 如何讓網絡模型加速訓練
如何讓網絡模型加速訓練
如果我們使用的 數據集較大 ,且 網絡較深 ,則會造成 訓練較慢 ,此時我們要想加速訓練可以使用 Pytorch的AMP ( autocast與Gradscaler );本文便是依據此寫出的博文,對 Pytorch的AMP (autocast與Gradscaler進行對比) 自動混合精度對模型訓練加速 。
注意Pytorch1.6+,已經內置torch.cuda.amp,因此便不需要加載NVIDIA的apex庫(半精度加速),為方便我們便 不使用NVIDIA的apex庫 (安裝麻煩),轉而 使用torch.cuda.amp 。
AMP (Automatic mixed precision): 自動混合精度,那 什么是自動混合精度 ?
先來梳理一下歷史:先有NVIDIA的apex,之后NVIDIA的開發人員將其貢獻到Pytorch 1.6+產生了torch.cuda.amp[這是筆者梳理,可能有誤,請留言]
詳細講:默認情況下,大多數深度學習框架都采用32位浮點算法進行訓練。2017年,NVIDIA研究了一種用于混合精度訓練的方法(apex),該方法在訓練網絡時將單精度(FP32)與半精度(FP16)結合在一起,并使用相同的超參數實現了與FP32幾乎相同的精度,且速度比之前快了不少
之后,來到了AMP時代(特指torch.cuda.amp),此有兩個關鍵詞:自動與 混合精度 (Pytorch 1.6+中的torch.cuda.amp)其中,自動表現在Tensor的dtype類型會自動變化,框架按需自動調整tensor的dtype,可能有些地方需要手動干預;混合精度表現在采用不止一種精度的Tensor, torch.FloatTensor與torch.HalfTensor。并且從名字可以看出torch.cuda.amp,這個功能 只能在cuda上使用 !
為什么我們要使用AMP自動混合精度?
1.減少顯存占用(FP16優勢)
2.加快訓練和推斷的計算(FP16優勢)
3.張量核心的普及(NVIDIA Tensor Core),低精度(FP16優勢)
- 混合精度訓練緩解舍入誤差問題,(FP16有此劣勢,但是FP32可以避免此)
5.損失放大,可能使用混合精度還會出現無法收斂的問題[其原因時激活梯度值較小],造成了溢出,則可以通過使用torch.cuda.amp.GradScaler放大損失來防止梯度的下溢
申明此篇博文主旨為 如何讓網絡模型加速訓練 ,而非去了解其原理,且其以AlexNet為網絡架構(其需要輸入的圖像大小為227x227x3),CIFAR10為數據集,Adamw為梯度下降函數,學習率機制為ReduceLROnPlateau舉例。使用的電腦是2060的拯救者,雖然渣,但是還是可以搞搞這些測試。
本文從1.沒使用DDP與DP訓練與評估代碼(之后加入amp),2.分布式DP訓練與評估代碼(之后加入amp),3.單進程占用多卡DDP訓練與評估代碼(之后加入amp) 角度講解。
運行此程序時,文件的結構:
D:/PycharmProject/Simple-CV-Pytorch-master
|
|
|
|----AMP(train_without.py、train_DP.py、train_autocast.py、train_GradScaler.py、eval_XXX.py
|等,之后加入的alexnet也在這里,alexnet.py)
|
|
|
|----tensorboard(保存tensorboard的文件夾)
|
|
|
|----checkpoint(保存模型的文件夾)
|
|
|
|----data(數據集所在文件夾)
1.沒使用DDP與DP訓練與評估代碼
沒使用DDP與DP的訓練與評估實驗,作為我們實驗的參照組
(1)原本模型的訓練與評估源碼:
訓練源碼:
注意:此段代碼無比簡陋,僅為代碼的雛形,大致能理解尚可!
train_without.py
import time
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision.models import alexnet
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
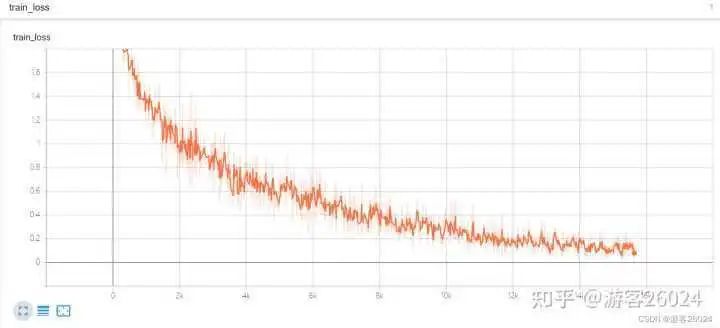
運行結果:
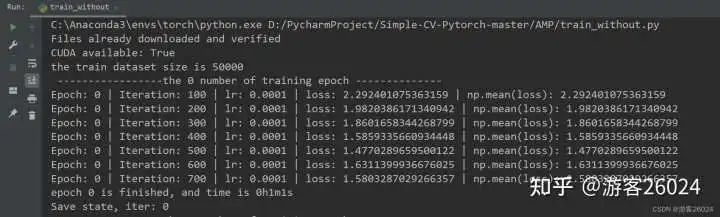
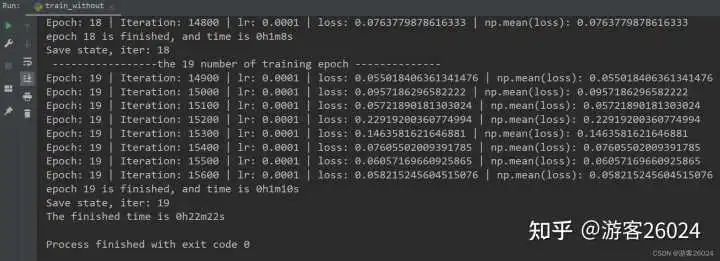
Tensorboard觀察:

評估源碼:
代碼特別粗獷,尤其是device與精度計算,僅供參考,切勿模仿!
eval_without.py
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from alexnet import alexnet
import argparse
# eval
def parse_args():
parser = argparse.ArgumentParser(description='CV Evaluation')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create model
model = alexnet()
# 2.Ready Dataset
if args.dataset == 'CIFAR10':
test_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=False,
transform=transforms.Compose(
[transforms.Resize(args.img_size),
transforms.ToTensor()]),
download=True)
else:
raise ValueError("Dataset is not CIFAR10")
# 3.Length
test_dataset_size = len(test_dataset)
print("the test dataset size is {}".format(test_dataset_size))
# 4.DataLoader
test_dataloader = DataLoader(dataset=test_dataset, batch_size=args.batch_size)
# 5. Set some parameters for testing the network
total_accuracy = 0
# test
model.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
device = torch.device('cpu')
imgs, targets = imgs.to(device), targets.to(device)
model_load = torch.load("{}/AlexNet.pth".format(args.checkpoint), map_location=device)
model.load_state_dict(model_load)
outputs = model(imgs)
outputs = outputs.to(device)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
accuracy = total_accuracy / test_dataset_size
print("the total accuracy is {}".format(accuracy))
運行結果:

分析:
原本模型訓練完20個epochs花費了22分22秒,得到的準確率為0.8191
(2)原本模型加入autocast的訓練與評估源碼:
訓練源碼:
訓練大致代碼流程:
from torch.cuda.amp import autocast as autocast
...
# Create model, default torch.FloatTensor
model = Net().cuda()
# SGD,Adm, Admw,...
optim = optim.XXX(model.parameters(),..)
...
for imgs,targets in dataloader:
imgs,targets = imgs.cuda(),targets.cuda()
....
with autocast():
outputs = model(imgs)
loss = loss_fn(outputs,targets)
...
optim.zero_grad()
loss.backward()
optim.step()
...
train_autocast_without.py
import time
import torch
import torchvision
from torch import nn
from torch.cuda.amp import autocast
from torchvision import transforms
from torchvision.models import alexnet
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
運行結果:
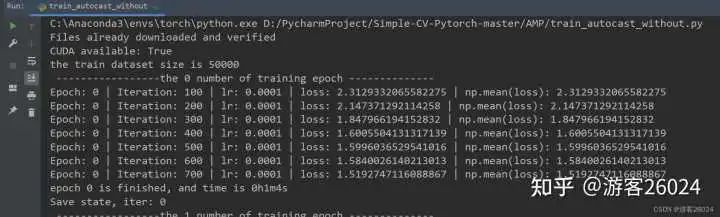

Tensorboard觀察:

評估源碼:
eval_without.py 和 1.(1)一樣
運行結果:

分析:
原本模型訓練完20個epochs花費了22分22秒,加入autocast之后模型花費的時間為21分21秒,說明模型速度增加了,并且準確率從之前的0.8191提升到0.8403
(3)原本模型加入autocast與GradScaler的訓練與評估源碼:
使用torch.cuda.amp.GradScaler是放大損失值來防止梯度的下溢
訓練源碼:
訓練大致代碼流程:
from torch.cuda.amp import autocast as autocast
from torch.cuda.amp import GradScaler as GradScaler
...
# Create model, default torch.FloatTensor
model = Net().cuda()
# SGD,Adm, Admw,...
optim = optim.XXX(model.parameters(),..)
scaler = GradScaler()
...
for imgs,targets in dataloader:
imgs,targets = imgs.cuda(),targets.cuda()
...
optim.zero_grad()
....
with autocast():
outputs = model(imgs)
loss = loss_fn(outputs,targets)
scaler.scale(loss).backward()
scaler.step(optim)
scaler.update()
...
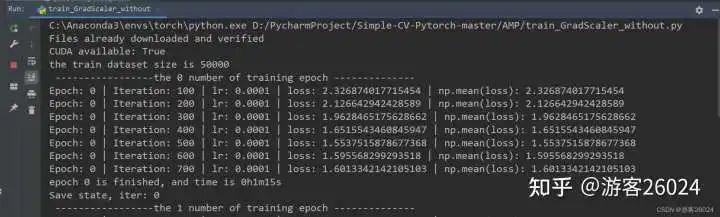
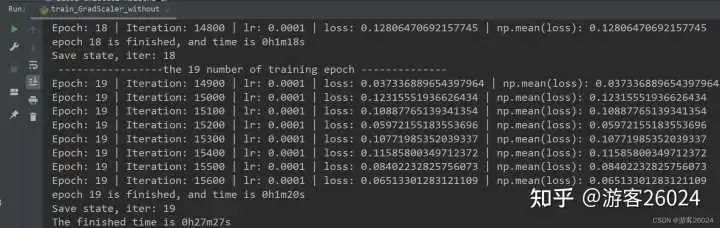
train_GradScaler_without.py
import time
import torch
import torchvision
from torch import nn
from torch.cuda.amp import autocast, GradScaler
from torchvision import transforms
from torchvision.models import alexnet
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
scaler = GradScaler()
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
optim.zero_grad()
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
scaler.scale(loss_train).backward()
scaler.step(optim)
scaler.update()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
運行結果:
Tensorboard觀察:
評估源碼:
eval_without.py 和 1.(1)一樣
運行結果:

分析:
為什么,我們訓練完20個epochs花費了27分27秒,比之前原模型未使用任何amp的時間(22分22秒)都多了?
這是因為我們使用了GradScaler放大了損失降低了模型訓練的速度,還有個原因可能是筆者自身的顯卡太小,沒有起到加速的作用
2.分布式DP訓練與評估代碼
(1)DP原本模型的訓練與評估源碼:
訓練源碼:
train_DP.py
import time
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision.models import alexnet
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
運行結果:
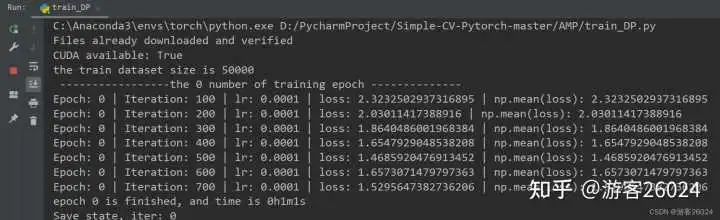
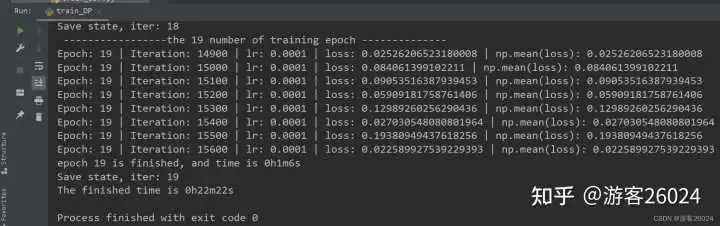
Tensorboard觀察:
評估源碼:
eval_DP.py
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from alexnet import alexnet
import argparse
# eval
def parse_args():
parser = argparse.ArgumentParser(description='CV Evaluation')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create model
model = alexnet()
model = torch.nn.DataParallel(model)
# 2.Ready Dataset
if args.dataset == 'CIFAR10':
test_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=False,
transform=transforms.Compose(
[transforms.Resize(args.img_size),
transforms.ToTensor()]),
download=True)
else:
raise ValueError("Dataset is not CIFAR10")
# 3.Length
test_dataset_size = len(test_dataset)
print("the test dataset size is {}".format(test_dataset_size))
# 4.DataLoader
test_dataloader = DataLoader(dataset=test_dataset, batch_size=args.batch_size)
# 5. Set some parameters for testing the network
total_accuracy = 0
# test
model.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
device = torch.device('cpu')
imgs, targets = imgs.to(device), targets.to(device)
model_load = torch.load("{}/AlexNet.pth".format(args.checkpoint), map_location=device)
model.load_state_dict(model_load)
outputs = model(imgs)
outputs = outputs.to(device)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
accuracy = total_accuracy / test_dataset_size
print("the total accuracy is {}".format(accuracy))
運行結果:

(2)DP使用autocast的訓練與評估源碼:
訓練源碼:
如果你 這樣寫代碼 ,那么你的代碼 無效 !!!
...
model = Model()
model = torch.nn.DataParallel(model)
...
with autocast():
output = model(imgs)
loss = loss_fn(output)
正確寫法 ,訓練大致流程代碼:
1.Model(nn.Module):
@autocast()
def forward(self, input):
...
2.Model(nn.Module):
def foward(self, input):
with autocast():
...
1與2皆可,之后:
...
model = Model()
model = torch.nn.DataParallel(model)
with autocast():
output = model(imgs)
loss = loss_fn(output)
...
模型:
須在forward函數上加入@autocast()或者在forward里面最上面加入with autocast():
alexnet.py
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
from torch.cuda.amp import autocast
from typing import Any
__all__ = ['AlexNet', 'alexnet']
model_urls = {
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',
}
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) - > None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
@autocast()
def forward(self, x: torch.Tensor) - > torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def alexnet(pretrained: bool = False, progress: bool = True, **kwargs: Any) - > AlexNet:
r"""AlexNet model architecture from the
`"One weird trick..." < https://arxiv.org/abs/1404.5997 >`_ paper.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
model = AlexNet(**kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls["alexnet"],
progress=progress)
model.load_state_dict(state_dict)
return model
train_DP_autocast.py 導入自己的alexnet.py
import time
import torch
from alexnet import alexnet
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.cuda.amp import autocast as autocast
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
運行結果:

Tensorboard觀察:
評估源碼:
eval_DP.py 相比與2. (1)導入自己的alexnet.py
運行結果:

分析:
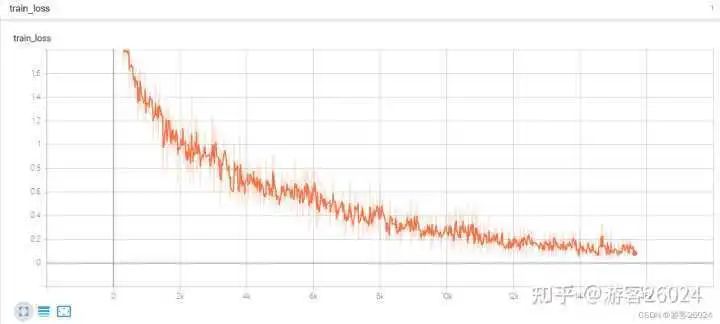
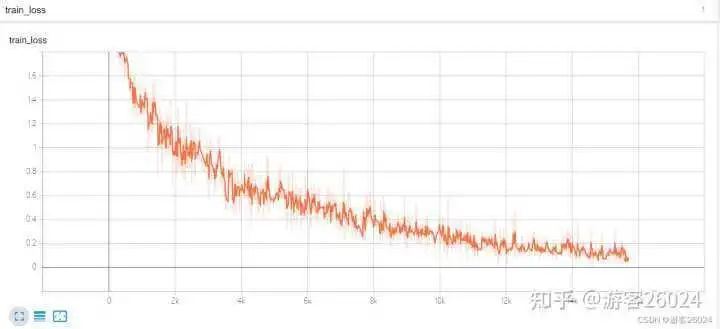
可以看出DP使用autocast訓練完20個epochs時需要花費的時間是21分21秒,相比與之前DP沒有使用的時間(22分22秒)快了1分1秒
之前DP未使用amp能達到準確率0.8216,而現在準確率降低到0.8188,說明還是使用自動混合精度加速還是對模型的準確率有所影響,后期可通過增大batch_sizel讓運行時間和之前一樣,但是準確率上升,來降低此影響
(3)DP使用autocast與GradScaler的訓練與評估源碼:
訓練源碼:
train_DP_GradScaler.py 導入自己的alexnet.py
import time
import torch
from alexnet import alexnet
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.cuda.amp import autocast as autocast
from torch.cuda.amp import GradScaler as GradScaler
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
scaler = GradScaler()
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
optim.zero_grad()
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
scaler.scale(loss_train).backward()
scaler.step(optim)
scaler.update()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
運行結果:
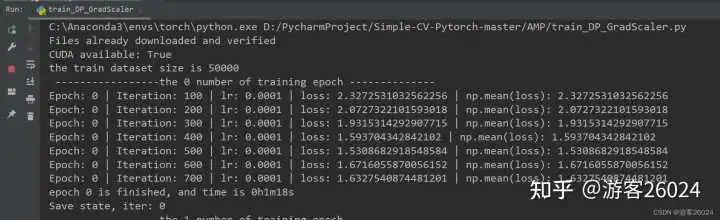
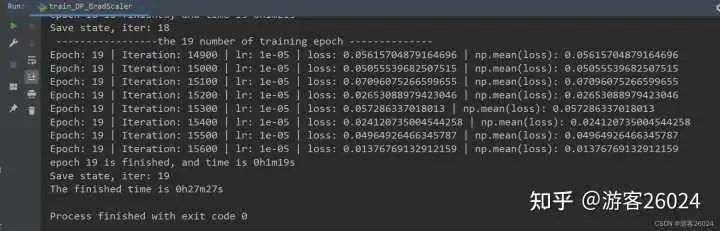
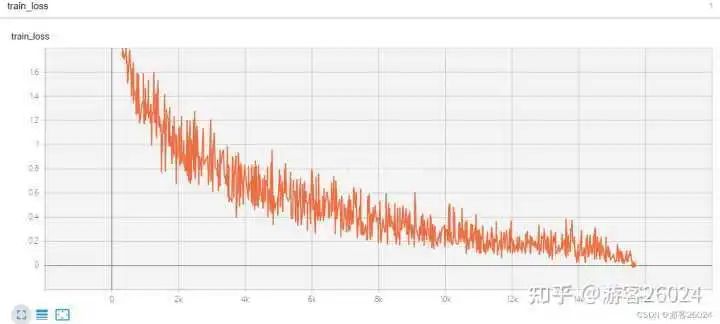
Tensorboard觀察:
評估源碼:
eval_DP.py 相比與2. (1)導入自己的alexnet.py
運行結果:

分析:
跟之前一樣,DP使用了GradScaler放大了損失降低了模型訓練的速度
現在DP使用了autocast與GradScaler的準確率為0.8409,相比與DP只使用autocast準確率0.8188還是有所上升,并且之前DP未使用amp是準確率(0.8216)也提高了不少
3.單進程占用多卡DDP訓練與評估代碼
(1)DDP原模型訓練與評估源碼:
訓練源碼:
train_DDP.py
import time
import torch
from torchvision.models.alexnet import alexnet
import torchvision
from torch import nn
import torch.distributed as dist
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def train():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size, sampler=train_sampler,
num_workers=2,
pin_memory=True)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model).cuda()
else:
model = torch.nn.parallel.DistributedDataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
train()
運行結果:

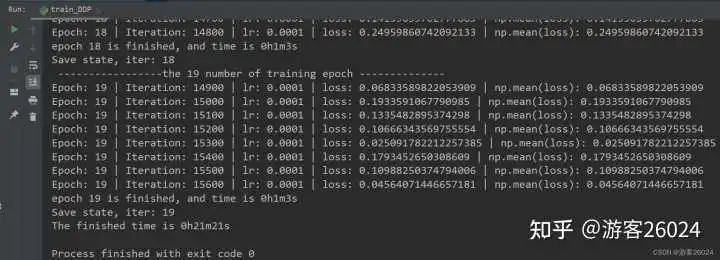
Tensorboard觀察:

評估源碼:
eval_DDP.py
import torch
import torchvision
import torch.distributed as dist
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
# from alexnet import alexnet
from torchvision.models.alexnet import alexnet
import argparse
# eval
def parse_args():
parser = argparse.ArgumentParser(description='CV Evaluation')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def eval():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create model
model = alexnet()
model = torch.nn.parallel.DistributedDataParallel(model)
# 2.Ready Dataset
if args.dataset == 'CIFAR10':
test_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=False,
transform=transforms.Compose(
[transforms.Resize(args.img_size),
transforms.ToTensor()]),
download=True)
else:
raise ValueError("Dataset is not CIFAR10")
# 3.Length
test_dataset_size = len(test_dataset)
print("the test dataset size is {}".format(test_dataset_size))
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
# 4.DataLoader
test_dataloader = DataLoader(dataset=test_dataset, sampler=test_sampler, batch_size=args.batch_size,
num_workers=2,
pin_memory=True)
# 5. Set some parameters for testing the network
total_accuracy = 0
# test
model.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
device = torch.device('cpu')
imgs, targets = imgs.to(device), targets.to(device)
model_load = torch.load("{}/AlexNet.pth".format(args.checkpoint), map_location=device)
model.load_state_dict(model_load)
outputs = model(imgs)
outputs = outputs.to(device)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
accuracy = total_accuracy / test_dataset_size
print("the total accuracy is {}".format(accuracy))
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
eval()
運行結果:

(2)DDP使用autocast的訓練與評估源碼:
訓練源碼:
train_DDP_autocast.py 導入自己的alexnet.py
import time
import torch
from alexnet import alexnet
import torchvision
from torch import nn
import torch.distributed as dist
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.cuda.amp import autocast as autocast
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def train():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size, sampler=train_sampler,
num_workers=2,
pin_memory=True)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model).cuda()
else:
model = torch.nn.parallel.DistributedDataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
train()
運行結果:
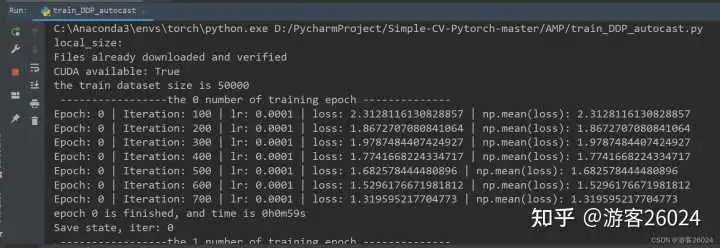
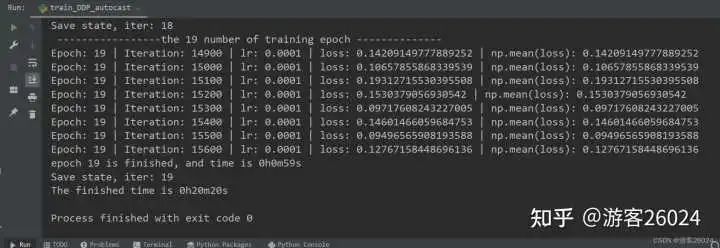
Tensorboard觀察:

評估源碼:
eval_DDP.py 導入自己的alexnet.py
import torch
import torchvision
import torch.distributed as dist
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from alexnet import alexnet
# from torchvision.models.alexnet import alexnet
import argparse
# eval
def parse_args():
parser = argparse.ArgumentParser(description='CV Evaluation')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def eval():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create model
model = alexnet()
model = torch.nn.parallel.DistributedDataParallel(model)
# 2.Ready Dataset
if args.dataset == 'CIFAR10':
test_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=False,
transform=transforms.Compose(
[transforms.Resize(args.img_size),
transforms.ToTensor()]),
download=True)
else:
raise ValueError("Dataset is not CIFAR10")
# 3.Length
test_dataset_size = len(test_dataset)
print("the test dataset size is {}".format(test_dataset_size))
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
# 4.DataLoader
test_dataloader = DataLoader(dataset=test_dataset, sampler=test_sampler, batch_size=args.batch_size,
num_workers=2,
pin_memory=True)
# 5. Set some parameters for testing the network
total_accuracy = 0
# test
model.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
device = torch.device('cpu')
imgs, targets = imgs.to(device), targets.to(device)
model_load = torch.load("{}/AlexNet.pth".format(args.checkpoint), map_location=device)
model.load_state_dict(model_load)
outputs = model(imgs)
outputs = outputs.to(device)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
accuracy = total_accuracy / test_dataset_size
print("the total accuracy is {}".format(accuracy))
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
eval()
運行結果:

分析:
從DDP未使用amp花費21分21秒,DDP使用autocast花費20分20秒,說明速度提升了
DDP未使用amp的準確率0.8224,之后DDP使用了autocast準確率下降到0.8162
(3)DDP使用autocast與GradScaler的訓練與評估源碼
訓練源碼:
train_DDP_GradScaler.py 導入自己的alexnet.py
import time
import torch
from alexnet import alexnet
import torchvision
from torch import nn
import torch.distributed as dist
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.cuda.amp import autocast as autocast
from torch.cuda.amp import GradScaler as GradScaler
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def train():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size, sampler=train_sampler,
num_workers=2,
pin_memory=True)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model).cuda()
else:
model = torch.nn.parallel.DistributedDataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
scaler = GradScaler()
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
optim.zero_grad()
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
scaler.scale(loss_train).backward()
scaler.step(optim)
scaler.update()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
train()
運行結果:

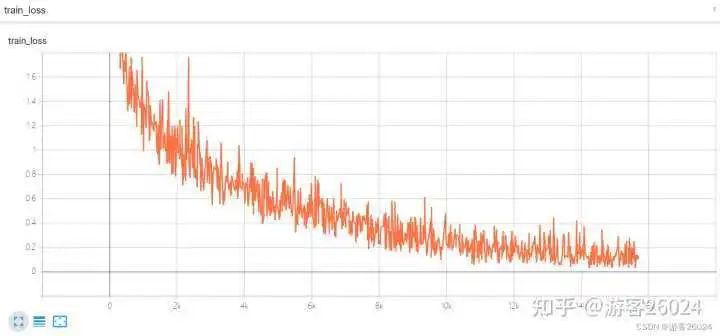
Tensorboard觀察:
評估源碼:
eval_DDP.py 與3. (2) 一樣,導入自己的alexnet.py
運行結果:
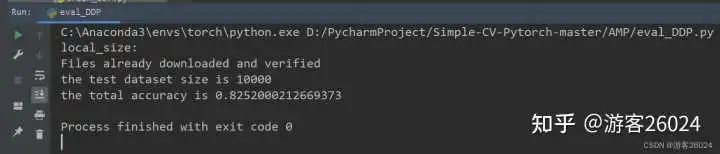
分析:
運行起來了,速度也比DDP未使用amp(用時21分21秒)快了不少(用時20分20秒),之前DDP未使用amp準確率到達0.8224,現在DDP使用了autocast與GradScaler的準確率達到0.8252,提升了
-
NVIDIA
+關注
關注
14文章
5107瀏覽量
104467 -
數據集
+關注
關注
4文章
1212瀏覽量
24990 -
網絡模型
+關注
關注
0文章
44瀏覽量
8550 -
深度學習
+關注
關注
73文章
5527瀏覽量
121878
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的預訓練
請問Labveiw如何調用matlab訓練好的神經網絡模型呢?
Pytorch模型訓練實用PDF教程【中文】
基于tensorflow.js設計、訓練面向web的神經網絡模型的經驗
如何利用Google Colab的云TPU加速Keras模型訓練
如何讓PyTorch模型訓練變得飛快?
基于預訓練模型和長短期記憶網絡的深度學習模型
利用視覺語言模型對檢測器進行預訓練
類GPT模型訓練提速26.5%,清華朱軍等人用INT4算法加速神經網絡訓練






 工商網監
工商網監
評論