


云端深度學(xué)習(xí)的服務(wù)的性能加速通常需要算法和工程的協(xié)同加速,需要模型推理和計算節(jié)點的融合,并保證整個“木桶”沒有太明顯的短板。
如何在滿足時延前提下讓算法工程師的服務(wù)的吞吐盡可能高,盡可能簡便成了性能優(yōu)化的關(guān)鍵一環(huán)。為了解決這些問題,TorchPipe通過深入PyTorch的C++計算后端和CUDA流管理,以及針對多節(jié)點的領(lǐng)域特定語言建模,對外提供面向PyTorch前端的線程安全函數(shù)接口,對內(nèi)提供面向用戶的細粒度后端擴展。
背景
深度學(xué)習(xí)的Serving面臨多個難題:
一是GIL鎖帶來的多線程使用受限
二是cpu-gpu異構(gòu)設(shè)備開銷和復(fù)雜性
三是復(fù)雜流程
業(yè)界有一些實踐,如triton inference server, 阿里媽媽high_service, 美團視覺GPU推理服務(wù)部署架構(gòu)優(yōu)化實踐。總體上,有以下方向去做這些事情:
全流程gpu化
DAG的并行化
對于cpu計算后端,去克服GIL鎖
通常用戶對于trinton inference server的一個抱怨是,在多個節(jié)點交織的系統(tǒng)中,有大量業(yè)務(wù)邏輯在客戶端完成,通過RPC調(diào)用服務(wù)端,很麻煩;而為了性能考慮,不得不考慮共享顯存,ensemble,BLS[5]等非常規(guī)手段。
一. 問題定義
對于我們自己來說,面臨的第一個問題是,pytorch 中如何并發(fā)調(diào)用resnet18模型。本項目開始于一個簡單的需求,即我們需要求得一個 X,能夠?qū)崿F(xiàn)模型推理并滿足:
前向接口需要是線程安全的。
在主要硬件平臺(如 NVIDIA GPU)以及主要通用加速引擎(如 TensorRT/Libtorch)上實現(xiàn)了此 X。
import torch, X
resnet18 = X(model="resnet18_-1x3x224x224.onnx", # 動態(tài)尺度
precision="fp16",
max=4, # 動態(tài)batch模型的最大batch數(shù)目
instance_num=4, # 多個并行計算實例
batching_timeout=5) # 湊batch超時時間
data = torch.from_numpy(data)
net_output: torch.Tensor = resnet18(data=data) # 線程安全調(diào)用
以此為起點,我們擴展到了對以下場景的支持:
包含前處理在內(nèi)的通用計算后端X的細粒度泛型擴展
多節(jié)點組成的有向無環(huán)圖(DAG)的流水線并行,多級結(jié)構(gòu)化
條件控制流
二. 背景知識
首先,我們介紹一些背景知識。您也可以跳過這一部分。
2.1 CUDA: 流和并發(fā)
CUDA提供了一致的抽象,來控制并發(fā)訪問,以便用戶最大化、完整地利用單塊GPU設(shè)備的資源能力。為了最有效的使用GPU設(shè)備,我們希望:
- 單位硬件資源能承載更多的業(yè)務(wù)請求量
- GPU盡可能滿載(前提:關(guān)聯(lián)資源使用量小,時延達標)
為了達到此目的,我們簡單分析下CUDA的編程模型。
硬件
Cuda Core是顯卡主要的運算單元。采用Pascal及以上架構(gòu)的顯卡擁有上千的CUDA核心,對應(yīng)著多組SM(Streaming Multiprocessor),可共用于一個任務(wù),也可承載不同的運算任務(wù)。從volta架構(gòu)開始,NVIDIA引入了專為深度學(xué)習(xí)設(shè)計的Tensor Core. 在Turing架構(gòu)的 Tesla T4中,一共有40個SM, 共享6MB的L2緩存。一個SM由64個FP32 算數(shù)單元,和8個Tensor Core組成。對于模型的算子級優(yōu)化,需要關(guān)注較為底層的優(yōu)化。而對于業(yè)務(wù)使用場景,既需要算子級優(yōu)化(選取針對性的計算后端負責(zé)),也需要整體視角的分析。
參考鏈接: GPU Architecture.
CUDA流
CUDA流表示一個GPU操作隊列,所有提交給GPU的任務(wù),均指定了執(zhí)行流。存在一個默認流,也就是`stream 0`, 作為默認的隊列。`提交任務(wù)`這個操作本身可以是異步的,對流進行同步化,則意味著需要阻塞cpu線程,直至所有已經(jīng)提交至該隊列中的任務(wù)執(zhí)行完畢。不同流之間的任務(wù)可以借助硬件的不同單元并行執(zhí)行或者時分并發(fā)執(zhí)行。
CUDA上下文(CUDA Context)
CUDA-Stream/CUDA-Context可以類比于線程/進程:多線程分配調(diào)用的GPU資源同屬一個CUDA Context下,有自己的隔離的地址空間,資源不能跨Context共享。默認情況下,一個進程中,在初次調(diào)用CUDA runtime軟件庫中的任何一個API時,會自動初始化當前進程中唯一的一個CUDA上下文。GPU在同一時刻只能切換到一個context,而默認情況下一個進程有一個上下文,故多個進程使用GPU,無法同時利用硬件。
虛擬化
由于GPU無法同時執(zhí)行跨CUDA context的任務(wù),導(dǎo)致硬件利用率可能不高,此時可采用一些虛擬化手段。典型的如NVIDIA官方的MPS(Multi Process Service),它實際上啟動了一個獨立進程去轉(zhuǎn)發(fā)所有的任務(wù)。采用此方法的壞處是隔離性收到了一定破壞:一旦此進程失效,所有關(guān)聯(lián)任務(wù)都將受到影響。
為了充分利用GPU的性能,可以采取一些措施:
- GPU任務(wù)合理分配到多個流,并只在恰當時機同步;
- 將單個顯卡的任務(wù)限制在單個進程中,去克服CUDA上下文分時特性帶來的資源利用率可能不足的問題。
2.2 PyTorch CUDA 語義
PyTorch 以易用性為核心,按照一致的原則組織了對GPU資源的訪問。
當前流
在PyTorch內(nèi),當前流(current stream)指的是當前線程綁定的CUDA流。PyTorch通過以下API提供了綁定CUDA流到當前線程,以及獲取當前線程綁定的CUDA流的功能:
torch.cuda.set_stream(stream) torch.cuda.current_stream(device=None)默認情況下,所有線程都綁定到默認流(stream 0)上. PyTorch的GPU運算均提交到當前線程綁定的`當前流`上。PyTorch盡量讓用戶感知不到這點: - 通常來說,當前流是都是默認流,而在同一個流上提交的任務(wù)會按提交時間串行執(zhí)行; - 對于涉及到將GPU數(shù)據(jù)拷貝到CPU或者另外一塊GPU設(shè)備的操作, PyTorch默認地在操作中插入當前流的同步操作 . 為了在多線程環(huán)境使得PyTorch充分利用GPU資源,我們需要打破以上慣例:
計算后端線程綁定到獨立的CUDA流;
在線程轉(zhuǎn)換時進行流同步
三. 單節(jié)點的并行化
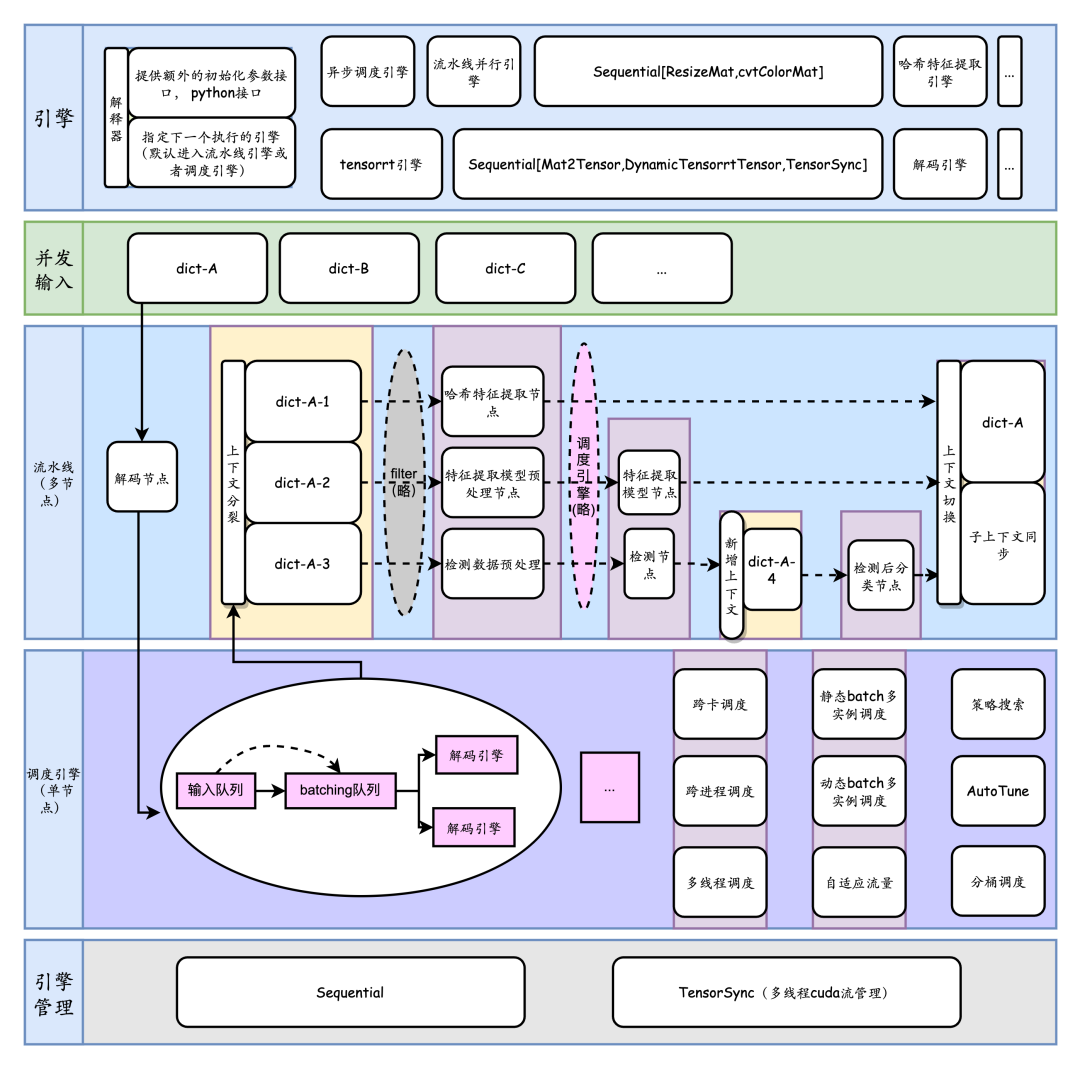
3.1 resnet18 計算加速
對于onnx格式的 resnet18的模型resnet18_-1x3x224x224.onnx, 通常有以下手段進行推理加速:
使用tensorrt等框架進行模型針對性加速
避免頻繁顯存申請
多實例,batching,分別用來提高資源使用量和使用效率
優(yōu)化數(shù)據(jù)傳輸
線程安全的本地推理
為了方便,假設(shè)將tensorrt推理功能封裝為名稱為 TensorrtTensor 的計算后端。由于計算發(fā)生在gpu設(shè)備上,我們加上SyncTensor 表示gpu上的流同步操作。
| 配置項 | 參數(shù) | 說明 |
| backend | "SyncTensor[TensorrtTensor]" | 計算后端和tensorrt推理本身一樣,不是線程安全的。 |
| max | 4 | 模型支持的最大batchsize,用于模型轉(zhuǎn)換(onnx->tensorrt) |
torchpipe默認會在此計算后端上包裹一層可擴展的單節(jié)點調(diào)度后端,實現(xiàn)以下三個基本能力:
前向接口線程安全性
多實例并行
| 配置項 | 默認值 | 說明 |
| instance_num | 1 | 多個模型實例并行執(zhí)行推理任務(wù)。 |
Batching
對于resnet18, 模型本身輸入為-1x3x224x224, batchsize越大,單位硬件資源所完成的任務(wù)越多。batchsize 從計算后端(TensorrtTensor)讀取。
| 配置項 | 默認值 | 說明 |
| batching_timeout | 0 | 單位為毫秒,在此時間內(nèi)如果沒有接收到 batchsize 個數(shù)目的請求,則放棄等待。 |
性能調(diào)優(yōu)技巧
匯總以上步驟,我們獲得推理resnet18在torchpipe下的必要參數(shù):
import torchpipe as tp
import torch
config = {
# 單節(jié)點調(diào)度器參數(shù):
"instance_num":2,
"batching_timeout":5,
# 計算后端:
"backend":"SyncTensor[TensorrtTensor]",
# 計算后端參數(shù):
"model":"resnet18_-1x3x224x224.onnx",
"max":4
}
# 初始化
models = tp.pipe(config)
data = torch.ones(1,3,224,224).cuda()
## 前向
input = {"data":data}
models(input) # <== 可多線程調(diào)用
result: torch.Tensor = input["result"] # 失敗則 "result" 不存在
假設(shè)我們想要支持最多10路的客戶端/并發(fā)請求, instance_num 一般設(shè)置2,以便最多有處理 instance_num*max = 8 路的能力。
性能取舍 請注意,我們的加速做了如下假設(shè): 同設(shè)備上的數(shù)據(jù)拷貝(如cpu-cpu數(shù)據(jù)拷貝,gpu-gpu同一顯卡內(nèi)部顯存拷貝)速度快,消耗資源少,整體上可忽略不計。 相對于cpu-gpu數(shù)據(jù)拷貝以及其他的計算,這條假設(shè)是沒問題的。后面我們將看到,在一些特殊場景,這條假設(shè)可能不成立,需要相應(yīng)的規(guī)避手段。
3.2 計算后端
在深度學(xué)習(xí)的服務(wù)中,如果僅支持模型加速遠遠不夠。為此,我們內(nèi)置了一些常用的細粒度后端。
內(nèi)置后端舉例:
| 名稱 | 說明 |
| DecodeMat | jpg解碼 |
| cvtColorMat | 顏色空間轉(zhuǎn)換 |
| ResizeMat | resize |
| PillowResizeMat | 嚴格保持和pillow的結(jié)果一致的resize |
| 更多... |
| 名稱 | 說明 |
| DecodeTensor | GPU上jpg解碼 |
| cvtColorTensor | 顏色空間轉(zhuǎn)換 |
| ResizeTensor | resize |
| PillowResizeTensor | 嚴格保持和pillow的結(jié)果一致的resize |
| 更多... |
3.3 Sequential
Sequential能串聯(lián)多個后端。也就是說,Sequential[DecodeTensor,ResizeTensor,cvtColorTensor,SyncTensor]和Sequential[DecodeMat,ResizeMat]是有效后端。
在Sequential[DecodeMat,ResizeMat]的前向執(zhí)行中,數(shù)據(jù)(dict)會依次經(jīng)過下列流程:
執(zhí)行 DecodeMat:DecodeMat讀取data, 并將結(jié)果賦值給result和color
條件控制流:嘗試將數(shù)據(jù)中的result的值賦值給data 并刪除result
執(zhí)行 ResizeMat :ResizeMat讀取data, 并將結(jié)果賦值給result鍵值
Sequential可簡寫為S.
3.4 單節(jié)點調(diào)度系統(tǒng)
輸入數(shù)據(jù)經(jīng)由默認的單節(jié)點調(diào)度系統(tǒng)BaselineSchedule分發(fā)給計算后端執(zhí)行。在此過程中主要經(jīng)歷了湊batch和多實例的調(diào)度。
湊batch/多實例
對于TensorrtTensor等模型推理引擎,輸入范圍一般是[1, max_batch_size], 此時調(diào)度系統(tǒng)可將輸入數(shù)據(jù)打包送入。BaselineSchedule單節(jié)點調(diào)度后端實現(xiàn)了如下的調(diào)度功能:
根據(jù)instance_num參數(shù)啟動多個計算后端實例
從計算后端讀取max_batch_size=max(), 如果大于1,啟動湊batch功能
從輸入隊列獲取數(shù)據(jù),在batching_timeout的時間內(nèi),如果獲得了max_batch_size個數(shù)據(jù),那么將其送往Batch隊列, 如果時間到了仍然沒有獲得足夠數(shù)據(jù),那么將已有數(shù)據(jù)送入Batch隊列
將任務(wù)從Batch隊列中分發(fā)到空閑的計算實例中。
以上是主干的大致流程,細節(jié)部分會有差別,如BaselineSchedule也實現(xiàn)了基礎(chǔ)的自適應(yīng)流量功能,根據(jù)多實例計算引擎的狀態(tài)決定batch狀態(tài)的功能,以及組合調(diào)度的功能。
單節(jié)點組合調(diào)度
有些計算后端的輸入范圍最小值大于1, 導(dǎo)致無法作為正常的后端進行調(diào)度(可能導(dǎo)致有些數(shù)據(jù)永遠沒有辦法進行處理)。BaselineSchedule通過&符號提供了組合的能力。
舉例來講,對于TensorrtTensor后端,一些模型不方便轉(zhuǎn)為動態(tài)模型, 此時可以用一個 batchsize=1 的模型和幾個 batchsize=N 的模擬動態(tài)batch.
[model] model="batch1.onnx&batch4.onnx&batch8.onnx" backend="SyncTensor[TensorrtTensor]" # or 'SyncTensor[TensorrtTensor]&SyncTensor[TensorrtTensor]' instance_num = 2 # auto extend to '2&2&2' min="1&4&8" max="1&4&8"
此時,將共有6個實例,前兩個實例輸入范圍均是[1, 1],中間兩個均是[4, 4],最后兩個均是[8, 8]。對BaselineSchedule來說,這六個實例組成了兩個虛擬實例,每個虛擬實例占用了三個實例,虛擬實例的輸入范圍是[1, 8].
四. 多節(jié)點調(diào)度
針對多節(jié)點,主要考慮了:
多個節(jié)點的鏈接, filter: 有向無環(huán)圖中的條件控制流, context: 自動map語法糖, 圖的跳轉(zhuǎn), 邏輯節(jié)點。
五. RoadMap
torchpie目前處于一個快速迭代階段,我們非常需要你的幫助。歡迎通過issues或者反饋等方式幫助我們。 我們的最終目標是讓服務(wù)端高吞吐部署盡可能簡單。為了實現(xiàn)這一目標,我們將積極自我迭代,也愿意參與有相近目標的其他項目。
2023年度和2024年度 RoadMap
大模型方面的示例
公開的基礎(chǔ)鏡像和pypi(manylinux)
優(yōu)化編譯系統(tǒng),分為core,pplcv,model/tensorrt,opencv等模塊
基礎(chǔ)結(jié)構(gòu)優(yōu)化。包含python與c++交互,異常,日志系統(tǒng),跨進程后端的優(yōu)化;
技術(shù)報告
潛在未完成的研究方向
單節(jié)點調(diào)度和多節(jié)點調(diào)度后端,他們與計算后端無本質(zhì)差異,需要更多面向用戶進行解耦,我們想要將這部分優(yōu)化為用戶API的一部分;
針對多節(jié)點的調(diào)試工具。由于在多節(jié)點調(diào)度中,使用了模擬棧設(shè)計,比較容易設(shè)計節(jié)點級別的調(diào)試工具;
負載均衡
審核編輯:湯梓紅
-
cpu
+關(guān)注
關(guān)注
68文章
11086瀏覽量
217278 -
多線程
+關(guān)注
關(guān)注
0文章
279瀏覽量
20465 -
C++
+關(guān)注
關(guān)注
22文章
2119瀏覽量
75396 -
pytorch
+關(guān)注
關(guān)注
2文章
809瀏覽量
13987
原文標題:torchpipe : Pytorch 內(nèi)的多線程計算并行庫
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是并行多線程實時處理器?MC3172開發(fā)環(huán)境開發(fā)實踐

Java多線程的用法
LabView的多線程語言
多線程的過程程序
多線程好還是單線程好?單線程和多線程的區(qū)別 優(yōu)缺點分析
什么是多線程編程?多線程編程基礎(chǔ)知識
多線程的并行實例恢復(fù)方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論