 大模型在代碼缺陷檢測領域的應用實踐
大模型在代碼缺陷檢測領域的應用實踐
作者 | 小新、車厘子
導讀
靜態代碼掃描(SA)能快速識別代碼缺陷,如空指針訪問、數組越界等,以較高ROI保障質量及提升交付效率。當前掃描能力主要依賴人工經驗生成規則,泛化能力弱且迭代滯后,導致漏出。本文提出基于代碼知識圖譜解決給機器學什么的問題,以及基于代碼大模型解決機器怎么學的問題,讓計算機像人一樣看懂代碼,并自動發現代碼中的缺陷,給出提示,以期達到更小的人力成本,更好的效果泛化和更高的問題召回。
01代碼缺陷檢測背景介紹
靜態代碼掃描(SA)指在軟件工程中,程序員寫好源代碼后,在不運行計算機程序的條件下,對程序進行分析檢查。通過在代碼測試之前,在編碼階段就介入SA,提前發現并修復代碼問題,有效減少測試時間,提高研發效率,發現BUG越晚,修復的成本越大。
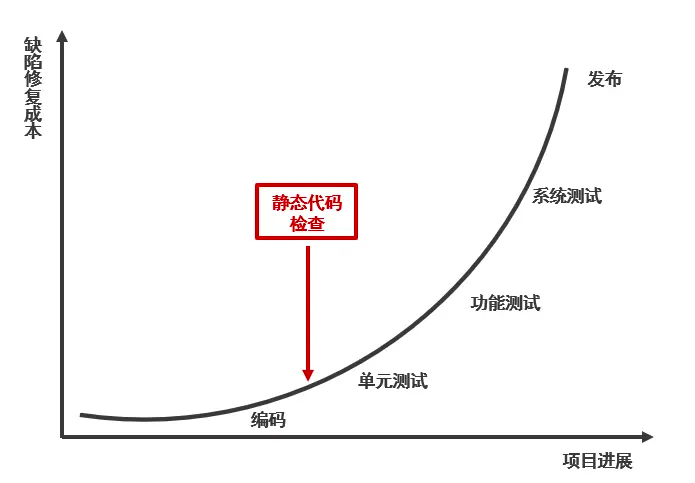
MEG的SA能力于2018年建立,支持C++、GO等語言,建設100+個規則,覆蓋大部分MEG的模塊,一定程度保障線上質量。當前檢測主要依賴人工生成規則,存在人工編寫成本高,以及泛化能力弱且迭代滯后,導致問題漏出。2022年Q2,我們團隊嘗試引入大模型:通過代碼語言大模型,實現機器自主檢測缺陷,提升泛化能力和迭代效率,減少人工編寫規則的成本。接下來,為大家帶來相關介紹。
02基于規則的代碼缺陷檢測主要問題
隨著缺陷規則增多,覆蓋的語言和模塊增多,有兩個突出的痛點急需解決:
1、每種規則都需人工根據經驗和后續的漏出分析維護,成本較高;以空指針場景為例,人工編寫的規則代碼共4439行,維護的回歸case共227個,但Q2仍有3個bug漏出。我們如何引入大模型減少開發成本,提質增效?
2、有效率偏低,掃描的能力有限(如斷鏈、框架保證非空、復雜場景靜態很難識別等,且風險的接受不同,掃描的部分高風險問題存在修復意愿低,對用戶造成打擾。我們如何通過模型,從歷史誤報中學習經驗,進行過濾,減少打擾,提升召回?
03解決方案
為了解決2個痛點問題,提出對應的解決方案。
3.1基于大模型的缺陷自動掃描
如何讓計算機像人一樣看懂代碼,并自動發現代碼中的缺陷,給出提示。要讓計算機自主進行缺陷檢測,核心需要解決2個技術難題:
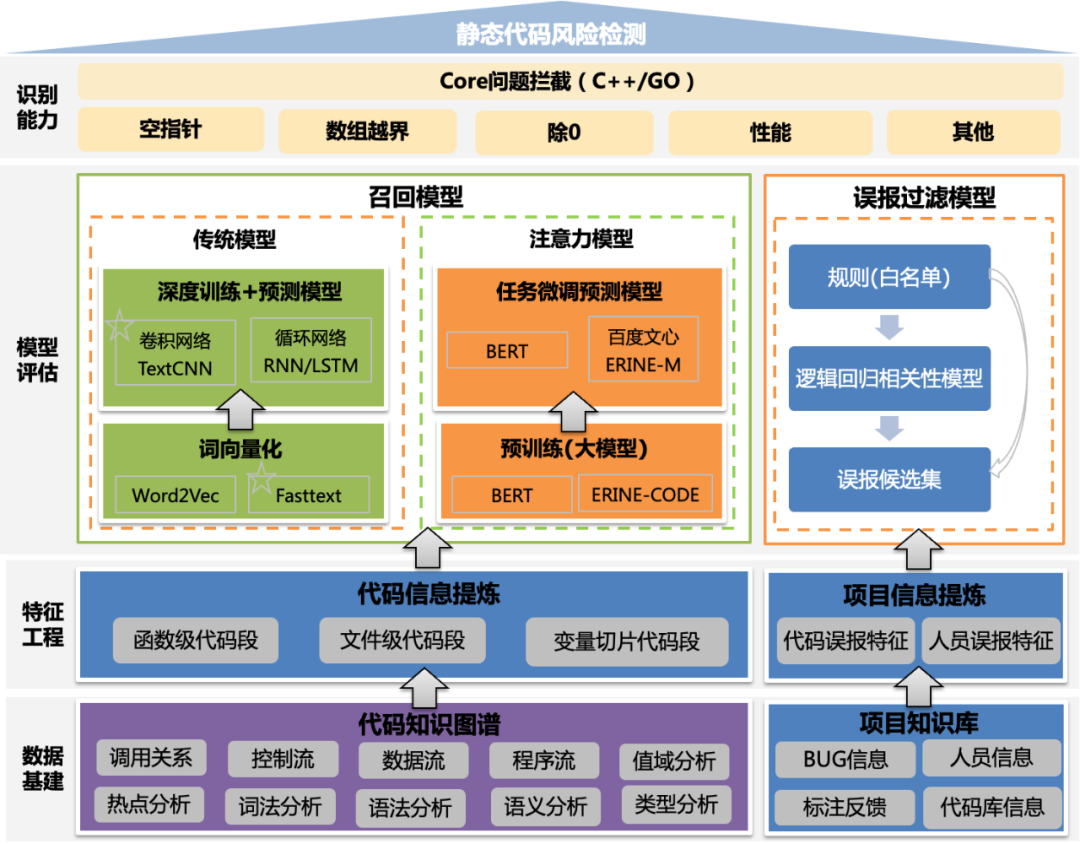
【學什么】給計算機輸入什么內容,能讓計算機更快、更好的學習;主要依托代碼知識圖譜提取目標變量相關的片段,減少機器學習需要的樣本量,提升學習的準確性。
【怎么學】針對輸入的內容,采用什么算法,能讓機器像人一樣讀懂多種程序語言,并完成檢測任務;采用深度學習的方法,主要包含預訓練和微調兩部分。預訓練技術讓計算機在海量無標簽的樣本中學習到多種語言的通用代碼語義,本項目主要采用開源的預訓練大模型。微調技術通過給大模型輸入缺陷檢測的樣本,從而得到適配場景的大模型,讓機器自主的進行缺陷識別。
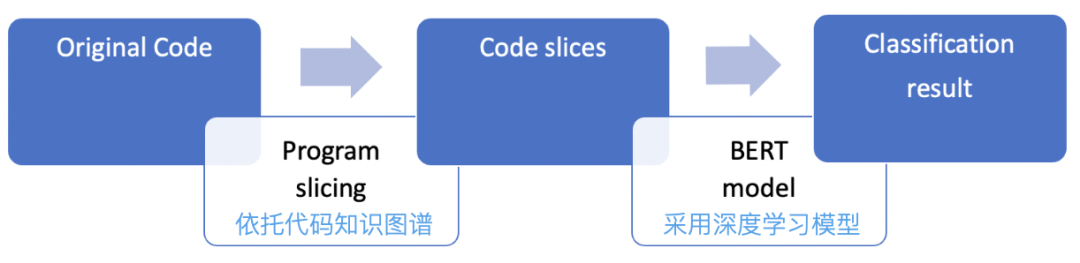
3.1.1 代碼知識圖譜提取片段
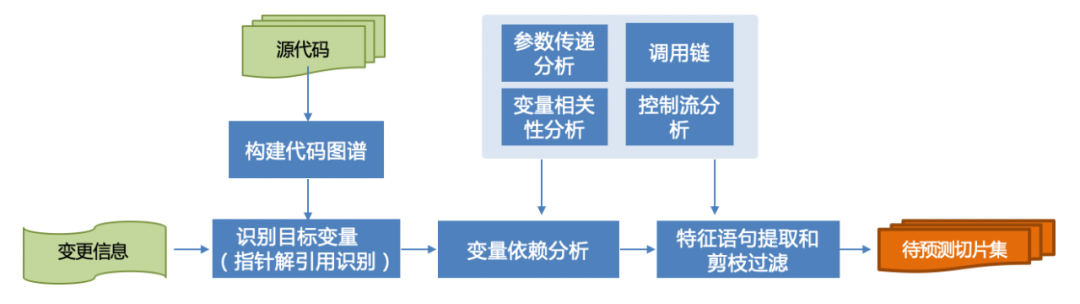
為了平衡模型性能和資源,不同大模型允許輸入的token量級不同,如Bert模型限制512個token,因此,需要對輸入進行縮減。代碼知識圖譜是基于程序分析手段,對業務源代碼經過模糊或精準的詞法分析、語法分析和語義分析后,結合依賴分析、關系挖掘等手段,構建得到的軟件白盒代碼知識網。圖譜提供了多種數據訪問方式,用戶可以低成本的訪問代碼數據。
借助于代碼知識圖譜能力,可以根據不同場景制定不同的與目標變量或目標場景相關的上下文源碼獲取能力,提取的關鍵步驟包括:
構建被分析代碼的知識圖譜
目標變量檢測識別:在變更代碼中識別目標變量,作為待檢測變量
變量依賴分析:基于控制流和數據流的與目標變量相關的依賴變量分析
特征語句提取和剪枝
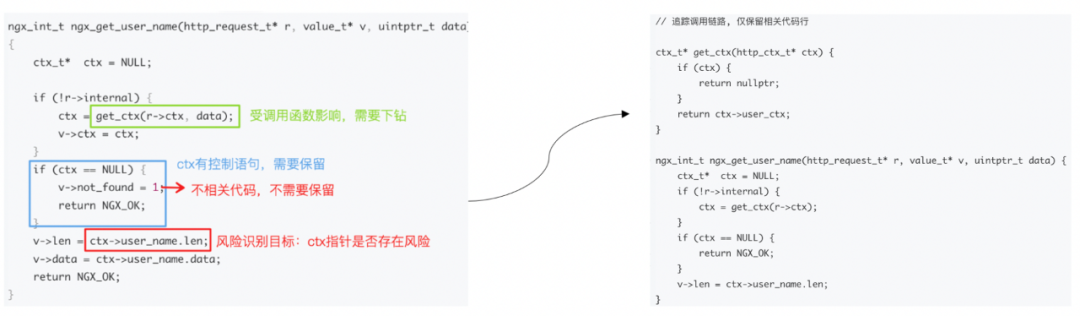
以空指針風險檢測為例,最終得到如下樣例的代碼切片信息:
3.1.2 采用大模型學習算法進行缺陷預測
大模型檢測缺陷有兩種思路:
1、一種是通過判別式的方法,識別是否有缺陷以及缺陷類型;
2、一種是通過生成式的方法,構建prompt,讓程序自動掃描所有相關缺陷。
本項目主要采用判別式的方法,并在實踐中證明該方法具有一定可行性。生成式的方法同步實驗中,接下來分別介紹兩種思路的一些實踐。
3.1.2.1 判別式的方法
通過分類的思想,基于模型,從歷史的樣本中學習規律,從而預測新樣本的類別。深度學習眾多算法中,如TextCNN、LSTM等,應該采用哪一種?我們通過多組對比實驗,最終選擇效果最佳的BERT代碼大模型。
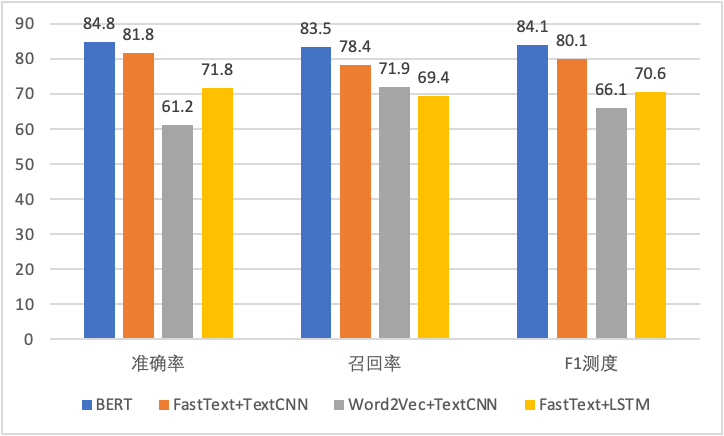
△模型效果
采用BERT進行缺陷檢測共含3步,分別是預訓練、微調和推理。
預訓練階段采用開源的多語言大模型,已較好的學習多種程序語言的語義。
微調階段,給模型輸入上述通過代碼知識圖譜提取的變量使用點相關的切片,以及是否有缺陷或者缺陷類型的標簽,生成微調模型,讓機器具備做檢測任務的能力。輸入的格式:
{
"slices": [{"line":"行代碼內容", "loc": "行號"}],
"mark": {"label":"樣本標簽", "module_name":"代碼庫名", "commit_id":"代碼版本", "file_path":"文件名", "risk_happend_line":"發生異常的行"}
}
推理階段,分析使用點目標變量的相關切片,通過微調模型進行預測,得到使用點是否有缺陷,以及缺陷類型
模型上線后,用戶對結果反饋狀態包括誤報和接受,采集真實反饋樣本,加入微調模型自動訓練,從而到達自動迭代、快速學習新知識的目的。
3.1.2.2 生成式的方法
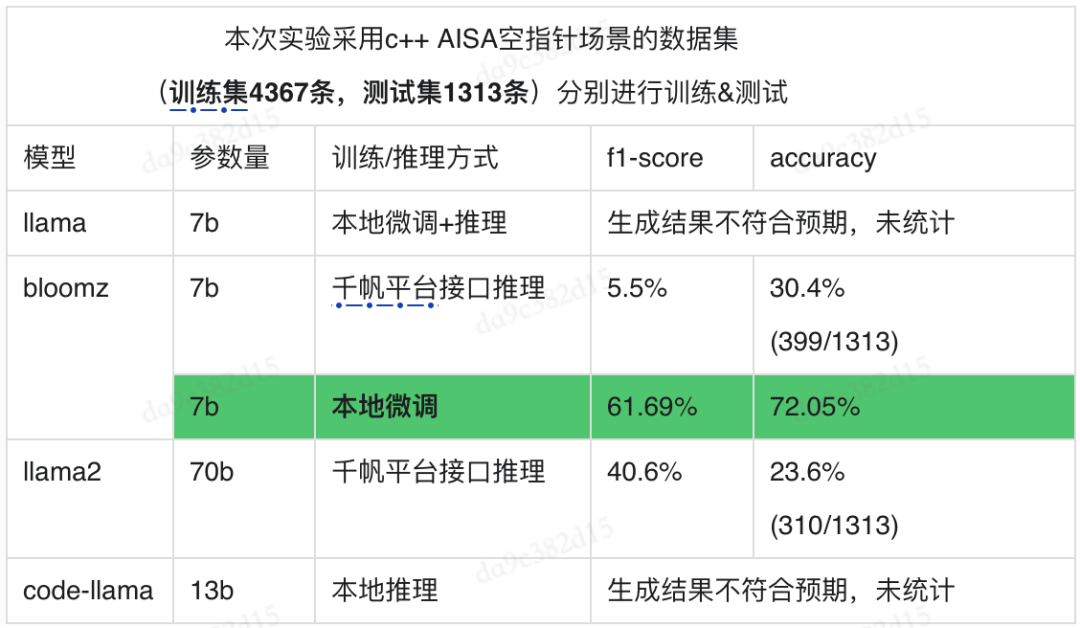
生成式模型百花齊發,有閉源的如chatgpt、文心一言,有開源的如llama、bloom和starcode等。我們主要嘗試文心一言、llama和bloom,通過prompt(few shot、引入思維鏈、指定抽象的引導規則)和微調的方式,探索模型在空指針缺陷檢測的預測效果。整體f1測度不高,最佳的bloom61.69%,相比Bert路線的80%有差距,且模型的穩定性較差。因生成式路線有自身的優勢,如參數量大存在智能涌現具有更強的推理能力,允許輸入的token量不斷增加可減少對切片清洗的依賴,可與修復一起結合等,我們預判在缺陷檢測場景生成式是個趨勢,接下來我們將繼續優化,不斷嘗試prompt和微調,通過更合適的引導,更好的激發模型的潛力,從而提升生成式方法在檢測場景的效果。
 ? ?
? ?
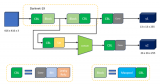
3.2 采用規則+機器學習進行誤報過濾
缺陷檢測場景識別的缺陷是風險,存在接受度問題,如何過濾掉其中低風險問題,是個難題。通過分析誤報和修復的樣本,我們采集誤報相關的特征,如指針類型,模塊誤報率、文件誤報率等跟誤報相關的10+特征,訓練機器學習模型(邏輯回歸),判斷是否需要過濾.
整體方案架構圖如下:
04業務落地
基于AI的代碼缺陷檢測能力可以集成進入code管理平臺,每次代碼提交,展示可能存在的代碼缺陷,阻塞合入,并采集研發人員的反饋,便于模型迭代。
05收益和展望
5.1 收益
通過理論和實踐證明,讓計算機自主學習程序語言并完成缺陷檢測任務具有一定可行性。
1、本項目的方法已在IEEE AITest Conference 2023發表論文:
2、實際落地效果:2023Q2 C++空指針場景已覆蓋1100+模塊,修復問題數662個,相比規則型靜態代碼掃描召回占比26.9%,增量召回484個,重合度26.8%,初步證明AI的召回能力,打開了大模型做代碼缺陷檢測的大門,同時也驗證大模型具備傳統規則的擴召回、低成本的優勢,可形成標記+訓練+檢測的自閉環。
5.2 展望
基于5.1收益,給了我們用大模型做代碼缺陷檢測的信心,后續我們繼續在以下幾個方面加強:
1、擴展更多語言和場景,如除零、死循環、數組越界場景,并在多語言go、java等進行快速訓練,并進行發布;
2、隨著生成式模型的興起,也會逐漸積累有效的問題和修復數據,貢獻文心通用大模型,進行預訓練和微調,以探索生成式模型在智能缺陷檢測與修復領域的應用;
3、同時將調研更多基礎切片技術,拿到更多豐富有效代碼切片,以提升準召率。
審核編輯:湯梓紅
-
計算機
+關注
關注
19文章
7575瀏覽量
89100 -
代碼
+關注
關注
30文章
4857瀏覽量
69529 -
缺陷檢測
+關注
關注
2文章
147瀏覽量
12379 -
大模型
+關注
關注
2文章
2781瀏覽量
3432
原文標題:大模型在代碼缺陷檢測領域的應用實踐
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
【大語言模型:原理與工程實踐】大語言模型的評測
[轉]產品表面缺陷檢測
labview深度學習應用于缺陷檢測
廣東機器視覺缺陷檢測系統在包裝袋封口檢測的應用
芯片缺陷檢測
表面檢測市場案例,SMT缺陷檢測
表面缺陷檢測系統的應用領域有哪些
魔方大模型在智能汽車領域的應用實踐與探索
瑞薩電子深度學習算法在缺陷檢測領域的應用
深度學習在工業缺陷檢測中的應用

描繪未知:數據缺乏場景的缺陷檢測方案






 工商網監
工商網監
評論