") 如何在FPGA中實現(xiàn)高效的compressor加法樹呢?
如何在FPGA中實現(xiàn)高效的compressor加法樹呢?
大規(guī)模的整數(shù)加法在數(shù)字信號處理和圖像視頻處理領(lǐng)域應用很多,其對資源消耗很多,如何能依據(jù)FPGA物理結(jié)構(gòu)特點來有效降低加法樹的資源和改善其時序特征是非常有意義的。本篇論文是基于altera公司的FPGA,利用其LUT特點,探索設計最大程度利用LUT以及改善時序的compressor樹的結(jié)構(gòu)。
01
半加器和全加器
半加器是兩個輸入bit相加,輸出結(jié)果S和進位C。表達式為:
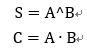
全加器是三個bit相加,有進位參與,表達式為:
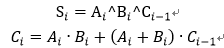
Compressor樹就是在全加器的基礎上建立的,通過全加器的S和C結(jié)果相互連接形成多層樹狀結(jié)構(gòu),其相比于普通的進位加法樹消耗更少資源。普通進位加法樹是用兩個或者三個加法模塊連接成樹,形成多層結(jié)構(gòu)來計算多輸入加法。放一張wallace樹的經(jīng)典文獻中的圖片來大致了解一下compressor樹的結(jié)構(gòu)。
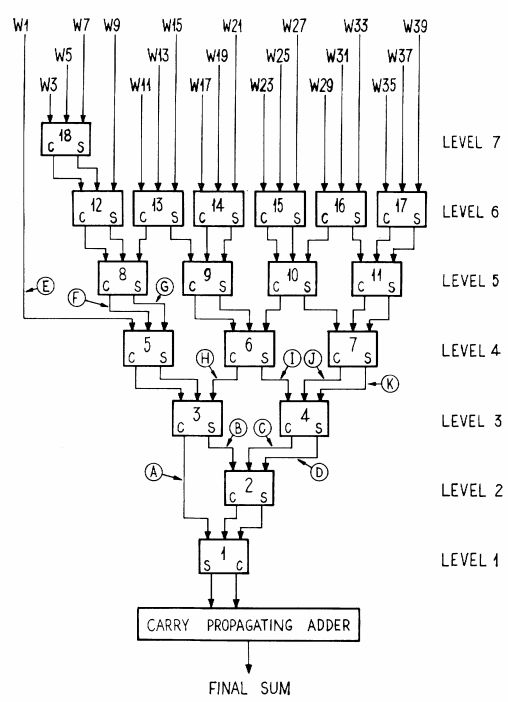
圖1.1 compressor樹結(jié)構(gòu)
02
Compressor樹
Compressor樹就是在圖1.1中carry propagating adder以上的部分,其目的就是為了減少被加數(shù)個數(shù),上圖中降低到S和C兩個后送到進位鏈加法器完成最后求和。這樣就可以降低加法對資源的消耗。假設有如下加數(shù):
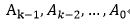
Compressor樹的結(jié)果就是:
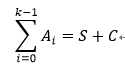
Compressor樹就是由以上的全加器構(gòu)成的。全加器構(gòu)成一個基本的并行計數(shù)器,并行計數(shù)器(Generalized parallel counters)GPC可以用一個元組表示:
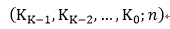
其中Ki表示的是輸入的被加數(shù)中處于同一位置的bit個數(shù),如果用點來代表bit,那么下圖中的bit0的個數(shù)有1,而bit1有2,bit2有3,…。假設一個GPC允許的最大輸入bit數(shù)為M,這個條件是考慮到FPGA中LUT的結(jié)構(gòu),比如在altera的stratix等器件中,LUT是6輸入的,為了更好的利用LUT資源,需要適配LUT輸入。那么根據(jù)這個條件,可以得到以下的約束:
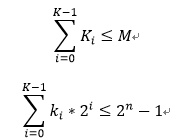
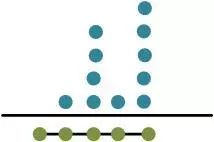
圖2.1 (1, 4, 1, 5; 5)
第一個約束條件是所有列的bit數(shù)被限制在M以內(nèi),第二個條件是所能實現(xiàn)的最大數(shù)據(jù)范圍。后邊會根據(jù)這兩個條件提出一個在FPGA上優(yōu)化compressor樹的算法。
用GPC來實現(xiàn)元組(1, 4, 1, 5; 5)為下圖:
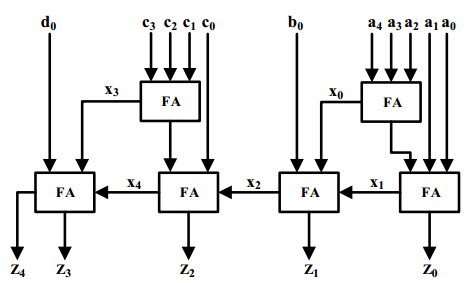
圖2.2 實現(xiàn)元組(1, 4, 1, 5; 5)的GPC結(jié)構(gòu)
從圖中看出其延時包括一個FA的延時和4個進位鏈產(chǎn)生的延時。在FPGA中提供了高速的進位鏈,所以GPC很適合在FPGA中實現(xiàn)。因此在FPGA上利用好GPC可以降低加法樹的級數(shù)。
比如舉個例子,如圖2.3所示,計算兩列數(shù)據(jù)和,如果使用華萊士樹的方式,會采用兩級電路,第一級用兩個全加器,將三行數(shù)據(jù)降低到兩行數(shù)據(jù),最后再用一個進位鏈加法器實現(xiàn)最后數(shù)據(jù)相加。而如果使用GPC(3, 3; 4)僅僅用一級電路就能實現(xiàn)這三行數(shù)據(jù)的相加。
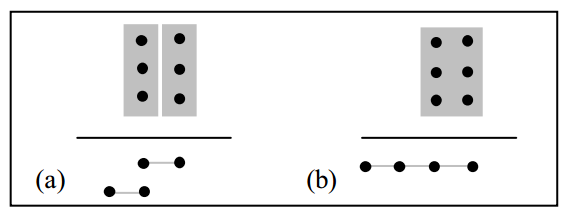
圖2.3 compressor樹構(gòu)建方式:a)用連個全加器和進位鏈加法器 b)用一個(3, 3; 4)GPC
現(xiàn)在結(jié)合altera的器件結(jié)構(gòu)來分析如何能更好的利用LUT來搭建一個GPC。Stratix器件中的adaptive logic module(ALM)包含兩個6-LUT,這兩個LUT共享輸入,因此一個ALM模塊可以實現(xiàn)6-2的功能。
通過圖2.4可以看出,如果將6輸入3輸出進行映射,會有一個LUT空置,利用率為75%。如果將6輸入4輸出映射到LUT,那么利用率為100%。如果將2個6輸入3輸出映射到2個ALM,這個無法實現(xiàn),因為ALM中兩個LUT共享輸入則無法綜合。
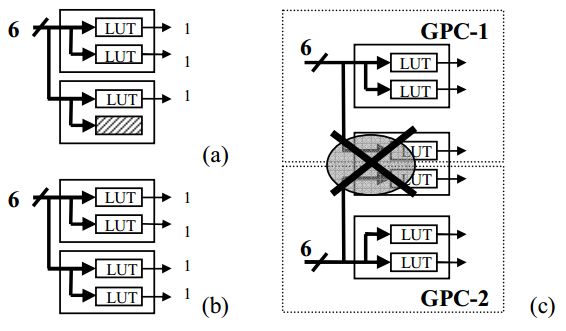
圖2.4 (a)一個6-3GPC映射,只有75%利用率(b)6-4GPC映射,利用率100%(c)2個6-3映射到2個ALM不可實現(xiàn)
03
高效映射算法
為了提高LUT利用率,降低器件中邏輯使用面積,論文基于以上的兩個約束以及altera LUT結(jié)構(gòu)特點提出了GPC選擇的算法。
首先我們定義兩個概念,primitive GPC是滿足以上約束的所有GPC集。比如對于M=6,n=3,一共有12個GPC。Covering GPC是指可以不被其它GPC實現(xiàn)的,即其實現(xiàn)是唯一的。比如(2, 2; 3)就不是一個covering GPC,因為其利用(2, 3; 3)GPC同樣可以實現(xiàn),只要將bit0對應的一個數(shù)置為0就行了。比如對于6-3GPC的covering GPC有{(0, 6; 3), (1, 5; 3), (2, 3; 3)}。而(3, 1; 3)是一個不夠高效的GPC,因為其bit0只有一個bit有數(shù),其可以繞過GPC直接輸出。compressor ratio是輸入對輸出的比率,比如(2, 3; 3)的比率是5/3=1.66。
算法步驟如下:
1) 首先依據(jù)M和n生成covering GPC;
2) 產(chǎn)生一些列primitive GPC,compressor樹將會由這些GPC來構(gòu)建,但是最后將由對應的covering GPC來替代;
3) 計算每個primitive GPC的compressor ratio并分類;
接下來的4-6步是一個不斷迭代過程,每一次迭代生成一級GPC,直到達到k行和kbit每列的限制條件。
4) 首先從所有求和列中選擇一個bit數(shù)最多的列作為基準,然后再同時向前和向后進行搜索,比較前后兩個列的compressor ratio,選擇最大的作為將要用于GPC映射的列。不斷重復這個過程直到所有列都完成搜索。
比如圖3.1展示的是一個6-3GPC建立過程。
第一個GPC是有6個bit的列,可以用(0, 6; 3)GPC來表示;
第二個最高列是有5bit,可以用(1, 5; 3)表示,附帶上旁邊的一個bit;
第三個高列有4bit,可以用(1, 4; 3)GPC實現(xiàn);
…。
這樣共實現(xiàn)了4個GPC,余下的沒有實現(xiàn)的bit使用GPC實現(xiàn)不能有效提高LUT利用率,直接傳遞到下一級。
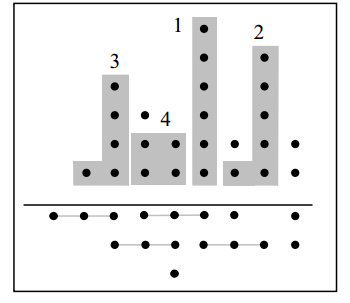
圖3.1 GPC生成過程
5) 對步驟4生成的新bit重復步驟4,進行提取新的GPC;
6) 當最終生成的bit行數(shù)小于k或者列數(shù)bit數(shù)小于k,迭代過程結(jié)束,這時上一級沒有被分配GPC的bit傳遞到本級,通過一個進位鏈加法器將所有結(jié)果相加;
04
結(jié)果
論文比較了GPC和另外兩種加法器實現(xiàn)方式的邏輯面積和資源對比,這另種加法器分別為:
1 ADD:由一個三輸入加法器作為基本結(jié)構(gòu)構(gòu)建的加法樹;
2 3GD:采用carry-save 加法器來實現(xiàn),這種結(jié)構(gòu)沒有利用ALM中的進位鏈;
延時、邏輯面積、資源利用對比如下圖所示:
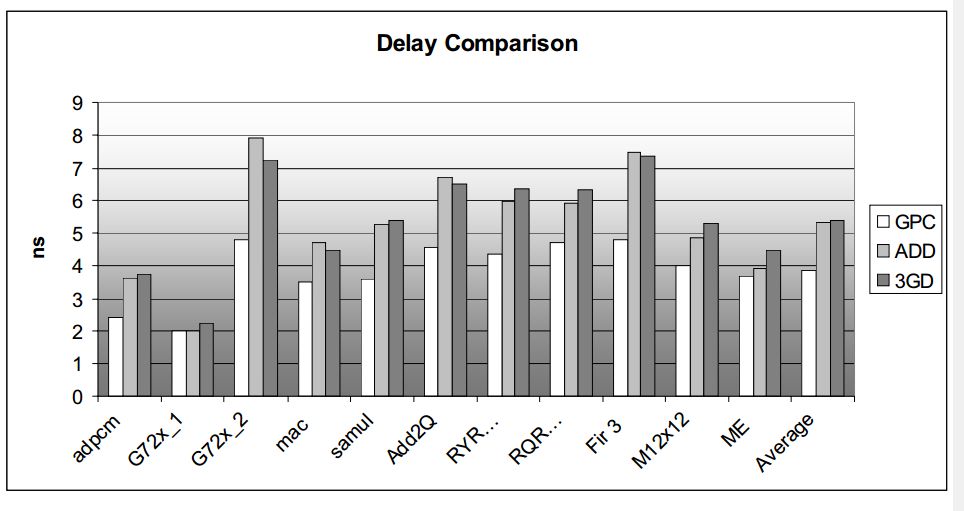
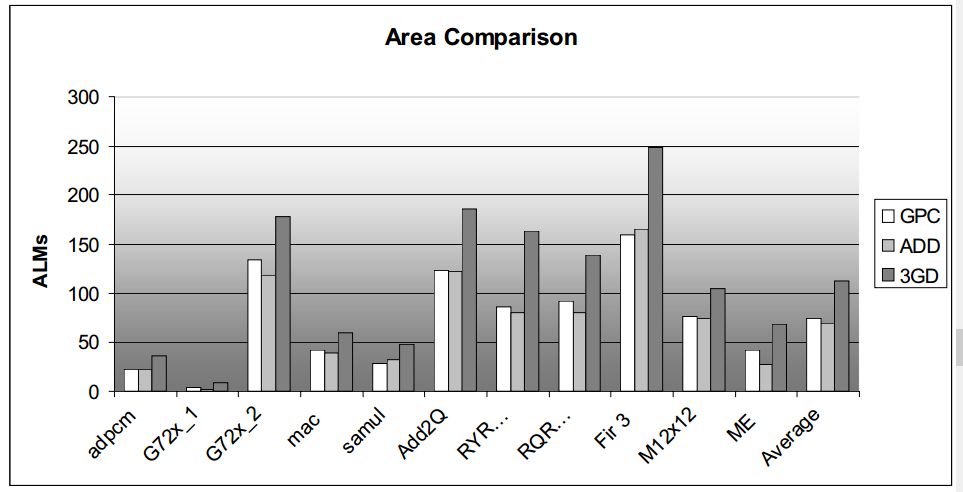
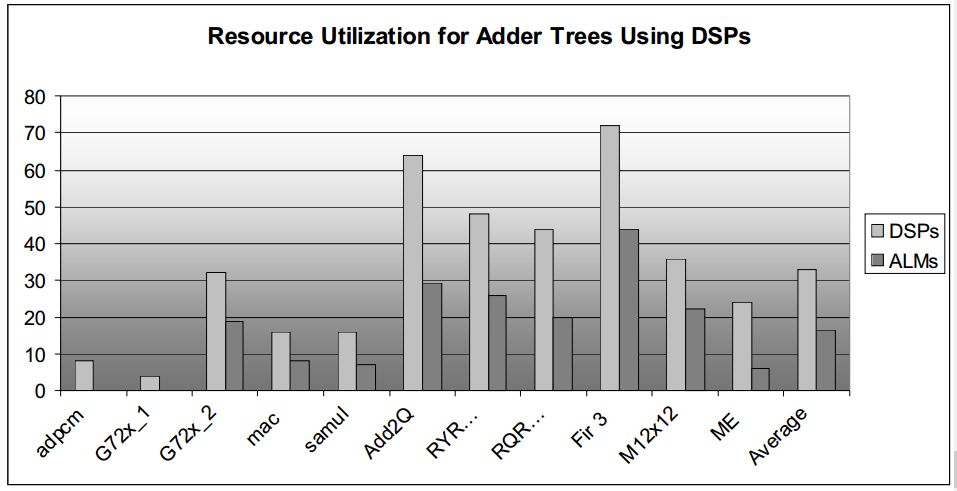
圖4.1 不同加法器實現(xiàn)方式的對比結(jié)果
總結(jié)
論文探索了利用FPGA的LUT和進位鏈結(jié)構(gòu)來實現(xiàn)GPC,相比于ADD和3GD有更低的延時,而資源使用和ADD相差不大,比3GD小很多。這主要是源于ADD和GPC都使用了進位鏈。
審核編輯:劉清
-
FPGA
+關(guān)注
關(guān)注
1629文章
21729瀏覽量
602997 -
全加器
+關(guān)注
關(guān)注
10文章
62瀏覽量
28496 -
LUT
+關(guān)注
關(guān)注
0文章
49瀏覽量
12502 -
半加器
+關(guān)注
關(guān)注
1文章
29瀏覽量
8790 -
gpc
+關(guān)注
關(guān)注
0文章
5瀏覽量
1338
原文標題:在FPGA中實現(xiàn)高效的compressor加法樹
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
FPGA工程師:如何在FPGA中實現(xiàn)狀態(tài)機?
為什么研究浮點加法運算,對FPGA實現(xiàn)方法很有必要?
如何利用FPGA實現(xiàn)高速流水線浮點加法器研究?
如何在低端FPGA中實現(xiàn)DPA的功能?
如何在FPGA中利用低頻源同步時鐘實現(xiàn)LVDS接收字對齊呢?
如何在EasyEDA中創(chuàng)建圣誕樹
用Verilog/SystemVerilog快速實現(xiàn)一個加法樹
采用StratixⅡ FPGA器件提高加法樹性能并實現(xiàn)設計
FPGA_ASIC-MAC在FPGA中的高效實現(xiàn)

fpga實現(xiàn)加法和減法運算的方法是什么

如何在FPGA中實現(xiàn)狀態(tài)機
如何在FPGA中實現(xiàn)隨機數(shù)發(fā)生器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論