") 生成式AI的I/O瓶頸,或許可以用光子IC來(lái)突破
生成式AI的I/O瓶頸,或許可以用光子IC來(lái)突破
電子發(fā)燒友網(wǎng)報(bào)道(文/周凱揚(yáng))從回答問(wèn)題對(duì)話到寫(xiě)文章,ChatGPT這類(lèi)應(yīng)用已經(jīng)幫我們展示了生成式AI帶來(lái)的第一波震撼,從OpenAI的路線也可以看出,他們已經(jīng)在努力把處理對(duì)象從單純的文字,轉(zhuǎn)換成圖片、音頻乃至視頻了。但這也意味著待處理的數(shù)據(jù)大小以數(shù)量級(jí)提升,畢竟再長(zhǎng)的文本和視頻文件大小比起來(lái)還是相去甚遠(yuǎn)。
I/O瓶頸
要想進(jìn)一步提升生成式AI的處理性能,我們就不得不看下背后為其提供動(dòng)力的基礎(chǔ)設(shè)備,也就是GPU、AI加速器、高帶寬內(nèi)存和光模塊。AI模型發(fā)展的早期,只需單個(gè)GPU甚至是CPU就能處理簡(jiǎn)單的AI模型,而如今這些先進(jìn)的AI模型,沒(méi)有大型機(jī)柜組成的服務(wù)器和成千上萬(wàn)個(gè)GPU,是很難運(yùn)行起來(lái)的。
比如特斯拉老版的自動(dòng)駕駛訓(xùn)練超算,就是由720個(gè)節(jié)點(diǎn)的8x英偉達(dá)A100 GPU構(gòu)成的,算力高達(dá)1.8 EFLOPS。小鵬于去年建成的智算中心扶搖算力規(guī)模高達(dá)600PFLOPS,預(yù)計(jì)也用到了上千塊GPU。
盡管部署大量GPU是擴(kuò)展算力的最直接途徑,但與此同時(shí)傳統(tǒng)的互聯(lián)方案還是創(chuàng)造了巨大的I/O瓶頸,嚴(yán)重影響了GPU的性能利用率,導(dǎo)致更多的時(shí)間花在了等待數(shù)據(jù)而不是處理數(shù)據(jù)上。
為此,常用的方案變成了添加更多的GPU來(lái)彌補(bǔ)性能和計(jì)算效率上的損失,可這樣的趨勢(shì)已經(jīng)在逐漸被淘汰,因?yàn)閺臏p少碳足跡的角度來(lái)看,全球范圍內(nèi)各個(gè)國(guó)家都在開(kāi)始考慮減少數(shù)據(jù)中心的能源損耗了。
光子IC
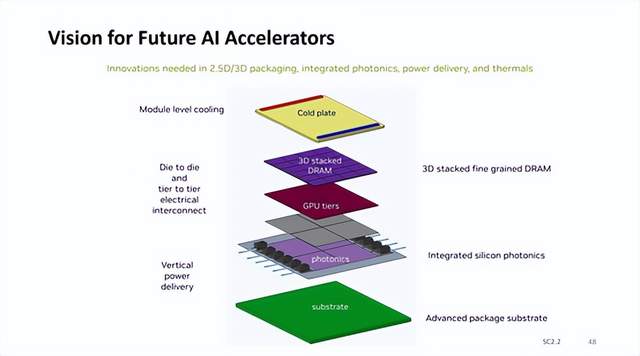
除此之外,另一解決方案就是利用光模塊來(lái)解決速度慢的節(jié)點(diǎn)間電氣連接,然而光模塊成本較高、密度較低,所以需要更高速、端到端又能降低成本互聯(lián)方案,即芯片到芯片之間的光學(xué)I/O。
利用更高帶寬的光學(xué)連接取代諸多并行和高速串行I/O通道,這一愿景促使了行業(yè)對(duì)近封裝光學(xué)和共封裝光學(xué)的追求。相較外部可插拔的管模塊,光子IC可將光學(xué)I/O集成到GPU封裝內(nèi)部,用來(lái)與其他的GPU節(jié)點(diǎn)進(jìn)行直接通信,進(jìn)一步提高了AI算力的擴(kuò)展效率,滿(mǎn)足了當(dāng)下持續(xù)增長(zhǎng)的AI需求。
近期,Sivers Semiconductors就在歐洲光通信展覽會(huì)上展出了他們打造的八波長(zhǎng)分布式反饋(DFB)激光器陣列,該陣列集成在了Ayar Labs的SuperNova多波長(zhǎng)光源中,支持GPU之間最高4TB/s的數(shù)據(jù)傳輸。根據(jù)Ayar Labs提供的數(shù)據(jù),新的光源配合它們的TeraPHY封裝內(nèi)光學(xué)I/O Chiplet,還提供了低上10倍的延遲和8倍的傳輸能效。
這樣的表現(xiàn)無(wú)疑極大地提升GPU的性能利用效率,解決當(dāng)下生成式AI在I/O性能瓶頸上的燃眉之急。盡管光子計(jì)算芯片目前尚不能替代傳統(tǒng)的電子半導(dǎo)體器件,但從解決帶寬和延遲需求上已經(jīng)有了長(zhǎng)足的進(jìn)步。
寫(xiě)在最后
面對(duì)生成式AI模型大小的指數(shù)級(jí)上漲,以及逐漸龐大起來(lái)的推理數(shù)據(jù)量,傳統(tǒng)的I/O性能必然會(huì)面臨淘汰,而光子IC為高性能的AI芯片提供了一條更快更高效的通路。不過(guò)仍然需要注意的是,光子IC與傳統(tǒng)IC還有設(shè)計(jì)與制造上的區(qū)別,比如需要特定的設(shè)計(jì)工具以及工藝等。因此要想發(fā)展光子IC跟上這一波趨勢(shì),就必須從EDA和晶圓代工廠開(kāi)始抓起。
-
IC
+關(guān)注
關(guān)注
36文章
5960瀏覽量
175769
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Google兩款先進(jìn)生成式AI模型登陸Vertex AI平臺(tái)
英偉達(dá)AI加速器新藍(lán)圖:集成硅光子I/O,3D垂直堆疊 DRAM 內(nèi)存
生成式AI工具作用
谷歌Vertex AI助力企業(yè)生成式AI應(yīng)用
使用OpenVINO GenAI API的輕量級(jí)生成式AI
生成式AI的基本原理和應(yīng)用領(lǐng)域
原來(lái)這才是【生成式AI】!!

請(qǐng)問(wèn)移動(dòng)端生成式AI如何在Arm CPU上運(yùn)行呢?


軟件可配置模擬 I/O 的設(shè)計(jì)理念

生成式 AI 進(jìn)入模型驅(qū)動(dòng)時(shí)代

生成式 AI 制作動(dòng)畫(huà):周期短、成本低!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論