 Bamboo-pipeline:Python高效流程編排引擎
Bamboo-pipeline:Python高效流程編排引擎
Bamboo-pipeline 是藍鯨智云旗下SaaS標準運維的流程編排引擎。其具備以下特點:
- 多種流程模式 :支持串行、并行,支持子流程,可以根據全局參數自動選擇分支執行,節點失敗處理機制可配置。
- 參數引擎 :支持參數共享,支持參數替換。
- 可交互的任務執行 :任務執行中可以隨時暫停、繼續、撤銷,節點失敗后可以重試、跳過。
1.準備
開始之前,你要確保Python和pip已經成功安裝在電腦上,如果沒有,可以訪問這篇文章:超詳細Python安裝指南 進行安裝。
(可選1) 如果你用Python的目的是數據分析,可以直接安裝Anaconda:Python數據分析與挖掘好幫手—Anaconda,它內置了Python和pip.
(可選2) 此外,推薦大家用VSCode編輯器,它有許多的優點:Python 編程的最好搭檔—VSCode 詳細指南。
請選擇以下任一種方式輸入命令安裝依賴 :
- Windows 環境 打開 Cmd (開始-運行-CMD)。
- MacOS 環境 打開 Terminal (command+空格輸入Terminal)。
- 如果你用的是 VSCode編輯器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install bamboo-engine
pip install bamboo-pipeline
pip install django
pip install celery
2. 項目初始化
(選項一:無Django項目) 如果你沒有任何的現成Django項目,請按下面的流程初始化
由于 ** bamboo-pipeline ** 運行時基于 Django 實現,所以需要新建一個 Django 項目:
django-admin startproject easy_pipeline
cd easy_pipeline
在 ** easy_pipeline.settings.py ** 下添加如下配置:
from pipeline.eri.celery.queues import *
from celery import Celery
app = Celery("proj")
app.config_from_object("django.conf:settings")
INSTALLED_APPS = [
...
"pipeline",
"pipeline.engine",
"pipeline.component_framework",
"pipeline.eri",
...
]
在 ** easy_pipeline **目錄下初始化數據庫:
python manage.py migrate
(選項二:有Django項目需要使用流程引擎) 如果你有現成的PipeLine項目需要使用此流程引擎,請在項目的** settings.py **下添加如下配置:
from pipeline.eri.celery.queues import *
from celery import Celery
app = Celery("proj")
app.config_from_object("django.conf:settings")
INSTALLED_APPS = [
...
"pipeline",
"pipeline.engine",
"pipeline.component_framework",
"pipeline.eri",
...
]
然后重新執行migrate,生成pipeline相關的流程模型:
python manage.py migrate
migrate 執行完畢后會如下圖所示:

由于是在原有項目上使用流程引擎,可能會遇到一些版本不匹配的問題,如果遇到報錯,請排查解決或到藍鯨官網上進行詢問。
3. 簡單的流程例子
首先在項目目錄下啟動 celery worker:
python manage.py celery worker -Q er_execute,er_schedule --pool=solo -l info
啟動成功類似下圖所示:

(注意) 如果你是在你的原有Django項目上做改造,它并不一定能夠順利地啟動成功,這是因為Pipeline使用了 Django 2.2.24,會存在許多版本不兼容的情況。如果遇到報錯,請排查解決或到藍鯨官網上進行詢問。
在下面的例子中,我們將會創建并執行一個簡單的流程:

3.1 創建流程APP
在 bamboo_pipeline 中,一個流程由多個組件組成,官方推薦使用APP統一管控組件:
python manage.py create_plugins_app big_calculator
該命令會在 Django 工程根目錄下生成擁有以下目錄結構的 APP:
big_calculator
├── __init__.py
├── components
│ ├── __init__.py
│ └── collections
│ ├── __init__.py
│ └── plugins.py
├── migrations
│ └── __init__.py
└── static
└── big_calculator
└── plugins.js
別忘了把新創建的這個插件添加到 Django 配置的 **INSTALLED_APPS **中:
INSTALLED_APPS = (
...
'big_calculator',
...
)
3.2 編寫流程的Service原子
組件服務 ** Service是組件的核心,Service ** 定義了組件被調用時執行的邏輯,下面讓我們實現一個計算傳入的參數n的階乘,并把結果寫到輸出中的 ** Service ** ,在 **big_calculator/components/collections/plugins.py ** 中輸入以下代碼:
import math
from pipeline.core.flow.activity import Service
class FactorialCalculateService(Service):
def execute(self, data, parent_data):
"""
組件被調用時的執行邏輯
:param data: 當前節點的數據對象
:param parent_data: 該節點所屬流程的數據對象
:return:
"""
n = data.get_one_of_inputs('n')
if not isinstance(n, int):
data.outputs.ex_data = 'n must be a integer!'
return False
data.outputs.factorial_of_n = math.factorial(n)
return True
def inputs_format(self):
"""
組件所需的輸入字段,每個字段都包含字段名、字段鍵、字段類型及是否必填的說明。
:return:必須返回一個 InputItem 的數組,返回的這些信息能夠用于確認該組件需要獲取什么樣的輸入數據。
"""
return [
Service.InputItem(name='integer n', key='n', type='int', required=True)
]
def outputs_format(self):
"""
組件執行成功時輸出的字段,每個字段都包含字段名、字段鍵及字段類型的說明
:return: 必須返回一個 OutputItem 的數組, 便于在流程上下文或后續節點中進行引用
"""
return [
Service.OutputItem(name='factorial of n', key='factorial_of_n', type='int')
]
首先我們繼承了 ** Service基類,并實現了execute() ** 和 **outputs_format() ** 這兩個方法,他們的作用如下:
- execute :組件被調用時執行的邏輯。接收 data 和 parent_data 兩個參數。
其中,data 是當前節點的數據對象,這個數據對象存儲了用戶傳遞給當前節點的參數的值以及當前節點輸出的值。parent_data 則是該節點所屬流程的數據對象,通常會將一些全局使用的常量存儲在該對象中,如當前流程的執行者、流程的開始時間等。 - outputs_format :組件執行成功時輸出的字段,每個字段都包含字段名、字段鍵及字段類型的說明。這個方法必須返回一個 OutputItem 的數組,返回的這些信息能夠用于確認某個組件在執行成功時輸出的數據,便于在流程上下文或后續節點中進行引用。
- inputs_format :組件所需的輸入字段,每個字段都包含字段名、字段鍵、字段類型及是否必填的說明。這個方法必須返回一個 InputItem 的數組,返回的這些信息能夠用于確認某個組件需要獲取什么樣的輸入數據。
下面我們來看一下 **execute() **方法內部執行的邏輯,首先我們嘗試從當前節點數據對象的輸出中獲取輸入參數n,如果獲取到的參數不是一個 int 實例,那么我們會將異常信息寫入到當前節點輸出的 **ex_data **字段中, 這個字段是引擎內部的保留字段,節點執行失敗時產生的異常信息都應該寫入到該字段中 。隨后我們返回 ** False ** 代表組件本次執行失敗,隨后節點會進入失敗狀態:
n = data.get_one_of_inputs('n')
if not isinstance(n, int):
data.outputs.ex_data = 'n must be a integer!'
return False
若獲取到的 n 是一個正常的 int,我們就調用 **math.factorial() **函數來計算 n 的階乘,計算完成后,我們會將結果寫入到輸出的 factorial_of_n 字段中,以供流程中的其他節點使用:
data.outputs.factorial_of_n = math.factorial(n)
return True
3.3 編寫流程組件,綁定Service原子
完成 Service 的編寫后,我們需要將其與一個 Component 綁定起來,才能夠注冊到組件庫中,在**big_calculatorcomponents__init__.py **文件下添加如下的代碼:
import logging
from pipeline.component_framework.component import Component
from big_calculator.components.collections.plugins import FactorialCalculateService
logger = logging.getLogger('celery')
class FactorialCalculateComponent(Component):
name = 'FactorialCalculateComponent'
code = 'fac_cal_comp'
bound_service = FactorialCalculateService
我們定義了一個繼承自基類 **Component **的類 FactorialCalculateComponent ,他擁有以下屬性:
1.name:組件名。
2.code:組件代碼,這個代碼必須是全局唯一的。
3.bound_service:與該組件綁定的 Service。
這樣一來,我們就完成了一個流程原子的開發。
3.4 生成流程,測試剛編寫的組件
在 big_calculatortest.py 寫入以下內容,生成一個流程,測試剛剛編寫的組件:
# Python 實用寶典
# 2021/06/20
import time
from bamboo_engine.builder import *
from big_calculator.components import FactorialCalculateComponent
from pipeline.eri.runtime import BambooDjangoRuntime
from bamboo_engine import api
from bamboo_engine import builder
def bamboo_playground():
"""
測試流程引擎
"""
# 使用 builder 構造出流程描述結構
start = EmptyStartEvent()
# 這里使用 我們剛創建好的n階乘組件
act = ServiceActivity(component_code=FactorialCalculateComponent.code)
# 傳入參數
act.component.inputs.n = Var(type=Var.PLAIN, value=4)
end = EmptyEndEvent()
start.extend(act).extend(end)
pipeline = builder.build_tree(start)
api.run_pipeline(runtime=BambooDjangoRuntime(), pipeline=pipeline)
# 等待 1s 后獲取流程執行結果
time.sleep(1)
result = api.get_execution_data_outputs(BambooDjangoRuntime(), act.id).data
print(result)
隨后,在命令行輸入:
python manage.py shell
打開 django console, 輸入以下命令,執行此流程:
from big_calculator.test import bamboo_playground
bamboo_playground()
流程運行完后,獲取節點的執行結果,可以看到,該節點輸出了 factorial_of_n,并且值為 24(4 * 3 * 2 *1),這正是我們需要的效果:
{'_loop': 0, '_result': True, 'factorial_of_n': 24}
恭喜你,你已經成功的創建了一個流程并把它運行起來了!在這期間你可能會遇到不少的坑,建議嘗試先自行解決,如果實在無法解決,可以前往 標準運維 倉庫提 issues,或者前往藍鯨智云官網提問。
-
WINDOWS
+關注
關注
4文章
3551瀏覽量
88801 -
參數
+關注
關注
11文章
1838瀏覽量
32261 -
編輯器
+關注
關注
1文章
806瀏覽量
31190 -
python
+關注
關注
56文章
4797瀏覽量
84750
發布評論請先 登錄
相關推薦
python基礎語法及流程控制
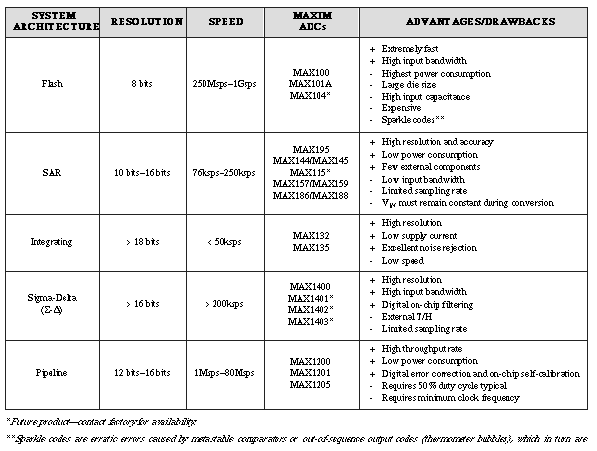
Pipeline ADCs Come of Age
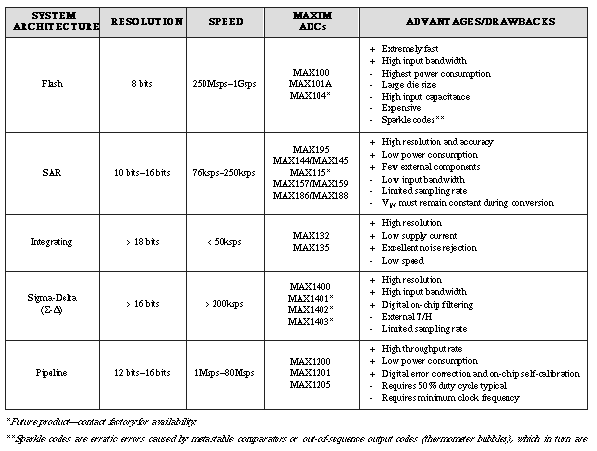
Pipeline ADCs Come of Age
python爬蟲入門教程之python爬蟲視頻教程分布式爬蟲打造搜索引擎
Vivado綜合引擎的增量綜合流程
什么是流程/規則編排
Python一鍵轉化代碼為流程圖
一圖讀懂CodeArts Pipeline全新升級,5大特性使能企業研發治理

開箱即用!教你如何正確使用華為云CodeArts Pipeline!

Python 如何一鍵轉化代碼為流程圖





 工商網監
工商網監
評論