 基于主觀知識的任務型對話建模
基于主觀知識的任務型對話建模
1 引言
對話系統技術挑戰賽 DSTC(The Dialog System Technology Challenge)是對話技術領域的頂級賽事,到 2023 年已舉辦至第 11 屆。
DSTC11 共設有 5 個賽道,其中剛剛結束的 track5 的主題是基于主觀知識的任務型對話建模。本賽道包括三個子任務:
Turn Detection:判斷當前的對話是否需要外部知識
Knowledge Selection:在非結構化主觀知識文檔中選出相關的知識候選
Response Generation:根據第二步的知識候選生成回復
我們參加了 DSTC11-track5 并在所有 14 個參賽隊伍中排名第三(客觀指標),其中 Turn Detection 子任務排名第一。本文將介紹 track 5 相關內容以及我們在競賽中嘗試的方法。
2 賽題介紹
我們在本章中詳細介紹具有主觀知識的任務型對話 (SK-TOD) 建模任務的數據集、子任務、競賽評價指標以及進行的前期相關調研。
2.1 數據集介紹
下圖[1]為對話數據集中的三個對話實例和與它們相關的知識數據中的主觀知識條目示例:

對話實例與主觀知識條目示例
對話數據集有兩部分來源:
主辦方標注的 19696 條需要主觀知識的對話,這些對話既有包含單個實體,又有包含多個實體的(如圖 1 的 Dialogue 2)。
從 MultiWOZ[2] 任務型對話數據集中抽取的 18383 條不需要主觀知識的對話。
知識包括兩種:review 類型的主觀知識(由多個句子組成) 和 FAQs 類型的知識(問答對)。這些知識被被劃分為兩個域:hotel 和 restaurant,分別包含 33 個實體和 110 個實體。
例如,hotel 域中的 Hobsons House 實體,包含的 review 知識有:
"IwasverypleasewithmyrecentvisittoHobsonsHouse." "Iwasonabusinesstripandneededaquietplacetostayandthisplacefitthebill!" "WhileIwasnotpleasedwiththeslowwi-fiandsmallroom,Iwascontentwiththeirawesomebreakfastoptions,friendlyandengagingstaffmembersandthebestpart!" "Niceandquiet,justthewayIlikeit!" "Woulddefinitelyrecommendthisplacetofriendsandplanonstayinghereagainonmynextventure!" ...
包含的 FAQs 知識有:
question:"Whatdoyouofferforbreakfast?", answer:"AnFullEnglish/IrishbreakfastisavailableattheHOBSONSHOUSE" question:"Whatisthecheck-outtimeatyourlocation?", answer:"Check-outtimeattheHobsonsHouseisbetween7:30amand10am." ...
2.2 問題定義
我們給出 DSTC11-track5 賽題的一般化定義。對于每一個對話實例 ,除最后一輪外,之前每一輪都有 agent 的回復 與用戶查詢 對應。整個對話實例 可能與一個或多個實體相關,我們將該實體集合定義為。
定義主觀知識數據,其中,表示每一個實體包含的若干知識條目。
我們的做法將整個任務進一步分解為如下圖所示的四個階段:
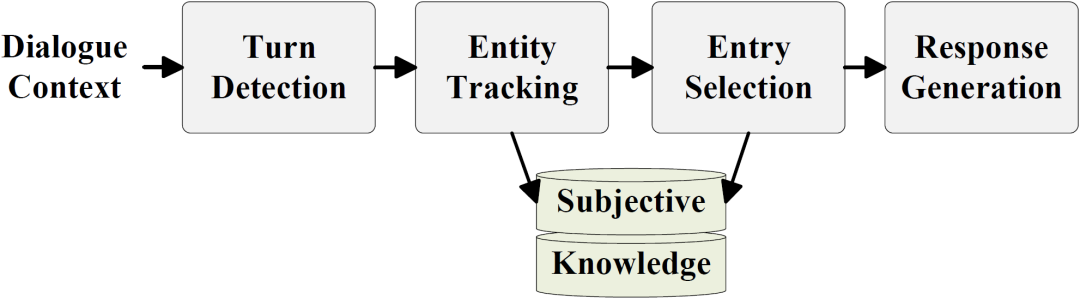
圖2. 基于主觀知識的任務型對話建模流程
Turn Detection:判斷用戶最后一輪查詢 是否需要主觀知識
Entity Tracking:如需要主觀知識,則確定與之相關的實體集合 (本部分不在比賽評測中)
Entry Selection:從實體 包含的知識候選集合 中選出相關的主觀知識條目
Response Generation:由對話上文 和相關的主觀知識條目生成回復
本賽道的難點有三個:
當需要檢索主觀知識時,每個對話對應的知識條目是不確定數目的若干條;
驗證集和測試集的分布與訓練集有較大差異,有大量的 unseen 信息;
不同的主觀知識有不同的情感傾向,回復中需要考慮多條主觀知識中的不同情感傾向。
2.3 評價指標
三個子任務的評價指標分別為:
Turn Detection:Precision、Recall、F1
Knowledge Selection:Precision、Recall、F1、Exact Match
Response Generation:BLEU、METEOR、ROUGE-1、ROUGE-2、Rouge-L
客觀評測的最終分數為每個評價指標排名的倒數和,即
其中 為第 個評測指標的結果在所有參賽結果中的排名。
2.4 相關調研
我們首先調研了 DSTC 的往屆比賽,其中 DSTC9-track1 和 DSTC10-track2 均與本屆賽題類似。
DSTC9-track1 的問題定義,數據集格式與本賽題完全相同,唯一的不同點在于每輪對話只需找出一條最相關的知識,問題要簡單許多:
He[3]等人提出了圖式引導的知識決策、否定強化的知識選擇和基于知識及機器理解的回復生成以適應三個子任務。
Tang[4]等人提出了基于 API 關鍵字與對話上下文相關性學習的方法。
DSTC10-track2 將外部知識數據從書面語更改為口語,使得構建高泛化能力的模型更為重要。而且,由于該競賽并未給出訓練集,參賽隊伍提出了很多有效的數據增廣方法:
Yan[5]等人提出了一種基于域分類任務和實體選擇任務來學習多級語義信息的方法,以及通過注入基于語音相似性的人工生成的擾動方法來擴充書面數據的思路。
Xu[6]等人首次嘗試將掩碼跨度語言建模應用于對話狀態生成,該方法有效增強了模型的泛化能力。
Whang[7]等人使用了 Levenstein 距離進行后處理來避免模型預測失真問題。
Yu[8]等人在 baseline 中增加了卷積層,這一改動獲得了更好的跨度預測性能,并使用了一種稱為 multiple 的跟蹤多值的自適應方法。
Cho[9]等人采用了實體檢測以及域跟蹤的方法縮小了候選知識的范圍。
Tan[10]等人提出了基于指針網絡的“知識復制”方法,有效減輕了 decoder 的壓力,同時提出分段響應的方法:用不同的模型生成知識選取部分和問候應答部分。
除此外,我們還調研了一些使用 MultiWOZ 數據集做端到端對話生成的模型:
He[11]等人提出的 GALAXY 模型使用門控機制來給未標記數據打偽標簽。
Lee[12]設計了一個巧妙的模型,用對話狀態跟蹤模塊在考慮對話歷史的情況下跟蹤信念狀態(用戶目標),然后再通過信念狀態作為查詢獲得數據庫狀態,最后生成回復。
3 競賽方案
3.1 數據增強
我們基于原始數據集構造了兩種增強數據集:
unseen 數據集:利用知識數據擴充對話。在對話數據集中,每一個對話實例都圍繞一個實體展開,知識數據中會有很多與這個實體相關的問答型知識(FAQ)。我們將這些問答對隨機拼接在原始的對話實例中,就得到了只涉及一個實體的新的對話實例。為了模擬真實場景中話題轉移,我們在另一個實體下生成對話的另一部分,并以 80% 的概率將它們拼接在一起[13]。
noise 數據集:采用谷歌翻譯服務將英語翻譯成其它四種語言(西班牙語/德語/日語/法語),然后再將其回譯為英語。當回譯句子與原句子相似度過高(這一現象在英法互譯中較為普遍)時,我們使用 Wordnet 進行同義詞替換以增加其多樣性。最后,我們將對話數據集及知識數據擴充為原來的 5 倍,這些數據用于對模型預訓練。進一步將 5 種對話數據集和知識數據兩兩組合,得到原來 25 倍大小的數據集。因為回譯和同義詞替換引入了詞級和語義級的干擾,所以我們定義此數據為noise數據。
3.2 Turn Detection 階段
本階段的目標是判斷當前對話用戶的最后一輪查詢是否需要主觀知識,是一個二分類問題。
我們使用自編碼預訓練模型 DeBERTa-v3-base[14],將當前對話上文和最一輪查詢 作為輸入,取最后一個隱藏層的第一個 token 即 [CLS] 的向量作為對話表示,將其輸入一個線性層中就求得分類概率:
為了在后面進行模型融合,提高整體的泛化能力,我們訓練了三個模型,分別適用于三種場景:
Seen expert。使用 DSTC11-track5 提供的訓練集微調 DeBERTA-v3-base 模型,得到在驗證集上表現最好的模型。這個模型在見過的對話實例上有極好的表現。
Unseen expert。為增強模型在未見過的對話實例上的檢測能力,我們使用 3.1 介紹的 unseen 數據集對 RoBERTa[15] 模型進行微調。
De-noise expert。為得到一個泛化能力較強的模型,我們考慮使用 3.1 介紹的 noise 數據集進行訓練。首先,用回譯的 5 倍數據集基于 word-masking[16]預訓練方法對 DeBERTa 模型進行預訓練,然后,使用兩兩組合的 25 倍含有噪音的數據集進行微調。
在后面,我們會使用基于差異感知的模型融合方法來融合這三種模型,讓它們相得益彰。
3.3 Entity Track 階段
本階段的目標是確定與當前對話用戶的最后一輪查詢相關的實體。該階段可以縮小后續知識選擇的范圍。
我們使用啟發式方法為每個實體名稱建立一個詞典,然后基于 n-gram 匹配最后一輪對話中出現的實體。這種方法已經能達到較為不錯的結果,驗證集性能為 F1=0.9676,accuracy=0.9398。
3.4 Entry Selection 階段
本階段目標是選出與用戶查詢相關的知識條目。輸入是對話上文,以及知識候選 ,輸出為知識候選的子集 。我們使用同一個編碼器獲得兩者的表示 ,。然后將 ,, 拼接在一起計算相關性:
在訓練時,我們將與 ground-truth 同一實體的知識和其它實體的知識按 1 : 1 比例構造負例。在驗證時,我們使用 Entity Track 階段確定的實體中的知識作為知識候選。
與 Turn Detection 類似,我們同樣訓練了 Seen expert,Unseen expert 和 De-noise expert 這三種模型,之后也使用基于差異感知的模型融合方法來融合這三種模型。
3.5 Response Generation 階段
本階段目標是基于對話上下文 和相關知識片段 來創建響應用戶請求的回復 。我們將 和 連接起來作為輸入,并使用經預訓練的生成模型來生成回復。
我們既考慮了 decoder-only 架構的模型(如 GPT-2[17])也考慮了 encoder-decoder 架構的模型(如 BART[18]和 T5[19])。
此外,為了降低 Entity Track 和 Entry Selection 階段對本階段的影響,我們在訓練時使用了一些方法調整模型輸入:
拼接對話時額外添加實體名字段強化實體信息;
隨機丟棄 15% 的知識以讓模型在 Entry Selection 階段漏選知識時仍能取得良好的生成效果。
此外,我們還考慮了其他生成方式:
使用 KAT-TSLF 結構[20],考察將對話上下文和全部候選知識條目作為輸入以及將對話上下文和 KS 階段選取的知識條目作為輸入,但是效果均不如 BART 模型;
使用在本任務上經過 alpaca 微調的 LLAMA-13B[21],結合專門設計的 instruction,輸入對話上下文和所選的知識條目來生成回復。然而,正如近期研究顯示,LLM 存在幻覺問題[22],不能很好地執行特定領域或知識密集型任務。因此該模型在本任務上其表現也不如 BART 模型。
3.6 基于差異感知的模型融合方法
為了融合 Seen expert,Unseen expert 和 De-noise expert 這三種模型,我們提出了一種基于差異感知的模型融合方法。
以 Entry Selection 階段訓練出來的三種模型為例。對于驗證集的第 個對話實例,設 為 ground-truth 標簽,它包含 條知識。我們用不同模型得到 條知識條目候選,并將它們按相關度降序排列。對于每個知識條目候選,我們為其設置權重為它的相關度排序加一的倒數。例如 Seen-expert 模型得到的知識候選的第 條 權重為 。同理, 和 分別為 Unseen expert 和 De-noise expert 得到的知識候選和權重。
由此得到知識候選集合,對于第 條知識,將它的融合權重定義為,其中,如果存在 使 ,則 ,否則, 是超參數,滿足 。
此外,我們還對權重設置了一個閾值,得到的超過閾值的知識條目集合 即為最終輸出。使用驗證集的 Recall/Precision/F1/EM 等指標學習超參數 ,整體算法如下圖所示:

算法流程圖
該方法對于不同任務和不同數據集均可適用:
比如在 Entry Selection 階段,為同時保證知識選擇的準確率和召回率,我們使用權重閾值來決定該知識是否相關,而不是直接選擇 Top-N 權重的知識。
對于不同測試集,我們可以根據其中 unseen 對話條數的比例相應調整驗證集中 unseen 的比例來學習 。通過 的調整,測試集中 unseen 對話條數比例越高,我們的 Unseen expert 在最后權重占比也就越大。
4 結果分析
本章分析我們的方法在驗證集及最終測試集上的表現。
4.1 Turn Detection 子任務
Turn Detection 子任務實驗結果如表 1 所示:
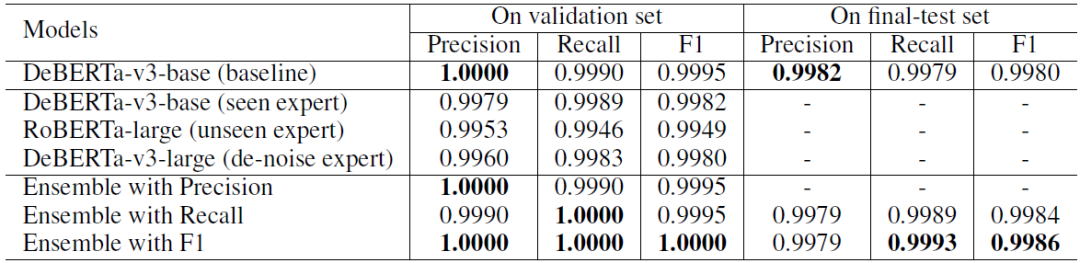
表1 Turn Detection 子任務實驗結果
不難看出 baseline 在驗證集上已經有了很高的性能。考慮到最終測試集中有 unseen 對話 ,于是我們使用基于差異感知的模型融合方法,力求在測試集的 unseen 對話上獲得更好的性能。
我們分別使用 Precision、Recall 和 F1 作為指標來學習模型融合參數,因為更高的 Recall 對 unseen 對話更有效,所以我們選擇 Recall 和 F1 訓練的結果模型融合結果作為最終提交。
在最終測試集上,我們的方法在所有提交結果中 F1 指標排名第一,Recall 指標排名第二,三項總和排名第一。
4.2 Knowledge Selection 子任務
Knowledge Selection 子任務實驗結果如表 2 所示:
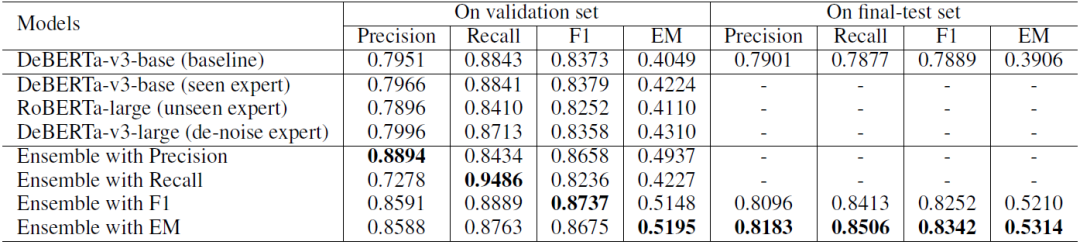
表2 knowledge selection 子任務實驗結果
可以看到:
我們的單個模型表現都只略好于 baseline,然而使用我們的模型融合方法后,性能大幅提高,這說明我們的模型融合方法能結合不同 expert 的優勢,使得模型綜合性能大大提升;
分別使用不同的指標學習模型融合參數,就能得到相應指標下表現最好的模型。
我們依據 4 個指標的驗證集結果總和選擇最后兩個結果(F1 和 EM)作為最終提交。在測試集上,我們的方法具有一致的性能,并且在很大程度上優于 baseline。尤其在 EM 指標上,我們的方法比 baseline 高出 14%。
為下一節表述方便,我們將這兩個結果表示為 KS-F1 和 KS-EM。
4.3 Response Generation 子任務
Response Generation 子任務實驗結果如表 3 所示:

表3 knowledge selection 子任務實驗結果
我們在生成回復過程中并沒有使用模型融合方法。上述結果可以反映出知識選擇子任務對生成任務的影響。
使用 KS-F1 的 BART-base 生成結果在所有指標上都優于 baseline。這一結果表明,KS-F1 提供了更高質量的知識條目,并再次證明了我們模型融合方法的有效性。
BART-large 和 T5 作為更大的模型,在大多數指標上都優于 BART-base。此外,BART-large (KS-F1) 的 BLEU 指標表現極好,在所有提交中排名第二。BART-large (KS-EM) 在 ROUGE 指標上表現更好,T5-3B (KS-EM) 在 METEOR 指標上更好。然而,T5 在測試集上的 BLEU 指標表現不佳,與 BART-large 相比沒有明顯的優勢。
5 總結
我們在 DSTC11-track5 競賽中提出了一種基于差異感知的模型融合方法。該方法很好的解決了競賽的兩大難點:
每個對話實例都與數量不定的若干條知識相關,如何讓模型學習到這種分類能力。
訓練集、驗證集和測試集分布差異較大,如何讓模型在 seen 對話和 unseen 對話上都能有不錯的表現。
最后我們獲得了客觀指標排名第三的成績,這一成績證明了我們方法的有效性。
未來可以繼續嘗試的工作包括:
知識選擇子任務:
可以將基于差異感知的模型融合方法同樣運用在 Entity Track 階段。
review 型的主觀知識和 FAQ 型的主觀知識具有不同的語義特性,比如 FAQ 的問句可能與用戶查詢有著較高的相似度,考慮如何分別對這兩類知識進行選擇。
回復生成子任務:
可以考慮分別用對話歷史 encoder 和外部知識 encoder 對輸入進行編碼再對其加以融合,這可能有助于模型對于對話生成和知識整合兩部分的單獨學習。
可以考慮使用大模型對知識加以初步的理解,再用我們的回復生成模型根據被理解的信息進行回復,這可能有助于增強模型的泛化能力。
可以考慮用對話狀態追蹤技術分析輸入的對話歷史,這可能有助于增強模型抗干擾能力。
針對前文提到的第三個難點,不同的主觀知識有不同的情感傾向。可以考慮使用特定的情感理解模型輔助生成的訓練。
模型融合:
考慮進一步優化我們的基于差異感知的模型融合方法,讓模型自動學習閾值。
-
模型
+關注
關注
1文章
3226瀏覽量
48809 -
追蹤技術
+關注
關注
0文章
19瀏覽量
4299
原文標題:基于主觀知識的任務型對話建模
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于CVR建模的多任務聯合學習訓練方法——ESMM
結合NLU在面向任務的對話系統中的具體應用進行介紹
【安富萊原創】【STemWin教程】第39章 對話框基礎知識
基于任務鏈的實時多任務軟件可靠性建模
知識型員工任務評價信息系統的指標模型
四大維度講述了一個較為完整的智能任務型對話全景
強化學習應用中對話系統的用戶模擬器
將對話中的情感分類任務建模為序列標注 并對情感一致性進行建模
口語語言理解在任務型對話系統中的探討

視覺問答與對話任務研究綜述

NLP中基于聯合知識的任務導向型對話系統HyKnow
基于知識的對話生成任務
NVIDIA NeMo 如何支持對話式 AI 任務的訓練與推理?

知識分享 | 輕松實現優質建模






 工商網監
工商網監
評論