

一、背景
圖處理在社交媒體、導(dǎo)航、推薦等領(lǐng)域應(yīng)用廣泛。很多場合下圖數(shù)據(jù)往往非常大以至于難以在單個機(jī)器的內(nèi)存中存儲。分布式圖處理選擇將圖數(shù)據(jù)存儲在分布式集群的內(nèi)存中;而與分布式圖處理不同,外部圖處理系統(tǒng)選擇在單臺機(jī)器上利用二級存儲來輔助存儲圖數(shù)據(jù),同時也能提供與分布式圖處理相近或更優(yōu)的性能。外部圖處理系統(tǒng)根據(jù)存儲方式可以進(jìn)一步分為半外部系統(tǒng)和全外部系統(tǒng)。前者將圖數(shù)據(jù)中的頂點(diǎn)數(shù)據(jù)存儲在內(nèi)存、邊數(shù)據(jù)存儲在SSD中;后者則將兩者都存儲在SSD中。本文提出的Blaze就屬于半外部系統(tǒng)。
二、問題
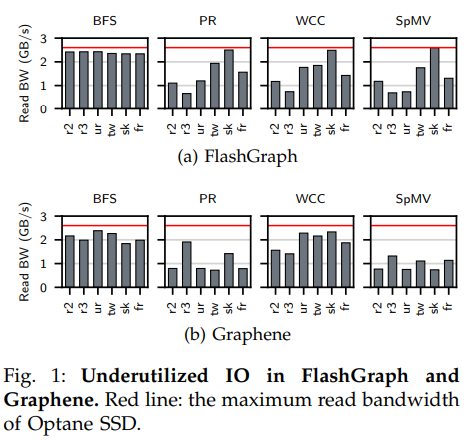
盡管現(xiàn)在新興的快速NVMe SSD提供了比過去的SSD更高的帶寬,但是現(xiàn)有的半外部圖處理系統(tǒng)不能充分利用這些快速SSD帶來的性能提升。本文通過實(shí)驗(yàn)(上圖)發(fā)現(xiàn)主要問題為IO利用率低下,可以看出在兩個代表性的半外部處理系統(tǒng)中除了BFS算法以外其他例程的執(zhí)行中IO帶寬(柱)都遠(yuǎn)未達(dá)到快速SSD的最大帶寬(紅線)。
本文作者認(rèn)為IO利用率低下的原因主要包含3個方面:計(jì)算傾斜、IO傾斜、IO快計(jì)算慢。
1. 計(jì)算傾斜
并行圖處理系統(tǒng)需要同步機(jī)制來避免并發(fā)更新算法相關(guān)的頂點(diǎn)數(shù)據(jù)時出現(xiàn)競爭。現(xiàn)有的半外部圖處理系統(tǒng)FlashGraph采用消息機(jī)制來解決同步問題,它為每個頂點(diǎn)分配了一個消息隊(duì)列,并按照頂點(diǎn)ID將每個頂點(diǎn)分派給一個計(jì)算線程。圖算法迭代性地執(zhí)行,在執(zhí)行的每一個迭代中頂點(diǎn)間通過消息通信;在迭代結(jié)束的時候系統(tǒng)處理這些消息,并根據(jù)處理的結(jié)果更新頂點(diǎn)數(shù)據(jù)。
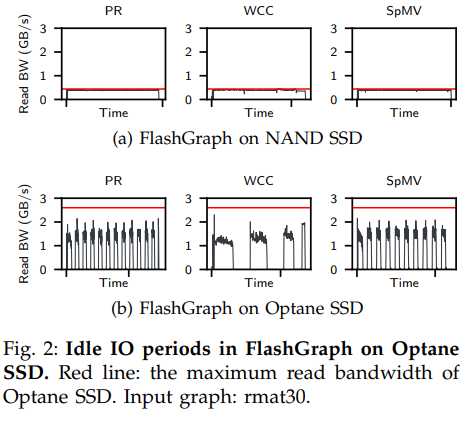
對于FlashGraph而言,由于圖結(jié)構(gòu)服從照冪律分布,一些線程需要比其他的處理更多消息,即計(jì)算傾斜。而(下一迭代的)IO必須得等待這種落伍線程完成處理才能開始。快速SSD在本輪迭代中的IO操作很可能比這個落伍線程完成的早,導(dǎo)致其空閑。
下圖的實(shí)驗(yàn)證明快速SSD(Optane SSD)相較于低速SSD(圖中NAND SSD)帶來的帶寬提升(紅線為磁盤最大讀取帶寬)確實(shí)造成了上述問題,造成了IO更多的空閑。
2. IO傾斜
為了更大的容量和帶寬,一些半外部圖處理系統(tǒng)會將邊數(shù)據(jù)分布在多塊磁盤中。而當(dāng)IO負(fù)載不均的時候顯然會造成部分磁盤比其他磁盤完成IO更慢而造成其他磁盤的空閑。
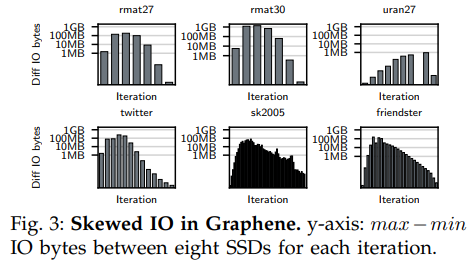
另一個半外部圖處理系統(tǒng)Graphene采用了一種2D圖分區(qū)技術(shù)以將邊均勻地分配到每個分區(qū),并將這些分區(qū)均勻分布到多個磁盤上。盡管其分布均勻,但是Graphene在執(zhí)行采用了邊數(shù)據(jù)選擇性調(diào)度的算法的時候仍然受IO傾斜的影響。
下圖中的實(shí)驗(yàn)證實(shí)了上述問題,圖中縱軸表示每輪迭代中各個磁盤間最大IO量減去最小IO量。盡管均勻分布的數(shù)據(jù)集可能有著低于1MB的傾斜,但對于其他冪律分布的圖則有著最大可達(dá)100MB的傾斜。
3. IO快計(jì)算慢
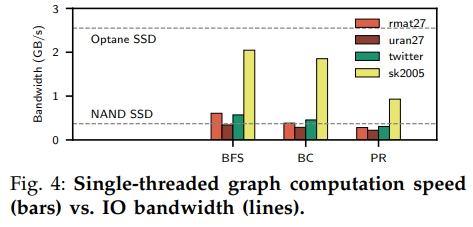
Graphene為每個SSD分配了一個計(jì)算核心和一個IO核心,對于慢速SSD而言這樣的設(shè)計(jì)可以最大化IO帶寬;然而對于快速SSD而言這樣的設(shè)計(jì)導(dǎo)致計(jì)算速度比IO更慢,IO填滿緩沖區(qū)的速度比計(jì)算使用的速度更快,導(dǎo)致緩沖區(qū)填滿后IO必須等待新的緩沖區(qū)。
下圖中的實(shí)驗(yàn)對比了計(jì)算的速度和存儲設(shè)備的讀取帶寬,可以看出計(jì)算的速度比快速SSD要慢得多,證明了上述問題。
三、設(shè)計(jì)
1. Online binning
Blaze采用名為Online binning的機(jī)制應(yīng)對計(jì)算傾斜的問題。Bin是存儲在內(nèi)存中的數(shù)據(jù)結(jié)構(gòu),存儲了多條bin record,而bin record則是包含頂點(diǎn)ID和一個數(shù)值。Blaze在算法執(zhí)行時根據(jù)目標(biāo)頂點(diǎn)ID和用戶定義的scatter函數(shù)的返回值創(chuàng)建bin record,然后對頂點(diǎn)ID取模計(jì)算出需要進(jìn)入的bin ID。填滿的bin被推入名為full_bins的并發(fā)隊(duì)列,由gather線程取出處理。每個gather線程獨(dú)自處理一個填滿的bin,以避免同步開銷。
2. 頁面交織
為了應(yīng)對IO傾斜的問題,Blaze采用了頁面交織的存儲方式來存儲邊數(shù)據(jù)。頁面交織基本類似RAID 0的方式。Blaze將CSR格式存儲的邊數(shù)據(jù)以4KB粒度交織分布到多個SSD上。
3. Blaze整體執(zhí)行流程
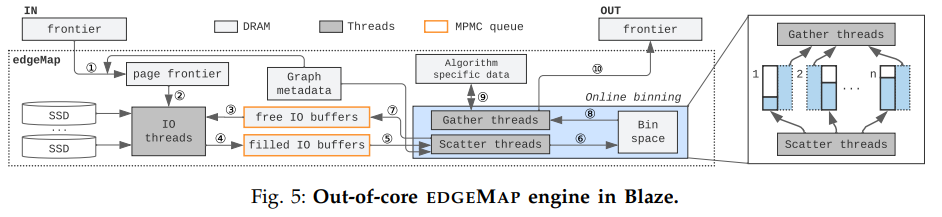
圖算法一般按迭代執(zhí)行,上圖提供了Blaze中每輪迭代中的處理流程。
作為輸入之一,算法程序會提供需要處理的頂點(diǎn)ID。為了接下來訪問各個頂點(diǎn)的邊列表,Blaze在第1步發(fā)動所有可用的線程將頂點(diǎn)ID集合轉(zhuǎn)換成其邊列表所在的磁盤頁面ID集合(即page frontier內(nèi)容)。轉(zhuǎn)換完成后根據(jù)其磁盤頁面ID從SSD中訪問數(shù)據(jù),寫入到空的IO buffer中,生成滿的IO buffer。Scatter線程取出填滿的IO buffer,計(jì)算并生成bin record裝入對應(yīng)的bin,并將用完的IO buffer還給空IO buffer池。Gather線程取出填滿的bin并處理,根據(jù)處理結(jié)果修改算法相關(guān)的頂點(diǎn)數(shù)據(jù)。最后返回下一個迭代所需要處理的頂點(diǎn)集合。
四、實(shí)驗(yàn)評估
1. 實(shí)驗(yàn)設(shè)置
實(shí)驗(yàn)測試平臺是一臺單處理器(Intel Xeon Gold 6230,20核心,禁用超線程),96GB內(nèi)存的機(jī)器,存儲配置了一塊960GB的快速SSD(Intel DC P4800X)。
對比的算法包含:BFS、PageRank、WCC、稀疏矩陣乘(SpMV)、BC。
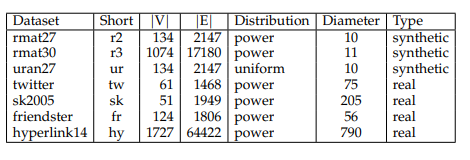
數(shù)據(jù)集如下表所示:
2. 系統(tǒng)對比
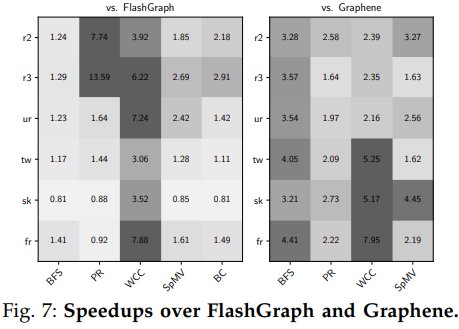
本文將Blaze與FlashGraph和Graphene分別作了對比計(jì)算了加速比,加速比如下圖所示(Graphene沒有實(shí)現(xiàn)BC算法所以沒做對比)。除了sk2005數(shù)據(jù)集中FlashGraph表現(xiàn)更優(yōu)以外總體都有一定提升。sk2005數(shù)據(jù)集上的處理有著更高的局部性,F(xiàn)lashGraph的LRU頁面緩存借此減少了存儲訪問,而Blaze并沒有針對頁面緩存做專門的優(yōu)化。
3. IO利用率
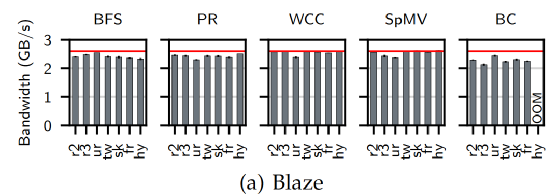
IO利用率的評估如下圖所示,可以看出Blaze的平均IO帶寬基本達(dá)到快速SSD的帶寬。
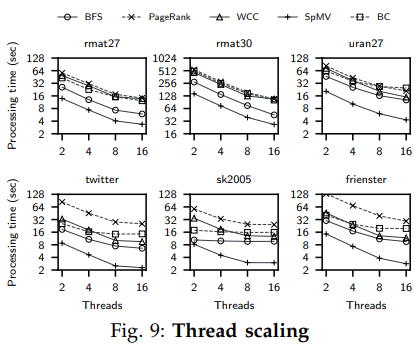
4. 可擴(kuò)展性
實(shí)驗(yàn)表明Blaze的性能大致隨著核心數(shù)的增加而線性增長,除了少部分負(fù)載下(如sk2005上的BFS)較快地飽和了IO帶寬而不能擴(kuò)張其性能。
五、總結(jié)
本文提出了一個新的半外部圖處理系統(tǒng)Blaze。Blaze采用了全新的scatter-gather技術(shù),online binning,解決了現(xiàn)有半外部圖處理系統(tǒng)應(yīng)用快速SSD后不能充分利用其高帶寬的問題。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
19819瀏覽量
233683 -
CSR
+關(guān)注
關(guān)注
3文章
118瀏覽量
70100 -
SSD
+關(guān)注
關(guān)注
21文章
2953瀏覽量
119162 -
BFS
+關(guān)注
關(guān)注
0文章
9瀏覽量
2243
原文標(biāo)題:Blaze:低延遲SSD上的快速圖處理
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
游戲黨的福音:支持ALLM自動低延遲模式的HDMI線推薦
延遲低至30ms+ LLSM流媒體傳輸模塊低延遲方案推薦

LLSM——基于RK3588的低延遲低帶寬流媒體傳輸模塊
XMOS直播聲卡——可支持實(shí)時音頻DSP處理的低延遲音頻方案
明遠(yuǎn)智睿SSD2351核心板在語音對講與HMI領(lǐng)域的創(chuàng)新應(yīng)用
可支持實(shí)時音頻DSP處理的低延遲直播聲卡方案

深度解析SSD2351核心板:硬核視頻處理+工業(yè)級可靠性設(shè)計(jì)
英偉達(dá)帶來Reflex 2低延遲技術(shù)
QLC SSD與TLC SSD哪個更強(qiáng)
EE-295:在SHARC處理器上實(shí)現(xiàn)延遲塊

什么是SSD硬盤 SSD硬盤的優(yōu)勢和劣勢
邊緣計(jì)算對網(wǎng)絡(luò)延遲的影響
交互式低延遲音頻解碼器

數(shù)字控制環(huán)路中測量單元的低延遲信號鏈





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論