 178頁,128個案例,GPT-4V醫療領域全面測評,離臨床應用與實際決策尚有距離
178頁,128個案例,GPT-4V醫療領域全面測評,離臨床應用與實際決策尚有距離
在大型基礎模型的推動下,人工智能的發展近來取得了巨大進步,尤其是 OpenAI 的 GPT-4,其在問答、知識方面展現出的強大能力點亮了 AI 領域的尤里卡時刻,引起了公眾的普遍關注。
GPT-4V (ision) 是 OpenAI 最新的多模態基礎模型。相較于 GPT-4,它增加了圖像與語音的輸入能力。該研究則旨在通過案例分析評估 GPT-4V (ision) 在多模態醫療診斷領域的性能,一共展現并分析共計了 128(92 個放射學評估案例,20 個病理學評估案例以及 16 個定位案例)個案例共計 277 張圖像的 GPT-4V 問答實例(注:本文不會涉及案例展示,請參閱原論文查看具體的案例展示與分析)。

-
ArXiv 鏈接:https://arxiv.org/abs/2310.09909
-
百度云下載地址:https://pan.baidu.com/s/11xV8MkUfmF3emJQH9awtcw?pwd=krk2
-
Google Drive下載地址:https://drive.google.com/file/d/1HPvPDwhgpOwxi2sYH3_xrcaoXjBGWhK9/view?usp=sharing
總結而言,原作者希望系統地評估 GPT-4V 如下的多種能力:
-
GPT-4V 能否識別醫學圖像的模態和成像位置?識別各種模態(如 X 射線、CT、核磁共振成像、超聲波和病理)并識別這些圖像中的成像位置,是進行更復雜診斷的基礎。
-
GPT-4V 能否定位醫學影像中的不同解剖結構?精確定位圖像中的特定解剖結構對識別異常、確保正確處理潛在問題至關重要。
-
GPT-4V 能否發現和定位醫學圖像中的異常?檢測異常,如 腫瘤、骨折或感染是醫學圖像分析的主要目標。在臨床環境中,可靠的人工智能模型不僅需要發現這些異常,還需要準確定位,以便進行有針對性的干預或治療。
-
GPT-4V 能否結合多張圖像進行診斷?醫學診斷往往需要綜合不同成像模態或視圖的信息,進行整體觀察。因此探究 GPT-4V 組合和分析多圖信息的能力至關重要。
-
GPT-4V 能否撰寫醫療報告,描述異常情況和相關的正常結果?對于放射科醫生和病理學家來說,撰寫報告是一項耗時的工作。如果 GPT-4V 在這一過程中提供幫助,生成準確且與臨床相關的報告,無疑將提高整個工作流程的效率。
-
GPT-4V 能否在解讀醫學影像時整合患者病史?患者的基本信息和既往病史會在很大程度上影響對當前醫學影像的解讀。在模型預測過程中如果能綜合考慮到這些信息去分析圖像將使分析更加個性化,也更加準確。
-
GPT-4V 能否在多輪交互中保持一致性和記憶性?在某些醫療場景中,單輪分析可能是不夠的。在長時間的對話或分析過程中,尤其是在復雜的醫療環境中,保持對數據認知的連續性至關重要。
原論文的評估涵蓋了 17 個醫學系統,包括:中樞神經系統、頭頸部、心臟、胸部、血液、肝膽、肛腸、泌尿、婦科、產科、乳腺科、肌肉骨骼科、脊柱科、血管科、腫瘤科、創傷科、兒科。
圖像來自日常臨床使用的 8 種模態,包括:X 光、計算機斷層掃描 (CT)、磁共振成像 (MRI)、正電子發射斷層掃描 (PET)、數字減影血管造影 (DSA)、 乳房 X 射線照相術、超聲波檢查和病理學檢查。
論文指出,雖然 GPT-4V 在區分醫學影像模態和解剖結構方面表現出很強的能力,但在疾病診斷和生成綜合報告方面卻仍面臨巨大挑戰。這些發現突出表明,雖然大型多模態模型在計算機視覺和自然語言處理方面取得了重大進展,但仍遠未達到有效支持真實世界的醫療應用和臨床決策的要求。
測試案例挑選
原論文的放射學問答來自于 Radiopaedia,圖像直接從網頁下載,定位案例來自于多個醫學公開分割數據集,病理圖像則來自于 PathologyOutlines 。在挑選案例時作者們全面的考慮了如下方面:
-
公布時間:考慮到 GPT-4V 的訓練數據極有可能異常龐大,為了避免所選到的測試案例出現在訓練集中,作者只選用了 2023 年發布的最新案例。
-
標注可信度:醫療診斷本身具有爭議和模糊性,作者根據 Radiopaedia 提供的案例完成度,盡量選用完成度大于 90% 的案例來保證標注或診斷的可信程度。
-
圖像模態多樣性:在選取案例時,作者盡可能地展示 GPT-4V 對于多種成像模態的響應情況。
在圖像處理時作者也做了如下規范化以保證輸入圖像的質量:
-
多圖選擇:考慮到 GPT-4V 支持的最大圖像輸入上限為 4,但部分案例會有超過 4 張的相關圖像,首先作者在選取案例時會盡可能避免這種情況,其次在不可避免地遇到這種案例時,作者會根據 Radiopaedia 提供的案例注釋挑選最相關的圖像。
-
截面選擇:大量的放射圖像數據為 3D(連續多幀二維圖像)形式,無法直接輸入 GPT-4V,必須挑選一個最有代表性的截面代替完整的 3D 圖像輸入 GPT-4V。根據 Radiopaedia 的案例上傳規范,放射醫生在上傳 3D 圖像時被要求選擇一個最相關的截面。作者們利用了這一點,選用了 Radiopaedia 推薦的軸截面替代 3D 數據進行輸入。
-
圖像標準化:醫療圖像的標準化設計窗寬窗位的選擇,不同的視窗會突出不同的組織,作者們使用的 Radiopaedio 案例上傳時放射專家所選擇的窗寬窗位輸入圖像。對于分割數據集而言,原論文則采用了 [-300,300] 的視窗,并作 0-1 的案例級的歸一化。
原論文的測試均使用了 GPT-4V 的網頁版,第一輪問答用戶會輸入圖像,然后展開多輪的問答。為了避免上下文的互相影響,對于每次新的案例,都會新建一個問答窗口進行問答。
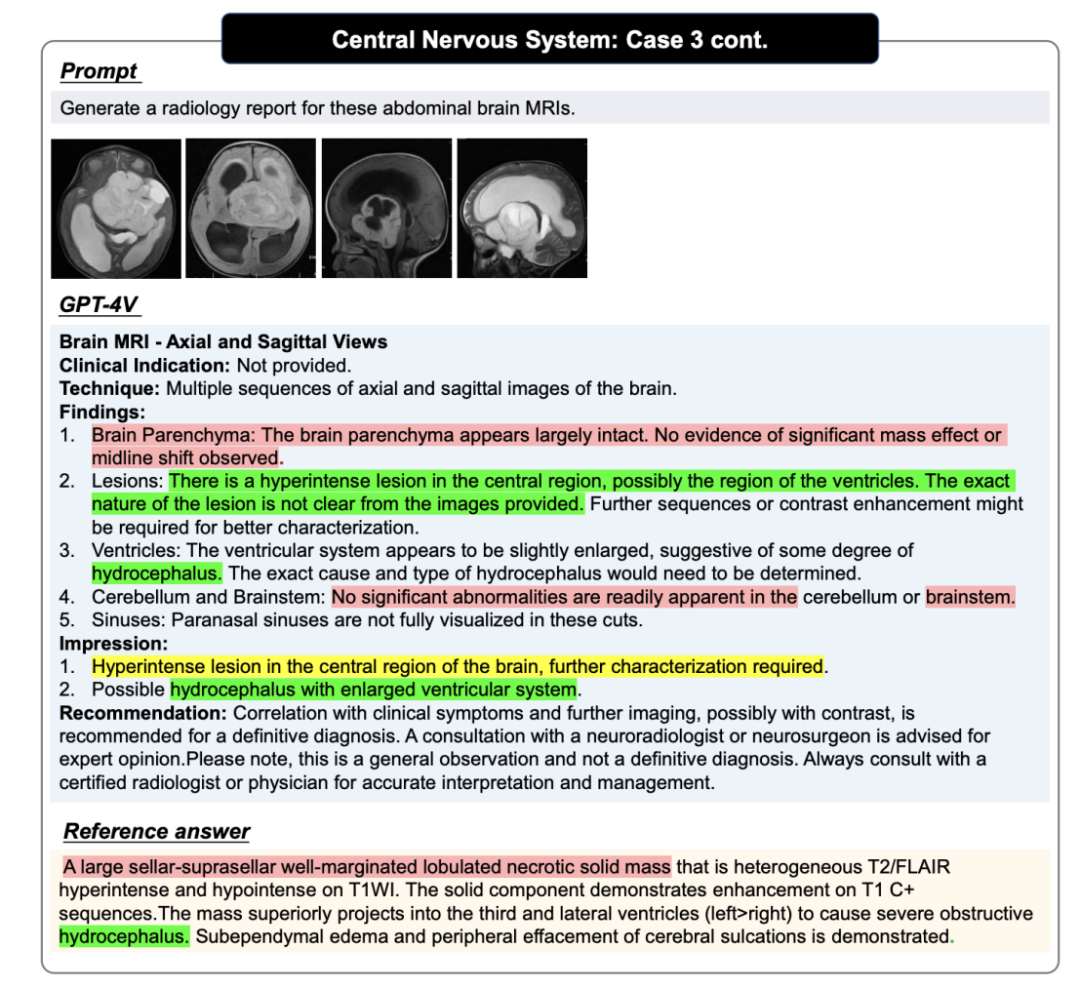 GPT-4V 問答案例,圖中紅色代表錯誤,黃色代表不確定,綠色代表正確,Reference 中的顏色則代表對應判斷的依據,未標記顏色的句子需要讀者自行判斷正確性,更多案例以及案例分析請參考原論文
GPT-4V 問答案例,圖中紅色代表錯誤,黃色代表不確定,綠色代表正確,Reference 中的顏色則代表對應判斷的依據,未標記顏色的句子需要讀者自行判斷正確性,更多案例以及案例分析請參考原論文
在病理評估中,所有圖像都會進行兩輪對話。第一輪詢問能否僅根據輸入圖像生成報告。這一輪的目的是評估 GPT-4V 能否在不提供任何相關醫療提示的情況下識別圖像模態和組織來源。在第二輪中,用戶會提供正確的組織來源,并詢問 GPT-4V 是否能根據病理圖像及其組織來源信息做出診斷,希望 GPT-4V 能修改報告并提供明確的診斷結果。
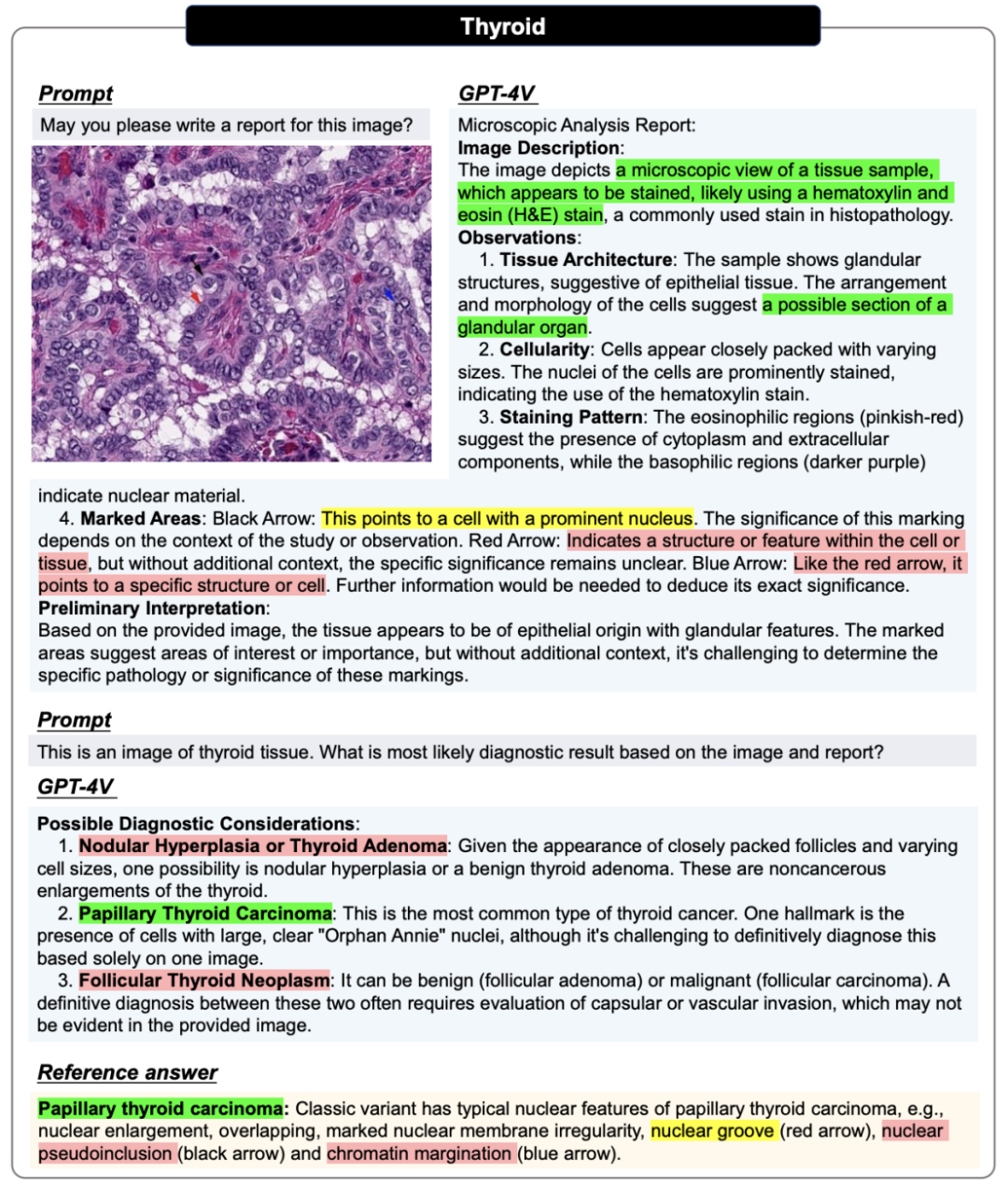
病理圖像的案例展示,更多案例以及案例分析請參考原論文
在定位評估中,原論文采取了循序漸進的方式:首先測試 GPT-4V 是否能識別出所提供圖像中目標的存在;然后要求它根據圖像左上角為(x,y)=(0,0)和右下角為(x,y)=(w,h)生成目標的邊界框坐標,并對每個單一定位任務重復評估多次,以獲得至少 4 個預測邊界框,計算它們的 IOU 分數,并選出最高的一個來證明其上限性能;然后得出平均邊界框,計算 IOU 分數,以證明其平均性能。
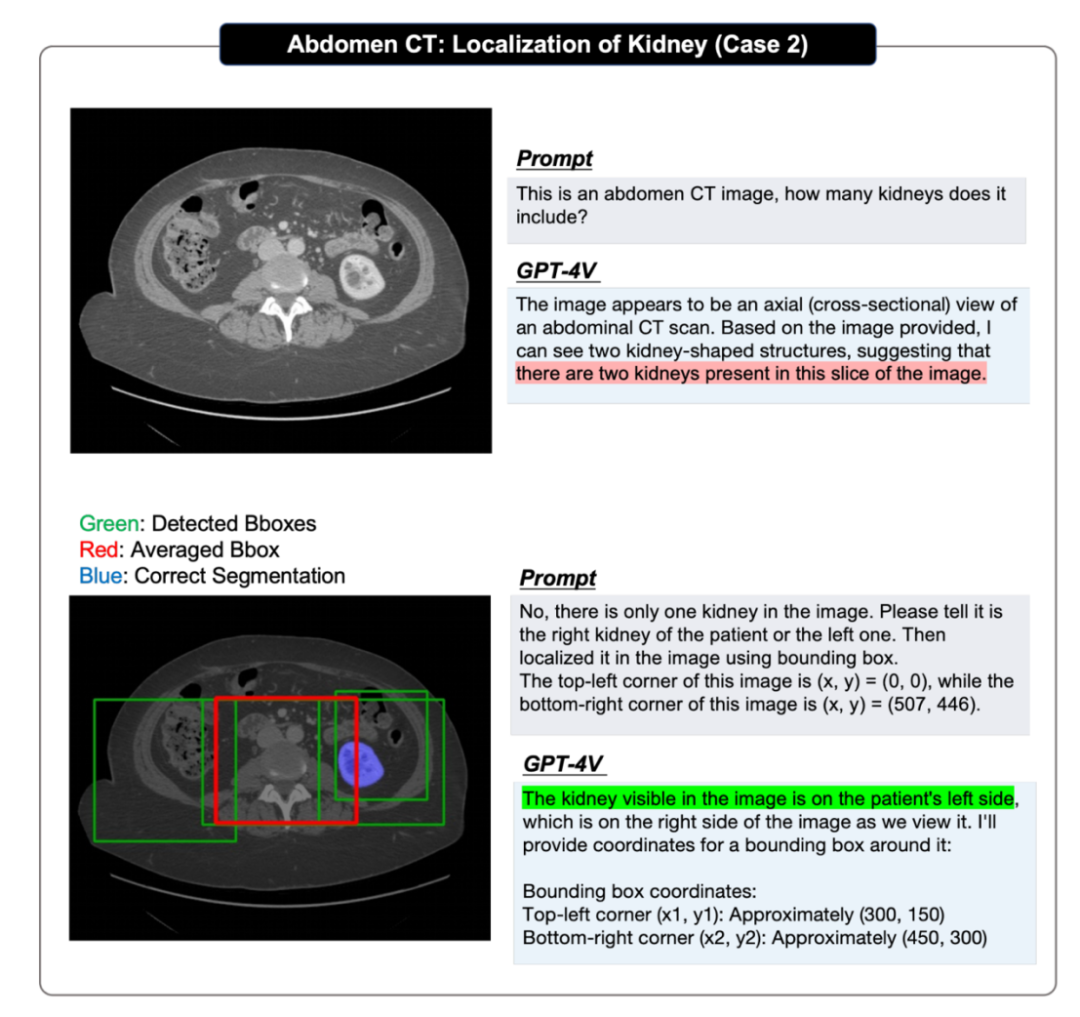
定位問答的案例展示,更多案例以及案例分析請參考原論文
測評中的局限性
當然原作者也提到了一些測評中的不足與限制:
1. 只能進行定性而非定量的評估
鑒于 GPT-4V 只提供在線網頁界面,只能手動上傳測試用例,導致原評估報告在可擴展性方面受到限制,因此只能提供定性評估。
2. 樣本偏差
所選樣本均來自在線網站,可能無法反映日常門診中的數據分布情況。尤其是大多數評估病例都是異常病例,這可能會給評估帶來潛在偏差。
3. 注釋或參考答案并不完整
從 Radiopaedia 或者 PathologyOutlines 網站上獲得的參考描述大多沒有結構,也沒有標準化的放射學 / 病理學報告格式。特別是,這些報告中的大部分主要側重于描述異常情況,而不是對病例進行全面描述,并不能直接作為完美的回復簡單對比。
4. 只有二維切片輸入
在實際臨床環境中,包括 CT、MRI 掃描在內的放射圖像通常采用 3D DICOM 格式。然而,GPT-4V 最多只能支持四張二維圖像的輸入,所以原文在測評時只能輸入二維關鍵切片或小片段(用于病理學)。
總之,盡管評估可能并不徹底詳盡,但原作者們相信,這一分析仍舊可以為研究人員和醫學專業人員提供了寶貴的見解,它揭示了多模態基礎模型的當前能力,并可能激勵未來建立醫學基礎模型的工作。
重要觀察結果
原測評報告根據測評案例,概括了多個觀察到的 GPT-4V 的表現特點:
放射案例部分
作者們根據 92 個放射學評估案例和 20 個定位案例得出如下觀察結果:
1. GPT-4V 可以辨識出醫療圖像的模態以及成像位置
對于大多數圖像內容的模態識別、成像部位判定以及圖像平面類別判定等任務,GPT4-V 都表現出了良好的處理能力。例如,作者們指出 GPT-4V 能很容易區分核磁共振、CT、X 光等各種模態;判斷圖像所描述的人體具體部位;判斷出核磁共振圖像的軸位、失狀位和冠狀位等。
2. GPT-4V 幾乎無法做出精確的診斷
作者們發現:一方面,OpenAI 似乎設置了安全機制,嚴格限制了 GPT-4V 做出直接診斷;另一方面,除了針對非常明顯的診斷案例,GPT-4V 的分析能力較差,僅局限于列舉出可能存在的一系列疾病,而不能給出較為精確的診斷。
3. GPT-4V 可以生成出結構化的報告,但是內容大部分并不正確
GPT-4V 在絕大多數情況下都能生成較為標準的報告,但作者們認為,相比于整合程度更高且內容更靈活的手寫報告,在針對多模態或多幀圖像時,它更傾向于逐圖描述且缺乏綜合能力。因此內容大部分參考價值較小且缺乏準確性。
4. GPT-4V 可以辨識出醫學圖像中的標記以及文本注釋,但并不能理解其出現在圖像中的意義
GPT-4V 展現出較強的文本識別、標記識別等能力,并且會嘗試利用這些標記進行分析。但作者們認為,其局限性在于:其一,GPT-4V 總是會過度利用文本和標記且圖像本身成為次要參考對象;其二,它魯棒性較低,常常會誤解圖像中的醫學注釋和引導。
5. GPT-4V 可以辨識出醫療植入器械以及它們在圖像中的位置
在大多數案例中,GPT4-V 都能正確識別到植入人體的醫療設備,并較為準確地定位它們的位置。并且作者們發現,甚至在一些較為困難的案例中,可能出現診斷錯誤,但判斷醫療設備識別正確的情況。
6. GPT-4V 面對多圖輸入時會遇到分析障礙
作者們發現,在面對同一模態的不同視角下的圖像時,GPT-4V 盡管會展現出相比于進輸入單張圖的更好的分析能力,但仍然傾向于分別對每張視圖進行單獨的分析;而在面對不同模態的圖像混合輸入時,GPT-4V 更難得出綜合了不同模態信息的合理分析。
7. GPT-4V 的預測極易受到患者疾病史的引導
作者們發現是否提供患者疾病史會對 GPT-4V 的回答產生較大影響。在提供疾病史的情況下,GPT-4V 常常會將其作為關鍵點,對圖中的潛在異常做出推斷;而在不提供疾病史的情況下,GPT-4V 則會更傾向于將圖像作為正常案例進行分析。
8. GPT-4V 并不能在醫學圖像中定位到解剖結構和異常
作者們認為 GPT-4V 定位效果較差主要表現為:其一,GPT-4V 在定位過程中總是會得到遠離真實邊界的預測框;其二,它在對同一幅圖的多輪重復預測中表現出顯著的隨機性;其三,GPT-4V 顯示出了明顯的偏置性,例如:腦部 MRI 圖像中小腦一定位于底部。
9. GPT-4V 可以根據用戶的多輪交互,改變它的既有回答。
GPT-4V 可以在一系列的互動中修改其響應,使之正確。例如,在文中所示的例子中,作者們輸入了子宮內膜異位癥的 MRI 圖像。GPT-4V 最初錯誤地將盆腔 MRI 分類為膝關節 MRI,從而得到了一個不正確的輸出。但用戶通過與 GPT-4V 的多輪互動對其進行糾正,最終做出了準確的診斷。
10. GPT-4V 幻覺問題嚴重,尤其傾向將患者敘述為正常即使異常信號極為顯著。
GPT-4V 總是生成出結構上看上去非常完整詳實的報告,但其中的內容卻并不正確,很多時候即使圖像異常區域明顯它仍舊會認為患者正常。
11. GPT-4V 在醫學問答上不夠穩定
GPT-4V 在常見圖像和罕見圖像上的表現差異巨大,在不同的身體系統方面也展現出明顯的性能差別。另外,對同一醫學圖像的分析可能會因更改 prompt 而產生不一致的結果,例如,如,GPT-4V 在 “ What is the diagnosis for this brain CT?” 的 prompt 下最初判斷給定的圖像為異常,但后來它生成了一個認為同一圖像為正常的報告。這種不一致性強調了 GPT-4V 在臨床診斷中的性能可能是不穩定和不可靠的。
12. GPT-4V 對醫療領域做了嚴格的安全限制
作者們發現 GPT-4V 已經在醫學領域的問答中建立了防止潛在誤用的安全防護措施,確保用戶能夠安全使用。例如,當 GPT-4V 被要求做出診斷時,"Please provide the diagnosis for this chest X-ray.",它可能會拒絕給出答案,或強調 “我不是專業醫學建議的替代品”。在多數情況下,GPT-4V 會傾向于使用包含 “appears to be” 或 “could be” 之類的短語來表示不確定性。
病理案例部分
此外,作者們為了探索 GPT-4V 在病理圖像的報告生成和醫學診斷方面的能力,對來自不同組織的 20 種惡性腫瘤病理圖像開展了圖像塊級別的測試,并得出以下結論:
1. GPT-4V 能夠進行準確的模態識別
在所有測試案例中,GPT-4V 都可以正確地識別所有病理圖像(H&E 染色的組織病理圖像)的模態。
2. GPT-4V 能夠生成結構化報告
給定一個沒有任何醫學提示的病理圖像,GPT-4V 可以生成一個結構化且詳細的報告來描述圖像特征。在 20 個案例中,有 7 個案例能夠使用如 “組織結構”、“細胞特征”、“基質”、“腺體結構”、“細胞核” 等術語明確地列出了其觀察結果,甚至可以正確地從不同組織的病理圖像中識別腺體結構和上皮特征。
3. GPT-4V 在 Prompt 的引導下能夠對報告進行修正
當在第二輪對話的 prompt 中對組織器官進行修正時,GPT-4V 可以很大程度地修改報告修改其報告,并為預測正常的案例提供一個確切的診斷,或為預測異常的案例提供幾個可能的選項。
4. GPT-4V 生成的描述大多基于知識
盡管 GPT-4V 可以為病理圖像寫一個結構化的報告,但許多關于細胞和細胞核的詳細描述都是 H&E 染色圖像的通用特征,而不是根據圖像特有模式生成。此外,GPT-4V 提供的診斷結果也可能來源于通用醫學知識,而不是根據病理圖像的形態結構推理得到。
5. GPT-4V 的診斷性能有限
在 20 個案例中,GPT-4V 將四個腫瘤案例誤診為正常組織,正確診斷了源于膀胱、中樞神經系統和口腔組織中的 3 類癌癥,對其余 13 個惡性腫瘤則給出了模糊的診斷。尤其是針對肛門和子宮組織上的癌癥,GPT-4V 的診斷結果中既包含正常組織也涵蓋惡性腫瘤,這表明 GPT-4V 可能并沒有真正從這些病理圖像中檢測到異常。
總的來說,GPT-4V 在醫療領域的表現并不像 GPT-4 在醫療問答中那樣驚艷,遠未達到實際臨床要求。
本文只概括性的截取了部分原論文觀點,更多分析細節請參考原文。
-
物聯網
+關注
關注
2909文章
44701瀏覽量
373974
原文標題:178頁,128個案例,GPT-4V醫療領域全面測評,離臨床應用與實際決策尚有距離
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
解鎖 GPT-4o!2024 ChatGPT Plus 代升級全攻略(附國內支付方法)
云知聲山海多模態大模型UniGPT-mMed登頂MMMU測評榜首

GE醫療與亞馬遜云科技達成戰略合作,通過生成式AI加速醫療健康領域轉型
OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜

微軟調整Copilot Pro服務,移除GPT Builder功能
開發者如何調用OpenAI的GPT-4o API以及價格詳情指南
OpenAI CEO: GPT-4o and GPT-5引領未來12個月編程領域,GPT-5更具潛力
阿里云正式發布通義千問2.5,中文性能全面趕超GPT-4 Turbo
阿里云發布通義千問2.5大模型,多項能力超越GPT-4
訊飛星火大模型V3.5春季升級,多領域知識問答超越GPT-4 Turbo?
商湯科技發布5.0多模態大模型,綜合能力全面對標GPT-4 Turbo
微軟Copilot全面更新為OpenAI的GPT-4 Turbo模型
全球最強大模型易主,GPT-4被超越
Anthropic推出Claude 3系列模型,全面超越GPT-4,樹立AI新標桿
利用人工智能和機器人技術實現復雜的自動化任務!





 工商網監
工商網監
評論