 Direct Inversion:三行代碼提升基于擴散的圖像編輯效果
Direct Inversion:三行代碼提升基于擴散的圖像編輯效果
導讀
本文介紹了由香港中文大學和粵港澳大灣區數字經濟院聯合提出的基于 Diffusion 的 Inversion 方法 Direct Inversion,可以在現有編輯算法上即插即用,無痛提點。
現有主流編輯算法大多為雙分支結構,一個分支主要負責編輯,另一個分支則負責重要信息保留,Direct Inversion 可以完成(1)對兩分支解耦(2)使兩分支分別發揮最大效能,因此可以大幅提升現有算法的編輯效果。
同時,為了更加公平公正的進行基于 text 的編輯效果對比,這篇文章提出了 PIE-Bench,一個包含 700 張圖片和 10 個編輯類別的“圖片-編輯指令-編輯區域”數據集,并提供一系列包含結構保留性、背景保留性、編輯結果與編輯指令一致性、編輯時間四個方面的評測指標。
數值結果和可視化結果共同展示了Direct Inversion的優越性。

主頁:https://idea-research.github.io/DirectInversion/
代碼:https://arxiv.org/abs/2310.01506
論文:https://github.com/cure-lab/DirectInversion
這篇論文是如何發現過往方法問題,并找到新解決方案的呢?
基于 Diffusion 的編輯在近兩年來一直是文生圖領域的研究重點,也有無數文章從各個角度(比如效果較好的在Stable Diffusion的Attention Map上特征融合)對其進行研究,作者在文章中進行了一個比較全面的相關方法review,并把這些方法從“重要信息保留”和“編輯信息添加”兩個方面分別進行了四分類,具體可以參見原文,此處不再贅述。
這里提到了一個編輯的重點,也就是“重要信息保留”和“編輯信息添加”。事實上,這兩個要點正是編輯所需要完成的兩個任務,比如把圖1的貓變成狗,那紅色的背景和貓的位置需要保留,這就是“重要信息保留”;同時編輯要完成“變成狗”的任務,這就是“編輯信息添加”。
為了完成這兩個任務,最為直覺,也是使用最多的方式就是:使用兩個分支來完成這兩件事,一個用來保留信息,一個用來添加信息。之前的編輯算法大多可以劃分出這兩個分支,但可能隱含在模型中或者沒有顯式割離,也正是在這篇文章中,作者將兩個概念劃分清楚并給出了過往方法的分類。
到現在為止,已經弄清楚了編輯的兩個分支及其各自作用,但編輯不僅僅只需要這兩個分支,還需要重要的一步,也就是Inversion。
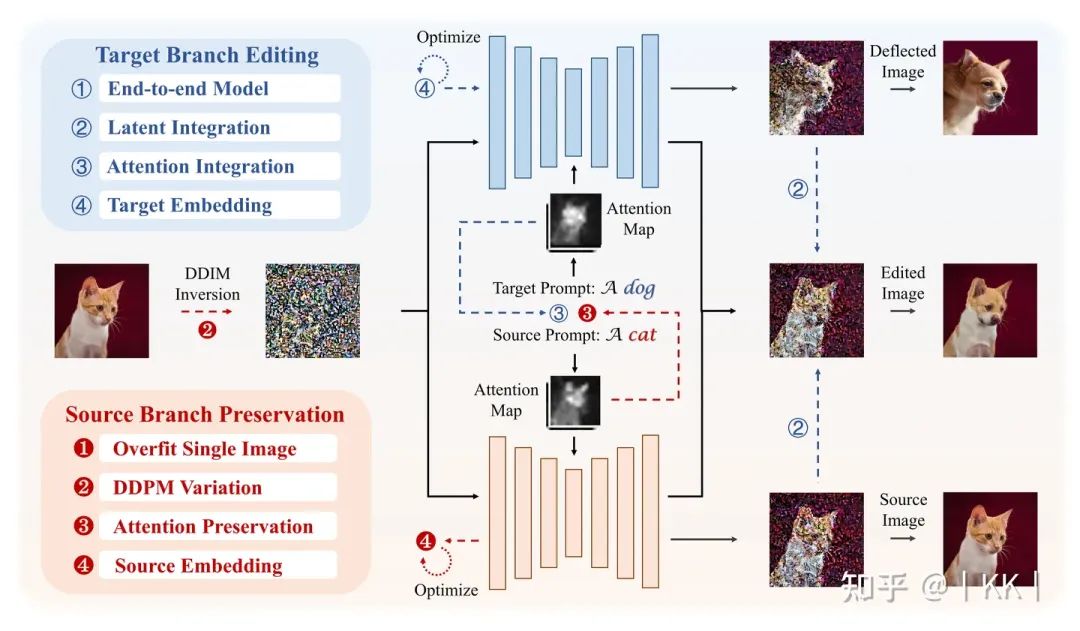
圖1 基于 Diffusion 的編輯算法總結
我們都知道,Diffusion是一個把噪聲映射到有用信息(比如圖片)的過程,但 Diffusion 到噪聲的過程是單向的,它并不可逆,不能直接像VAE一樣直接把有用信息再映射回到隱空間,即,可以根據一個噪聲得到圖片,但不能根據一張圖片得到“可以得到這張圖片的噪聲”,但這個噪聲又在編輯中非常重要,因為它是雙分支的起點。
所以大部分人就采用了一種近似的方法,即 DDIM Inversion,它能夠將圖片映射到噪聲,但從這個噪聲得到的新圖片就會稍微偏離原圖片一點(如圖DDIM Inversion上標注的distance),其實如果不給模型文本控制條件,偏離還不太嚴重,但當文本的控制加強時,偏離就會逐漸不可接受。
因此,一系列的 Inversion 方法被提出用來修正這一偏差,比如著名的基于優化的 Null-Text Inversion,而在無數方法進行嘗試和探索之后,大家似乎得到了一個 common sense:好的偏離修正必須要包含優化過程。所以這篇文章就更加深入的探索了一下基于優化的inversion(或者說修正)到底在做什么。
這些方法在優化什么?優化真的必要嗎?
基于優化的Inversion方法通常使用一個模型輸入變量(如Null Text)存儲剛剛提到的偏差,而這一偏差則作為優化過程中的loss,通過梯度下降來擬合變量。因此優化的過程本質上就是把一個高精度的偏差存儲在了一個低精度的變量中(該變量的數值精度相對 noise latent 更不敏感)。
但這種做法是存在問題的:(1)優化相當于在推導過程中訓練,非常消耗時間,比如Null-Text Inversion通常需要兩三分鐘編輯一張圖片;(2)優化存在誤差,因此不能完全消除“偏差”,如圖2 Null-Text Inversion/StyleDiffusion中畫出的,保留分支與原始inversion分支之間的偏差只是被縮小并沒有被消除,這就使得重要信息的保護沒有發揮到最大限度;(3)優化得到的變量其實在Diffusion模型訓練過程中并未出現過,因此相當于進行了強制賦值,會影響模型輸入和模型參數之間數據分布的協調。
回到上文提到的雙分支編輯,之前的方法訓練好優化的變量之后,就會將其同時送入到編輯分支和保留分支(其實不僅僅是基于優化的方法,非基于優化的方法也沒有將兩分支解耦),根據上面的分析,其實可以發現一個很簡單的改進策略:將可編輯分支和保留分支解耦,使兩個分支充分發揮各自效能。
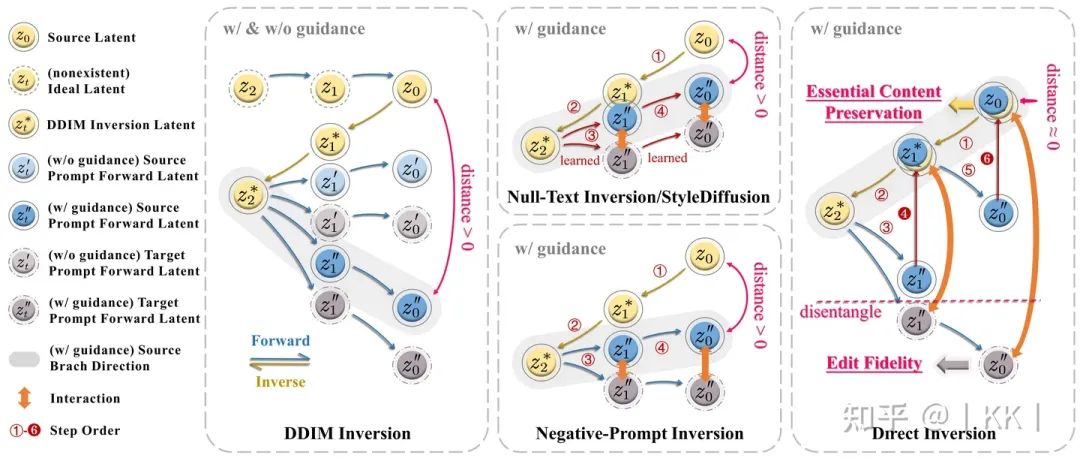
圖2 各類 Inversion 方法對比
Direct Inversion
這篇文章通過解耦編輯分支和保留分支,僅用三行代碼就能夠大幅提升現有編輯算法效果(如圖3中偽代碼),具體做法非常簡單,即:將保留分支加回到原始DDIM Inversion路徑,而保持編輯分支不被影響。

圖3 偽代碼
PIE-Bench
盡管基于 Diffusion 的編輯在近幾年引起了廣泛關注,但各類編輯方法的評估主要依賴于主觀且不確定性的可視化。因此這篇文章為了系統驗證所提出的Direct Inversion,并對比過往Inversion方法,以及彌補編輯領域的性能標準缺失,構建了一個基準數據集,名為PIE-Bench(Prompt-based Image Editing Benchmark)。
PIE-Bench包括700張圖像,涵蓋了10種不同的編輯類型。這些圖像均勻分布在自然和人工場景(例如繪畫作品)中,分為四個類別:動物、人物、室內和室外。PIE-Bench中的每張圖像都包括五個注釋:源圖像提示語句、目標圖像提示語句、編輯指令、主要編輯部分和編輯掩碼。值得注意的是,編輯掩碼注釋(即使用一個mask指示預期的編輯區域)在準確的指標計算中至關重要,因為期望編輯僅發生在指定的區域內。

圖4 PIE-Bench
實驗效果
數值結果
在各個編輯算法上對比不同Inversion和Direct Inversion 算法效果
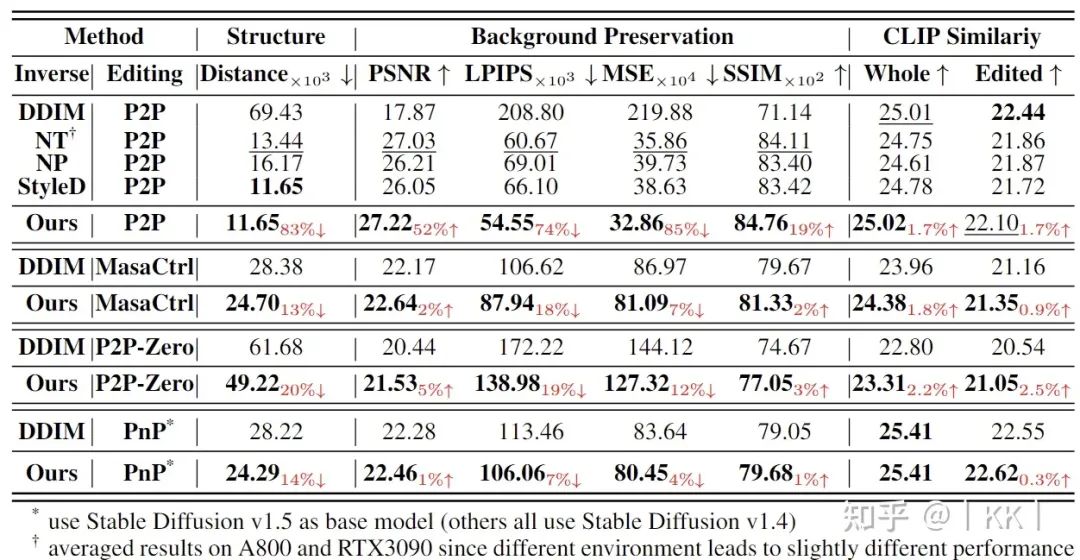
Direct Inversion 在多種編輯方法上對比其他 inversion 方法的效果。編輯方法:Prompt-to-Prompt (P2P), MasaCtrl, Pix2Pix-Zero (P2P-Zero), Plug-and-Play (PnP), Inversion方法:DDIM Inversion (DDIM), Null-Text Inversion (NT), Negative-Prompt Inversion (NP), StyleDiffusion (SD)
各類 Inversion 算法運行時間對比

運行時間對比
可視化對比

圖5 Direct Inversion 與四種基于 Diffusion 的編輯方法結合后在各種編輯類別(從上到下依次為:風格轉移、物體替換和顏色變更)上的性能提升,每組結果第一列為未加 Direct Inversion,第二列為添加 Direct Inversion

圖6 不同 inversion 和編輯技術的可視化結果
更多可視化和消融實驗結果可以參考原論文。
-
算法
+關注
關注
23文章
4622瀏覽量
93101 -
代碼
+關注
關注
30文章
4807瀏覽量
68801 -
數據集
+關注
關注
4文章
1208瀏覽量
24747
原文標題:簡單有效!Direct Inversion:三行代碼提升基于擴散的圖像編輯效果
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
請問前三行是什么意思?
請問這三行代碼是固定這樣寫的嗎?
三行搞定獨立按鍵
STM32之三行按鍵宏定義
什么是三行按鍵?有什么用
EditGAN圖像編輯框架將影響未來幾代GAN的發展
谷歌新作Dreamix:視頻擴散模型是通用視頻編輯器,效果驚艷!
AI圖像編輯技術DragGAN開源,拖動鼠標即可改變人物笑容
生成式 AI 研究通過引導式圖像結構控制為創作者賦能
伯克利AI實驗室開源圖像編輯模型InstructPix2Pix,簡化生成圖像編輯并提供一致結果
來看看他們用代碼寫的“三行詩”

Sweetviz: 讓你三行代碼實現探索性數據分析
放下你的PhotoShop!無限圖像編輯已開源!





 工商網監
工商網監
評論