 HTTP服務器項目實現介紹
HTTP服務器項目實現介紹
項目介紹
本項目實現的是一個HTTP服務器,項目中將會通過基本的網絡套接字讀取客戶端發來的HTTP請求并進行分析,最終構建HTTP響應并返回給客戶端。
HTTP在網絡應用層中的地位是不可撼動的,無論是移動端還是PC端瀏覽器,HTTP無疑是打開互聯網應用窗口的重要協議。
該項目將會把HTTP中最核心的模塊抽取出來,采用CS模型實現一個小型的HTTP服務器,目的在于理解HTTP協議的處理過程。
該項目主要涉及C/C++、HTTP協議、網絡套接字編程、CGI、單例模式、多線程、線程池等方面的技術。
網絡協議棧介紹
協議分層
協議分層
網絡協議棧的分層情況如下:
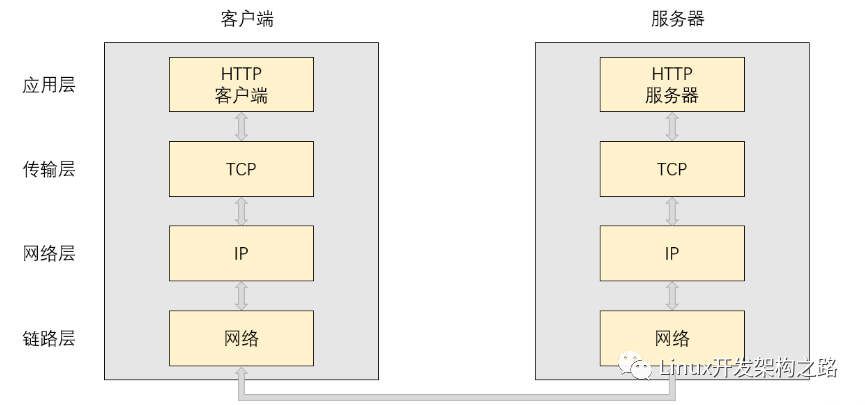
網絡協議棧中各層的功能如下:
- 應用層:根據特定的通信目的,對數據進行分析處理,以達到某種業務性的目的。
- 傳輸層:處理傳輸時遇到的問題,主要是保證數據傳輸的可靠性。
- 網絡層:完成數據的轉發,解決數據去哪里的問題。
- 鏈路層:負責數據真正的發生過程。
數據的封裝與分用
數據的封裝與分用
數據封裝與分用的過程如下:
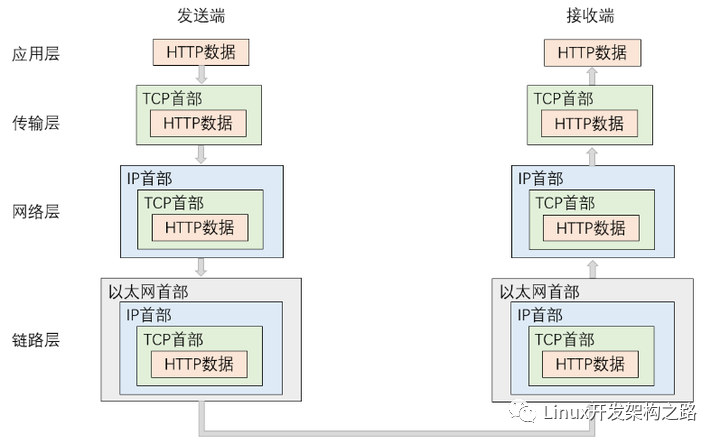
也就是說,發送端在發生數據前,該數據需要先自頂向下貫穿網絡協議棧完成數據的封裝,在這個過程中,每一層協議都會為該數據添加上對應的報頭信息。接收端在收到數據后,該數據需要先自底向上貫穿網絡協議棧完成數據的解包和分用,在這個過程中,每一層協議都會將對應的報頭信息提取出來。
而本項目要做的就是,在接收到客戶端發來的HTTP請求后,將HTTP的報頭信息提取出來,然后對數據進行分析處理,最終將處理結果添加上HTTP報頭再發送給客戶端。
需要注意的是,該項目中我們所處的位置是應用層,因此我們讀取的HTTP請求實際是從傳輸層讀取上來的,而我們發送的HTTP響應實際也只是交給了傳輸層,數據真正的發送還得靠網絡協議棧中的下三層來完成,這里直接說“接收到客戶端的HTTP請求”以及“發送HTTP響應給客戶端”,只是為了方便大家理解,此外,同層協議之間本身也是可以理解成是在直接通信的。
HTTP相關知識介紹
HTTP的特點
HTTP的五大特點
HTTP的五大特點如下:
- 客戶端服務器模式(CS,BS): 在一條通信線路上必定有一端是客戶端,另一端是服務器端,請求從客戶端發出,服務器響應請求并返回。
- 簡單快速: 客戶端向服務器請求服務時,只需傳送請求方法和請求資源路徑,不需要發送額外過多的數據,并且由于HTTP協議結構較為簡單,使得HTTP服務器的程序規模小,因此通信速度很快。
- 靈活: HTTP協議對數據對象沒有要求,允許傳輸任意類型的數據對象,對于正在傳輸的數據類型,HTTP協議將通過報頭中的Content-Type屬性加以標記。
- 無連接: 每次連接都只會對一個請求進行處理,當服務器對客戶端的請求處理完畢并收到客戶端的應答后,就會直接斷開連接。HTTP協議采用這種方式可以大大節省傳輸時間,提高傳輸效率。
- 無狀態: HTTP協議自身不對請求和響應之間的通信狀態進行保存,每個請求都是獨立的,這是為了讓HTTP能更快地處理大量事務,確保協議的可伸縮性而特意設計的。
說明一下:
- 隨著HTTP的普及,文檔中包含大量圖片的情況多了起來,每次請求都要斷開連接,無疑增加了通信量的開銷,因此HTTP1.1支持了長連接Keey-Alive,就是任意一端只要沒有明確提出斷開連接,則保持連接狀態。(當前項目實現的是1.0版本的HTTP服務器,因此不涉及長連接)
- HTTP無狀態的特點無疑可以減少服務器內存資源的消耗,但是問題也是顯而易見的。比如某個網站需要登錄后才能訪問,由于無狀態的特點,那么每次跳轉頁面的時候都需要重新登錄。為了解決無狀態的問題,于是引入了Cookie技術,通過在請求和響應報文中寫入Cookie信息來控制客戶端的狀態,同時為了保護用戶數據的安全,又引入了Session技術,因此現在主流的HTTP服務器都是通過Cookie+Session的方式來控制客戶端的狀態的。
URL格式
URL(Uniform Resource Lacator)叫做統一資源定位符,也就是我們通常所說的網址,是因特網的萬維網服務程序上用于指定信息位置的表示方法。
一個URL大致由如下幾部分構成:

簡單說明:
- http://表示的是協議名稱,表示請求時需要使用的協議,通常使用的是HTTP協議或安全協議HTTPS。
- user:pass表示的是登錄認證信息,包括登錄用戶的用戶名和密碼。(可省略)
- www.example.jp表示的是服務器地址,通常以域名的形式表示。
- 80表示的是服務器的端口號。(可省略)
- /dir/index.html表示的是要訪問的資源所在的路徑(/表示的是web根目錄)。
- uid=1表示的是請求時通過URL傳遞的參數,這些參數以鍵值對的形式通過&符號分隔開。(可省略)
- ch1表示的是片段標識符,是對資源的部分補充。(可省略)
注意:
- 如果訪問服務器時沒有指定要訪問的資源路徑,那么瀏覽器會自動幫我們添加/,但此時仍然沒有指明要訪問web根目錄下的哪一個資源文件,這時默認訪問的是目標服務的首頁。
- 大部分URL中的端口號都是省略的,因為常見協議對應的端口號都是固定的,比如HTTP、HTTPS和SSH對應的端口號分別是80、443和22,在使用這些常見協議時不必指明協議對應的端口號,瀏覽器會自動幫我們進行填充。
URI、URL、URN
URI、URL、URN的定義
URI、URL、URN的定義如下:
- URI(Uniform Resource Indentifier)統一資源標識符:用來唯一標識資源。
- URL(Uniform Resource Locator)統一資源定位符:用來定位唯一的資源。
- URN(Uniform Resource Name)統一資源名稱:通過名字來標識資源,比如mailto:java-net@java.sun.com。
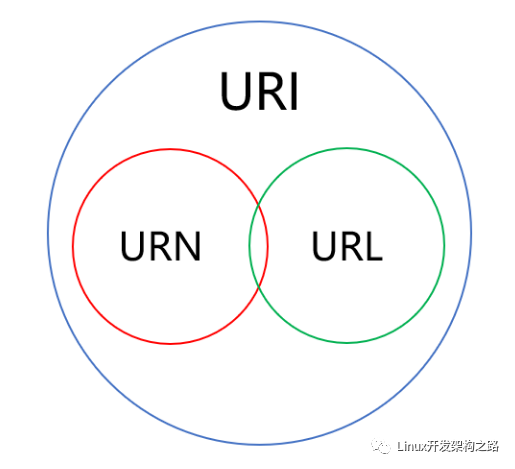
URI、URL、URN三者的關系
URL是URI的一種,URL不僅能唯一標識資源,還定義了該如何訪問或定位該資源,URN也是URI的一種,URN通過名字來標識資源,因此URL和URN都是URI的子集。
URI、URL、URN三者的關系如下:
絕對的URI和相對的URI
URI有絕對和相對之分:
- 絕對的URI: 對標識符出現的環境沒有依賴,比如URL就是一種絕對的URI,同一個URL無論出現在什么地方都能唯一標識同一個資源。
- 相對的URI: 對標識符出現的環境有依賴,比如HTTP請求行中的請求資源路徑就是一種相對的URI,這個資源路徑出現在不同的主機上標識的就是不同的資源。
HTTP的協議格式
HTTP請求協議格式
HTTP請求協議格式如下:
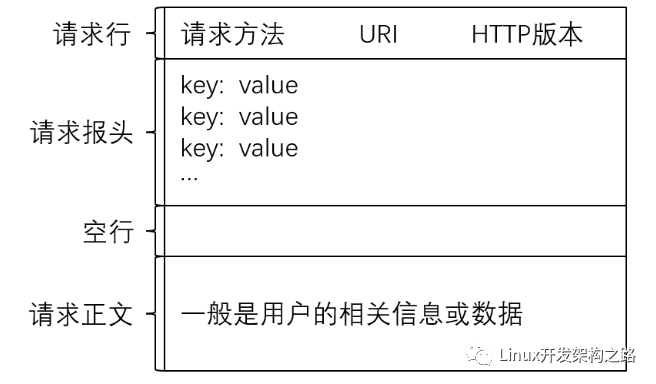
HTTP請求由以下四部分組成:
- 請求行:[請求方法] + [URI] + [HTTP版本]。
- 請求報頭:請求的屬性,這些屬性都是以key: value的形式按行陳列的。
- 空行:遇到空行表示請求報頭結束。
- 請求正文:請求正文允許為空字符串,如果請求正文存在,則在請求報頭中會有一個Content-Length屬性來標識請求正文的長度。
HTTP響應協議格式
HTTP響應協議格式如下:
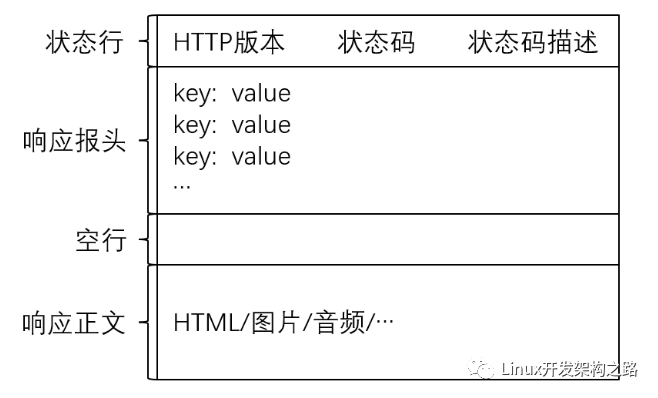
HTTP響應由以下四部分組成:
- 狀態行:[HTTP版本] + [狀態碼] + [狀態碼描述]。
- 響應報頭:響應的屬性,這些屬性都是以key: value的形式按行陳列的。
- 空行:遇到空行表示響應報頭結束。
- 響應正文:響應正文允許為空字符串,如果響應正文存在,則在響應報頭中會有一個Content-Length屬性來標識響應正文的長度。
HTTP的請求方法
HTTP的請求方法
HTTP常見的請求方法如下:
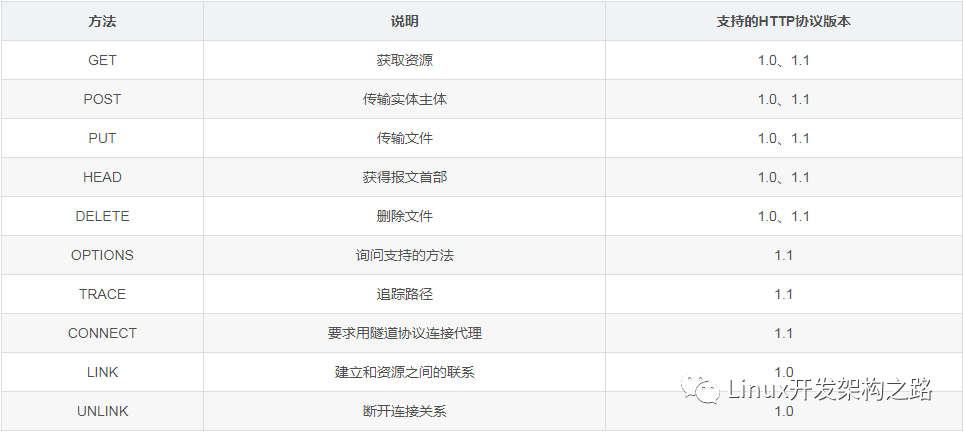
GET方法和POST方法
HTTP的請求方法中最常用的就是GET方法和POST方法,其中GET方法一般用于獲取某種資源信息,而POST方法一般用于將數據上傳給服務器,但實際GET方法也可以用來上傳數據,比如百度搜索框中的數據就是使用GET方法提交的。
GET方法和POST方法都可以帶參,其中GET方法通過URL傳參,POST方法通過請求正文傳參。由于URL的長度是有限制的,因此GET方法攜帶的參數不能太長,而POST方法通過請求正文傳參,一般參數長度沒有限制。
HTTP的狀態碼
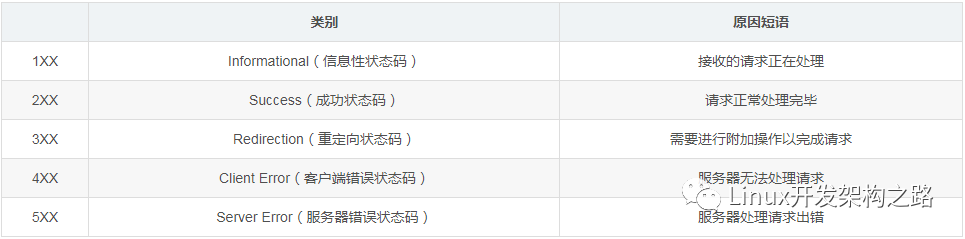
HTTP的狀態碼
HTTP狀態碼是用來表示服務器HTTP響應狀態的3位數字代碼,通過狀態碼可以知道服務器端是否正確的處理了請求,以及請求處理錯誤的原因。
HTTP的狀態碼如下:
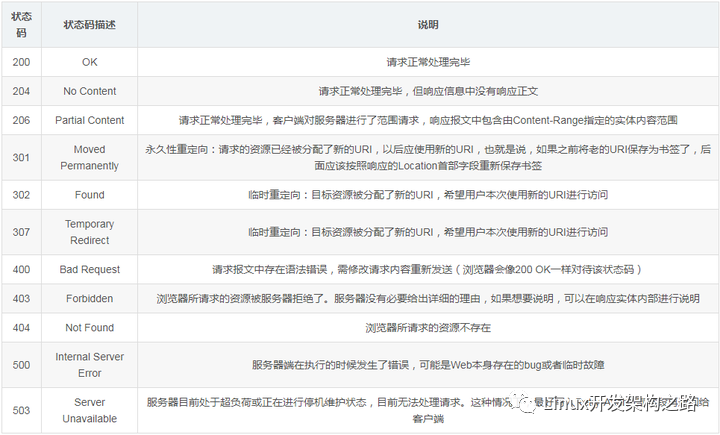
常見狀態碼
常見的狀態碼如下:
HTTP常見的Header
HTTP常見的Header
HTTP常見的Header如下:
- Content-Type:數據類型(text/html等)。
- Content-Length:正文的長度。
- Host:客戶端告知服務器,所請求的資源是在哪個主機的哪個端口上。
- User-Agent:聲明用戶的操作系統和瀏覽器的版本信息。
- Referer:當前頁面是哪個頁面跳轉過來的。
- Location:搭配3XX狀態碼使用,告訴客戶端接下來要去哪里訪問。
- Cookie:用戶在客戶端存儲少量信息,通常用于實現會話(session)的功能。
簡歷沒項目可寫?加入學習更多實戰項目(完整視頻教程+源碼+難點答疑)

CGI機制介紹
CGI機制的概念
CGI(Common Gateway Interface,通用網關接口)是一種重要的互聯網技術,可以讓一個客戶端,從網頁瀏覽器向執行在網絡服務器上的程序請求數據。CGI描述了服務器和請求處理程序之間傳輸數據的一種標準。
實際我們在進行網絡請求時,無非就兩種情況:
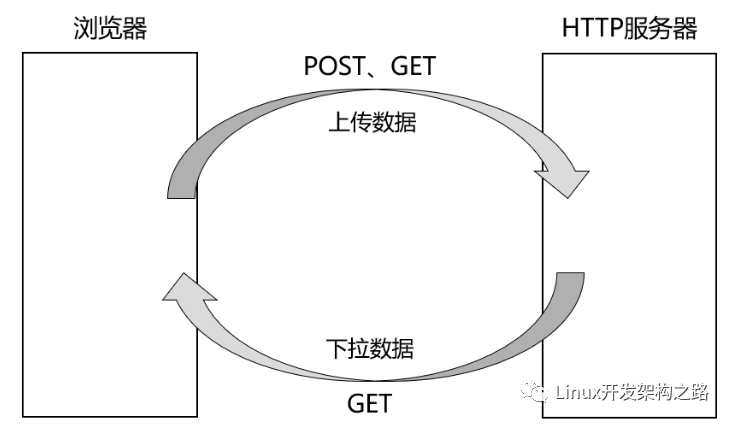
通常從服務器上獲取資源對應的請求方法就是GET方法,而將數據上傳至服務器對應的請求方法就是POST方法,但實際GET方法有時也會用于上傳數據,只不過POST方法是通過請求正文傳參的,而GET方法是通過URL傳參的。
而用戶將自己的數據上傳至服務器并不僅僅是為了上傳,用戶上傳數據的目的是為了讓HTTP或相關程序對該數據進行處理,比如用戶提交的是搜索關鍵字,那么服務器就需要在后端進行搜索,然后將搜索結果返回給瀏覽器,再由瀏覽器對HTML文件進行渲染刷新展示給用戶。
但實際對數據的處理與HTTP的關系并不大,而是取決于上層具體的業務場景的,因此HTTP不對這些數據做處理。但HTTP提供了CGI機制,上層可以在服務器中部署若干個CGI程序,這些CGI程序可以用任何程序設計語言編寫,當HTTP獲取到數據后會將其提交給對應CGI程序進行處理,然后再用CGI程序的處理結果構建HTTP響應返回給瀏覽器。
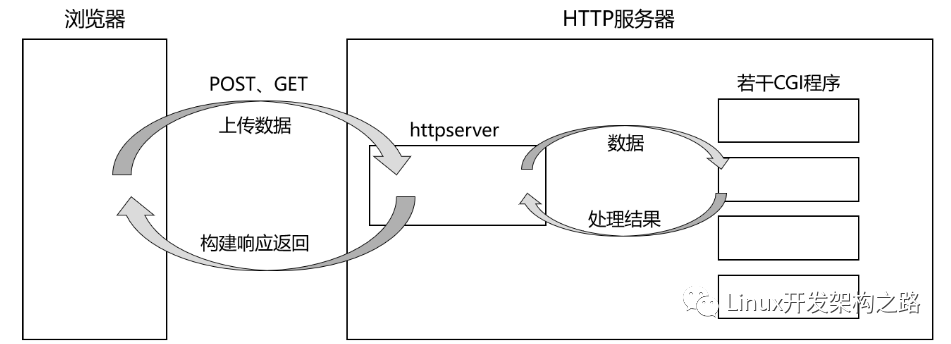
其中HTTP獲取到數據后,如何調用目標CGI程序、如何傳遞數據給CGI程序、如何拿到CGI程序的處理結果,這些都屬于CGI機制的通信細節,而本項目就是要實現一個HTTP服務器,因此CGI的所有交互細節都需要由我們來完成。
何時需要使用CGI模式
只要用戶請求服務器時上傳了數據,那么服務器就需要使用CGI模式對用戶上傳的數據進行處理,而如果用戶只是單純的想請求服務器上的某個資源文件則不需要使用CGI模式,此時直接將用戶請求的資源文件返回給用戶即可。
此外,如果用戶請求的是服務器上的一個可執行程序,說明用戶想讓服務器運行這個可執行程序,此時也需要使用CGI模式。
CGI機制的實現步驟
一、創建子進程進行程序替換
服務器獲取到新連接后一般會創建一個新線程為其提供服務,而要執行CGI程序一定需要調用exec系列函數進行進程程序替換,但服務器創建的新線程與服務器進程使用的是同一個進程地址空間,如果直接讓新線程調用exec系列函數進行進程程序替換,此時服務器進程的代碼和數據就會直接被替換掉,相當于HTTP服務器在執行一次CGI程序后就直接退出了,這肯定是不合理的。因此新線程需要先調用fork函數創建子進程,然后讓子進程調用exec系列函數進行進程程序替換。
二、完成管道通信信道的建立
調用CGI程序的目的是為了讓其進行數據處理,因此我們需要通過某種方式將數據交給CGI程序,并且還要能夠獲取到CGI程序處理數據后的結果,也就是需要進行進程間通信。因為這里的服務器進程和CGI進程是父子進程,因此優先選擇使用匿名管道。
由于父進程不僅需要將數據交給子進程,還需要從子進程那里獲取數據處理的結果,而管道是半雙工通信的,為了實現雙向通信于是需要借助兩個匿名管道,因此在創建調用fork子進程之前需要先創建兩個匿名管道,在創建子進程后還需要父子進程分別關閉兩個管道對應的讀寫端。
三、完成重定向相關的設置
創建用于父子進程間通信的兩個匿名管道時,父子進程都是各自用兩個變量來記錄管道對應讀寫端的文件描述符的,但是對于子進程來說,當子進程調用exec系列函數進行程序替換后,子進程的代碼和數據就被替換成了目標CGI程序的代碼和數據,這也就意味著被替換后的CGI程序無法得知管道對應的讀寫端,這樣父子進程之間也就無法進行通信了。
需要注意的是,進程程序替換只替換對應進程的代碼和數據,而對于進程的進程控制塊、頁表、打開的文件等內核數據結構是不做任何替換的。因此子進程進行進程程序替換后,底層創建的兩個匿名管道仍然存在,只不過被替換后的CGI程序不知道這兩個管道對應的文件描述符罷了。
這時我們可以做一個約定:被替換后的CGI程序,從標準輸入讀取數據等價于從管道讀取數據,向標準輸出寫入數據等價于向管道寫入數據。這樣一來,所有的CGI程序都不需要得知管道對應的文件描述符了,當需要讀取數據時直接從標準輸入中進行讀取,而數據處理的結果就直接寫入標準輸出就行了。
當然,這個約定并不是你說有就有的,要實現這個約定需要在子進程被替換之前進行重定向,將0號文件描述符重定向到對應管道的讀端,將1號文件描述符重定向到對應管道的寫端。
四、父子進程交付數據
這時父子進程已經能夠通過兩個匿名管道進行通信了,接下來就應該討論父進程如何將數據交給CGI程序,以及CGI程序如何將數據處理結果交給父進程了。
父進程將數據交給CGI程序:
- 如果請求方法為GET方法,那么用戶是通過URL傳遞參數的,此時可以在子進程進行進程程序替換之前,通過putenv函數將參數導入環境變量,由于環境變量也不受進程程序替換的影響,因此被替換后的CGI程序就可以通過getenv函數來獲取對應的參數。
- 如果請求方法為POST方法,那么用戶是通過請求正文傳參的,此時父進程直接將請求正文中的數據寫入管道傳遞給CGI程序即可,但是為了讓CGI程序知道應該從管道讀取多少個參數,父進程還需要通過putenv函數將請求正文的長度導入環境變量。
說明一下:請求正文長度、URL傳遞的參數以及請求方法都比較短,通過寫入管道來傳遞會導致效率降低,因此選擇通過導入環境變量的方式來傳遞。
也就是說,使用CGI模式時如果請求方法為POST方法,那么CGI程序需要從管道讀取父進程傳遞過來的數據,如果請求方法為GET方法,那么CGI程序需要從環境變量中獲取父進程傳遞過來的數據。
但被替換后的CGI程序實際并不知道本次HTTP請求所對應的請求方法,因此在子進程在進行進程程序替換之前,還需要通過putenv函數將本次HTTP請求所對應的請求方法也導入環境變量。因此CGI程序啟動后,首先需要先通過環境變量得知本次HTTP請求所對應的請求方法,然后再根據請求方法對應從管道或環境變量中獲取父進程傳遞過來的數據。
CGI程序讀取到父進程傳遞過來的數據后,就可以進行對應的數據處理了,最終將數據處理結果寫入到管道中,此時父進程就可以從管道中讀取CGI程序的處理結果了。
CGI機制的意義
CGI機制的處理流程
CGI機制的處理流程如下:
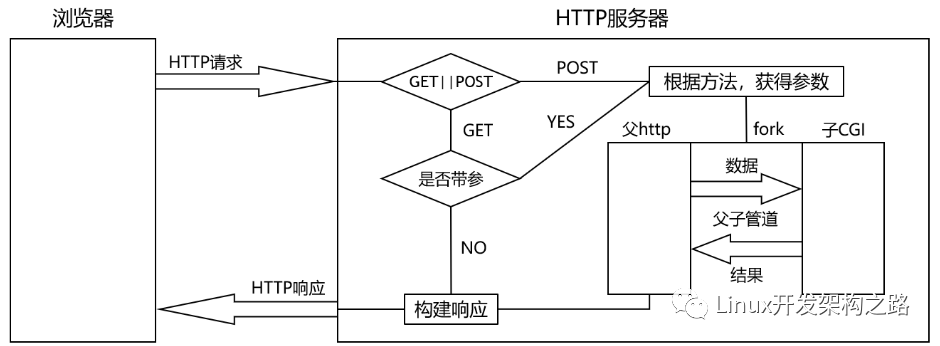
處理HTTP請求的步驟如下:
- 判斷請求方法是GET方法還是POST方法,如果是GET方法帶參或POST方法則進行CGI處理,如果是GET方法不帶參則進行非CGI處理。
- 非CGI處理就是直接根據用戶請求的資源構建HTTP響應返回給瀏覽器。
- CGI處理就是通過創建子進程進行程序替換的方式來調用CGI程序,通過創建匿名管道、重定向、導入環境變量的方式來與CGI程序進行數據通信,最終根據CGI程序的處理結果構建HTTP響應返回給瀏覽器。
CGI機制的意義
- CGI機制就是讓服務器將獲取到的數據交給對應的CGI程序進行處理,然后將CGI程序的處理結果返回給客戶端,這顯然讓服務器邏輯和業務邏輯進行了解耦,讓服務器和業務程序可以各司其職。
- CGI機制使得瀏覽器輸入的數據最終交給了CGI程序,而CGI程序輸出的結果最終交給了瀏覽器。這也就意味著CGI程序的開發者,可以完全忽略中間服務器的處理邏輯,相當于CGI程序從標準輸入就能讀取到瀏覽器輸入的內容,CGI程序寫入標準輸出的數據最終就能輸出到瀏覽器。
日志編寫
服務器在運作時會產生一些日志,這些日志會記錄下服務器運行過程中產生的一些事件。
日志格式
本項目中的日志格式如下:

日志說明:
- 日志級別: 分為四個等級,從低到高依次是INFO、WARNING、ERROR、FATAL。
- 時間戳: 事件產生的時間。
- 日志信息: 事件產生的日志信息。
- 錯誤文件名稱: 事件在哪一個文件產生。
- 行數: 事件在對應文件的哪一行產生。
日志級別說明:
- INFO: 表示正常的日志輸出,一切按預期運行。
- WARNING: 表示警告,該事件不影響服務器運行,但存在風險。
- ERROR: 表示發生了某種錯誤,但該事件不影響服務器繼續運行。
- FATAL: 表示發生了致命的錯誤,該事件將導致服務器停止運行。
日志函數編寫
我們可以針對日志編寫一個輸出日志的Log函數,該函數的參數就包括日志級別、日志信息、錯誤文件名稱、錯誤的行數。如下:
{
std::cout<<"["<}<<"]["<
說明一下: 調用time函數時傳入nullptr即可獲取當前的時間戳,因此調用Log函數時不必傳入時間戳。
文件名稱和行數的問題
通過C語言中的預定義符號__FILE__和__LINE__,分別可以獲取當前文件的名稱和當前的行數,但最好在調用Log函數時不用調用者顯示的傳入__FILE__和__LINE__,因為每次調用Log函數時傳入的這兩個參數都是固定的。
需要注意的是,不能將__FILE__和__LINE__設置為參數的缺省值,因為這樣每次獲取到的都是Log函數所在的文件名稱和所在的行數。而宏可以在預處理期間將代碼插入到目標地點,因此我們可以定義如下宏:
后續需要打印日志的時候就直接調用LOG,調用時只需要傳入日志級別和日志信息,在預處理期間__FILE__和__LINE__就會被插入到目標地點,這時就能獲取到日志產生的文件名稱和對應的行數了。
日志級別傳入問題
我們后續調用LOG傳入日志級別時,肯定希望以INFO、WARNING這樣的方式傳入,而不是以"INFO"、"WARNING"這樣的形式傳入,這時我們可以將這四個日志級別定義為宏,然后通過#將宏參數level變成對應的字符串。如下:
#define WARNING 2
#define ERROR 3
#define FATAL 4
#define LOG(level, message) Log(#level, message, __FILE__, __LINE__)
此時以INFO、WARNING的方式傳入LOG的宏參數,就會被轉換成對應的字符串傳遞給Log函數的level參數,后續我們就可以以如下方式輸出日志了:
套接字相關代碼編寫
套接字相關代碼編寫
我們可以將套接字相關的代碼封裝到TcpServer類中,在初始化TcpServer對象時完成套接字的創建、綁定和監聽動作,并向外提供一個Sock接口用于獲取監聽套接字。
此外,可以將TcpServer設置成單例模式:
- 將TcpServer類的構造函數設置為私有,并將拷貝構造和拷貝賦值函數設置為私有或刪除,防止外部創建或拷貝對象。
- 提供一個指向單例對象的static指針,并在類外將其初始化為nullptr。
- 提供一個全局訪問點獲取單例對象,在單例對象第一次被獲取的時候就創建這個單例對象并進行初始化。
代碼如下:
//TCP服務器
class TcpServer{
private:
int _port; //端口號
int _listen_sock; //監聽套接字
static TcpServer* _svr; //指向單例對象的static指針
private:
//構造函數私有
TcpServer(int port)
:_port(port)
,_listen_sock(-1)
{}
//將拷貝構造函數和拷貝賦值函數私有或刪除(防拷貝)
TcpServer(const TcpServer&)=delete;
TcpServer* operator=(const TcpServer&)=delete;
public:
//獲取單例對象
static TcpServer* GetInstance(int port)
{
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; //定義靜態的互斥鎖
if(_svr == nullptr){
pthread_mutex_lock(&mtx); //加鎖
if(_svr == nullptr){
//創建單例TCP服務器對象并初始化
_svr = new TcpServer(port);
_svr->InitServer();
}
pthread_mutex_unlock(&mtx); //解鎖
}
return _svr; //返回單例對象
}
//初始化服務器
void InitServer()
{
Socket(); //創建套接字
Bind(); //綁定
Listen(); //監聽
LOG(INFO, "tcp_server init ... success");
}
//創建套接字
void Socket()
{
_listen_sock = socket(AF_INET, SOCK_STREAM, 0);
if(_listen_sock < 0){ //創建套接字失敗
LOG(FATAL, "socket error!");
exit(1);
}
//設置端口復用
int opt = 1;
setsockopt(_listen_sock, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
LOG(INFO, "create socket ... success");
}
//綁定
void Bind()
{
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = INADDR_ANY;
if(bind(_listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0){ //綁定失敗
LOG(FATAL, "bind error!");
exit(2);
}
LOG(INFO, "bind socket ... success");
}
//監聽
void Listen()
{
if(listen(_listen_sock, BACKLOG) < 0){ //監聽失敗
LOG(FATAL, "listen error!");
exit(3);
}
LOG(INFO, "listen socket ... success");
}
//獲取監聽套接字
int Sock()
{
return _listen_sock;
}
~TcpServer()
{
if(_listen_sock >= 0){ //關閉監聽套接字
close(_listen_sock);
}
}
};
//單例對象指針初始化為nullptr
TcpServer* TcpServer::_svr = nullptr;
說明一下:
- 如果使用的是云服務器,那么在設置服務器的IP地址時,不需要顯式綁定IP地址,直接將IP地址設置為INADDR_ANY即可,此時服務器就可以從本地任何一張網卡當中讀取數據。此外,由于INADDR_ANY本質就是0,因此在設置時不需要進行網絡字節序列的轉換。
- 在第一次調用GetInstance獲取單例對象時需要創建單例對象,這時需要定義一個鎖來保證線程安全,代碼中以PTHREAD_MUTEX_INITIALIZER的方式定義的靜態的鎖是不需要釋放的,同時為了保證后續調用GetInstance獲取單例對象時不會頻繁的加鎖解鎖,因此代碼中以雙檢查的方式進行加鎖。
HTTP服務器主體邏輯
HTTP服務器主體邏輯
我們可以將HTTP服務器封裝成一個HttpServer類,在構造HttpServer對象時傳入一個端口號,之后就可以調用Loop讓服務器運行起來了。服務器運行起來后要做的就是,先獲取單例對象TcpServer中的監聽套接字,然后不斷從監聽套接字中獲取新連接,每當獲取到一個新連接后就創建一個新線程為該連接提供服務。
代碼如下:
//HTTP服務器
class HttpServer{
private:
int _port; //端口號
public:
HttpServer(int port)
:_port(port)
{}
//啟動服務器
void Loop()
{
LOG(INFO, "loop begin");
TcpServer* tsvr = TcpServer::GetInstance(_port); //獲取TCP服務器單例對象
int listen_sock = tsvr->Sock(); //獲取監聽套接字
while(true){
struct sockaddr_in peer;
memset(&peer, 0, sizeof(peer));
socklen_t len = sizeof(peer);
int sock = accept(listen_sock, (struct sockaddr*)&peer, &len); //獲取新連接
if(sock < 0){
continue; //獲取失敗,繼續獲取
}
//打印客戶端相關信息
std::string client_ip = inet_ntoa(peer.sin_addr);
int client_port = ntohs(peer.sin_port);
LOG(INFO, "get a new link: ["+client_ip+":"+std::to_string(client_port)+"]");
//創建新線程處理新連接發起的HTTP請求
int* p = new int(sock);
pthread_t tid;
pthread_create(&tid, nullptr, CallBack::HandlerRequest, (void*)p);
pthread_detach(tid); //線程分離
}
}
~HttpServer()
{}
};
說明一下:
- 服務器需要將新連接對應的套接字作為參數傳遞給新線程,為了避免該套接字在新線程讀取之前被下一次獲取到的套接字覆蓋,因此在傳遞套接字時最好重新new一塊空間來存儲套接字的值。
- 新線程創建后可以將新線程分離,分離后主線程繼續獲取新連接,而新線程則處理新連接發來的HTTP請求,代碼中的HandlerRequest函數就是新線程處理新連接時需要執行的回調函數。
主函數邏輯
運行服務器時要求指定服務器的端口號,我們用這個端口號創建一個HttpServer對象,然后調用Loop函數運行服務器,此時服務器就會不斷獲取新連接并創建新線程來處理連接。
代碼如下:
{
std::cout<<"Usage:nt"<}
int main(int argc, char* argv[])
{
if(argc != 2){
Usage(argv[0]);
exit(4);
}
int port = atoi(argv[1]); //端口號
std::shared_ptr svr(new HttpServer(port)); //創建HTTP服務器對象
svr->Loop(); //啟動服務器
return 0;
}<<">
HTTP請求結構設計
HTTP請求類
我們可以將HTTP請求封裝成一個類,這個類當中包括HTTP請求的內容、HTTP請求的解析結果以及是否需要使用CGI模式的標志位。后續處理請求時就可以定義一個HTTP請求類,讀取到的HTTP請求的數據就存儲在這個類當中,解析HTTP請求后得到的數據也存儲在這個類當中。
代碼如下:
class HttpRequest{
public:
//HTTP請求內容
std::string _request_line; //請求行
std::vector _request_header; //請求報頭
std::string _blank; //空行
std::string _request_body; //請求正文
//解析結果
std::string _method; //請求方法
std::string _uri; //URI
std::string _version; //版本號
std::unordered_map _header_kv; //請求報頭中的鍵值對
int _content_length; //正文長度
std::string _path; //請求資源的路徑
std::string _query_string; //uri中攜帶的參數
//CGI相關
bool _cgi; //是否需要使用CGI模式
public:
HttpRequest()
:_content_length(0) //默認請求正文長度為0
,_cgi(false) //默認不使用CGI模式
{}
~HttpRequest()
{}
};,>
HTTP響應結構設計
HTTP響應類
HTTP響應也可以封裝成一個類,這個類當中包括HTTP響應的內容以及構建HTTP響應所需要的數據。后續構建響應時就可以定義一個HTTP響應類,構建響應需要使用的數據就存儲在這個類當中,構建后得到的響應內容也存儲在這個類當中。
代碼如下:
class HttpResponse{
public:
//HTTP響應內容
std::string _status_line; //狀態行
std::vector _response_header; //響應報頭
std::string _blank; //空行
std::string _response_body; //響應正文(CGI相關)
//所需數據
int _status_code; //狀態碼
int _fd; //響應文件的fd (非CGI相關)
int _size; //響應文件的大小(非CGI相關)
std::string _suffix; //響應文件的后綴(非CGI相關)
public:
HttpResponse()
:_blank(LINE_END) //設置空行
,_status_code(OK) //狀態碼默認為200
,_fd(-1) //響應文件的fd初始化為-1
,_size(0) //響應文件的大小默認為0
{}
~HttpResponse()
{}
};
EndPoint類編寫
EndPoint結構設計
EndPoint結構設計
EndPoint這個詞經常用來描述進程間通信,比如在客戶端和服務器通信時,客戶端是一個EndPoint,服務器則是另一個EndPoint,因此這里將處理請求的類取名為EndPoint。
EndPoint類中包含三個成員變量:
- sock:表示與客戶端進行通信的套接字。
- http_request:表示客戶端發來的HTTP請求。
- http_response:表示將會發送給客戶端的HTTP響應。
EndPoint類中主要包含四個成員函數:
- RecvHttpRequest:讀取客戶端發來的HTTP請求。
- HandlerHttpRequest:處理客戶端發來的HTTP請求。
- BuildHttpResponse:構建將要發送給客戶端的HTTP響應。
- SendHttpResponse:發送HTTP響應給客戶端。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
public:
EndPoint(int sock)
:_sock(sock)
{}
//讀取請求
void RecvHttpRequest();
//處理請求
void HandlerHttpRequest();
//構建響應
void BuildHttpResponse();
//發送響應
void SendHttpResponse();
~EndPoint()
{}
};
設計線程回調
設計線程回調
服務器每獲取到一個新連接就會創建一個新線程來進行處理,而這個線程要做的實際就是定義一個EndPoint對象,然后依次進行讀取請求、處理請求、構建響應、發送響應,處理完畢后將與客戶端建立的套接字關閉即可。
代碼如下:
public:
static void* HandlerRequest(void* arg)
{
LOG(INFO, "handler request begin");
int sock = *(int*)arg;
EndPoint* ep = new EndPoint(sock);
ep->RecvHttpRequest(); //讀取請求
ep->HandlerHttpRequest(); //處理請求
ep->BuildHttpResponse(); //構建響應
ep->SendHttpResponse(); //發送響應
close(sock); //關閉與該客戶端建立的套接字
delete ep;
LOG(INFO, "handler request end");
return nullptr;
}
};
讀取HTTP請求
讀取HTTP請求
讀取HTTP請求的同時可以對HTTP請求進行解析,這里我們分為五個步驟,分別是讀取請求行、讀取請求報頭和空行、解析請求行、解析請求報頭、讀取請求正文。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
public:
//讀取請求
void RecvHttpRequest()
{
RecvHttpRequestLine(); //讀取請求行
RecvHttpRequestHeader(); //讀取請求報頭和空行
ParseHttpRequestLine(); //解析請求行
ParseHttpRequestHeader(); //解析請求報頭
RecvHttpRequestBody(); //讀取請求正文
}
};
一、讀取請求行
讀取請求行很簡單,就是從套接字中讀取一行內容存儲到HTTP請求類中的request_line中即可。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
private:
//讀取請求行
void RecvHttpRequestLine()
{
auto& line = _http_request._request_line;
if(Util::ReadLine(_sock, line) > 0){
line.resize(line.size() - 1); //去掉讀取上來的n
}
}
};
需要注意的是,這里在按行讀取HTTP請求時,不能直接使用C/C++提供的gets或getline函數進行讀取,因為不同平臺下的行分隔符可能是不一樣的,可能是r、n或者rn。
比如下面是用WFetch請求百度首頁時得到的HTTP響應,可以看到其中使用的行分隔符就是rn:
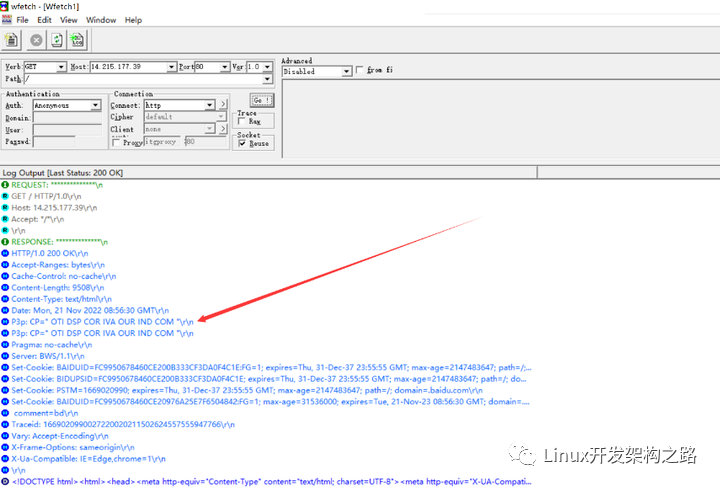
因此我們這里需要自己寫一個ReadLine函數,以確保能夠兼容這三種行分隔符。我們可以把這個函數寫到一個工具類當中,后續編寫的處理字符串的函數也都寫到這個類當中。
ReadLine函數的處理邏輯如下:
- 從指定套接字中讀取一個個字符。
- 如果讀取到的字符既不是n也不是r,則將讀取到的字符push到用戶提供的緩沖區后繼續讀取下一個字符。
- 如果讀取到的字符是n,則說明行分隔符是n,此時將npush到用戶提供的緩沖區后停止讀取。
- 如果讀取到的字符是r,則需要繼續窺探下一個字符是否是n,如果窺探成功則說明行分隔符為rn,此時將未讀取的n讀取上來后,將npush到用戶提供的緩沖區后停止讀取;如果窺探失敗則說明行分隔符是r,此時也將npush到用戶提供的緩沖區后停止讀取。
也就是說,無論是哪一種行分隔符,最終讀取完一行后我們都把npush到了用戶提供的緩沖區當中,相當于將這三種行分隔符統一轉換成了以n為行分隔符,只不過最終我們把n一同讀取到了用戶提供的緩沖區中罷了,因此如果調用者不需要讀取上來的n,需要后續自行將其去掉。
代碼如下:
class Util{
public:
//讀取一行
static int ReadLine(int sock, std::string& out)
{
char ch = 'X'; //ch只要不初始化為n即可(保證能夠進入while循環)
while(ch != 'n'){
ssize_t size = recv(sock, &ch, 1, 0);
if(size > 0){
if(ch == 'r'){
//窺探下一個字符是否為n
recv(sock, &ch, 1, MSG_PEEK);
if(ch == 'n'){ //下一個字符是n
//rn->n
recv(sock, &ch, 1, 0); //將這個n讀走
}
else{ //下一個字符不是n
//r->n
ch = 'n'; //將ch設置為n
}
}
//普通字符或n
out.push_back(ch);
}
else if(size == 0){ //對方關閉連接
return 0;
}
else{ //讀取失敗
return -1;
}
}
return out.size(); //返回讀取到的字符個數
}
};
說明一下:recv函數的最后一個參數如果設置為MSG_PEEK,那么recv函數將返回TCP接收緩沖區頭部指定字節個數的數據,但是并不把這些數據從TCP接收緩沖區中取走,這個叫做數據的窺探功能。
二、讀取請求報頭和空行
由于HTTP的請求報頭和空行都是按行陳列的,因此可以循環調用ReadLine函數進行讀取,并將讀取到的每行數據都存儲到HTTP請求類的request_header中,直到讀取到空行為止。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
private:
//讀取請求報頭和空行
void RecvHttpRequestHeader()
{
std::string line;
while(true){
line.clear(); //每次讀取之前清空line
Util::ReadLine(_sock, line);
if(line == "n"){ //讀取到了空行
_http_request._blank = line;
break;
}
//讀取到一行請求報頭
line.resize(line.size() - 1); //去掉讀取上來的n
_http_request._request_header.push_back(line);
}
}
};
說明一下:
- 由于ReadLine函數是將讀取到的數據直接push_back到用戶提供的緩沖區中的,因此每次調用ReadLine函數進行讀取之前需要將緩沖區清空。
- ReadLine函數會將行分隔符n一同讀取上來,但對于我們來說n并不是有效數據,因此在將讀取到的行存儲到HTTP請求類的request_header中之前,需要先將n去掉。
三、解析請求行
解析請求行要做的就是將請求行中的請求方法、URI和HTTP版本號拆分出來,依次存儲到HTTP請求類的method、uri和version中,由于請求行中的這些數據都是以空格作為分隔符的,因此可以借助一個stringstream對象來進行拆分。此外,為了后續能夠正確判斷用戶的請求方法,這里需要通過transform函數統一將請求方法轉換為全大寫。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
private:
//解析請求行
void ParseHttpRequestLine()
{
auto& line = _http_request._request_line;
//通過stringstream拆分請求行
std::stringstream ss(line);
ss>>_http_request._method>>_http_request._uri>>_http_request._version;
//將請求方法統一轉換為全大寫
auto& method = _http_request._method;
std::transform(method.begin(), method.end(), method.begin(), toupper);
}
};
四、解析請求報頭
解析請求報頭要做的就是將讀取到的一行一行的請求報頭,以: 為分隔符拆分成一個個的鍵值對存儲到HTTP請求的header_kv中,后續就可以直接通過屬性名獲取到對應的值了。
代碼如下:
//服務端EndPoint
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
private:
//解析請求報頭
void ParseHttpRequestHeader()
{
std::string key;
std::string value;
for(auto& iter : _http_request._request_header){
//將每行請求報頭打散成kv鍵值對,插入到unordered_map中
if(Util::CutString(iter, key, value, SEP)){
_http_request._header_kv.insert({key, value});
}
}
}
};
此處用于切割字符串的CutString函數也可以寫到工具類中,切割字符串時先通過find方法找到指定的分隔符,然后通過substr提取切割后的子字符串即可。
代碼如下:
class Util{
public:
//切割字符串
static bool CutString(std::string& target, std::string& sub1_out, std::string& sub2_out, std::string sep)
{
size_t pos = target.find(sep, 0);
if(pos != std::string::npos){
sub1_out = target.substr(0, pos);
sub2_out = target.substr(pos + sep.size());
return true;
}
return false;
}
};
五、讀取請求正文
在讀取請求正文之前,首先需要通過本次的請求方法來判斷是否需要讀取請求正文,因為只有請求方法是POST方法才可能會有請求正文,此外,如果請求方法為POST,我們還需要通過請求報頭中的Content-Length屬性來得知請求正文的長度。
在得知需要讀取請求正文以及請求正文的長度后,就可以將請求正文讀取到HTTP請求類的request_body中了。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
private:
//判斷是否需要讀取請求正文
bool IsNeedRecvHttpRequestBody()
{
auto& method = _http_request._method;
if(method == "POST"){ //請求方法為POST則需要讀取正文
auto& header_kv = _http_request._header_kv;
//通過Content-Length獲取請求正文長度
auto iter = header_kv.find("Content-Length");
if(iter != header_kv.end()){
_http_request._content_length = atoi(iter->second.c_str());
return true;
}
}
return false;
}
//讀取請求正文
void RecvHttpRequestBody()
{
if(IsNeedRecvHttpRequestBody()){ //先判斷是否需要讀取正文
int content_length = _http_request._content_length;
auto& body = _http_request._request_body;
//讀取請求正文
char ch = 0;
while(content_length){
ssize_t size = recv(_sock, &ch, 1, 0);
if(size > 0){
body.push_back(ch);
content_length--;
}
else{
break;
}
}
}
}
};
說明一下:
- 由于后續還會用到請求正文的長度,因此代碼中將其存儲到了HTTP請求類的content_length中。
- 在通過Content-Length獲取到請求正文的長度后,需要將請求正文長度從字符串類型轉換為整型。
處理HTTP請求
定義狀態碼
在處理請求的過程中可能會因為某些原因而直接停止處理,比如請求方法不正確、請求資源不存在或服務器處理請求時出錯等等。為了告知客戶端本次HTTP請求的處理情況,服務器需要定義不同的狀態碼,當處理請求被終止時就可以設置對應的狀態碼,后續構建HTTP響應的時候就可以根據狀態碼返回對應的錯誤頁面。
狀態碼定義如下:
#define BAD_REQUEST 400
#define NOT_FOUND 404
#define INTERNAL_SERVER_ERROR 500
處理HTTP請求
處理HTTP請求的步驟如下:
- 判斷請求方法是否是正確,如果不正確則設置狀態碼為BAD_REQUEST后停止處理。
- 如果請求方法為GET方法,則需要判斷URI中是否帶參。如果URI不帶參,則說明URI即為客戶端請求的資源路徑;如果URI帶參,則需要以?為分隔符對URI進行字符串切分,切分后?左邊的內容就是客戶端請求的資源路徑,而?右邊的內容則是GET方法攜帶的參數,由于此時GET方法攜帶了參數,因此后續處理需要使用CGI模式,于是需要將HTTP請求類中的cgi設置為true。
- 如果請求方法為POST方法,則說明URI即為客戶端請求的資源路徑,由于POST方法會通過請求正文上傳參數,因此后續處理需要使用CGI模式,于是需要將HTTP請求類中的cgi設置為true。
- 接下來需要對客戶端請求的資源路徑進行處理,首先需要在請求的資源路徑前拼接上web根目錄,然后需要判斷請求資源路徑的最后一個字符是否是/,如果是則說明客戶端請求的是一個目錄,這時服務器不會將該目錄下全部的資源都返回給客戶端,而是默認將該目錄下的index.html返回給客戶端,因此這時還需要在請求資源路徑的后面拼接上index.html。
- 對請求資源的路徑進行處理后,需要通過stat函數獲取客戶端請求資源文件的屬性信息。如果客戶端請求的是一個目錄,則需要在請求資源路徑的后面拼接上/index.html并重新獲取資源文件的屬性信息;如果客戶端請求的是一個可執行程序,則說明后續處理需要使用CGI模式,于是需要將HTTP請求類中的cgi設置為true。
- 根據HTTP請求類中的cgi分別進行CGI或非CGI處理。
代碼如下:
#define HOME_PAGE "index.html"
//服務端EndPoint
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
public:
//處理請求
void HandlerHttpRequest()
{
auto& code = _http_response._status_code;
if(_http_request._method != "GET"&&_http_request._method != "POST"){ //非法請求
LOG(WARNING, "method is not right");
code = BAD_REQUEST; //設置對應的狀態碼,并直接返回
return;
}
if(_http_request._method == "GET"){
size_t pos = _http_request._uri.find('?');
if(pos != std::string::npos){ //uri中攜帶參數
//切割uri,得到客戶端請求資源的路徑和uri中攜帶的參數
Util::CutString(_http_request._uri, _http_request._path, _http_request._query_string, "?");
_http_request._cgi = true; //上傳了參數,需要使用CGI模式
}
else{ //uri中沒有攜帶參數
_http_request._path = _http_request._uri; //uri即是客戶端請求資源的路徑
}
}
else if(_http_request._method == "POST"){
_http_request._path = _http_request._uri; //uri即是客戶端請求資源的路徑
_http_request._cgi = true; //上傳了參數,需要使用CGI模式
}
else{
//Do Nothing
}
//給請求資源路徑拼接web根目錄
std::string path = _http_request._path;
_http_request._path = WEB_ROOT;
_http_request._path += path;
//請求資源路徑以/結尾,說明請求的是一個目錄
if(_http_request._path[_http_request._path.size() - 1] == '/'){
//拼接上該目錄下的index.html
_http_request._path += HOME_PAGE;
}
//獲取請求資源文件的屬性信息
struct stat st;
if(stat(_http_request._path.c_str(), &st) == 0){ //屬性信息獲取成功,說明該資源存在
if(S_ISDIR(st.st_mode)){ //該資源是一個目錄
_http_request._path += "/"; //需要拼接/,以/結尾的目錄前面已經處理過了
_http_request._path += HOME_PAGE; //拼接上該目錄下的index.html
stat(_http_request._path.c_str(), &st); //需要重新資源文件的屬性信息
}
else if(st.st_mode&S_IXUSR||st.st_mode&S_IXGRP||st.st_mode&S_IXOTH){ //該資源是一個可執行程序
_http_request._cgi = true; //需要使用CGI模式
}
_http_response._size = st.st_size; //設置請求資源文件的大小
}
else{ //屬性信息獲取失敗,可以認為該資源不存在
LOG(WARNING, _http_request._path + " NOT_FOUND");
code = NOT_FOUND; //設置對應的狀態碼,并直接返回
return;
}
//獲取請求資源文件的后綴
size_t pos = _http_request._path.rfind('.');
if(pos == std::string::npos){
_http_response._suffix = ".html"; //默認設置
}
else{
_http_response._suffix = _http_request._path.substr(pos);
}
//進行CGI或非CGI處理
if(_http_request._cgi == true){
code = ProcessCgi(); //以CGI的方式進行處理
}
else{
code = ProcessNonCgi(); //簡單的網頁返回,返回靜態網頁
}
}
};
說明一下:
- 本項目實現的HTTP服務器只支持GET方法和POST方法,因此如果客戶端發來的HTTP請求中不是這兩種方法則認為請求方法錯誤,如果想讓服務器支持其他的請求方法則直接增加對應的邏輯即可。
- 服務器向外提供的資源都會放在web根目錄下,比如網頁、圖片、視頻等資源,本項目中的web根目錄取名為wwwroot。web根目錄下的所有子目錄下都會有一個首頁文件,當用戶請求的資源是一個目錄時,就會默認返回該目錄下的首頁文件,本項目中的首頁文件取名為index.html。
- stat是一個系統調用函數,它可以獲取指定文件的屬性信息,包括文件的inode編號、文件的權限、文件的大小等。如果調用stat函數獲取文件的屬性信息失敗,則可以認為客戶端請求的這個資源文件不存在,此時直接設置狀態碼為NOT_FOUND后停止處理即可。
- 當獲取文件的屬性信息后發現該文件是一個目錄,此時請求資源路徑一定不是以/結尾的,因為在此之前已經對/結尾的請求資源路徑進行過處理了,因此這時需要給請求資源路徑拼接上/index.html。
- 只要一個文件的擁有者、所屬組、other其中一個具有可執行權限,則說明這是一個可執行文件,此時就需要將HTTP請求類中的cgi設置為true。
- 由于后續構建HTTP響應時需要用到請求資源文件的后綴,因此代碼中對請求資源路徑通過從后往前找.的方式,來獲取請求資源文件的后綴,如果沒有找到.則默認請求資源的后綴為.html。
- 由于請求資源文件的大小后續可能會用到,因此在獲取到請求資源文件的屬性后,可以將請求資源文件的大小保存到HTTP響應類的size中。
CGI處理
CGI處理時需要創建子進程進行進程程序替換,但是在創建子進程之前需要先創建兩個匿名管道。這里站在父進程角度對這兩個管道進行命名,父進程用于讀取數據的管道叫做input,父進程用于寫入數據的管道叫做output。
示意圖如下:
創建匿名管道并創建子進程后,需要父子進程各自關閉兩個管道對應的讀寫端:
- 對于父進程來說,input管道是用來讀數據的,因此父進程需要保留input[0]關閉input[1],而output管道是用來寫數據的,因此父進程需要保留output[1]關閉output[0]。
- 對于子進程來說,input管道是用來寫數據的,因此子進程需要保留input[1]關閉input[0],而output管道是用來讀數據的,因此子進程需要保留output[0]關閉output[1]。
此時父子進程之間的通信信道已經建立好了,但為了讓替換后的CGI程序從標準輸入讀取數據等價于從管道讀取數據,向標準輸出寫入數據等價于向管道寫入數據,因此在子進程進行進程程序替換之前,還需要對子進程進行重定向。
假設子進程保留的input[1]和output[0]對應的文件描述符分別是3和4,那么子進程對應的文件描述符表的指向大致如下:
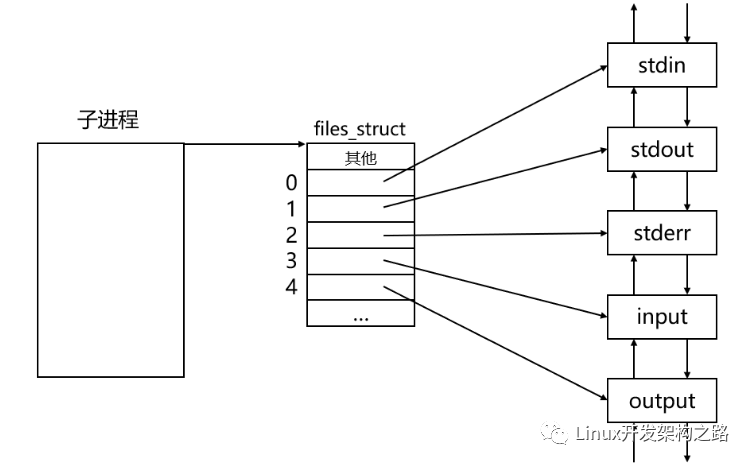
現在我們要做的就是將子進程的標準輸入重定向到output管道,將子進程的標準輸出重定向到input管道,也就是讓子進程的0號文件描述符指向output管道,讓子進程的1號文件描述符指向input管道。
示意圖如下:
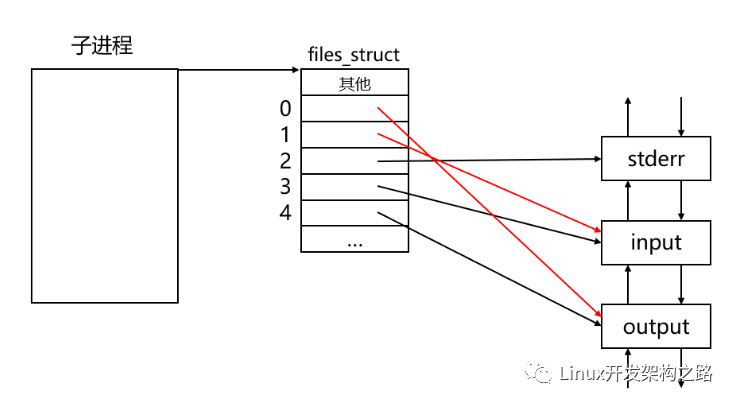
此外,在子進程進行進程程序替換之前,還需要進行各種參數的傳遞:
- 首先需要將請求方法通過putenv函數導入環境變量,以供CGI程序判斷應該以哪種方式讀取父進程傳遞過來的參數。
- 如果請求方法為GET方法,則需要將URL中攜帶的參數通過導入環境變量的方式傳遞給CGI程序。
- 如果請求方法為POST方法,則需要將請求正文的長度通過導入環境變量的方式傳遞給CGI程序,以供CGI程序判斷應該從管道讀取多少個參數。
此時子進程就可以進行進程程序替換了,而父進程需要做如下工作:
- 如果請求方法為POST方法,則父進程需要將請求正文中的參數寫入管道中,以供被替換后的CGI程序進行讀取。
- 然后父進程要做的就是不斷調用read函數,從管道中讀取CGI程序寫入的處理結果,并將其保存到HTTP響應類的response_body當中。
- 管道中的數據讀取完畢后,父進程需要調用waitpid函數等待CGI程序退出,并關閉兩個管道對應的文件描述符,防止文件描述符泄露。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
private:
//CGI處理
int ProcessCgi()
{
int code = OK; //要返回的狀態碼,默認設置為200
auto& bin = _http_request._path; //需要執行的CGI程序
auto& method = _http_request._method; //請求方法
//需要傳遞給CGI程序的參數
auto& query_string = _http_request._query_string; //GET
auto& request_body = _http_request._request_body; //POST
int content_length = _http_request._content_length; //請求正文的長度
auto& response_body = _http_response._response_body; //CGI程序的處理結果放到響應正文當中
//1、創建兩個匿名管道(管道命名站在父進程角度)
//創建從子進程到父進程的通信信道
int input[2];
if(pipe(input) < 0){ //管道創建失敗,則返回對應的狀態碼
LOG(ERROR, "pipe input error!");
code = INTERNAL_SERVER_ERROR;
return code;
}
//創建從父進程到子進程的通信信道
int output[2];
if(pipe(output) < 0){ //管道創建失敗,則返回對應的狀態碼
LOG(ERROR, "pipe output error!");
code = INTERNAL_SERVER_ERROR;
return code;
}
//2、創建子進程
pid_t pid = fork();
if(pid == 0){ //child
//子進程關閉兩個管道對應的讀寫端
close(input[0]);
close(output[1]);
//將請求方法通過環境變量傳參
std::string method_env = "METHOD=";
method_env += method;
putenv((char*)method_env.c_str());
if(method == "GET"){ //將query_string通過環境變量傳參
std::string query_env = "QUERY_STRING=";
query_env += query_string;
putenv((char*)query_env.c_str());
LOG(INFO, "GET Method, Add Query_String env");
}
else if(method == "POST"){ //將正文長度通過環境變量傳參
std::string content_length_env = "CONTENT_LENGTH=";
content_length_env += std::to_string(content_length);
putenv((char*)content_length_env.c_str());
LOG(INFO, "POST Method, Add Content_Length env");
}
else{
//Do Nothing
}
//3、將子進程的標準輸入輸出進行重定向
dup2(output[0], 0); //標準輸入重定向到管道的輸入
dup2(input[1], 1); //標準輸出重定向到管道的輸出
//4、將子進程替換為對應的CGI程序
execl(bin.c_str(), bin.c_str(), nullptr);
exit(1); //替換失敗
}
else if(pid < 0){ //創建子進程失敗,則返回對應的錯誤碼
LOG(ERROR, "fork error!");
code = INTERNAL_SERVER_ERROR;
return code;
}
else{ //father
//父進程關閉兩個管道對應的讀寫端
close(input[1]);
close(output[0]);
if(method == "POST"){ //將正文中的參數通過管道傳遞給CGI程序
const char* start = request_body.c_str();
int total = 0;
int size = 0;
while(total < content_length && (size = write(output[1], start + total, request_body.size() - total)) > 0){
total += size;
}
}
//讀取CGI程序的處理結果
char ch = 0;
while(read(input[0], &ch, 1) > 0){
response_body.push_back(ch);
} //不會一直讀,當另一端關閉后會繼續執行下面的代碼
//等待子進程(CGI程序)退出
int status = 0;
pid_t ret = waitpid(pid, &status, 0);
if(ret == pid){
if(WIFEXITED(status)){ //正常退出
if(WEXITSTATUS(status) == 0){ //結果正確
LOG(INFO, "CGI program exits normally with correct results");
code = OK;
}
else{
LOG(INFO, "CGI program exits normally with incorrect results");
code = BAD_REQUEST;
}
}
else{
LOG(INFO, "CGI program exits abnormally");
code = INTERNAL_SERVER_ERROR;
}
}
//關閉兩個管道對應的文件描述符
close(input[0]);
close(output[1]);
}
return code; //返回狀態碼
}
};
說明一下:
- 在CGI處理過程中,如果管道創建失敗或者子進程創建失敗,則屬于服務器端處理請求時出錯,此時返回INTERNAL_SERVER_ERROR狀態碼后停止處理即可。
- 環境變量是key=value形式的,因此在調用putenv函數導入環境變量前需要先正確構建環境變量,此后被替換的CGI程序在調用getenv函數時,就可以通過key獲取到對應的value。
- 子進程傳遞參數的代碼最好放在重定向之前,否則服務器運行后無法看到傳遞參數對應的日志信息,因為日志是以cout的方式打印到標準輸出的,而dup2函數調用后標準輸出已經被重定向到了管道,此時打印的日志信息將會被寫入管道。
- 父進程循環調用read函數從管道中讀取CGI程序的處理結果,當CGI程序執行結束時相當于寫端進程將寫端關閉了(文件描述符的生命周期隨進程),此時讀端進程將管道當中的數據讀完后,就會繼續執行后續代碼,而不會被阻塞。
- 父進程在等待子進程退出后,可以通過WIFEXITED判斷子進程是否是正常退出,如果是正常退出再通過WEXITSTATUS判斷處理結果是否正確,然后根據不同情況設置對應的狀態碼(此時就算子進程異常退出或處理結果不正確也不能立即返回,需要讓父進程繼續向后執行,關閉兩個管道對應的文件描述符,防止文件描述符泄露)。
非CGI處理
非CGI處理時只需要將客戶端請求的資源構建成HTTP響應發送給客戶端即可,理論上這里要做的就是打開目標文件,將文件中的內容讀取到HTTP響應類的response_body中,以供后續發送HTTP響應時進行發送即可,但我們并不推薦這種做法。
因為HTTP響應類的response_body屬于用戶層的緩沖區,而目標文件是存儲在服務器的磁盤上的,按照這種方式需要先將文件內容讀取到內核層緩沖區,再由操作系統將其拷貝到用戶層緩沖區,發送響應正文的時候又需要先將其拷貝到內核層緩沖區,再由操作系統將其發送給對應的網卡進行發送。
示意圖如下:
可以看到上述過程涉及數據在用戶層和內核層的來回拷貝,但實際這個拷貝操作是不需要的,我們完全可以直接將磁盤當中的目標文件內容讀取到內核,再由內核將其發送給對應的網卡進行發送。
示意圖如下:
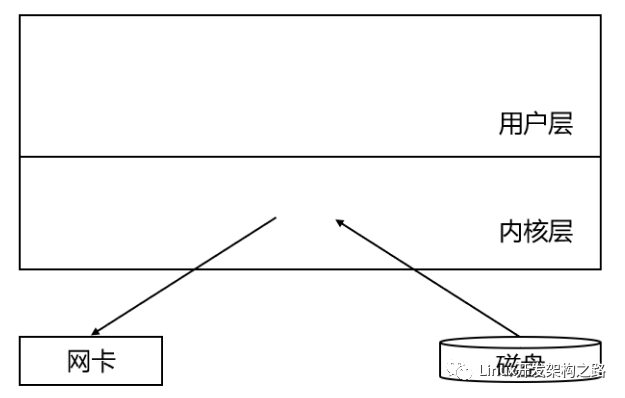
要達到上述效果就需要使用sendfile函數,該函數的功能就是將數據從一個文件描述符拷貝到另一個文件描述符,并且這個拷貝操作是在內核中完成的,因此sendfile比單純的調用read和write更加高效。
但是需要注意的是,這里還不能直接調用sendfile函數,因為sendfile函數調用后文件內容就發送出去了,而我們應該構建HTTP響應后再進行發送,因此我們這里要做的僅僅是將要發送的目標文件打開即可,將打開文件對應的文件描述符保存到HTTP響應的fd當中。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
private:
//非CGI處理
int ProcessNonCgi()
{
//打開客戶端請求的資源文件,以供后續發送
_http_response._fd = open(_http_request._path.c_str(), O_RDONLY);
if(_http_response._fd >= 0){ //打開文件成功
return OK;
}
return INTERNAL_SERVER_ERROR; //打開文件失敗
}
};
說明一下: 如果打開文件失敗,則返回INTERNAL_SERVER_ERROR狀態碼表示服務器處理請求時出錯,而不能返回NOT_FOUND,因為之前調用stat獲取過客戶端請求資源的屬性信息,說明該資源文件是一定存在的。
構建HTTP響應
構建HTTP響應
構建HTTP響應首先需要構建的就是狀態行,狀態行由狀態碼、狀態碼描述、HTTP版本構成,并以空格作為分隔符,將狀態行構建好后保存到HTTP響應的status_line當中即可,而響應報頭需要根據請求是否正常處理完畢分別進行構建。
代碼如下:
#define LINE_END "rn"
#define PAGE_400 "400.html"
#define PAGE_404 "404.html"
#define PAGE_500 "500.html"
//服務端EndPoint
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
public:
//構建響應
void BuildHttpResponse()
{
int code = _http_response._status_code;
//構建狀態行
auto& status_line = _http_response._status_line;
status_line += HTTP_VERSION;
status_line += " ";
status_line += std::to_string(code);
status_line += " ";
status_line += CodeToDesc(code);
status_line += LINE_END;
//構建響應報頭
std::string path = WEB_ROOT;
path += "/";
switch(code){
case OK:
BuildOkResponse();
break;
case NOT_FOUND:
path += PAGE_404;
HandlerError(path);
break;
case BAD_REQUEST:
path += PAGE_400;
HandlerError(path);
break;
case INTERNAL_SERVER_ERROR:
path += PAGE_500;
HandlerError(path);
break;
default:
break;
}
}
};
注意:本項目中將服務器的行分隔符設置為rn,在構建完狀態行以及每行響應報頭之后都需要加上對應的行分隔符,而在HTTP響應類的構造函數中已經將空行初始化為了LINE_END,因此在構建HTTP響應時不用處理空行。
對于狀態行中的狀態碼描述,我們可以編寫一個函數,該函數能夠根據狀態碼返回對應的狀態碼描述。
代碼如下:
static std::string CodeToDesc(int code)
{
std::string desc;
switch(code){
case 200:
desc = "OK";
break;
case 400:
desc = "Bad Request";
break;
case 404:
desc = "Not Found";
break;
case 500:
desc = "Internal Server Error";
break;
default:
break;
}
return desc;
}
構建響應報頭(請求正常處理完畢)
構建HTTP的響應報頭時,我們至少需要構建Content-Type和Content-Length這兩個響應報頭,分別用于告知對方響應資源的類型和響應資源的長度。
對于請求正常處理完畢的HTTP請求,需要根據客戶端請求資源的后綴來得知返回資源的類型。而返回資源的大小需要根據該請求被處理的方式來得知,如果該請求是以非CGI方式進行處理的,那么返回資源的大小早已在獲取請求資源屬性時被保存到了HTTP響應類中的size當中,如果該請求是以CGI方式進行處理的,那么返回資源的大小應該是HTTP響應類中的response_body的大小。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
private:
void BuildOkResponse()
{
//構建響應報頭
std::string content_type = "Content-Type: ";
content_type += SuffixToDesc(_http_response._suffix);
content_type += LINE_END;
_http_response._response_header.push_back(content_type);
std::string content_length = "Content-Length: ";
if(_http_request._cgi){ //以CGI方式請求
content_length += std::to_string(_http_response._response_body.size());
}
else{ //以非CGI方式請求
content_length += std::to_string(_http_response._size);
}
content_length += LINE_END;
_http_response._response_header.push_back(content_length);
}
};
對于返回資源的類型,我們可以編寫一個函數,該函數能夠根據文件后綴返回對應的文件類型。查看Content-Type轉化表可以得知后綴與文件類型的對應關系,將這個對應關系存儲一個unordered_map容器中,當需要根據后綴得知文件類型時直接在這個unordered_map容器中進行查找,如果找到了則返回對應的文件類型,如果沒有找到則默認該文件類型為text/html。
代碼如下:
static std::string SuffixToDesc(const std::string& suffix)
{
static std::unordered_map suffix_to_desc = {
{".html", "text/html"},
{".css", "text/css"},
{".js", "application/x-javascript"},
{".jpg", "application/x-jpg"},
{".xml", "text/xml"}
};
auto iter = suffix_to_desc.find(suffix);
if(iter != suffix_to_desc.end()){
return iter->second;
}
return "text/html"; //所給后綴未找到則默認該資源為html文件
},>
構建響應報頭(請求處理出現錯誤)
對于請求處理過程中出現錯誤的HTTP請求,服務器將會為其返回對應的錯誤頁面,因此返回的資源類型就是text/html,而返回資源的大小可以通過獲取錯誤頁面對應的文件屬性信息來得知。此外,為了后續發送響應時可以直接調用sendfile進行發送,這里需要將錯誤頁面對應的文件打開,并將對應的文件描述符保存在HTTP響應類的fd當中。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
private:
void HandlerError(std::string page)
{
_http_request._cgi = false; //需要返回對應的錯誤頁面(非CGI返回)
//打開對應的錯誤頁面文件,以供后續發送
_http_response._fd = open(page.c_str(), O_RDONLY);
if(_http_response._fd > 0){ //打開文件成功
//構建響應報頭
struct stat st;
stat(page.c_str(), &st); //獲取錯誤頁面文件的屬性信息
std::string content_type = "Content-Type: text/html";
content_type += LINE_END;
_http_response._response_header.push_back(content_type);
std::string content_length = "Content-Length: ";
content_length += std::to_string(st.st_size);
content_length += LINE_END;
_http_response._response_header.push_back(content_length);
_http_response._size = st.st_size; //重新設置響應文件的大小
}
}
};
特別注意:對于處理請求時出錯的HTTP請求,需要將其HTTP請求類中的cgi重新設置為false,因為后續發送HTTP響應時,需要根據HTTP請求類中的cgi來進行響應正文的發送,當請求處理出錯后要返回給客戶端的本質就是一個錯誤頁面文件,相當于是以非CGI方式進行處理的。
發送HTTP響應
發送HTTP響應
發送HTTP響應的步驟如下:
- 調用send函數,依次發送狀態行、響應報頭和空行。
- 發送響應正文時需要判斷本次請求的處理方式,如果本次請求是以CGI方式成功處理的,那么待發送的響應正文是保存在HTTP響應類的response_body中的,此時調用send函數進行發送即可。
- 如果本次請求是以非CGI方式處理或在處理過程中出錯的,那么待發送的資源文件或錯誤頁面文件對應的文件描述符是保存在HTTP響應類的fd中的,此時調用sendfile進行發送即可,發送后關閉對應的文件描述符。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
public:
//發送響應
void SendHttpResponse()
{
//發送狀態行
send(_sock, _http_response._status_line.c_str(), _http_response._status_line.size(), 0);
//發送響應報頭
for(auto& iter : _http_response._response_header){
send(_sock, iter.c_str(), iter.size(), 0);
}
//發送空行
send(_sock, _http_response._blank.c_str(), _http_response._blank.size(), 0);
//發送響應正文
if(_http_request._cgi){
auto& response_body = _http_response._response_body;
const char* start = response_body.c_str();
size_t size = 0;
size_t total = 0;
while(total < response_body.size()&&(size = send(_sock, start + total, response_body.size() - total, 0)) > 0){
total += size;
}
}
else{
sendfile(_sock, _http_response._fd, nullptr, _http_response._size);
//關閉請求的資源文件
close(_http_response._fd);
}
}
};
差錯處理
至此服務器邏輯其實已經已經走通了,但你會發現服務器在處理請求的過程中有時會莫名其妙的崩潰,根本原因就是當前服務器的錯誤處理還沒有完全處理完畢。
邏輯錯誤
邏輯錯誤
邏輯錯誤主要是服務器在處理請求的過程中出現的一些錯誤,比如請求方法不正確、請求資源不存在或服務器處理請求時出錯等等。邏輯錯誤其實我們已經處理過了,當出現這類錯誤時服務器會將對應的錯誤頁面返回給客戶端。
讀取錯誤
讀取錯誤
邏輯錯誤是在服務器處理請求時可能出現的錯誤,而在服務器處理請求之前首先要做的是讀取請求,在讀取請求的過程中出現的錯誤就叫做讀取錯誤,比如調用recv讀取請求時出錯或讀取請求時對方連接關閉等。
出現讀取錯誤時,意味著服務器都沒有成功讀取完客戶端發來的HTTP請求,因此服務器也沒有必要進行后續的處理請求、構建響應以及發送響應的相關操作了。
可以在EndPoint類中新增一個bool類型的stop成員,表示是否停止本次處理,stop的值默認設置為false,當讀取請求出錯時就直接設置stop為true并不再進行后續的讀取操作,因此讀取HTTP請求的代碼需要稍作修改。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
bool _stop; //是否停止本次處理
private:
//讀取請求行
bool RecvHttpRequestLine()
{
auto& line = _http_request._request_line;
if(Util::ReadLine(_sock, line) > 0){
line.resize(line.size() - 1); //去掉讀取上來的n
}
else{ //讀取出錯,則停止本次處理
_stop = true;
}
return _stop;
}
//讀取請求報頭和空行
bool RecvHttpRequestHeader()
{
std::string line;
while(true){
line.clear(); //每次讀取之前清空line
if(Util::ReadLine(_sock, line) <= 0){ //讀取出錯,則停止本次處理
_stop = true;
break;
}
if(line == "n"){ //讀取到了空行
_http_request._blank = line;
break;
}
//讀取到一行請求報頭
line.resize(line.size() - 1); //去掉讀取上來的n
_http_request._request_header.push_back(line);
}
return _stop;
}
//讀取請求正文
bool RecvHttpRequestBody()
{
if(IsNeedRecvHttpRequestBody()){ //先判斷是否需要讀取正文
int content_length = _http_request._content_length;
auto& body = _http_request._request_body;
//讀取請求正文
char ch = 0;
while(content_length){
ssize_t size = recv(_sock, &ch, 1, 0);
if(size > 0){
body.push_back(ch);
content_length--;
}
else{ //讀取出錯或對端關閉,則停止本次處理
_stop = true;
break;
}
}
}
return _stop;
}
public:
EndPoint(int sock)
:_sock(sock)
,_stop(false)
{}
//本次處理是否停止
bool IsStop()
{
return _stop;
}
//讀取請求
void RecvHttpRequest()
{
if(!RecvHttpRequestLine()&&!RecvHttpRequestHeader()){ //短路求值
ParseHttpRequestLine();
ParseHttpRequestHeader();
RecvHttpRequestBody();
}
}
};
說明一下:
- 可以將讀取請求行、讀取請求報頭和空行、讀取請求正文對應函數的返回值改為bool類型,當讀取請求行成功后再讀取請求報頭和空行,而當讀取請求報頭和空行成功后才需要進行后續的解析請求行、解析請求報頭以及讀取請求正文操作,這里利用到了邏輯運算符的短路求值策略。
- EndPoint類當中提供了IsStop函數,用于讓外部處理線程得知是否應該停止本次處理。
此時服務器創建的新線程在讀取請求后,就需要判斷是否應該停止本次處理,如果需要則不再進行處理請求、構建響應以及發送響應操作,而直接關閉于客戶端建立的套接字即可。
代碼如下:
public:
static void* HandlerRequest(void* arg)
{
LOG(INFO, "handler request begin");
int sock = *(int*)arg;
EndPoint* ep = new EndPoint(sock);
ep->RecvHttpRequest(); //讀取請求
if(!ep->IsStop()){
LOG(INFO, "Recv No Error, Begin Handler Request");
ep->HandlerHttpRequest(); //處理請求
ep->BuildHttpResponse(); //構建響應
ep->SendHttpResponse(); //發送響應
}
else{
LOG(WARNING, "Recv Error, Stop Handler Request");
}
close(sock); //關閉與該客戶端建立的套接字
delete ep;
LOG(INFO, "handler request end");
return nullptr;
}
};
寫入錯誤
寫入錯誤
除了讀取請求時可能出現讀取錯誤,處理請求時可能出現邏輯錯誤,在響應構建完畢發送響應時同樣可能會出現寫入錯誤,比如調用send發送響應時出錯或發送響應時對方連接關閉等。
出現寫入錯誤時,服務器也沒有必要繼續進行發送了,這時需要直接設置stop為true并不再進行后續的發送操作,因此發送HTTP響應的代碼也需要進行修改。
代碼如下:
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
public:
//發送響應
bool SendHttpResponse()
{
//發送狀態行
if(send(_sock, _http_response._status_line.c_str(), _http_response._status_line.size(), 0) <= 0){
_stop = true; //發送失敗,設置_stop
}
//發送響應報頭
if(!_stop){
for(auto& iter : _http_response._response_header){
if(send(_sock, iter.c_str(), iter.size(), 0) <= 0){
_stop = true; //發送失敗,設置_stop
break;
}
}
}
//發送空行
if(!_stop){
if(send(_sock, _http_response._blank.c_str(), _http_response._blank.size(), 0) <= 0){
_stop = true; //發送失敗,設置_stop
}
}
//發送響應正文
if(_http_request._cgi){
if(!_stop){
auto& response_body = _http_response._response_body;
const char* start = response_body.c_str();
size_t size = 0;
size_t total = 0;
while(total < response_body.size()&&(size = send(_sock, start + total, response_body.size() - total, 0)) > 0){
total += size;
}
}
}
else{
if(!_stop){
if(sendfile(_sock, _http_response._fd, nullptr, _http_response._size) <= 0){
_stop = true; //發送失敗,設置_stop
}
}
//關閉請求的資源文件
close(_http_response._fd);
}
return _stop;
}
};
此外,當服務器發送響應出錯時會收到SIGPIPE信號,而該信號的默認處理動作是終止當前進程,為了防止服務器因為寫入出錯而被終止,需要在初始化HTTP服務器時調用signal函數忽略SIGPIPE信號。
代碼如下:
class HttpServer{
private:
int _port; //端口號
public:
//初始化服務器
void InitServer()
{
signal(SIGPIPE, SIG_IGN); //忽略SIGPIPE信號,防止寫入時崩潰
}
};
接入線程池
當前多線程版服務器存在的問題:
- 每當獲取到新連接時,服務器主線程都會重新為該客戶端創建為其提供服務的新線程,而當服務結束后又會將該新線程銷毀,這樣做不僅麻煩,而且效率低下。
- 如果同時有大量的客戶端連接請求,此時服務器就要為每一個客戶端創建對應的服務線程,而計算機中的線程越多,CPU壓力就越大,因為CPU要不斷在這些線程之間來回切換。此外,一旦線程過多,每一個線程再次被調度的周期就變長了,而線程是為客戶端提供服務的,線程被調度的周期變長,客戶端也就遲遲得不到應答。
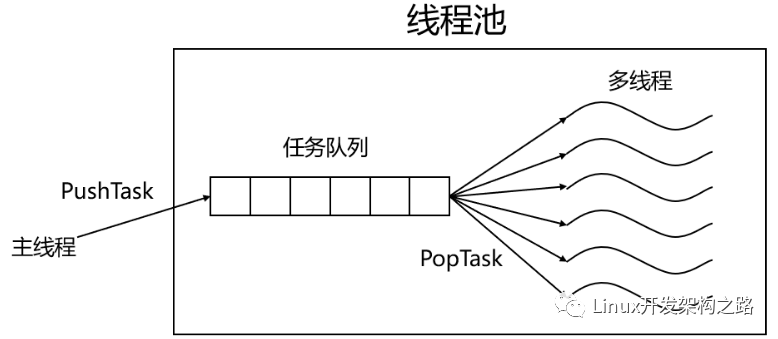
這時可以在服務器端引入線程池:
- 在服務器端預先創建一批線程和一個任務隊列,每當獲取到一個新連接時就將其封裝成一個任務對象放到任務隊列當中。
- 線程池中的若干線程就不斷從任務隊列中獲取任務進行處理,如果任務隊列當中沒有任務則線程進入休眠狀態,當有新任務時再喚醒線程進行任務處理。
示意圖如下:
設計任務
設計任務
當服務器獲取到一個新連接后,需要將其封裝成一個任務對象放到任務隊列當中。任務類中首先需要有一個套接字,也就是與客戶端進行通信的套接字,此外還需要有一個回調函數,當線程池中的線程獲取到任務后就可以調用這個回調函數進行任務處理。
代碼如下:
class Task{
private:
int _sock; //通信的套接字
CallBack _handler; //回調函數
public:
Task()
{}
Task(int sock)
:_sock(sock)
{}
//處理任務
void ProcessOn()
{
_handler(_sock); //調用回調
}
~Task()
{}
};
說明一下: 任務類需要提供一個無參的構造函數,因為后續從任務隊列中獲取任務時,需要先以無參的方式定義一個任務對象,然后再以輸出型參數的方式來獲取任務。
編寫任務回調
任務類中處理任務時需要調用的回調函數,實際就是之前創建新線程時傳入的執行例程CallBack::HandlerRequest,我們可以將CallBack類的()運算符重載為調用HandlerRequest函數,這時CallBack對象就變成了一個仿函數對象,這個仿函數對象被調用時實際就是在調用HandlerRequest函數。
代碼如下:
public:
CallBack()
{}
void operator()(int sock)
{
HandlerRequest(sock);
}
void HandlerRequest(int sock)
{
LOG(INFO, "handler request begin");
EndPoint* ep = new EndPoint(sock);
ep->RecvHttpRequest(); //讀取請求
if(!ep->IsStop()){
LOG(INFO, "Recv No Error, Begin Handler Request");
ep->HandlerHttpRequest(); //處理請求
ep->BuildHttpResponse(); //構建響應
ep->SendHttpResponse(); //發送響應
if(ep->IsStop()){
LOG(WARNING, "Send Error, Stop Send Response");
}
}
else{
LOG(WARNING, "Recv Error, Stop Handler Request");
}
close(sock); //關閉與該客戶端建立的套接字
delete ep;
LOG(INFO, "handler request end");
}
~CallBack()
{}
};
編寫線程池
設計線程池結構
可以將線程池設計成單例模式:
- 將ThreadPool類的構造函數設置為私有,并將拷貝構造和拷貝賦值函數設置為私有或刪除,防止外部創建或拷貝對象。
- 提供一個指向單例對象的static指針,并在類外將其初始化為nullptr。
- 提供一個全局訪問點獲取單例對象,在單例對象第一次被獲取時就創建這個單例對象并進行初始化。
ThreadPool類中的成員變量包括:
- 任務隊列:用于暫時存儲未被處理的任務對象。
- num:表示線程池中線程的個數。
- 互斥鎖:用于保證任務隊列在多線程環境下的線程安全。
- 條件變量:當任務隊列中沒有任務時,讓線程在該條件變量下進行等等,當任務隊列中新增任務時,喚醒在該條件變量下進行等待的線程。
- 指向單例對象的指針:用于指向唯一的單例線程池對象。
ThreadPool類中的成員函數主要包括:
- 構造函數:完成互斥鎖和條件變量的初始化操作。
- 析構函數:完成互斥鎖和條件變量的釋放操作。
- InitThreadPool:初始化線程池時調用,完成線程池中若干線程的創建。
- PushTask:生產任務時調用,將任務對象放入任務隊列,并喚醒在條件變量下等待的一個線程進行處理。
- PopTask:消費任務時調用,從任務隊列中獲取一個任務對象。
- ThreadRoutine:線程池中每個線程的執行例程,完成線程分離后不斷檢測任務隊列中是否有任務,如果有則調用PopTask獲取任務進行處理,如果沒有則進行休眠直到被喚醒。
- GetInstance:獲取單例線程池對象時調用,如果單例對象未創建則創建并初始化后返回,如果單例對象已經創建則直接返回單例對象。
代碼如下:
//線程池
class ThreadPool{
private:
std::queue _task_queue; //任務隊列
int _num; //線程池中線程的個數
pthread_mutex_t _mutex; //互斥鎖
pthread_cond_t _cond; //條件變量
static ThreadPool* _inst; //指向單例對象的static指針
private:
//構造函數私有
ThreadPool(int num = NUM)
:_num(num)
{
//初始化互斥鎖和條件變量
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
}
//將拷貝構造函數和拷貝賦值函數私有或刪除(防拷貝)
ThreadPool(const ThreadPool&)=delete;
ThreadPool* operator=(const ThreadPool&)=delete;
//判斷任務隊列是否為空
bool IsEmpty()
{
return _task_queue.empty();
}
//任務隊列加鎖
void LockQueue()
{
pthread_mutex_lock(&_mutex);
}
//任務隊列解鎖
void UnLockQueue()
{
pthread_mutex_unlock(&_mutex);
}
//讓線程在條件變量下進行等待
void ThreadWait()
{
pthread_cond_wait(&_cond, &_mutex);
}
//喚醒在條件變量下等待的一個線程
void ThreadWakeUp()
{
pthread_cond_signal(&_cond);
}
public:
//獲取單例對象
static ThreadPool* GetInstance()
{
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; //定義靜態的互斥鎖
//雙檢查加鎖
if(_inst == nullptr){
pthread_mutex_lock(&mtx); //加鎖
if(_inst == nullptr){
//創建單例線程池對象并初始化
_inst = new ThreadPool();
_inst->InitThreadPool();
}
pthread_mutex_unlock(&mtx); //解鎖
}
return _inst; //返回單例對象
}
//線程的執行例程
static void* ThreadRoutine(void* arg)
{
pthread_detach(pthread_self()); //線程分離
ThreadPool* tp = (ThreadPool*)arg;
while(true){
tp->LockQueue(); //加鎖
while(tp->IsEmpty()){
//任務隊列為空,線程進行wait
tp->ThreadWait();
}
Task task;
tp->PopTask(task); //獲取任務
tp->UnLockQueue(); //解鎖
task.ProcessOn(); //處理任務
}
}
//初始化線程池
bool InitThreadPool()
{
//創建線程池中的若干線程
pthread_t tid;
for(int i = 0;i < _num;i++){
if(pthread_create(&tid, nullptr, ThreadRoutine, this) != 0){
LOG(FATAL, "create thread pool error!");
return false;
}
}
LOG(INFO, "create thread pool success");
return true;
}
//將任務放入任務隊列
void PushTask(const Task& task)
{
LockQueue(); //加鎖
_task_queue.push(task); //將任務推入任務隊列
UnLockQueue(); //解鎖
ThreadWakeUp(); //喚醒一個線程進行任務處理
}
//從任務隊列中拿任務
void PopTask(Task& task)
{
//獲取任務
task = _task_queue.front();
_task_queue.pop();
}
~ThreadPool()
{
//釋放互斥鎖和條件變量
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
}
};
//單例對象指針初始化為nullptr
ThreadPool* ThreadPool::_inst = nullptr;
說明一下:
- 由于線程的執行例程的參數只能有一個void*類型的參數,因此線程的執行例程必須定義成靜態成員函數,而線程執行例程中又需要訪問任務隊列,因此需要將this指針作為參數傳遞給線程的執行例程,這樣線程才能夠通過this指針訪問任務隊列。
- 在向任務隊列中放任務以及從任務隊列中獲取任務時,都需要通過加鎖的方式來保證線程安全,而線程在調用PopTask之前已經進行過加鎖了,因此在PopTask函數中不必再加鎖。
- 當任務隊列中有任務時會喚醒線程進行任務處理,為了防止被偽喚醒的線程調用PopTask時無法獲取到任務,因此需要以while的方式判斷任務隊列是否為空。
引入線程池后服務器要做的就是,每當獲取到一個新連接時就構建一個任務,然后調用PushTask將其放入任務隊列即可。
代碼如下:
class HttpServer{
private:
int _port; //端口號
public:
//啟動服務器
void Loop()
{
LOG(INFO, "loop begin");
TcpServer* tsvr = TcpServer::GetInstance(_port); //獲取TCP服務器單例對象
int listen_sock = tsvr->Sock(); //獲取監聽套接字
while(true){
struct sockaddr_in peer;
memset(&peer, 0, sizeof(peer));
socklen_t len = sizeof(peer);
int sock = accept(listen_sock, (struct sockaddr*)&peer, &len); //獲取新連接
if(sock < 0){
continue; //獲取失敗,繼續獲取
}
//打印客戶端相關信息
std::string client_ip = inet_ntoa(peer.sin_addr);
int client_port = ntohs(peer.sin_port);
LOG(INFO, "get a new link: ["+client_ip+":"+std::to_string(client_port)+"]");
//構建任務并放入任務隊列中
Task task(sock);
ThreadPool::GetInstance()->PushTask(task);
}
}
};
項目測試
服務器結構
至此HTTP服務器后端邏輯已經全部編寫完畢,此時我們要做的就是將對外提供的資源文件放在一個名為wwwroot的目錄下,然后將生成的HTTP服務器可執行程序與wwwroot放在同級目錄下。比如:
由于當前HTTP服務器沒有任何業務邏輯,因此向外提供的資源文件只有三個錯誤頁面文件,這些錯誤頁面文件中的內容大致如下:
404 Not Found
對不起,你所要訪問的資源不存在!
首頁請求測試
服務器首頁編寫
服務器的web根目錄下的資源文件主要有兩種,一種就是用于處理客戶端上傳上來的數據的CGI程序,另一種就是供客戶端請求的各種網頁文件了,而網頁的制作實際是前端工程師要做的,但現在我們要對服務器進行測試,至少需要編寫一個首頁,首頁文件需要放在web根目錄下,取名為index.html。
以演示為主,首頁的代碼如下:
首頁請求測試
指定端口號運行服務器后可以看到一系列日志信息被打印出來,包括套接字創建成功、綁定成功、監聽成功,這時底層用于通信的TCP服務器已經初始化成功了。
此時在瀏覽器上指定IP和端口訪問我們的HTTP服務器,由于我們沒有指定要訪問服務器web根目錄下的那個資源,此時服務器就會默認將web根目錄下的index.html文件進行返回,瀏覽器收到index.html文件后經過刷新渲染就顯示出了對應的首頁頁面。
同時服務器端也打印出了本次請求的一些日志信息。如下:
此時通過ps -aL命令可以看到線程池中的線程已經被創建好了,其中PID和LWP相同的就是主線程,剩下的就是線程池中處理任務的若干新線程。如下:
錯誤請求測試
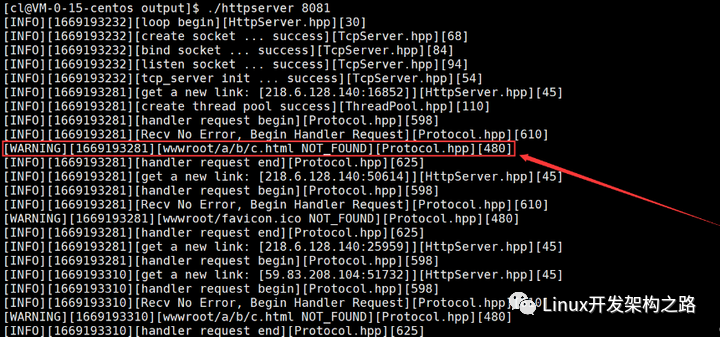
錯誤請求測試
如果我們請求的資源服務器并沒有提供,那么服務器就會在獲取請求資源屬性信息時失敗,這時服務器會停止本次請求處理,而直接將web根目錄下的404.html文件返回瀏覽器,瀏覽器收到后經過刷新渲染就顯示出了對應的404頁面。

這時在服務器端就能看到一條日志級別為WARNING的日志信息,這條日志信息中說明了客戶端請求的哪一個資源是不存在的。
GET方法上傳數據測試
編寫CGI程序
如果用戶請求服務器時上傳了數據,那么服務器就需要將該數據后交給對應的CGI程序進行處理,因此在測試GET方法上傳數據之前,我們需要先編寫一個簡單的CGI程序。
首先,CGI程序啟動后需要先獲取父進程傳遞過來的數據:
- 先通過getenv函數獲取環境變量中的請求方法。
- 如果請求方法為GET方法,則繼續通過getenv函數獲取父進程傳遞過來的數據。
- 如果請求方法為POST方法,則先通過getenv函數獲取父進程傳遞過來的數據的長度,然后再從0號文件描述符中讀取指定長度的數據即可。
代碼如下:
bool GetQueryString(std::string& query_string)
{
bool result = false;
std::string method = getenv("METHOD"); //獲取請求方法
if(method == "GET"){ //GET方法通過環境變量獲取參數
query_string = getenv("QUERY_STRING");
result = true;
}
else if(method == "POST"){ //POST方法通過管道獲取參數
int content_length = atoi(getenv("CONTENT_LENGTH"));
//從管道中讀取content_length個參數
char ch = 0;
while(content_length){
read(0, &ch, 1);
query_string += ch;
content_length--;
}
result = true;
}
else{
//Do Nothing
result = false;
}
return result;
}
CGI程序在獲取到父進程傳遞過來的數據后,就可以根據具體的業務場景進行數據處理了,比如用戶上傳的如果是一個關鍵字則需要CGI程序做搜索處理。我們這里以演示為目的,認為用戶上傳的是形如a=10&b=20的兩個參數,需要CGI程序進行加減乘除運算。
因此我們的CGI程序要做的就是,先以&為分隔符切割數據將兩個操作數分開,再以=為分隔符切割數據分別獲取到兩個操作數的值,最后對兩個操作數進行加減乘除運算,并將計算結果打印到標準輸出即可(標準輸出已經被重定向到了管道)。
代碼如下:
bool CutString(std::string& in, const std::string& sep, std::string& out1, std::string& out2)
{
size_t pos = in.find(sep);
if(pos != std::string::npos){
out1 = in.substr(0, pos);
out2 = in.substr(pos + sep.size());
return true;
}
return false;
}
int main()
{
std::string query_string;
GetQueryString(query_string); //獲取參數
//以&為分隔符將兩個操作數分開
std::string str1;
std::string str2;
CutString(query_string, "&", str1, str2);
//以=為分隔符分別獲取兩個操作數的值
std::string name1;
std::string value1;
CutString(str1, "=", name1, value1);
std::string name2;
std::string value2;
CutString(str2, "=", name2, value2);
//處理數據
int x = atoi(value1.c_str());
int y = atoi(value2.c_str());
std::cout<<"";
std::cout<<"";
std::cout<<"";
std::cout<<"
"<";
std::cout<<"
"<";
std::cout<<"
"<";
std::cout<<"
"<"; //除0后cgi程序崩潰,屬于異常退出
std::cout<<"";
std::cout<<"";
return 0;
}<<">
<<"><<"><<">說明一下:
- CGI程序輸出的結果最終會交給瀏覽器,因此CGI程序輸出的最好是一個HTML文件,這樣瀏覽器收到后就可以其渲染到頁面上,讓用戶看起來更美觀。
- 可以看到,使用C/C++以HTML的格式進行輸出是很費勁的,因此這部分操作一般是由Python等語言來完成的,而在此之前對數據進行業務處理的動作一般才用C/C++等語言來完成。
- 在編寫CGI程序時如果要進行調試,debug內容應該通過標準錯誤流進行輸出,因為子進程在被替換成CGI程序之前,已經將標準輸出重定向到管道了。
URL上傳數據測試
CGI程序編寫編寫完畢并生成可執行程序后,將這個可執行程序放到web根目錄下,這時在請求服務器時就可以指定請求這個CGI程序,并通過URL上傳參數讓其進行處理,最終我們就能得到計算結果。

此外,如果請求CGI程序時指定的第二個操作數為0,那么CGI程序在進行除法運算時就會崩潰,這時父進程等待子進程后就會發現子進程是異常退出的,進而設置狀態碼為INTERNAL_SERVER_ERROR,最終服務器就會構建對應的錯誤頁面返回給瀏覽器。

表單上傳數據測試
當然,讓用戶通過更改URL的方式來向服務器上傳參數是不現實的,服務器一般會讓用戶通過表單來上傳參數。
HTML中的表單用于搜集用戶的輸入,我們可以通過設置表單的method屬性來指定表單提交的方法,通過設置表單的action屬性來指定表單需要提交給服務器上的哪一個CGI程序。
比如現在將服務器的首頁改成以下HTML代碼,指定將表單中的數據以GET方法提交給web根目錄下的test_cgi程序:
操作數1:
操作數2:
此時我們直接訪問服務器看到的就是一個表單,向表單中輸入兩個操作數并點擊“計算”后,表單中的數據就會以GET方法提交給web根目錄下的test_cgi程序,此時CGI程序進行數據計算后同樣將結果返回給了瀏覽器。
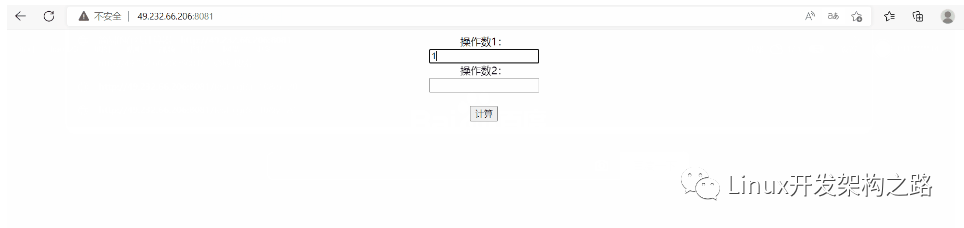
同時在提交表單的一瞬間可以看到,通過表單上傳的數據也回顯到了瀏覽器上方的URL中,并且請求的資源也變成了web根目錄下的test_cgi。實際就是我們在點擊“計算”后,瀏覽器檢測到表單method為“get”后,將把表單中數據添加到了URL中,并將請求資源路徑替換成了表單action指定的路徑,然后再次向服務器發起HTTP請求。
理解百度搜索
當我們在百度的搜索框輸入關鍵字并回車后,可以看到上方的URL發生了變化,URL中的請求資源路徑為/s,并且URL后面攜帶了很多參數。
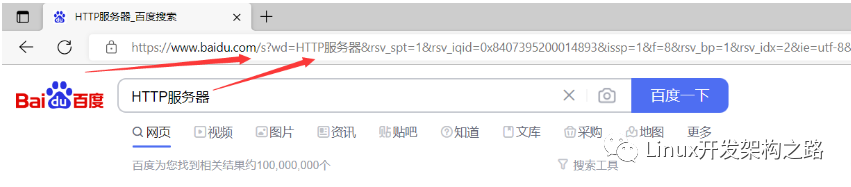
實際這里的/s就可以理解成是百度web根目錄下的一個CGI程序,而URL中攜帶的各種參數就是交給這個CGI程序做搜索處理的,可以看到攜帶的參數中有一個名為wd的參數,這個參數正是用戶的搜索關鍵字。
POST方法上傳數據測試
表單上傳數據測試
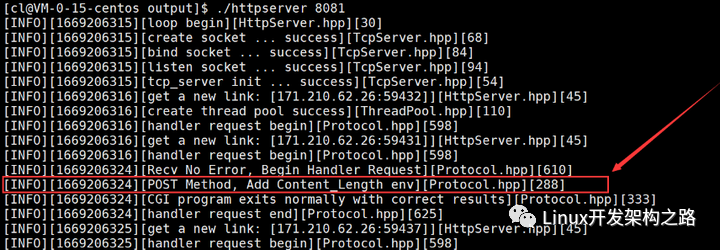
測試表單通過POST方法上傳數據時,只需要將表單中的method屬性改為“post”即可,此時點擊“計算”提交表單時,瀏覽器檢測到表單的提交方法為POST后,就會將表單中的數據添加到請求正文中,并將請求資源路徑替換成表單action指定的路徑,然后再次向服務器發起HTTP請求。

可以看到,由于POST方法是通過請求正文上傳的數據,因此表單提交后瀏覽器上方的URL中只有請求資源路徑發生了改變,而并沒有在URL后面添加任何參數。同時觀察服務器端輸出的日志信息,也可以確認瀏覽器本次的請求方法為POST方法。
項目擴展
當前項目的重點在于HTTP服務器后端的處理邏輯,主要完成的是GET和POST請求方法,以及CGI機制的搭建。如果想對當前項目進行擴展,可以選擇在技術層面或應用層面進行擴展。
技術層面的擴展
技術層面可以選擇進行如下擴展:
- 當前項目編寫的是HTTP1.0版本的服務器,每次連接都只會對一個請求進行處理,當服務器對客戶端的請求處理完畢并收到客戶端的應答后,就會直接斷開連接。可以將其擴展為HTTP1.1版本,讓服務器支持長連接,即通過一條連接可以對多個請求進行處理,避免重復建立連接(涉及連接管理)。
- 當前項目雖然在后端接入了線程池,但也只能滿足中小型應用,可以考慮將服務器改寫成epoll版本,讓服務器的IO變得更高效。
- 可以給當前的HTTP服務器新增代理功能,也就是可以替代客戶端去訪問某種服務,然后將訪問結果再返回給客戶端。
應用層面的擴展
應用層面可以選擇進行如下擴展:
- 基于當前HTTP服務器,搭建在線博客。
- 基于當前HTTP服務器,編寫在線畫圖板。
- 基于當前HTTP服務器,編寫一個搜索引擎。
-
互聯網
+關注
關注
54文章
11148瀏覽量
103237 -
服務器
+關注
關注
12文章
9123瀏覽量
85329 -
網絡
+關注
關注
14文章
7553瀏覽量
88732 -
編程
+關注
關注
88文章
3614瀏覽量
93686 -
HTTP
+關注
關注
0文章
504瀏覽量
31197
發布評論請先 登錄
相關推薦
求助,能否實現PPP撥號功能+構建HTTP服務器?
有沒有辦法讓HTTP服務器安全?
HTTP OTA webclient獲取不到服務器如何處理?
如何基于HTTP Web服務器示例實現TLS HTTPS服務器?
HTTP服務器fsdata_custom.c項目問題求解
如何實現ESP32上運行運行HTTP服務器?
如何辨別Web服務器,應用程序服務器,HTTP服務器
如何用Python 實現 HTTP 和 FTP 服務器
利用iMCU7100EVB實現HTTP服務器(一)
如何正確的理解使用WEB服務器和應用程序服務器及HTTP服務器
三種常見的服務器詳細介紹
基于LwIP的HTTP服務器設計
如何利用AWFlow搭建HTTP服務器







 工商網監
工商網監
評論