 最全綜述:圖像分割算法
最全綜述:圖像分割算法
圖像分割是計算機視覺研究中的一個經典難題,已經成為圖像理解領域關注的一個熱點,圖像分割是圖像分析的第一步,是計算機視覺的基礎,是圖像理解的重要組成部分,同時也是圖像處理中最困難的問題之一。所謂圖像分割是指根據灰度、彩色、空間紋理、幾何形狀等特征把圖像劃分成若干個互不相交的區域,使得這些特征在同一區域內表現出一致性或相似性,而在不同區域間表現出明顯的不同。簡單的說就是在一副圖像中,把目標從背景中分離出來。對于灰度圖像來說,區域內部的像素一般具有灰度相似性,而在區域的邊界上一般具有灰度不連續性。關于圖像分割技術,由于問題本身的重要性和困難性,從20世紀70年代起圖像分割問題就吸引了很多研究人員為之付出了巨大的努力。雖然到目前為止,還不存在一個通用的完美的圖像分割的方法,但是對于圖像分割的一般性規律則基本上已經達成的共識,已經產生了相當多的研究成果和方法。
本文對于目前正在使用的各種圖像分割方法進行了一定的歸納總結,由于筆者對于圖像分割的了解也是初窺門徑,所以難免會有一些錯誤,還望各位讀者多多指正,共同學習進步。
傳統分割方法
這一大部分我們將要介紹的是深度學習大火之前人們利用數字圖像處理、拓撲學、數學等方面的只是來進行圖像分割的方法。當然現在隨著算力的增加以及深度學習的不斷發展,一些傳統的分割方法在效果上已經不能與基于深度學習的分割方法相比較了,但是有些天才的思想還是非常值得我們去學習的。
1.基于閾值的分割方法
閾值法的基本思想是基于圖像的灰度特征來計算一個或多個灰度閾值,并將圖像中每個像素的灰度值與閾值作比較,最后將像素根據比較結果分到合適的類別中。因此,該方法最為關鍵的一步就是按照某個準則函數來求解最佳灰度閾值。
閾值法特別適用于目標和背景占據不同灰度級范圍的圖。
圖像若只有目標和背景兩大類,那么只需要選取一個閾值進行分割,此方法成為單閾值分割;但是如果圖像中有多個目標需要提取,單一閾值的分割就會出現作物,在這種情況下就需要選取多個閾值將每個目標分隔開,這種分割方法相應的成為多閾值分割。

如圖所示即為對數字的一種閾值分割方法。
閥值分割方法的優缺點:
計算簡單,效率較高;
只考慮像素點灰度值本身的特征,一般不考慮空間特征,因此對噪聲比較敏感,魯棒性不高。
從前面的介紹里我們可以看出,閾值分割方法的最關鍵就在于閾值的選擇。若將智能遺傳算法應用在閥值篩選上,選取能最優分割圖像的閥值,這可能是基于閥值分割的圖像分割法的發展趨勢。
2.基于區域的圖像分割方法
基于區域的分割方法是以直接尋找區域為基礎的分割技術,基于區域提取方法有兩種基本形式:一種是區域生長,從單個像素出發,逐步合并以形成所需要的分割區域;另一種是從全局出發,逐步切割至所需的分割區域。
區域生長
區域生長是從一組代表不同生長區域的種子像素開始,接下來將種子像素鄰域里符合條件的像素合并到種子像素所代表的生長區域中,并將新添加的像素作為新的種子像素繼續合并過程,知道找不到符合條件的新像素為止(小編研一第一學期的機器學習期末考試就是手寫該算法 T.T),該方法的關鍵是選擇合適的初始種子像素以及合理的生長準則。
區域生長算法需要解決的三個問題:
(1)選擇或確定一組能正確代表所需區域的種子像素;
(2)確定在生長過程中能將相鄰像素包括進來的準則;
(3)指定讓生長過程停止的條件或規則。
區域分裂合并
區域生長是從某個或者某些像素點出發,最終得到整個區域,進而實現目標的提取。而分裂合并可以說是區域生長的逆過程,從整幅圖像出發,不斷的分裂得到各個子區域,然后再把前景區域合并,得到需要分割的前景目標,進而實現目標的提取。其實如果理解了上面的區域生長算法這個區域分裂合并算法就比較好理解啦。
四叉樹分解法就是一種典型的區域分裂合并法,基本算法如下:
(1)對于任一區域,如果H(Ri)=FALSE就將其分裂成不重疊的四等分;
(2)對相鄰的兩個區域Ri和Rj,它們也可以大小不同(即不在同一層),如果條件H(RiURj)=TURE滿足,就將它們合并起來;
(3)如果進一步的分裂或合并都不可能,則結束。
其中R代表整個正方形圖像區域,P代表邏輯詞。
區域分裂合并算法優缺點:
(1)對復雜圖像分割效果好;
(2)算法復雜,計算量大;
(3)分裂有可能破怪區域的邊界。
在實際應用當中通常將區域生長算法和區域分裂合并算法結合使用,該類算法對某些復雜物體定義的復雜場景的分割或者對某些自然景物的分割等類似先驗知識不足的圖像分割效果較為理想。
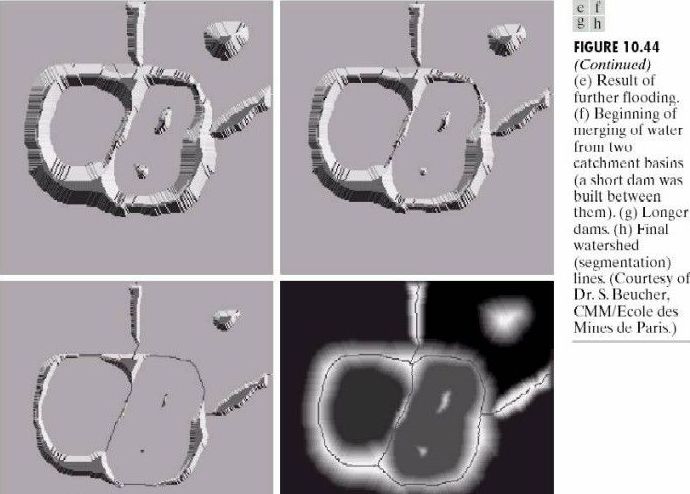
分水嶺算法
分水嶺算法是一個非常好理解的算法,它根據分水嶺的構成來考慮圖像的分割,現實中我們可以想象成有山和湖的景象,那么一定是如下圖的,水繞山山圍水的景象。
分水嶺分割方法,是一種基于拓撲理論的數學形態學的分割方法,其基本思想是把圖像看作是測地學上的拓撲地貌,圖像中每一點像素的灰度值表示該點的海拔高度,每一個局部極小值及其影響區域稱為集水盆,而集水盆的邊界則形成分水嶺。分水嶺的概念和形成可以通過模擬浸入過程來說明。在每一個局部極小值表面,刺穿一個小孔,然后把整個模型慢慢浸入水中,隨著浸入的加深,每一個局部極小值的影響域慢慢向外擴展,在兩個集水盆匯合處構筑大壩,即形成分水嶺。
分水嶺對微弱邊緣具有良好的響應,圖像中的噪聲、物體表面細微的灰度變化都有可能產生過度分割的現象,但是這也同時能夠保證得到封閉連續邊緣。同時,分水嶺算法得到的封閉的集水盆也為分析圖像的區域特征提供了可能。
3.基于邊緣檢測的分割方法
基于邊緣檢測的圖像分割算法試圖通過檢測包含不同區域的邊緣來解決分割問題。它可以說是人們最先想到也是研究最多的方法之一。通常不同區域的邊界上像素的灰度值變化比較劇烈,如果將圖片從空間域通過傅里葉變換到頻率域,邊緣就對應著高頻部分,這是一種非常簡單的邊緣檢測算法。
邊緣檢測技術通常可以按照處理的技術分為串行邊緣檢測和并行邊緣檢測。串行邊緣檢測是要想確定當前像素點是否屬于檢測邊緣上的一點,取決于先前像素的驗證結果。并行邊緣檢測是一個像素點是否屬于檢測邊緣高尚的一點取決于當前正在檢測的像素點以及與該像素點的一些臨近像素點。
最簡單的邊緣檢測方法是并行微分算子法,它利用相鄰區域的像素值不連續的性質,采用一階或者二階導數來檢測邊緣點。近年來還提出了基于曲面擬合的方法、基于邊界曲線擬合的方法、基于反應-擴散方程的方法、串行邊界查找、基于變形模型的方法。

邊緣檢測的優缺點:
(1)邊緣定位準確;
(2)速度快;
(3)不能保證邊緣的連續性和封閉性;
(4)在高細節區域存在大量的碎邊緣,難以形成一個大區域,但是又不宜將高細節區域分成小碎片;
由于上述的(3)(4)兩個難點,邊緣檢測只能產生邊緣點,而非完整意義上的圖像分割過程。這也就是說,在邊緣點信息獲取到之后還需要后續的處理或者其他相關算法相結合才能完成分割任務。
在以后的研究當中,用于提取初始邊緣點的自適應閾值選取、用于圖像的層次分割的更大區域的選取以及如何確認重要邊緣以去除假邊緣將變得非常重要。
結合特定工具的圖像分割算法
基于小波分析和小波變換的圖像分割方法
小波變換是近年來得到的廣泛應用的數學工具,也是現在數字圖像處理必學部分,它在時間域和頻率域上都有量高的局部化性質,能將時域和頻域統一于一體來研究信號。而且小波變換具有多尺度特性,能夠在不同尺度上對信號進行分析,因此在圖像分割方面的得到了應用,
二進小波變換具有檢測二元函數的局部突變能力,因此可作為圖像邊緣檢測工具。圖像的邊緣出現在圖像局部灰度不連續處,對應于二進小波變換的模極大值點。通過檢測小波變換模極大值點可以確定圖像的邊緣小波變換位于各個尺度上,而每個尺度上的小波變換都能提供一定的邊緣信息,因此可進行多尺度邊緣檢測來得到比較理想的圖像邊緣。
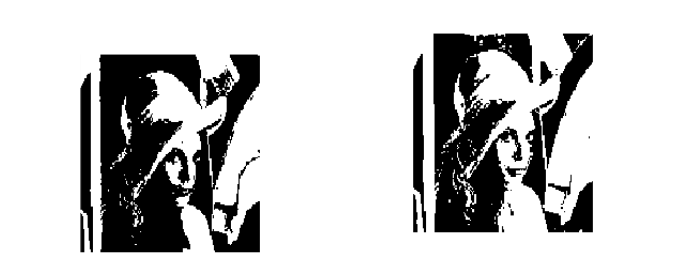
上圖左圖是傳統的閾值分割方法,右邊的圖像就是利用小波變換的圖像分割。可以看出右圖分割得到的邊緣更加準確和清晰
另外,將小波和其他方法結合起來處理圖像分割的問題也得到了廣泛研究,比如一種局部自適應閾值法就是將Hilbert圖像掃描和小波相結合,從而獲得了連續光滑的閾值曲線。
基于遺傳算法的圖像分割
遺傳算法(Genetic Algorithms,簡稱GA)是1973年由美國教授Holland提出的,是一種借鑒生物界自然選擇和自然遺傳機制的隨機化搜索算法。是仿生學在數學領域的應用。其基本思想是,模擬由一些基因串控制的生物群體的進化過程,把該過程的原理應用到搜索算法中,以提高尋優的速度和質量。此算法的搜索過程不直接作用在變量上,而是在參數集進行了編碼的個體,這使得遺傳算法可直接對結構對象(圖像)進行操作。整個搜索過程是從一組解迭代到另一組解,采用同時處理群體中多個個體的方法,降低了陷入局部最優解的可能性,并易于并行化。搜索過程采用概率的變遷規則來指導搜索方向,而不采用確定性搜索規則,而且對搜索空間沒有任何特殊要求(如連通性、凸性等),只利用適應性信息,不需要導數等其他輔助信息,適應范圍廣。
遺傳算法擅長于全局搜索,但局部搜索能力不足,所以常把遺傳算法和其他算法結合起來應用。將遺傳算法運用到圖像處理主要是考慮到遺傳算法具有與問題領域無關且快速隨機的搜索能力。其搜索從群體出發,具有潛在的并行性,可以進行多個個體的同時比較,能有效的加快圖像處理的速度。但是遺傳算法也有其缺點:搜索所使用的評價函數的設計、初始種群的選擇有一定的依賴性等。要是能夠結合一些啟發算法進行改進且遺傳算法的并行機制的潛力得到充分的利用,這是當前遺傳算法在圖像處理中的一個研究熱點。
基于主動輪廓模型的分割方法
主動輪廓模型(active contours)是圖像分割的一種重要方法,具有統一的開放式的描述形式,為圖像分割技術的研究和創新提供了理想的框架。在實現主動輪廓模型時,可以靈活的選擇約束力、初始輪廓和作用域等,以得到更佳的分割效果,所以主動輪廓模型方法受到越來越多的關注。
該方法是在給定圖像中利用曲線演化來檢測目標的一類方法,基于此可以得到精確的邊緣信息。其基本思想是,先定義初始曲線C,然后根據圖像數據得到能量函數,通過最小化能量函數來引發曲線變化,使其向目標邊緣逐漸逼近,最終找到目標邊緣。這種動態逼近方法所求得的邊緣曲線具有封閉、光滑等優點。
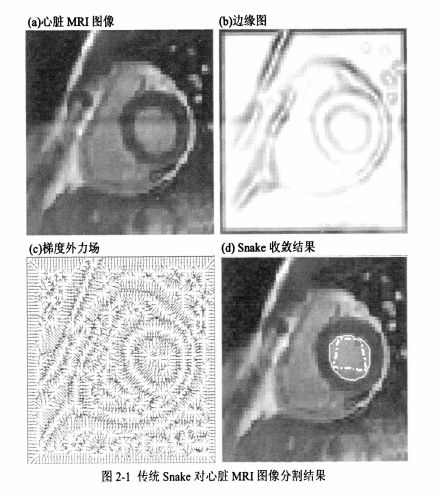
傳統的主動輪廓模型大致分為參數主動輪廓模型和幾何主動輪廓模型。參數主動輪廓模型將曲線或曲面的形變以參數化形式表達,Kass等人提出了經典的參數活動輪廓模型即“Snake”模型,其中Snake定義為能量極小化的樣條曲線,它在來自曲線自身的內力和來自圖像數據的外力的共同作用下移動到感興趣的邊緣,內力用于約束曲線形狀,而外力則引導曲線到特征此邊緣。參數主動輪廓模型的特點是將初始曲線置于目標區域附近,無需人為設定曲線的的演化是收縮或膨脹,其優點是能夠與模型直接進行交互,且模型表達緊湊,實現速度快;其缺點是難以處理模型拓撲結構的變化。比如曲線的合并或分裂等。而使用水平集(level set)的幾何活動輪廓方法恰好解決了這一問題。
基于深度學習的分割
1.基于特征編碼(feature encoder based)
在特征提取領域中VGGnet和ResNet是兩個非常有統治力的方法,接下來的一些篇幅會對這兩個方法進行簡短的介紹
a.VGGNet
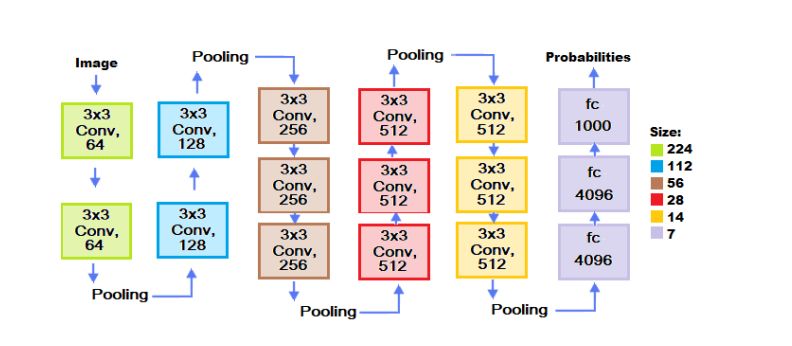
由牛津大學計算機視覺組合和Google DeepMind公司研究員一起研發的深度卷積神經網絡。它探索了卷積神經網絡的深度和其性能之間的關系,通過反復的堆疊33的小型卷積核和22的最大池化層,成功的構建了16~19層深的卷積神經網絡。VGGNet獲得了ILSVRC 2014年比賽的亞軍和定位項目的冠軍,在top5上的錯誤率為7.5%。目前為止,VGGNet依然被用來提取圖像的特征。
VGGNet的優缺點
由于參數量主要集中在最后的三個FC當中,所以網絡加深并不會帶來參數爆炸的問題;
多個小核卷積層的感受野等同于一個大核卷積層(三個3x3等同于一個7x7)但是參數量遠少于大核卷積層而且非線性操作也多于后者,使得其學習能力較強
VGG由于層數多而且最后的三個全連接層參數眾多,導致其占用了更多的內存(140M)
b.ResNet
隨著深度學習的應用,各種深度學習模型隨之出現,雖然在每年都會出現性能更好的新模型,但是對于前人工作的提升卻不是那么明顯,其中有重要問題就是深度學習網絡在堆疊到一定深度的時候會出現梯度消失的現象,導致誤差升高效果變差,后向傳播時無法將梯度反饋到前面的網絡層,使得前方的網絡層的參數難以更新,訓練效果變差。這個時候ResNet恰好站出來,成為深度學習發展歷程中一個重要的轉折點。
ResNet是由微軟研究院的Kaiming He等四名華人提出,他們通過自己提出的ResNet Unit成功訓練出來152層的神經網絡并在ILSVRC2015比賽中斬獲冠軍。ResNet語義分割領域最受歡迎且最廣泛運用的神經網絡.ResNet的核心思想就是在網絡中引入恒等映射,允許原始輸入信息直接傳到后面的層中,在學習過程中可以只學習上一個網絡輸出的殘差(F(x)),因此ResNet又叫做殘差網絡。、
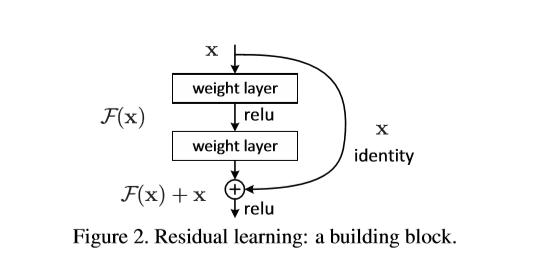
使用到ResNet的分割模型:
Efficient Neural Network(ENet):該網絡類似于ResNet的bottleNeck方法;
ResNet-38:該網絡在訓練or測試階段增加并移除了一些層,是一種淺層網絡,它的結構是ResNet+FCN;
full-resolution residual network(FRRN):FRRN網絡具有和ResNet相同優越的訓練特性,它由殘差流和池化流兩個處理流組成;
AdapNey:根據ResNet-50的網絡進行改進,讓原本的ResNet網絡能夠在更短的時間內學習到更多高分辨率的特征;
……
ResNet的優缺點:
1)引入了全新的網絡結構(殘差學習模塊),形成了新的網絡結構,可以使網絡盡可能地加深;
2)使得前饋/反饋傳播算法能夠順利進行,結構更加簡單;
3)恒等映射地增加基本上不會降低網絡的性能;
4)建設性地解決了網絡訓練的越深,誤差升高,梯度消失越明顯的問題;
5)由于ResNet搭建的層數眾多,所以需要的訓練時間也比平常網絡要長。
2.基于區域選擇(regional proposal based)
Regional proposal 在計算機視覺領域是一個非常常用的算法,尤其是在目標檢測領域。其核心思想就是檢測顏色空間和相似矩陣,根據這些來檢測待檢測的區域。然后根據檢測結果可以進行分類預測。
在語義分割領域,基于區域選擇的幾個算法主要是由前人的有關于目標檢測的工作漸漸延伸到語義分割的領域的,接下來小編將逐步介紹其個中關系。
Stage Ⅰ:R-CNN
伯克利大學的Girshick教授等人共同提出了首個在目標檢測方向應用的深度學習模型:Region-based Convolutional Neural Network(R-CNN)。該網絡模型如下圖所示,其主要流程為:先使用selective search算法提取2000個候選框,然后通過卷積網絡對候選框進行串行的特征提取,再根據提取的特征使用SVM對候選框進行分類預測,最后使用回歸方法對區域框進行修正。
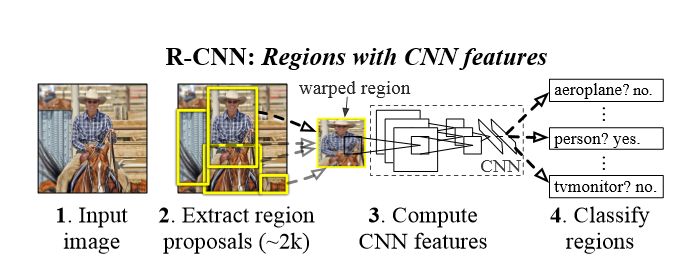
R-CNN的優缺點:
是首個開創性地將深度神經網絡應用到目標檢測的算法;
使用Bounding Box Regression對目標檢測的框進行調整;
由于進行特征提取時是串行,處理耗時過長;
Selective search算法在提取每一個region時需要2s的時間,浪費大量時間
Stage Ⅱ:Fast R-CNN
由于R-CNN的效率太低,2015年由Ross等學者提出了它的改進版本:Fast R-CNN。其網絡結構圖如下圖所示(從提取特征開始,略掉了region的選擇)Fast R-CNN在傳統的R-CNN模型上有所改進的地方是它是直接使用一個神經網絡對整個圖像進行特征提取,就省去了串行提取特征的時間;接著使用一個RoI Pooling Layer在全圖的特征圖上摘取每一個RoI對應的特征,再通過FC進行分類和包圍框的修正。
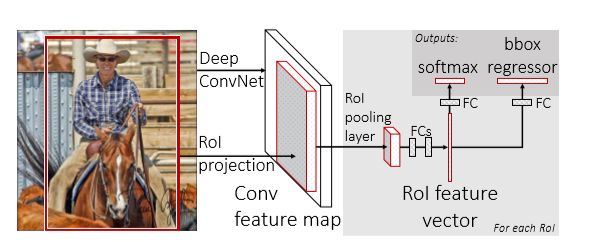
Fast R-CNN的優缺點
節省了串行提取特征的時間;
除了selective search以外的其它所有模塊都可以合在一起訓練;
最耗時間的selective search算法依然存在。
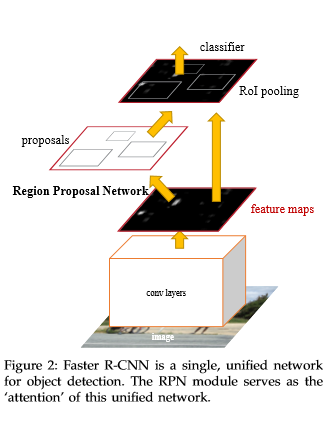
Stage Ⅲ:Faster R-CNN
2016年提出的Faster R-CNN可以說有了突破性的進展(雖然還是目標檢測哈哈哈),因為它改變了它的前輩們最耗時最致命的部位:selective search算法。它將selective search算法替換成為RPN,使用RPN網絡進行region的選取,將2s的時間降低到10ms,其網絡結構如下圖所示:
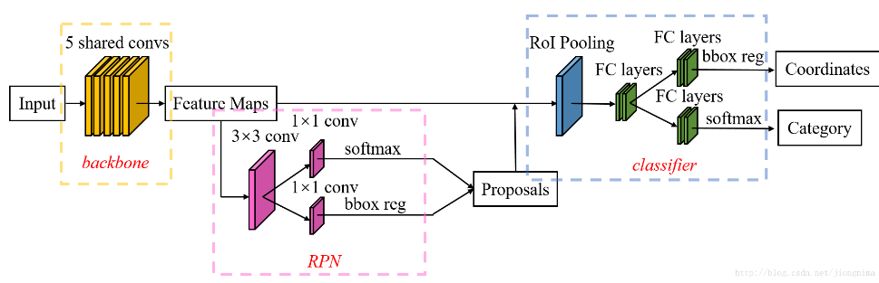
Faster R-CNN優缺點:
使用RPN替換了耗時的selective search算法,對整個網絡結構有了突破性的優化;
Faster R-CNN中使用的RPN和selective search比起來雖然速度更快,但是精度和selective search相比稍有不及,如果更注重速度而不是精度的話完全可以只使用RPN;
Stage Ⅳ:Mask R-CNN
Mask R-CNN(終于到分割了!)是何愷明大神團隊提出的一個基于Faster R-CNN模型的一種新型的分割模型,此論文斬獲ICCV 2017的最佳論文,在Mask R-CNN的工作中,它主要完成了三件事情:目標檢測,目標分類,像素級分割。
愷明大神是在Faster R-CNN的結構基礎上加上了Mask預測分支,并且改良了ROI Pooling,提出了ROI Align。其網絡結構真容就如下圖所示啦:
Mask R-CNN的優缺點:
引入了預測用的Mask-Head,以像素到像素的方式來預測分割掩膜,并且效果很好;
用ROI Align替代了ROI Pooling,去除了RoI Pooling的粗量化,使得提取的特征與輸入良好對齊;
分類框與預測掩膜共享評價函數,雖然大多數時間影響不大,但是有的時候會對分割結果有所干擾。
Stage Ⅴ:Mask Scoring R-CNN
最后要提出的是2019年CVPR的oral,來自華中科技大學的研究生黃釗金同學提出的
MS R-CNN,這篇文章的提出主要是對上文所說的Mask R-CNN的一點點缺點進行了修正。他的網絡結構也是在Mask R-CNN的網絡基礎上做了一點小小的改進,添加了Mask-IoU。
黃同學在文章中提到:愷明大神的Mask R-CNN已經很好啦!但是有個小毛病,就是評價函數只對目標檢測的候選框進行打分,而不是分割模板(就是上文提到的優缺點中最后一點),所以會出現分割模板效果很差但是打分很高的情況。所以黃同學增加了對模板進行打分的MaskIoU Head,并且最終的分割結果在COCO數據集上超越了愷明大神,下面就是MS R-CNN的網絡結構啦~
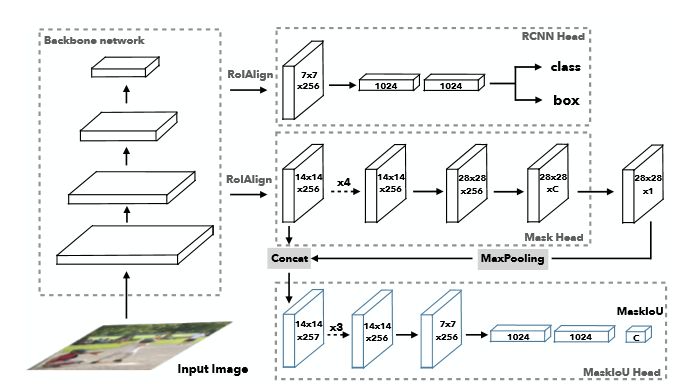
MS R-CNN的優缺點:
優化了Mask R-CNN中的信息傳播,提高了生成預測模板的質量;
未經大批量訓練的情況下,就拿下了COCO 2017挑戰賽實例分割任務冠軍;
要說缺點的話。。應該就是整個網絡有些龐大,一方面需要ResNet當作主干網絡,另一方面需要其它各種Head共同承擔各種任務。
3.基于RNN的圖像分割
Recurrent neural networks(RNNs)除了在手寫和語音識別上表現出色外,在解決計算機視覺的任務上也表現不俗,在本篇文章中我們就將要介紹RNN在2D圖像處理上的一些應用,其中也包括介紹使用到它的結構或者思想的一些模型。
RNN是由Long-Short-Term Memory(LSTM)塊組成的網絡,RNN來自序列數據的長期學習的能力以及隨著序列保存記憶的能力使其在許多計算機視覺的任務中游刃有余,其中也包括語義分割以及數據標注的任務。接下來的部分我們將介紹幾個使用到RNN結構的用于分割的網絡結構模型:
1.ReSeg模型
ReSeg可能不被許多人所熟知,在百度上搜索出的相關說明與解析也不多,但是這是一個很有效的語義分割方法。眾所周知,FCN可謂是圖像分割領域的開山作,而RegNet的作者則在自己的文章中大膽的提出了FCN的不足:沒有考慮到局部或者全局的上下文依賴關系,而在語義分割中這種依賴關系是非常有用的。所以在ReSeg中作者使用RNN去檢索上下文信息,以此作為分割的一部分依據。
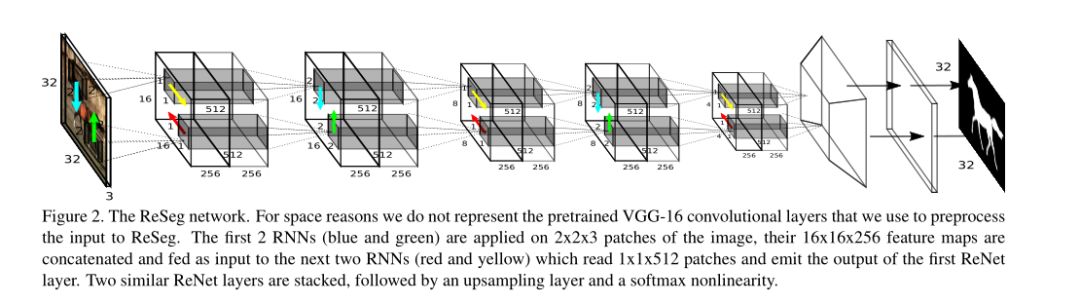
該結構的核心就是Recurrent Layer,它由多個RNN組合在一起,捕獲輸入數據的局部和全局空間結構。
優缺點:
充分考慮了上下文信息關系;
使用了中值頻率平衡,它通過類的中位數(在訓練集上計算)和每個類的頻率之間的比值來重新加權類的預測。這就增加了低頻率類的分數,這是一個更有噪聲的分割掩碼的代價,因為被低估的類的概率被高估了,并且可能導致在輸出分割掩碼中錯誤分類的像素增加。
2.MDRNNs(Multi-Dimensional Recurrent Neural Networks)模型
傳統的RNN在一維序列學習問題上有著很好的表現,比如演講(speech)和在線手寫識別。但是 在多為問題中應用卻并不到位。MDRNNs在一定程度上將RNN拓展到多維空間領域,使之在圖像處理、視頻處理等領域上也能有所表現。
該論文的基本思想是:將單個遞歸連接替換為多個遞歸連接,相應可以在一定程度上解決時間隨數據樣本的增加呈指數增長的問題。以下就是該論文提出的兩個前向反饋和反向反饋的算法。

4.基于上采樣/反卷積的分割方法
卷積神經網絡在進行采樣的時候會丟失部分細節信息,這樣的目的是得到更具特征的價值。但是這個過程是不可逆的,有的時候會導致后面進行操作的時候圖像的分辨率太低,出現細節丟失等問題。因此我們通過上采樣在一定程度上可以不全一些丟失的信息,從而得到更加準確的分割邊界。
接下來介紹幾個非常著名的分割模型:
a.FCN(Fully Convolutional Network)
是的!講來講去終于講到這位大佬了,FCN!在圖像分割領域已然成為一個業界標桿,大多數的分割方法多多少少都會利用到FCN或者其中的一部分,比如前面我們講過的Mask R-CNN。
在FCN當中的反卷積-升采樣結構中,圖片會先進性上采樣(擴大像素);再進行卷積——通過學習獲得權值。FCN的網絡結構如下圖所示:
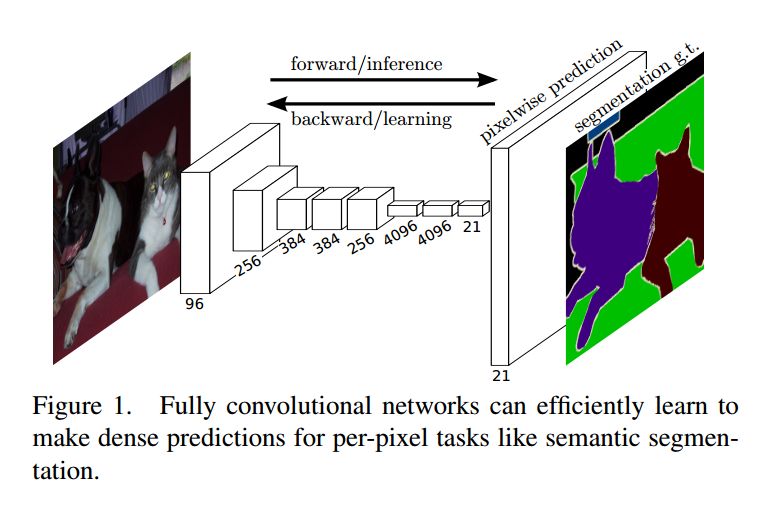
當然最后我們還是需要分析一下FCN,不能無腦吹啦~
優缺點:
FCN對圖像進行了像素級的分類,從而解決了語義級別的圖像分割問題;
FCN可以接受任意尺寸的輸入圖像,可以保留下原始輸入圖像中的空間信息;
得到的結果由于上采樣的原因比較模糊和平滑,對圖像中的細節不敏感;
對各個像素分別進行分類,沒有充分考慮像素與像素的關系,缺乏空間一致性。
2.SetNet
SegNet是劍橋提出的旨在解決自動駕駛或者智能機器人的圖像語義分割深度網絡,SegNet基于FCN,與FCN的思路十分相似,只是其編碼-解碼器和FCN的稍有不同,其解碼器中使用去池化對特征圖進行上采樣,并在分各種保持高頻細節的完整性;而編碼器不使用全連接層,因此是擁有較少參數的輕量級網絡:
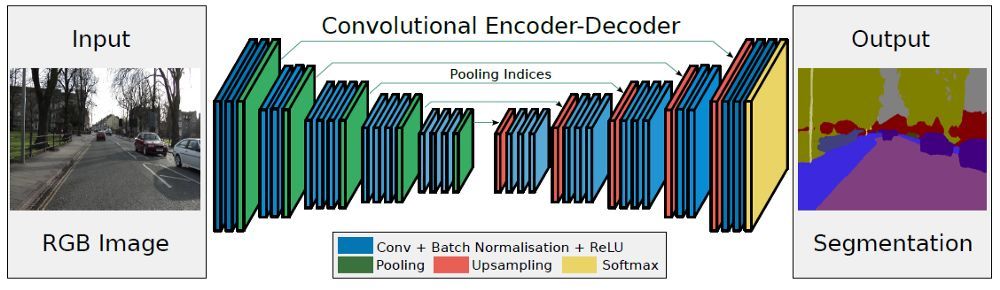
SetNet的優缺點:
保存了高頻部分的完整性;
網絡不笨重,參數少,較為輕便;
對于分類的邊界位置置信度較低;
對于難以分辨的類別,例如人與自行車,兩者如果有相互重疊,不確定性會增加。
以上兩種網絡結構就是基于反卷積/上采樣的分割方法,當然其中最最最重要的就是FCN了,哪怕是后面大名鼎鼎的SegNet也是基于FCN架構的,而且FCN可謂是語義分割領域中開創級別的網絡結構,所以雖然這個部分雖然只有兩個網絡結構,但是這兩位可都是重量級嘉賓,希望各位能夠深刻理解~
5.基于提高特征分辨率的分割方法
在這一個模塊中我們主要給大家介紹一下基于提升特征分辨率的圖像分割的方法。換一種說法其實可以說是恢復在深度卷積神經網絡中下降的分辨率,從而獲取更多的上下文信息。這一系列我將給大家介紹的是Google提出的DeepLab 。
DeepLab是結合了深度卷積神經網絡和概率圖模型的方法,應用在語義分割的任務上,目的是做逐像素分類,其先進性體現在DenseCRFs(概率圖模型)和DCNN的結合。是將每個像素視為CRF節點,利用遠程依賴關系并使用CRF推理直接優化DCNN的損失函數。
在圖像分割領域,FCN的一個眾所周知的操作就是平滑以后再填充,就是先進行卷積再進行pooling,這樣在降低圖像尺寸的同時增大感受野,但是在先減小圖片尺寸(卷積)再增大尺寸(上采樣)的過程中一定有一些信息損失掉了,所以這里就有可以提高的空間。
接下來我要介紹的是DeepLab網絡的一大亮點:Dilated/Atrous Convolution,它使用的采樣方式是帶有空洞的采樣。在VGG16中使用不同采樣率的空洞卷積,可以明確控制網絡的感受野。
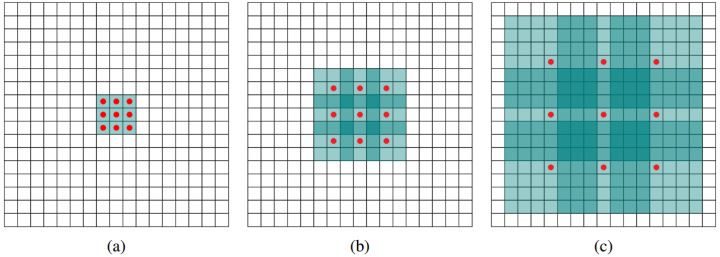
圖a對應3x3的1-dilated conv,它和普通的卷積操作是相同的;圖b對應3x3的2-dilated conv,事跡卷積核的尺寸還是3x3(紅點),但是空洞為1,其感受野能夠達到7x7;圖c對應3x3的4-dilated conv,其感受野已經達到了15x15.寫到這里相信大家已經明白,在使用空洞卷積的情況下,加大了感受野,使每個卷積輸出都包含了較大范圍的信息。
這樣就解決了DCNN的幾個關于分辨率的問題:
1)內部數據結構丟失;空間曾計劃信息丟失;
2)小物體信息無法重建;
當然空洞卷積也存在一定的問題,它的問題主要體現在以下兩方面:1)網格效應
加入我們僅僅多次疊加dilation rate 2的 3x3 的卷積核則會出現以下問題
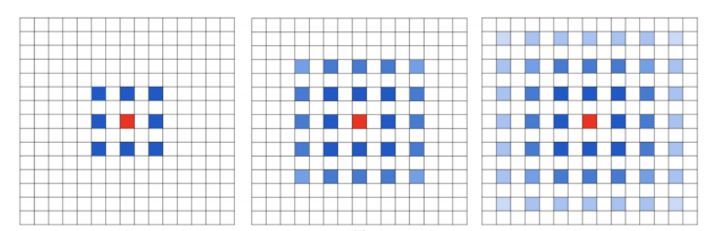
我們發現卷積核并不連續,也就是說并不是所有的像素都用來計算了,這樣會喪失信息的連續性;
2)小物體信息處理不當
我們從空洞卷積的設計背景來看可以推測出它是設計來獲取long-ranged information。然而空洞步頻選取得大獲取只有利于大物體得分割,而對于小物體的分割可能并沒有好處。所以如何處理好不同大小物體之間的關系也是設計好空洞卷積網絡的關鍵。
6.基于特征增強的分割方法
基于特征增強的分割方法包括:提取多尺度特征或者從一系列嵌套的區域中提取特征。在圖像分割的深度網絡中,CNN經常應用在圖像的小方塊上,通常稱為以每個像素為中心的固定大小的卷積核,通過觀察其周圍的小區域來標記每個像素的分類。在圖像分割領域,能夠覆蓋到更大部分的上下文信息的深度網絡通常在分割的結果上更加出色,當然這也伴隨著更高的計算代價。多尺度特征提取的方法就由此引進。
在這一模塊中我先給大家介紹一個叫做SLIC,全稱為simple linear iterative cluster的生成超像素的算法。
首先我們要明確一個概念:啥是超像素?其實這個比較容易理解,就像上面說的“小方塊”一樣,我們平常處理圖像的最小單位就是像素了,這就是像素級(pixel-level);而把像素級的圖像劃分成為區域級(district-level)的圖像,把區域當成是最基本的處理單元,這就是超像素啦。
算法大致思想是這樣的,將圖像從RGB顏色空間轉換到CIE-Lab顏色空間,對應每個像素的(L,a,b)顏色值和(x,y)坐標組成一個5維向量V[l, a, b, x, y],兩個像素的相似性即可由它們的向量距離來度量,距離越大,相似性越小。
算法首先生成K個種子點,然后在每個種子點的周圍空間里搜索距離該種子點最近的若干像素,將他們歸為與該種子點一類,直到所有像素點都歸類完畢。然后計算這K個超像素里所有像素點的平均向量值,重新得到K個聚類中心,然后再以這K個中心去搜索其周圍與其最為相似的若干像素,所有像素都歸類完后重新得到K個超像素,更新聚類中心,再次迭代,如此反復直到收斂。
有點像聚類的K-Means算法,最終會得到K個超像素。
Mostahabi等人提出的一種前向傳播的分類方法叫做Zoom-Out就使用了SLIC的算法,它從多個不同的級別提取特征:局部級別:超像素本身;遠距離級別:能夠包好整個目標的區域;全局級別:整個場景。這樣綜合考慮多尺度的特征對于像素或者超像素的分類以及分割來說都是很有意義的。
接下來的部分我將給大家介紹另一種完整的分割網絡:PSPNet:Pyramid Scene Parsing Network
論文提出在場景分割是,大多數的模型會使用FCN的架構,但是FCN在場景之間的關系和全局信息的處理能力存在問題,其典型問題有:1.上下文推斷能力不強;2.標簽之間的關系處理不好;3.模型可能會忽略小的東西。
本文提出了一個具有層次全局優先級,包含不同子區域時間的不同尺度的信息,稱之為金字塔池化模塊。
該模塊融合了4種不同金字塔尺度的特征,第一行紅色是最粗糙的特征–全局池化生成單個bin輸出,后面三行是不同尺度的池化特征。為了保證全局特征的權重,如果金字塔共有N個級別,則在每個級別后使用1×1 1×11×1的卷積將對于級別通道降為原本的1/N。再通過雙線性插值獲得未池化前的大小,最終concat到一起。其結構如下圖:
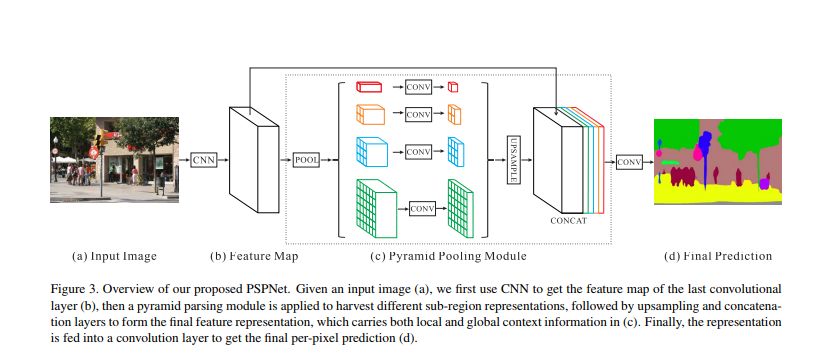
最終結果就是,在融合不同尺度的feature后,達到了語義和細節的融合,模型的性能表現提升很大,作者在很多數據集上都做過訓練,最終結果是在MS-COCO數據集上預訓練過的效果最好。
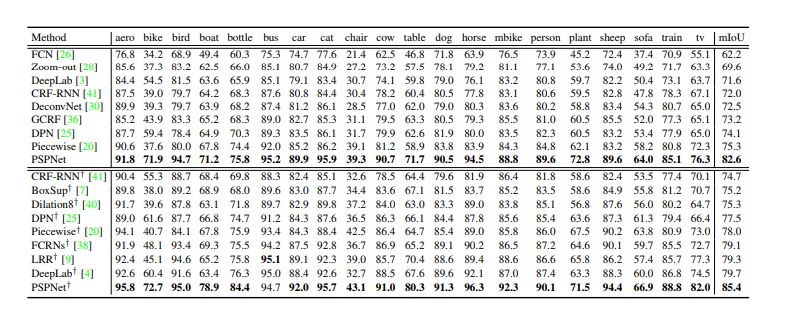
為了捕捉多尺度特征,高層特征包含了更多的語義和更少的位置信息。結合多分辨率圖像和多尺度特征描述符的優點,在不丟失分辨率的情況下提取圖像中的全局和局部信息,這樣就能在一定程度上提升網絡的性能。
7.使用CRF/MRF的方法
首先讓我們熟悉熟悉到底啥是MRF的CRF的。
MRF全稱是Marcov Random Field,馬爾可夫隨機場,其實說起來筆者在剛讀碩士的時候有一次就有同學在匯報中提到了隱馬爾可夫、馬爾可夫鏈啥的,當時還啥都不懂,小白一枚(現在是準小白hiahia),覺得馬爾可夫這個名字賊帥,后來才慢慢了解什么馬爾科夫鏈呀,馬爾可夫隨機場,并且在接觸到圖像分割了以后就對馬爾科夫隨機場有了更多的了解。
MRF其實是一種基于統計的圖像分割算法,馬爾可夫模型是指一組事件的集合,在這個集合中,事件逐個發生,并且下一刻事件的發生只由當前發生的事件決定,而與再之前的狀態沒有關系。而馬爾可夫隨機場,就是具有馬爾可夫模型特性的隨機場,就是場中任何區域都只與其臨近區域相關,與其他地方的區域無關,那么這些區域里元素(圖像中可以是像素)的集合就是一個馬爾可夫隨機場。
CRF的全稱是Conditional Random Field,條件隨機場其實是一種特殊的馬爾可夫隨機場,只不過是它是一種給定了一組輸入隨機變量X的條件下另一組輸出隨機變量Y的馬爾可夫隨機場,它的特點是埃及設輸出隨機變量構成馬爾可夫隨機場,可以看作是最大熵馬爾可夫模型在標注問題上的推廣。
在圖像分割領域,運用CRF比較出名的一個模型就是全連接條件隨機場(DenseCRF),接下來我們將花費一些篇幅來簡單介紹一下。
CRF在運行中會有一個問題就是它只對相鄰節點進行操作,這樣會損失一些上下文信息,而全連接條件隨機場是對所有節點進行操作,這樣就能獲取盡可能多的臨近點信息,從而獲得更加精準的分割結果。
在Fully connected CRF中,吉布斯能量可以寫作:
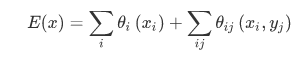
我們重點關注二元部分:
其中k(m)為高斯核,寫作:
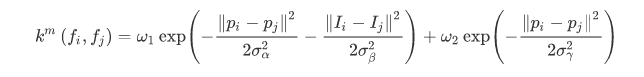
該模型的一元勢能包含了圖像的形狀,紋理,顏色和位置,二元勢能使用了對比度敏感的的雙核勢能,CRF的二元勢函數一般是描述像素點與像素點之間的關系,鼓勵相似像素分配相同的標簽,而相差較大的像素分配不同標簽,而這個“距離”的定義與顏色值和實際相對距離有關,這樣CRF能夠使圖像盡量在邊界處分割。全連接CRF模型的不同就在于其二元勢函數描述的是每一個像素與其他所有像素的關系,使用該模型在圖像中的所有像素對上建立點對勢能從而實現極大地細化和分割。
在分割結果上我們可以看看如下的結果圖:

可以看到它在精細邊緣的分割比平常的分割方法要出色得多,而且文章中使用了另一種優化算法,使得本來需要及其大量運算的全連接條件隨機場也能在很短的時間里給出不錯的分割結果。
至于其優缺點,我覺得可以總結為以下幾方面:
在精細部位的分割非常優秀;
充分考慮了像素點或者圖片區域之間的上下文關系;
在粗略的分割中可能會消耗不必要的算力;
可以用來恢復細致的局部結構,但是相應的需要較高的代價。
OK,那么本次的推送就到這里結束啦,本文的主要內容是對圖像分割的算法進行一個簡單的分類和介紹。綜述對于各位想要深入研究的看官是非常非常重要的資源:大佬們經常看綜述一方面可以了解算法的不足并在此基礎上做出改進;萌新們可以通過閱讀一篇好的綜述入門某一個學科。
-
算法
+關注
關注
23文章
4607瀏覽量
92839 -
圖像分割
+關注
關注
4文章
182瀏覽量
17995 -
機器學習
+關注
關注
66文章
8406瀏覽量
132563
原文標題:最全綜述 | 圖像分割算法
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
免疫克隆SAR圖像分割算法
一種新的彩色圖像分割算法

圖像分割算法的深入研究






 工商網監
工商網監
評論