。考慮到傳感器的價格,Jamie的想法可能現在這個時候是更合適的。不過也許最終Antonio的想法才最make sense。

Antonio的小模型,大感知
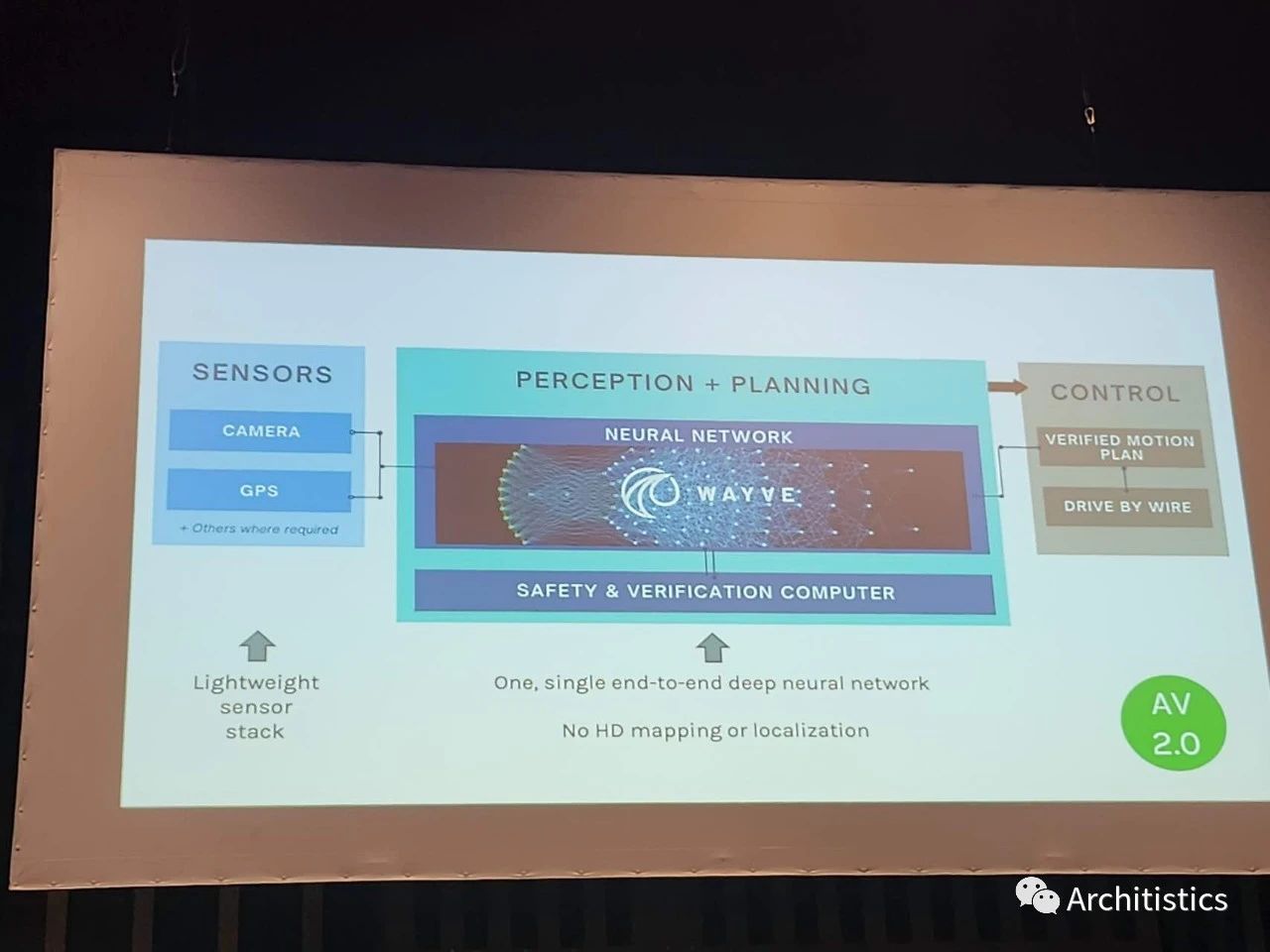
Jamie的大模型,小感知
閑話就說到這里了。這次ICCV還是有不少有意思的talks,希望之后能有公開的videos/slides。最后,祝愿各位同仁們都能繼續做自己感興趣的方向,做出令自己滿意的工作!
-
計算機視覺
+關注
關注
8文章
1699瀏覽量
46058 -
數據集
+關注
關注
4文章
1209瀏覽量
24768 -
LLM
+關注
關注
0文章
298瀏覽量
360
原文標題:計算機視覺走向何方?參會ICCV的一些感想
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺的五大技術
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺的十大算法






 工商網監
工商網監
評論