") 一篇文章讓你輕松看的智駕感知的進階算法策略
一篇文章讓你輕松看的智駕感知的進階算法策略
算法是決定自動駕駛車輛感知能力的核心要素。當前主流的自動駕駛模型框架分為感知、規(guī)劃決策和執(zhí)行三部分。從設計角度上講,以上三個層面的駕駛模型處理通常可以是基于傳統(tǒng)的規(guī)則的算法進行設計控制,為了適應更多的駕駛場景,泛化適配更多的場景處理能力,當前很多主機廠或者 tier1 也開始研究基于 AI 模型處理的自動駕駛算法策略。AI 模型的研究方向主要包括如下三個方面:
1、基于 Transformer+BEV 的算法在自動駕駛設計中的應用趨勢日益明顯;
2、城市領航輔助駕駛趨向于“去高精地圖”,替代的沿用輕地圖方案;
3、AI 模型需要大數(shù)據(jù)、大算力對模型進行有效的訓練和驅動。

基于 AI 模型控制的感知算法
從感知角度講,前期很多算法模型都是以傳統(tǒng)的計算機視覺為基礎且基于基礎神經(jīng)網(wǎng)絡模型(如 DNN、CNN、RNN 為代表的小模型)。
這三者模型的區(qū)別簡單的說就是 DNN 是通過對像素級別進行逐個對比,通過圖像特征進行識別。而 CNN 則是通過通過將整幅圖進行按照按興趣區(qū)域 ROI 進行特征分割后,分別對 ROI 進行局部像素對比識別。這樣看起來 CNN 實際是在 DNN 全鏈接層之前做了適當?shù)慕稻S(其方法是先通過卷積層、池化層)后再處理的,因此 CNN 將使得整個計算更加高效。但是,卷積層和池化層都是提前通過利用一定的卷積核對原始圖像進行遍歷后生成局部特征,這一過 程雖然能夠在短時間內獲取到一些有價值且感興趣的信息,但是也容易忽略局部與整體之間的關聯(lián)性。
比如進行前景和背景的提取過程中,如果多次池化,就可能導致所感興趣的車輛最后提取出來并不在我們所感興趣的車道內。亦或者把最邊緣的錐桶最后識別為在自車道前方,這些都不是我們所愿意看到的。
相比于 CNN 只是針對單幅圖像的神經(jīng)網(wǎng)絡處理來說,我們在自動駕駛中,實際上是需要 對連續(xù)視頻進行連續(xù)處理的。也就是說這類處理要從二維圖像擴展到三維視頻處理上,從這點上講,就需要從時序上做更深層次的延展。而 RNN 就是針對 CNN 在時間上的擴展,其處理過程是對時間連續(xù)輸出的狀態(tài)處理。
這里我們舉個非常典型的例子說明 RNN 相對于 CNN 的好處。在自動駕駛系統(tǒng)中,比較極端的場景是很多時候無法解決鬼探頭的問題,也就是對于跟蹤的目標如果在前一時刻還能看到,而當前時刻如果被大車遮擋,下一時刻的預測如果不能結合前一時刻的運動估計,那么 該目標可能碰撞的趨勢將無法被預測到,這也就是無法及時做出提前控制減速避撞的原因。RNN 在隱藏層引入了循環(huán)核提取對應的時間特征,從而將需要識別的圖像序列在時序上進行了有效關聯(lián)和預測。不難看出循環(huán)核是需要存儲歷史狀態(tài)的,且存儲的歷史狀態(tài)越多,其要求的存儲量更大。基于這一特性就使得 RNN 很難用于長時間長距離下的依賴關系處理。這也 就導致了 RNN 在并行計算能力上非常受限。
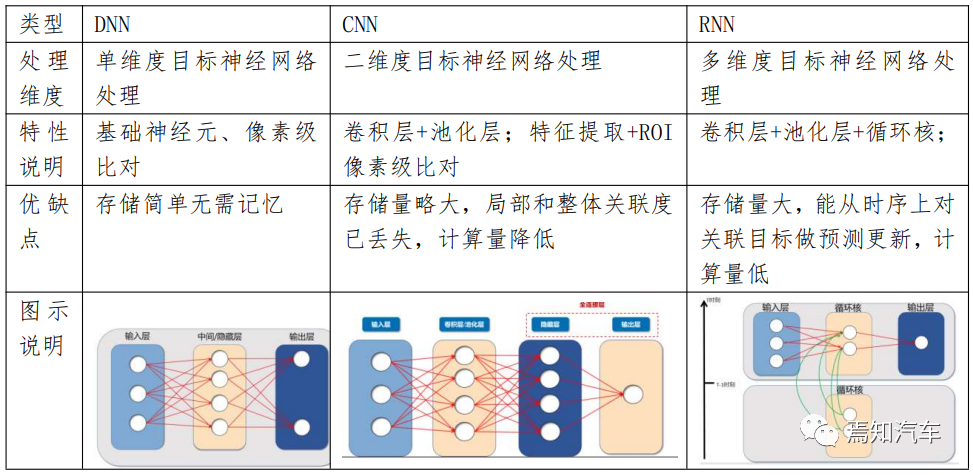
簡單的說,這類小模型神經(jīng)網(wǎng)絡是一種受生物神經(jīng)元啟發(fā)而產(chǎn)生的深度學習方法,由眾多的感知機構成。感知機類似于生物學中的神經(jīng)元,輸入信號經(jīng)過加權平均運算,若超過某一個閾值則向后傳遞信號,否則被抑制。不同的神經(jīng)網(wǎng)絡模型實際就是對感知機之間設定不同的邏輯關系。在自動駕駛感知模塊中輸入數(shù)據(jù)為圖像,而圖像通常是多維計算單元,因此,感知神經(jīng)元對其識別時需要設置大量輸入神經(jīng)元以及多個中間層,模型參數(shù)量大且難以訓練且消耗算力高,并可能帶來過擬合的問題。
其獨有的長序列處理能力和并行計算效率,使得 Transformer 擁有了更強的泛化能力。為什么這么說呢?比如針對自動駕駛系統(tǒng)識別來說,如果是針對前方車輛目標識別跟蹤而言, CNN 主要是通過先驗信息提前進行相似性對比,并通過將該模型輸入到學習模型中,實現(xiàn)該物體的識別任務。而 Transformer 則通過注意力機制,找到了該目標車周圍更多的基本元素及元素之間的多個維度關聯(lián)關系,這樣,及時模型中本身并未存儲該目標的基礎學習模型, 也可以通過周邊元素的泛化能力提升對該模型的識別能力。同時,Transformer 通過在時域范圍內尋找對應數(shù)據(jù)幀之間的關系,可以在通過存儲幀間的變化關系,從而通過幀間變換實現(xiàn)對各幀之間的約束。因此,可以說 Transformer 模型具有更高的并行計算效率并且可以學習到長時間距離的依賴關系。
多方面講述精細化感知融合方案
自動駕駛配備多個傳感器可以實現(xiàn)感知冗余和信息互補的作用。感知后端是融合部分,對于原始感知而言需要在后端進行前融合、特征融合及后融合。
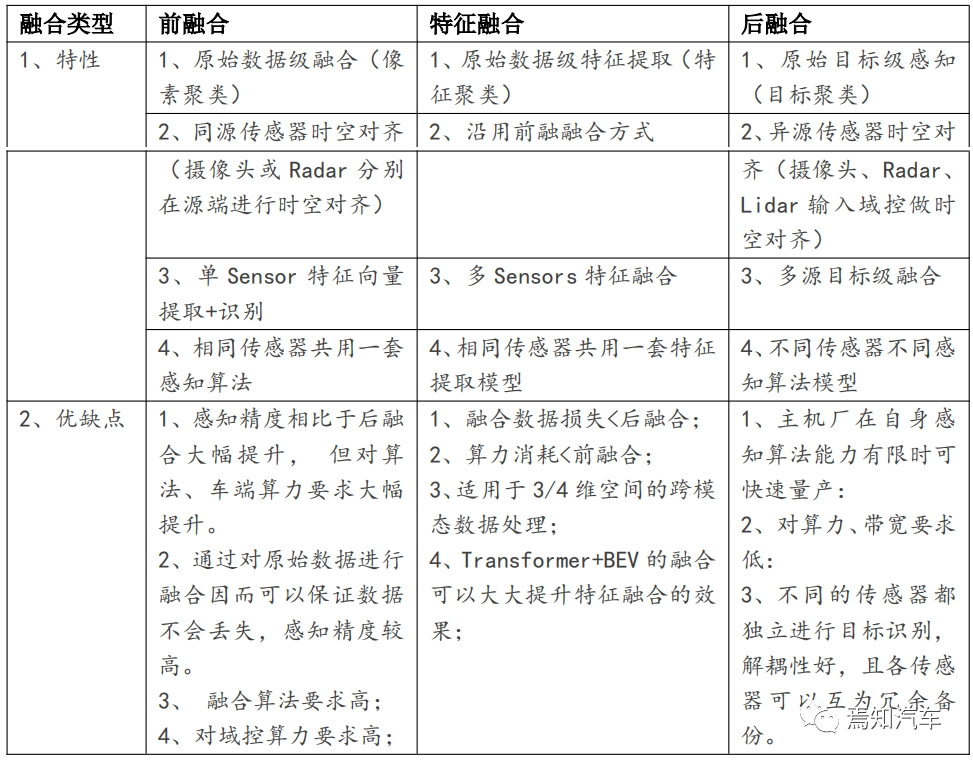
基于以上分析,前融合+特征級融合+后融合的分階段處理成為了整個感知處理的主流方案。如下圖所示表示了典型的融合處理架構框圖。
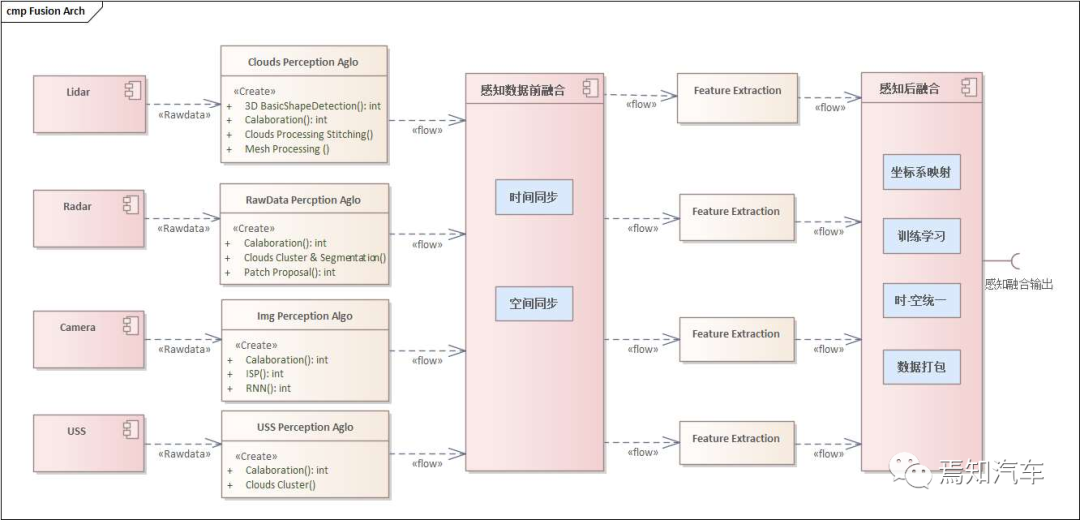
以上三種融合方式在設置融合策略上分別有不同的方式。對于整體的融合策略來說,一般是針對相同類型的傳感器而言,比如前視、側視攝像頭這類行車攝像頭的融合。針對這類同源攝像頭來說,融合策略針對不同的感知區(qū)域進行權重分配。比如如果識別本車道目標, 則一般對前視攝像頭分配更大的權重。如果是識別旁車道目標,則對側視攝像頭分配更大的權重。
此外,按照識別距離來看,也會區(qū)分行泊車攝像頭識別的融合權重。如果車速較低, 識別距離較近,則通常會將泊車攝像頭分配更多的權重。同時,如果考慮雷達回撥干擾,在低速近距離情況下,也會降低對 Radar 的分配權重。此外,考慮到不同目標的運動特性,對于橫向移動的目標,由于攝像頭識別橫向移動過程精準度遠大于 Radar,因此,在融合過程中,也會給攝像頭識別的橫向移動目標分別更大的權重。最后,如果將環(huán)境天氣等要素納入進來考慮,就業(yè)需要針對性對傳感器的特性采用不同的權重分配。比如,粉塵、雨天等場景, 攝像頭對運動目標的識別能力顯然遠不如 Radar、Lidar 等傳感源。此時,通常會對如上傳感器分配更多的權重實現(xiàn)對應的感知融合功能。
綜合起來,可以總結出如下不同維度的傳感器融合方案。

BEV 空間結合 Transformer 如何提升特征級融合效果呢?
BEV 一種對真實感知世界的表達方式,實際是基于規(guī)則的算法如逆透視投影變換 IPM 將攝像頭所采集到的 2D 圖像呈現(xiàn)在 3D 場景中。這里需要注意對智能駕駛比較典型的兩種識別場景:車道線和目標級識別,該兩種環(huán)境場景模型的識別實際會在 BEV 模型處理過程中產(chǎn)生不同的性能預期。
對于車道線來說,由于透視關系可能產(chǎn)生出近大遠小的情況,這樣在真實世界中平行的車道線就會呈現(xiàn)出不平行的情況。而 BEV 在 IPM 變換過程中,會提前通過兩個有帶有重疊區(qū)域的攝像頭信息求得對重疊區(qū)域下 2 維到 3 維的投影矩陣,這個投影矩陣將 3 維世界坐標系下的環(huán)境模型變換到 2 維圖像坐標系下可以完全消除 3 維物體在視角下的失真。因此,BEV 對真實場景下的車道線還原能力是遠優(yōu)于單目識別能力的。然而,BEV 在環(huán)境立體目標的識別能力卻可能產(chǎn)生不太理想的效果,比如在環(huán)境中的車輛、錐桶等障礙物在 BEV 視角下可能產(chǎn)生較大程度的扭曲。
原因如下:BEV 強依賴于對投影矩陣的精確計算,然而投影矩陣的計算需要提前標定各個相機在世界坐標系下的外參矩陣。不難看出,這樣的投影矩陣需要提前對地面做出強烈的假設需求。假設一旦標定了投影矩陣,地面就應該維持標定時刻的平整狀態(tài)。一旦地面發(fā)生凹凸不平導致車輛顛簸或高差變化,那么整個投影矩陣將會發(fā)生較大的變化,如果仍然利用之前的投影矩陣進行計算的話,就有可能造成較大的圖像失真。此外,由于投影矩陣實際是對有一定視差的兩個相機進行同一目標的識別來計算的。因此,這就在很大程度上會縮短對于環(huán)境目標的識別距離。
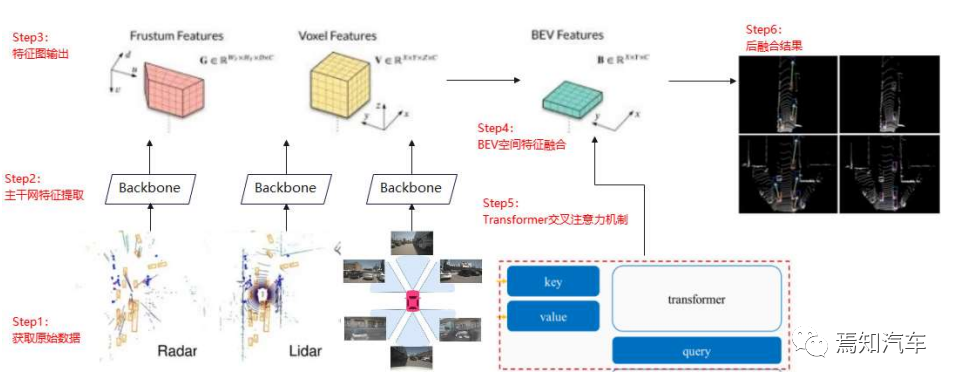
為了解決以上問題,通常采用在 BEV 空間中基于深度學習的方法做特征級融合。具體來說就是構建共享主干網(wǎng)絡分別對來自于不同感知源數(shù)據(jù)進行處理,處理過程需要很好的提取到數(shù)據(jù)特征值圖。隨后,這些特征圖需要輸入到 BEV 空間中進行特征融合,該融合的過程需要充分考慮不同的感知源數(shù)據(jù),比如視覺中的像素數(shù)據(jù)和雷達中的點云數(shù)據(jù)。
此時,對于固 定在某一時刻的場景圖像已經(jīng)有個初步的雛形了,但是對于智駕系統(tǒng)來說,環(huán)境肯定不是動 態(tài)不變的,各個目標會隨著時間的推移產(chǎn)生一定的變化。如果分割視頻圖像為前景和背景區(qū)域而言,我們對于大部分的背景區(qū)域,采用以上 BEV 處理網(wǎng)絡已經(jīng)能夠完全描繪出整體的場景感知。然而涉及前景區(qū)域,比如運動的車輛、行人等信息,則需要進行實時的規(guī)劃更新, 因此,還需要考慮在該融合過程中還需要加入時序處理網(wǎng)絡中的時間信息形成 4D 空間模型。加入時序處理的過程實際是融合 RNN 和 Transformer 的過程。其中,Transformer 的交叉注意力機制可以很好的提高 BEV 空間中的適配度。因為,交叉注意力中的 Query 和 Key/Value 來源不同,可以天然適配于不同域之間的數(shù)據(jù)轉換。
到底 Transformer 和 BEV 怎么結合呢
為了解決如上問題,智駕領域引入了 Transformer 的自注意力機制,該機制通過尋找各 個基本元素之間的多維度相關性,從而推理出各元素之間的相似規(guī)律。
自注意力機制實際上是針對性的關注環(huán)境目標圖像中需要關注的信息。相比于 RNN 的全信息存儲處理模型而言,Transformer 只全量處理和存儲首幀數(shù)據(jù),后續(xù)的處理過程只存儲關注的信息部分,也可以稱之為“前景部分”。這樣通過只存儲圖像幀之間的變化量數(shù)據(jù), 通過編碼該變化量數(shù)據(jù),從而大大減少了對圖像信息的全量存儲消耗。這樣在解碼端實際上 可以通過首幀數(shù)據(jù)和存儲的變化量信息,自恢復對應的全量數(shù)據(jù)也非常快了。
具體說來,在 Transformer 模型中,有三種注意力元素。注意力機制中最主要的三個 元素分別是 query、key 和 value。輸入元素需要經(jīng)過三次線性變換,分別得到查詢向量 Q (Query)、鍵向量 K(Key)和值向量 V(Value)。這三個向量均代表了同一個輸入元素, 但經(jīng)過不同的線性變換后,它們的表示和功能都有所不同。
比如識別到環(huán)境中的同一輛汽車,其關注點有不同幾個方向。其一是其目標類型,其二 是目標位置,其三是目標大小、其四是目標運動快慢等。因此,對于這一相同的目標實際上需要從多方向進行跟蹤和關注。在 Transformer 里面這叫做多頭注意力機制,也叫并行計算注意力方法。這樣可以針對性對每一個頭進行不同特征的跟蹤關注。如果關注目標位置信息, 引用以上三種向量 Q、K、V 則可以表示為:通過 V 表示實際車輛位置信息,而 K 則是檢索與該位置周邊相近的其他元素(該車周圍有多少其他目標注意要素),則 Q 是表示這些元素的具體信息(如周邊車輛要素類型、位置等) 。
最后,輸出向量可以表示為:
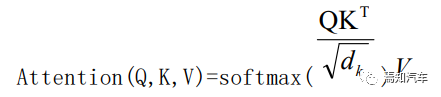
如上圖所示:Transformer 的交叉注意力機制整體的處理步驟如下:
階段 1:計算查詢向量與鍵向量的點積,得到注意力得分,點積結果越大表明相似度越 高,注意力得分越高;
階段 2:對注意力得分進行縮放和歸一化為概率分布;
階段 3:用歸一化后的注意力得分對值向量進行加權求和,得到輸出向量。
因此,將 Transformer 算法模型應用在需要大量計算量的 BEV 模型計算中就可以很好的生成不同的計算效果。
寫在最后
自動駕駛向更高等級邁進,城市領航輔助駕駛落地在即。城市領航輔助駕駛的落地需 求對自動駕駛模型的泛化能力提出更高的要求,同時考慮到成本、算法復雜度、實時性、高效性等處理因素的約束,優(yōu)秀的感知融合方案在應用 AI 大模型提高泛化能力+降低/控制車端硬件成本是自動駕駛算法演變的核心脈絡。這對于提升城市場景下復雜路況增強處理場景異質性,提升對自動駕駛遇到的 Corner case 的處理能力都是很大的幫助。
-
算法
+關注
關注
23文章
4625瀏覽量
93129 -
矩陣
+關注
關注
0文章
424瀏覽量
34598 -
自動駕駛
+關注
關注
784文章
13904瀏覽量
166736
原文標題:一篇文章讓你輕松看的智駕感知的進階算法策略
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
感知時間等比縮減的機會頻譜接入算法研究
行者手機可以讓你輕輕松松的享受著什么都一鍵自動
即插即用的自動駕駛LiDAR感知算法盒子 RS-Box
智能駕倉上怎么選擇一個合適的藍牙模塊?
一種選擇觸發(fā)協(xié)作頻譜感知算法
驍龍數(shù)字底盤讓你的座駕越來越聰明
北醒CTO疏達:算法和算力的進階將促進激光雷達、高階智能駕駛的發(fā)展

RK3568驅動指南|驅動基礎進階篇-進階5 自定義實現(xiàn)insmod命令實驗






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論