 如何選擇垃圾收集器
如何選擇垃圾收集器
1、垃圾收集器種類
事實上Java虛擬機規范對垃圾收集器應該如何實現,并沒有任何的規定,所以不同的廠商、不同版本的虛擬機所提供的垃圾收集器都會有所不同,并且一般都會提供參數供用戶根據自己的應用特點和要求組合出各個年代所使用的收集器。
下圖是基于 Sun HotSpot 虛擬機1.6版 Update 22的虛擬機種類:
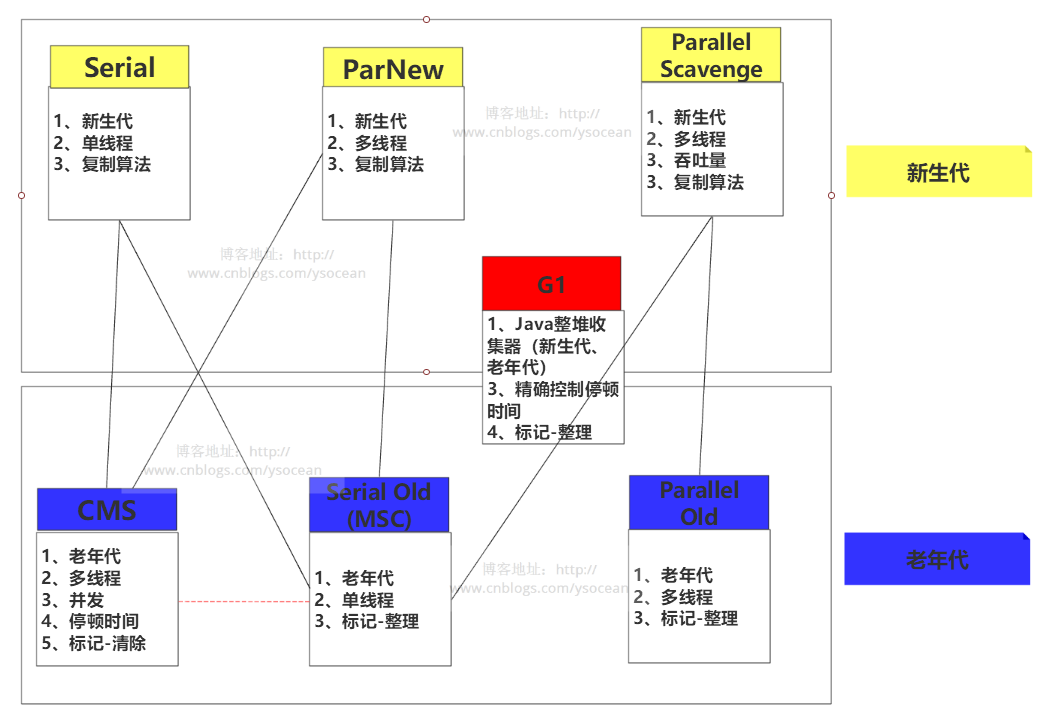
由上圖我們可以總結出幾個結論:
①、新生代垃圾收集器:Serial、ParNew、Parallel Scavenge;
老年代垃圾收集器:Serial Old(MSC)、Parallel Old、CMS;
整堆垃圾收集器:G1
②、垃圾收集器之間的連線表示可以搭配使用,有如下幾種組合:
Serial/Serial Old、Serial/CMS、ParNew/Serial Old、ParNew/CMS、Parallel Scavenge/Serial Old、Parallel Scavenge/Parallel Old、G1;
③、串行收集器Serial:Serial、Serial Old
并行收集器 Parallel:Parallel Scavenge、Parallel Old
并發收集器:CMS、G1
2、Serial收集器
這是一個最基本,歷史最悠久的垃圾收集器,是JDK1.3之前新生代唯一的垃圾收集器。
該收集器有如下特點:
①、作用于新生代
由上圖也可看出,這是一個新生代垃圾收集器,采用的垃圾回收算法是復制算法。
②、單線程
工作時只會使用一個CPU或者一條收集線程去完成工作。
③、進行垃圾收集時,必須暫停所有工作線程
也就是說使用Serial收集器進行垃圾回收時,別的工作線程都暫停,系統這時候會有卡頓現象產生。
④、適用場景
Serial 收集器由于沒有線程交互的開銷,對于限定單個CPU的環境,可以獲得最高的單線程收集效率。
一般在用戶的桌面場景中,分配給虛擬機管理的內存一般來說不會很大,收集幾十兆或一兩百兆的新生代,定頓時間可以控制在幾十毫秒,只要不是頻繁發生的,這點停頓是可以接受的。
所以 Serial 收集器對于運行在 Client 模式下的虛擬機是一種很好的選擇。
3、ParNew收集器
這個收集器其實就是Serial收集器的多線程版本。
也就是說其特點除了多線程,其余和Serial收集器一樣,事實上,這兩個收集器實現上也共用了很多代碼。
①、作用于新生代
一個新生代垃圾收集器,采用的垃圾回收算法是復制算法。
②、多線程
彌補了Serial收集器單線程的缺陷。
③、適用場景
由于其多線程的特性,是大多數運行在 Server 模式下的虛擬機首選新生代垃圾收集器。
另外需要說明的是,能夠與下面將要介紹的劃時代垃圾收集器CMS(Concurrent Mark Sweep)配合使用,也是一個重要原因。
4、Parallel Scavenge收集器
前面介紹的垃圾收集器關注點是盡可能縮小垃圾收集時的用戶線程停頓時間。而 Parallel Scanvenge 收集器是為了達到一個可控制的吞吐量。
吞吐量 = 運行用戶代碼的時間 / (運行用戶代碼的時間+垃圾收集時間)
可以用下面兩個參數進行精確控制:
-XX:MaxGCPauseMills 設置最大垃圾收集停頓時間
-XX:GCTimeRatio 設置吞吐量大小
①、作用于新生代
一個新生代垃圾收集器,采用的垃圾回收算法是復制算法。
②、多線程
并行的多線程垃圾收集器。
③、吞吐量
這個收集器可以精確控制吞吐量。
④、適用場景
設置垃圾收集停頓時間短適合需要與用戶快速交互的程序;
而設置高吞吐量可以最高效的利用CPU效率,盡快的完成程序的運算任務,主要適合在后臺運算而不需要太多交互的任務。
5、Serial Old收集器
Serial Old 收集器是 Serial 收集器的老年代版本,特點如下:
①、作用于老年代
②、單線程
③、使用標記-整理算法
④、進行垃圾收集時,必須暫停所有工作線程
6、Parallel Old收集器
Parallel Old 是 Parallel Scavenge收集器的老年代版本,使用多線程和“標記-整理”算法。
①、作用于老年代
②、多線程
③、使用標記-整理算法
除了具有以上幾個特點,比較關鍵的是能和新生代收集器 Parallel Scavenge 配置使用,獲得吞吐量最大化的效果。
7、CMS收集器
CMS,全稱為 Concurrent Mark Sweep ,顧名思義并發的,采用標記-清除算法。另外也將這個收集器稱為并發低延遲收集器(Concurrent Low Pause Collector)
這是一款跨時代的垃圾收集器,真正做到了垃圾收集線程與用戶線程(基本上)同時工作。和 Serial 收集器的 Stop The World(媽媽打掃房間的時候,你不能再將垃圾丟到地上) 相比,真正做到了媽媽一邊打掃房間,你一邊丟垃圾。
①、作用于老年代
②、多線程
③、使用標記-清除算法
整個算法過程分為如下 4 步:
一、初始標記(CMS initial mark):只是僅僅標記GC Root 能夠直接關聯的對象,速度很快,但是需要“Stop The World”
二、并發標記(CMS concurrent mark):進行GC Root Tracing的過程,簡單來說就是遍歷Initial Marking階段標記出來的存活對象,然后繼續遞歸標記這些對象可達的對象。
三、重新標記(CMS Remark):修正并發標記期間,因用戶程序繼續運行而導致標記產生變動的那一部分對象的標記記錄,需要“Stop The World”。這個時間一般比初始標記長,但是遠比并發標記時間短。
四、并發清除(CMS concurrent sweep):對上一步標記的對象進行清除操作。
由于整個過程最耗時的操作是第二(并發標記)、四步(并發清除),而這兩步垃圾收集器線程是可以和用戶線程一起工作的。所以整體來說,CMS垃圾收集和用戶線程是一起并發的執行的。
缺點:
①、對CPU資源敏感
因為在并發階段,會占用一部分CPU資源,從而導致應用程序變慢,總吞吐量會降低。
②、產生浮動垃圾
由于CMS并發清理階段用戶線程還在工作,這個時候產生的垃圾,CMS無法在本次收集中處理掉它們,只能留在下一次GC時再將其處理掉,這部分垃圾稱為“浮動垃圾”。
③、產生內存垃圾碎片
因為采用的算法是標記-清除,很明顯,會有空間碎片產生。
8、G1收集器
這是當前收集器技術發展的最前沿的成果。可以實現在基本不犧牲吞吐量的前提下完成低停頓的內存回收,首發于JDK8中,是JDK9默認的垃圾回收器。
這是因為它并不像前面介紹的所有垃圾收集器是區分新生代,老年代的,它作用于全區域。將整個Java堆劃分為多個大小固定的獨立區域(Regin),并且跟蹤這些區域的垃圾堆積面積,在后臺維護一個優先級列表,每次根據允許的收集時間,優先回收垃圾最多的區域,這樣保證了G1收集器在有限的時間內可以獲得最高的收集效率。
它與前面講的 CMS 垃圾收集器相比,有兩個顯著的改進:
①、采用 標記-整理 的回收算法
這樣不會產生空間碎片
②、可以精確的控制停頓時間
能讓使用者明確指定一個長度為M毫秒的時間片內,消耗在垃圾回收上的時間不超過 N 毫秒。
③、作用于整個Java堆
G1收集器不區分年輕代和老年代,是整堆垃圾收集器。
9、ZGC 收集器
這是JDK11發布的一款垃圾收集器,是一個可擴展的低延遲垃圾收集器,JDK17的默認垃圾收集器,能用就用,性能絕對可以。有如下特性:
①、暫停時間不超過10毫秒
②、暫停時間不會隨堆或實時設置大小而增加
③、處理堆范圍從幾百M到幾TB。
10、如何選擇垃圾收集器
除非應用程序有相當嚴格的暫停時間要求,否則就讓JVM自己選擇垃圾收集器。并且可以適當優先調整堆的大小來提高性能。如果還不滿足要求,則以下面四點作為指導:
- 如果應用程序內存小于100M,那么使用選項選擇串行收集器-XX:+UseSerialGC。
- 如果應用程序將在單核處理器上運行,并且沒有停頓時間的要求,選擇串行-XX:+UseSerialGC或者 JVM 自己選
- 如果允許停頓時間超過1秒,選擇并行或 JVM 自己選
- 如果響應時間比總吞吐量更重要,并且垃圾收集暫停必須保持短于大約1秒,則使用-XX:+UseConcMarkSweepGC或選擇并發收集器-XX:+UseG1GC。
當然,現在無腦選擇ZGC,絕對沒錯。
-
JAVA
+關注
關注
19文章
2966瀏覽量
104702 -
虛擬機
+關注
關注
1文章
914瀏覽量
28160 -
JDK
+關注
關注
0文章
81瀏覽量
16592 -
收集器
+關注
關注
0文章
30瀏覽量
3134
發布評論請先 登錄
相關推薦
BQ25504設計太陽能收集器,請問的輸出電壓VSTOR怎么設定。
簡易6LoWPAN網格數據收集器參考設計包括BOM及層圖
基于LTC3588EDD-1熱電能量收集器的應用電路
基于MCU和RF組件實現的能量收集器
Microgen公司的壓電-MEMS振動能量收集器支持線性技術SmartMesh IP無線傳感器網絡

LTC3108演示電路-Peltier供電的遙感器能量收集器(30 mV至3.3V)
護河神器-自動收集水面垃圾!
JVM的垃圾機制是如何工作的呢?
漫途智能網關助力必藍水面垃圾收集器成為智慧數字城市的環境守護者!
垃圾收集器的JVM參數配置





 工商網監
工商網監
評論