 關于兩個Python開源識別工具的效果
關于兩個Python開源識別工具的效果
OCR 是光學字符識別(英語:Optical Character Recognition,OCR)是指對文本資料的圖像文件進行分析識別處理,獲取文字及版面信息的過程。
很早之前就有同學在公眾號后臺回復希望出一篇 OCR 相關的文章,今天嘗試了一下 cnocr 和 tesseract 兩個 Python 開源識別工具的效果,給大家分別講講兩個工具的使用方法和對比效果。
1.準備
開始之前,你要確保Python和pip已經成功安裝在電腦上,如果沒有,可以訪問這篇文章:超詳細Python安裝指南 進行安裝。
(可選1) 如果你用Python的目的是數據分析,可以直接安裝Anaconda:Python數據分析與挖掘好幫手—Anaconda,它內置了Python和pip.
(可選2) 此外,推薦大家用VSCode編輯器,它有許多的優點:Python 編程的最好搭檔—VSCode 詳細指南。
請選擇以下任一種方式輸入命令安裝依賴 :
- Windows 環境 打開 Cmd (開始-運行-CMD)。
- MacOS 環境 打開 Terminal (command+空格輸入Terminal)。
- 如果你用的是 VSCode編輯器 或 Pycharm,可以直接使用界面下方的Terminal.
(選擇一)安裝 cnocr:
pip install cnocr
看到 Successfully installed xxx 則說明安裝成功。
如果你只想對圖片中的中文進行識別,那么 cnocr 是一個不錯的選擇,你只需要安裝 cnocr 包即可。
但如果你想試試其他語言的OCR識別,Tesseract 是更好的選擇。
(選擇二)安裝 pytesseract:
首先,無論是Windows還是macOS,你都需要安裝 pytesseract:
pip install pytesseract
其次,還需要安裝Tesseract.
(macOS) Tesseract 在macOS下可以使用brew安裝:
brew install tesseract
非常方便,一條命令即可完成安裝。
(Windows )**** 安裝Tesseract
需要先下載安裝tesseract的程序,然后下載中文簡體字預訓練好的模型包(盡管本教程不會用tesseract,但還是給大家提供了)。
你可以在Python實用寶典公眾號后臺回復:**tesseract **打包下載。
下載完成后,將 tesseract-ocr-setup-4.00.00dev.exe 安裝到 Tesseract-OCR 指定目錄下,復制該目錄路徑增加到Path中:
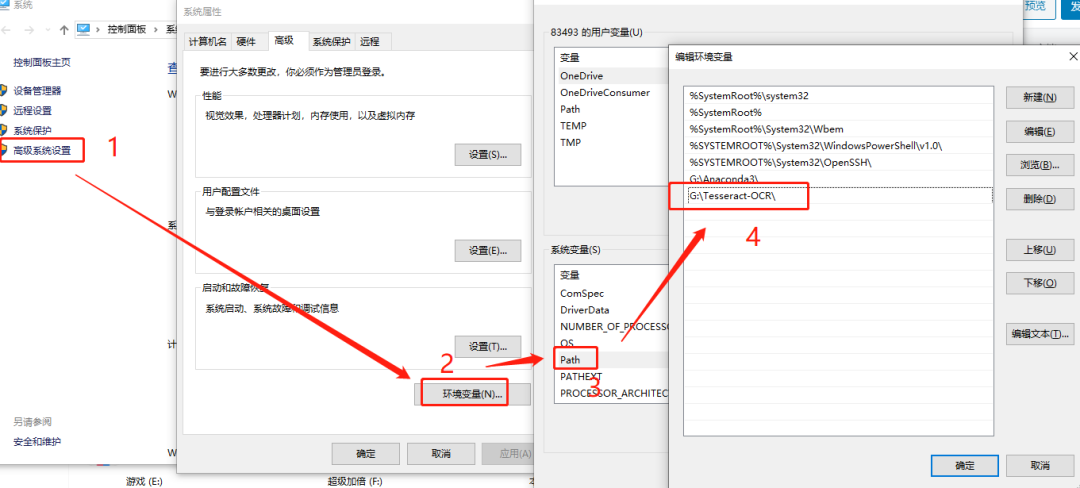
并將訓練好的模型文件 chi_sim.traineddata 放入該目錄中,這樣安裝就完成了。
2.cnocr 識別圖片的中文
cnocr 主要針對的是排版簡單的印刷體文字圖片,如截圖圖片,掃描件等。目前內置的文字檢測和分行模塊無法處理復雜的文字排版定位。
盡管它分別提供了單行識別函數和多行識別函數,但在本人實測下,單行識別函數的效果非常糟糕,或者說要求的條件十分苛刻,基本上連截圖的文字都識別不出來。
不過多行識別函數還不錯,使用該函數識別的代碼如下:
from cnocr import CnOcr
ocr = CnOcr()
res = ocr.ocr('test.png')
print("Predicted Chars:", res)
用于識別這個圖片里的文字:
效果如下:

如果不是很吹毛求疵,這樣的效果已經很不錯了。
3.pytesseract 識別圖片的英文
如果你的OCR目的不是中文而是英文,是需要別的模型的。這里給大家分享Tesseract-OCR,它是一款由HP實驗室開發,由Google維護的開源OCR引擎。
Tesseract-OCR 可擴展性很強,你可以基于它訓練屬于自己的OCR模型。
現在給大家看看它分類英文的效果,代碼如下:
import pytesseract
from PIL import Image
image = Image.open('test.png')
code = pytesseract.image_to_string(image, lang='eng')
print(code)
識別的圖片:
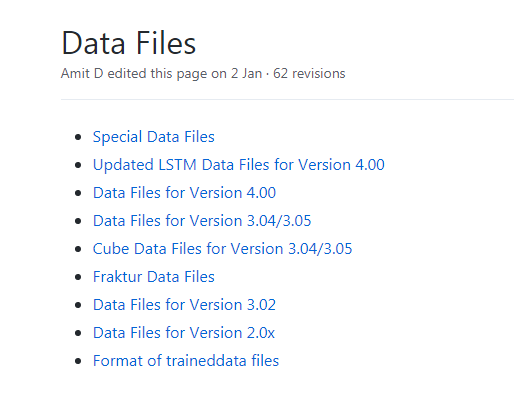
效果如下:
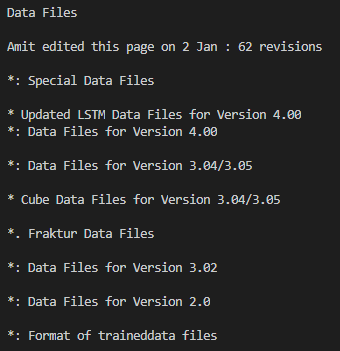
Tesseract 識別英文的效果真的很不錯,中文效果就比較一般了。
如果你想試試Tesseract識別中文,只需要將代碼中的eng改為chi_sim即可,不過相信我,效果不忍直視。
-
程序
+關注
關注
117文章
3786瀏覽量
81015 -
開源
+關注
關注
3文章
3333瀏覽量
42478 -
python
+關注
關注
56文章
4795瀏覽量
84646 -
OCR
+關注
關注
0文章
144瀏覽量
16353
發布評論請先 登錄
相關推薦








 工商網監
工商網監
評論