


前言
網(wǎng)上關(guān)于BIO和塊設(shè)備讀寫流程的文章何止千萬,但是能夠讓你徹底讀懂讀明白的文章實在難找,可以說是越讀越糊涂!
我曾經(jīng)跨過山和大海 也穿過人山人海
我曾經(jīng)問遍整個世界 從來沒得到答案
本文用一個最簡單的read(fd, buf, 4096)的代碼,分析它從開始讀到讀結(jié)束,在整個Linux系統(tǒng)里面波瀾壯闊的一生。本文涉及到的代碼如下:
#include
#include
main()
{
int fd;
char buf[4096];
sleep(30); //run ./funtion.sh to trace vfs_read of this process
fd = open("file", O_RDONLY);
read(fd, buf, 4096);
read(fd, buf, 4096);
}
本文的寫作宗旨是:絕不裝逼,一定要簡單,簡單,再簡單!
本文適合:已經(jīng)讀了很多亂七八糟的block資料,但是沒打通脈絡(luò)的讀者;
本文不適合:完全不知道block子系統(tǒng)是什么的讀者,和完全知道block子系統(tǒng)是什么的讀者
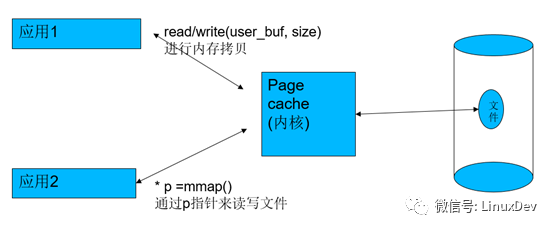
Page cache與預(yù)讀
在Linux中,內(nèi)存充當(dāng)硬盤的page cache,所以,每次讀的時候,會先check你讀的那一部分硬盤文件數(shù)據(jù)是否在內(nèi)存命中,如果沒有命中,才會去硬盤;如果已經(jīng)命中了,就直接從內(nèi)存里面讀出來。如果是寫的話,應(yīng)用如果是以非SYNC方式寫的話,寫的數(shù)據(jù)也只是進(jìn)內(nèi)存,然后由內(nèi)核幫忙在適當(dāng)?shù)臅r機(jī)writeback進(jìn)硬盤。
代碼中有2行read(fd, buf, 4096),第1行read(fd, buf, 4096)發(fā)生的時候,顯然”file”文件中的數(shù)據(jù)都不在內(nèi)存,這個時候,要執(zhí)行真正的硬盤讀,app只想讀4096個字節(jié)(一頁),但是內(nèi)核不會只是讀一頁,而是要多讀,提前讀,把用戶現(xiàn)在不讀的也先讀,因為內(nèi)核懷疑你讀了一頁,接著要連續(xù)讀,懷疑你想讀后面的。與其等你發(fā)指令,不如提前先斬后奏(存儲介質(zhì)執(zhí)行大塊讀比多個小塊讀要快),這個時候,它會執(zhí)行預(yù)讀,直接比如讀4頁,這樣當(dāng)你后面接著讀第2-4頁的硬盤數(shù)據(jù)的時候,其實是直接命中了。
所以這個代碼路徑現(xiàn)在是 :

當(dāng)你執(zhí)行完第一個read(fd, buf, 4096)后,”file”文件的0~16KB都進(jìn)入了pagecache,同時內(nèi)核會給第2頁標(biāo)識一個PageReadahead標(biāo)記,意思就是如果app接著讀第2頁,就可以預(yù)判app在做順序讀,這樣我們在app讀第2頁的時候,內(nèi)核可以進(jìn)一步異步預(yù)讀。
第一個read(fd,buf, 4096)之前,page cache命中情況(都不命中):

第一個read(fd,buf, 4096)之后,page cache命中情況:

我們緊接著又碰到第二個read(fd, buf, 4096),它要讀硬盤文件的第2頁內(nèi)容,這個時候,第2頁是page cache命中的,這一次的讀,由于第2頁有PageReadahead標(biāo)記,讓內(nèi)核覺得app就是在順序讀文件,內(nèi)核會執(zhí)行更加激進(jìn)的異步預(yù)讀,比如讀文件的第16KB~48KB。
所以第二個read(fd,buf, 4096)的代碼路徑現(xiàn)在是 :

第二個read(fd,buf, 4096)之前,page cache命中情況:

第二個read(fd,buf, 4096)之后,page cache命中情況:

內(nèi)存到硬盤的轉(zhuǎn)換
剛才我們提到,第一次的read(fd, buf, 4096),變成了讀硬盤里面的16KB數(shù)據(jù),到內(nèi)存的4個頁面(對應(yīng)硬盤里面文件數(shù)據(jù)的第0~16KB)。但是我們還是不知道,硬盤里面文件數(shù)據(jù)的第0~16KB在硬盤的哪些位置?我們必須把內(nèi)存的頁,轉(zhuǎn)化為硬盤里面真實要讀的位置。
在Linux里面,用于描述硬盤里面要真實操作的位置與page cache的頁映射關(guān)系的數(shù)據(jù)結(jié)構(gòu)是bio。相信大家已經(jīng)見到bio一萬次了,但是就是和真實的案例對不上。
bio的定義如下(include/linux/blk_types.h):
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
struct bio {
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
…
struct bvec_iter bi_iter;
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned int bi_phys_segments;
…
bio_end_io_t *bi_end_io;
void *bi_private;
unsigned short bi_vcnt; /* how many bio_vec's */
atomic_t bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
…
};
它是一個描述硬盤里面的位置與page cache的頁對應(yīng)關(guān)系的數(shù)據(jù)結(jié)構(gòu),每個bio對應(yīng)的硬盤里面一塊連續(xù)的位置,每一塊硬盤里面連續(xù)的位置,可能對應(yīng)著page cache的多頁,或者一頁,所以它里面會有一個bio_vec *bi_io_vec的表。
我們現(xiàn)在假設(shè)2種情況
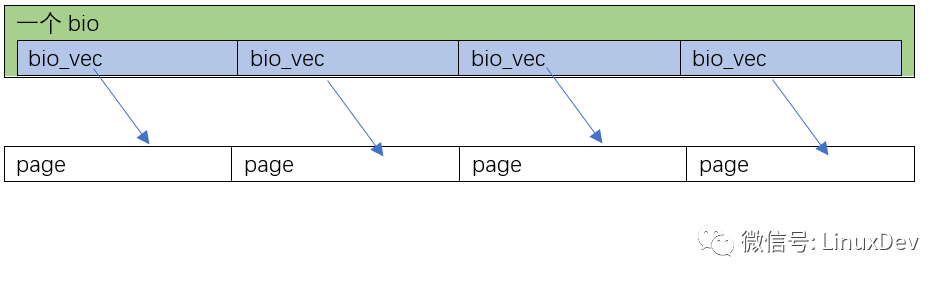
第1種情況是page_cache_sync_readahead()要讀的0~16KB數(shù)據(jù),在硬盤里面正好是順序排列的(是否順序排列,要查文件系統(tǒng),如ext3、ext4),Linux會為這一次4頁的讀,分配1個bio就足夠了,并且讓這個bio里面分配4個bi_io_vec,指向4個不同的內(nèi)存頁:
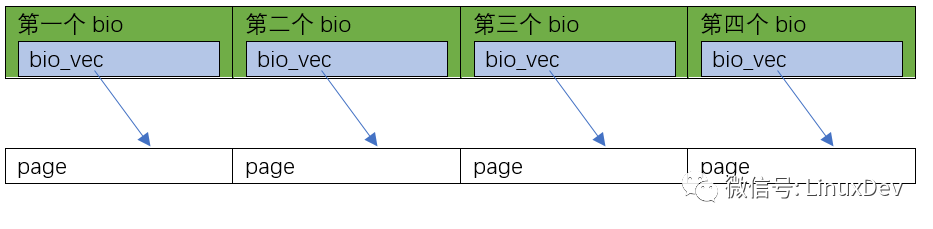
第2種情況是page_cache_sync_readahead()要讀的0~16KB數(shù)據(jù),在硬盤里面正好是完全不連續(xù)的4塊 (是否順序排列,要查文件系統(tǒng),如ext3、ext4),Linux會為這一次4頁的讀,分配4個bio,并且讓這4個bio里面,每個分配1個bi_io_vec,指向4個不同的內(nèi)存頁面:
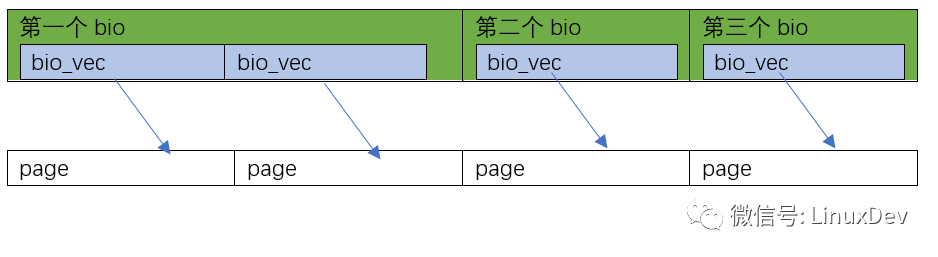
當(dāng)然你還可以有第3種情況,比如0~8KB在硬盤里面連續(xù),8~16KB不連續(xù),那可以是這樣的:
其他的情況請類似推理…完成這項工作的史詩級的代碼就是mpage_readpages()。

mpage_readpages()會間接調(diào)用ext4_get_block(),真的搞清楚0~16KB的數(shù)據(jù),在硬盤里面的擺列位置,并依據(jù)這個信息,轉(zhuǎn)化出來一個個的bio。
bio和request的三進(jìn)三出
人生,說到最后,簡單得只有生死兩個字。但由于有了命運的浮沉,由于有了人世的冷暖,簡單的過程才變得跌宕起伏,紛繁復(fù)雜。小平三落三起,最終建立了不朽的功勛。曼德拉受非人待遇在監(jiān)獄服刑數(shù)十年,終成世界公認(rèn)的領(lǐng)袖。走向自由之路不會平坦,斗爭就是生活。與天斗,其樂無窮;與地斗,其樂無窮;與Linux斗,痛苦無窮!
bio產(chǎn)生后,到最終的完成,同樣經(jīng)歷了三進(jìn)三出的隊列,這個過程的艱辛和痛苦,讓人欲罷不能,欲說還休,求生不得求死不能。
這三步是:
1.原地蓄勢
把bio轉(zhuǎn)化為request,把request放入進(jìn)程本地的plug隊列;蓄勢多個request后,再進(jìn)行泄洪。
2.電梯排序
進(jìn)程本地的plug隊列的request進(jìn)入到電梯,進(jìn)行再次的合并、排序,執(zhí)行QoS的排隊,之后按照QoS的結(jié)果,分發(fā)給塊設(shè)備驅(qū)動。電梯內(nèi)部的實現(xiàn),可以有各種各樣的隊列。
3.分發(fā)執(zhí)行
電梯分發(fā)的request,被設(shè)備驅(qū)動的request_fn()挨個取出來,派發(fā)真正的硬件讀寫命令到硬盤。這個分發(fā)的隊列,一般就是我們在塊設(shè)備驅(qū)動里面見到的request_queue了。
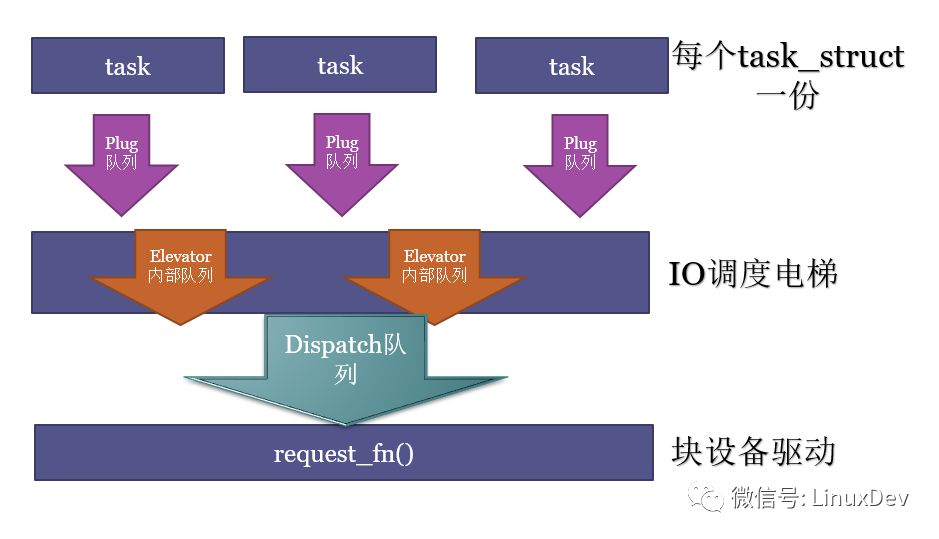
下面我們再一一呈現(xiàn),這三進(jìn)三出。
原地蓄勢
在Linux中,每個task_struct(對應(yīng)一個進(jìn)程,或輕量級進(jìn)程——線程),會有一個plug的list。什么叫plug呢?類似于葛洲壩和三峽,先蓄水,當(dāng)app需要發(fā)多個bio請求的時候,比較好的辦法是先蓄勢,而不是一個個單獨發(fā)給最終的硬盤。
這個類似你現(xiàn)在有10個老師,這10個老師開學(xué)的時候都接受學(xué)生報名。然后有一個大的學(xué)生隊列,如果每個老師有一個學(xué)生報名的時候,都訪問這個唯一的學(xué)生隊列,那么這個隊列的操作會變成一個重要的鎖瓶頸:
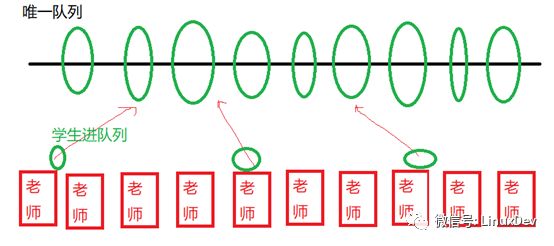
如果我們換一個方法,讓每個老師有學(xué)生報名的時候,每天的報名的學(xué)生掛在老師自己的隊列上面,老師的隊列上面掛了很多學(xué)生后,一天之后再泄洪,掛到最終的學(xué)生隊列,則可以避免這個問題,最終小隊列融合進(jìn)大隊列的時候控制住時序就好。
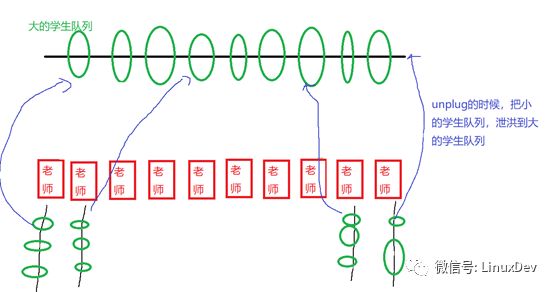
你會發(fā)現(xiàn),代碼路徑是這樣的:

read_pages()函數(shù)先把閘門拉上,然后發(fā)起一系列bio后,再通過blk_finish_plug()的調(diào)用來泄洪。

在這個蓄勢的過程中,還要完成一項重要的工作,就是make request(造請求)。這個完成“造請求”的史詩級的函數(shù),一般是void blk_queue_bio(struct request_queue *q, struct bio *bio),位于block/blk-core.c。
它會嘗試把bio合并進(jìn)入一個進(jìn)程本地plug list里面的一個request,如果無法合并,則造一個新的request。request里面包含一個bio的list,這個list的bio對應(yīng)的硬盤位置,最終在硬盤上是連續(xù)存放的。
下面我們假設(shè)"file"的第0~16KB在硬盤的存放位置為:

根據(jù)我們前面"內(nèi)存到硬盤的轉(zhuǎn)換"一節(jié)舉的例子,這屬于在硬盤里面完全不連續(xù)的"情況2",于是這4塊數(shù)據(jù),會被史詩級的mpage_readpages()轉(zhuǎn)化為4個bio。

當(dāng)他們進(jìn)入進(jìn)程本地的plug list的時候,由于最開始plug list為空,100顯然無法與誰合并,這樣形成一個新的request0。
Bio1也無法合并進(jìn)request0,于是得到新的request1。
Bio2正好可以合并進(jìn)request1,于是Bio1合并進(jìn)request1。
Bio3對應(yīng)硬盤的200塊,無法合并,于是得到新的request2。
現(xiàn)在進(jìn)程本地plug list上的request排列如下:

泄洪的時候,進(jìn)程本地的plug list的request,會通過調(diào)用elevator調(diào)度算法的elevator_add_req_fn() callback函數(shù),被加入電梯的隊列。
電梯排序
當(dāng)各個進(jìn)程本地的plug list里面的request被泄洪,以排山倒海之勢進(jìn)入的,不是最終的設(shè)備驅(qū)動(不會直接被拍死在沙灘上的),而是一個電梯排隊算法,進(jìn)行再一次的排隊。這個電梯調(diào)度,其實目的3個:
進(jìn)一步的合并request
把request對硬盤的訪問變得順序化
執(zhí)行QoS
電梯的內(nèi)部實現(xiàn)可以非常靈活,但是入口是elevator_add_req_fn(),出口是elevator_dispatch_fn()。
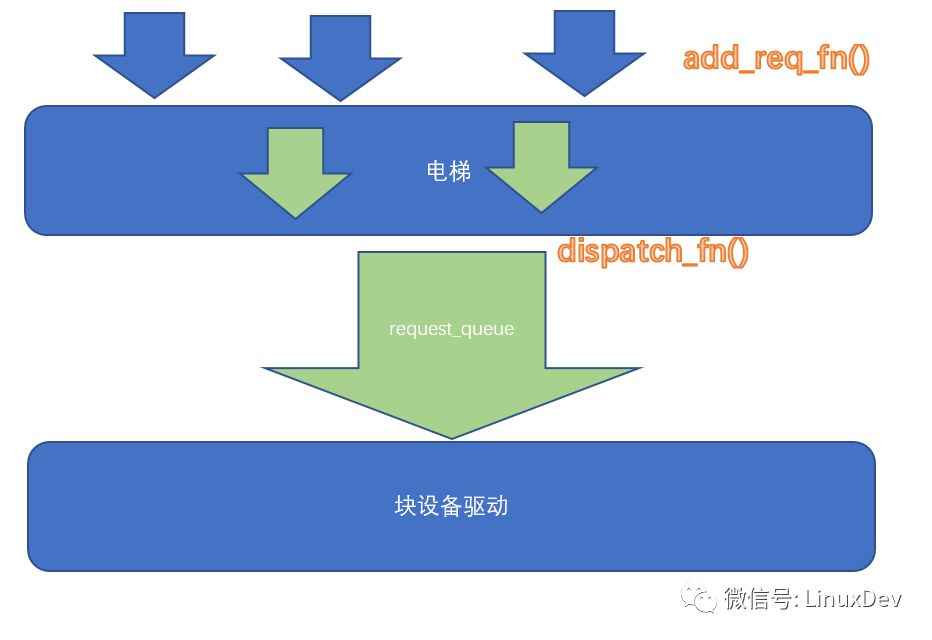
合并和排序都好理解,下面我們重點解釋QoS(服務(wù)質(zhì)量)。想象你家里的寬帶,有迅雷,有在線電影,有機(jī)頂盒看電視。
當(dāng)你只用迅雷下電影的時候,你當(dāng)然可以全速的下電影,但是當(dāng)你還看電視,在線看電影,這個時候,你可能會對迅雷限流,以保證相關(guān)電視盒電影的服務(wù)質(zhì)量。
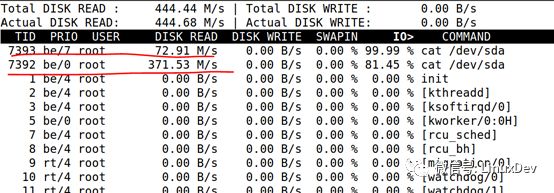
電梯調(diào)度里面也執(zhí)行同樣的邏輯,比如CFQ調(diào)度算法,可以根據(jù)進(jìn)程的ionice,調(diào)整不同進(jìn)程訪問硬盤的時候的優(yōu)先級。比如,如下2個優(yōu)先級不同的dd
# ionice-c 2 -n 0 cat /dev/sda > /dev/null&
# ionice -c 2 -n 7 cat /dev/sda >/dev/null&
最終訪問硬盤的速度是不一樣的,一個371M,一個只有72M。
所以當(dāng)泄洪開始,漫江碧透,百舸爭流,誰能到中流擊水,浪遏飛舟?QoS是一個關(guān)于一將功成萬骨枯的故事。
目前常用的IO電梯調(diào)度算法有:cfq, noop, deadline。詳細(xì)的區(qū)別不是本文的重點,建議閱讀《劉正元:Linux 通用塊層之DeadLine IO調(diào)度器》從了解deadline的實現(xiàn)開始。
分發(fā)執(zhí)行
到了最后要交差的時刻了,設(shè)備驅(qū)動的request_fn()通過調(diào)用電梯調(diào)度算法的elevator_dispatch_fn()取出經(jīng)過QoS排序后的request并發(fā)命令給最終的存儲設(shè)備執(zhí)行I/O動作。
static void xxx_request_fn(struct request_queue *q)
{
struct request *req;
struct bio *bio;
while ((req = blk_peek_request(q)) != NULL) {
struct xxx_disk_dev *dev = req->rq_disk->private_data;
if (req->cmd_type != REQ_TYPE_FS) {
printk (KERN_NOTICE "Skip non-fs request ");
blk_start_request(req);
__blk_end_request_all(req, -EIO);
continue;
}
blk_start_request(req);
__rq_for_each_bio(bio, req)
xxx_xfer_bio(dev, bio);
}
}
request_fn()只是派發(fā)讀寫事件和命令,最終的完成一般是在另外一個上下文,而不是發(fā)起IO的進(jìn)程。request處理完成后,探知到IO完成的上下文會以blk_end_request()的形式,通知等待IO請求完成的本進(jìn)程。主動發(fā)起IO的進(jìn)程的代碼序列一般是:
submit_bio()
io_schedule(),放棄CPU。
blk_end_request()一般把io_schedule()后放棄CPU的進(jìn)程喚醒。io_schedule()的這段等待時間,會計算到進(jìn)程的iowait時間上,詳見:《朱輝(茶水):Linux Kernel iowait 時間的代碼原理》。
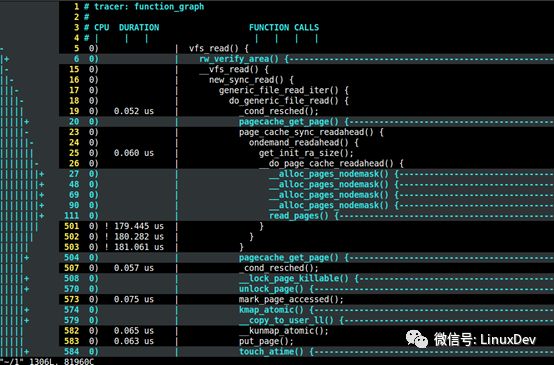
用Ftrace抓所有流程
本文所涉及到的所有流程,都可以用ftrace跟蹤到。這樣可以了解更多更深刻的細(xì)節(jié)。
char buf[4096];
sleep(30); //run ./funtion.sh to trace vfs_read of this process
fd = open("file", O_RDONLY);
read(fd, buf, 4096);
在上述代碼的中間,我特意留下了30秒的延時,在這個延時的空擋,你可以啟動如下的腳本,來對整個過程進(jìn)行function graph的trace,抓取進(jìn)程對vfs_read()開始后的調(diào)用棧:
#!/bin/bash
debugfs=/sys/kernel/debug
echo nop > $debugfs/tracing/current_tracer
echo 0 > $debugfs/tracing/tracing_on
echo `pidof read` > $debugfs/tracing/set_ftrace_pid
echo function_graph > $debugfs/tracing/current_tracer
echo vfs_read > $debugfs/tracing/set_graph_function
echo 1 > $debugfs/tracing/tracing_on
筆者也是通過ftrace的結(jié)果,用vim打開,逐句分析的。關(guān)于ftrace使用的詳細(xì)方法,可以閱讀《宋寶華:關(guān)于Ftrace的一個完整案例》。
最后的話
本文描述的是主干,許多的細(xì)節(jié)和代碼分支沒有涉及,因為在本文描述太多的分支,會讓讀者抓不住主干。很多分支都沒有介紹,比如unplug的泄洪,除了可以人為的blk_finish_plug()泄洪外,也會發(fā)生plug隊列較滿的時候,以及進(jìn)程睡眠schedule()的時候的自動泄洪。另外,關(guān)于寫,后面的三進(jìn)三出的過程,基本與讀類似,但是寫有個page cache堆積和writeback的啟動機(jī)制,是read所沒有的。
審核編輯:湯梓紅
-
硬盤
+關(guān)注
關(guān)注
3文章
1339瀏覽量
58684 -
Linux
+關(guān)注
關(guān)注
88文章
11534瀏覽量
214803 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3132瀏覽量
75430 -
Linux系統(tǒng)
+關(guān)注
關(guān)注
4文章
606瀏覽量
28839 -
代碼
+關(guān)注
關(guān)注
30文章
4907瀏覽量
71209
原文標(biāo)題:宋寶華:Linux文件讀寫(BIO)波瀾壯闊的一生
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Linux文件系統(tǒng)啟動流程
Linux文件系統(tǒng)課程
文件I/O編程之文件讀寫及上鎖實驗
《Linux設(shè)備驅(qū)動開發(fā)詳解》第5章、Linux文件系統(tǒng)與設(shè)備文件系統(tǒng)

linux文件系統(tǒng)基礎(chǔ)
可以了解的Linux 文件系統(tǒng)結(jié)構(gòu)
需要了解的Linux內(nèi)核讀寫文件
Linux系統(tǒng)日志文件中的JFS文件系統(tǒng)
Linux文件系統(tǒng)解析
嵌入式linux系統(tǒng)中常用的文件系統(tǒng)

Linux I/O 接口的類型及處理流程
Linux的文件系統(tǒng)特點





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論