") LLaMA2上下文長度暴漲至100萬tokens,只需調(diào)整1個超參數(shù)
LLaMA2上下文長度暴漲至100萬tokens,只需調(diào)整1個超參數(shù)
只需微調(diào)一下,大模型支持上下文大小就能從1.6萬tokens延長至100萬?!
還是在只有70億參數(shù)的LLaMA 2上。
要知道,即使是當前最火的Claude 2和GPT-4,支持上下文長度也不過10萬和3.2萬,超出這個范圍大模型就會開始胡言亂語、記不住東西。
現(xiàn)在,一項來自復旦大學和上海人工智能實驗室的新研究,不僅找到了讓一系列大模型提升上下文窗口長度的方法,還發(fā)掘出了其中的規(guī)律。

按照這個規(guī)律,只需調(diào)整1個超參數(shù),就能確保輸出效果的同時,穩(wěn)定提升大模型外推性能。
外推性,指大模型輸入長度超過預訓練文本長度時,輸出表現(xiàn)變化情況。如果外推能力不好,輸入長度一旦超過預訓練文本長度,大模型就會“胡言亂語”。
所以,它究竟能提升哪些大模型的外推能力,又是如何做到的?
大模型外推能力提升“機關”
這種提升大模型外推能力的方法,和Transformer架構中名叫位置編碼的模塊有關。
事實上,單純的注意力機制(Attention)模塊無法區(qū)分不同位置的token,例如“我吃蘋果”和“蘋果吃我”在它眼里沒有差異。
因此需要加入位置編碼,來讓它理解詞序信息,從而真正讀懂一句話的含義。
目前的Transformer位置編碼方法,有絕對位置編碼(將位置信息融入到輸入)、相對位置編碼(將位置信息寫入attention分數(shù)計算)和旋轉(zhuǎn)位置編碼幾種。其中,最火熱的要屬旋轉(zhuǎn)位置編碼,也就是RoPE了。
RoPE通過絕對位置編碼的形式,實現(xiàn)了相對位置編碼的效果,但與相對位置編碼相比,又能更好地提升大模型的外推潛力。
如何進一步激發(fā)采用RoPE位置編碼的大模型的外推能力,也成為了最近不少研究的新方向。
這些研究,又主要分為限制注意力和調(diào)整旋轉(zhuǎn)角兩大流派。
限制注意力的代表研究包括ALiBi、xPos、BCA等。最近MIT提出的StreamingLLM,可以讓大模型實現(xiàn)無限的輸入長度(但并不增加上下文窗口長度),就屬于這一方向的研究類型。
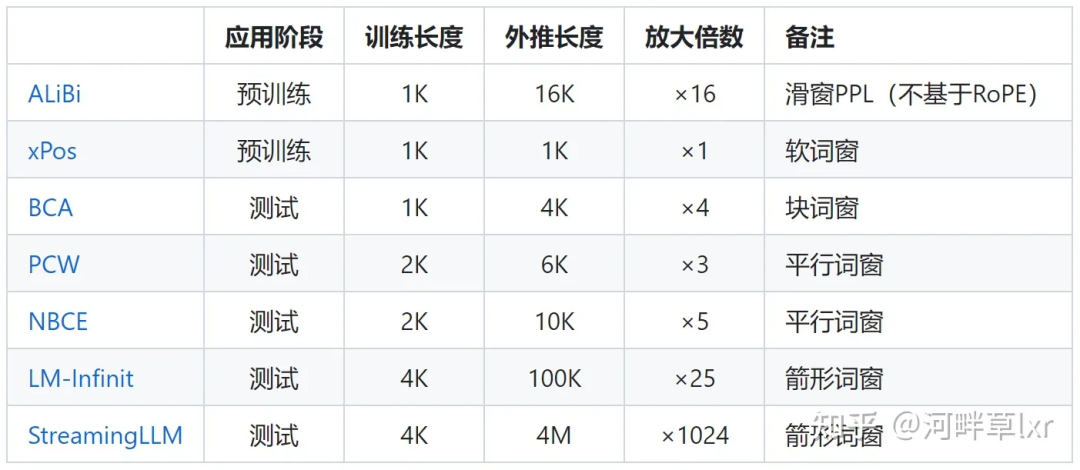
△圖源作者
調(diào)整旋轉(zhuǎn)角的工作則更多,典型代表如線性內(nèi)插、Giraffe、Code LLaMA、LLaMA2 Long等都屬于這一類型的研究。
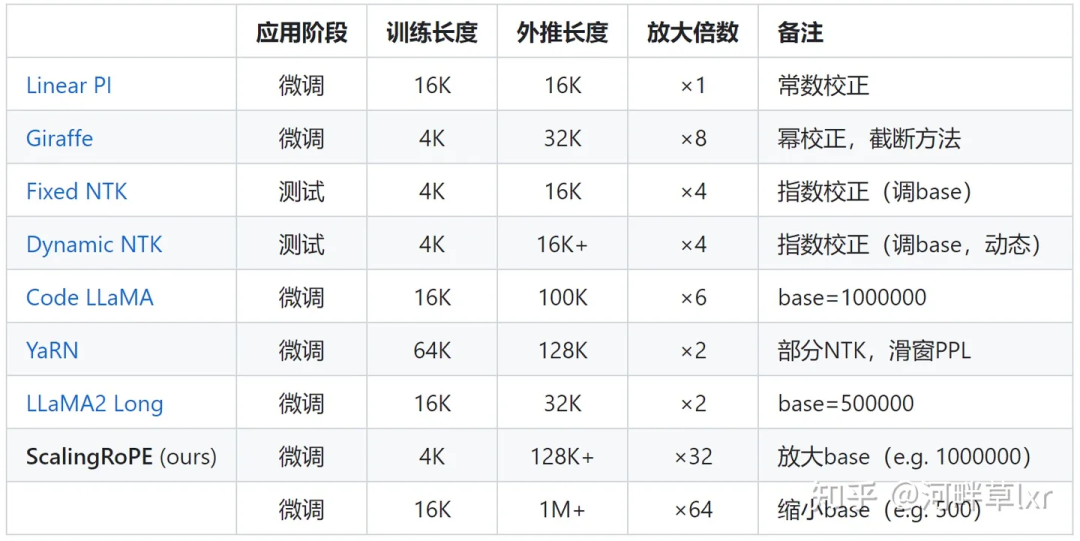
△圖源作者
以Meta最近爆火的LLaMA2 Long研究為例,它就提出了一個名叫RoPE ABF的方法,通過修改一個超參數(shù),成功將大模型的上下文長度延長到3.2萬tokens。
這個超參數(shù),正是Code LLaMA和LLaMA2 Long等研究找出的“開關”——
旋轉(zhuǎn)角底數(shù)(base)。
只需要微調(diào)它,就可以確保提升大模型的外推表現(xiàn)。
但無論是Code LLaMA還是LLaMA2 Long,都只是在特定的base和續(xù)訓長度上進行微調(diào),使得其外推能力增強。
是否能找到一種規(guī)律,確保所有用了RoPE位置編碼的大模型,都能穩(wěn)定提升外推表現(xiàn)?
掌握這個規(guī)律,上下文輕松100w+
來自復旦大學和上海AI研究院的研究人員,針對這一問題進行了實驗。
他們先是分析了影響RoPE外推能力的幾種參數(shù),提出了一種名叫臨界維度(Critical Dimension)的概念,隨后基于這一概念,總結(jié)出了一套RoPE外推的縮放法則(Scaling Laws of RoPE-based Extrapolation)。
只需要應用這個規(guī)律,就能確保任意基于RoPE位置編碼大模型都能改善外推能力。
先來看看臨界維度是什么。
從定義中來看,它和預訓練文本長度Ttrain、自注意力頭維度數(shù)量d等參數(shù)都有關系,具體計算方法如下:

其中,10000即超參數(shù)、旋轉(zhuǎn)角底數(shù)base的“初始值”。
作者發(fā)現(xiàn),無論放大還是縮小base,最終都能讓基于RoPE的大模型的外推能力得到增強,相比之下當旋轉(zhuǎn)角底數(shù)為10000時,大模型外推能力是最差的。
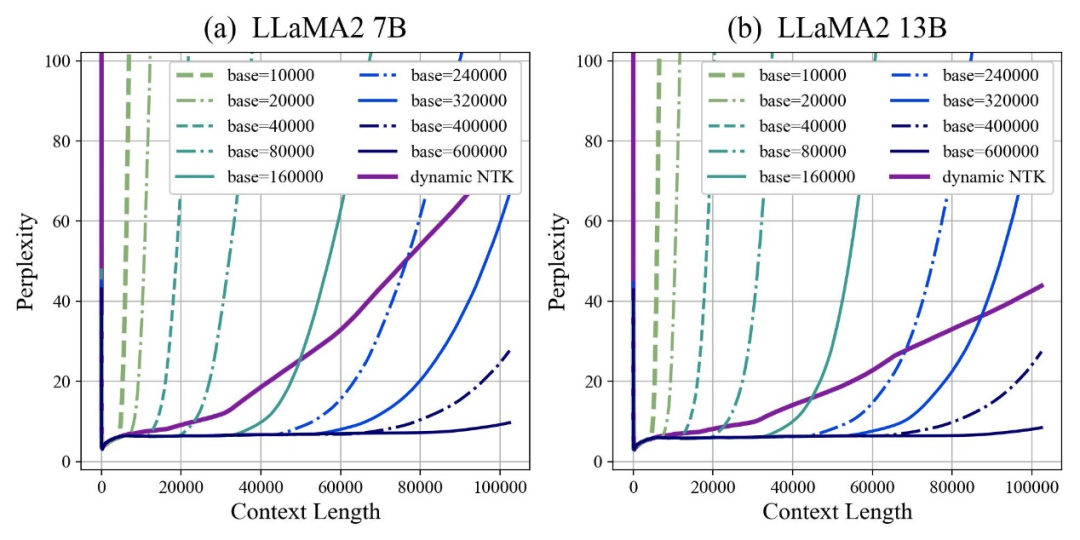
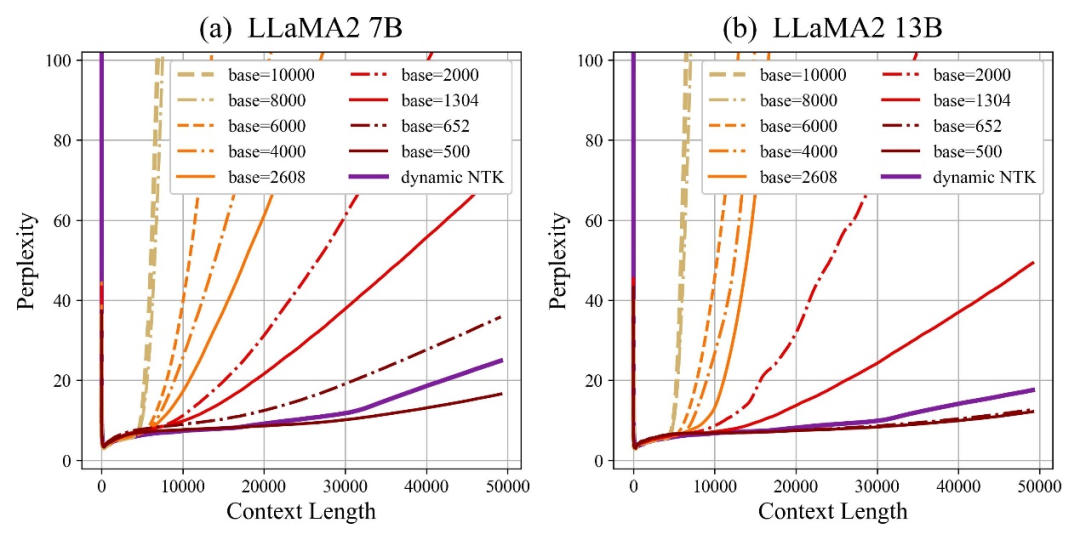
對此論文認為,旋轉(zhuǎn)角底數(shù)更小,能讓更多的維度感知到位置信息,旋轉(zhuǎn)角底數(shù)更大,則能表示出更長的位置信息。
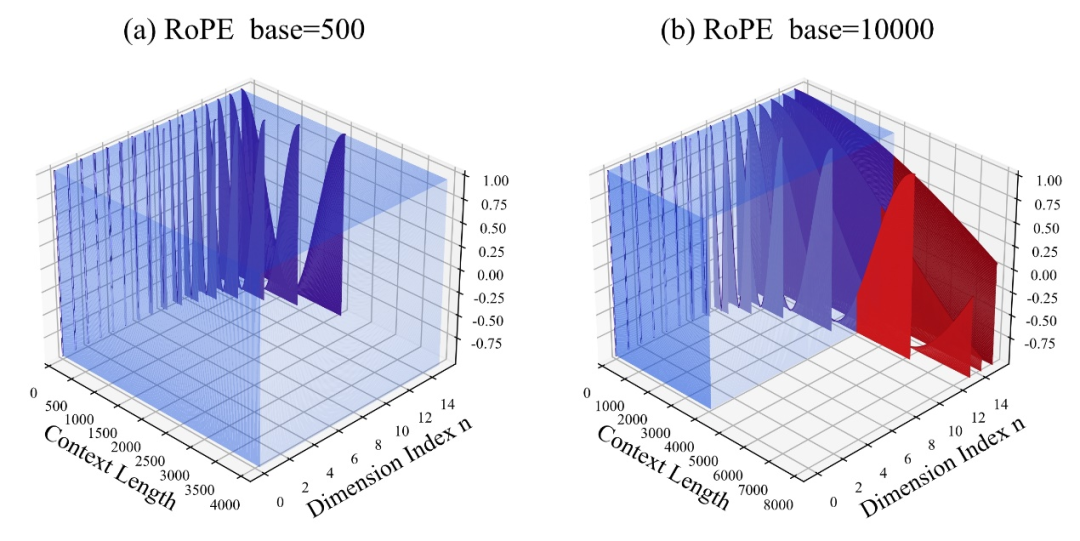
既然如此,在面對不同長度的續(xù)訓語料時,究竟縮小和放大多少旋轉(zhuǎn)角底數(shù),才能確保大模型外推能力得到最大程度上的提升?
論文給出了一個擴展RoPE外推的縮放法則,與臨界維度、大模型的續(xù)訓文本長度和預訓練文本長度等參數(shù)有關:

基于這一規(guī)律,可以根據(jù)不同預訓練和續(xù)訓文本長度,來直接計算出大模型的外推表現(xiàn),換言之就是預測大模型的支持的上下文長度。
反之利用這一法則,也能快速推導出如何最好地調(diào)整旋轉(zhuǎn)角底數(shù),從而提升大模型外推表現(xiàn)。
作者針對這一系列任務進行了測試,發(fā)現(xiàn)實驗上目前輸入10萬、50萬甚至100萬tokens長度,都可以保證,無需額外注意力限制即可實現(xiàn)外推。
與此同時,包括Code LLaMA和LLaMA2 Long在內(nèi)的大模型外推能力增強工作都證明了這一規(guī)律是確實合理有效的。
這樣一來,只需要根據(jù)這個規(guī)律“調(diào)個參”,就能輕松擴展基于RoPE的大模型上下文窗口長度、增強外推能力了。
論文一作柳瀟然表示,目前這項研究還在通過改進續(xù)訓語料,提升下游任務效果,等完成之后就會將代碼和模型開源,可以期待一下~
-
參數(shù)
+關注
關注
11文章
1829瀏覽量
32195 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238261 -
大模型
+關注
關注
2文章
2423瀏覽量
2643
原文標題:LLaMA2上下文長度暴漲至100萬tokens,只需調(diào)整1個超參數(shù)|復旦邱錫鵬團隊出品
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
關于進程上下文、中斷上下文及原子上下文的一些概念理解
進程上下文與中斷上下文的理解
中斷中的上下文切換詳解
基于多Agent的用戶上下文自適應站點構架
基于交互上下文的預測方法
終端業(yè)務上下文的定義方法及業(yè)務模型
基于Pocket PC的上下文菜單實現(xiàn)
基于Pocket PC的上下文菜單實現(xiàn)
基于上下文相似度的分解推薦算法
Web服務的上下文的訪問控制策略模型
初學OpenGL:什么是繪制上下文
如何分析Linux CPU上下文切換問題
在線研討會 | 基于 LLM 構建中文場景檢索式對話機器人:Llama2 + NeMo






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論