") 【AI簡(jiǎn)報(bào)20231103期】ChatGPT參數(shù)揭秘,中文最強(qiáng)開(kāi)源大模型來(lái)了!
【AI簡(jiǎn)報(bào)20231103期】ChatGPT參數(shù)揭秘,中文最強(qiáng)開(kāi)源大模型來(lái)了!
1. 用FP8訓(xùn)練大模型有多香?微軟:比BF16快64%,省42%內(nèi)存
原文:https://mp.weixin.qq.com/s/xLvJXe2FDL8YdByZLHjGMQ
低精度訓(xùn)練是大模型訓(xùn)練中擴(kuò)展模型大小,節(jié)約訓(xùn)練成本的最關(guān)鍵技術(shù)之一。相比于當(dāng)前的 16 位和 32 位浮點(diǎn)混合精度訓(xùn)練,使用 FP8 8 位浮點(diǎn)混合精度訓(xùn)練能帶來(lái) 2 倍的速度提升,節(jié)省 50% - 75% 的顯存和 50% - 75% 的通信成本,而且英偉達(dá)最新一代卡皇 H100 自帶良好的 FP8 硬件支持。但目前業(yè)界大模型訓(xùn)練框架對(duì) FP8 訓(xùn)練的支持還非常有限。最近,微軟提出了一種用于訓(xùn)練 LLM 的 FP8 混合精度框架 FP8-LM,將 FP8 盡可能應(yīng)用在大模型訓(xùn)練的計(jì)算、存儲(chǔ)和通信中,使用 H100 訓(xùn)練 GPT-175B 的速度比 BF16 快 64%,節(jié)省 42% 的內(nèi)存占用。更重要的是:它開(kāi)源了。??
大型語(yǔ)言模型(LLM)具有前所未有的語(yǔ)言理解和生成能力,但是解鎖這些高級(jí)的能力需要巨大的模型規(guī)模和訓(xùn)練計(jì)算量。在這種背景下,尤其是當(dāng)我們關(guān)注擴(kuò)展至 OpenAI 提出的超級(jí)智能 (Super Intelligence) 模型規(guī)模時(shí),低精度訓(xùn)練是其中最有效且最關(guān)鍵的技術(shù)之一,其優(yōu)勢(shì)包括內(nèi)存占用小、訓(xùn)練速度快,通信開(kāi)銷(xiāo)低。目前大多數(shù)訓(xùn)練框架(如 Megatron-LM、MetaSeq 和 Colossal-AI)訓(xùn)練 LLM 默認(rèn)使用 FP32 全精度或者 FP16/BF16 混合精度。
但這仍然沒(méi)有推至極限:隨著英偉達(dá) H100 GPU 的發(fā)布,F(xiàn)P8 正在成為下一代低精度表征的數(shù)據(jù)類(lèi)型。理論上,相比于當(dāng)前的 FP16/BF16 浮點(diǎn)混合精度訓(xùn)練,F(xiàn)P8 能帶來(lái) 2 倍的速度提升,節(jié)省 50% - 75% 的內(nèi)存成本和 50% - 75% 的通信成本。
盡管如此,目前對(duì) FP8 訓(xùn)練的支持還很有限。英偉達(dá)的 Transformer Engine (TE),只將 FP8 用于 GEMM 計(jì)算,其所帶來(lái)的端到端加速、內(nèi)存和通信成本節(jié)省優(yōu)勢(shì)就非常有限了。
但現(xiàn)在微軟開(kāi)源的 FP8-LM FP8 混合精度框架極大地解決了這個(gè)問(wèn)題:FP8-LM 框架經(jīng)過(guò)高度優(yōu)化,在訓(xùn)練前向和后向傳遞中全程使用 FP8 格式,極大降低了系統(tǒng)的計(jì)算,顯存和通信開(kāi)銷(xiāo)。
論文地址:https://arxiv.org/abs/2310.18313
開(kāi)源框架:https://github.com/Azure/MS-AMP
實(shí)驗(yàn)結(jié)果表明,在 H100 GPU 平臺(tái)上訓(xùn)練 GPT-175B 模型時(shí), FP8-LM 混合精度訓(xùn)練框架不僅減少了 42% 的實(shí)際內(nèi)存占用,而且運(yùn)行速度比廣泛采用的 BF16 框架(即 Megatron-LM)快 64%,比 Nvidia Transformer Engine 快 17%。而且在預(yù)訓(xùn)練和多個(gè)下游任務(wù)上,使用 FP8-LM 訓(xùn)練框架可以得到目前標(biāo)準(zhǔn)的 BF16 混合精度框架相似結(jié)果的模型。
在給定計(jì)算資源情況下,使用 FP8-LM 框架能夠無(wú)痛提升可訓(xùn)練的模型大小多達(dá) 2.5 倍。有研發(fā)人員在推特上熱議:如果 GPT-5 使用 FP8 訓(xùn)練,即使只使用同樣數(shù)量的 H100,模型大小也將會(huì)是 GPT-4 的 2.5 倍!
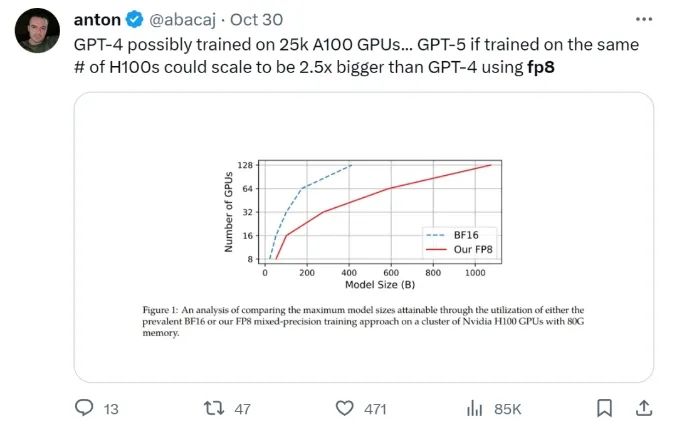
Huggingface 研發(fā)工程師調(diào)侃:「太酷啦,通過(guò) FP8 大規(guī)模訓(xùn)練技術(shù),可以實(shí)現(xiàn)計(jì)算欺騙!」
FP8-LM 主要貢獻(xiàn):
-
一個(gè)新的 FP8 混合精度訓(xùn)練框架。其能以一種附加方式逐漸解鎖 8 位的權(quán)重、梯度、優(yōu)化器和分布式訓(xùn)練,這很便于使用。這個(gè) 8 位框架可以簡(jiǎn)單直接地替代現(xiàn)有 16/32 位混合精度方法中相應(yīng)部分,而無(wú)需對(duì)超參數(shù)和訓(xùn)練方式做任何修改。此外,微軟的這個(gè)團(tuán)隊(duì)還發(fā)布了一個(gè) PyTorch 實(shí)現(xiàn),讓用戶(hù)可通過(guò)少量代碼就實(shí)現(xiàn) 8 位低精度訓(xùn)練。?
-
一個(gè)使用 FP8 訓(xùn)練的 GPT 式模型系列。他們使用了新提出的 FP8 方案來(lái)執(zhí)行 GPT 預(yù)訓(xùn)練和微調(diào)(包括 SFT 和 RLHF),結(jié)果表明新方法在參數(shù)量從 70 億到 1750 億的各種大小的模型都頗具潛力。他們讓常用的并行計(jì)算范式都有了 FP8 支持,包括張量、流水線(xiàn)和序列并行化,從而讓用戶(hù)可以使用 FP8 來(lái)訓(xùn)練大型基礎(chǔ)模型。他們也以開(kāi)源方式發(fā)布了首個(gè)基于 Megatron-LM 實(shí)現(xiàn)的 FP8 GPT 訓(xùn)練代碼庫(kù)。
FP8-LM 實(shí)現(xiàn)
具體來(lái)說(shuō),對(duì)于使用 FP8 來(lái)簡(jiǎn)化混合精度和分布式訓(xùn)練的目標(biāo),他們?cè)O(shè)計(jì)了三個(gè)優(yōu)化層級(jí)。這三個(gè)層級(jí)能以一種漸進(jìn)方式來(lái)逐漸整合 8 位的集體通信優(yōu)化器和分布式并行訓(xùn)練。優(yōu)化層級(jí)越高,就說(shuō)明 LLM 訓(xùn)練中使用的 FP8 就越多。
此外,對(duì)于大規(guī)模訓(xùn)練(比如在數(shù)千臺(tái) GPU 上訓(xùn)練 GPT-175B),該框架能提供 FP8 精度的低位數(shù)并行化,包括張量、訓(xùn)練流程和訓(xùn)練的并行化,這能鋪就通往下一代低精度并行訓(xùn)練的道路。
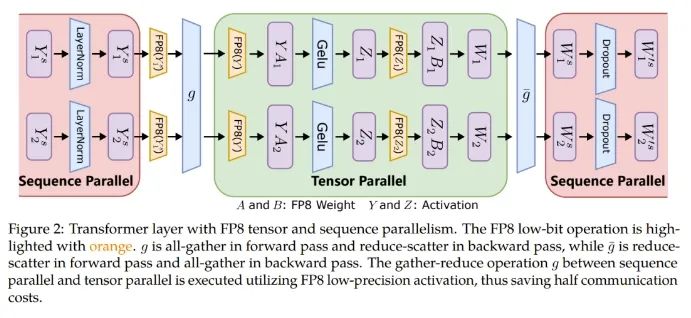
張量并行化是將一個(gè)模型的各個(gè)層分散到多臺(tái)設(shè)備上,從而將權(quán)重、梯度和激活張量的分片放在不同的 GPU 上。
為了讓張量并行化支持 FP8,微軟這個(gè)團(tuán)隊(duì)的做法是將分片的權(quán)重和激活張量轉(zhuǎn)換成 FP8 格式,以便線(xiàn)性層計(jì)算,從而讓前向計(jì)算和后向梯度集體通信全都使用 FP8。
另一方面,序列并行化則是將輸入序列切分成多個(gè)數(shù)據(jù)塊,然后將子序列饋送到不同設(shè)備以節(jié)省激活內(nèi)存。
如圖 2 所示,在一個(gè) Transformer 模型中的不同部分,序列并行化和張量并行化正在執(zhí)行,以充分利用可用內(nèi)存并提高訓(xùn)練效率。
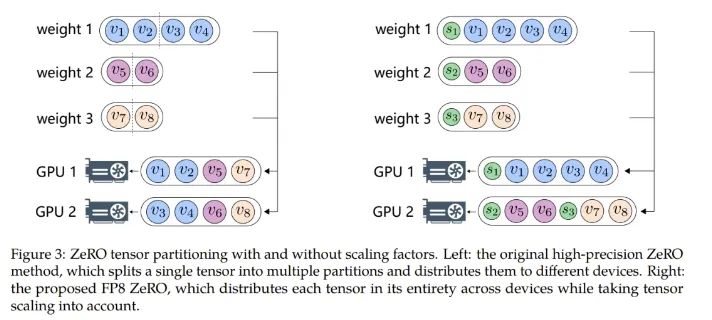
而對(duì)于 ZeRO(零冗余優(yōu)化器 / Zero Redundancy Optimizer),卻無(wú)法直接應(yīng)用 FP8,因?yàn)槠潆y以處理與 FP8 劃分有關(guān)的縮放因子。因此針對(duì)每個(gè)張量的縮放因子應(yīng)當(dāng)沿著 FP8 的劃分方式分布。
為了解決這個(gè)問(wèn)題,研究者實(shí)現(xiàn)了一種新的 FP8 分配方案,其可將每個(gè)張量作為一個(gè)整體分散到多臺(tái)設(shè)備上,而不是像 ZeRO 方法一樣將其切分成多個(gè)子張量。該方法是以一種貪婪的方式來(lái)處理 FP8 張量的分配,如算法 1 所示。

具體來(lái)說(shuō),該方法首先根據(jù)大小對(duì)模型狀態(tài)的張量排序,然后根據(jù)每個(gè) GPU 的剩余內(nèi)存大小將張量分配到不同的 GPU。這種分配遵循的原則是:剩余內(nèi)存更大的 GPU 更優(yōu)先接收新分配的張量。通過(guò)這種方式,可以平滑地沿張量分配張量縮放因子,同時(shí)還能降低通信和計(jì)算復(fù)雜度。圖 3 展示了使用和不使用縮放因子時(shí),ZeRO 張量劃分方式之間的差異。
使用 FP8 訓(xùn)練 LLM 并不容易。其中涉及到很多挑戰(zhàn)性問(wèn)題,比如數(shù)據(jù)下溢或溢出;另外還有源自窄動(dòng)態(tài)范圍的量化錯(cuò)誤和 FP8 數(shù)據(jù)格式固有的精度下降問(wèn)題。這些難題會(huì)導(dǎo)致訓(xùn)練過(guò)程中出現(xiàn)數(shù)值不穩(wěn)定問(wèn)題和不可逆的分歧問(wèn)題。為了解決這些問(wèn)題,微軟提出了兩種技術(shù):精度解耦(precision decoupling)和自動(dòng)縮放(automatic scaling),以防止關(guān)鍵信息丟失。
精度解耦
精度解耦涉及到解耦數(shù)據(jù)精度對(duì)權(quán)重、梯度、優(yōu)化器狀態(tài)等參數(shù)的影響,并將經(jīng)過(guò)約簡(jiǎn)的精度分配給對(duì)精度不敏感的組件。
針對(duì)精度解耦,該團(tuán)隊(duì)表示他們發(fā)現(xiàn)了一個(gè)指導(dǎo)原則:梯度統(tǒng)計(jì)可以使用較低的精度,而主權(quán)重必需高精度。
更具體而言,一階梯度矩可以容忍較高的量化誤差,可以配備低精度的 FP8,而二階矩則需要更高的精度。這是因?yàn)樵谑褂?Adam 時(shí),在模型更新期間,梯度的方向比其幅度更重要。具有張量縮放能力的 FP8 可以有效地將一階矩的分布保留成高精度張量,盡管它也會(huì)導(dǎo)致精度出現(xiàn)一定程度的下降。由于梯度值通常很小,所以為二階梯度矩計(jì)算梯度的平方可能導(dǎo)致數(shù)據(jù)下溢問(wèn)題。因此,為了保留數(shù)值準(zhǔn)確度,有必要分配更高的 16 位精度。
另一方面,他們還發(fā)現(xiàn)使用高精度來(lái)保存主權(quán)重也很關(guān)鍵。其根本原因是在訓(xùn)練過(guò)程中,權(quán)重更新有時(shí)候會(huì)變得非常大或非常小,對(duì)于主權(quán)重而言,更高的精度有助于防止權(quán)重更新時(shí)丟失信息,實(shí)現(xiàn)更穩(wěn)定和更準(zhǔn)確的訓(xùn)練。
自動(dòng)縮放
自動(dòng)縮放是為了將梯度值保存到 FP8 數(shù)據(jù)格式的表征范圍內(nèi),這需要?jiǎng)討B(tài)調(diào)整張量縮放因子,由此可以減少 all-reduce 通信過(guò)程中出現(xiàn)的數(shù)據(jù)下溢和溢出問(wèn)題。
具體來(lái)說(shuō),研究者引入了一個(gè)自動(dòng)縮放因子 μ,其可以在訓(xùn)練過(guò)程中根據(jù)情況變化。
實(shí)驗(yàn)結(jié)果
為了驗(yàn)證新提出的 FP8 低精度框架,研究者實(shí)驗(yàn)了用它來(lái)訓(xùn)練 GPT 式的模型,其中包括預(yù)訓(xùn)練和監(jiān)督式微調(diào)(SFT)。實(shí)驗(yàn)在 Azure 云計(jì)算最新 NDv5 H100 超算平臺(tái)上進(jìn)行。
實(shí)驗(yàn)結(jié)果表明新提出的 FP8 方法是有效的:相比于之前廣泛使用 BF16 混合精度訓(xùn)練方法,新方法優(yōu)勢(shì)明顯,包括真實(shí)內(nèi)存用量下降了 27%-42%(比如對(duì)于 GPT-7B 模型下降了 27%,對(duì)于 GPT-175B 模型則下降了 42%);權(quán)重梯度通信開(kāi)銷(xiāo)更是下降了 63%-65%。
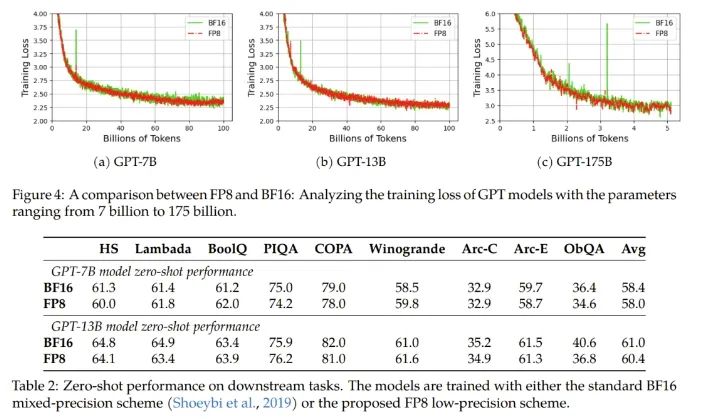
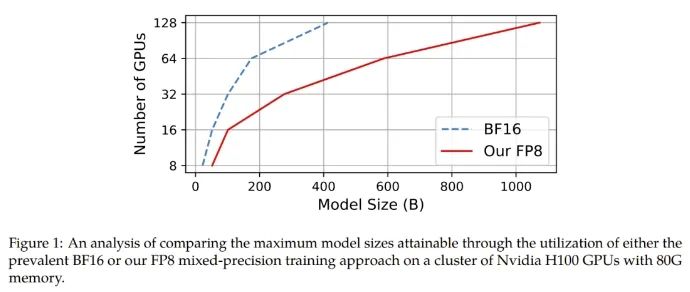
不修改學(xué)習(xí)率和權(quán)重衰減等任何超參數(shù),不管是預(yù)訓(xùn)練任務(wù)還是下游任務(wù),使用 FP8 訓(xùn)練的模型與使用 BF16 高精度訓(xùn)練的模型的表現(xiàn)相當(dāng)。值得注意的是,在 GPT-175B 模型的訓(xùn)練期間,相比于 TE 方法,在 H100 GPU 平臺(tái)上,新提出的 FP8 混合精度框架可將訓(xùn)練時(shí)間減少 17%,同時(shí)內(nèi)存占用少 21%。更重要的是,隨著模型規(guī)模繼續(xù)擴(kuò)展,通過(guò)使用低精度的 FP8 還能進(jìn)一步降低成本,如圖 1 所示。
對(duì)于微調(diào),他們使用了 FP8 混合精度來(lái)進(jìn)行指令微調(diào),并使用了使用人類(lèi)反饋的強(qiáng)化學(xué)習(xí)(RLHF)來(lái)更好地將預(yù)訓(xùn)練后的 LLM 與終端任務(wù)和用戶(hù)偏好對(duì)齊。
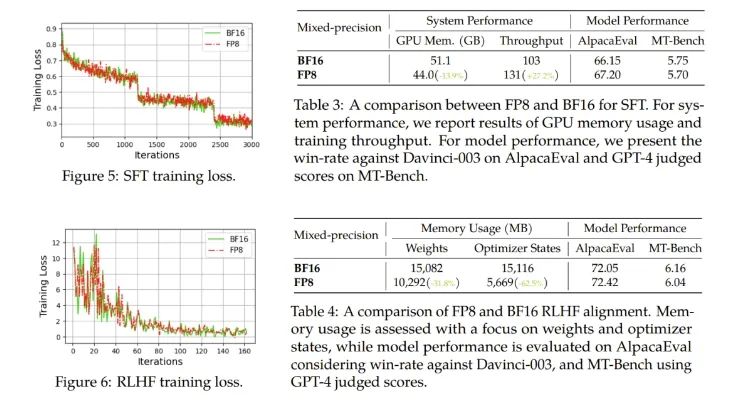
結(jié)果發(fā)現(xiàn),在 AlpacaEval 和 MT-Bench 基準(zhǔn)上,使用 FP8 混合精度微調(diào)的模型與使用半精度 BF16 微調(diào)的模型的性能相當(dāng),而使用 FP8 的訓(xùn)練速度還快 27%。此外,F(xiàn)P8 混合精度在 RLHF 方面也展現(xiàn)出了巨大的潛力,該過(guò)程需要在訓(xùn)練期間加載多個(gè)模型。通過(guò)在訓(xùn)練中使用 FP8,流行的 RLHF 框架 AlpacaFarm 可將模型權(quán)重減少 46%,將優(yōu)化器狀態(tài)的內(nèi)存消耗減少 62%。這能進(jìn)一步展現(xiàn)新提出的 FP8 低精度訓(xùn)練框架的多功能性和適應(yīng)性。
他們也進(jìn)行了消融實(shí)驗(yàn),驗(yàn)證了各組件的有效性。
可預(yù)見(jiàn),F(xiàn)P8 低精度訓(xùn)練將成為未來(lái)大模型研發(fā)的新基建。
2. 萬(wàn)萬(wàn)沒(méi)想到,ChatGPT參數(shù)只有200億?
原文:https://mp.weixin.qq.com/s/4oovtS-FaA-Yvk0Tgy3Lng
誰(shuí)都沒(méi)有想到,ChatGPT 的核心秘密是由這種方式,被微軟透露出來(lái)的。
昨天晚上,很多討論 AI 的微信群都被一篇 EMNLP 論文和其中的截圖突然炸醒。
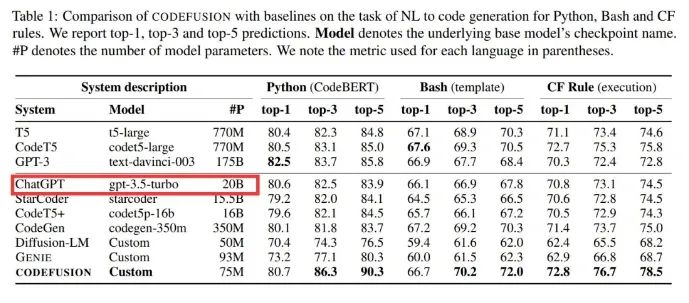
微軟一篇題為《CodeFusion: A Pre-trained Diffusion Model for Code Generation》的論文,在做對(duì)比的時(shí)候透露出了重要信息:ChatGPT 是個(gè)「只有」20B(200 億)參數(shù)的模型,這件事引起了廣泛關(guān)注。
距 ChatGPT 發(fā)布已經(jīng)快一年了,但 OpenAI 一直未透露 ChatGPT 的技術(shù)細(xì)節(jié)。由于其強(qiáng)大的模型性能,人們對(duì) ChatGPT 的參數(shù)量、訓(xùn)練數(shù)據(jù)等信息抱有諸多疑問(wèn)和猜測(cè)。
作為行業(yè)一直以來(lái)的標(biāo)桿,ChatGPT 性能強(qiáng)大,可以解決各種各樣的問(wèn)題。它的前身 GPT-3 參數(shù)量就達(dá)到了 1750 億,實(shí)用化以后的大模型居然被 OpenAI 瘦身了快 9 倍,這合理嗎?
「如何看待這篇論文」的話(huà)題立刻沖上了知乎熱榜。

具體來(lái)說(shuō),微軟這篇論文提出了一種預(yù)訓(xùn)練的擴(kuò)散代碼生成模型 ——CodeFusion。CodeFusion 的參數(shù)量是 75M。在實(shí)驗(yàn)比較部分,論文的表 1 將 ChatGPT 的參數(shù)量明確標(biāo)成了 20B。
眾所周知,微軟和 OpenAI 是合作已久的一對(duì)伙伴,并且這是一篇 EMNLP 2023 論文,因此大家推測(cè)這個(gè)數(shù)據(jù)很有可能是真實(shí)的。
然而,關(guān)于 ChatGPT 參數(shù)量的猜測(cè),人們一直認(rèn)為是一個(gè)龐大的數(shù)字,畢竟 GPT-3 的參數(shù)量就已經(jīng)達(dá)到了 175B(1750 億)。掀起大型語(yǔ)言模型(LLM)浪潮的 ChatGPT,難道就只有 20B 參數(shù)?
大家怎么看?
這個(gè)數(shù)據(jù)被扒出來(lái)之后,在知乎和 Twitter 已經(jīng)引起了廣泛討論。畢竟,200 億參數(shù)達(dá)到這樣的效果十分驚人。再則,國(guó)內(nèi)追趕出的大模型動(dòng)則就是數(shù)百億、上千億。
那么這個(gè)數(shù)據(jù)保不保真?大家都有什么看法呢?
NLP 知名博主、新浪微博新技術(shù)研發(fā)負(fù)責(zé)人張俊林「盲猜」分析了一波,引起了大家廣泛贊同:
不負(fù)責(zé)任猜測(cè)一波:GPT 4 是去年 8 月做好的,ChatGPT 估計(jì)是 OpenAI 應(yīng)對(duì) Anthropic 要推出的 Claude 專(zhuān)門(mén)做的,那時(shí)候 GPT 4 應(yīng)該價(jià)值觀(guān)還沒(méi)對(duì)齊,OpenAI 不太敢放出來(lái),所以臨時(shí)做了 ChatGPT 來(lái)?yè)屜劝l(fā)優(yōu)勢(shì)。OpenAI 在 2020 年推出 Scaling law 的文章,Deepmind 在 2022 年推出的改進(jìn)版本 chinchilla law。OpenAI 做大模型肯定會(huì)遵循科學(xué)做法的,不會(huì)拍腦袋,那么就有兩種可能:
可能性一:OpenAI 已經(jīng)看到 Chinchilla 的論文,模型是按照龍貓法則做的,我們假設(shè) ChatGPT 的訓(xùn)練數(shù)據(jù)量不低于 2.5T token 數(shù)量(為啥這樣后面分析),那么按照龍貓法則倒推,一般訓(xùn)練數(shù)據(jù)量除以 20 就應(yīng)該是最優(yōu)參數(shù)量。于是我們可以推出:這種情況 ChatGPT 模型的大小約在 120B 左右。
可能性二:OpenAI 在做 ChatGPT 的時(shí)候還沒(méi)看到 Chinchilla 的論文,于是仍然按照 OpenAI 自己推導(dǎo)的 Scaling law 來(lái)設(shè)計(jì)訓(xùn)練數(shù)據(jù)量和模型大小,推算起來(lái)訓(xùn)練數(shù)據(jù)量除以 12.5 左右對(duì)應(yīng)模型最優(yōu)參數(shù),他們自己的 Scaling law 更傾向把模型推大。假設(shè)訓(xùn)練數(shù)據(jù)量是 2.5T 左右,那么這種情況 ChatGPT 的模型大小應(yīng)該在 190 到 200B 左右。
大概率第一個(gè)版本 ChatGPT 推出的時(shí)候在 200B 左右,所以剛出來(lái)的時(shí)候大家還是覺(jué)得速度慢,價(jià)格也高。3 月份 OpenAI 做過(guò)一次大升級(jí),價(jià)格降低為原先的十分之一。如果僅僅靠量化是不太可能壓縮這么猛的,目前的結(jié)論是大模型量化壓縮到 4 到 6bit 模型效果是能保持住不怎么下降的。
所以很可能 OpenAI 這次升級(jí)從自己的 Scaling law 升級(jí)到了 Chinchilla 的 Scaling law,這樣模型大小就壓縮了 120B 左右,接近一半(也有可能遠(yuǎn)小于 120B,如果按照 chinchilla law,llama 2 最大的模型應(yīng)該是 100B 左右,此時(shí)算力分配最優(yōu),也就是說(shuō)成本收益最合算。但是實(shí)際最大的 llama2 模型才 70B,而且更小的模型比如 7B 模型也用超大數(shù)據(jù)集。
llama1 65B 基本是符合 chinchilla law 的,llama2 最大模型已經(jīng)打破 chinchilla law 開(kāi)始懟數(shù)據(jù)了。就是說(shuō)目前大家做大模型的趨勢(shì)是盡管不是算力分配最優(yōu),但是都傾向于增加數(shù)據(jù)減小模型規(guī)模,這樣盡管訓(xùn)練成本不合算,但是推理合算,而訓(xùn)練畢竟是一次性的,推理則并發(fā)高次數(shù)多,所以這么配置很明顯總體是更合算的),再加上比如 4bit 量化,這樣推理模型的大小可以壓縮 4 倍,速度大約可提升 8 倍左右,如果是采取繼續(xù)增加訓(xùn)練數(shù)據(jù)減小模型規(guī)模,再加上其它技術(shù)優(yōu)化是完全有可能把推理價(jià)格打到十分之一的。
后續(xù)在 6 月份和 8 月份各自又價(jià)格下調(diào)了 25%,最終可能通過(guò)反復(fù)加數(shù)據(jù)減小規(guī)模逐漸把模型壓縮到 20B 左右。
這里解釋下為何 ChatGPT 的訓(xùn)練數(shù)據(jù)量不太可能比 2.5T 低,LLaMA 2 的訓(xùn)練數(shù)據(jù)量是 2T,效果應(yīng)該稍弱于 ChatGPT,所以這里假設(shè)最少 2.5T 的訓(xùn)練數(shù)據(jù)。目前研究結(jié)論是當(dāng)模型規(guī)模固定住,只要持續(xù)增加訓(xùn)練數(shù)據(jù)量,模型效果就會(huì)直接增長(zhǎng),mistral 7B 效果炸裂,歸根結(jié)底是訓(xùn)練數(shù)據(jù)量達(dá)到了 8 個(gè) T,所以導(dǎo)致基礎(chǔ)模型效果特別強(qiáng)。以 ChatGPT 的效果來(lái)說(shuō),它使用的數(shù)據(jù)量不太可能低于 2.5T。
當(dāng)然,還有另外一種可能,就是 ChatGPT 在后期優(yōu)化(比如第一次大升級(jí)或者后續(xù)的升級(jí)中,開(kāi)始版本不太可能走的這條路)的時(shí)候也不管 scaling law 了,走的是類(lèi)似 mistral 的路線(xiàn),就是模型大小固定在 20B,瘋狂增加訓(xùn)練數(shù)據(jù),如果又構(gòu)造出合適的 instruct 數(shù)據(jù),效果也可能有保障。
不論怎么講,對(duì)于 6B 到 13B 左右比較適合應(yīng)用落地的模型,強(qiáng)烈呼吁中文開(kāi)源模型模仿 mistral,固定住一個(gè)最適合使用的模型大小,然后瘋狂增加訓(xùn)練數(shù)據(jù),再加上好的 instruct 策略,是有可能作出小規(guī)模效果體驗(yàn)足夠好的模型的。我個(gè)人認(rèn)為對(duì)于開(kāi)源模型來(lái)說(shuō),7B-13B 左右大小的模型應(yīng)該是兵家必爭(zhēng)之地。有心氣做開(kāi)源的可以再努把力,把訓(xùn)練數(shù)據(jù)往上再努力懟一懟。
早在 OpenAI 開(kāi)放 ChatGPT API 時(shí),0.002 美元 / 1k token 的定價(jià)就令人們意外,這個(gè)價(jià)格只有 GPT-3.5 的 1/10。彼時(shí)就有人推測(cè):「ChatGPT 是百億(~10B)參數(shù)的模型」,并且「ChatGPT 使用的獎(jiǎng)勵(lì)模型(reward model)可能是千億級(jí)模型」。該推測(cè)來(lái)源于清華大學(xué) NLP 在讀博士鄭楚杰的知乎回答。

但所有這些都是猜測(cè),由于 OpenAI 對(duì)參數(shù)量、訓(xùn)練數(shù)據(jù)、方法等核心信息一直諱莫如深,因此 20B 這個(gè)數(shù)據(jù)到底是不是真的根本無(wú)法求證。如果是真的,那么大型語(yǔ)言模型未來(lái)的改進(jìn)方向還會(huì)是增加參數(shù)量嗎?
再過(guò)幾天,就是 OpenAI 的開(kāi)發(fā)者大會(huì)了,也許我們能夠了解到更多有用的信息,讓我們拭目以待吧。
3. 代碼能力超越GPT-4,這個(gè)模型登頂Big Code排行榜,YC創(chuàng)始人點(diǎn)贊
原文:https://mp.weixin.qq.com/s/fSVPRjNpWPVrLVA59PrIBA
一款號(hào)稱(chēng)代碼能力超越GPT-4的模型,引發(fā)了不少網(wǎng)友的關(guān)注。
準(zhǔn)確率比GPT-4高出超過(guò)10%,速度卻接近GPT-3.5,而且窗口長(zhǎng)度也更長(zhǎng)。
據(jù)開(kāi)發(fā)者描述,他們的模型取得了74.7%的Pass@1通過(guò)率,超過(guò)了原始GPT-4的67%,登上了Big Code榜首。
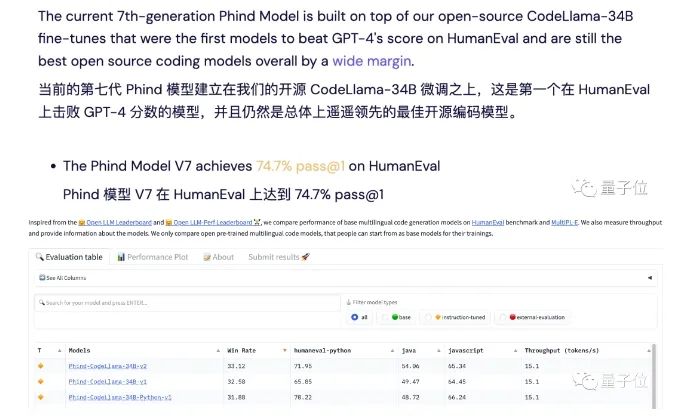
這個(gè)模型名叫Phind,和以其為基礎(chǔ)的面向開(kāi)發(fā)者的AI搜索工具同名。
它是由開(kāi)發(fā)團(tuán)隊(duì)在CodeLlama-34B的基礎(chǔ)之上微調(diào)得到的。
Phind利用TensorRT-LLM在H100上可以跑出每秒100個(gè)token的速度,是GPT-4的5倍。
此外,Phind的上下文長(zhǎng)度達(dá)到了16k,其中12k可供用戶(hù)輸入,另外4k保留給檢索結(jié)果中的文本。

針對(duì)這個(gè)產(chǎn)品,網(wǎng)友們議論紛紛,結(jié)果是喜憂(yōu)參半:
支持的人,如著名創(chuàng)業(yè)投資公司YCombinator創(chuàng)始人Paul Graham表示,Phind可以讓人們用更少的資源和大廠(chǎng)抗衡。

Phind vs GPT-4
正式開(kāi)始之前,先來(lái)說(shuō)說(shuō)對(duì)Phind的第一印象。
它的界面十分簡(jiǎn)潔,主要就是一個(gè)搜索框,而且不需要登錄就能無(wú)限量使用。
左下角有一個(gè)Pair Programmer的開(kāi)關(guān),直觀(guān)上的區(qū)別就是開(kāi)啟之后回答界面更側(cè)重對(duì)話(huà),不開(kāi)啟的話(huà)則更像搜索引擎。
此外,還可以從自研模型和GPT-4中選擇,GPT-4則需要登錄,而且每天只能用10次。

接下來(lái)就是和GPT-4進(jìn)行的對(duì)比測(cè)試,GPT-4沒(méi)有開(kāi)啟代碼解釋器。
首先還是從LeetCode題目開(kāi)始測(cè)起,Prompt就是是原問(wèn)題加上下面這段話(huà):
請(qǐng)用Python寫(xiě)一段代碼解決這個(gè)問(wèn)題,給出通用的解法,不需要設(shè)定參數(shù)值,代碼需要以如下內(nèi)容開(kāi)頭:(LeetCode頁(yè)面中給出的起始片段)
為了防止Phind通過(guò)檢索來(lái)“作弊”,我們還在Phind的Prompt結(jié)尾加入了這句話(huà):
不要檢索任何信息,靠你自己的能力創(chuàng)建代碼
第一題在LeetCode中被歸為組合數(shù)學(xué)問(wèn)題,難度為困難,通過(guò)率67.1%。

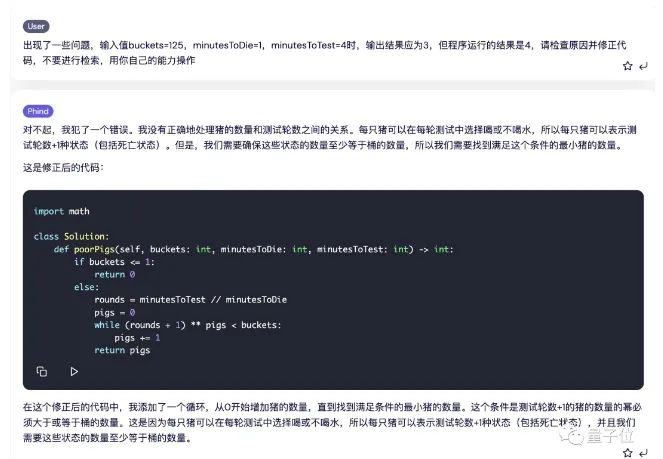
Phind給出了這樣的代碼和解釋?zhuān)?jīng)過(guò)測(cè)試,20條測(cè)試數(shù)據(jù)中有19項(xiàng)正確。

出錯(cuò)的是這一條,這里的輸出結(jié)果應(yīng)該是3,但Phind給出的程序運(yùn)行結(jié)果是4。

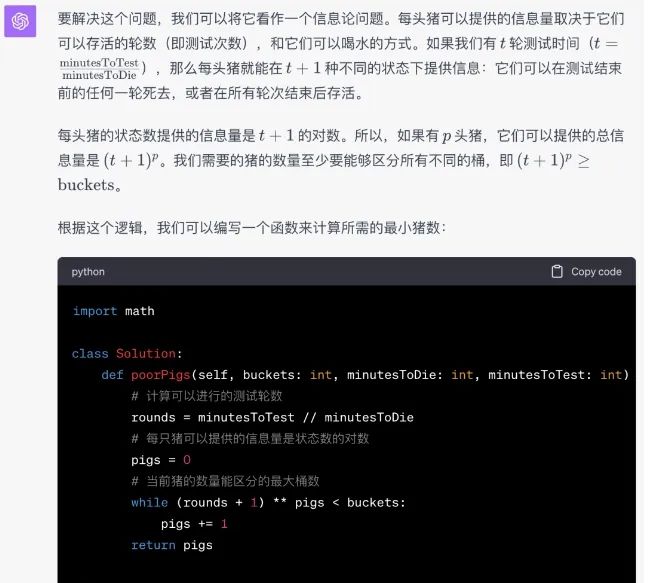
我們?cè)囍答伣oPhind,看它能不能找出錯(cuò)誤的原因,結(jié)果分析一番之后給出了新的代碼,并通過(guò)了測(cè)試。
而GPT-4這邊,則是一次性通過(guò)。
道LeetCode題目測(cè)試下來(lái),Phind以一平兩負(fù)的成績(jī)輸給了GPT-4。
但需要說(shuō)明的是,這里我們?yōu)榱藴y(cè)試模型本身表現(xiàn),通過(guò)提示詞關(guān)閉了Phind的檢索功能,但從實(shí)用角度出發(fā),如果保留搜索,Phind還是能很好地解決這些問(wèn)題的。
接著,我們又測(cè)試了一下他們的實(shí)際開(kāi)發(fā)能力,這次的題目是掃雷游戲。
Phind會(huì)問(wèn)我們有沒(méi)有什么特殊要求,這里我們直接點(diǎn)跳過(guò)。
然后Phind會(huì)對(duì)任務(wù)進(jìn)行拆解,對(duì)每個(gè)子任務(wù)又分別進(jìn)行檢索。

這時(shí)的代碼也是分段給出的,有趣的是,在生成過(guò)程中,Phind會(huì)使用不同來(lái)源中的代碼。
然后我們讓Phind給出完整代碼,并通過(guò)鏈接的第三方平臺(tái)直接運(yùn)行。
結(jié)果呢,我們一進(jìn)去就看到程序已經(jīng)非常“貼心”地把雷的位置清楚地標(biāo)注好了。
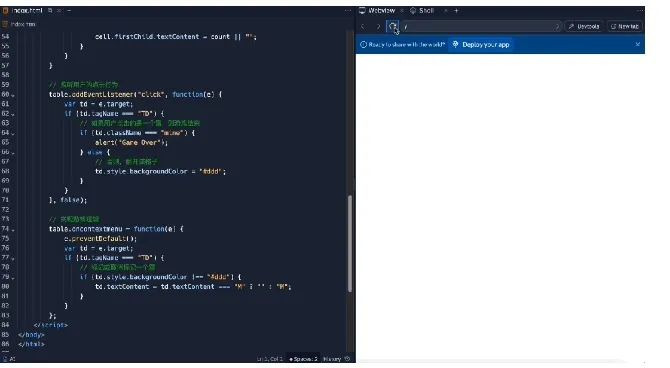
不過(guò)這次,GPT-4的代碼更加離譜一些,運(yùn)行出來(lái)是這樣的:

雖然都沒(méi)做對(duì),但硬要比較的話(huà),這一輪,Phind略勝一籌。
一路測(cè)試下來(lái),很難判斷它們孰優(yōu)孰劣,但考慮到搜索能力,以及免費(fèi)免登錄的特性,Phind還是可圈可點(diǎn)的。
4. 中文最強(qiáng)開(kāi)源大模型來(lái)了!130億參數(shù),0門(mén)檻商用,來(lái)自昆侖萬(wàn)維
原文:https://mp.weixin.qq.com/s/MKu6eusxyCXw3fLhgbcp0A
開(kāi)源最徹底的大模型來(lái)了——130億參數(shù),無(wú)需申請(qǐng)即可商用。
不僅如此,它還附帶著把全球最大之一的中文數(shù)據(jù)集也一并開(kāi)源了出來(lái):600G、1500億tokens!
這就是來(lái)自昆侖萬(wàn)維的Skywork-13B系列,包含兩大版本:
-
Skywork-13B-Base:該系列的基礎(chǔ)模型,在多種基準(zhǔn)評(píng)測(cè)中都拔得頭籌的那種。
-
Skywork-13B-Math:該系列的數(shù)學(xué)模型,數(shù)學(xué)能力在GSM8K評(píng)測(cè)上得分第一。
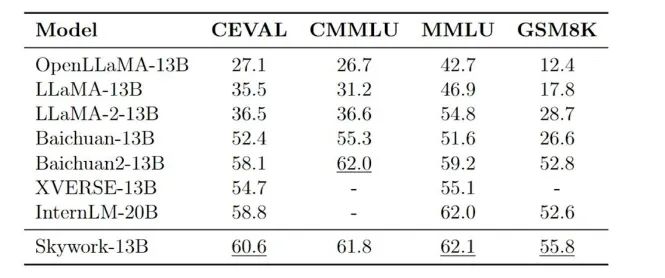
在各大權(quán)威評(píng)測(cè)benchmark上,如C-Eval、MMLU、CMMLU、GSM8K,可以看到Skywork-13B在中文開(kāi)源模型中處于前列,在同等參數(shù)規(guī)模下為最優(yōu)水平。
而Skywork-13B系列之所以能取得如此亮眼的成績(jī),部分原因離不開(kāi)剛才我們提到的數(shù)據(jù)集。
畢竟清洗好的中文數(shù)據(jù)對(duì)于大模型來(lái)說(shuō)可謂是至關(guān)重要,幾乎從某種程度上決定了其性能。
但昆侖萬(wàn)維能將如此“至寶”無(wú)償?shù)亟o奉獻(xiàn)出來(lái),不難看出它對(duì)于構(gòu)建開(kāi)源社區(qū)、服務(wù)開(kāi)發(fā)者的滿(mǎn)滿(mǎn)誠(chéng)意。
除此之外,昆侖萬(wàn)維Skywork-13B此次還配套了“輕量版”大模型,是在消費(fèi)級(jí)顯卡中就能部署和推理的那種!
Skywork-13B下載地址(Model Scope):https://modelscope.cn/organization/skywork
Skywork-13B下載地址(Github):https://github.com/SkyworkAI/Skywork
接下來(lái),我們進(jìn)一步來(lái)看下Skywork-13B系列更多的能力。
無(wú)需申請(qǐng)即可商用
Skywork-13B系列大模型擁有130億參數(shù)、3.2萬(wàn)億高質(zhì)量多語(yǔ)言訓(xùn)練數(shù)據(jù)。
由此,模型在生成、創(chuàng)作、數(shù)學(xué)推理等任務(wù)上提升明顯。
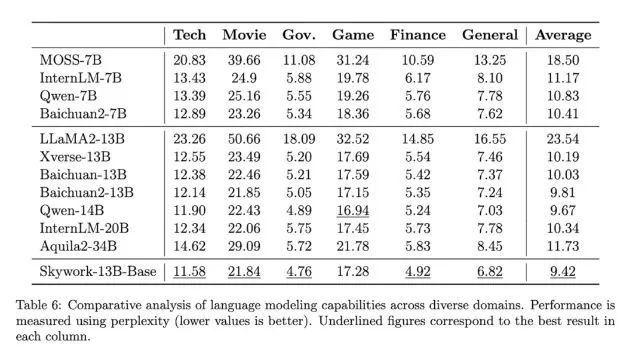
首先在中文語(yǔ)言建模困惑度評(píng)測(cè)中,Skywork-13B系列大模型超越了目前所有中文開(kāi)源模型。
在科技、金融、政務(wù)、企業(yè)服務(wù)、文創(chuàng)、游戲等領(lǐng)域均表現(xiàn)出色。
另外,Skywork-13B-Math專(zhuān)長(zhǎng)數(shù)學(xué)任務(wù),進(jìn)行過(guò)數(shù)學(xué)能力強(qiáng)化訓(xùn)練,在GSM8K等數(shù)據(jù)集中取得了同等規(guī)模模型最佳效果。
與此同時(shí),昆侖萬(wàn)維還開(kāi)源了數(shù)據(jù)集Skypile/Chinese-Web-Text-150B。其數(shù)據(jù)是通過(guò)精心過(guò)濾的數(shù)據(jù)處理流程從中文網(wǎng)頁(yè)中篩選而來(lái)。
由此,開(kāi)發(fā)者可以最大程度借鑒技術(shù)報(bào)告中大模型預(yù)訓(xùn)練的過(guò)程和經(jīng)驗(yàn),深度定制模型參數(shù),進(jìn)行針對(duì)性訓(xùn)練與優(yōu)化 。
除此之外,Skywork-13B還公開(kāi)了模型使用的評(píng)估方法、數(shù)據(jù)配比研究和訓(xùn)練基礎(chǔ)設(shè)施調(diào)優(yōu)方案等。
而Skywork-13B的一系列開(kāi)源,無(wú)需申請(qǐng)即可商用!
用戶(hù)在下載模型并同意遵守《Skywork模型社區(qū)許可協(xié)議》后,不用再次申請(qǐng)商業(yè)授權(quán)。
授權(quán)流程也取消了對(duì)行業(yè)、公司規(guī)模、用戶(hù)數(shù)量等方面限制。
昆侖萬(wàn)維會(huì)如此徹底開(kāi)源其實(shí)也并不意外。
昆侖萬(wàn)維董事長(zhǎng)兼CEO方漢是最早參與到開(kāi)源生態(tài)建設(shè)的老兵了,也是中文Linux開(kāi)源最早的推動(dòng)者之一。
在今年ChatGPT趨勢(shì)剛剛興起時(shí),他就多次公開(kāi)發(fā)聲、強(qiáng)調(diào)開(kāi)源的重要性:
代碼開(kāi)源可助力中國(guó)版ChatGPT彎道超車(chē)。
所以也就不難理解Skywork-13B系列大模型的推出了。
而在短短2個(gè)月后,昆侖萬(wàn)維又將最新的大模型、最新的數(shù)據(jù)集,一并發(fā)布且開(kāi)源,可以說(shuō)它的一切動(dòng)作不僅在于快,更是在于敢。
那么接下來(lái)的問(wèn)題是——為什么要這么做?
其實(shí),對(duì)于A(yíng)IGC這一板塊,昆侖萬(wàn)維早在2020年便已經(jīng)開(kāi)始涉足,早早的準(zhǔn)備和技術(shù)積累就是它能夠在大熱潮來(lái)臨之際快速跟進(jìn)的原因之一。
據(jù)了解,昆侖萬(wàn)維目前已形成AI大模型、AI搜索、AI游戲、AI音樂(lè)、AI動(dòng)漫、AI社交六大AI業(yè)務(wù)矩陣。
至于不遺余力的將開(kāi)源這事做好做大,一方面是源于企業(yè)的基因。
昆侖萬(wàn)維董事長(zhǎng)兼CEO方漢是最早參與到開(kāi)源生態(tài)建設(shè)的開(kāi)源老兵,也是中文Linux開(kāi)源最早的推動(dòng)者之一,開(kāi)源的精神和AIGC技術(shù)的發(fā)展早已在昆侖萬(wàn)維戰(zhàn)略中完美融合。
正如方漢此前所言:
昆侖天工之所以選擇開(kāi)源,因?yàn)槲覀儓?jiān)信開(kāi)源是推動(dòng)AIGC生態(tài)發(fā)展的土壤和重要力量。昆侖萬(wàn)維致力于在A(yíng)IGC模型算法方面的技術(shù)創(chuàng)新和開(kāi)拓,致力于推進(jìn)開(kāi)源AIGC算法和模型社區(qū)的發(fā)展壯大,致力于降低AIGC技術(shù)在各行各業(yè)的使用和學(xué)習(xí)門(mén)檻。
沒(méi)錯(cuò),降低門(mén)檻,便是其堅(jiān)持開(kāi)源的另一大原因。
從昆侖萬(wàn)維入局百模大戰(zhàn)以來(lái)的種種動(dòng)作中,也很容易看到它正在踐行著讓天工用起來(lái)更簡(jiǎn)單、更絲滑。
總而言之,昆侖萬(wàn)維目前已然是處于國(guó)產(chǎn)大模型的第一梯隊(duì),甚至說(shuō)是立于金字塔尖都不足為過(guò)。
那么在更大力度的開(kāi)源加持之下,天工大模型還將有怎樣驚艷的表現(xiàn),是值得期待一波了。
5. A17 Pro vs 8Gen3,手機(jī)旗艦SoC迭代,GPU和NPU成為下一輪發(fā)力點(diǎn)
原文:https://mp.weixin.qq.com/s/1snqc5TKjPajcUz4ELIO6w
電子發(fā)燒友網(wǎng)報(bào)道(文/周凱揚(yáng))隨著2023年步入尾聲,無(wú)論是蘋(píng)果還是高通,都已經(jīng)推出了新一代的旗艦手機(jī)SoC,這也昭示著安卓與iOS陣營(yíng)手機(jī)性能的又一次年末大比。然而,對(duì)比過(guò)去拼通用計(jì)算性能和通用圖形計(jì)算性能的局面,今年兩大廠(chǎng)商都已經(jīng)開(kāi)始卷向其他的計(jì)算負(fù)載,比如光追、超分這樣的特殊GPU負(fù)載,以及終于被積極調(diào)動(dòng)算力的NPU單元。我們就從CPU,GPU和NPU三個(gè)手機(jī)SoC主力計(jì)算單元來(lái)分析蘋(píng)果A17 Pro和高通驍龍8Gen3在設(shè)計(jì)上新一輪迭代。
CPU,單核多核性能各有千秋
A17 Pro和驍龍8Gen3分別是基于臺(tái)積電3nm和4nm工藝打造的芯片,在最先進(jìn)的半導(dǎo)體工藝下,CPU上的提升尤其引人注目,尤其是蘋(píng)果的A17 Pro還是首發(fā)3nm的芯片。然而在各路實(shí)機(jī)測(cè)試的表現(xiàn)中,兩者的成績(jī)卻是各有勝負(fù)。
A17 Pro雖說(shuō)用上了最先進(jìn)的3nm工藝,且對(duì)微架構(gòu)進(jìn)行了一定的改進(jìn),最大主頻從A16時(shí)期的3.46GHz大幅提升至3.78GHz,但A17 Pro依然保持了6核(2性能核+4能效核)的配置,即便是在蘋(píng)果自己給出的性能指標(biāo)中,相較上一代也只有10%的性能提升。
而高通的驍龍8Gen3 Kyro CPU,通過(guò)升級(jí)大核為Cortex-X4、升級(jí)中核為Cortex-A720、升級(jí)小核為Cortex-A520,并將一個(gè)額外的能效核轉(zhuǎn)換成了性能核,從上一代的1:4:3配置,換成了1:5:2配置。正是因?yàn)樵谌绱思みM(jìn)的設(shè)計(jì)改動(dòng)下,8Gen3的CPU實(shí)現(xiàn)了30%的性能提升,20%的能效提升。
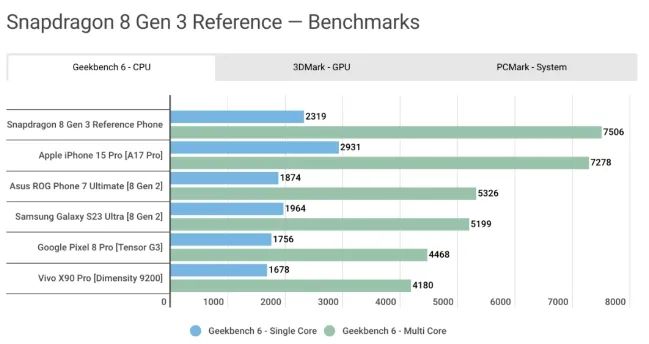
然而在Geekbench 6的測(cè)試中,我們還是能看到一些有意思的對(duì)比。根據(jù)androidauthority對(duì)iPhone15 Pro和驍龍8Gen3參考機(jī)的測(cè)試可以看出,在單核性能上,A17 Pro還是領(lǐng)先一大截的,而在多核性能上,驍龍8Gen3終于實(shí)現(xiàn)了反超。這不免讓人期待起未來(lái)Snapdragon X Elite的CPU架構(gòu)下放到手機(jī)SoC后,高通CPU的單核性能會(huì)有怎樣的提升。
GPU,光追和超分辨率技術(shù)
至于GPU性能的對(duì)比,結(jié)果與上一代似乎并沒(méi)有太大不同,在3D Mark的測(cè)試中,A17 Pro的GPU全方位落后于驍龍8Gen3。根據(jù)蘋(píng)果的說(shuō)法,他們對(duì)這一代GPU進(jìn)行了歷史上最大的一次重新設(shè)計(jì),但從這個(gè)結(jié)果來(lái)看,重新設(shè)計(jì)的方向應(yīng)該主要放在了硬件光追和超分技術(shù)上,其相比前代提升的20%GPU性能還是無(wú)法與驍龍8Gen3相提并論。
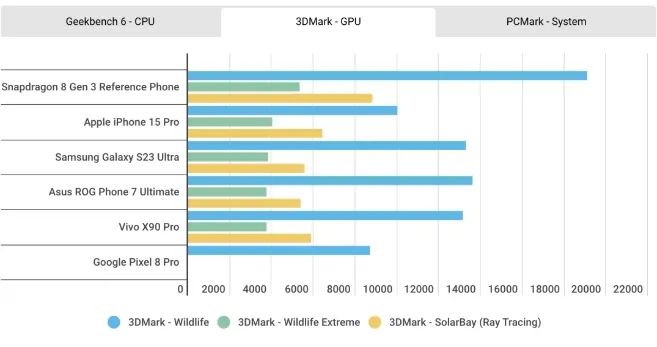
今年的手機(jī)SoC設(shè)計(jì)中,硬件光追已經(jīng)成了標(biāo)配。蘋(píng)果稱(chēng)其GPU加入的硬件光追相較基于軟件的光追,速度提升了4倍,更適合用于沉浸式AR應(yīng)用和游戲體驗(yàn)。不過(guò)相較從上一代驍龍8Gen2就開(kāi)始布局硬件光追的高通來(lái)說(shuō),蘋(píng)果在硬件光追上的性能水平還是有所不及。從上面的3DMark光追測(cè)試成績(jī)可以看出,8Gen3的硬件光追加速性能要高出A17 Pro一大截。
高通在硬件光追的開(kāi)發(fā)上也領(lǐng)先于蘋(píng)果,相比去年8Gen2僅有實(shí)時(shí)光追支持,今年的驍龍8Gen3還加入了對(duì)虛幻5引擎Lumen全局光照和反射系統(tǒng)的支持,可以實(shí)現(xiàn)比普通硬件光追更好的光線(xiàn)表現(xiàn)效果。
除了硬件光追以外,無(wú)論是高通還是蘋(píng)果,都在這一代GPU的設(shè)計(jì)中加入了超分辨率的技術(shù),比如蘋(píng)果的MetalFX和高通的Snapdragon Game Super Resolution(GSR)。為了運(yùn)行性能要求更高的3A游戲大作,僅僅靠堆高GPU性能是遠(yuǎn)遠(yuǎn)不夠的,受限于智能手機(jī)的散熱結(jié)構(gòu),我們需要英偉達(dá)DLSS或AMD的FSR這類(lèi)超分辨率技術(shù)進(jìn)一步降低配置要求和功耗。
去年的WWDC 2022上,蘋(píng)果正式宣布了MetalFX這一超分技術(shù),利用相對(duì)較低分辨率的圖像輸出更高的分辨率,從而減少渲染負(fù)載,提高應(yīng)用或游戲體驗(yàn)。不過(guò)屆時(shí)該技術(shù)主要是為M2系列的處理器開(kāi)發(fā)的,而如今蘋(píng)果已經(jīng)打算將這一技術(shù)引入手機(jī)GPU。
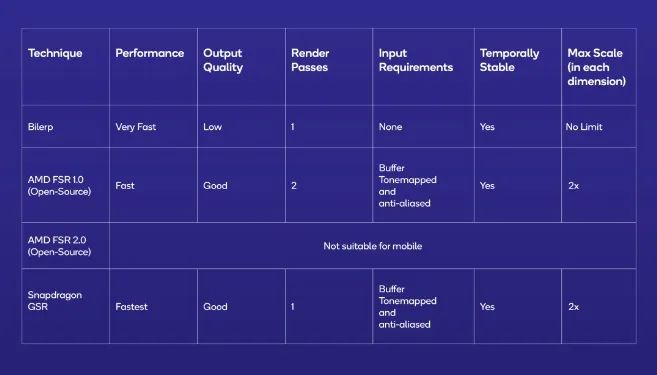
而高通則在今年推出了GSR這一超分技術(shù),高通宣稱(chēng)可以提供10bit HDR 144FPS的游戲性能體驗(yàn)。從上述超分技術(shù)對(duì)比中可以看出,GSR最高可以實(shí)現(xiàn)兩倍的超分。高通還表示,雖然GSR技術(shù)兼容大部分GPU,但只有在驍龍硬件平臺(tái)上才能發(fā)揮出最大性能。
不過(guò)在實(shí)現(xiàn)方式上,蘋(píng)果的MetalFX和高通的GSR還是有一些區(qū)別的。高通的GSR是一項(xiàng)單通空域超分辨率技術(shù),與AMD開(kāi)源的FSR 1.0實(shí)現(xiàn)方式一樣。而蘋(píng)果的MetalFX,則給到了開(kāi)發(fā)者選擇,既可以采用空域超分辨率技術(shù),也可以使用FSR 2.0一樣的時(shí)域抗鋸齒超分辨率技術(shù)。
不過(guò),高通選擇這一技術(shù)路線(xiàn)不是沒(méi)有原因的,首先空域超分更容易達(dá)到較好的性能和圖像質(zhì)量表現(xiàn),比過(guò)去的插值超分在邊緣細(xì)節(jié)上更有優(yōu)勢(shì)。而時(shí)域超分雖說(shuō)可以實(shí)現(xiàn)更好的圖像質(zhì)量,但其所需的數(shù)據(jù)輸入在手機(jī)圖形的渲染管線(xiàn)卻不常見(jiàn),只有一部分PC游戲移植到手機(jī)上更適合這一方案。
這點(diǎn)從蘋(píng)果MetaFX的開(kāi)發(fā)文檔中也可以看出,如果只選擇空域超分的話(huà),開(kāi)發(fā)者只需要輸入像素色彩,而選擇時(shí)域超分則需要提供像素色彩、深度和動(dòng)態(tài)信息,這對(duì)游戲開(kāi)發(fā)者來(lái)說(shuō),就需要在渲染管線(xiàn)上花更多的工夫。所以高通的GSR和蘋(píng)果MetaFX中的空域超分更容易適配,相信未來(lái)即將支持超分的一大批游戲都會(huì)選擇這一方案。
NPU,設(shè)備端生成式AI
自今年生成式AI成為熱門(mén)應(yīng)用后,手機(jī)SoC廠(chǎng)商以及大模型應(yīng)用開(kāi)發(fā)者們均看到了手機(jī)AI計(jì)算單元NPU的另一大功用。尤其是在高通驍龍8Gen 3的產(chǎn)品詳情中,高通著重介紹了這一芯片平臺(tái)在生成式AI上的優(yōu)勢(shì)。
驍龍8Gen 3的Hexagon NPU相較上一代有了質(zhì)的提升,性能提升高達(dá)98%,能效比提升高達(dá)40%。這也是高通首度在NPU中加入支持多模態(tài)生成式AI模型的AI引擎,該引擎支持LLM(大語(yǔ)言模型)、LVM(語(yǔ)言視覺(jué)模型)和ASR(自動(dòng)語(yǔ)音識(shí)別)模型,端側(cè)最大支持100億參數(shù)的模型。
在LLM上,以Meta 70億參數(shù)的Llama 2模型為例,驍龍8Gen 3支持到20token每秒的表現(xiàn)。同時(shí)NPU也進(jìn)一步提高了Sensing Hub各大傳感器調(diào)用用戶(hù)數(shù)據(jù)的能力,比如同時(shí)支持兩個(gè)始終感應(yīng)的攝像頭等。
蘋(píng)果今年似乎并沒(méi)有著重強(qiáng)調(diào)A17 Pro的神經(jīng)引擎,除了35TOPS的計(jì)算性能。不過(guò)從M2和M3系列的神經(jīng)引擎配置來(lái)看,蘋(píng)果或許對(duì)于A(yíng)17 Pro這一智能手機(jī)SoC的AI性能有更多的準(zhǔn)備。要知道,同為16核的神經(jīng)引擎,去年的A16和M2芯片其AI算力只有17 TOPS,哪怕是剛公布的M3系列芯片,其AI算力都只有18TOPS。
寫(xiě)在最后
至此,我們看到了高通和蘋(píng)果兩家廠(chǎng)商對(duì)于A(yíng)I計(jì)算的重視,只不過(guò)兩者的側(cè)重點(diǎn)略有不同。比如目前蘋(píng)果目前更注重于打造“直覺(jué)式AI”,著重加強(qiáng)設(shè)備端系統(tǒng)級(jí)AI和多媒體AI的表現(xiàn),比如輸入法自動(dòng)更正、個(gè)人語(yǔ)音、拍照人像模式、第三方app中的圖片降噪/超分等。而高通已經(jīng)開(kāi)始擁抱生成式AI,尤其是智能語(yǔ)音助手的AI性能,也給到了第三方AI應(yīng)用開(kāi)發(fā)者更自由的硬件資源調(diào)用。
然而無(wú)論是從紙面參數(shù),還是從各大性能測(cè)試得出的結(jié)果可知,安卓旗艦SoC與蘋(píng)果SoC的性能代差已經(jīng)完全消除了,甚至前者在GPU性能上已經(jīng)實(shí)現(xiàn)了反超。由此也可以看出,半導(dǎo)體工藝提升帶來(lái)的性能收益已經(jīng)在縮小,反而是芯片微架構(gòu)和核心配置決定了最終的手機(jī)SoC性能。
6. IBM最新推出一款類(lèi)腦芯片“NorthPole” 用于快速高效的人工智能
原文:https://mp.weixin.qq.com/s/nG3otCtN1mwSHKXEw-0vxw
據(jù)悉,IBM公司最新推出了一款名為“NorthPole(https://research.ibm.com/blog/northpole-ibm-ai-chip)”的類(lèi)腦芯片,其運(yùn)行由人工智能驅(qū)動(dòng)的圖像識(shí)別算法的速度是同類(lèi)商業(yè)芯片的22倍,能效是同類(lèi)芯片的25倍。根據(jù)IBM的一項(xiàng)研究顯示,新型硅芯片的應(yīng)用可能包括自動(dòng)駕駛汽車(chē)和機(jī)器人。
以大腦為靈感的計(jì)算機(jī)硬件旨在模仿人腦以異常節(jié)能的方式快速執(zhí)行計(jì)算的非凡能力。這些機(jī)器通常用于實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò),類(lèi)似地模仿大腦的學(xué)習(xí)和操作方式。
“NorthPole merges the boundaries between brain-inspired computing and silicon-optimized computing, between compute and memory, between hardware and software.”
—DHARMENDRA MODHA, IBM
受大腦啟發(fā)的電子學(xué)經(jīng)常采用的一種策略是復(fù)制生物神經(jīng)元計(jì)算和存儲(chǔ)數(shù)據(jù)的方式。將處理器和內(nèi)存結(jié)合起來(lái),可以大大減少計(jì)算機(jī)在這些組件之間穿梭數(shù)據(jù)所損失的能量和時(shí)間。
該研究的主要作者、IBM大腦啟發(fā)計(jì)算的首席科學(xué)家Dharmendra Modha說(shuō):“大腦比現(xiàn)代計(jì)算機(jī)節(jié)能得多,部分原因是它在每個(gè)神經(jīng)元中都存儲(chǔ)了帶有計(jì)算功能的內(nèi)存。”
Modha說(shuō):“NorthPole融合了大腦啟發(fā)計(jì)算和硅優(yōu)化計(jì)算、計(jì)算和內(nèi)存、硬件和軟件之間的界限。”
新芯片針對(duì)2位、4位和8位低精度操作進(jìn)行了優(yōu)化。研究人員表示,這足以在許多神經(jīng)網(wǎng)絡(luò)上實(shí)現(xiàn)最先進(jìn)的精度,同時(shí)省去訓(xùn)練所需的數(shù)值。該研究原型在25至425兆赫的頻率范圍內(nèi)工作,每個(gè)核心每個(gè)周期可以以8位精度執(zhí)行2048次操作,以2位精度執(zhí)行8192次操作。
NorthPole是在過(guò)去八年中開(kāi)發(fā)的,它建立在IBM最后一款類(lèi)腦芯片TrueNorth的基礎(chǔ)上。TrueNorth于2014年首次亮相,其功率效率比當(dāng)時(shí)的傳統(tǒng)微處理器低四個(gè)數(shù)量級(jí)。
Modha說(shuō):“NorthPole的主要目標(biāo)是大幅降低TrueNorth的潛在資本成本。”
科學(xué)家們用兩個(gè)人工智能系統(tǒng)測(cè)試了NorthPole —— ResNet 50圖像分類(lèi)網(wǎng)絡(luò)和Yolo-v4物體檢測(cè)網(wǎng)絡(luò)。與使用類(lèi)似12納米節(jié)點(diǎn)制造的英偉達(dá)V100 GPU相比,NorthPole每瓦的能效是后者的25倍,速度是后者的22倍,同時(shí)面積只占五分之一。
“Given that analog systems are yet to reach technological maturity, this work presents a near-term option for AI to be deployed close to where it is needed.”
—VWANI ROYCHOWDHURY, UCLA
NorthPole的表現(xiàn)也優(yōu)于市場(chǎng)上所有其他芯片,即使是使用更先進(jìn)節(jié)點(diǎn)制造的芯片。例如,與使用4nm節(jié)點(diǎn)實(shí)現(xiàn)的英偉達(dá)H100 GPU相比,NorthPole的能效高出五倍。事實(shí)證明,NorthPole的速度大約是TrueNorth的4000倍。
加州大學(xué)洛杉磯分校的計(jì)算和人工智能科學(xué)家Vwani Roychowdhury沒(méi)有參與這項(xiàng)研究,他說(shuō):“這篇論文代表了一場(chǎng)工程之旅。”
新芯片的速度和效率來(lái)自于它所有的內(nèi)存都在芯片上。這意味著每個(gè)核心都可以同樣輕松地訪(fǎng)問(wèn)芯片上的存儲(chǔ)器。
此外,Modha說(shuō),從設(shè)備外部看,NorthPole是一個(gè)有源存儲(chǔ)芯片。這有助于將NorthPole集成到系統(tǒng)中。
Modha說(shuō),NorthPole的潛在應(yīng)用可能包括圖像和視頻分析、語(yǔ)音識(shí)別,以及被稱(chēng)為變壓器的神經(jīng)網(wǎng)絡(luò),這些網(wǎng)絡(luò)是為聊天機(jī)器人(如ChatGPT)提供動(dòng)力的大型語(yǔ)言模型(LLM)的基礎(chǔ)。IBM表示,這些人工智能任務(wù)可能會(huì)用于自動(dòng)駕駛汽車(chē)、機(jī)器人、數(shù)字助理和衛(wèi)星觀(guān)測(cè)等領(lǐng)域。
一些應(yīng)用程序要求神經(jīng)網(wǎng)絡(luò)太大,無(wú)法安裝在單個(gè)NorthPole芯片上。Modha說(shuō),在這種情況下,這些網(wǎng)絡(luò)可以分解成更小的部分,可以分布在多個(gè)NorthPole芯片上。
IBM指出,NorthPole的效率顯示出它不需要龐大的液體冷卻系統(tǒng)來(lái)運(yùn)行——風(fēng)扇和散熱器就足夠了。這意味著它可以部署在更小的空間。
科學(xué)家們注意到,IBM用12納米的節(jié)點(diǎn)工藝制造了NorthPole。目前CPU的技術(shù)水平是3納米,IBM已經(jīng)花了數(shù)年時(shí)間研究2納米節(jié)點(diǎn)。該公司表示,這表明,這種類(lèi)腦策略可能很容易取得進(jìn)一步的成果。
NorthPole的架構(gòu)類(lèi)型通常被稱(chēng)為內(nèi)存計(jì)算,可以是數(shù)字的,也可以是模擬的。在諸如NorthPole之類(lèi)的數(shù)字內(nèi)存計(jì)算系統(tǒng)中,需要許多電路來(lái)運(yùn)行乘法-累加(MAC)運(yùn)算,這是神經(jīng)網(wǎng)絡(luò)中最基本的計(jì)算。相比之下,內(nèi)存中的模擬計(jì)算系統(tǒng)擁有更適合執(zhí)行這些操作的組件。
內(nèi)存中的模擬計(jì)算比數(shù)字計(jì)算需要更少的功率和空間。然而,這些模擬系統(tǒng)通常需要新的材料和制造技術(shù),而NorthPole是使用傳統(tǒng)的半導(dǎo)體制造技術(shù)制造的。
Roychowdhury表示:“鑒于模擬系統(tǒng)尚未達(dá)到技術(shù)成熟度,這項(xiàng)工作為人工智能在需要的地方部署提供了一個(gè)近期選擇。”
———————End———————
新生態(tài),創(chuàng)未來(lái) | 2023RT-Thread 開(kāi)發(fā)者大會(huì)開(kāi)啟報(bào)名
邀請(qǐng)你參加 2023 RT-Thread 開(kāi)發(fā)者大會(huì)的六大理由
1、刷新RT-Thread最新技術(shù)動(dòng)態(tài)和產(chǎn)業(yè)服務(wù)能力
2、聆聽(tīng)行業(yè)大咖分享,洞察產(chǎn)業(yè)趨勢(shì)
3、豐富的技術(shù)和產(chǎn)品展示,前沿技術(shù)發(fā)展和應(yīng)用
4、絕佳的實(shí)踐機(jī)會(huì):AIOT、MPU、RISC-V...
5、精美伴手禮人手一份開(kāi)發(fā)板盲盒和免費(fèi)午餐
6、黑科技滿(mǎn)點(diǎn)~滴水湖地鐵口安排無(wú)人車(chē)接送至?xí)?chǎng)
立刻掃碼報(bào)名吧

-
RT-Thread
+關(guān)注
關(guān)注
31文章
1286瀏覽量
40102
原文標(biāo)題:【AI簡(jiǎn)報(bào)20231103期】ChatGPT參數(shù)揭秘,中文最強(qiáng)開(kāi)源大模型來(lái)了!
文章出處:【微信號(hào):RTThread,微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
開(kāi)源AI模型庫(kù)是干嘛的
開(kāi)源與閉源之爭(zhēng):最新的開(kāi)源模型到底還落后多少?
Llama 3 與開(kāi)源AI模型的關(guān)系

4050億參數(shù)!Meta發(fā)布最強(qiáng)開(kāi)源AI模型Llama3.1
Meta即將發(fā)布超強(qiáng)開(kāi)源AI模型Llama 3-405B
名單公布!【書(shū)籍評(píng)測(cè)活動(dòng)NO.34】大語(yǔ)言模型應(yīng)用指南:以ChatGPT為起點(diǎn),從入門(mén)到精通的AI實(shí)踐教程
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來(lái)了
通義千問(wèn)推出1100億參數(shù)開(kāi)源模型
Meta推出最強(qiáng)開(kāi)源模型Llama 3 要挑戰(zhàn)GPT

號(hào)稱(chēng)全球最強(qiáng)開(kāi)源AI模型DBRX登場(chǎng)
海信發(fā)布電視行業(yè)最強(qiáng)中文大模型,開(kāi)啟電視AI新時(shí)代
谷歌發(fā)布輕量級(jí)開(kāi)源人工智能模型Gemma
新火種AI|谷歌深夜炸彈!史上最強(qiáng)開(kāi)源模型Gemma,打響新一輪AI之戰(zhàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論