") 如何本地部署大模型
如何本地部署大模型
近期,openEuler A-Tune SIG在openEuler 23.09版本引入llama.cpp&chatglm-cpp兩款應(yīng)用,以支持用戶在本地部署和使用免費的開源大語言模型,無需聯(lián)網(wǎng)也能使用!
大語言模型(Large Language Model, LLM)是一種人工智能模型,旨在理解和生成人類語言。它們在大量的文本數(shù)據(jù)上進行訓練,可以執(zhí)行廣泛的任務(wù),包括文本總結(jié)、翻譯、情感分析等等。openEuler通過集成llama.cpp&chatglm-cpp兩款應(yīng)用,降低了用戶使用大模型的門檻,為Build openEuler with AI, for AI, by AI打下堅實基礎(chǔ)。
openEuler技術(shù)委員會主席胡欣慰在OSSUMMIT 2023中的演講
應(yīng)用簡介
1. llama.cpp是基于C/C++實現(xiàn)的英文大模型接口,支持LLaMa/LLaMa2/Vicuna等開源模型的部署;
2. chatglm-cpp是基于C/C++實現(xiàn)的中文大模型接口,支持ChatGlm-6B/ChatGlm2-6B/Baichuan-13B等開源模型的部署。
應(yīng)用特性
這兩款應(yīng)用具有以下特性:
1. 基于ggml的C/C++實現(xiàn);
2. 通過int4/int8等多種量化方式,以及優(yōu)化KV緩存和并行計算等手段實現(xiàn)高效的CPU推理;
3. 無需 GPU,可只用 CPU 運行。
使用指南
用戶可參照下方的使用指南,在openEuler 23.09版本上進行大模型嘗鮮體驗。
llama.cpp使用指南如下圖所示:
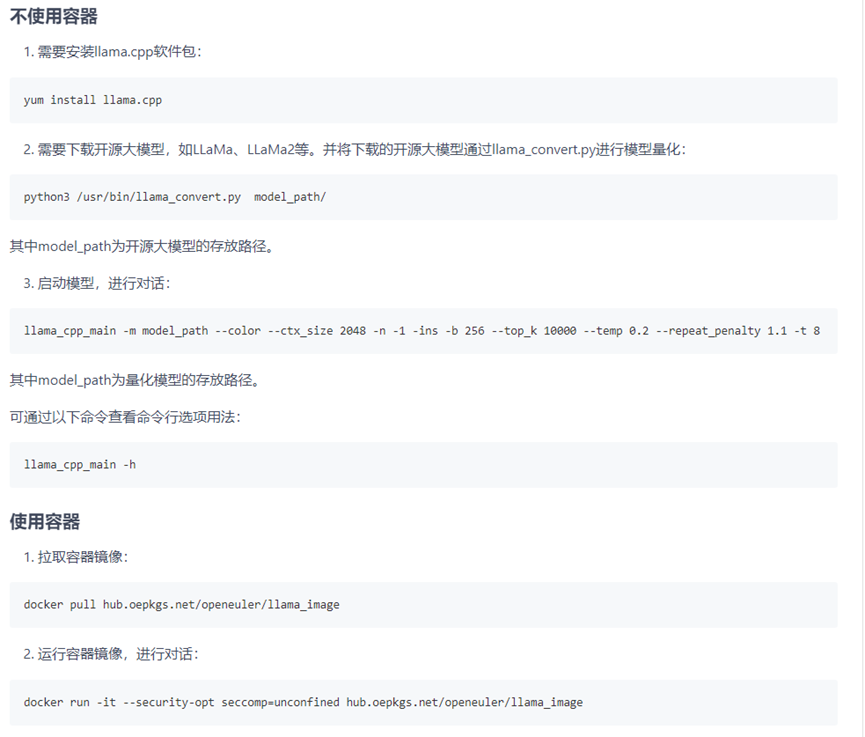
llama.cpp使用指南
正常啟動界面如下圖所示:
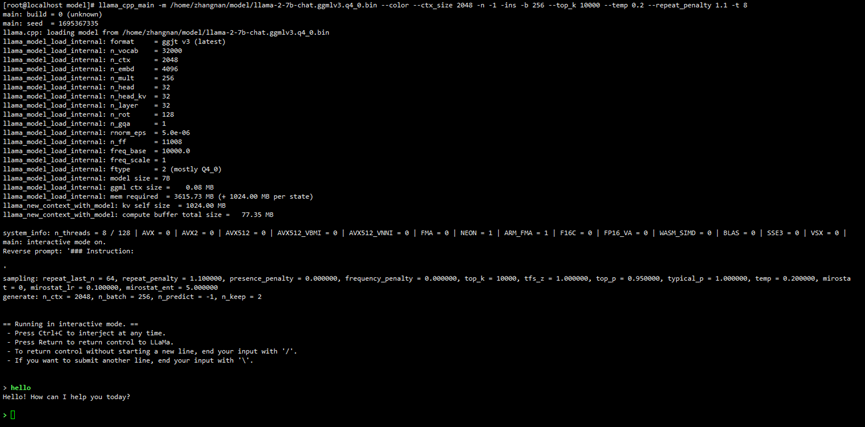
LLaMa啟動界面
2. chatlm-cpp使用指南如下圖所示:

chatlm-cpp使用指南
正常啟動界面如下圖所示:
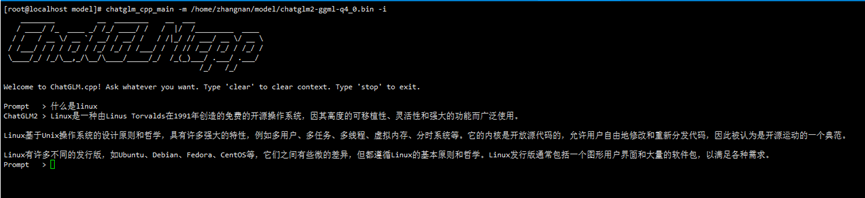
ChatGLM啟動界面
規(guī)格說明
這兩款應(yīng)用都可以支持在CPU級別的機器上進行大模型的部署和推理,但是模型推理速度對硬件仍有一定的要求,硬件配置過低可能會導致推理速度過慢,降低使用效率。
以下是模型推理速度的測試數(shù)據(jù)表格,可作為不同機器配置下推理速度的參考。
表格中Q4_0,Q4_1,Q5_0,Q5_1代表模型的量化精度;ms/token代表模型的推理速度,含義為每個token推理耗費的毫秒數(shù),該值越小推理速度越快;
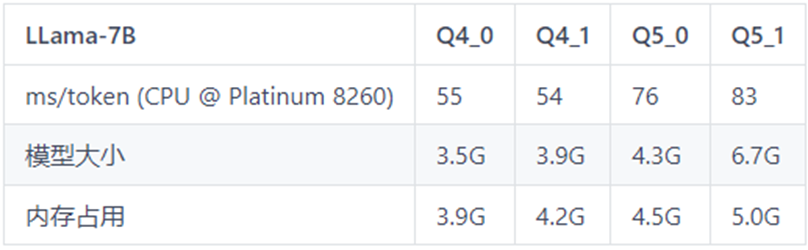
表1 LLaMa-7B測試表格
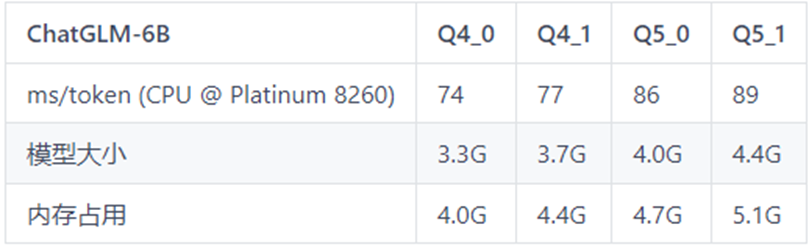
表2 ChatGLM-6B測試表格
歡迎用戶下載體驗,玩轉(zhuǎn)開源大模型,近距離感受AI帶來的技術(shù)革新!
感謝LLaMa、ChatGLM等提供開源大模型等相關(guān)技術(shù),感謝開源項目llama.cpp&chatglm-cpp提供模型輕量化部署等相關(guān)技術(shù)。
審核編輯:湯梓紅
-
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238245 -
C++
+關(guān)注
關(guān)注
22文章
2108瀏覽量
73618 -
openEuler
+關(guān)注
關(guān)注
2文章
312瀏覽量
5860 -
大模型
+關(guān)注
關(guān)注
2文章
2423瀏覽量
2640 -
LLM
+關(guān)注
關(guān)注
0文章
286瀏覽量
327
原文標題:手把手帶你玩轉(zhuǎn)openEuler | 如何本地部署大模型
文章出處:【微信號:openEulercommunity,微信公眾號:openEuler】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
使用CUBEAI部署tflite模型到STM32F0中,模型創(chuàng)建失敗怎么解決?
賽思互動:淺析CRM Online與CRM本地部署的區(qū)別
介紹在STM32cubeIDE上部署AI模型的系列教程
通過Cortex來非常方便的部署PyTorch模型
部署基于嵌入的機器學習模型
如何使用TensorFlow將神經(jīng)網(wǎng)絡(luò)模型部署到移動或嵌入式設(shè)備上
ERP到底該選云部署還是本地部署?兩種模式有什么優(yōu)勢?
深度學習模型的部署方法
本地化ChatGPT?Firefly推出基于BM1684X的大語言模型本地部署方案

AI PC風潮來臨,2027年達到81%,成為PC市場主流
源2.0適配FastChat框架,企業(yè)快速本地化部署大模型對話平臺

llm模型本地部署有用嗎
用Ollama輕松搞定Llama 3.2 Vision模型本地部署






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論