 參數少近一半,性能逼近谷歌Minerva,又一個數學大模型開源了
參數少近一半,性能逼近谷歌Minerva,又一個數學大模型開源了
大模型家族來了一個專門解決數學問題的「新成員」——Llemma。
如今,在各種文本混合數據上訓練出來的語言模型會顯示出非常通用的語言理解和生成能力,可以作為基礎模型適應各種應用。開放式對話或指令跟蹤等應用要求在整個自然文本分布中實現均衡的性能,因此更傾向于通用模型。
不過如果想要在某一領域(如醫學、金融或科學)內最大限度地提高性能,那么特定領域的語言模型可能會以給定的計算成本提供更優越的能力,或以更低的計算成本提供給定的能力水平。
普林斯頓大學、 EleutherAI 等的研究者為解決數學問題訓練了一個特定領域的語言模型。他們認為:首先,解決數學問題需要與大量的專業先驗知識進行模式匹配,因此是進行領域適應性訓練的理想環境;其次,數學推理本身就是 AI 的核心任務;最后,能夠進行強數學推理的語言模型是許多研究課題的上游,如獎勵建模、推理強化學習和算法推理。
因此,他們提出一種方法,通過對 Proof-Pile-2 進行持續的預訓練,使語言模型適應數學。Proof-Pile-2 是數學相關文本和代碼的混合數據。將這一方法應用于 Code Llama,可以得到 LLEMMA:7B 和 34B 的基礎語言模型,其數學能力得到了大幅提高。

論文地址:https://arxiv.org/pdf/2310.10631.pdf
項目地址:https://github.com/EleutherAI/math-lm
LLEMMA 7B 的 4-shot Math 性能遠超谷歌 Minerva 8B,LLEMMA 34B 在參數少近一半的情況下性能逼近 Minerva 62B。
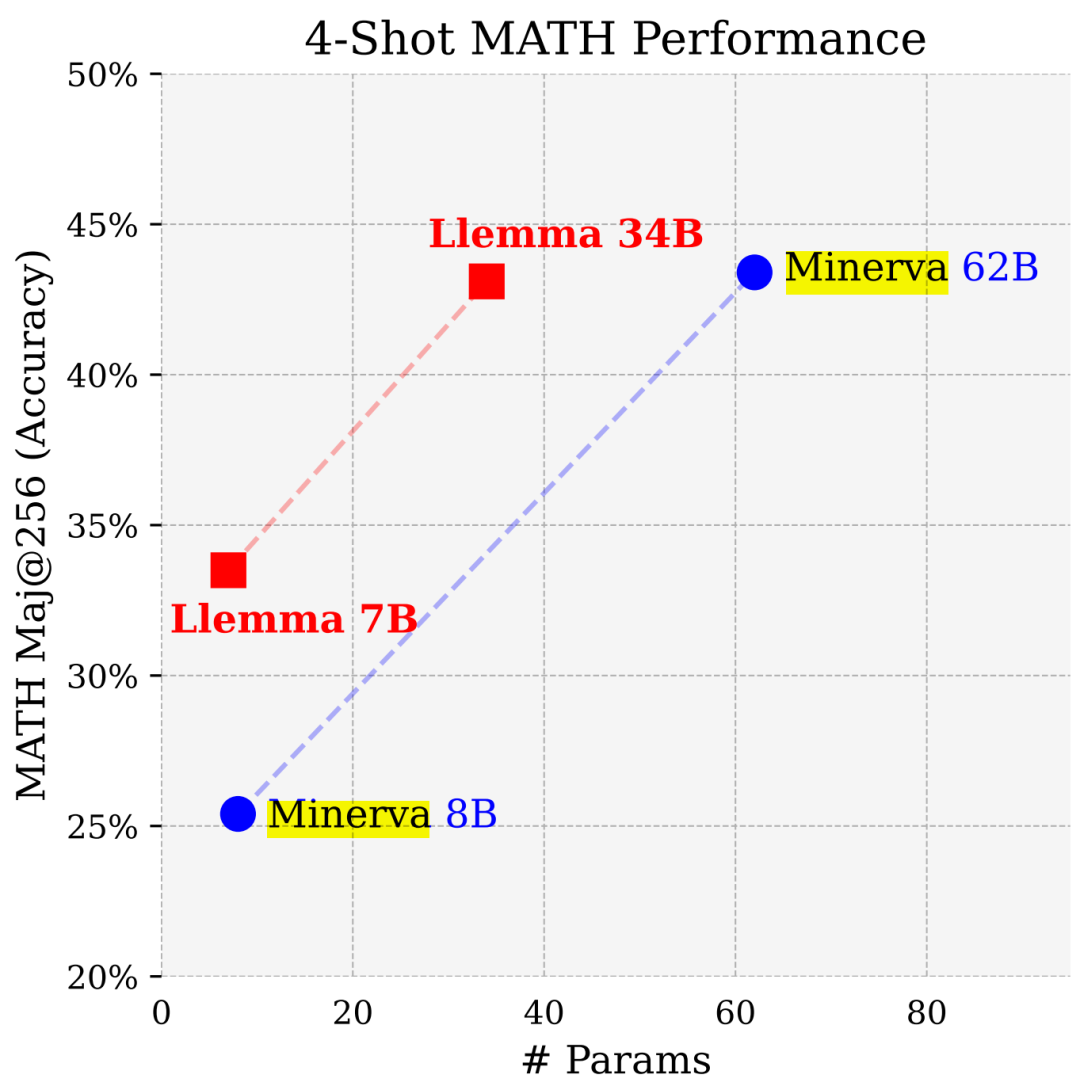
具體來說,本文貢獻如下:
-
1. 訓練并發布了 LLEMMA 模型:專門用于數學的 7B 和 34B 語言模型。LLEMMA 模型是在 MATH 上公開發布的基礎模型的最新水平。
-
2. 發布了代數堆棧(AlgebraicStack),這是一個包含 11B 專門與數學相關的代碼 token 的數據集。
-
3. 證明了 LLEMMA 能夠使用計算工具來解決數學問題,即 Python 解釋器和形式定理證明器。
-
4. 與之前的數學語言模型(如 Minerva)不同,LLEMMA 模型是開放式的。研究者開放了訓練數據和代碼。這使得 LLEMMA 成為未來數學推理研究的一個平臺。
方法概覽
LLEMMA 是專門用于數學的 70B 和34B 語言模型。它由 Proof-Pile-2 上繼續對代碼 Llama 進行預訓練得到的。
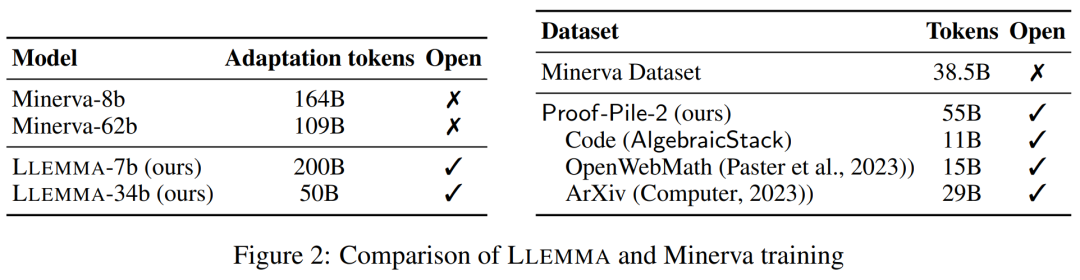
DATA: Proof-Pile-2
研究者創建了 Proof-Pile-2,這是一個 55B token 的科學論文、包含數學的網絡數據和數學代碼的混合物。除了 Lean proofsteps 子集之外,Proof-Pile-2 的知識截止日期為 2023 年 4 月。
數值模擬、計算機代數系統和形式定理證明器等計算工具對數學家的重要性與日俱增。因此,研究者創建了代數堆棧(AlgebraicStack),這是一個包含 17 種語言源代碼的 11B token 數據集,涵蓋數值數學、符號數學和形式數學。該數據集由來自 Stack、GitHub 公共資源庫和形式證明步驟數據的過濾代碼組成。表9顯示了AlgebraicStack 中各語言的 token 數量。
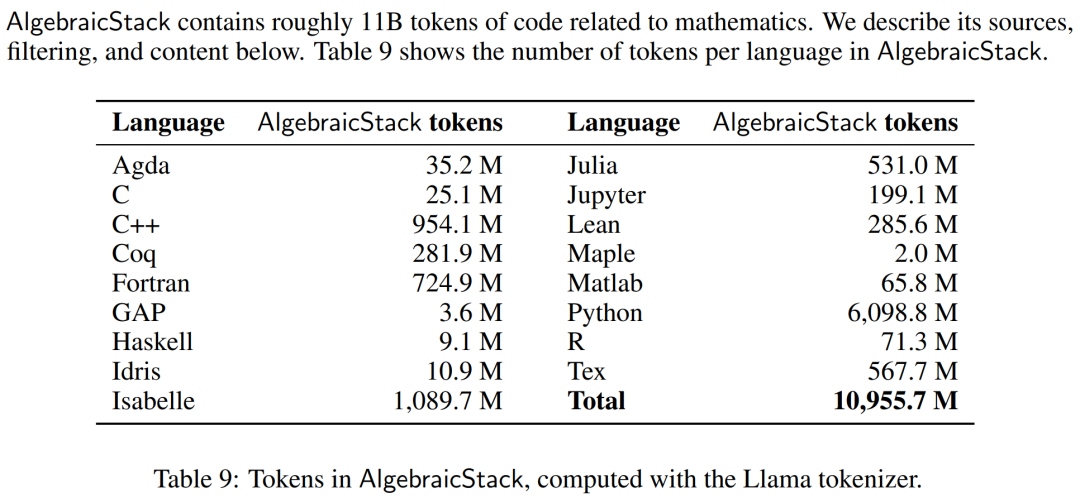
AlgebraicStack 中各語言的 token 數。
研究者了使用 OpenWebMath,這是一個由高質量網頁組成的 15B token 數據集,其中過濾了數學內容。OpenWebMath 根據數學相關關鍵詞和基于分類器的數學評分過濾 CommonCrawl 網頁,保留數學格式(如 LATEX、AsciiMath),并包含額外的質量過濾器(如 plexity、domain、length)和近似重復。
除此之外,研究者還使用了 RedPajama 的 ArXiv 子集,它是 LLaMA 訓練數據集的開放再現。ArXiv 子集包含 29B 個詞塊。訓練混合數據由少量一般領域數據組成,起到了正則化的作用。由于 LLaMA 2 的預訓練數據集尚未公開,研究者使用 Pile 作為替代訓練數據集。
模型和訓練
每個模型都是從 Code Llama 初始化而來,該模型又初始化自 Llama 2,使用僅解碼器(deconder only)的 transformer 結構,在 500B 的代碼 token 上訓練而成。研究者使用標準自回歸語言建模目標,在 Proof-Pile-2 上繼續訓練 Code Llama 模型。這里,LLEMMA 7B 模型有 200B token,LLEMMA 34B 模型有 50B token。
研究者使用 GPT-NeoX 庫在 256 個 A100 40GB GPU 上,以 bfloat16 混合精度來訓練以上兩個模型。他們為 LLEMMA-7B 使用了世界大小為 2 的張量并行,為 34B 使用了世界大小為 8 的張量并行,以及跨數據并行副本的 ZeRO Stage 1 分片優化器狀態。此外還使用 Flash Attention 2 來提高吞吐量并進一步降低內存需求。
LLEMMA 7B 經過了 42000 步的訓練,全局 batch 大小為 400 萬個 token,上下文長度為 4096 個 token。這相當于 23000 個 A100 時。學習率在 500 步后預熱到了 1?10^?4,然后在 48000 步后將余弦衰減到最大學習率的 1/30。
LLEMMA 34B 經過了 12000 步的訓練,全局 batch 大小同樣為 400 萬個 token,上下文長度為 4096。這相當于 47000 個 A100 時。學習率在 500 步后預熱到了 5?10^?5,然后衰減到峰值學習率的 1/30。
評估結果
在實驗部分,研究者旨在評估 LLEMMA 是否可以作為數學文本的基礎模型。他們利用少樣本評估來比較 LLEMMA 模型,并主要關注沒有在數學任務監督樣本上進行微調的 SOTA 模型。
研究者首先使用思維鏈推理和多數投票(majority voting)方法來評估 LLEMMA 求解數學題的能力,評估基準包括了 MATH 和 GSM8k。然后探索使用少樣本工具和定理證明。最后研究了內存和數據混合的影響。
使用思維鏈(CoT)求解數學題
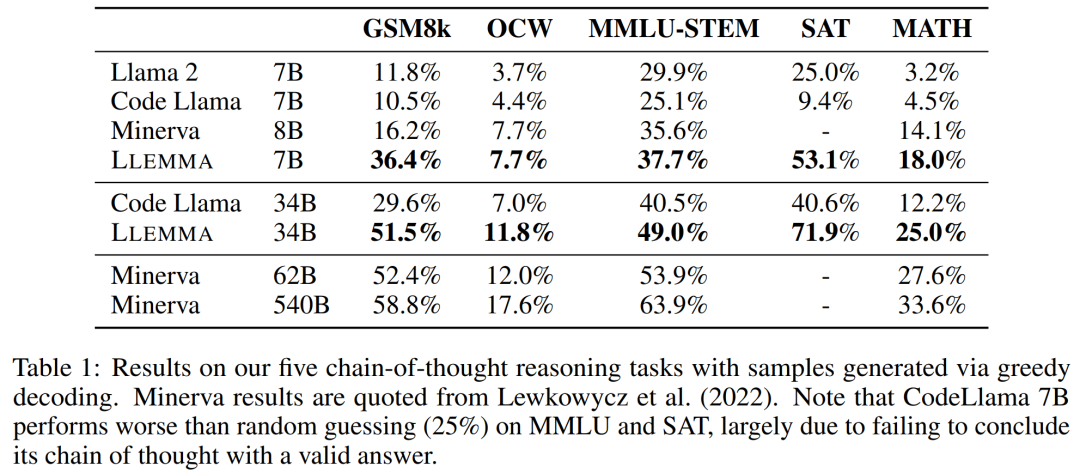
這些任務包括為 LATEX 或自然語言表示的問題生成獨立的文本答案,而無需使用外部工具。研究者使用到的評估基準有 MATH、GSM8k、 OCWCourses、SAT 和 MMLU-STEM。
結果如下表 1 所示,LLEMMA 在 Proof-Pile-2 語料庫上的持續預訓練在 5 個數學基準上均提升了少樣本性能,其中 LLEMMA 34B 在 GSM8k 上比 Code Llama 提高了 20 個百分點,在 MATH 上比 Code Llama 提高了 13 個百分點。同時 LLEMMA 7B 優于專有的 Minerva 模型。
因此,研究者得到結論,在 Proof-Pile-2 上進行持續預訓練有助于提升預訓練模型求解數學題的能力。
使用工具求解數學題
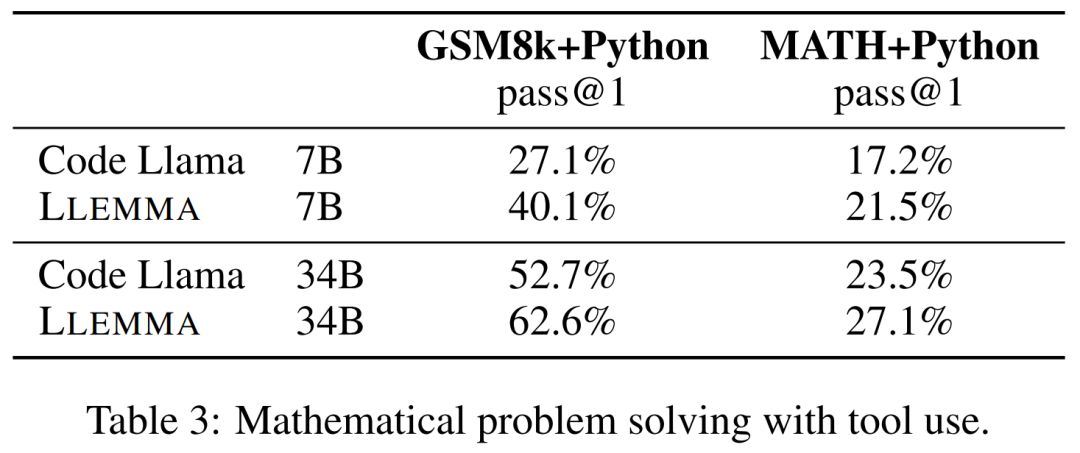
這些任務包括使用計算工具來解題。研究者使用到的評估基準有 MATH+Python 和 GSM8k+Python。
結果如下表 3 所示,LLEMMA 在這兩項任務上均優于 Code Llama。同時使用工具后在 MATH 和 GSM8k 上的性能也優于沒有工具的情況。
形式數學
Proof-Pile-2 的 AlgebraicStack 數據集擁有 15 億 token 的形式數學數據,包括提取自 Lean 和 Isabelle 的形式化證明。雖然對形式數學的全面研究超出了本文的探討范圍,但研究者在以下兩個任務上評估了 LLEMMA 的少樣本性能。

非形式到形式證明任務,即在給定形式命題、非形式 LATEX 命題和非形式 LATEX 證明的情況下,生成一個形式證明;
形式到形式證明任務,即通過生成一系列證明步驟(或策略)來證明一個形式命題。
結果如下表 4 所示,LLEMMA 在 Proof-Pile-2 上的持續預訓練在兩個形式定理證明任務上提升了少樣本性能。
數據混合的影響
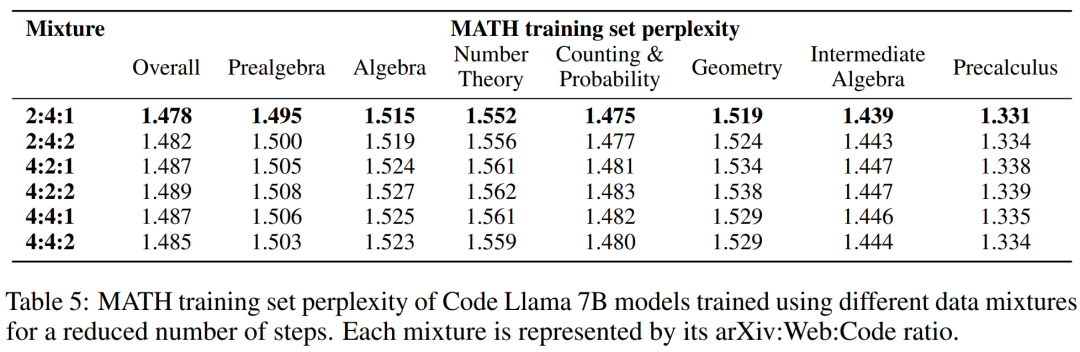
訓練語言模型時,一種常見的做法是根據混合權重對訓練數據的高質量子集進行上采樣。研究者在幾個精心挑選的混合權重上進行了短期訓練,以此選擇混合權重。接著選擇了在一組高質量 held-out 文本(這里使用了 MATH 訓練集)上能夠最小化困惑度的混合權重。
下表 5 顯示了使用 arXiv、web 和代碼等不同數據混合訓練后,模型的 MATH 訓練集困惑度。
更多技術細節和評估結果參閱原論文。
-
物聯網
+關注
關注
2909文章
44736瀏覽量
374487
原文標題:參數少近一半,性能逼近谷歌Minerva,又一個數學大模型開源了
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Kimi發布新一代數學推理模型k0-math
用opa842連了個簡單的跟隨器,就是輸出端直接反饋到反向端,為什么輸出會衰減為一半?
如何將輸出電壓降低一半?
使用VCA821進行可調增益倍數放大,輸出的信號只有一半放大了,另一半沒有變化,為什么?
通義千問推出1100億參數開源模型
谷歌發布用于輔助編程的代碼大模型CodeGemma
STM32L496 DMA收集到數據一半產生中斷,但是仿真時發現并不是數據的一半,為什么?
谷歌模型框架是什么軟件?谷歌模型框架怎么用?
谷歌模型軟件有哪些功能
谷歌發布輕量級開源人工智能模型Gemma
新火種AI|谷歌深夜炸彈!史上最強開源模型Gemma,打響新一輪AI之戰

谷歌開源70億參數大語言模型,全方位超越Meta Llama-2?
谷歌大型模型終于開放源代碼,遲到但重要的開源戰略






 工商網監
工商網監
評論