

有網友問昇騰910和含光800性能對比;華為推出的昇騰910性能強大,而含光800則是阿里巴巴發布的含光800AI芯片。
2019年9月25日,阿里巴巴發布含光800AI芯片;含光800是高性能的AI推理芯片。該芯片推理性能達到78563 IPS,能效比500 IPS/W。
含光800AI芯片基于RISC-V和阿里自有算法,含光800芯片性能的突破得益于軟硬件的協同創新:硬件層面采用自研芯片架構,通過推理加速等技術有效解決芯片性能瓶頸問題;軟件層面集成了達摩院先進算法,針對CNN及視覺類算法深度優化計算、存儲密度,可實現大網絡模型在一顆NPU上完成計算。
含光800AI芯片相比傳統GPU算力,性價比提升100%。根據云棲大會的現場演示結果顯示,比如拍立淘商品庫每天新增10億商品圖片,使用傳統GPU算力識別需要1小時,使用含光800后可縮減至5分鐘。
據阿里介紹含光NPU采用TSMC 12nm工藝制程,可提供全球最高單芯片AI推理性能。 在HGAI模型的推理應用中,含光NPU每秒鐘可處理高達78000 IPS的圖片,是同類處理器的數十倍性能。
目前含光800目前已被應用到阿里巴巴旗下的的多個業務場景,比如圖像視頻分析、城市大腦、搜索優化等等。
2019年8月23日,華為發布AI芯片Ascend 910(昇騰910)。
據華為官方介紹,昇騰910AI處理器,基于自研華為達芬奇架構3D Cube技術,實現業界最佳AI性能與能效,架構靈活伸縮,支持云邊端全棧全場景應用。
除了基于達芬奇架構的AI核外,昇騰910還集成了多個CPU、DVPP和任務調度器(Task Scheduler),因而具有自我管理能力,可以充分發揮其高算力的優勢。
昇騰910集成了HCCS、PCIe 4.0和RoCE v2接口,為構建橫向擴展(Scale Out)和縱向擴展(Scale Up)系統提供了靈活高效的方法。HCCS是華為自研的高速互聯接口,片內RoCE可用于節點間直接互聯。最新的PCIe 4.0的吞吐量比上一代提升一倍。
昇騰910算力是國際頂尖AI芯片的2倍,相當50個當前最新最強的CPU;其訓練速度,也比當前最新最強的芯片提升了50%-100%。同時華為還發布了配套的新一代AI開源計算框架MindSpore。兩者搭配性能最大化利用芯片算力。
新一代的AI開源計算框架MindSpore創新編程范式,使得工程師更容易使用;該計算框架可滿足終端、邊緣計算、云全場景需求,能更好保護數據隱私;可開源,形成廣闊應用生態。
昇騰910半精度(FP16)算力達256 TFLOPS。(還有一個說法是昇騰910的半精度(FP16)算力達到320 TFLOPS);而整數精度(INT8)算力達到 640 TOPS,(還有一個說法是整數精度(INT8)算力達到512 Tera-OPS;小編認為一個數值可能是設計參數值,一個可能是極值)功耗 310W,采用 7nm 先進工藝。此外,昇騰 910 集成了 HCCS、PCIe 4.0 和 RoCE v2 接口,為構建橫向擴展 (Scale Out)和縱向擴展(Scale Up)系統提供了靈活高效的方法。
比如華為的Atlas 900 AI訓練集群,算力達到了256 PFLOPS。要實現這樣的算力,如果采用通用CPU需要6195個機柜,用GPU需要208個機柜,而NPU如昇騰只要128個機柜,這歸功于昇騰架構對深度學習業務的優化。而且最終,華為只用了16個機柜來實現。
此外,昇騰910為國產AI芯片助力,華為盤古大模型從算力(昇騰算力,昇騰的底層架構也是華為自創的)、芯片使能、AI框架(MindSpore AI計算框架)到AI平臺(AI開發生產線ModelArts)實現了全棧自主創新。
-
gpu
+關注
關注
28文章
4908瀏覽量
130625 -
NPU
+關注
關注
2文章
319瀏覽量
19485 -
AI芯片
+關注
關注
17文章
1968瀏覽量
35686 -
昇騰910
+關注
關注
0文章
14瀏覽量
6979 -
含光800
+關注
關注
0文章
3瀏覽量
1742
發布評論請先 登錄
華為昇騰人工智能伙伴峰會成功舉行
DeepSeek在昇騰上的模型部署的常見問題及解決方案
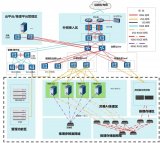

(原創)昇騰310B(8T/20T)算力主板定制方案
潤和軟件將持續深化“昇騰+DeepSeek”技術路線

昇騰推理服務器+DeepSeek大模型 技術培訓在圖為科技成功舉辦

迅龍軟件出席華為昇騰APN伙伴大會,獲昇騰APN鉆石伙伴授牌及兩項大獎

喜訊 英碼科技受邀出席華為昇騰APN伙伴大會,正式成為「昇騰鉆石部件伙伴」,喜獲多個重磅獎項!

谷東科技民航維修智能決策大模型榮獲華為昇騰技術認證
研華發布高性能工業邊緣 AI 算力方案 攜手昇騰引領邊緣 AI 革新

昇騰與昇思原生,助力智譜打造自主創新大模型體系!

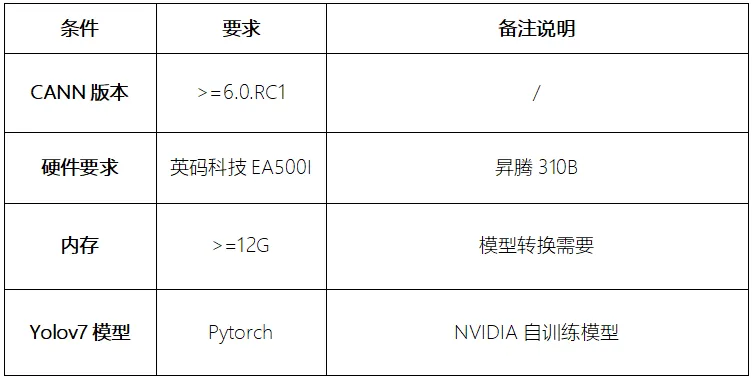
基于昇騰AI Yolov7模型遷移到昇騰平臺EA500I邊緣計算盒子的實操指南





 工商網監
工商網監

評論