") 【AI簡報(bào)20231020期】出自華人之手:DALL-E 3論文公布、上線ChatGPT!超火迷你GPT-4
【AI簡報(bào)20231020期】出自華人之手:DALL-E 3論文公布、上線ChatGPT!超火迷你GPT-4
1. OpenAI終于Open一回:DALL-E 3論文公布、上線ChatGPT,作者一半是華人
原文:https://mp.weixin.qq.com/s/xLvJXe2FDL8YdByZLHjGMQ
打開 ChatGPT 就能用 DALL?E 3 生成圖片了,OpenAI 還罕見地發(fā)布了一些技術(shù)細(xì)節(jié)。
終于,「OpenAI 又 Open 了」。在看到 OpenAI 剛剛發(fā)布的 DALL?E 3 相關(guān)論文后,一位網(wǎng)友感嘆說。DALL?E 3 是 OpenAI 在 2023 年 9 月份發(fā)布的一個(gè)文生圖模型。與上一代模型 DALL?E 2 最大的區(qū)別在于,它可以利用 ChatGPT 生成提示(prompt),然后讓模型根據(jù)該提示生成圖像。對(duì)于不擅長編寫提示的普通人來說,這一改進(jìn)大大提高了 DALL?E 3 的使用效率。此外,與 DALL?E 2 相比,DALL?E 3 生成的圖質(zhì)量也更高。
 即使與當(dāng)前最流行的文生圖應(yīng)用 Midjourney 相比,DALL?E 3 也能打個(gè)平手甚至超越 Midjourney。而且與 Midjourney 相比,DALL?E 3 不需要用戶自己掌握復(fù)雜的 Prompt 編寫知識(shí),使用起來門檻更低。
即使與當(dāng)前最流行的文生圖應(yīng)用 Midjourney 相比,DALL?E 3 也能打個(gè)平手甚至超越 Midjourney。而且與 Midjourney 相比,DALL?E 3 不需要用戶自己掌握復(fù)雜的 Prompt 編寫知識(shí),使用起來門檻更低。 這一模型的發(fā)布引發(fā)了不小的轟動(dòng),也再次鞏固了 OpenAI 技術(shù)領(lǐng)頭羊的形象。一時(shí)間,所有人都很好奇,這么炸裂的效果是怎么做到的?不過,令人失望的是,當(dāng)時(shí) OpenAI 并沒有透露技術(shù)細(xì)節(jié),就像之前發(fā)布 GPT-4 時(shí)一樣。不過,一個(gè)月后,OpenAI 還是給了大家一些驚喜。在一份篇幅達(dá) 22 頁的論文中,他們闡述了針對(duì) DALL?E 3 所做的改進(jìn)。論文要點(diǎn)包括:
這一模型的發(fā)布引發(fā)了不小的轟動(dòng),也再次鞏固了 OpenAI 技術(shù)領(lǐng)頭羊的形象。一時(shí)間,所有人都很好奇,這么炸裂的效果是怎么做到的?不過,令人失望的是,當(dāng)時(shí) OpenAI 并沒有透露技術(shù)細(xì)節(jié),就像之前發(fā)布 GPT-4 時(shí)一樣。不過,一個(gè)月后,OpenAI 還是給了大家一些驚喜。在一份篇幅達(dá) 22 頁的論文中,他們闡述了針對(duì) DALL?E 3 所做的改進(jìn)。論文要點(diǎn)包括:- 模型能力的提升主要來自于詳盡的圖像文本描述(image captioning);
- 他們訓(xùn)練了一個(gè)圖像文本描述模型來生成簡短而詳盡的文本;
- 他們使用了 T5 文本編碼器;
- 他們使用了 GPT-4 來完善用戶寫出的簡短提示;
- 他們訓(xùn)練了一個(gè) U-net 解碼器,并將其蒸餾成 2 個(gè)去噪步驟;
- 文本渲染仍然不可靠,他們認(rèn)為該模型很難將單詞 token 映射為圖像中的字母
 如果對(duì)結(jié)果不滿意,你還可以直接讓它在原圖的基礎(chǔ)上修改:
如果對(duì)結(jié)果不滿意,你還可以直接讓它在原圖的基礎(chǔ)上修改: 不過,隨著對(duì)話長度的增加,生成結(jié)果變得有些不穩(wěn)定:
不過,隨著對(duì)話長度的增加,生成結(jié)果變得有些不穩(wěn)定: 為了保證 DALL?E 3 輸出內(nèi)容的安全性和合規(guī)性,OpenAI 也做了一些努力,確保模型輸出的內(nèi)容是被檢查過的,而且不侵犯在世藝術(shù)家的版權(quán)。當(dāng)然,要了解 DALL?E 3 背后的技術(shù),還是要詳細(xì)閱讀論文。以下是論文介紹:論文概覽OpenAI 發(fā)布的 DALL?E 3 相關(guān)論文總共有 19 頁,作者共有 15 位,半數(shù)為華人,分別來自 OpenAI 和微軟。
為了保證 DALL?E 3 輸出內(nèi)容的安全性和合規(guī)性,OpenAI 也做了一些努力,確保模型輸出的內(nèi)容是被檢查過的,而且不侵犯在世藝術(shù)家的版權(quán)。當(dāng)然,要了解 DALL?E 3 背后的技術(shù),還是要詳細(xì)閱讀論文。以下是論文介紹:論文概覽OpenAI 發(fā)布的 DALL?E 3 相關(guān)論文總共有 19 頁,作者共有 15 位,半數(shù)為華人,分別來自 OpenAI 和微軟。 論文地址:https://cdn.openai.com/papers/dall-e-3.pdf論文提出了一種解決提示跟隨(prompt following)問題的新方法:文本描述改進(jìn)(caption improvement)。本文假設(shè)現(xiàn)有的文本 - 圖像模型面臨的一個(gè)基本問題是:訓(xùn)練數(shù)據(jù)集中的文本 - 圖像對(duì)的質(zhì)量較差,這一問題在其他研究中也已經(jīng)被指出。本文建議通過為數(shù)據(jù)集中的圖像生成改進(jìn)的文本描述來解決這個(gè)問題。為了達(dá)到這一目標(biāo),該研究首先學(xué)習(xí)了一個(gè)具有穩(wěn)健性的圖像文本生成器,它可以生成詳細(xì)、準(zhǔn)確的圖像描述。然后,將此文本生成器應(yīng)用到數(shù)據(jù)集以生成更詳細(xì)的文本。最終在改進(jìn)的數(shù)據(jù)集上訓(xùn)練文本 - 圖像模型。其實(shí),用合成數(shù)據(jù)進(jìn)行訓(xùn)練并不是一個(gè)全新的概念。本文的貢獻(xiàn)主要在于研究者構(gòu)建了一個(gè)新穎的具有描述性的圖像文本系統(tǒng),并對(duì)用合成文本訓(xùn)練生成的模型進(jìn)行了評(píng)估。該研究還為一系列評(píng)估建立了一個(gè)可重復(fù)的基準(zhǔn)性能概要文件,這些評(píng)估用于測量提示執(zhí)行的情況。在接下來的章節(jié)中,第 2 節(jié)對(duì)訓(xùn)練圖像文本生成器的策略進(jìn)行了全面概述,第 3 節(jié)對(duì)在原始文本和生成文本上訓(xùn)練的文本到圖像模型進(jìn)行了評(píng)估,第 4 節(jié)對(duì) DALL-E 3 進(jìn)行了評(píng)估,第 5 節(jié)討論了限制和風(fēng)險(xiǎn)。下面我們看看每個(gè)章節(jié)的具體內(nèi)容。數(shù)據(jù)集重描述(Recaptioning)OpenAI 的文本到圖像模型是在大量 (t, i) 對(duì)組成的數(shù)據(jù)集上進(jìn)行訓(xùn)練的,其中 i 是圖像,t 是描述圖像的文本。在大規(guī)模數(shù)據(jù)集中,t 通常源于人類作者,他們主要對(duì)圖像中的對(duì)象進(jìn)行簡單描述,而忽略圖像中的背景細(xì)節(jié)或常識(shí)關(guān)系。更糟糕的是,在互聯(lián)網(wǎng)上找到的描述往往根本不正確或者描述與圖像不怎么相關(guān)的細(xì)節(jié)。OpenAI 認(rèn)為所有的缺陷都可以使用合成描述來解決。為了改進(jìn)在圖像生成數(shù)據(jù)集上的描述效果,OpenAI 希望使用描述生成器來生成圖像描述,這有助于學(xué)習(xí)文本到圖像模型。在首次嘗試中,他們構(gòu)建了一個(gè)僅能描述圖像主對(duì)象的小規(guī)模描述數(shù)據(jù)集,然后繼續(xù)在這個(gè)數(shù)據(jù)集上訓(xùn)練自己的描述生成器。該過程誘導(dǎo)的更新到 θ 使得模型偏向于描述圖像的主對(duì)象。OpenAI 將這種微調(diào)生成的描述稱為「短合成描述」。OpenAI 做了第二次嘗試,創(chuàng)建了一個(gè)更長的、描述更豐富的文本數(shù)據(jù)集,來描述微調(diào)數(shù)據(jù)集中每個(gè)圖像的內(nèi)容。這些描述包括圖像的主對(duì)象,以及周圍對(duì)象、背景、圖像中的文本、風(fēng)格、顏色。他們?cè)谠摂?shù)據(jù)集上對(duì)基礎(chǔ)文本生成器進(jìn)行進(jìn)一步微調(diào),并將該文本生成器生成的文本稱為「描述性合成描述」。下圖 3 展示了真值、短合成和描述性合成描述的示例
論文地址:https://cdn.openai.com/papers/dall-e-3.pdf論文提出了一種解決提示跟隨(prompt following)問題的新方法:文本描述改進(jìn)(caption improvement)。本文假設(shè)現(xiàn)有的文本 - 圖像模型面臨的一個(gè)基本問題是:訓(xùn)練數(shù)據(jù)集中的文本 - 圖像對(duì)的質(zhì)量較差,這一問題在其他研究中也已經(jīng)被指出。本文建議通過為數(shù)據(jù)集中的圖像生成改進(jìn)的文本描述來解決這個(gè)問題。為了達(dá)到這一目標(biāo),該研究首先學(xué)習(xí)了一個(gè)具有穩(wěn)健性的圖像文本生成器,它可以生成詳細(xì)、準(zhǔn)確的圖像描述。然后,將此文本生成器應(yīng)用到數(shù)據(jù)集以生成更詳細(xì)的文本。最終在改進(jìn)的數(shù)據(jù)集上訓(xùn)練文本 - 圖像模型。其實(shí),用合成數(shù)據(jù)進(jìn)行訓(xùn)練并不是一個(gè)全新的概念。本文的貢獻(xiàn)主要在于研究者構(gòu)建了一個(gè)新穎的具有描述性的圖像文本系統(tǒng),并對(duì)用合成文本訓(xùn)練生成的模型進(jìn)行了評(píng)估。該研究還為一系列評(píng)估建立了一個(gè)可重復(fù)的基準(zhǔn)性能概要文件,這些評(píng)估用于測量提示執(zhí)行的情況。在接下來的章節(jié)中,第 2 節(jié)對(duì)訓(xùn)練圖像文本生成器的策略進(jìn)行了全面概述,第 3 節(jié)對(duì)在原始文本和生成文本上訓(xùn)練的文本到圖像模型進(jìn)行了評(píng)估,第 4 節(jié)對(duì) DALL-E 3 進(jìn)行了評(píng)估,第 5 節(jié)討論了限制和風(fēng)險(xiǎn)。下面我們看看每個(gè)章節(jié)的具體內(nèi)容。數(shù)據(jù)集重描述(Recaptioning)OpenAI 的文本到圖像模型是在大量 (t, i) 對(duì)組成的數(shù)據(jù)集上進(jìn)行訓(xùn)練的,其中 i 是圖像,t 是描述圖像的文本。在大規(guī)模數(shù)據(jù)集中,t 通常源于人類作者,他們主要對(duì)圖像中的對(duì)象進(jìn)行簡單描述,而忽略圖像中的背景細(xì)節(jié)或常識(shí)關(guān)系。更糟糕的是,在互聯(lián)網(wǎng)上找到的描述往往根本不正確或者描述與圖像不怎么相關(guān)的細(xì)節(jié)。OpenAI 認(rèn)為所有的缺陷都可以使用合成描述來解決。為了改進(jìn)在圖像生成數(shù)據(jù)集上的描述效果,OpenAI 希望使用描述生成器來生成圖像描述,這有助于學(xué)習(xí)文本到圖像模型。在首次嘗試中,他們構(gòu)建了一個(gè)僅能描述圖像主對(duì)象的小規(guī)模描述數(shù)據(jù)集,然后繼續(xù)在這個(gè)數(shù)據(jù)集上訓(xùn)練自己的描述生成器。該過程誘導(dǎo)的更新到 θ 使得模型偏向于描述圖像的主對(duì)象。OpenAI 將這種微調(diào)生成的描述稱為「短合成描述」。OpenAI 做了第二次嘗試,創(chuàng)建了一個(gè)更長的、描述更豐富的文本數(shù)據(jù)集,來描述微調(diào)數(shù)據(jù)集中每個(gè)圖像的內(nèi)容。這些描述包括圖像的主對(duì)象,以及周圍對(duì)象、背景、圖像中的文本、風(fēng)格、顏色。他們?cè)谠摂?shù)據(jù)集上對(duì)基礎(chǔ)文本生成器進(jìn)行進(jìn)一步微調(diào),并將該文本生成器生成的文本稱為「描述性合成描述」。下圖 3 展示了真值、短合成和描述性合成描述的示例 評(píng)估重描述(re-captioned)數(shù)據(jù)集OpenAI 利用重描述數(shù)據(jù)集,開始評(píng)估訓(xùn)練模型對(duì)合成文本的影響。他們尤其試圖回答以下兩個(gè)問題:
評(píng)估重描述(re-captioned)數(shù)據(jù)集OpenAI 利用重描述數(shù)據(jù)集,開始評(píng)估訓(xùn)練模型對(duì)合成文本的影響。他們尤其試圖回答以下兩個(gè)問題:- 使用每種類型的合成描述對(duì)性能有什么影響
- 合成描述與真值描述的最佳混合比例是多少?
- 合成與真值描述混合
- 評(píng)估方法
 接下來針對(duì)為所有 50000 個(gè)文本 / 圖像對(duì)計(jì)算的余弦距離,OpenAI 執(zhí)行了平均操作,并做了 100 倍重縮放(rescale)。在計(jì)算 CLIP 分?jǐn)?shù),選擇使用哪個(gè)描述非常重要。對(duì)于 OpenAI 的測試,他們要么使用真值描述,要么使用描述性合成描述。同時(shí),每次評(píng)估時(shí)都注明使用了哪個(gè)描述。限制與風(fēng)險(xiǎn)本文的最后一章是大家比較關(guān)心的關(guān)于限制與風(fēng)險(xiǎn)的問題。雖然 DALL-E 3 在 prompt 跟隨方面表現(xiàn)出色,但它仍然在空間感知等方面表現(xiàn)不佳。例如,DALL-E 3 不能很好的理解左邊、下面、后面等表示方位的詞語。此外,在構(gòu)建文本描述生成器時(shí),本文著重考慮了一些突出的引導(dǎo)詞(prominent words),這些引導(dǎo)詞存在于原本圖像以及生成的描述中。因此,DALL-E 3 可以在出現(xiàn) prompt 時(shí)生成文本。在測試過程中,本文注意到此功能并不可靠。本文懷疑這可能與使用 T5 文本編碼器有關(guān):當(dāng)模型遇到 prompt 中的文本時(shí),它實(shí)際上會(huì)看到代表整個(gè)單詞的 token,并且將它們映射到圖像中出現(xiàn)的文本。在未來的工作中,本文希望進(jìn)一步探索字符級(jí)語言模型,以幫助改善 DALL-E 3 面臨的這種限制。最后,本文還觀察到,合成的文本還會(huì)讓生成的圖片在重要細(xì)節(jié)上產(chǎn)生幻覺。這對(duì)下游任務(wù)產(chǎn)生了一定的影響,本文也表示,DALL-E 3 在為特定術(shù)語生成圖像方面并不可靠。不過,該研究相信,對(duì)圖像文本描述的完善能進(jìn)一步改進(jìn) DALL-E 3 的生成結(jié)果。
接下來針對(duì)為所有 50000 個(gè)文本 / 圖像對(duì)計(jì)算的余弦距離,OpenAI 執(zhí)行了平均操作,并做了 100 倍重縮放(rescale)。在計(jì)算 CLIP 分?jǐn)?shù),選擇使用哪個(gè)描述非常重要。對(duì)于 OpenAI 的測試,他們要么使用真值描述,要么使用描述性合成描述。同時(shí),每次評(píng)估時(shí)都注明使用了哪個(gè)描述。限制與風(fēng)險(xiǎn)本文的最后一章是大家比較關(guān)心的關(guān)于限制與風(fēng)險(xiǎn)的問題。雖然 DALL-E 3 在 prompt 跟隨方面表現(xiàn)出色,但它仍然在空間感知等方面表現(xiàn)不佳。例如,DALL-E 3 不能很好的理解左邊、下面、后面等表示方位的詞語。此外,在構(gòu)建文本描述生成器時(shí),本文著重考慮了一些突出的引導(dǎo)詞(prominent words),這些引導(dǎo)詞存在于原本圖像以及生成的描述中。因此,DALL-E 3 可以在出現(xiàn) prompt 時(shí)生成文本。在測試過程中,本文注意到此功能并不可靠。本文懷疑這可能與使用 T5 文本編碼器有關(guān):當(dāng)模型遇到 prompt 中的文本時(shí),它實(shí)際上會(huì)看到代表整個(gè)單詞的 token,并且將它們映射到圖像中出現(xiàn)的文本。在未來的工作中,本文希望進(jìn)一步探索字符級(jí)語言模型,以幫助改善 DALL-E 3 面臨的這種限制。最后,本文還觀察到,合成的文本還會(huì)讓生成的圖片在重要細(xì)節(jié)上產(chǎn)生幻覺。這對(duì)下游任務(wù)產(chǎn)生了一定的影響,本文也表示,DALL-E 3 在為特定術(shù)語生成圖像方面并不可靠。不過,該研究相信,對(duì)圖像文本描述的完善能進(jìn)一步改進(jìn) DALL-E 3 的生成結(jié)果。2. 在RTX 4090被限制的時(shí)代下,讓大模型使用RLHF更高效的方法來了
原文:https://mp.weixin.qq.com/s/3I0kOE1FprOeXSEERVVBIQ
該論文介紹了一種名為 ReMax 的新算法,專為基于人類反饋的強(qiáng)化學(xué)習(xí)(RLHF)而設(shè)計(jì)。ReMax 在計(jì)算效率(約減少 50% 的 GPU 內(nèi)存和 2 倍的訓(xùn)練速度提升)和實(shí)現(xiàn)簡易性(6 行代碼)上超越了最常用的算法 PPO,且性能沒有損失。
- 論文鏈接:https://arxiv.org/abs/2310.10505
- 作者:李子牛,許天,張雨舜,俞揚(yáng),孫若愚,羅智泉
- 機(jī)構(gòu):香港中文大學(xué)(深圳),深圳市大數(shù)據(jù)研究院,南京大學(xué),南棲仙策
- 開源代碼:https://github.com/liziniu/ReMax
 我們發(fā)現(xiàn) RLHF 的主要計(jì)算開銷來源于第三階段(獎(jiǎng)勵(lì)最大化)。這一點(diǎn)可以從 DeepSpeed-Chat 的報(bào)告里看到,第三階段的訓(xùn)練時(shí)間是前兩個(gè)階段時(shí)間總和的 4 倍以上。而且,根據(jù)我們的經(jīng)驗(yàn),第三階段的 GPU 消耗是前兩階段的 2 倍以上。
我們發(fā)現(xiàn) RLHF 的主要計(jì)算開銷來源于第三階段(獎(jiǎng)勵(lì)最大化)。這一點(diǎn)可以從 DeepSpeed-Chat 的報(bào)告里看到,第三階段的訓(xùn)練時(shí)間是前兩個(gè)階段時(shí)間總和的 4 倍以上。而且,根據(jù)我們的經(jīng)驗(yàn),第三階段的 GPU 消耗是前兩階段的 2 倍以上。 目前 RLHF 第 3 階段的主要計(jì)算瓶頸是什么?我們發(fā)現(xiàn)該階段的計(jì)算瓶頸主要來源用來目前使用的 RL 算法:PPO 算法。PPO 算法是用來解決普適 RL 問題的最流行的算法之一,有非常多成功的案例。我們?cè)谶@里省略 PPO 的技術(shù)細(xì)節(jié),著重介紹 PPO 的一個(gè)關(guān)鍵組件:價(jià)值模型 (The value model)。價(jià)值模型是一個(gè)需要被訓(xùn)練的神經(jīng)網(wǎng)絡(luò),能夠有效地估計(jì)給定策略的預(yù)期長期回報(bào)。盡管價(jià)值模型為 PPO 帶來了良好的性能,但它在 RLHF 任務(wù)中也引入了沉重的計(jì)算開銷。例如,為了更好地與人類偏好對(duì)齊,PPO 中的價(jià)值模型通常與 LLM 大小相似,這使存儲(chǔ)需求翻了一番。此外,價(jià)值模型的訓(xùn)練需要存儲(chǔ)其梯度、激活和優(yōu)化器狀態(tài),這進(jìn)一步增加了近 4 倍的 GPU 存儲(chǔ)需求。總結(jié)來說,PPO 和它的價(jià)值模型(以及其訓(xùn)練相關(guān)部分)已成為 RLHF 獎(jiǎng)勵(lì)最大化階段的主要計(jì)算障礙。
目前 RLHF 第 3 階段的主要計(jì)算瓶頸是什么?我們發(fā)現(xiàn)該階段的計(jì)算瓶頸主要來源用來目前使用的 RL 算法:PPO 算法。PPO 算法是用來解決普適 RL 問題的最流行的算法之一,有非常多成功的案例。我們?cè)谶@里省略 PPO 的技術(shù)細(xì)節(jié),著重介紹 PPO 的一個(gè)關(guān)鍵組件:價(jià)值模型 (The value model)。價(jià)值模型是一個(gè)需要被訓(xùn)練的神經(jīng)網(wǎng)絡(luò),能夠有效地估計(jì)給定策略的預(yù)期長期回報(bào)。盡管價(jià)值模型為 PPO 帶來了良好的性能,但它在 RLHF 任務(wù)中也引入了沉重的計(jì)算開銷。例如,為了更好地與人類偏好對(duì)齊,PPO 中的價(jià)值模型通常與 LLM 大小相似,這使存儲(chǔ)需求翻了一番。此外,價(jià)值模型的訓(xùn)練需要存儲(chǔ)其梯度、激活和優(yōu)化器狀態(tài),這進(jìn)一步增加了近 4 倍的 GPU 存儲(chǔ)需求。總結(jié)來說,PPO 和它的價(jià)值模型(以及其訓(xùn)練相關(guān)部分)已成為 RLHF 獎(jiǎng)勵(lì)最大化階段的主要計(jì)算障礙。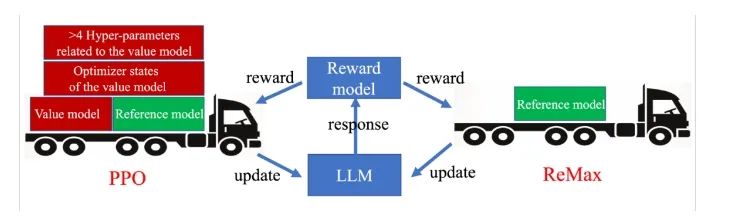 思路是否有可能找到比 PPO 更適配 RLHF 的算法?我們得出的答案是肯定的。這是因?yàn)?PPO 和價(jià)值模型是為通用 RL 問題設(shè)計(jì)的,而不是針對(duì)像 RLHF 這樣的特定問題(RLHF 只是 RL 問題中的一個(gè)子類)。有趣的是,我們發(fā)現(xiàn) RLHF 具有三個(gè)在 PPO 中未使用的重要結(jié)構(gòu):1. 快速模擬(fast simulation):軌跡(即 LLM 中的整個(gè)響應(yīng))可以在很短的時(shí)間內(nèi)迅速執(zhí)行(小于 1s),幾乎沒有時(shí)間開銷。2. 確定性轉(zhuǎn)移(deterministic transitions):上下文確定性依賴于過去的標(biāo)記和當(dāng)前生成的標(biāo)記。3. 軌跡級(jí)獎(jiǎng)勵(lì)(trajectory-level rewards):獎(jiǎng)勵(lì)模型只在響應(yīng)完成時(shí)提供一個(gè)獎(jiǎng)賞值。通過這三個(gè)觀察,我們不難發(fā)現(xiàn) value model 在 RLHF 的問題中是 “冗余” 的。這是因?yàn)?value model 設(shè)計(jì)的初衷是為了隨機(jī)環(huán)境下的樣本效率和慢仿真環(huán)境的計(jì)算效率。然而這在 RLHF 中是不需要的。
思路是否有可能找到比 PPO 更適配 RLHF 的算法?我們得出的答案是肯定的。這是因?yàn)?PPO 和價(jià)值模型是為通用 RL 問題設(shè)計(jì)的,而不是針對(duì)像 RLHF 這樣的特定問題(RLHF 只是 RL 問題中的一個(gè)子類)。有趣的是,我們發(fā)現(xiàn) RLHF 具有三個(gè)在 PPO 中未使用的重要結(jié)構(gòu):1. 快速模擬(fast simulation):軌跡(即 LLM 中的整個(gè)響應(yīng))可以在很短的時(shí)間內(nèi)迅速執(zhí)行(小于 1s),幾乎沒有時(shí)間開銷。2. 確定性轉(zhuǎn)移(deterministic transitions):上下文確定性依賴于過去的標(biāo)記和當(dāng)前生成的標(biāo)記。3. 軌跡級(jí)獎(jiǎng)勵(lì)(trajectory-level rewards):獎(jiǎng)勵(lì)模型只在響應(yīng)完成時(shí)提供一個(gè)獎(jiǎng)賞值。通過這三個(gè)觀察,我們不難發(fā)現(xiàn) value model 在 RLHF 的問題中是 “冗余” 的。這是因?yàn)?value model 設(shè)計(jì)的初衷是為了隨機(jī)環(huán)境下的樣本效率和慢仿真環(huán)境的計(jì)算效率。然而這在 RLHF 中是不需要的。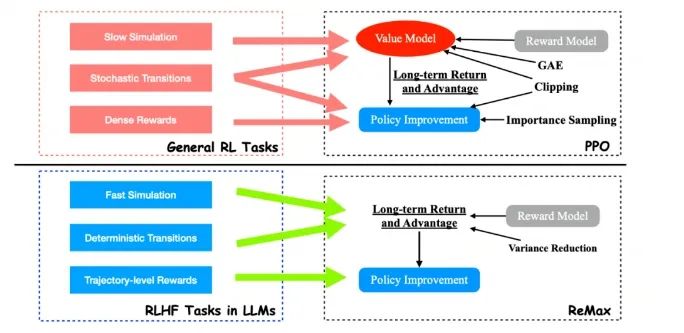 方法ReMaxReMax 算法基于一個(gè)古老的策略梯度算法 REINFORCE,REINFORCE 使用的策略梯度估計(jì)器如下圖所示:
方法ReMaxReMax 算法基于一個(gè)古老的策略梯度算法 REINFORCE,REINFORCE 使用的策略梯度估計(jì)器如下圖所示: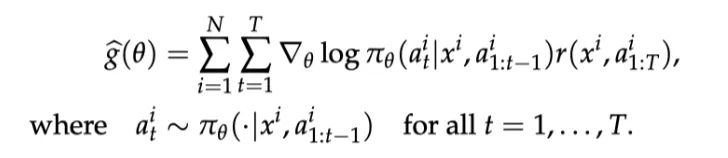 REINFORCE可以在計(jì)算層面利用好RLHF任務(wù)的三個(gè)性質(zhì),因?yàn)镽EINFORCE直接利用一個(gè)響應(yīng)的獎(jiǎng)勵(lì)來進(jìn)行優(yōu)化,不需要像一般的RL算法一樣需要知道中間步驟的獎(jiǎng)勵(lì)和值函數(shù)。然而,由于策略的隨機(jī)性, REINFORCE梯度估計(jì)器存在高方差問題(在Richard Sutton的RL書里有指出),這一問題會(huì)影響模型訓(xùn)練的有效性,因此REINFORCE在RLHF任務(wù)中的效果較差,見下面兩張圖片。
REINFORCE可以在計(jì)算層面利用好RLHF任務(wù)的三個(gè)性質(zhì),因?yàn)镽EINFORCE直接利用一個(gè)響應(yīng)的獎(jiǎng)勵(lì)來進(jìn)行優(yōu)化,不需要像一般的RL算法一樣需要知道中間步驟的獎(jiǎng)勵(lì)和值函數(shù)。然而,由于策略的隨機(jī)性, REINFORCE梯度估計(jì)器存在高方差問題(在Richard Sutton的RL書里有指出),這一問題會(huì)影響模型訓(xùn)練的有效性,因此REINFORCE在RLHF任務(wù)中的效果較差,見下面兩張圖片。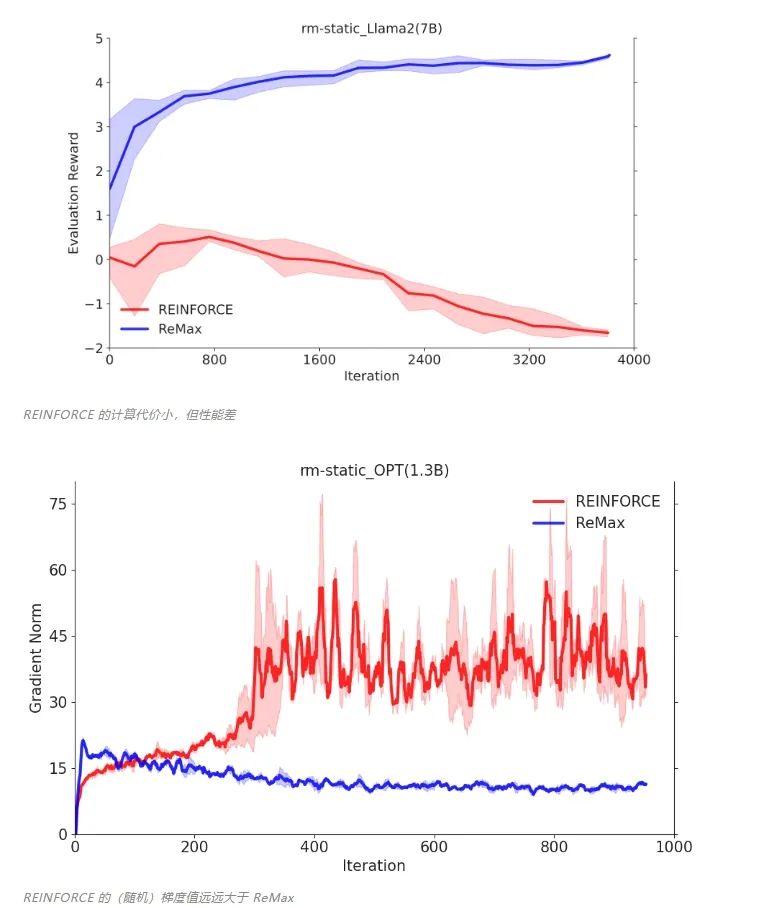 為解決這一問題,ReMax 使用貪婪生成的回答(greedy response)的獎(jiǎng)勵(lì)作為基準(zhǔn)值(baseline value)來構(gòu)建梯度估計(jì)器,具體公式如下:
為解決這一問題,ReMax 使用貪婪生成的回答(greedy response)的獎(jiǎng)勵(lì)作為基準(zhǔn)值(baseline value)來構(gòu)建梯度估計(jì)器,具體公式如下: 理論保證 我們證明了 ReMax 使用的梯度估計(jì)器仍然是真實(shí)策略梯度的一個(gè)無偏估計(jì)器。詳細(xì)理論介紹見論文。算法優(yōu)點(diǎn)
理論保證 我們證明了 ReMax 使用的梯度估計(jì)器仍然是真實(shí)策略梯度的一個(gè)無偏估計(jì)器。詳細(xì)理論介紹見論文。算法優(yōu)點(diǎn)- ReMax 的核心部分可以用 6 行代碼來實(shí)現(xiàn)。相比之下,PPO 要額外引入重要性采樣(importance sampling),廣義優(yōu)勢(shì)估計(jì)(generalized advantage estimation,GAE),價(jià)值模型學(xué)習(xí)等額外模塊。
- ReMax 的超參數(shù)很少。相比之下,PPO 有額外的超參數(shù),例如重要性采樣剪切閾值(importance sampling clipping ratio)、GAE 系數(shù)、價(jià)值模型學(xué)習(xí)率,離策略訓(xùn)練輪次(off-policy training epoch)等,這些超參數(shù)都需要花大量時(shí)間去調(diào)優(yōu)。
- ReMax 能理論上節(jié)省約 50% 內(nèi)存。相比于 PPO,ReMax 成功移除了所有和價(jià)值模型相關(guān)的部件,大大減小了內(nèi)存開銷。通過計(jì)算,我們發(fā)現(xiàn)相比于 PPO,ReMax 能節(jié)省約 50% 內(nèi)存。
- 更簡單的實(shí)現(xiàn):ReMax 的核心部分 6 行代碼即可實(shí)現(xiàn)。這與 PPO 中的眾多復(fù)雜的代碼構(gòu)建塊形成鮮明對(duì)比。
- 更少的內(nèi)存開銷:由于移除了價(jià)值模型及其全部訓(xùn)練組件,相比 PPO,ReMax 節(jié)省了大約 50% 的 GPU 內(nèi)存。
- 更少的超參數(shù): ReMax 成功移除了所有和價(jià)值模型訓(xùn)練相關(guān)的超參數(shù),其中包括:GAE 系數(shù)、價(jià)值模型學(xué)習(xí)率、重要性采樣時(shí)期、小批量(mini-batch)大小。這些超參數(shù)往往對(duì)問題敏感且難以調(diào)整。我們相信 ReMax 對(duì) RLHF 研究者更加友好。
- 更快的訓(xùn)練速度:在 GPT2(137M)的實(shí)驗(yàn)中,我們觀察到 ReMax 在真實(shí)運(yùn)行時(shí)間方面相比于 PPO 有 2.2 倍的加速。加速來自 ReMax 每次迭代中較少的計(jì)算開銷。通過我們的計(jì)算,該加速優(yōu)勢(shì)在更大的模型上也能維持(假設(shè)在足夠大的內(nèi)存下 PPO 可以被成功部署)。
- 優(yōu)異的性能:如前所示,ReMax在中等規(guī)模實(shí)驗(yàn)中與PPO實(shí)現(xiàn)了相當(dāng)?shù)男阅埽⑶矣袝r(shí)甚至超越它(可能是由于 ReMax 更容易找到合適的超參數(shù))。我們推測這種良好的性能可以拓展到更大規(guī)模的模型中。
3. 10年市場規(guī)模1.3萬億美元,「模力時(shí)代」已來
原文:https://mp.weixin.qq.com/s/ps274X9uf_hTe0UopkGtsg大模型風(fēng)暴刮了大半年,AIGC市場開始起了新的變化:酷炫的技術(shù)Demo,正在被完整的產(chǎn)品體驗(yàn)所取代。比如,OpenAI最新AI繪畫模型DALL· E 3剛一登場,就跟ChatGPT強(qiáng)強(qiáng)聯(lián)合,成為ChatGPT Plus里最令人期待的新生產(chǎn)力工具。
 又比如,微軟基于GPT-4打造的Copilot,已經(jīng)全線入駐Win11,正式取代Cortana成為操作系統(tǒng)里的新一代AI助手。
又比如,微軟基于GPT-4打造的Copilot,已經(jīng)全線入駐Win11,正式取代Cortana成為操作系統(tǒng)里的新一代AI助手。 再比如,國產(chǎn)汽車如極越01,已經(jīng)在座艙中正式搭載大模型,而且是完全離線的那種……如果說,「大模型重塑一切」在2023年的3月份還只是一句技術(shù)先行者的樂觀預(yù)言,到了今天,仍舊激烈的百模大戰(zhàn)、以及實(shí)際的應(yīng)用進(jìn)展,已經(jīng)讓這一觀點(diǎn)在行業(yè)內(nèi)外激發(fā)越來越多的共鳴。換言之,大到整個(gè)互聯(lián)網(wǎng)的生產(chǎn)方式,小到每一輛汽車中的智能座艙,一個(gè)以大模型為技術(shù)力底座、驅(qū)動(dòng)千行百業(yè)自我革新的時(shí)代正在來臨。按照蒸汽時(shí)代、電力時(shí)代的命名方式,或許能將之命名為「模力時(shí)代」。而在「模力時(shí)代」中,最受關(guān)注的場景之一,就是智能終端。原因很簡單:以智能手機(jī)、PC、智能汽車甚至XR設(shè)備等為代表的智能終端產(chǎn)業(yè),是與當(dāng)代人生活最緊密相關(guān)的科技產(chǎn)業(yè)之一,自然也就成為了檢驗(yàn)前沿技術(shù)成熟度的一個(gè)金標(biāo)準(zhǔn)。所以,當(dāng)技術(shù)熱潮帶來的第一波炒作逐漸冷靜,以智能終端場景為一個(gè)錨點(diǎn),「模力時(shí)代」新的機(jī)遇和挑戰(zhàn)應(yīng)該如何去看待和解讀?現(xiàn)在,是時(shí)候掰開揉碎,好好梳理一番了。智能終端,大模型新戰(zhàn)場在具體分析挑戰(zhàn)和機(jī)遇之前,還是先回到一個(gè)本質(zhì)的問題上:大模型為代表的生成式AI為何會(huì)如此火爆,甚至被認(rèn)為是“第四次工業(yè)革命”?針對(duì)這一現(xiàn)象,已經(jīng)有不少機(jī)構(gòu)在進(jìn)行研究,試圖預(yù)測或總結(jié)生成式AI在不同場景下的發(fā)展規(guī)律,如紅杉資本的《Generative AI: A Creative New World》。在這其中,也有不少行業(yè)頭部公司,基于自身經(jīng)驗(yàn)分析了生成式AI在特定行業(yè)中的落地場景和潛在變革方向。如終端側(cè)AI代表玩家高通,就在前段時(shí)間發(fā)布了關(guān)于生成式AI發(fā)展現(xiàn)狀和趨勢(shì)的白皮書《混合AI是AI的未來》。從中,或許能解讀出生成式AI在行業(yè)中火爆的三大原因。首先,是技術(shù)本身足夠硬核。無論是智能涌現(xiàn)的大模型,還是生成質(zhì)量以假亂真的AI繪畫,無不是用效果說話,實(shí)打?qū)嵲趲缀跛信c文字、圖像、視頻和自動(dòng)化相關(guān)的工作領(lǐng)域,展現(xiàn)出了顛覆傳統(tǒng)工作流的驚人能力。其次,是潛在落地場景豐富。大模型所帶來的AI代際式的突破,從一開始就帶給了人們無窮的想象空間:最早的一批體驗(yàn)者,很快就感知到了生成式AI給工作帶來的助益。用戶側(cè)龐大的需求,從ChatGPT等代表性應(yīng)用的用戶增速,就可見一斑。
再比如,國產(chǎn)汽車如極越01,已經(jīng)在座艙中正式搭載大模型,而且是完全離線的那種……如果說,「大模型重塑一切」在2023年的3月份還只是一句技術(shù)先行者的樂觀預(yù)言,到了今天,仍舊激烈的百模大戰(zhàn)、以及實(shí)際的應(yīng)用進(jìn)展,已經(jīng)讓這一觀點(diǎn)在行業(yè)內(nèi)外激發(fā)越來越多的共鳴。換言之,大到整個(gè)互聯(lián)網(wǎng)的生產(chǎn)方式,小到每一輛汽車中的智能座艙,一個(gè)以大模型為技術(shù)力底座、驅(qū)動(dòng)千行百業(yè)自我革新的時(shí)代正在來臨。按照蒸汽時(shí)代、電力時(shí)代的命名方式,或許能將之命名為「模力時(shí)代」。而在「模力時(shí)代」中,最受關(guān)注的場景之一,就是智能終端。原因很簡單:以智能手機(jī)、PC、智能汽車甚至XR設(shè)備等為代表的智能終端產(chǎn)業(yè),是與當(dāng)代人生活最緊密相關(guān)的科技產(chǎn)業(yè)之一,自然也就成為了檢驗(yàn)前沿技術(shù)成熟度的一個(gè)金標(biāo)準(zhǔn)。所以,當(dāng)技術(shù)熱潮帶來的第一波炒作逐漸冷靜,以智能終端場景為一個(gè)錨點(diǎn),「模力時(shí)代」新的機(jī)遇和挑戰(zhàn)應(yīng)該如何去看待和解讀?現(xiàn)在,是時(shí)候掰開揉碎,好好梳理一番了。智能終端,大模型新戰(zhàn)場在具體分析挑戰(zhàn)和機(jī)遇之前,還是先回到一個(gè)本質(zhì)的問題上:大模型為代表的生成式AI為何會(huì)如此火爆,甚至被認(rèn)為是“第四次工業(yè)革命”?針對(duì)這一現(xiàn)象,已經(jīng)有不少機(jī)構(gòu)在進(jìn)行研究,試圖預(yù)測或總結(jié)生成式AI在不同場景下的發(fā)展規(guī)律,如紅杉資本的《Generative AI: A Creative New World》。在這其中,也有不少行業(yè)頭部公司,基于自身經(jīng)驗(yàn)分析了生成式AI在特定行業(yè)中的落地場景和潛在變革方向。如終端側(cè)AI代表玩家高通,就在前段時(shí)間發(fā)布了關(guān)于生成式AI發(fā)展現(xiàn)狀和趨勢(shì)的白皮書《混合AI是AI的未來》。從中,或許能解讀出生成式AI在行業(yè)中火爆的三大原因。首先,是技術(shù)本身足夠硬核。無論是智能涌現(xiàn)的大模型,還是生成質(zhì)量以假亂真的AI繪畫,無不是用效果說話,實(shí)打?qū)嵲趲缀跛信c文字、圖像、視頻和自動(dòng)化相關(guān)的工作領(lǐng)域,展現(xiàn)出了顛覆傳統(tǒng)工作流的驚人能力。其次,是潛在落地場景豐富。大模型所帶來的AI代際式的突破,從一開始就帶給了人們無窮的想象空間:最早的一批體驗(yàn)者,很快就感知到了生成式AI給工作帶來的助益。用戶側(cè)龐大的需求,從ChatGPT等代表性應(yīng)用的用戶增速,就可見一斑。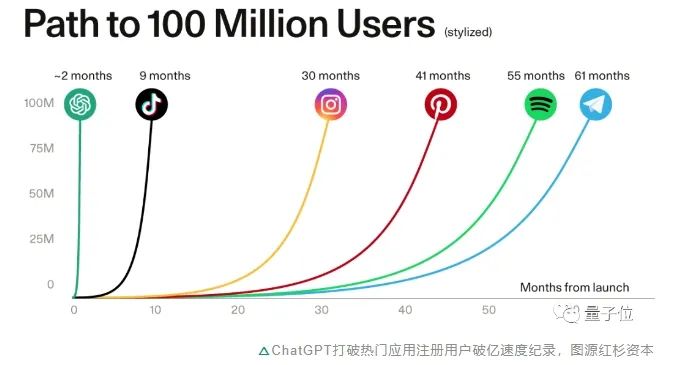 從最開始互聯(lián)網(wǎng)的搜索、編程、辦公,到現(xiàn)在涌現(xiàn)的文旅、法律、醫(yī)藥、工業(yè)、交通等等場景應(yīng)用,乘生成式AI之風(fēng)而起的,遠(yuǎn)不止能夠提供基礎(chǔ)大模型的公司,更是有一大批初創(chuàng)企業(yè)正順勢(shì)繁榮生長。有不少業(yè)內(nèi)專家認(rèn)為:對(duì)于創(chuàng)業(yè)者而言,大模型所帶來的應(yīng)用層的機(jī)會(huì)更大。底層有技術(shù)的代際式突破,上層有應(yīng)用需求的蓬勃爆發(fā),生態(tài)效應(yīng)由此被激發(fā)。根據(jù)Bloomberg Intelligence預(yù)測,到2032年生成式AI市場規(guī)模將從400億美元爆炸式增到1.3萬億美元,廣泛覆蓋生態(tài)鏈的各個(gè)參與方,包括基礎(chǔ)設(shè)施、基礎(chǔ)模型、開發(fā)者工具、應(yīng)用產(chǎn)品、終端產(chǎn)品等等。
從最開始互聯(lián)網(wǎng)的搜索、編程、辦公,到現(xiàn)在涌現(xiàn)的文旅、法律、醫(yī)藥、工業(yè)、交通等等場景應(yīng)用,乘生成式AI之風(fēng)而起的,遠(yuǎn)不止能夠提供基礎(chǔ)大模型的公司,更是有一大批初創(chuàng)企業(yè)正順勢(shì)繁榮生長。有不少業(yè)內(nèi)專家認(rèn)為:對(duì)于創(chuàng)業(yè)者而言,大模型所帶來的應(yīng)用層的機(jī)會(huì)更大。底層有技術(shù)的代際式突破,上層有應(yīng)用需求的蓬勃爆發(fā),生態(tài)效應(yīng)由此被激發(fā)。根據(jù)Bloomberg Intelligence預(yù)測,到2032年生成式AI市場規(guī)模將從400億美元爆炸式增到1.3萬億美元,廣泛覆蓋生態(tài)鏈的各個(gè)參與方,包括基礎(chǔ)設(shè)施、基礎(chǔ)模型、開發(fā)者工具、應(yīng)用產(chǎn)品、終端產(chǎn)品等等。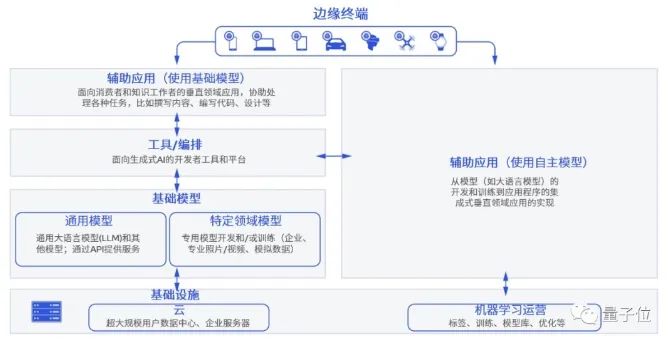 這種生態(tài)鏈的形成,推動(dòng)了行業(yè)新的變革,有望讓AI進(jìn)一步成為底層核心生產(chǎn)力。基于這樣的背景,我們?cè)賮砜粗悄墚a(chǎn)業(yè)當(dāng)下正在發(fā)生的事情。一方面,以大模型為代表的AIGC應(yīng)用風(fēng)暴,正在以天為單位的迭代節(jié)奏中迅速從云端走向終端。ChatGPT就率先在移動(dòng)端更新了“視聽說”的多模態(tài)功能,用戶們拍照上傳,就能針對(duì)照片內(nèi)容與ChatGPT進(jìn)行對(duì)話。高通也快速實(shí)現(xiàn)了在終端側(cè)運(yùn)行十幾億參數(shù)的Stable Diffusion和ControlNet大模型,在手機(jī)上生成高質(zhì)量AI圖像只需十幾秒。不少手機(jī)廠商也已經(jīng)宣布,要為自家語音助手裝上大模型這個(gè)“大腦”。還不僅僅是手機(jī)。在上海車展、成都車展、慕尼黑車展等等國內(nèi)外大型展會(huì)上,基礎(chǔ)模型廠商和車廠的合作越來越常見,大模型“上車”已然成為智能座艙領(lǐng)域新的競爭點(diǎn)。
這種生態(tài)鏈的形成,推動(dòng)了行業(yè)新的變革,有望讓AI進(jìn)一步成為底層核心生產(chǎn)力。基于這樣的背景,我們?cè)賮砜粗悄墚a(chǎn)業(yè)當(dāng)下正在發(fā)生的事情。一方面,以大模型為代表的AIGC應(yīng)用風(fēng)暴,正在以天為單位的迭代節(jié)奏中迅速從云端走向終端。ChatGPT就率先在移動(dòng)端更新了“視聽說”的多模態(tài)功能,用戶們拍照上傳,就能針對(duì)照片內(nèi)容與ChatGPT進(jìn)行對(duì)話。高通也快速實(shí)現(xiàn)了在終端側(cè)運(yùn)行十幾億參數(shù)的Stable Diffusion和ControlNet大模型,在手機(jī)上生成高質(zhì)量AI圖像只需十幾秒。不少手機(jī)廠商也已經(jīng)宣布,要為自家語音助手裝上大模型這個(gè)“大腦”。還不僅僅是手機(jī)。在上海車展、成都車展、慕尼黑車展等等國內(nèi)外大型展會(huì)上,基礎(chǔ)模型廠商和車廠的合作越來越常見,大模型“上車”已然成為智能座艙領(lǐng)域新的競爭點(diǎn)。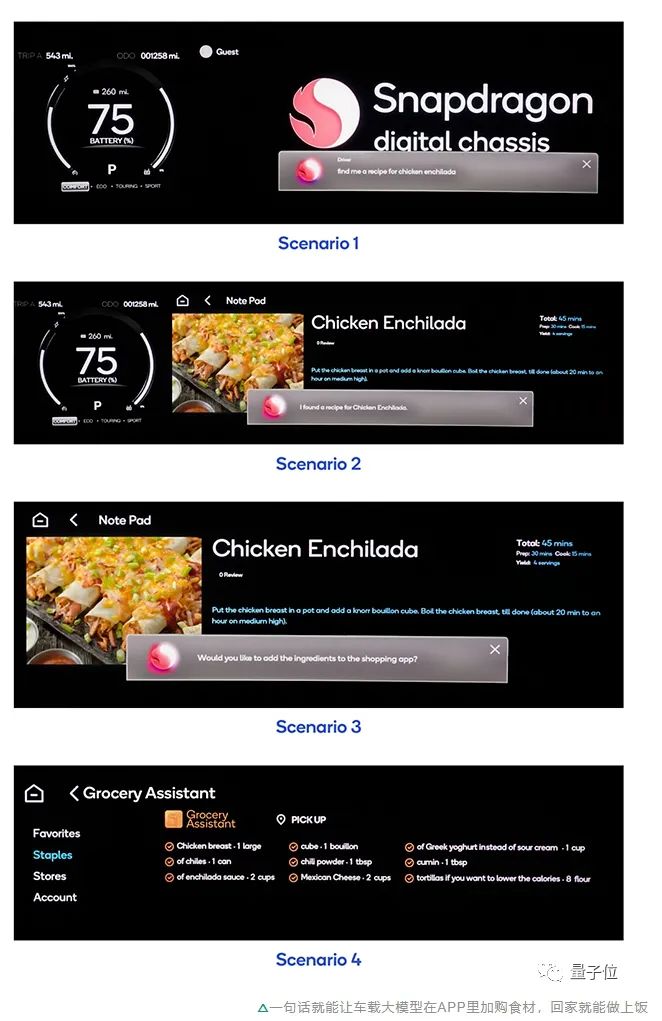 另一方面,應(yīng)用的爆發(fā)加劇了算力供不應(yīng)求的情況。可以預(yù)見的是,模型的推理成本將會(huì)隨著日活用戶數(shù)量及其使用頻率的增加而增加,僅僅只依靠云端算力,是不足以快速推進(jìn)生成式AI規(guī)模化的。從各行各業(yè)都在提升對(duì)終端側(cè)AI算力的重視程度,也能看出這一點(diǎn)。例如終端側(cè)AI玩家高通,針對(duì)PC端芯片性能提升發(fā)布了新一代PC計(jì)算平臺(tái),采用高通自研的Oryon CPU,尤其搭載的NPU將面向生成式AI提供更強(qiáng)大的性能,被命名為驍龍X系列平臺(tái)。預(yù)計(jì)會(huì)在2023驍龍峰會(huì)上,這一新的計(jì)算平臺(tái)就會(huì)發(fā)布。顯然,無論從應(yīng)用還是算力來看,智能終端都已經(jīng)成為AIGC落地潛力最大的場景之一。AIGC潮涌下的暗礁事物通常具有兩面性,大模型從快速發(fā)展到落地亦是如此。當(dāng)生成式AI一路狂飆到今天,智能終端產(chǎn)業(yè)巨大潛力下的現(xiàn)實(shí)瓶頸,已經(jīng)浮出水面。最大的掣肘之一,是最底層的硬件。正如紅杉兩位投資人Sonya Huang和Pat Grady最新一篇生成式AI分析文章《Generative AI’s Act Two》中所提到的,AIGC發(fā)展得很快,然而預(yù)料之中的瓶頸不在于客戶需求,而在于供應(yīng)端的算力。這里的算力,主要指AI和機(jī)器學(xué)習(xí)硬件加速器,從部署場景來看又可以被分為五大類:數(shù)據(jù)中心級(jí)系統(tǒng)、服務(wù)器級(jí)加速器、輔助駕駛&自動(dòng)駕駛場景下的加速器、邊緣計(jì)算和超低功耗加速器。
另一方面,應(yīng)用的爆發(fā)加劇了算力供不應(yīng)求的情況。可以預(yù)見的是,模型的推理成本將會(huì)隨著日活用戶數(shù)量及其使用頻率的增加而增加,僅僅只依靠云端算力,是不足以快速推進(jìn)生成式AI規(guī)模化的。從各行各業(yè)都在提升對(duì)終端側(cè)AI算力的重視程度,也能看出這一點(diǎn)。例如終端側(cè)AI玩家高通,針對(duì)PC端芯片性能提升發(fā)布了新一代PC計(jì)算平臺(tái),采用高通自研的Oryon CPU,尤其搭載的NPU將面向生成式AI提供更強(qiáng)大的性能,被命名為驍龍X系列平臺(tái)。預(yù)計(jì)會(huì)在2023驍龍峰會(huì)上,這一新的計(jì)算平臺(tái)就會(huì)發(fā)布。顯然,無論從應(yīng)用還是算力來看,智能終端都已經(jīng)成為AIGC落地潛力最大的場景之一。AIGC潮涌下的暗礁事物通常具有兩面性,大模型從快速發(fā)展到落地亦是如此。當(dāng)生成式AI一路狂飆到今天,智能終端產(chǎn)業(yè)巨大潛力下的現(xiàn)實(shí)瓶頸,已經(jīng)浮出水面。最大的掣肘之一,是最底層的硬件。正如紅杉兩位投資人Sonya Huang和Pat Grady最新一篇生成式AI分析文章《Generative AI’s Act Two》中所提到的,AIGC發(fā)展得很快,然而預(yù)料之中的瓶頸不在于客戶需求,而在于供應(yīng)端的算力。這里的算力,主要指AI和機(jī)器學(xué)習(xí)硬件加速器,從部署場景來看又可以被分為五大類:數(shù)據(jù)中心級(jí)系統(tǒng)、服務(wù)器級(jí)加速器、輔助駕駛&自動(dòng)駕駛場景下的加速器、邊緣計(jì)算和超低功耗加速器。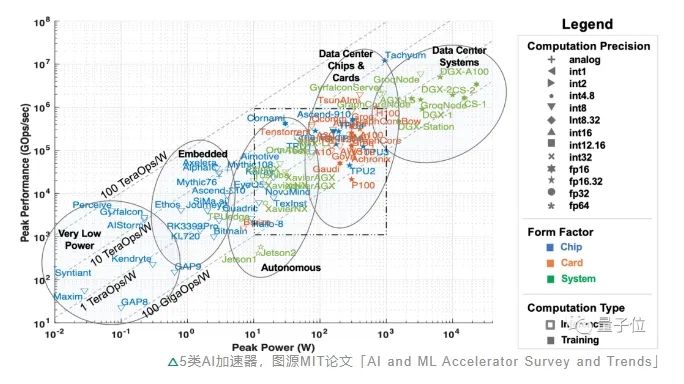 隨著ChatGPT爆火,大模型帶動(dòng)AIGC現(xiàn)象級(jí)出圈,使得數(shù)據(jù)中心、服務(wù)器級(jí)處理器等“云端算力”短期受到大量關(guān)注,甚至出現(xiàn)供不應(yīng)求的情況。然而,隨著生成式AI迎來第二階段,關(guān)于算力的一些問題也日漸凸顯。首先也是最大的問題,在于成本。如高通《混合AI是AI的未來》白皮書所言,如今大半年過去,隨著大模型從技術(shù)追逐轉(zhuǎn)向應(yīng)用落地,各公司的基礎(chǔ)模型訓(xùn)練逐漸塵埃落定,算力的大部頭落到大模型的推理上。短期內(nèi)推理成本還可以接受,但隨著大模型的APP越來越多、應(yīng)用場景越來越廣泛,在服務(wù)器等加速器上推理的成本也會(huì)急劇增加,最終導(dǎo)致調(diào)用大模型的成本比訓(xùn)練大模型本身還高。換言之,大模型進(jìn)入第二階段后,推理對(duì)算力的長期需求將會(huì)遠(yuǎn)遠(yuǎn)高于單次訓(xùn)練,僅僅依靠數(shù)據(jù)中心和服務(wù)器級(jí)處理器組成的“云端算力”,完全不足以將推理打到用戶能夠接受的成本。據(jù)高通在白皮書中統(tǒng)計(jì),以加持大模型的搜索引擎為例,每一次搜索查詢的成本,可以達(dá)到傳統(tǒng)方法的10倍,每年光是在這方面的開銷就可能增加數(shù)十億美元。這注定會(huì)成為大模型落地的關(guān)鍵掣肘。隨之而來的,還有時(shí)延、隱私和個(gè)性化問題。高通在《混合AI是AI的未來》中也提到,大模型直接部署在云端,除了用戶量激增帶來的服務(wù)器計(jì)算量不夠,需要“排隊(duì)使用”等bug,還勢(shì)必需要解決用戶隱私和個(gè)性化問題。如果用戶不希望上傳數(shù)據(jù)到云端,大模型的使用場景如辦公、智能助手等,就會(huì)受到不少限制,而這些場景多數(shù)分布在終端側(cè);而如果需要進(jìn)一步追求更好的效果,如定制大模型為己用,更是需要直接將個(gè)人信息用于大模型訓(xùn)練。種種因素之下,在推理上能發(fā)揮作用的“終端算力”,也就是包括自動(dòng)駕駛&輔助駕駛、邊緣計(jì)算(嵌入式)和超低功耗加速器在內(nèi)的幾大類處理器,開始進(jìn)入人們的視野。終端潛藏著巨大的計(jì)算能力。據(jù)IDC預(yù)測,2025年全球物聯(lián)網(wǎng)設(shè)備數(shù)將超過400億臺(tái),產(chǎn)生數(shù)據(jù)量接近80ZB,超過一半的數(shù)據(jù)需要依賴終端或者邊緣的計(jì)算能力進(jìn)行處理。但終端同樣存在功耗散熱受限導(dǎo)致算力受限等問題。這種情況下,如何利用潛藏在終端的巨大算力,來突破云端算力發(fā)展面臨的瓶頸,正在成為「模力時(shí)代」下的最普遍的技術(shù)難題之一。更別提除了算力以外,大模型落地還面臨著算法、數(shù)據(jù)和市場競爭等挑戰(zhàn)。對(duì)于算法而言,基礎(chǔ)模型的架構(gòu)依舊未知。ChatGPT固然已經(jīng)取得了很好的成果,但其堅(jiān)持的技術(shù)路線并非就是下一代模型的架構(gòu)方向。對(duì)于數(shù)據(jù)而言,其他公司要想取得ChatGPT一般的大模型成果,高質(zhì)量數(shù)據(jù)不可或缺,但《Generative AI’s Act Two》同樣指出,目前應(yīng)用公司生成的數(shù)據(jù)并沒有創(chuàng)造一個(gè)真正的壁壘。靠數(shù)據(jù)建立起來的優(yōu)勢(shì)是脆弱且無法持續(xù)的,下一代基礎(chǔ)模型很可能就能直接摧毀這堵“城墻”,相比之下,持續(xù)而穩(wěn)定的用戶才能真正構(gòu)建數(shù)據(jù)來源。對(duì)于市場而言,目前大模型產(chǎn)品尚未出現(xiàn)多個(gè)殺手級(jí)應(yīng)用,它究竟適配于何種場景仍舊未可知。在這個(gè)時(shí)代將它用于哪類產(chǎn)品之中、做出哪種應(yīng)用能發(fā)揮它最大的價(jià)值,目前市場還沒能給出一套能夠沿襲的方法論或標(biāo)準(zhǔn)答案。更感興趣的內(nèi)容,請(qǐng)查看源文。
隨著ChatGPT爆火,大模型帶動(dòng)AIGC現(xiàn)象級(jí)出圈,使得數(shù)據(jù)中心、服務(wù)器級(jí)處理器等“云端算力”短期受到大量關(guān)注,甚至出現(xiàn)供不應(yīng)求的情況。然而,隨著生成式AI迎來第二階段,關(guān)于算力的一些問題也日漸凸顯。首先也是最大的問題,在于成本。如高通《混合AI是AI的未來》白皮書所言,如今大半年過去,隨著大模型從技術(shù)追逐轉(zhuǎn)向應(yīng)用落地,各公司的基礎(chǔ)模型訓(xùn)練逐漸塵埃落定,算力的大部頭落到大模型的推理上。短期內(nèi)推理成本還可以接受,但隨著大模型的APP越來越多、應(yīng)用場景越來越廣泛,在服務(wù)器等加速器上推理的成本也會(huì)急劇增加,最終導(dǎo)致調(diào)用大模型的成本比訓(xùn)練大模型本身還高。換言之,大模型進(jìn)入第二階段后,推理對(duì)算力的長期需求將會(huì)遠(yuǎn)遠(yuǎn)高于單次訓(xùn)練,僅僅依靠數(shù)據(jù)中心和服務(wù)器級(jí)處理器組成的“云端算力”,完全不足以將推理打到用戶能夠接受的成本。據(jù)高通在白皮書中統(tǒng)計(jì),以加持大模型的搜索引擎為例,每一次搜索查詢的成本,可以達(dá)到傳統(tǒng)方法的10倍,每年光是在這方面的開銷就可能增加數(shù)十億美元。這注定會(huì)成為大模型落地的關(guān)鍵掣肘。隨之而來的,還有時(shí)延、隱私和個(gè)性化問題。高通在《混合AI是AI的未來》中也提到,大模型直接部署在云端,除了用戶量激增帶來的服務(wù)器計(jì)算量不夠,需要“排隊(duì)使用”等bug,還勢(shì)必需要解決用戶隱私和個(gè)性化問題。如果用戶不希望上傳數(shù)據(jù)到云端,大模型的使用場景如辦公、智能助手等,就會(huì)受到不少限制,而這些場景多數(shù)分布在終端側(cè);而如果需要進(jìn)一步追求更好的效果,如定制大模型為己用,更是需要直接將個(gè)人信息用于大模型訓(xùn)練。種種因素之下,在推理上能發(fā)揮作用的“終端算力”,也就是包括自動(dòng)駕駛&輔助駕駛、邊緣計(jì)算(嵌入式)和超低功耗加速器在內(nèi)的幾大類處理器,開始進(jìn)入人們的視野。終端潛藏著巨大的計(jì)算能力。據(jù)IDC預(yù)測,2025年全球物聯(lián)網(wǎng)設(shè)備數(shù)將超過400億臺(tái),產(chǎn)生數(shù)據(jù)量接近80ZB,超過一半的數(shù)據(jù)需要依賴終端或者邊緣的計(jì)算能力進(jìn)行處理。但終端同樣存在功耗散熱受限導(dǎo)致算力受限等問題。這種情況下,如何利用潛藏在終端的巨大算力,來突破云端算力發(fā)展面臨的瓶頸,正在成為「模力時(shí)代」下的最普遍的技術(shù)難題之一。更別提除了算力以外,大模型落地還面臨著算法、數(shù)據(jù)和市場競爭等挑戰(zhàn)。對(duì)于算法而言,基礎(chǔ)模型的架構(gòu)依舊未知。ChatGPT固然已經(jīng)取得了很好的成果,但其堅(jiān)持的技術(shù)路線并非就是下一代模型的架構(gòu)方向。對(duì)于數(shù)據(jù)而言,其他公司要想取得ChatGPT一般的大模型成果,高質(zhì)量數(shù)據(jù)不可或缺,但《Generative AI’s Act Two》同樣指出,目前應(yīng)用公司生成的數(shù)據(jù)并沒有創(chuàng)造一個(gè)真正的壁壘。靠數(shù)據(jù)建立起來的優(yōu)勢(shì)是脆弱且無法持續(xù)的,下一代基礎(chǔ)模型很可能就能直接摧毀這堵“城墻”,相比之下,持續(xù)而穩(wěn)定的用戶才能真正構(gòu)建數(shù)據(jù)來源。對(duì)于市場而言,目前大模型產(chǎn)品尚未出現(xiàn)多個(gè)殺手級(jí)應(yīng)用,它究竟適配于何種場景仍舊未可知。在這個(gè)時(shí)代將它用于哪類產(chǎn)品之中、做出哪種應(yīng)用能發(fā)揮它最大的價(jià)值,目前市場還沒能給出一套能夠沿襲的方法論或標(biāo)準(zhǔn)答案。更感興趣的內(nèi)容,請(qǐng)查看源文。4. 憶阻器存算一體芯片新突破!有望促進(jìn)人工智能、自動(dòng)駕駛等領(lǐng)域發(fā)展
原文:https://mp.weixin.qq.com/s/2BbWRjpu_lreG6TEiG0XKw電子發(fā)燒友網(wǎng)報(bào)道(文/李彎彎)近日,清華大學(xué)集成電路學(xué)院教授吳華強(qiáng)、副教授高濱團(tuán)隊(duì)基于存算一體計(jì)算范式,研制出全球首顆全系統(tǒng)集成的、支持高效片上學(xué)習(xí)的憶阻器存算一體芯片,在支持片上學(xué)習(xí)的憶阻器存算一體芯片領(lǐng)域取得重大突破。該芯片包含支持完整片上學(xué)習(xí)所必需的全部電路模塊,成功完成圖像分類、語音識(shí)別和控制任務(wù)等多種片上增量學(xué)習(xí)功能驗(yàn)證,展示出高適應(yīng)性、高能效、高通用性、高準(zhǔn)確率等特點(diǎn),有效強(qiáng)化智能設(shè)備在實(shí)際應(yīng)用場景下的學(xué)習(xí)適應(yīng)能力,有望促進(jìn)人工智能、自動(dòng)駕駛、可穿戴設(shè)備等領(lǐng)域的發(fā)展。什么是憶阻器憶阻器,全稱記憶電阻器(Memristor)。它是表示磁通與電荷關(guān)系的電路器件。憶阻具有電阻的量綱,但和電阻不同的是,憶阻的阻值是由流經(jīng)它的電荷確定。因此,通過測定憶阻的阻值,便可知道流經(jīng)它的電荷量,從而有記憶電荷的作用。1971年,蔡少棠從邏輯和公理的觀點(diǎn)指出,自然界應(yīng)該還存在一個(gè)電路元件,它表示磁通與電荷的關(guān)系。2008年,惠普公司的研究人員首次做出納米憶阻器件,掀起憶阻研究熱潮。納米憶阻器件的出現(xiàn),有望實(shí)現(xiàn)非易失性隨機(jī)存儲(chǔ)器。并且,基于憶阻的隨機(jī)存儲(chǔ)器的集成度、功耗、讀寫速度都要比傳統(tǒng)的隨機(jī)存儲(chǔ)器優(yōu)越。此外,憶阻是硬件實(shí)現(xiàn)人工神經(jīng)網(wǎng)絡(luò)突觸的最好方式。2012年,比勒菲爾德大學(xué)托馬斯博士及其同事制作出一種具有學(xué)習(xí)能力的憶阻器。2013年,安迪·托馬斯利用這種憶阻器作為人工大腦的關(guān)鍵部件,他的研究結(jié)果發(fā)表在《物理學(xué)學(xué)報(bào)D輯:應(yīng)用物理學(xué)》雜志上。安迪·托馬斯解釋說,因?yàn)閼涀杵髋c突觸的這種相似性,使其成為制造人工大腦——從而打造出新一代電腦——的絕佳材料,“它使我們得以建造極為節(jié)能、耐用,同時(shí)能夠自學(xué)的處理器。”托馬斯的文章總結(jié)了自己的實(shí)驗(yàn)結(jié)果,并借鑒其他生物學(xué)和物理學(xué)研究的成果,首次闡述了這種仿神經(jīng)系統(tǒng)的電腦如何將自然現(xiàn)象轉(zhuǎn)化為技術(shù)系統(tǒng),及其中應(yīng)該遵循的幾個(gè)原則。這些原則包括,憶阻器應(yīng)像突觸一樣,“注意”到之前的電子脈沖;而且只有當(dāng)刺激脈沖超過一定的量時(shí),神經(jīng)元才會(huì)做出反應(yīng),憶阻器也是如此。在國內(nèi),錢鶴、吳華強(qiáng)團(tuán)隊(duì)2012年開始研究用憶阻器來做存儲(chǔ),但由于憶阻器的材料器件優(yōu)化和集成工藝不成熟,團(tuán)隊(duì)只能靠自己在實(shí)驗(yàn)室里摸索,在一次次失敗的實(shí)驗(yàn)中探索提高器件的一致性和良率。兩年后,清華大學(xué)與中科院微電子所、北京大學(xué)等單位合作,優(yōu)化憶阻器的器件工藝,制備出高性能憶阻器陣列,成為我國率先實(shí)現(xiàn)憶阻器陣列大規(guī)模集成的重要基礎(chǔ)。基于憶阻器的新型存算一體架構(gòu)近些年,隨著人工智能應(yīng)用對(duì)計(jì)算和存儲(chǔ)需求的不斷提升,集成電路芯片技術(shù)面臨諸多新挑戰(zhàn)。一方面,摩爾定律“漸行漸遠(yuǎn)”,通過集成電路工藝微縮的方式獲得算力提升越來越難;另一方面,計(jì)算與存儲(chǔ)在不同電路單元中完成,會(huì)造成大量數(shù)據(jù)搬運(yùn)的功耗,增加延遲。如何用計(jì)算存儲(chǔ)一體化突破AI算力瓶頸,成為近年來國內(nèi)外的科研熱點(diǎn)。過去很多年里,學(xué)術(shù)界和產(chǎn)業(yè)界探索了多種用于實(shí)現(xiàn)存算一體的硬件,憶阻器被認(rèn)為是極具前景的器件之一。吳華強(qiáng)教授此前談到,基于憶阻器的新型存算一體架構(gòu),可以打破算力瓶頸,滿足人工智能等復(fù)雜任務(wù)對(duì)計(jì)算硬件的高需求。不過,想讓憶阻器陣列實(shí)現(xiàn)芯片的功能,還需解決器件、系統(tǒng)、算法等方面的瓶頸。吳華強(qiáng)表示,憶阻器固有的非理想特性,例如器件間波動(dòng)、器件電導(dǎo)卡滯、電導(dǎo)狀態(tài)漂移等,會(huì)導(dǎo)致計(jì)算準(zhǔn)確率降低;此外,在架構(gòu)方面,憶阻器陣列實(shí)現(xiàn)卷積功能需要以串行滑動(dòng)的方式連續(xù)采樣、計(jì)算多個(gè)輸入塊,無法匹配全連接結(jié)構(gòu)的計(jì)算效率。從最新的研究成果來看,吳華強(qiáng)團(tuán)隊(duì)似乎解決了這些困難。該團(tuán)隊(duì)創(chuàng)新設(shè)計(jì)出適用于憶阻器存算一體的高效片上學(xué)習(xí)的新型通用算法和架構(gòu),研制出全球首顆全系統(tǒng)集成的、支持高效片上學(xué)習(xí)的憶阻器存算一體芯片。相同任務(wù)下,該芯片實(shí)現(xiàn)片上學(xué)習(xí)的能耗僅為先進(jìn)工藝下專用集成電路(ASIC)系統(tǒng)的3%,展現(xiàn)出卓越的能效優(yōu)勢(shì),極具滿足人工智能時(shí)代高算力需求的應(yīng)用潛力,為突破馮·諾依曼傳統(tǒng)計(jì)算架構(gòu)下的能效瓶頸提供了一種創(chuàng)新發(fā)展路徑。吳華強(qiáng)介紹,存算一體片上學(xué)習(xí)在實(shí)現(xiàn)更低延遲和更低能耗的同時(shí),能夠有效保護(hù)用戶隱私和數(shù)據(jù)。該芯片參照仿生類腦處理方式,可實(shí)現(xiàn)不同任務(wù)的快速“片上訓(xùn)練”與“片上識(shí)別”,能夠有效完成邊緣計(jì)算場景下的增量學(xué)習(xí)任務(wù),以極低的耗電適應(yīng)新場景、學(xué)習(xí)新知識(shí),滿足用戶的個(gè)性化需求。小結(jié)近幾年,人工智能技術(shù)的發(fā)展對(duì)算力的需求越來越高,同時(shí)傳統(tǒng)計(jì)算架構(gòu)的瓶頸也越來越明顯,學(xué)術(shù)界和產(chǎn)業(yè)界都在積極探索新的發(fā)展模式來解決這一問題,存算一體技術(shù)憑借突出的能效比優(yōu)勢(shì)脫穎而出。而在實(shí)現(xiàn)存算一體的各類器件中,憶阻器的先天優(yōu)勢(shì)明顯。此次清華大學(xué)研制出支持片上學(xué)習(xí)的憶阻器存算一體芯片,意義重大。
5. 美國AI芯片出口管制再升級(jí),A800/H800禁止對(duì)大陸出口,國產(chǎn)GPU發(fā)展勢(shì)在必行!
原文:https://mp.weixin.qq.com/s/1snqc5TKjPajcUz4ELIO6w10月17日,美國商務(wù)部工業(yè)與安全局(BIS)發(fā)布更新針對(duì)人工智能(AI)芯片的出口管制規(guī)定。該計(jì)劃不僅限制英偉達(dá)等公司向中國出口先進(jìn)的AI芯片,還可能阻礙ASML、應(yīng)用材料、泛林和KLA等向中國銷售和出口半導(dǎo)體制造設(shè)備。與此同時(shí),BIS周二還在《聯(lián)邦公報(bào)》刊登了一份定于10月19日發(fā)布的行政措施,準(zhǔn)備將13家中國公司添加到出口管制名單,即所謂的“實(shí)體清單”。其中包括北京壁仞科技開發(fā)有限公司、摩爾線程智能科技(北京)有限責(zé)任公司兩家中國GPU企業(yè)。英偉達(dá)A100 / A800 / H100 / H800 / L40 / L40S / RTX 4090等產(chǎn)品都將受限美國商務(wù)部長吉娜·雷蒙多(Gina Raimondo)稱,新措施填補(bǔ)了去年10月發(fā)布法規(guī)中的漏洞,并表示這些措施未來可能至少每年更新一次。她表示,美國限制的目標(biāo)是阻止中國獲得先進(jìn)的半導(dǎo)體,這些半導(dǎo)體可能推動(dòng)中國人工智能和精密計(jì)算機(jī)的突破。去年10月,美國對(duì)出口中國的AI芯片實(shí)施帶寬速率限制。根據(jù)當(dāng)時(shí)英偉達(dá)發(fā)布的公告,美國通知該公司向中國出口A100和H100芯片將需要新的許可證要求,同時(shí)DGX或任何其他包含A100或H100芯片的產(chǎn)品,以及未來性能高于A100的芯片都將受到新規(guī)管制。A100是英偉達(dá)2020年推出的數(shù)據(jù)中心級(jí)云端加速芯片,支持FP16、FP32和FP64浮點(diǎn)運(yùn)算,為人工智能、數(shù)據(jù)分析和HPC數(shù)據(jù)中心等提供算力。H100是英偉達(dá)2022年推出的最新一代數(shù)據(jù)中心GPU,H100在FP16、FP32和FP64計(jì)算上比A100快三倍,非常適用于當(dāng)下流行且訓(xùn)練難度高的大模型。當(dāng)時(shí)國內(nèi)高端場景基本采用英偉達(dá)的A100,不少主流廠商也預(yù)定了計(jì)劃在2022年下半年發(fā)貨的H100。然而美國政府去年10月發(fā)布的法規(guī),讓這些廠商在一些高端應(yīng)用上面臨無合適芯片可用的局面。不過之后,英偉達(dá)向中國企業(yè)提供了替代版本A800和H800,用以解決美國商務(wù)部的半導(dǎo)體出口新規(guī)。根據(jù)美國商務(wù)部去年10月的發(fā)布的法規(guī),主要限制的是顯卡的算力和帶寬,算力上線是4800 TOPS,帶寬上線是600 GB/s。英偉達(dá)新發(fā)布的A800的帶寬為400GB/s,低于A100的600GB/s,H800雖然參數(shù)未公布,但據(jù)透露只約到H100(900 GB/s)的一半。這意味著A800、H800在進(jìn)行AI模型訓(xùn)練的時(shí)候,需要耗費(fèi)更長的時(shí)間,不過相對(duì)來說,也已經(jīng)很好了。然而,盡管A800、H800對(duì)關(guān)鍵性能進(jìn)行了大幅限制。但美國政府認(rèn)為,H800在某些情況下算力仍然不亞于H100。為了進(jìn)一步加強(qiáng)對(duì)AI芯片的出口管制,美國計(jì)劃用多項(xiàng)新的標(biāo)準(zhǔn)來替換掉之前針對(duì)“帶寬參數(shù)”(Bandwidth Parameter)提出的限制,盡管這已經(jīng)大大降低了AI芯片之間的通信速率,增加了AI開發(fā)的難度和成本。根據(jù)新規(guī),美國商務(wù)部計(jì)劃引入一項(xiàng)被稱為“性能密度”(performance density)的參數(shù),來防止企業(yè)尋找到變通的方案,修訂后的出口管制措施將禁止美國企業(yè)向中國出售運(yùn)行速度達(dá)到300 teraflops(即每秒可計(jì)算 3億次運(yùn)算)及以上的數(shù)據(jù)中心芯片。新措施還旨在防止企業(yè)通過Chiplet的芯片堆疊技術(shù)繞過芯片限制。針對(duì)美國政府此次發(fā)布的新規(guī),英偉達(dá)公司依規(guī)發(fā)布了8-K文件,對(duì)出口管制做出了解釋。英偉達(dá)稱,此次出口管制涉及的產(chǎn)品包括但不限于:A100、A800、H100、H800、L40、L40S 以及RTX 4090。任何集成了一個(gè)或多個(gè)以上芯片的系統(tǒng),包括但不限于英偉達(dá)DGX、HGX系統(tǒng),也在新規(guī)涵蓋范圍之內(nèi)。此外,美國政府還將要求企業(yè)獲得向40多個(gè)國家/地區(qū)出售芯片的許可證,以防止中國企業(yè)從海外其他國家和地區(qū)獲得先進(jìn)芯片。美國政府還對(duì)中國以外的21個(gè)國家提出了芯片制造設(shè)備的許可要求,并擴(kuò)大了禁止進(jìn)入這些國家和地區(qū)的設(shè)備清單。同時(shí),美國還將13家中國公司添加到出口管制名單,其中,壁仞科技、摩爾線程兩家GPU企業(yè)在列。發(fā)展國產(chǎn)GPU等大算力芯片勢(shì)在必行美國政府此次對(duì)人工智能芯片的出口管制升級(jí),對(duì)中國相關(guān)產(chǎn)業(yè)發(fā)展有何影響?中國主要的互聯(lián)網(wǎng)大廠、云服務(wù)廠商基本都依賴英偉達(dá)的GPU。尤其是近年來隨著ChatGPT的出圈,國內(nèi)各大互聯(lián)網(wǎng)公司、AI企業(yè)都在大力自研AI大模型產(chǎn)品,這更是加大了對(duì)英偉達(dá)GPU的需求。由于去年A100就已經(jīng)被禁,今年上半年各大互聯(lián)網(wǎng)廠商都在爭相采購A800。不過從目前的情況來看,新規(guī)對(duì)各大廠商短期的影響倒是不明顯。多家廠商對(duì)媒體表示,已經(jīng)提前接到消息,不少廠商已經(jīng)預(yù)先進(jìn)行囤貨。一家服務(wù)器廠商的內(nèi)部人士表示,公司囤了足夠的量。騰訊、百度等大廠也囤貨充足。一家上市公司17日晚間發(fā)布公告稱,其控股子公司向其供應(yīng)商采購了75臺(tái)H800及22臺(tái)A800現(xiàn)貨。該公司對(duì)媒體表示,已經(jīng)在兩周前就解決了這個(gè)問題。國內(nèi)一些大模型創(chuàng)業(yè)企業(yè)也已經(jīng)提前做了準(zhǔn)備,比如智譜AI,該公司表示公司囤貨充足。不過依靠囤貨畢竟不是長久之計(jì),有廠商表示,雖然吞了足夠的量,不過未來還是有很大壓力。美國此次新規(guī)的發(fā)布意味著其對(duì)我國算力的進(jìn)一步遏制,這對(duì)如今備受重視的大模型的發(fā)展也將會(huì)有所限制。從長遠(yuǎn)來看,國產(chǎn)GPU等大算力芯片的發(fā)展才是關(guān)鍵。事實(shí)上,過去這些年美國不斷升級(jí)出口管制,國內(nèi)企業(yè)已經(jīng)逐步傾向于采用***,國內(nèi)的芯片企業(yè)也在政策的支持下,下游企業(yè)更多的采用下,技術(shù)和產(chǎn)品也得到更多迭代,發(fā)展越來越好。比如,智譜AI雖然屯了足夠的芯片,同時(shí)它也為配合國產(chǎn)GPU發(fā)展,同步落地GLM(通用語言模型)***適配計(jì)劃,可適配10余種***等。當(dāng)前,國內(nèi)已經(jīng)有一些芯片可以支持大模型的訓(xùn)練和推理,長此發(fā)展下去,未來的性能、生態(tài)也一定會(huì)越來越成熟。從美國此次新規(guī)將壁仞科技、摩爾線程等公司列入實(shí)體清單,可以看出美國對(duì)中國GPU芯片快速發(fā)展的擔(dān)憂。當(dāng)然這也意味著,未來中國大算力芯片的進(jìn)一步突破,也將面臨著更大的困難,這需要設(shè)備、制造等產(chǎn)業(yè)鏈各環(huán)節(jié)的同步升級(jí)。小結(jié)為了阻止中國先進(jìn)技術(shù)的發(fā)展,美國無休止的實(shí)施出口管制。這確實(shí)在短期內(nèi)阻礙了一些企業(yè)的發(fā)展,不過從過去幾年的情況來看,美國的出口限制,也進(jìn)一步促進(jìn)了中國芯片產(chǎn)業(yè)的發(fā)展。未來,中國企業(yè)也同樣會(huì)不斷進(jìn)行探索,以應(yīng)對(duì)美方的打壓。除了對(duì)中國企業(yè)造成影響之外,美方不當(dāng)管制嚴(yán)重阻礙了各國芯片及芯片設(shè)備、材料、零部件企業(yè)正常經(jīng)貿(mào)往來,嚴(yán)重破壞了市場規(guī)則和國際經(jīng)貿(mào)秩序,威脅到全球產(chǎn)業(yè)鏈供應(yīng)鏈穩(wěn)定。美國自己的企業(yè)也損失巨大,比如英偉達(dá),雖然該公司表示短期內(nèi)財(cái)務(wù)業(yè)務(wù)新規(guī)影響較小,但是要知道其接近50%的收入來自中國,此次新規(guī)將幾乎阻斷英偉達(dá)大部分中國業(yè)務(wù)的開展。除此之外,因?yàn)槊绹牟划?dāng)管制,其他國家的半導(dǎo)體企業(yè)也深受其害。
6. 超火迷你GPT-4視覺能力暴漲,GitHub兩萬星,華人團(tuán)隊(duì)出品
原文:https://mp.weixin.qq.com/s/nG3otCtN1mwSHKXEw-0vxwGPT-4V來做目標(biāo)檢測?網(wǎng)友實(shí)測:還沒有準(zhǔn)備好。
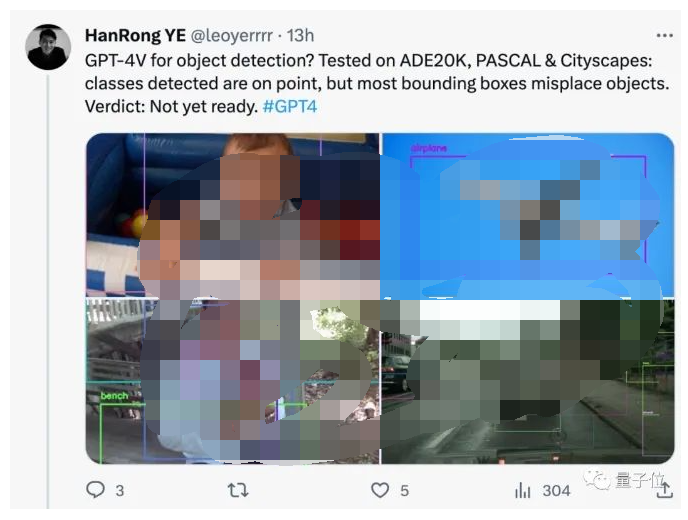 雖然檢測到的類別沒問題,但大多數(shù)邊界框都錯(cuò)放了。沒關(guān)系,有人會(huì)出手!那個(gè)搶跑GPT-4看圖能力幾個(gè)月的迷你GPT-4升級(jí)啦——MiniGPT-v2。
雖然檢測到的類別沒問題,但大多數(shù)邊界框都錯(cuò)放了。沒關(guān)系,有人會(huì)出手!那個(gè)搶跑GPT-4看圖能力幾個(gè)月的迷你GPT-4升級(jí)啦——MiniGPT-v2。 而且只是一句簡單指令:[grounding] describe this image in detail就實(shí)現(xiàn)的結(jié)果。不僅如此,還輕松處理各類視覺任務(wù)。圈出一個(gè)物體,提示詞前面加個(gè) [identify] 可讓模型直接識(shí)別出來物體的名字。
而且只是一句簡單指令:[grounding] describe this image in detail就實(shí)現(xiàn)的結(jié)果。不僅如此,還輕松處理各類視覺任務(wù)。圈出一個(gè)物體,提示詞前面加個(gè) [identify] 可讓模型直接識(shí)別出來物體的名字。 當(dāng)然也可以什么都不加,直接問~
當(dāng)然也可以什么都不加,直接問~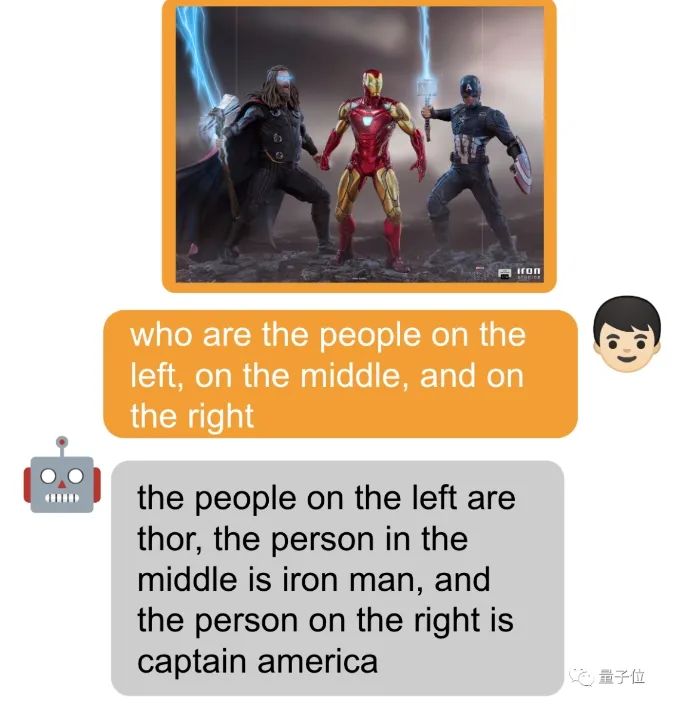 MiniGPT-v2由來自MiniGPT-4的原班人馬(KAUST沙特阿卜杜拉國王科技大學(xué))以及Meta的五位研究員共同開發(fā)。
MiniGPT-v2由來自MiniGPT-4的原班人馬(KAUST沙特阿卜杜拉國王科技大學(xué))以及Meta的五位研究員共同開發(fā)。 上次MiniGPT-4剛出來就引發(fā)巨大關(guān)注,一時(shí)間服務(wù)器被擠爆,如今GItHub項(xiàng)目已超22000+星。
上次MiniGPT-4剛出來就引發(fā)巨大關(guān)注,一時(shí)間服務(wù)器被擠爆,如今GItHub項(xiàng)目已超22000+星。 此番升級(jí),已經(jīng)有網(wǎng)友開始用上了~
此番升級(jí),已經(jīng)有網(wǎng)友開始用上了~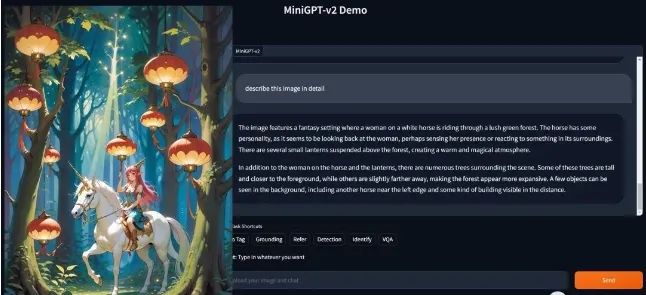 多視覺任務(wù)的通用界面大模型作為各文本應(yīng)用的通用界面,大家已經(jīng)司空見慣了。受此靈感,研究團(tuán)隊(duì)想要建立一個(gè)可用于多種視覺任務(wù)的統(tǒng)一界面,比如圖像描述、視覺問題解答等。
多視覺任務(wù)的通用界面大模型作為各文本應(yīng)用的通用界面,大家已經(jīng)司空見慣了。受此靈感,研究團(tuán)隊(duì)想要建立一個(gè)可用于多種視覺任務(wù)的統(tǒng)一界面,比如圖像描述、視覺問題解答等。 「如何在單一模型的條件下,使用簡單多模態(tài)指令來高效完成各類任務(wù)?」成為團(tuán)隊(duì)需要解決的難題。簡單來說,MiniGPT-v2由三個(gè)部分組成:視覺主干、線性層和大型語言模型。
「如何在單一模型的條件下,使用簡單多模態(tài)指令來高效完成各類任務(wù)?」成為團(tuán)隊(duì)需要解決的難題。簡單來說,MiniGPT-v2由三個(gè)部分組成:視覺主干、線性層和大型語言模型。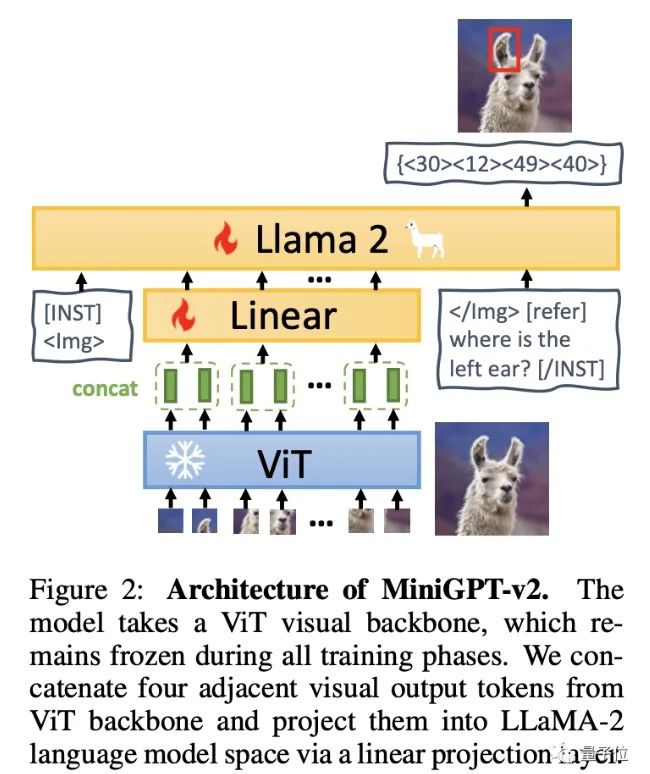 該模型以ViT視覺主干為基礎(chǔ),所有訓(xùn)練階段都保持不變。從ViT中歸納出四個(gè)相鄰的視覺輸出標(biāo)記,并通過線性層將它們投影到 LLaMA-2語言模型空間中。團(tuán)隊(duì)建議在訓(xùn)練模型為不同任務(wù)使用獨(dú)特的標(biāo)識(shí)符,這樣一來大模型就能輕松分辨出每個(gè)任務(wù)指令,還能提高每個(gè)任務(wù)的學(xué)習(xí)效率。訓(xùn)練主要分為三個(gè)階段:預(yù)訓(xùn)練——多任務(wù)訓(xùn)練——多模式指令調(diào)整。
該模型以ViT視覺主干為基礎(chǔ),所有訓(xùn)練階段都保持不變。從ViT中歸納出四個(gè)相鄰的視覺輸出標(biāo)記,并通過線性層將它們投影到 LLaMA-2語言模型空間中。團(tuán)隊(duì)建議在訓(xùn)練模型為不同任務(wù)使用獨(dú)特的標(biāo)識(shí)符,這樣一來大模型就能輕松分辨出每個(gè)任務(wù)指令,還能提高每個(gè)任務(wù)的學(xué)習(xí)效率。訓(xùn)練主要分為三個(gè)階段:預(yù)訓(xùn)練——多任務(wù)訓(xùn)練——多模式指令調(diào)整。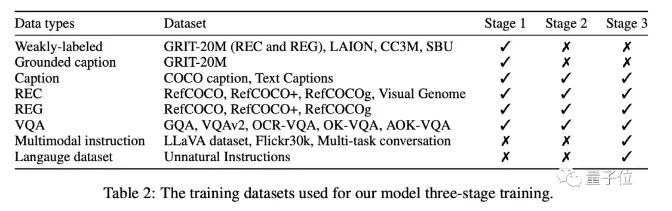 最終,MiniGPT-v2 在許多視覺問題解答和視覺接地基準(zhǔn)測試中,成績都優(yōu)于其他視覺語言通用模型。
最終,MiniGPT-v2 在許多視覺問題解答和視覺接地基準(zhǔn)測試中,成績都優(yōu)于其他視覺語言通用模型。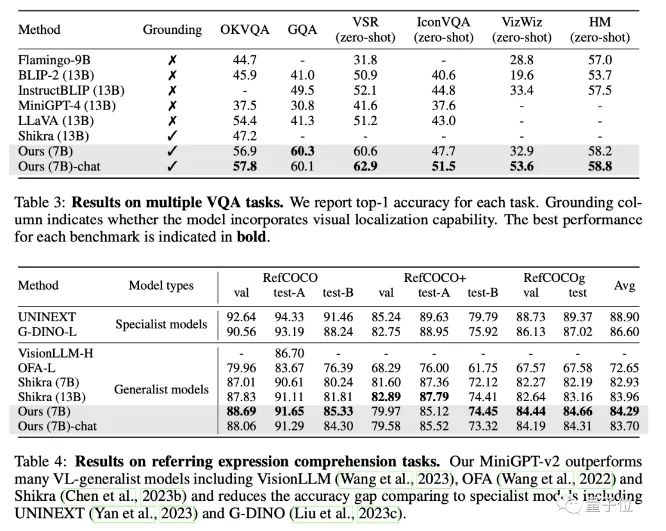 最終這個(gè)模型可以完成多種視覺任務(wù),比如目標(biāo)對(duì)象描述、視覺定位、圖像說明、視覺問題解答以及從給定的輸入文本中直接解析圖片對(duì)象。
最終這個(gè)模型可以完成多種視覺任務(wù),比如目標(biāo)對(duì)象描述、視覺定位、圖像說明、視覺問題解答以及從給定的輸入文本中直接解析圖片對(duì)象。 感興趣的朋友,可戳下方Demo鏈接體驗(yàn):https://minigpt-v2.github.io/https://huggingface.co/spaces/Vision-CAIR/MiniGPT-v2論文鏈接:https://arxiv.o?rg/abs/2310.09478GitHub鏈接:https://github.com/Vision-CAIR/MiniGPT-4參考鏈接:https://twitter.com/leoyerrrr
感興趣的朋友,可戳下方Demo鏈接體驗(yàn):https://minigpt-v2.github.io/https://huggingface.co/spaces/Vision-CAIR/MiniGPT-v2論文鏈接:https://arxiv.o?rg/abs/2310.09478GitHub鏈接:https://github.com/Vision-CAIR/MiniGPT-4參考鏈接:https://twitter.com/leoyerrrr
———————End———————
點(diǎn)擊閱讀原文進(jìn)入官網(wǎng)
原文標(biāo)題:【AI簡報(bào)20231020期】出自華人之手:DALL-E 3論文公布、上線ChatGPT!超火迷你GPT-4
文章出處:【微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
RT-Thread
+關(guān)注
關(guān)注
31文章
1285瀏覽量
40095
原文標(biāo)題:【AI簡報(bào)20231020期】出自華人之手:DALL-E 3論文公布、上線ChatGPT!超火迷你GPT-4
文章出處:【微信號(hào):RTThread,微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Llama 3 與 GPT-4 比較
OpenAI推出新模型CriticGPT,用GPT-4自我糾錯(cuò)
OpenAI API Key獲取:開發(fā)人員申請(qǐng)GPT-4 API Key教程
國內(nèi)直聯(lián)使用ChatGPT 4.0 API Key使用和多模態(tài)GPT4o API調(diào)用開發(fā)教程!

OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
OpenAI推出面向所有用戶的AI模型GPT-4o
OpenAI全新GPT-4o能力炸場!速度快/成本低,能讀懂人類情緒
OpenAI計(jì)劃宣布ChatGPT和GPT-4更新
微軟Copilot全面更新為OpenAI的GPT-4 Turbo模型
新火種AI|秒殺GPT-4,狙殺GPT-5,橫空出世的Claude 3振奮人心!

OpenAI推出ChatGPT新功能:朗讀,支持37種語言,兼容GPT-4和GPT-3
全球最強(qiáng)大模型易主,GPT-4被超越
Anthropic推出Claude 3系列模型,全面超越GPT-4,樹立AI新標(biāo)桿
微軟封禁員工討論OpenAI DALL-E 3模型漏洞
微軟推出Copilot安卓應(yīng)用 類似ChatGPT功能





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論