 如何用python實現RFM建模
如何用python實現RFM建模
RFM模型的含義
RFM模型是衡量客戶價值和客戶創利能力的重要工具和手段。在眾多的客戶關系管理(CRM)的分析模式中,RFM模型是被廣泛提到的。
該模型通過一個客戶的近期購買行為(R)、購買的總體頻率(F)以及花了多少錢(M)三項指標來描述該客戶的價值狀況,從而能夠更加準確地將成本和精力更精確的花在用戶層次身上,實現針對性的營銷。
詳細來說,R指的是客戶最后一次下單時間距離今天多少天了,該指標與客戶的復購和流失直接相關。F指標指的是客戶的下單頻率,即客戶在某個時間段內共消費了多少次,該指標用于衡量客戶消費的活躍度。M指標指的是客戶在該時間段內共消費了多少錢,該指標用于反應客戶對于公司的貢獻值。
RFM分析的前提條件:
- 最近有過交易行為的客戶,再次發生交易行為的可能性高于最近沒有交易行為的客戶。
- 交易頻率高的客戶,比交易頻率低的客戶,更有可能再次發生交易行為。
- 過去所有交易總金額較大的客戶,比過去所有交易總金額較小的客戶,更有消費積極性。
原始數據
原始數據集在這里先展示一下,讓你對這個數據有一個主觀印象。
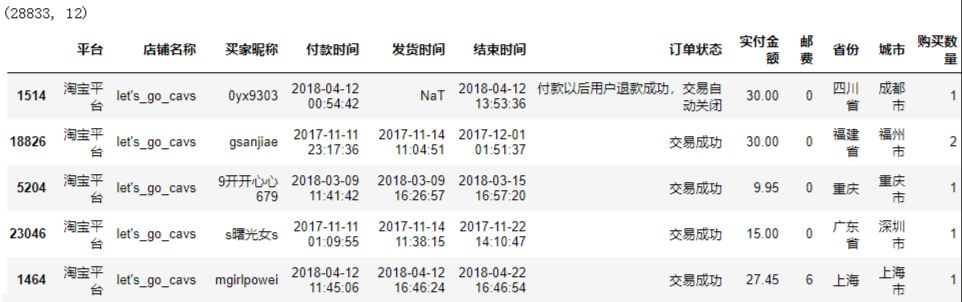
(點擊放大)
數據處理
1)什么是R、F、M呢?
“R”表示最近一次消費時間距離今天共有多少天。什么是最近一次消費時間呢?如果同一個人在不同時間有不同多個訂單,那么該時間距離當前時間的差值的最小值,就是最近一次消費時間。
“F”表示某個人一段時間內的消費頻次。
“M”表示一段時間內的消費總額。
2)熟悉數據集
熟悉數據集,就是在進行數據處理之前,應該先熟悉數據,只有對數據充分熟悉之后,才能更好的進行分析。
熟悉數據常用的方法和屬性有shape、head()、tail()、sample()、info()、describe()。
df = pd.read_excel(r"C:Users黃偉DesktopRFM_ModelRFM.xlsx")
display(df.shape)
display(df.sample(5))
結果如下:

從上述結果中可以發現:這筆數據總共有28833行條記錄,12列。觀察上圖,可以清楚地看到每一列數據代表什么含義。
3)保留有效數據
針對此數據集,我們先說一下什么是“有效數據”。“有效數據”指的就是有效購買,也就是說對應的“訂單狀態”字段顯示的是“交易成功”,對于“退款”的記錄,我們就直接將這個數據剔除掉。
display("剔除之前共有:"+ str(df.shape[0]) + "條記錄")
df = df[df["訂單狀態"]=="交易成功"]
display("剔除之后共有:"+ str(df.shape[0]) + "條記錄")
結果如下:

4)選取有效字段
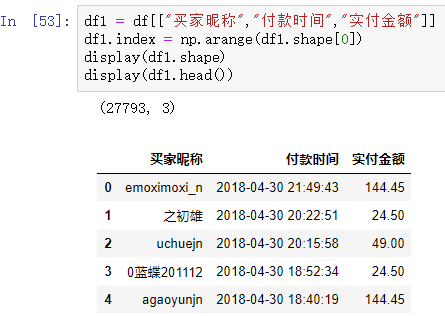
通過上面的分析,我們知道了“R”、“F”、“M”三個指標的概念。鑒于此,我們只需要選取"買家昵稱",“付款時間”,"實付金額"這三個字段,用于RFM模型的構建,其余字段用處不大,因此刪除其余字段。
df1 = df[["買家昵稱","付款時間","實付金額"]]
df1.index = np.arange(df1.shape[0])
display(df1.shape)
display(df1.head())
結果如下:
5)缺失值處理
df1.isnull().sum(axis=0)
結果如下:

從上述結果中可以發現:各字段中沒有缺失值,因此不需要做任何處理。
RFM建模過程
1)計算RFM三個指標
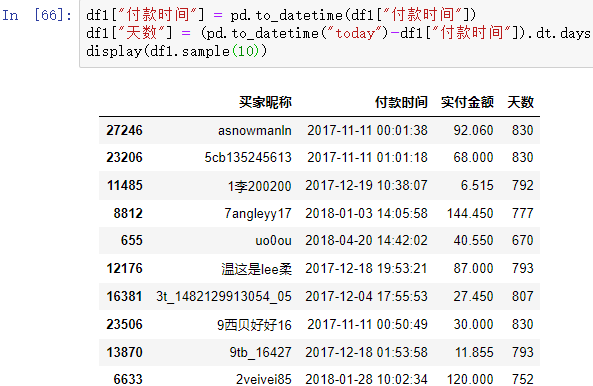
① 增加“天數”字段,用于計算“R”指標
針對上述“R”、“F”、“M”三個指標的概念,我們對數據做一定的處理。由于 “R”表示的是最近一次消費時間距離今天共有多少天。但是數據集中只有每一天的“付款時間”字段。因此計算RFM指標之前,需要事先添加一個“天數”字段,求出每個“付款時間”距今共有多少天。“天數”越小,就表示最近一次的消費時間。
然后針對上述處理后的數據,做一個數據透視表。以“買家昵稱”作為分組字段,對“天數”求最小值;對“付款昵稱”計數;對“實付金額”求和,就可以得到我們想要的RFM三個指標。
df1["付款時間"] = pd.to_datetime(df1["付款時間"])
df1["天數"] = (pd.to_datetime("today")-df1["付款時間"]).dt.days
display(df1.sample(10))
結果如下:
② 計算RFM三個指標
df2 = pd.pivot_table(df1,index="買家昵稱",
values=["買家昵稱","天數","實付金額"],
aggfunc={"買家昵稱":"count","天數":"min","實付金額":"sum"})
df2 = df2[["天數","買家昵稱","實付金額"]]
df2.columns = ["R","F","M"]
df2.reset_index()
display(df2.shape)
display(df2.head(10))
結果如下:

2)用戶分層打分
通過上述分析,我們已經得到了每一個用戶的“R”、“F”、“M”值。接下來要做的,就是給每一個用戶進行分層。這里我們需要建立一個評判標準,由于RFM模型本身就是需要根據不同場景和業務需求來建立的,因此這個分層標準,也是需要我們溝通業務后,得到最后的分層標準。
以R指標為例進行說明,根據上表我們知道,R表示每個用戶最后一次購買時間距離今天共經歷了多少天。當這個值越小,說明用戶近期又回購了此產品;當這個值越大,說明用戶已經好久沒有再次購買產品了,這個用戶很有可能流失掉了(猜測)。
基于上述分析,我們采用通用的5分制打分法,對RFM進行分類打分。
說明:由于這個數據集時間較早,因此計算出來的最近一次購買時間距離今天的天數,會特別大,但是沒有關系,我們演示這個案例只是為了說明RFM模型的建模過程,實際中,肯定是過幾個月進行一次RFM建模是比較好的,這里你只需要知道原理就好。
對于R指標來說:我們可以求出,R指標最小值是660天,我們以30天作為時間間隔,660-690天,打5分;690-720,打4分;720-750打3分;750-780打2分;>780,打1分。
對于F指標來說:我們可以求出,F指標最小值是1次,我們以1次作為時間間隔,0-2,打1分;2-3,打2分;3-4,打3分;4-5,打4分;>5,打5分。
對于M指標來說:我們可以求出,M指標最小值是0.005元,我們以500元作為時間間隔,0-50,打1分;50-100,打2分;100-150,打3分;150-200,打4分;>200,打5分。
至此,我們已經建立好了打分標準,下面我們開始對每個用戶進行分類打分。
def func1(x):
if x >=660and x< 690:
return5
elif x >=690and x< 720:
return4
elif x >=720and x< 750:
return3
elif x >=750and x< 780:
return2
elif x >=780:
return1
def func2(x):
if x >=0and x< 2:
return1
elif x >=2and x< 3:
return2
elif x >=3and x< 4:
return3
elif x >=4and x< 5:
return4
elif x >=5:
return5
def func3(x):
if x >=0and x< 50:
return1
elif x >=50and x< 100:
return2
elif x >=100and x< 150:
return3
elif x >=150and x< 200:
return4
elif x >=200:
return5
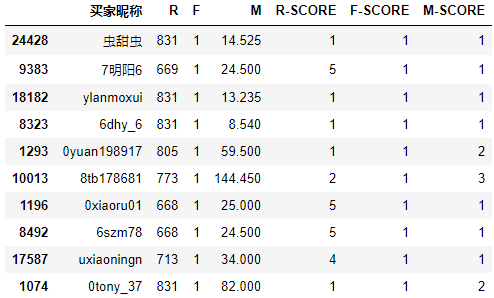
df2["R-SCORE"] = df2["R"].apply(func1)
df2["F-SCORE"] = df2["F"].apply(func2)
df2["M-SCORE"] = df2["M"].apply(func3)
df2.sample(10)
結果如下:
3)用戶貼標簽
前面的步驟中,我們已經根據業務需求,對RFM指標進行了分類打分,得到了R-SCORE、F-SCORE、M-SCORE三個指標。接下來,我們需要給每個用戶貼標簽,這里有兩種方式可以進行用戶貼標簽。
第一種:根據業務場景和業務來分配全重,對于RFM這3個指標,你更看重哪個指標,就賦予它相應較大一點的權重,比如說賦予的權重是3:1:2。
第二種:完全根據單獨的RFM標簽來計算,比如說:R-SCORE>avg(R-SCORE)、F-SCORE>avg(F-SCORE)、M-SCORE>avg(M-SCORE),表示一個客戶近期有購買,購買頻率高于所有客戶平均購買頻率,購買金額高于所有客戶的平均購買金額,因此我們貼上一個“重要挽留客戶”的標簽。
下面以第二種方法進行說明。根據上述敘述,每個指標有兩種情況,要么>avg(),要么avg(),我們記為1;當指標

① 第一步
avg_r = df2["R-SCORE"].mean()
avg_f = df2["F-SCORE"].mean()
avg_m = df2["M-SCORE"].mean()
display(avg_r,avg_f,avg_m)
結果如下:

② 第二步
def func1(x):
if x >avg_r:
return1
else:
return0
def func2(x):
if x >avg_f:
return1
else:
return0
def func3(x):
if x >avg_m:
return1
else:
return0
df2["R-SCORE是否大于均值"] = df2["R-SCORE"].apply(func1)
df2["F-SCORE是否大于均值"] = df2["F-SCORE"].apply(func1)
df2["M-SCORE是否大于均值"] = df2["M-SCORE"].apply(func1)
display(df2.sample(10))
結果如下:

③ 第三步
def functions(x):
if x.iloc[0]==1and x.iloc[1]==1and x.iloc[2]==1:
return"重要價值客戶"
elif x.iloc[0]==1and x.iloc[1]==1and x.iloc[2]==0:
return"潛力客戶"
elif x.iloc[0]==1and x.iloc[1]==0and x.iloc[2]==1:
return"重要深耕客戶"
elif x.iloc[0]==1and x.iloc[1]==0and x.iloc[2]==0:
return"新客戶"
elif x.iloc[0]==0and x.iloc[1]==1and x.iloc[2]==1:
return"重要喚回客戶"
elif x.iloc[0]==0and x.iloc[1]==1and x.iloc[2]==0:
return"一般客戶"
elif x.iloc[0]==0and x.iloc[1]==0and x.iloc[2]==1:
return"重要挽回客戶"
elif x.iloc[0]==0and x.iloc[1]==0and x.iloc[2]==0:
return"流失客戶"
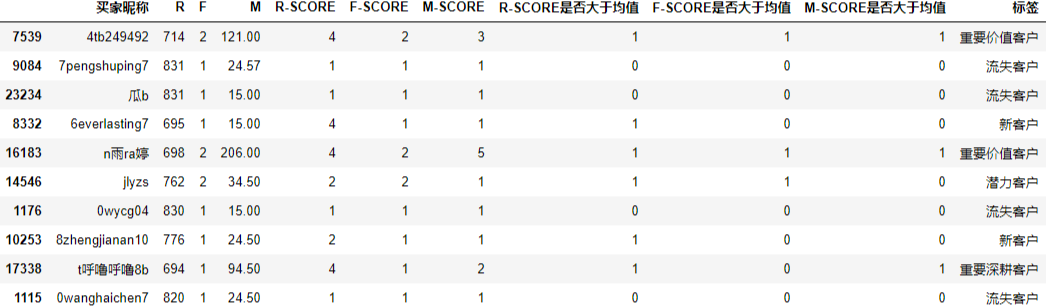
df2["標簽"] = df2[["R-SCORE是否大于均值","F-SCORE是否大于均值","M-SCORE是否大于均值"]].apply(functions,axis=1)
df2.sample(10)
結果如下:
4)可視化展示
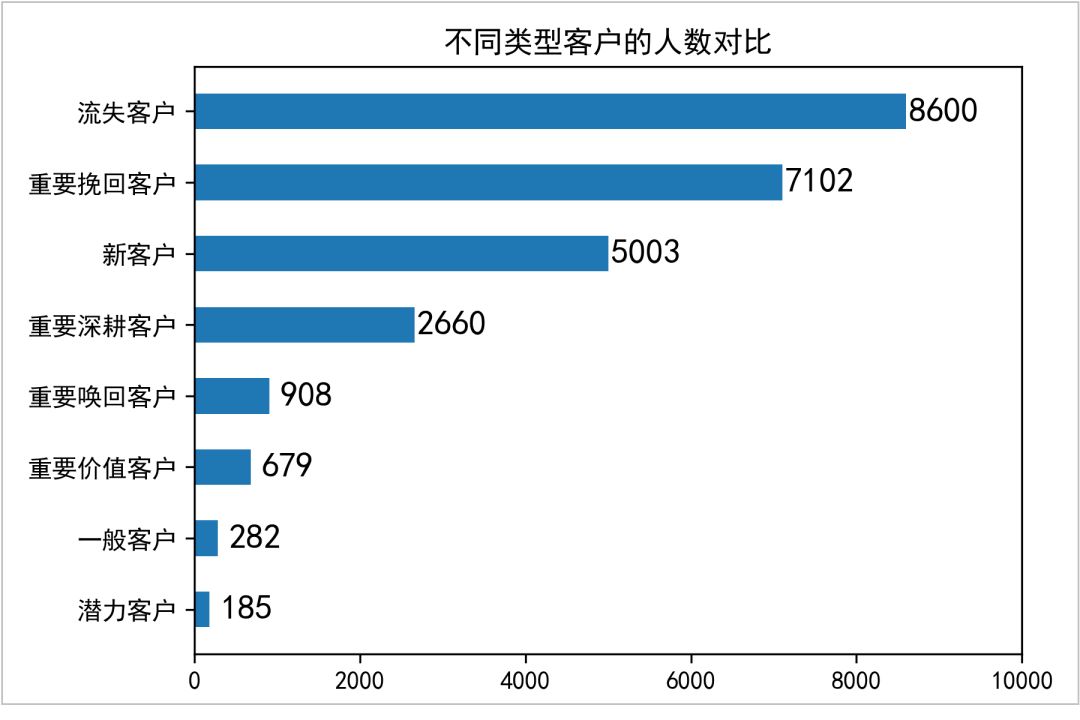
① 繪制不同類型客戶的人數對比
df3 = df2.groupby("標簽").agg({"標簽":"count"})
df3["不同客戶的占比"] = df3["標簽"].apply(lambda x:x/np.sum(df3["標簽"]))
df3 = df3.sort_values(by="標簽",ascending=True)
plt.figure(figsize=(6,4),dpi=100)
x = df3.index
y = df3["標簽"]
plt.barh(x,height=0.5,width=y,align="center")
plt.title("不同類型客戶的人數對比")
for x,y in enumerate(y):
plt.text(y+450,x,y,ha="center",va="center",fontsize=14)
plt.xticks(np.arange(0,10001,2000))
plt.tight_layout()
plt.savefig("不同類型客戶的人數對比",dpi=300)
結果如下:
② 繪制不同類型客戶人數占比圖
df3 = df2.groupby("標簽").agg({"標簽":"count"})
df3["不同客戶的占比"] = df3["標簽"].apply(lambda x:x/np.sum(df3["標簽"]))
df3 = df3.sort_values(by="標簽",ascending=True)
plt.figure(figsize=(7,4),dpi=100)
x = df3["不同客戶的占比"]
labels = ['潛力客戶', '一般客戶', '重要價值客戶', '重要喚回客戶', '重要深耕客戶', '新客戶', '重要挽回客戶', '流失客戶']
colors = ['#9999ff','#ff9999','#7777aa','#2442aa','#dd5555','deeppink','yellowgreen','lightskyblue']
explode = [0,0,0,0,0,0,0,0]
patches,l_text = plt.pie(x,labels=labels,colors=colors,
explode=explode,startangle=90,counterclock=False)
for t in l_text:
t.set_size(0)
plt.axis("equal")
plt.legend(loc=(0.001,0.001),frameon=False)
plt.title("不同類型客戶人數占比圖")
plt.savefig("不同類型客戶人數占比圖",dpi=300)
結果如下:

③ 繪制不同類型客戶累計消費金額
df3 = df2.groupby("標簽").agg({"M":"sum"})
df3["M"] = df3["M"].apply(lambda x:round(x))
df3["不同客戶的占比"] = df3["M"].apply(lambda x:x/np.sum(df3["M"]))
df3 = df3.sort_values(by="M",ascending=True)
plt.figure(figsize=(6,4),dpi=100)
x = df3.index
y = df3["M"]
plt.barh(x,height=0.5,width=y,align="center")
plt.title("不同類型客戶累計消費金額")
for x,y in enumerate(y):
plt.text(y+45000,x,y,ha="center",va="center",fontsize=14)
plt.xticks(np.arange(0,700001,100000))
plt.tight_layout()
plt.savefig("不同類型客戶累計消費金額",dpi=300)
結果如下:

④ 繪制不同類型客戶金額占比圖
df3 = df2.groupby("標簽").agg({"M":"sum"})
df3["M"] = df3["M"].apply(lambda x:round(x))
df3["不同客戶的占比"] = df3["M"].apply(lambda x:x/np.sum(df3["M"]))
df3 = df3.sort_values(by="M",ascending=True)
plt.figure(figsize=(7,4),dpi=100)
x = df3["不同客戶的占比"]
labels = ['潛力客戶', '一般客戶', '重要價值客戶', '重要喚回客戶', '重要深耕客戶', '新客戶', '重要挽回客戶', '流失客戶']
colors = ['#9999ff','#ff9999','#7777aa','#2442aa','#dd5555','deeppink','yellowgreen','lightskyblue']
explode = [0,0,0,0,0,0,0,0]
patches,l_text= plt.pie(x,labels=labels,colors=colors,
explode=explode,startangle=90,counterclock=False)
for t in l_text:
t.set_size(0)
plt.axis("equal")
plt.legend(loc=(0.001,0.001),frameon=False)
plt.title("不同類型客戶金額占比圖")
plt.savefig("不同類型客戶金額占比圖",dpi=300)
-
建模
+關注
關注
1文章
309瀏覽量
60787 -
模型
+關注
關注
1文章
3261瀏覽量
48914 -
RFM
+關注
關注
0文章
5瀏覽量
7062 -
python
+關注
關注
56文章
4798瀏覽量
84810
發布評論請先 登錄
相關推薦
!RFM151 RFM 151有線電視射頻分析儀.(歐陽R/
RI-RFM-008B RI-RFM-008B, RI-ACC-008B
RI-RFM-007B RI-RFM-007B, RI-RFM-008B, RI-ACC-008B
基于Python語言的RFM模型講解
如何用Python計算提高機器學習算法和結果
python有什么用 如何用python創建數據庫
如何用Python來實現文件系統的操作功能







 工商網監
工商網監
評論