") Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例
Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例
本篇文章主要介紹如何使用新的Hugging Face LLM推理容器將開源LLMs,比如BLOOM大型語言模型部署到亞馬遜云科技Amazon SageMaker進(jìn)行推理的示例。我們將部署12B Open Assistant Model,這是一款由開放助手計(jì)劃訓(xùn)練的開源Chat LLM。
這個示例包括:
設(shè)置開發(fā)環(huán)境
獲取全新Hugging Face LLM DLC
將開放助手12B部署到亞馬遜云科技Amazon SageMaker
進(jìn)行推理并與我們的模型聊天
清理環(huán)境
什么是Hugging Face LLM Inference DLC?
Hugging Face LLM DLC是一款全新的專用推理容器,可在安全的托管環(huán)境中輕松部署LLM。DLC由文本生成推理(TGI)提供支持,這是一種用于部署和服務(wù)大型語言模型(LLM)的開源、專門構(gòu)建的解決方案。TGI使用張量并行和動態(tài)批處理為最受歡迎的開源LLM(包括StarCoder、BLOOM、GPT-Neox、Llama和T5)實(shí)現(xiàn)高性能文本生成。文本生成推理已被IBM、Grammarly等客戶使用,Open-Assistant計(jì)劃對所有支持的模型架構(gòu)進(jìn)行了優(yōu)化,包括:
張量并行性和自定義cuda內(nèi)核
在最受歡迎的架構(gòu)上使用flash-attention優(yōu)化了用于推理的變形器代碼
使用bitsandbytes進(jìn)行量化
連續(xù)批處理傳入的請求以增加總吞吐量
使用safetensors加速重量加載(啟動時間)
Logits扭曲器(溫度縮放、topk、重復(fù)懲罰…)
用大型語言模型的水印添加水印
停止序列,記錄概率
使用服務(wù)器發(fā)送事件(SSE)進(jìn)行Token流式傳輸
官方支持的模型架構(gòu)目前為:
BLOOM/BLOOMZ
MT0-XXL
Galactica
SantaCoder
gpt-Neox 20B(joi、pythia、lotus、rosey、chip、redPajama、open Assistant)
FLAN-T5-XXL(T5-11B)
Llama(vicuna、alpaca、koala)
Starcoder/santaCoder
Falcon 7B/Falcon 40B
借助亞馬遜云科技Amazon SageMaker上推出的全新Hugging Face LLM Inference DLC,亞馬遜云科技客戶可以從支持高度并發(fā)、低延遲LLM體驗(yàn)的相同技術(shù)中受益,例如HuggingChat、OpenAssistant和Hugging Face Hub上的LLM模型推理API。
1.設(shè)置開發(fā)環(huán)境
使用SageMaker python SDK將OpenAssistant/pythia-12b-sft-v8-7k-steps部署到亞馬遜云科技Amazon SageMaker。需要確保配置一個亞馬遜云科技賬戶并安裝SageMaker python SDK。

如果打算在本地環(huán)境中使用SageMaker。需要訪問具有亞馬遜云科技Amazon SageMaker所需權(quán)限的IAM角色。可以在這里找到更多關(guān)于它的信息。

2.獲取全新Hugging Face LLM DLC
與部署常規(guī)的HuggingFace模型相比,首先需要檢索容器URI并將其提供給HuggingFaceModel模型類,并使用image_uri指向該鏡像。要在亞馬遜云科技Amazon SageMaker中檢索新的HuggingFace LLM DLC,可以使用SageMaker SDK 提供的get_huggingface_llm_image_uri方法。此方法允許根據(jù)指定的 “后端”、“會話”、“區(qū)域” 和 “版本”檢索所需的Hugging Face LLM DLC 的 URI。

要將[Open Assistant Model](openAssistant/Pythia-12b-sft-v8-7K-steps)部署到亞馬遜云科技Amazon SageMaker,創(chuàng)建一個HuggingFaceModel模型類并定義終端節(jié)點(diǎn)配置,包括hf_model_id、instance_type等。使用g5.4xlarge實(shí)例類型,它有1個NVIDIA A10G GPU和64GB的GPU內(nèi)存。

亞馬遜云科技Amazon SageMaker現(xiàn)在創(chuàng)建端點(diǎn)并將模型部署到該端點(diǎn)。這可能需要10-15分鐘。
4.進(jìn)行推理并與模型聊天
部署終端節(jié)點(diǎn)后,可以對其進(jìn)行推理。使用predictor中的predict方法在端點(diǎn)上進(jìn)行推理。可以用不同的參數(shù)進(jìn)行推斷來影響生成。參數(shù)可以設(shè)置在parameter中設(shè)置。
溫度:控制模型中的隨機(jī)性。較低的值將使模型更具確定性,而較高的值將使模型更隨機(jī)。默認(rèn)值為0。
max_new_tokens:要生成的最大token數(shù)量。默認(rèn)值為20,最大值為512。
repeption_penalty:控制重復(fù)的可能性,默認(rèn)為null。
seed:用于隨機(jī)生成的種子,默認(rèn)為null。
stop:用于停止生成的代幣列表。生成其中一個令牌后,生成將停止。
top_k:用于top-k篩選時保留的最高概率詞匯標(biāo)記的數(shù)量。默認(rèn)值為null,它禁用top-k過濾。
top_p:用于核采樣時保留的參數(shù)最高概率詞匯標(biāo)記的累積概率,默認(rèn)為null。
do_sample:是否使用采樣;否則使用貪婪的解碼。默認(rèn)值為false。
best_of:生成best_of序列如果是最高標(biāo)記logpros則返回序列,默認(rèn)為null。
details:是否返回有關(guān)世代的詳細(xì)信息。默認(rèn)值為false。
return_full_text:是返回全文還是只返回生成的部分。默認(rèn)值為false。
truncate:是否將輸入截?cái)嗟侥P偷淖畲箝L度。默認(rèn)值為true。
typical_p:代幣的典型概率。默認(rèn)值null。
水印:生成時使用的水印。默認(rèn)值為false。
可以在swagger文檔中找到TGI的開放api規(guī)范。
openAssistant/Pythia-12b-sft-v8-7K-steps是一種對話式聊天模型,這意味著我們可以使用以下提示與它聊天:

先試一試,問一下夏天可以做的一些很酷的想法:

現(xiàn)在,使用不同的參數(shù)進(jìn)行推理,以影響生成。參數(shù)可以通過輸入的parameters屬性定義。這可以用來讓模型在“機(jī)器人”回合后停止生成。

現(xiàn)在構(gòu)建一個快速gradio應(yīng)用程序來和它聊天。

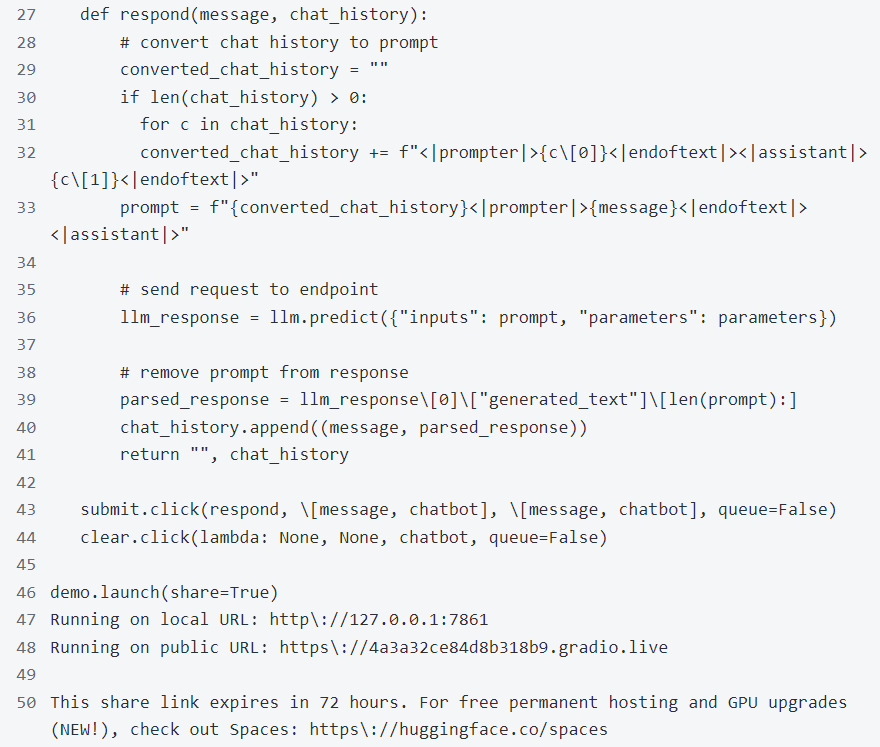
程序運(yùn)行成功后,顯示如下聊天窗口:
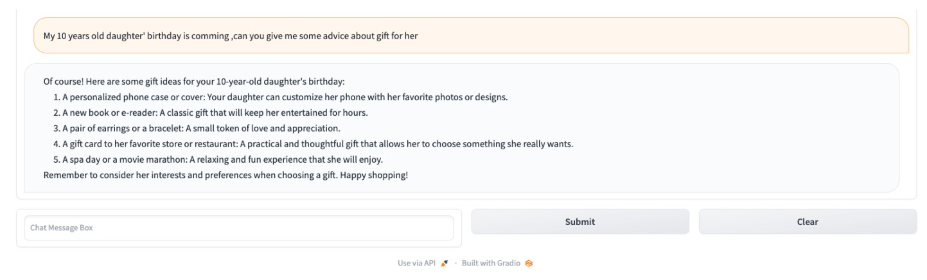
現(xiàn)在已經(jīng)成功地將Open Assistant模型部署到亞馬遜云科技Amazon SageMaker并對其進(jìn)行了推理。此外,還構(gòu)建了一個快速的gradio應(yīng)用程序,可以與模型聊天。
現(xiàn)在,可以使用亞馬遜云科技Amazon SageMaker上全新Hugging Face LLM DLC構(gòu)建世代人工智能應(yīng)用程序的時候了。
5.清理環(huán)境
刪除模型和端點(diǎn)。

6.總結(jié)
從上面的部署過程,可以看到整個部署大語言模型的過程非常簡單,這個主要得益于SageMaker Hugging Face LLM DLC的支持,還可以通過將Amazon SageMaker部署的端點(diǎn)與應(yīng)用集成,滿足實(shí)際的業(yè)務(wù)需求。
審核編輯 黃宇
-
語言模型
+關(guān)注
關(guān)注
0文章
520瀏覽量
10268 -
亞馬遜
+關(guān)注
關(guān)注
8文章
2650瀏覽量
83315 -
LLM
+關(guān)注
關(guān)注
0文章
286瀏覽量
327
發(fā)布評論請先 登錄
相關(guān)推薦
?使用AWS Graviton降低Amazon SageMaker推理成本

基于Transformer的大型語言模型(LLM)的內(nèi)部機(jī)制

Hugging Face更改文本推理軟件許可證,不再“開源”
NVIDIA 與 Hugging Face 將連接數(shù)百萬開發(fā)者與生成式 AI 超級計(jì)算

NVIDIA 與 Hugging Face 將連接數(shù)百萬開發(fā)者與生成式 AI 超級計(jì)算

亞馬遜云科技推出五項(xiàng)Amazon SageMaker新功能
ServiceNow、Hugging Face 和 NVIDIA 發(fā)布全新開放獲取 LLM,助力開發(fā)者運(yùn)用生成式 AI 構(gòu)建企業(yè)應(yīng)用

Mistral Large模型現(xiàn)已在Amazon Bedrock上正式可用
亞馬遜云攜手AI新創(chuàng)企業(yè)Hugging Face,提升AI模型在定制芯片計(jì)算性能
Hugging Face科技公司推出SmolLM系列語言模型
LLM大模型推理加速的關(guān)鍵技術(shù)
亞馬遜云科技正式上線Meta Llama 3.2模型
亞馬遜云科技上線Meta Llama 3.2模型
Amazon Bedrock推出多個新模型和全新強(qiáng)大的推理和數(shù)據(jù)處理功能





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論