 日志設計開發過程中的常見問題
日志設計開發過程中的常見問題
阿里妹導讀
日志是系統中熵增最快的一個模塊,它承載了業務野蠻生長過程中的所有副產品。本文介紹了一個日志治理案例,圍繞降本和提效兩大主題,取得一定成效,分享給所有渴望造物樂趣的同學。
前言
履約管理是一個面向物流商家的OMS工作臺,自從初代目把架子搭起來之后,就沒有繼續投入了,后來一直是合作伙伴同學在負責日常維護和需求支撐。經過幾年的野蠻生長,系統已經雜草叢生,亂象百出。再后來,甚至一度成為一塊無主之地,走行業共建的方式來支持。對于一個不支持行業隔離的系統,行業共建意味這個系統將快速腐化。
兩年前我開始接管履約管理,來到這片廣闊的蠻荒之地,正如所有那些渴望造物樂趣并且手里剛好有錘子鐮刀的人,我就像一匹脫韁的野馬,腦子里經常會產生很多大膽且新奇的想法,希望借此把履約管理打造成一個完美的系統。只可惜真正能夠付諸實踐的少之又少,本篇就是為數不多得以落地,并且有相當實用價值idea中的一個,整理出來分享給有需要的同學做參考。
日志亂象
日志是日常開發中最有可能被忽視,最容易被濫用的一個模塊。被忽視是因為打日志實在是一個再簡單不過的事,前人設計好了一個logback.xml,后面只需要依樣畫葫蘆定義一個logger,隨手一個info調用就搞定,他甚至不確定這條日志能不能打出來,也不知道會打在哪個文件,反正先跑一次試試,不行就換error。被濫用是因為不同場景日志的格式內容千差萬別,或者說日志打法太靈活,太隨意了,風格太多樣化了,以至于幾乎每個人一言不合就要自己寫一個LogUtil,我見過最夸張的,一個系統中用于打日志的工具類,有二三十個之多,后人糾結該用哪個工具可能就要做半個小時的思想斗爭,完美詮釋了什么叫破窗效應。
最好的學習方式就是通過反面教材吸取教訓,下面我們列舉一些最常見的日志設計開發過程中的問題。
分類之亂
一般來說,一個系統必然需要設計多個日志文件以區分不同業務或場景,不可能所有的日志都打到一個文件里。但是怎么進行分類,沒人告訴我們,于是就有了各種各樣的分類。
按系統模塊分。這種分類應該是最基礎的一種分類,也是最有層次感的分類。比如履約服務中樞的系統分層。基本上每一層對應一個日志文件。 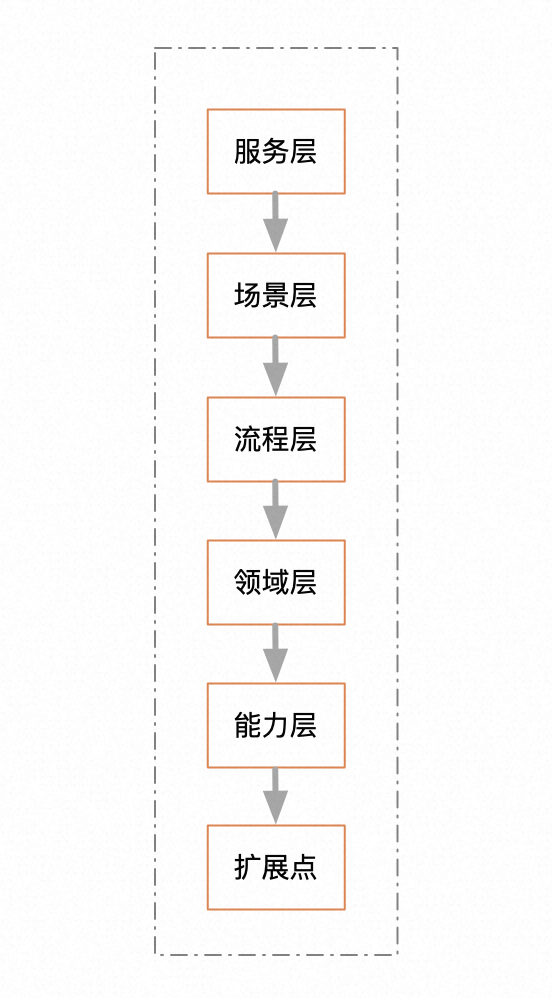
按租戶身份分。
一般中臺系統都會支持多個租戶(行業),每一個租戶單獨對應一個日志文件。這種分類一般不會單獨使用,除非你要做完全意義上的租戶隔離。
意識流分類法。
不符合MECE法則,沒有清晰統一的分類邏輯,按業務分,按系統模塊分,按接口能力分,按新老鏈路分,各種分法的影子都能看到,結果就是分出來幾十個文件,打日志的人根本就不知道這一行的日志會打進哪個文件。
以上說的各種分類方式,都不是絕對純粹的,因為無論哪一種,無論一開始設計的多么邊界清晰,隨著時間的推進,最后都會演變為一個大雜燴。
某人希望單獨監控某個類產生的日志,新增日志文件;
新增了一個業務,比如一盤貨,想單獨監控,新增日志文件;
發起了一場服務化戰役,針對服務化鏈路單獨監控,新增日志文件;
某個業務想采集用戶行為,又不想全接日志消息,新增日志文件;
資損敞口的場景,需要特別關注,新增日志文件;
特殊時期內產生的日志,比如大促,新增日志文件;
凡此種種,不一而足。發現沒有,總有那么一瞬間能讓人產生新增日志文件的神經沖動,他們的訴求和場景也不可謂不合理,盡管這些日志的維度完全不相關,然而沒有什么能阻止這種沖動。最開始的那一套日志設計,就像一個瀕臨死亡的大象,不斷地被不同的利益方從身上扯下一塊分去。
格式之亂
對于日志需要有一定的格式這點相信沒有人會有異議,格式的亂象主要體現在兩個方面,一個是格式的設計上,有些系統設計了非常復雜的格式,用多種分隔符組合,支持日志內容的分組,用關鍵詞定位的方式代替固定位置的格式,同時支持格式擴展,這對人腦和計算機去解析都是一種負擔。第二個是同一個日志文件,還能出現不同格式的內容,堆棧和正常業務日志混雜。
來看一個例子,我不給任何提示,你能在大腦里很快分析出這個日志的結構嗎?
requestParam$&trace@2150435916867358634668899ebccf&scene@test&logTime@2023-06-14 17:44:23&+skuPromiseInfo$&itemId@1234567:1&skuId@8888:1&buyerId@777:1&itemTags@,123:1,2049:1,249:1,&sellerId@6294:1&toCode@371621:1&toTownCode@371621003:1&skuBizCode@TMALL_TAOBAO:1&skuSubBizCode@TMALL_DEFAULT:1&fromCode@DZ_001:1+orderCommonInfo$&orderId@4a04c79734652f6bd7a8876379399777&orderBizCode@TMALL_TAOBAO&orderSubBizCode@TMALL_DEFAULT&toCode@371621&toTownCode@371621003&+
工具之亂
有時候甚至會出現,同一個類,同一個方法中,兩行不同的日志埋點,打出來的日志格式不一樣,落的日志文件也不一樣。為什么會出現這種情況?就是因為用了不同的日志工具。要究其根源,我們需要分析一下不同的工具究竟是在做什么。可以發現,很多工具之間的差別就是支持的參數類型不一樣,有些是打印訂單對象的,有些是打印消息的,有些是打印調度日志的。還有一些差別是面向不同業務場景的,比如一盤貨專用工具,負賣專用工具。還有一些差異是面向不同的異常封裝的,有些是打印ExceptionA,有些是打印ExceptionB的。人間離奇事,莫過于此,或許只能用存在即合理去解釋了。
日志分層
我一直信奉極簡的設計原則,簡單意味著牢不可破。上面提到,一套日志系統最終的結局一定是走向混亂,既然這種趨勢無法避免,那么我們在最初設計的時候就只能確保一件事,保證原始的分類盡量簡單,且不重疊。其實通用的分類方式無非就兩種,一種按職能水平拆分,一種按業務垂直拆分。一般來說,一級分類,應該采用水平拆分。因為業務的邊界一般是很難劃清的,邊界相對模糊,職能的邊界就相對清晰穩定很多,職能其實反映的是工作流,工作流一經形成,基本不會產生太大的結構性變化。基于這種思路,我設計了如下的日志分層。 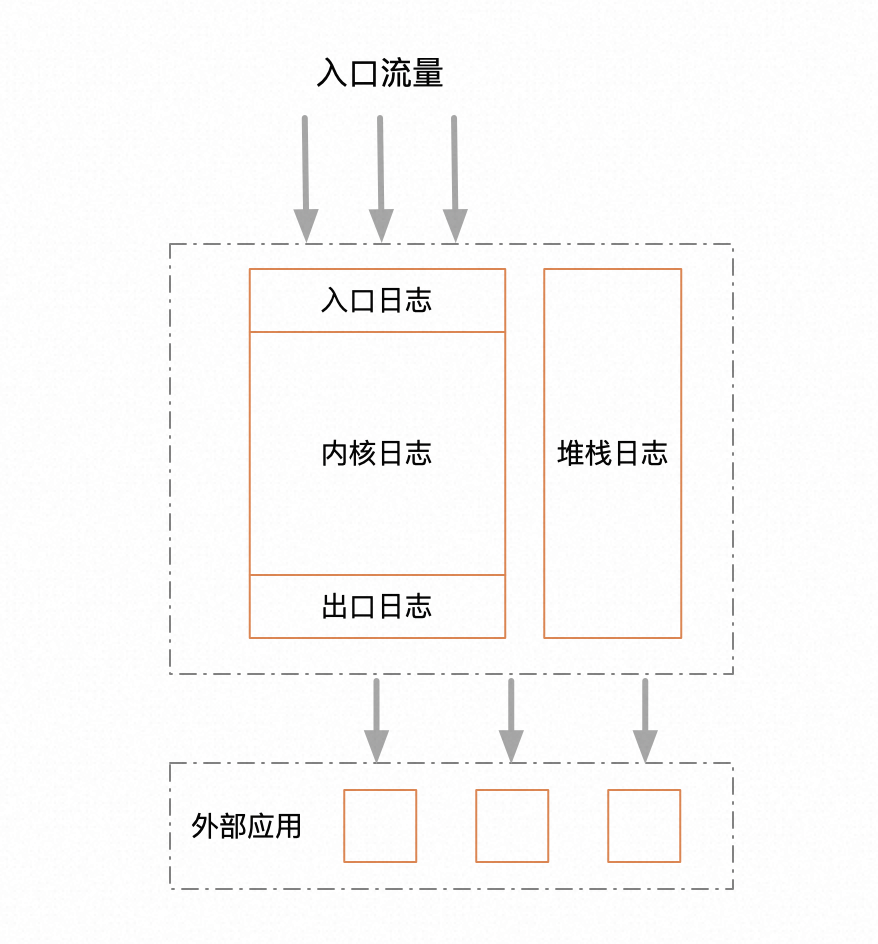
從層次上來看,其實只有三層,入口,內核,出口。入口日志只負責打印流量入口的出入參,比如HSF,controller。出口日志負責打印所有第三方服務調用的出入參。內核日志,負責打印所有中間執行過程中的業務日志。就三層足矣,足夠簡單,不重不漏。另外把堆棧日志單獨拎出來,堆棧相比業務日志有很大的特殊性,本文標題所指出的日志存儲降低優化,也只是針對堆棧日志做的優化,這個后面再講。
格式設計
日志的格式設計也有一些講究。首先日志的設計是面向人可讀的,這個無需多言。另外也非常重要的一個點,要面向可監控的設計,這是容易被很多人忽視的一個點。基于這兩個原則,說一下我在格式設計上的一些思路。
首先要做維度抽象。既然是面向監控,監控一般需要支持多個維護,比如行業維度,服務維度,商家維度等等,那么我們就需要把所有的維度因子抽出來。那么這些維度實際打印的時候怎么傳給logger呢?建議是把他們存到ThreadLocal中,打的時候從上下文中取。這樣做還有一個好處是,日志打印工具設計的時候就會很優雅,只需要傳很少的參數。
格式盡量簡單,采用約定大于配置的原則,每一個維度占據一個固定的位置,用逗號分割。切忌設計一個大而全的模型,然后直接整個的序列化為一個JSON字符串。
也不要被所謂的擴展性給誘惑,給使用方輕易開出一個能夠自定義格式的口子,即便你能輕而易舉的提供這種能力。根據我的經驗,這種擴展性一定會被濫用,到最后連設計者也不知道實際的格式究竟是怎樣的。當然這個需要設計者有較高的視野和遠見,不過這不是難點,難的還是克制自己炫技的欲望。
在內容上,盡量打印可以自解釋的文本,做到見名知義。舉個例子,我們要打印退款標,退款標原本是用1, 2, 4, 8這種二進制位存儲的,打印的時候不要直接打印存儲值,翻譯成一個能描述它含義的英文code。 格式示例
timeStamp|threadName logLevel loggerName|sourceAppName,flowId,traceId,sceneCode,identityCode,loginUserId,scpCode,rpcId,isYace,ip||businessCode,isSuccess||parameters||returnResult||內容示例
2023-08-14 14:37:12.919|http-nio-7001-exec-10 INFO c.a.u.m.s.a.LogAspect|default,c04e4b7ccc2a421995308b3b33503dda,0bb6d59616183822328322237e84cc,queryOrderStatus,XIAODIAN,5000000000014,123456,0.1.1.8,null,255.255.255.255||queryOrderStatus,success||{"@type":"com.alibaba.common.model.queryorder.req.QueryOrderListReq","currentUserDTO":{"bizGroup":888,"shopIdList":[123456],"supplierIdList":[1234,100000000001,100000000002,100000000004]},"extendFields":{"@type":"java.util.HashMap"},"invokeInfoDTO":{"appName":"uop-portal","operatorId":"1110","operatorName":"account_ANXRKY8NfqFjXvQ"},"orderQueryDTO":{"extendFields":{"@type":"java.util.HashMap"},"logisTypeList":[0,1],"pageSize":20,"pageStart":1},"routeRuleParam":{"@type":"java.util.HashMap","bizGroup":199000},"rule":{"$ref":"$.routeRuleParam"}}||{"@type":"com.alibaba.common.model.ResultDTO","idempotent":false,"needRetry":false,"result":{"@type":"com.alibaba.common.model.queryorderstatus.QueryOrderStatusResp","extendFields":{"@type":"java.util.HashMap"}},"success":true}||
堆棧倒打
本文的重點來啦,這個設計就是開頭提到的奇思妙想。堆棧倒打源于我在排查另一個系統問題過程中感受到的幾個痛點,首先來看一個堆棧示例。 
這么長的堆棧,這密密麻麻的字母,即使是天天跟它打交道的開發,相信第一眼看上去也會頭皮發麻。回想一下我們看堆棧,真正想得到的是什么信息。
所以我感受到的痛點核心有兩個。第一個是,SLS(阿里云日志產品系統)上搜出來的日志,默認是折疊的。對于堆棧,我們應該都知道,傳統異常堆棧的特征是,最頂層的異常,是最接近流量入口的異常,這種異常我們一般情況下不太關心。最底層的異常,才是引起系列錯誤的源頭,我們日常排查問題的時候,往往最關心的是錯誤源頭。所以對于堆棧日志,我們無法通過摘要一眼看出問題出在哪行代碼,必須點開,拉到最下面,看最后一個堆棧才能確定源頭。
我寫了一個錯誤示例來說明這個問題。常規的堆棧結構其實分兩部分,我稱之為,異常原因棧,和錯誤堆棧。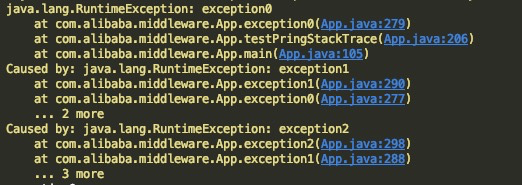
如上,一個堆棧包含有三組異常,每一個RuntimeException是一個異常,這三個異常連起來,我們稱為一個異常原因棧。
每一個RuntimeException內部的堆棧,我們稱為錯誤堆棧。
說明一下,這兩個名詞是我杜撰的,沒有看到有人對二者做區分,我們一般都統稱為堆棧。讀者能理解我想表達的就行,不用太糾結名詞。
第二個痛點是,這種堆棧存儲成本太高,有效信息承載率很低。老實說這一點可能大多數一線開發并沒有太強烈的體感,但在這個降本增效的大環境下,我們每個人應該把這點作為自己的OKR去踐行,變被動為主動,否則在機器成本和人力成本之間,公司只好做選擇題了。
現在目標很明確了,那我們就開始對癥下藥。核心思路有兩個。
針對堆棧折疊的問題,采用堆棧倒打。倒打之后,最底層的異常放在了最上面,甚至不用點開,瞟一眼就能知道原因。 
同時我們也支持異常原因棧層數配置化,以及錯誤堆棧的層數配置化。解這個問題,本質上就是這樣一個簡單的算法題:倒序打印堆棧的最后N個元素。核心代碼如下。
/** * 遞歸逆向打印堆棧及cause(即從最底層的異常開始往上打) * @param t 原始異常 * @param causeDepth 需要遞歸打印的cause的最大深度 * @param counter 當前打印的cause的深度計數器(這里必須用引用類型,如果用基本數據類型,你對計數器的修改只能對當前棧幀可見,但是這個計數器,又必須在所有棧幀中可見,所以只能用引用類型) * @param stackDepth 每一個異常棧的打印深度 * @param sb 字符串構造器 */ public static void recursiveReversePrintStackCause(Throwable t, int causeDepth, ForwardCounter counter, int stackDepth, StringBuilder sb){ if(t == null){ return; } if (t.getCause() != null){ recursiveReversePrintStackCause(t.getCause(), causeDepth, counter, stackDepth, sb); } if(counter.i++ < causeDepth){ doPrintStack(t, stackDepth, sb); } }
要降低存儲成本,同時也要確保信息不失真,我們考慮對堆棧行下手,把全限定類名簡化為類名全打,包路徑只打第一個字母,行號保留。如:c.a.u.m.s.LogAspect#log:88。核心代碼如下。
public static void doPrintStack(Throwable t, int stackDepth, StringBuilder sb){
StackTraceElement[] stackTraceElements = t.getStackTrace();
if(sb.lastIndexOf(" ") > -1){
sb.deleteCharAt(sb.length()-1);
sb.append("Caused: ");
}
sb.append(t.getClass().getName()).append(": ").append(t.getMessage()).append("
");
for(int i=0; i < stackDepth; ++i){
if(i >= stackTraceElements.length){
break;
}
StackTraceElement element = stackTraceElements[i];
sb.append(reduceClassName(element.getClassName()))
.append("#")
.append(element.getMethodName())
.append(":")
.append(element.getLineNumber())
.append("
");
}
}
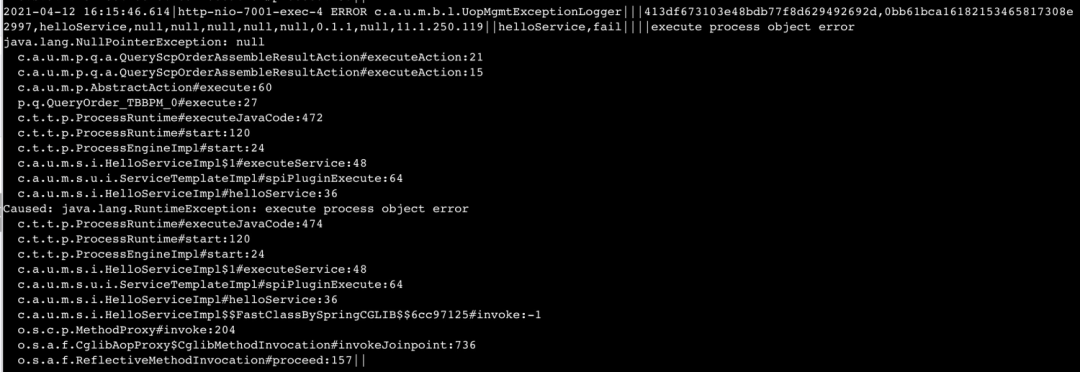
最終的效果大概長這樣。我們隨機挑了一個堆棧做對比,統計字符數量,在同等信息量的情況下,壓縮比達到88%。
思維拓展
很多文章喜歡鼓吹所謂的最佳實踐,在筆者看來最佳實踐是個偽命題。當你在談最佳實踐的時候,你需要指明這個"最"是跟誰比出來的,你的適用范圍是哪些,我相信沒有任何一個人敢大言不慚自己的框架或方案是放之四海而皆準的。
本文所提出的日志設計實踐方案,是在一個典型的中臺應用中落地的,三段的日志分層方案雖然足夠簡單,足夠通用,但是最近解觸了一些富客戶端應用,這個方案要想遷移,可能就得做一些本土化的改造了。他們的特點是依賴的三方服務少,大量的采用緩存設計,這種設計的底層邏輯是,盡量使得所有邏輯能在本地客戶端執行以降低分布式帶來的風險和成本,這意味著,可能99%的日志都是內部執行邏輯打的,那我們就得考慮從另一些維度去做拆分。另外對于日志降本,本文探討的也只是降堆棧的存儲,一個系統不可能所有日志都是堆棧,所以實際整體的日志存儲成本,可能降幅不會有這么多。
談這么多,歸根結底還是一句話,不要迷信銀彈,減肥藥一類的東西,所有的技術也好,思想也好,都要量體裁衣,量力而行。
審核編輯:湯梓紅
-
存儲
+關注
關注
13文章
4296瀏覽量
85799 -
文件
+關注
關注
1文章
565瀏覽量
24727 -
日志
+關注
關注
0文章
138瀏覽量
10639
原文標題:十行代碼讓日志存儲降低80%
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式系統開發過程中的常見問題和解決方法
單片機開發過程中的常見問題
學習ETS開發過程中的常見問題及解決辦法
客車產品設計與開發過程中的質量管理
軟件開發過程中需要的十三類文檔
光端機在使用過程中遇到的常見問題及對應的解決方案
STM32開發過程的常見問題

如何讀懂FPGA開發過程中的Vivado時序報告?

PCB設計中的常見問題有哪些?






 工商網監
工商網監
評論