 請問一下DSP數學能否在AI領域戰勝GPU呢?
請問一下DSP數學能否在AI領域戰勝GPU呢?
AI芯片初創公司Lemurian Labs發明了一種專為AI加速設計的新型對數數字格式,并正在構建一種芯片,利用它為數據中心AI工作負載服務。
Lemurian的CEO Jay Dawani說:“2018年,我正在為機器人訓練模型,部分是卷積,部分是Transformer,部分是強化學習。在1萬個Nvidia V100 GPU上訓練這個模型需要6個月時間……模型呈指數級增長,但很少有人有足夠的算力來嘗試訓練,很多想法就這樣被放棄了。我試圖為那些有偉大想法但卻苦于沒有算力的普通的ML工程師構建模型。”
對Lemurian首款芯片的模擬顯示,根據H100最新的MLPerf推理基準測試結果,Lemurian的新數字系統與專門設計的芯片相結合,其性能將優于Nvidia的H100。在離線模式下,Lemurian芯片在MLPerf版本的GPT-J中每個芯片每秒可處理17.54次推理(Nvidia H100在離線模式下每秒可處理13.07次推理)。Dawani說,Lemurian的模擬結果可能在真實芯片性能的10%以內,但他的團隊打算今后從軟件中榨取更多性能。他說,軟件優化加上稀疏性可以將性能再提高3-5倍。
對數數字系統??
Lemurian的秘訣在于該公司提出的新數字格式,稱之為PAL(parallel adaptive logarithms)。
Dawani說:“作為一個行業,我們開始急于采用8位整數量化,因為從硬件的角度來看,這是我們所擁有的最有效的東西。但從來沒有軟件工程師說過我想要8位整數!”
對于今天的LLM推理而言,INT8的精度已被證明是不夠的,業界已轉向FP8。但Dawani解釋說,AI工作負載的性質意味著數字經常處于亞正常范圍(接近零的區域),FP8可以表示的數字較少,因此精度較低。FP8在亞正常范圍內的覆蓋率存在差距,這也是許多訓練方案需要BF16和FP32等更高精度數據類型的原因。
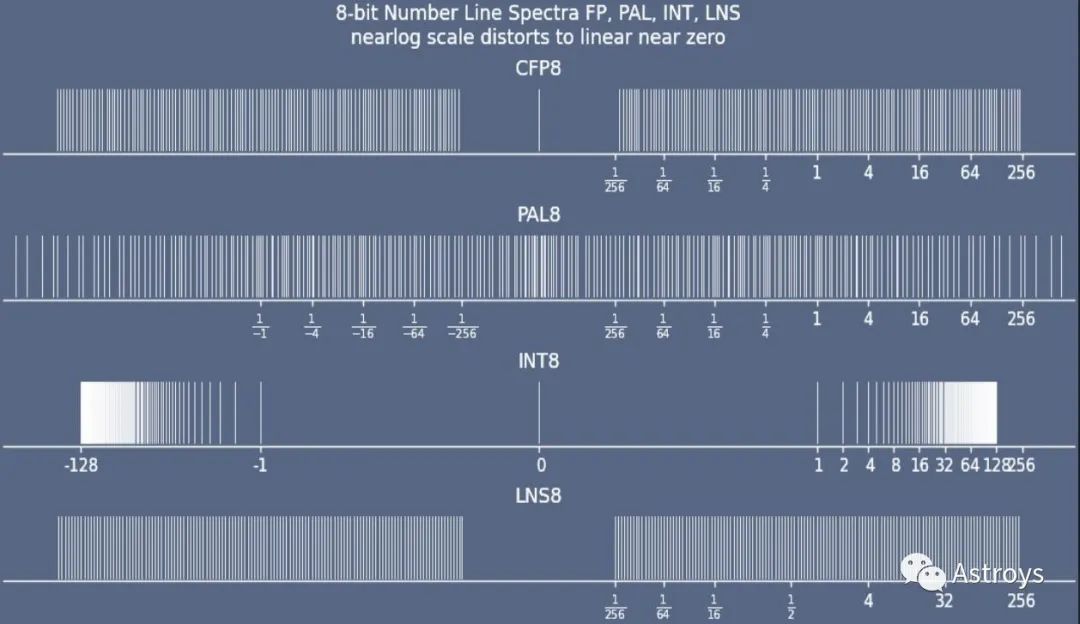
比較各種數字格式的覆蓋范圍。與CFP8(configurable floating point 8)、INT8(integer 8)和現有LNS8(logarithmic number system 8)相比,Lemurian的8位對數數據類型PAL8在亞正常范圍的覆蓋率更高。
Dawani的聯合創始人Vassil Dimitrov提出了一個想法,即通過使用多基數和多指數來擴展現有的LNS(logarithmic number system),該系統已在DSP中使用了幾十年。
Dawani說:“我們交錯表示多個指數,以重現浮點的精度和范圍。這樣就能提供更好的覆蓋范圍……它自然而然地形成了一個錐形輪廓,在重要的地方,即在亞正常范圍內,具有非常高的精度帶。” 這個精度帶可以進行偏置,以覆蓋所需的區域,這與浮點運算的原理類似,但Dawani說,它允許對偏置進行比浮點運算更精細的控制。
Lemurian開發了從PAL2到PAL64的PAL格式,其中14位格式與BF16相當。與FP8相比,PAL8的精度提高了約一個比特,大小約為INT8的1.2倍。Dawani希望其它公司也能采用這些格式。
他說:“我希望更多的人使用它,因為我認為是時候擺脫浮點運算了。PAL可以應用于目前浮點運算的任何應用,從DSP到HPC以及兩者之間,而不僅僅是AI,盡管這是我們目前的重點。我們更有可能與其它為這些應用構建芯片的公司合作,幫助他們采用我們的格式。”
對數加法器??
由于對數加法器簡化了乘法運算,因此在大部分為乘法運算的DSP工作負載中,對數加法器已使用了很長時間。LNS表示的兩個數的乘法就是這兩個對數的加法。然而,將兩個LNS數字相加卻比較困難。DSP傳統上使用LUT (large lookup table) 來實現加法運算,雖然效率相對較低,但如果所需的大部分運算都是乘法運算,這種方法已經足夠好了。
對于AI工作負載來說,矩陣乘法需要乘法和加法。Dawani說,Lemurian的秘訣之一就是“在硬件上解決了對數加法”。
他說:“我們完全摒棄了LUT,創建了一個純對數加法器。我們有一個比浮點精確得多的精確加法器。我們仍在進行更多優化,看看能否使它更便宜、更快速。它的PPA(power, performance, area)已經比FP8高出兩倍多。” Lemurian已經為這款加法器申請了多項專利。
他說:“DSP界以研究工作負載并從數值上理解它在尋找什么著稱,然后加以利用并將其轉化為芯片。這與我們正在做的事沒有什么不同。我們并沒有構建一個只做一件事的ASIC,而是研究了整個神經網絡空間的數值,并構建了一個具有適度靈活性的特定領域架構。”
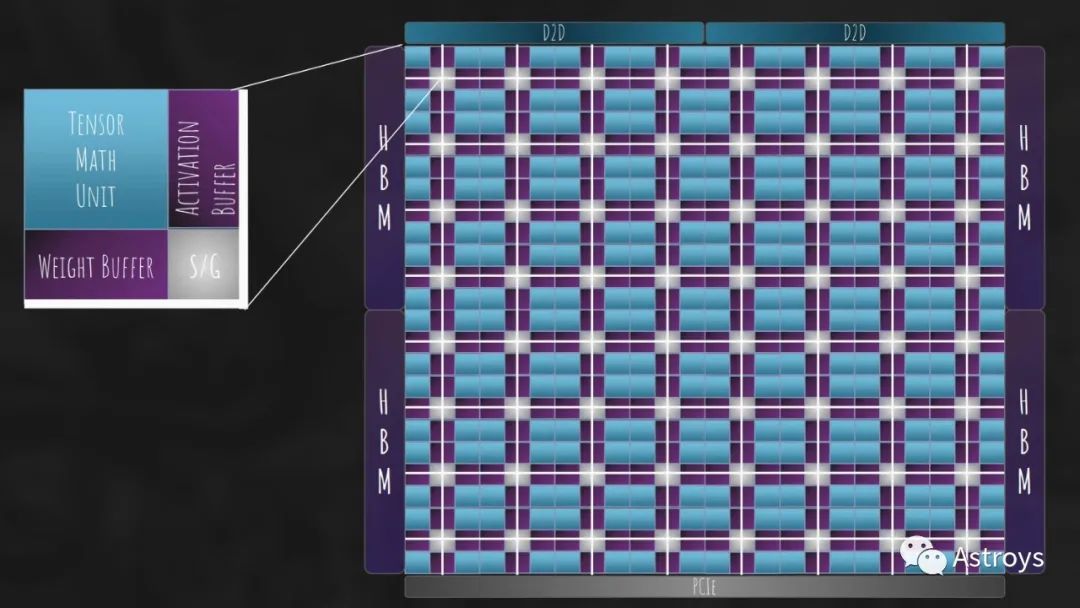
Lemurian數據流架構的高級視圖。該芯片是圍繞該公司的對數數字系統設計的。
軟件堆棧??
以高效的方式實現PAL格式需要硬件和軟件。
Dawani說:“我們花了很多心思去思考如何讓硬件更容易編程,因為除非你能首先提高工程師的生產力,否則任何架構都不會成功。我寧愿有一個糟糕的硬件架構和一個優秀的軟件堆棧,而不是相反。”
他說,Lemurian在開始考慮硬件架構之前,就已經構建了大約40%的編譯器。如今,Lemurian的軟件堆棧已經開始運行,Dawani希望保持它的完全開放性,這樣用戶就可以編寫自己的內核和融合程序。
軟件堆棧包括Lemurian的混合精度對數量化器Paladynn,它可以將浮點和整數工作負載映射到PAL格式,同時保持精度。
他說:“我們采用了神經架構搜索中的許多想法,并將其應用于量化,因為我們想讓這部分變得簡單。”
Dawani說,雖然卷積神經網絡的量化相對容易,但transformer卻并非如此。激活函數中存在異常值,需要更高的精度,因此transformer總體上可能需要更復雜的混合精度方法。不過,Dawani說,他正在關注多項研究工作,這些工作表明,到Lemurian的芯片上市時,transformer可能就不再流行了。
未來的AI工作負載可能會遵循Google的Gemini等公司設定的路徑,即運行非確定的步數。他說,這打破了大多數硬件和軟件堆棧的假設。
他說:“如果你事先不知道你的模型需要運行多少步,你該如何安排它,你需要在多少計算上安排它?你需要的是更動態的東西,這影響了我們的很多想法。”
該芯片將是一款300W的數據中心加速器,配備128GB HBM3,可提供3.5POPS的密集算力(稀疏性將稍后推出)。總體而言,Dawani的目標是打造一款性能優于H100的芯片,并使其價格與Nvidia上一代A100相當。目標應用包括內部AI服務器(任何行業)和一些二級或專業云公司(非超大規模公司)。
審核編輯:劉清
-
dsp
+關注
關注
553文章
8011瀏覽量
349122 -
HPC
+關注
關注
0文章
316瀏覽量
23801 -
GPU芯片
+關注
關注
1文章
303瀏覽量
5825 -
AI芯片
+關注
關注
17文章
1889瀏覽量
35061
原文標題:DSP數學能否在AI領域戰勝GPU?
文章出處:【微信號:Astroys,微信公眾號:Astroys】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
支付寶發布新一代AI視覺搜索“探一下”
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
TX7316使用換能器的中心頻率在45MHz,請問一下TX7316評估板可以使用嗎?
使用NDT2955代替2N6804,有沒有人幫忙分析一下無輸出的原因和能否替代?
為什么GPU對AI如此重要?

AI訓練,為什么需要GPU?

國產GPU在AI大模型領域的應用案例一覽

FPGA在深度學習應用中或將取代GPU
英偉達AI服務器NVLink版與PCIe版有何區別?又如何選擇呢?





 工商網監
工商網監
評論