


今天向大家介紹一個(gè)新的開(kāi)源大語(yǔ)言模型——LLEMMA,這是一個(gè)專為數(shù)學(xué)研究而設(shè)計(jì)的前沿語(yǔ)言模型。

LLEMMA解數(shù)學(xué)題的一個(gè)示例
LLEMMA的誕生源于在Proof-Pile-2數(shù)據(jù)集上對(duì)Code Llama模型的深度訓(xùn)練。這個(gè)數(shù)據(jù)集是一個(gè)科學(xué)論文、數(shù)學(xué)相關(guān)網(wǎng)頁(yè)和數(shù)學(xué)代碼的綜合體。
過(guò)去雖然有數(shù)學(xué)專用的模型,但許多模型都有各種限制。例如,有的模型是封閉訪問(wèn),這使得它們無(wú)法為更廣泛的研究所用。有的則技術(shù)上稍顯落后。
但LLEMMA的出現(xiàn)改變了這一局面。它不僅在MATH基準(zhǔn)測(cè)試上創(chuàng)下了新高,甚至超越了某些還未對(duì)外公開(kāi)的頂尖模型,如Minerva。更讓人欣喜的是,LLEMMA無(wú)需額外的調(diào)整,即可直接應(yīng)用于工具和定理證明。
讓我們一起了解下這個(gè)模型背后的技術(shù)吧!

Paper:Llemma: An Open Language Model For Mathematics
Link:https://arxiv.org/pdf/2310.10631.pdf
Code:https://github.com/EleutherAI/math-lm
->輔導(dǎo)界的小米帶你沖刺ACL2024
數(shù)據(jù)集
LLEMMA是專為數(shù)學(xué)設(shè)計(jì)的大型語(yǔ)言模型,具有70億和340億參數(shù)。這一模型的訓(xùn)練方法是在Proof-Pile-2.2.1數(shù)據(jù)集上繼續(xù)對(duì)Code Llama模型進(jìn)行預(yù)訓(xùn)練。以下是關(guān)于該數(shù)據(jù)集的簡(jiǎn)要說(shuō)明:
Proof-Pile-2:這是一個(gè)包含550億令牌的綜合數(shù)據(jù)集,融合了科學(xué)論文、數(shù)學(xué)相關(guān)的網(wǎng)絡(luò)內(nèi)容和數(shù)學(xué)代碼,其知識(shí)截止于2023年4月(不包括特定的Lean證明步驟子集)。
代碼:為了適應(yīng)數(shù)學(xué)家日益重視的計(jì)算工具,如數(shù)值模擬和計(jì)算代數(shù)系統(tǒng),研究團(tuán)隊(duì)創(chuàng)建了名為AlgebraicStack的源代碼數(shù)據(jù)集。這個(gè)數(shù)據(jù)集涉及17種編程語(yǔ)言,包括數(shù)值、符號(hào)和正式的數(shù)學(xué)內(nèi)容,共計(jì)110億令牌。
網(wǎng)絡(luò)數(shù)據(jù):研究團(tuán)隊(duì)利用了OpenWebMath數(shù)據(jù)集,這是一個(gè)精選的、與數(shù)學(xué)相關(guān)的高質(zhì)量網(wǎng)絡(luò)頁(yè)面集合,總計(jì)150億令牌。
科學(xué)論文:使用了名為RedPajama的ArXiv子集,其中包含290億令牌。
通用自然語(yǔ)言和代碼數(shù)據(jù):作為訓(xùn)練數(shù)據(jù)的補(bǔ)充,研究團(tuán)隊(duì)還融合了一些通用領(lǐng)域的數(shù)據(jù),并以Proof-Pile-2為主,還融合了Pile數(shù)據(jù)集和RedPajama的GitHub子集。
模型訓(xùn)練
模型初始化:所有模型都從Code Llama初始化,隨后在Proof-Pile-2上接受更多的訓(xùn)練。
訓(xùn)練量:
LLEMMA 7B:2000億令牌的訓(xùn)練。
LLEMMA 34B:500億令牌的訓(xùn)練。
訓(xùn)練工具和硬件:使用GPT-NeoX庫(kù)在256個(gè)A100 40GB GPU上進(jìn)行訓(xùn)練。使用了各種先進(jìn)技術(shù)如Tensor并行、ZeRO Stage 1分片優(yōu)化器狀態(tài)、Flash Attention 2等以提高效率和減少內(nèi)存需求。
訓(xùn)練細(xì)節(jié):
LLEMMA 7B:經(jīng)過(guò)42,000步訓(xùn)練,每個(gè)全局批次有400萬(wàn)令牌,上下文長(zhǎng)度為4096令牌,占用A100大約23,000小時(shí)。學(xué)習(xí)率開(kāi)始從1 × 10^(-4)漸溫,然后逐漸減少。雖然計(jì)劃是48,000步訓(xùn)練,但在42,000步時(shí)由于NaN損失中斷了。
LLEMMA 34B:經(jīng)過(guò)12,000步訓(xùn)練,每個(gè)全局批次有400萬(wàn)令牌,上下文長(zhǎng)度為4096令牌,約占用47,000個(gè)A100小時(shí)。學(xué)習(xí)率從5 × 10^(-5)開(kāi)始逐漸增加,然后逐漸減少。
RoPE調(diào)整:在訓(xùn)練LLEMMA 7B前,RoPE的基本周期從θ = 1,000,000減少到θ = 10,000,目的是為了在LLEMMA 7B上進(jìn)行長(zhǎng)上下文微調(diào)。而LLEMMA 34B維持了θ = 1,000,000的原始設(shè)置。
實(shí)驗(yàn)設(shè)置與評(píng)估結(jié)果
作者通過(guò)少樣本評(píng)估對(duì)LLEMMA模型進(jìn)行比較,并專注于沒(méi)有進(jìn)行微調(diào)的最新模型。具體來(lái)說(shuō),他們使用了使用思維鏈推理和多數(shù)投票,在MATH和GSM8k等基準(zhǔn)上進(jìn)行了評(píng)估。
評(píng)估范圍:
數(shù)學(xué)問(wèn)題求解:測(cè)試模型在思維鏈推理和多數(shù)投票的數(shù)學(xué)問(wèn)題上的表現(xiàn)。
少樣本工具使用和正式定理證明:研究模型在這些方面的表現(xiàn)。
記憶和數(shù)據(jù)混合的影響:分析這些因素如何影響模型的表現(xiàn)。
使用CoT解決數(shù)學(xué)任務(wù)
評(píng)估數(shù)據(jù)集和任務(wù):
MATH:一個(gè)來(lái)自高中數(shù)學(xué)競(jìng)賽的問(wèn)題集,模型必須生成一個(gè)LATEX的解決方案,且其答案需要與參考答案匹配。
GSM8k:包含中學(xué)數(shù)學(xué)問(wèn)題的數(shù)據(jù)集。
OCWCourses:從MIT的開(kāi)放課程Ware提取的STEM問(wèn)題。
MMLU-STEM:MMLU基準(zhǔn)中的18個(gè)子集,涵蓋57個(gè)主題。
SAT:包含2023年5月的SAT考試中不包含圖形的數(shù)學(xué)問(wèn)題的數(shù)據(jù)集。
作者與以下模型進(jìn)行了比較:
Minerva:這個(gè)模型在技術(shù)內(nèi)容的數(shù)據(jù)集上繼續(xù)預(yù)訓(xùn)練了PaLM語(yǔ)言模型。
Code Llama:LLEMMA繼續(xù)預(yù)訓(xùn)練的初始化模型。
Llama 2:Code Llama在代碼上繼續(xù)預(yù)訓(xùn)練的初始化模型。
對(duì)于開(kāi)源的模型,作者使用他們的評(píng)估套件來(lái)報(bào)告分?jǐn)?shù),該套件是Language Model Evaluation Harness的一個(gè)分支。對(duì)于Minerva模型,作者報(bào)告了Lewkowycz等人在2022年文章中的基準(zhǔn)分?jǐn)?shù)。
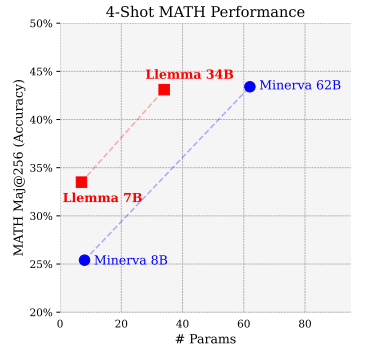
LLEMMA在Proof-Pile-2上的繼續(xù)預(yù)訓(xùn)練提高了五個(gè)數(shù)學(xué)基準(zhǔn)測(cè)試的少樣本性能。LLEMMA 34B在GSM8k上比Code Llama提高了20個(gè)百分點(diǎn),在MATH上提高了13個(gè)百分點(diǎn);LLEMMA 7B的表現(xiàn)超過(guò)了專有的Minerva模型。到目前為止,LLEMMA在所有開(kāi)放權(quán)重語(yǔ)言模型上均表現(xiàn)最佳。因此,可以得出結(jié)論,Proof-Pile-2上的繼續(xù)預(yù)訓(xùn)練對(duì)于提高預(yù)訓(xùn)練模型的數(shù)學(xué)問(wèn)題解決能力是有效的。
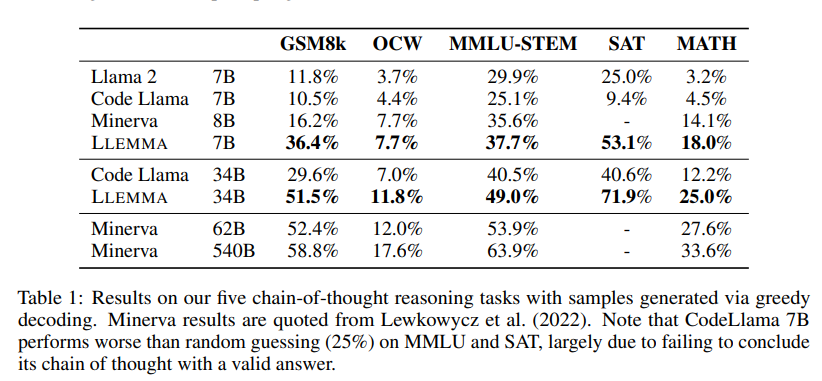
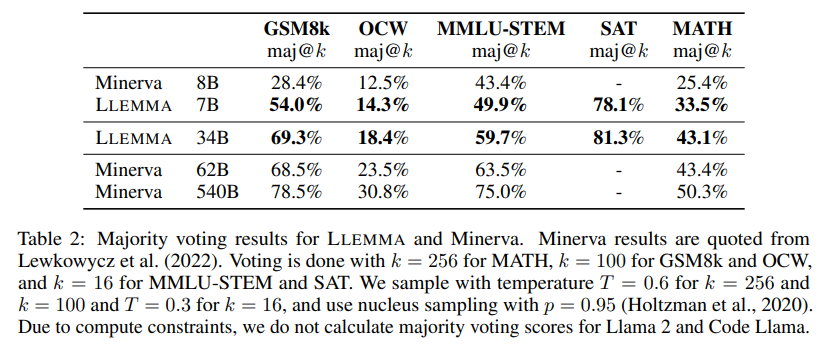
此外,LLEMMA是在與數(shù)學(xué)相關(guān)的多樣化數(shù)據(jù)上預(yù)訓(xùn)練的,而不是為特定任務(wù)進(jìn)行調(diào)優(yōu)。因此,預(yù)期LLEMMA可以通過(guò)任務(wù)特定的微調(diào)和少樣本提示適應(yīng)許多其他任務(wù)。
調(diào)用計(jì)算工具解決數(shù)學(xué)任務(wù)
這些任務(wù)涉及在有計(jì)算工具的情況下解決問(wèn)題,主要評(píng)估了以下內(nèi)容:
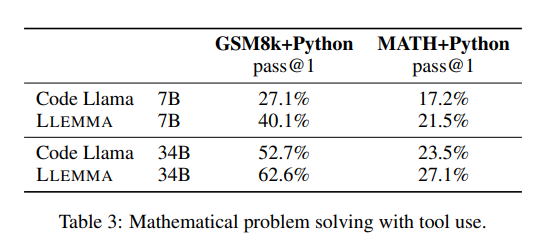
MATH+Python:模型被提示以自然語(yǔ)言交替描述解決方案的步驟,然后使用代碼執(zhí)行該步驟。最后的答案是一個(gè)可以執(zhí)行為數(shù)字類型或SymPy對(duì)象的程序。我們的少樣本提示包括使用內(nèi)置數(shù)字操作、math模塊和SymPy的示例。
GSM8k+Python:通過(guò)編寫(xiě)一個(gè)執(zhí)行為整數(shù)答案的Python程序來(lái)解決GSM8k單詞問(wèn)題。我們使用了Gao等人(2023)的提示。
如下表所示,LLEMMA在兩個(gè)任務(wù)上都優(yōu)于Code Llama。它在MATH和GSM8k上使用工具的性能也高于它在沒(méi)有工具的這些數(shù)據(jù)集上的性能。
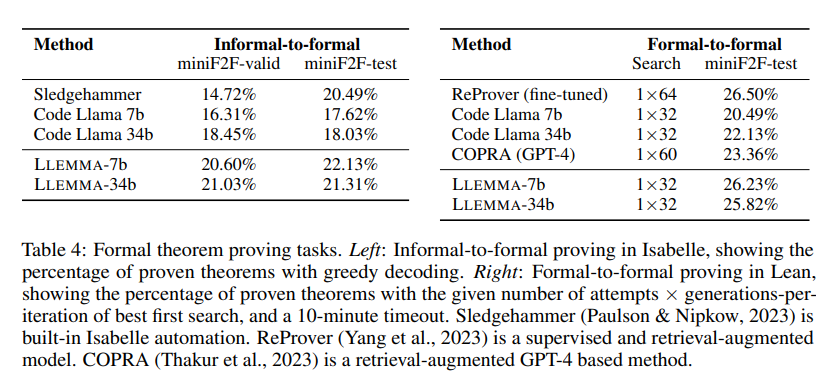
形式化數(shù)學(xué)(數(shù)學(xué)證明)
交互式證明助手,例如Lean和Isabelle,使用特殊的編程語(yǔ)言來(lái)幫助驗(yàn)證數(shù)學(xué)證明。但是,與常見(jiàn)的編程語(yǔ)言相比,這些特殊語(yǔ)言的數(shù)據(jù)非常少。
LLEMMA模型經(jīng)過(guò)進(jìn)一步的預(yù)訓(xùn)練,以處理與這些證明相關(guān)的任務(wù)。在給定問(wèn)題、非正式證明和正式聲明后,LLEMMA可以生成Isabelle代碼的正式證明。此外,模型還可以根據(jù)證明助手給出的狀態(tài),生成證明的下一個(gè)步驟。

LLEMMA在Proof-Pile-2的預(yù)訓(xùn)練包括從Lean和Isabelle提取的正式數(shù)學(xué)數(shù)據(jù),總計(jì)超過(guò)15億個(gè)標(biāo)記。作者對(duì)LLEMMA在兩個(gè)任務(wù)上的少樣本性能進(jìn)行了評(píng)估:
非正式到正式的證明:根據(jù)非正式的說(shuō)明,為數(shù)學(xué)問(wèn)題生成正式的證明。
正式到正式的證明:在已知的證明步驟中,為下一個(gè)步驟生成代碼。
結(jié)果顯示,LLEMMA在Proof-Pile-2上的繼續(xù)預(yù)訓(xùn)練提高了兩個(gè)正式定理證明任務(wù)的少樣本性能。
數(shù)據(jù)混合
在訓(xùn)練語(yǔ)言模型時(shí),經(jīng)常會(huì)根據(jù)混合權(quán)重提高訓(xùn)練數(shù)據(jù)中高質(zhì)量子集的樣本頻率。作者通過(guò)在多個(gè)手動(dòng)選擇的混合權(quán)重上進(jìn)行短期訓(xùn)練,然后選擇在高質(zhì)量保留文本上(使用MATH訓(xùn)練集)最小化困惑度的權(quán)重。通過(guò)這種方法,確定了訓(xùn)練LLEMMA的最佳數(shù)據(jù)混合比例為21。
數(shù)據(jù)重疊和記憶
作者檢查了測(cè)試問(wèn)題或解決方案是否出現(xiàn)在語(yǔ)料庫(kù)中。通過(guò)查找與測(cè)試序列中任何30-gram相匹配的文檔確定匹配程度。作者發(fā)現(xiàn)大約7%的MATH測(cè)試問(wèn)題陳述和0.6%的解決方案在語(yǔ)料庫(kù)中有匹配。
在隨機(jī)抽取的100個(gè)匹配中,作者詳細(xì)檢查了測(cè)試問(wèn)題與OpenWebMath文檔之間的關(guān)系。其中,41個(gè)案例沒(méi)有解決方案,49個(gè)提供了與MATH基準(zhǔn)解決方案不同但答案相同的解決方案,9個(gè)答案錯(cuò)誤或缺失,而只有1個(gè)與基準(zhǔn)解決方案相同。
作者進(jìn)一步探索了語(yǔ)料庫(kù)中的問(wèn)題如何影響模型的性能。當(dāng)將LLEMMA-34b應(yīng)用于具有30-gram匹配的測(cè)試示例和沒(méi)有30-gram匹配的測(cè)試示例時(shí),模型在難題上的準(zhǔn)確率仍然較低,例如在具有匹配的Level 5問(wèn)題上的準(zhǔn)確率為6.08%,而在沒(méi)有匹配的問(wèn)題上的準(zhǔn)確率為6.39%。
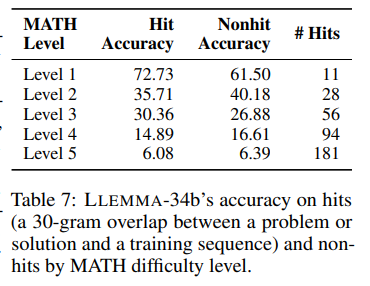
作者發(fā)現(xiàn),30-gram匹配與各個(gè)難度級(jí)別的準(zhǔn)確性之間沒(méi)有明確的關(guān)系。這意味著測(cè)試示例和訓(xùn)練文檔之間的重要匹配,并不意味著模型生成了一個(gè)記憶中的正確答案。
此外,作者還檢查了LLEMMA在MATH生成中與OpenWebMath之間的30-gram匹配,發(fā)現(xiàn)了13個(gè)匹配,這些匹配發(fā)生在模型生成了一系列常見(jiàn)的數(shù)字序列時(shí),例如斐波那契數(shù)列,以及一次多項(xiàng)式因式分解的情況。這些觀察結(jié)果值得進(jìn)一步研究。
結(jié)語(yǔ)
在這篇研究中,研究團(tuán)隊(duì)成功地推出了LLEMMA和Proof-Pile-2,這是專為數(shù)學(xué)語(yǔ)言建模設(shè)計(jì)的大語(yǔ)言模型和語(yǔ)料庫(kù)。他們公開(kāi)了模型、數(shù)據(jù)集和相關(guān)代碼。
研究揭示,LLEMMA在開(kāi)放權(quán)重模型的數(shù)學(xué)問(wèn)題解決標(biāo)準(zhǔn)測(cè)試上的表現(xiàn)尤為出眾,它不僅能通過(guò)Python代碼嫻熟地調(diào)用外部工具,還在定理證明中展示了少樣本策略預(yù)測(cè)的高效實(shí)用性。此外,該團(tuán)隊(duì)深入探討了模型在解決數(shù)學(xué)問(wèn)題時(shí)的卓越性能。
LLEMMA的出現(xiàn),為我們展現(xiàn)了數(shù)學(xué)與人工智能融合的新前景。隨著LLEMMA和Proof-Pile-2的應(yīng)用,期望在未來(lái)更能深化對(duì)語(yǔ)言模型的泛化能力、數(shù)據(jù)集結(jié)構(gòu)的認(rèn)知,探索將語(yǔ)言模型作為數(shù)學(xué)助手的可能性,并不斷提升其處理數(shù)學(xué)問(wèn)題的能力。
-
模型
+關(guān)注
關(guān)注
1文章
3519瀏覽量
50411 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10787 -
python
+關(guān)注
關(guān)注
56文章
4827瀏覽量
86708
原文標(biāo)題:開(kāi)源LLEMMA發(fā)布:超越未公開(kāi)的頂尖模型,可直接應(yīng)用于工具和定理證明
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
應(yīng)用于聲音振動(dòng)的高級(jí)信號(hào)處理算法-超越FFT pdf
MSO9000的偏斜校準(zhǔn)可以直接應(yīng)用于AUX BNC輸出嗎
開(kāi)源指南針發(fā)布在即:估量有尺,開(kāi)源有道
費(fèi)馬大定理的證明
柔性射頻濾波器,可直接應(yīng)用于柔性電子無(wú)線射頻通訊
最大功率傳輸定理證明
到底該怎么將這些頂尖工具用到我的模型里呢?
基于定理證明的內(nèi)存安全驗(yàn)證工具算法綜述

Nano BRK Arduino公開(kāi)發(fā)布板開(kāi)源

線性電路的基本定理
搭載ESP32芯片,體積小巧,接口方便,上手簡(jiǎn)單,可直接應(yīng)用于物聯(lián)網(wǎng)低功耗項(xiàng)目
【開(kāi)發(fā)實(shí)例】搭載ESP32芯片,體積小巧,接口方便,上手簡(jiǎn)單,可直接應(yīng)用于物聯(lián)網(wǎng)低功耗項(xiàng)目
清華等開(kāi)源「工具學(xué)習(xí)基準(zhǔn)」ToolBench,微調(diào)模型ToolLLaMA性能超越ChatGPT





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論