 XGBoost 2.0介紹
XGBoost 2.0介紹
XGBoost是處理不同類型表格數據的最著名的算法,LightGBM 和Catboost也是為了修改他的缺陷而發布的。近日XGBoost發布了新的2.0版,本文除了介紹讓XGBoost的完整歷史以外,還將介紹新機制和更新。
這是一篇很長的文章,因為我們首先從梯度增強決策樹開始。
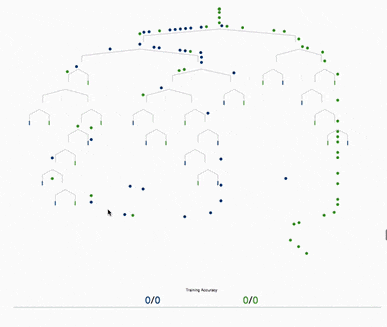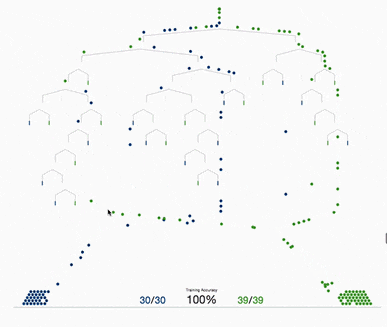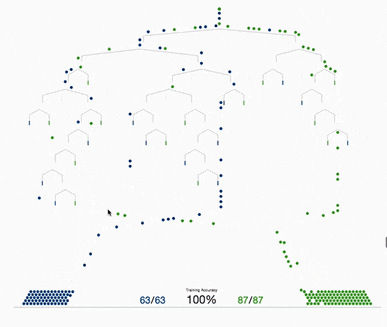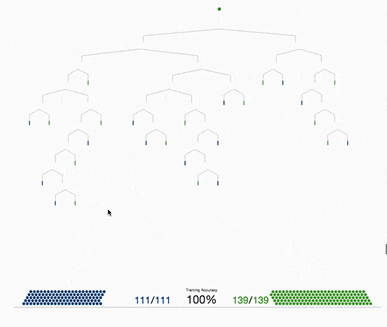
基于樹的方法,如決策樹、隨機森林以及擴展后的XGBoost,在處理表格數據方面表現出色,這是因為它們的層次結構天生就善于對表格格式中常見的分層關系進行建模。它們在自動檢測和整合特征之間復雜的非線性相互作用方面特別有效。另外這些算法對輸入特征的規模具有健壯性,使它們能夠在不需要規范化的情況下在原始數據集上表現良好。
最終要的一點是它們提供了原生處理分類變量的優勢,繞過了對one-hot編碼等預處理技術的需要,盡管XGBoost通常還是需要數字編碼。
另外還有一點是基于樹的模型可以輕松地可視化和解釋,這進一步增加了吸引力,特別是在理解表格數據結構時。通過利用這些固有的優勢,基于樹的方法——尤其是像XGBoost這樣的高級方法——非常適合處理數據科學中的各種挑戰,特別是在處理表格數據時。
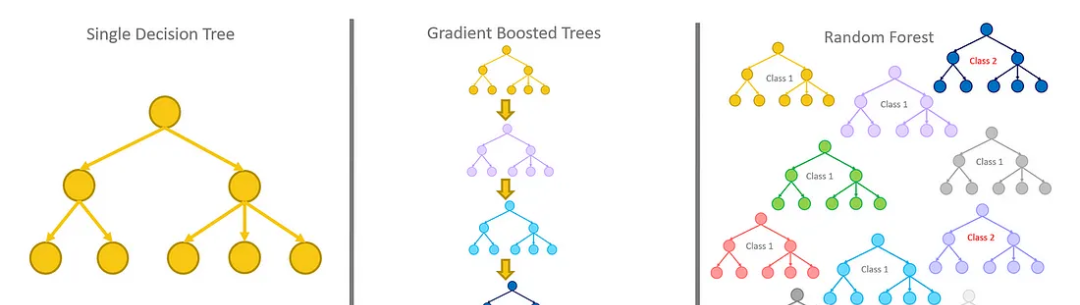
決策樹
在更嚴格的數學語言中,決策樹表示一個函數T:X→Y,其中X是特征空間,Y可以是連續值(在回歸的情況下)或類標簽(在分類的情況下)。我們可以將數據分布表示為D和真函數f:X→Y。決策樹的目標是找到與f(x)非常接近的T(x),理想情況下是在概率分布D上。
損失函數
與樹T相關的風險R相對于f表示為T(x)和f(x)之間的損失函數的期望值:
構建決策樹的主要目標是構建一個能夠很好地泛化到新的、看不見的數據的模型。在理想情況下,我們知道數據的真實分布D,可以直接計算任何候選決策樹的風險或預期損失。但是在實踐中真實的分布是未知的。
所以我們依賴于可用數據的子集來做出決策。這就是啟發式方法的概念出現的地方。
基尼系數
基尼指數是一種雜質度量,用于量化給定節點中類別的混合程度。給定節點t的基尼指數G的公式為:
式中p_i為節點t中屬于第i類樣本的比例,c為類的個數。
基尼指數的范圍從0到0.5,其中較低的值意味著節點更純粹(即主要包含來自一個類別的樣本)。
基尼指數還是信息增益?
基尼指數(Gini Index)和信息增益(Information Gain)都是量化區分不同階層的特征的“有用性”的指標。從本質上講,它們提供了一種評估功能將數據劃分為類的效果的方法。通過選擇雜質減少最多的特征(最低的基尼指數或最高的信息增益),就可以做出一個啟發式決策,這是樹生長這一步的最佳局部選擇。
過擬合和修剪
決策樹也會過度擬合,尤其是當它們很深的時候,會捕獲數據中的噪聲。有兩個主要策略可以解決這個問題:
- 分割:隨著樹的增長,持續監控它在驗證數據集上的性能。如果性能開始下降,這是停止生長樹的信號。
- 后修剪:在樹完全生長后,修剪不能提供太多預測能力的節點。這通常是通過刪除節點并檢查它是否會降低驗證準確性來完成的。如果不是則修剪節點。
找不到最優風險最小化的樹,是因為我們不知道真實的數據分布d。所以只能使用啟發式方法,如基尼指數或信息增益,根據可用數據局部優化樹,而謹慎分割和修剪等技術有助于管理模型的復雜性,避免過擬合。
隨機森林
隨機森林是決策樹T_1, T_2, ....的集合, T_n,其中每個決策樹T_i:X→Y將輸入特征空間X映射到輸出Y,輸出Y可以是連續值(回歸)或類標簽(分類)。
隨機森林集合定義了一個新函數R:X→Y,它對所有單個樹的輸出進行多數投票(分類)或平均(回歸),數學上表示為:

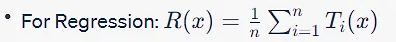
與決策樹一樣,隨機森林也旨在近似概率分布D上的真實函數f:X→Y。D在實踐中通常是未知的,因此有必要使用啟發式方法來構建單個樹。
與隨機森林相關的相對于f的風險R_RF是R(x)和f(x)之間損失函數的期望值。考慮到R是T的集合,風險通常低于與單個樹相關的風險,這有助于泛化:
過擬合和Bagging
與單一決策樹相比,隨機森林不太容易過度擬合,這要歸功于Bagging和特征隨機化,這在樹之間創造了多樣性。風險在多棵樹上平均,使模型對數據中的噪聲更有彈性。
隨機森林中的Bagging實現了多個目標:它通過在不同的樹上平均預測來減少過擬合,每棵樹都在不同的自舉樣本上訓練,從而使模型對數據中的噪聲和波動更具彈性。這也減少了方差可以得到更穩定和準確的預測。樹的集合可以捕獲數據的不同方面,提高了模型對未見數據的泛化。并且還可以提供更高的健壯性,因為來自其他樹的正確預測通常會抵消來自單個樹的錯誤。該技術可以增強不平衡數據集中少數類的表示,使集成更適合此類挑戰。
隨機森林它在單個樹級別采用啟發式方法,但通過集成學習減輕了一些限制,從而在擬合和泛化之間提供了平衡。Bagging和特征隨機化等技術進一步降低了風險,提高了模型的健壯性。
梯度增強決策樹
梯度增強決策樹(GBDT)也是一種集成方法,它通過迭代地增加決策樹來構建一個強預測模型,每棵新樹旨在糾正現有集成的錯誤。在數學上,GBDT也表示一個函數T:X→Y,但它不是找到一個單一的T(X),而是形成一個弱學習器t_1(X), t_2(X),…的序列,它們共同工作以近似真實函數f(X)。與隨機森林(Random Forest)通過Bagging獨立構建樹不同,GBDT在序列中構建樹,使用梯度下降最小化預測值和真實值之間的差異,通常通過損失函數表示。
在GBDT中,在構建每棵樹并進行預測之后,計算預測值與實際值之間的殘差(或誤差)。這些殘差本質上是梯度的一種形式——表明損失函數是如何隨其參數變化的。然后一個新的樹適合這些殘差,而不是原始的結果變量,有效地采取“步驟”,利用梯度信息最小化損失函數。這個過程是重復的,迭代地改進模型。
“梯度”一詞意味著使用梯度下降優化來指導樹的順序構建,旨在不斷最小化損失函數,從而使模型更具預測性。
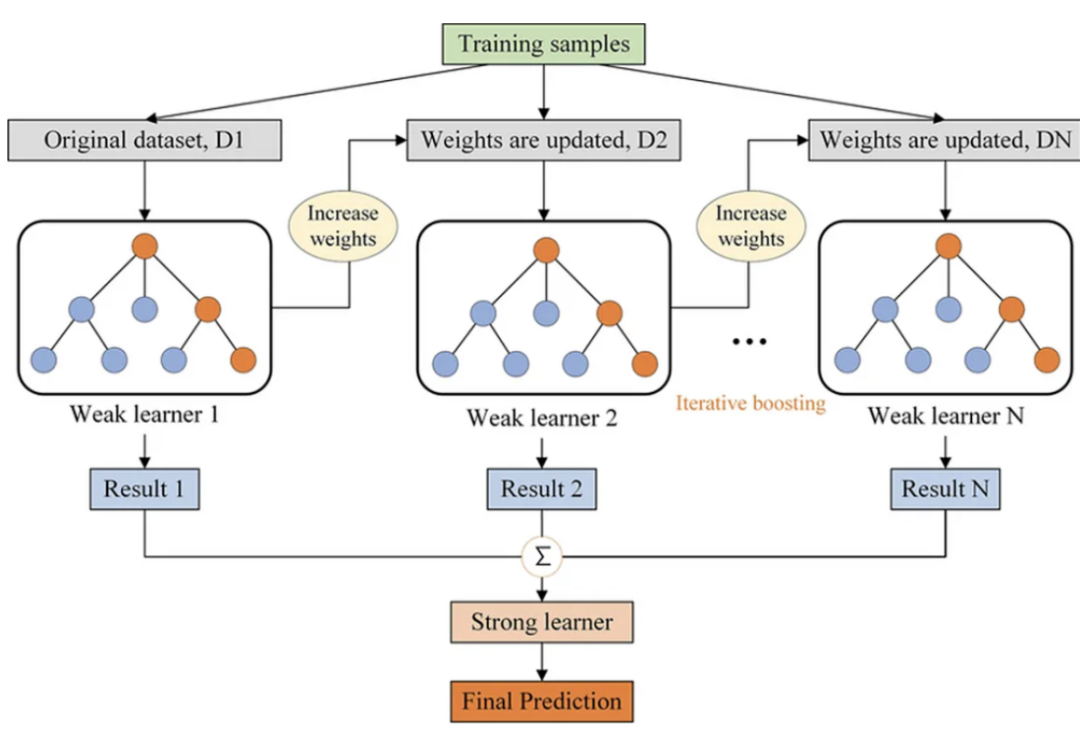
為什么它比決策樹和隨機森林更好?
- 減少過擬合:與隨機森林一樣,GBDT也避免過擬合,但它是通過構建淺樹(弱學習器)和優化損失函數來實現的,而不是通過平均或投票。
- 高效率:GBDT專注于難以分類的實例,更多地適應數據集的問題區域。這可以使它在分類性能方面比隨機森林更有效,因為隨機森林對所有實例都一視同仁。
- 優化損失函數:與啟發式方法(如基尼指數或信息增益)不同,GBDT中的損失函數在訓練期間進行了優化,允許更精確地擬合數據。
- 更好的性能:當選擇正確的超參數時,GBDT通常優于隨機森林,特別是在需要非常精確的模型并且計算成本不是主要關注點的情況下。
- 靈活性:GBDT既可以用于分類任務,也可以用于回歸任務,而且它更容易優化,因為您可以直接最小化損失函數。
梯度增強決策樹解決的問題
單個樹的高偏差:GBDT通過迭代修正單個樹的誤差,可以獲得比單個樹更高的性能。
模型復雜性:隨機森林旨在減少模型方差,而GBDT在偏差和方差之間提供了一個很好的平衡,通常可以獲得更好的整體性能。
梯度增強決策樹比決策樹和隨機森林具有性能、適應性和優化方面的優勢。當需要較高的預測準確性并愿意花費計算資源來微調模型時,它們特別有用。
XGBoost
在關于基于樹的集成方法的討論中,焦點經常落在標準的優點上:對異常值的健壯性、易于解釋等等。但是XGBoost還有其他特性,使其與眾不同,并在許多場景中具有優勢。
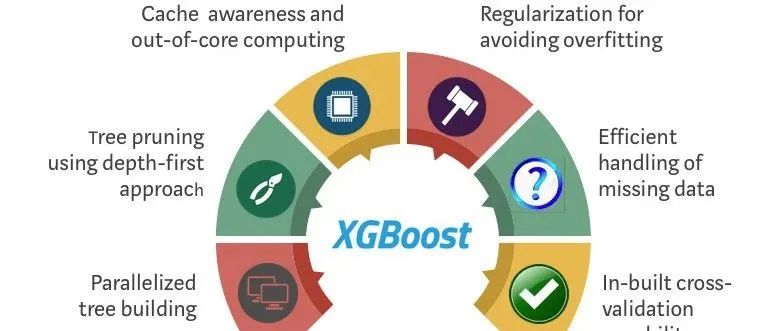
計算效率
通常,圍繞XGBoost的討論都集中在它的預測能力上。不常被強調的是它的計算效率,特別是在并行和分布式計算方面。該算法利用特征和數據點來并行化樹結構,使其能夠處理更大的數據集,并且比傳統實現運行得更快。
缺失數據的處理
XGBoost采用了一種獨特的方法來處理缺失值。與其他通常需要單獨預處理步驟的模型不同,XGBoost可以在內部處理丟失的數據。在訓練過程中,算法為缺失值找到最佳的imputation值(或在樹結構中移動的方向),然后將其存儲以供將來預測。這意味著XGBoost處理丟失數據的方法是自適應的,可以因節點而異,從而提供對這些值的更細致的處理。
正則化
雖然增強算法天生就容易過度擬合,特別是對于有噪聲的數據,但XGBoost在訓練過程中直接將L1 (Lasso)和L2 (Ridge)正則化合并到目標函數中。這種方法提供了一種額外的機制來約束單個樹的復雜性,而不是簡單地限制它們的深度,從而提高泛化。
稀疏性
XGBoost設計用于高效地處理稀疏數據,而不僅僅是密集矩陣。在使用詞袋或TF-IDF表示的自然語言處理等領域,特征矩陣的稀疏性可能是一個重大的計算挑戰。XGBoost利用壓縮的內存高效數據結構,其算法被設計為有效地遍歷稀疏矩陣。
硬件的優化
雖然很少被討論,但硬件優化是XGBoost的一個亮點。它對CPU上的內存效率和計算速度進行了優化,并支持GPU上的訓練模型,進一步加快了訓練過程。
特征重要性和模型可解釋性
大多數集成方法提供特征重要性度量,包括隨機森林和標準梯度增強。但是XGBoost提供了一套更全面的特性重要性度量,包括增益、頻率和覆蓋范圍,從而允許對模型進行更詳細的解釋。當需要了解哪些特征是重要的,以及它們如何對預測做出貢獻時,這一點非常重要。
早停策略
另一個未被討論的特性是提前停止。謹慎分割和修剪等技術用于防止過擬合,而XGBoost提供了一種更自動化的方法。一旦模型的性能在驗證數據集上停止改進,訓練過程就可以停止,從而節省了計算資源和時間。
處理分類變量
雖然基于樹的算法可以很好地處理分類變量,但是XGBoost采用了一種獨特的方法。不需要獨熱編碼或順序編碼,可以讓分類變量保持原樣。XGBoost對分類變量的處理比簡單的二進制分割更細致,可以捕獲復雜的關系,而無需額外的預處理。
XGBoost的獨特功能使其不僅是預測精度方面的最先進的機器學習算法,而且是高效和可定制的算法。它能夠處理現實世界的數據復雜性,如缺失值、稀疏性和多重共線性,同時計算效率高,并提供詳細的可解釋性,使其成為各種數據科學任務的寶貴工具。
XGBoost 2.0有什么新功能?
上面是我們介紹的一些背景知識,下面開始我們將介紹XGBoost 2.0提供了幾個有趣的更新,可能會影響機器學習社區和研究。
具有矢量葉輸出的多目標樹
前面我們談到了XGBoost中的決策樹是如何使用二階泰勒展開來近似目標函數的。在2.0中向具有矢量葉輸出的多目標樹轉變。這使得模型能夠捕捉目標之間的相關性,這一特征對于多任務學習尤其有用。它與XGBoost對正則化的強調一致,以防止過擬合,現在允許正則化跨目標工作。
設備參數
XGBoost可以使用不同硬件。在2.0版本中,XGBoost簡化了設備參數設置。“device”參數取代了多個與設備相關的參數,如gpu_id, gpu_hist等,這使CPU和GPU之間的切換更容易。
Hist作為默認樹方法
XGBoost允許不同類型的樹構建算法。2.0版本將' hist '設置為默認的樹方法,這可能會提高性能的一致性。這可以看作是XGBoost將基于直方圖的方法的效率提高了一倍。
基于gpu的近似樹方法
XGBoost的新版本還提供了使用GPU的“近似”樹方法的初始支持。這可以看作是進一步利用硬件加速的嘗試,這與XGBoost對計算效率的關注是一致的。
內存和緩存優化
2.0通過提供一個新參數(max_cached_hist_node)來控制直方圖的CPU緩存大小,并通過用內存映射替換文件IO邏輯來改進外部內存支持,從而延續了這一趨勢。
Learning-to-Rank增強
考慮到XGBoost在各種排名任務中的強大性能,2.0版本引入了許多特性來改進學習排名,例如用于配對構建的新參數和方法,支持自定義增益函數等等。
新的分位數回歸支持
結合分位數回歸XGBoost可以很好的適應對不同問題域和損失函數。它還為預測中的不確定性估計增加了一個有用的工具。
總結
很久沒有處理表格數據了,所以一直也沒有對XGBoost有更多的關注,但是最近才發現發更新了2.0版本,所以感覺還是很好的。
-
數據
+關注
關注
8文章
7223瀏覽量
90172 -
函數
+關注
關注
3文章
4353瀏覽量
63296 -
可視化
+關注
關注
1文章
1209瀏覽量
21233 -
XGBoost
+關注
關注
0文章
16瀏覽量
2270
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論