 無鎖隊列的潛在優勢
無鎖隊列的潛在優勢
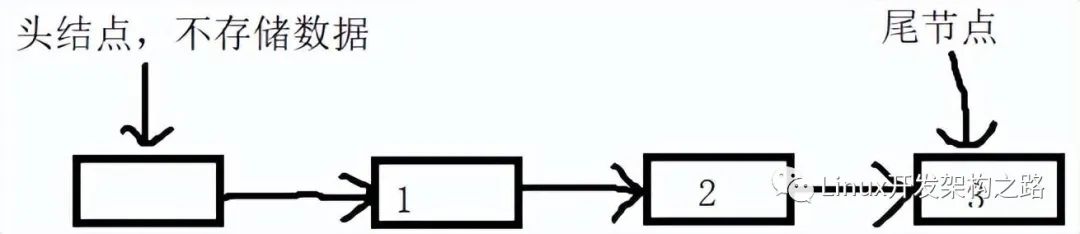
無鎖隊列
先大致介紹一下無鎖隊列。無鎖隊列的根本是CAS函數——CompareAndSwap,即比較并交換,函數功能可以用C++函數來說明:
{
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
return old_reg_val;
}
它將reg的值與oldval的值進行對比,若相同則將reg賦新值。注意以上操作是原子操作。大部分語言都有提供CAS支持,不過函數原型可能有些微的不同,許多語言(包括go)中CAS的返回值是標識是否賦值成功的bool值。
無鎖隊列則是以CAS來實現同步的一種隊列,我的具體實現這里就不貼出來了,有點冗長,文末給出了源碼地址。這里僅僅大致給出實現思路,網上關于無鎖隊列的資料很多,這里就不詳細說了。
{
q = new record();
q->value = x;
q->next = NULL;
p = tail;
oldp = p
do {
while (p->next != NULL)
p = p->next;
} while( CAS(p.next, NULL, q) != TRUE); //如果沒有把結點鏈在尾上,再試
CAS(tail, oldp, q); //置尾結點
}
DeQueue() //出隊列
{
do{
p = head;
if (p->next == NULL){
return ERR_EMPTY_QUEUE;
}
while( CAS(head, p, p->next) != TRUE );
return p->next->value;
}
自旋鎖
自旋鎖是加鎖失敗時接著循環請求加鎖,直到成功。它的特點是不會釋放CPU,故也沒有互斥鎖那種內核態切換操作,但缺點也很明顯,就是會一直占用CPU,理論上適用于臨界區小、不需要長時間加鎖的場景。 這里只貼鎖的相關代碼,隊列的實現就不貼了:
type spinMutex struct {
mutex int32
}
const locked = 1
const unlocked = 0
func (spin *spinMutex) lock() {
for !atomic.CompareAndSwapInt32(&spin.mutex, unlocked, locked) {}
}
func (spin *spinMutex) unlock() {
atomic.SwapInt32(&spin.mutex, unlocked)
}
互斥鎖
這個沒什么好說的,用的golang自帶的互斥鎖sync.Mutex。
測試
下面將分2種場景進行測試:分別是高并發和低并發。高并發我用4個協程往隊列中push數據,4個協程從隊列中pop數據(雖然不是很高,但足以區分性能,就沒測太高并發了,畢竟測一次等的太久也累);低并發不好模擬,于是我干脆極端點改為無并發——先順序寫,再順序讀。
無并發
大致測試代碼結構如下(刪減了不關鍵的語句):
for i := 1; i <= dataNum; i++ {
suc := queue.PushBack(i)
}
queue.Disable()
for {
val, enable := queue.PopFront()
if !enable {
break
}
}
fmt.Println("用時:", time.Since(t1))
為了方便對比,我特地還增加了不加鎖的隊列的測試結果。測試結果如下:(左側為dataNum數據量)
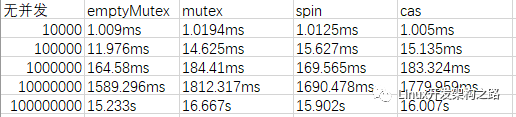
添加圖片注釋,不超過 140 字(可選)
可以看到數據量小的時候性能差別還不明顯,甚至cas還有少許的優勢。但數據量一大就很明顯的看出自旋鎖的效率會高一點,cas次之。不過它們差別都不大。
高并發
這里用4個生產者4個消費者共用一個隊列來模擬高并發。測試代碼結構如下:
wgr := sync.WaitGroup{}
wgw := sync.WaitGroup{}
t1 := time.Now()
for i := 0; i < 4; i++ {
wgr.Add(1)
go reader(i*1000000, &wgr)
}
for i := 0; i < 4; i++ {
wgw.Add(1)
go writter(&wgw)
}
wgr.Wait()
queue.Disable()
wgw.Wait()
fmt.Println("用時:", time.Since(t1))
}
func reader(startNum int, wg *sync.WaitGroup) {
for i := 0; i < dataNum; i++ {
suc := queue.PushBack(startNum + i)
for !suc {
suc = queue.PushBack(startNum + i)
}
}
wg.Done()
}
func writter(wg *sync.WaitGroup) {
for {
r, enable := queue.PopFront()
if enable == false {
break
}
if r == defaultVal {
continue
}
}
wg.Done()
}
這種情況下就沒法測試無鎖隊列了,數據都不完整(已驗證)。測試結果如下,左側為讀/寫協程數*dataNum數據量(下面讀/寫協程數為4指總共開了8個協程):

添加圖片注釋,不超過 140 字(可選)
可以看到cas有巨大的性能優勢,甚至達到了3到5倍的性能差距,說明這個思路還是可行的!(先開始被chan打擊到了)反倒是自旋鎖的性能最差,這個倒有些出乎我的意料,按照我的理解在這種頻繁加鎖解鎖的情況下自旋鎖的性能應該更好才對,若有知情人士望告知。
分析
為了對這幾種鎖的性能特點有更深入的分析,這里還補充了幾組測試,分別用了不同的協程數和數據量進行補充測試:

添加圖片注釋,不超過 140 字(可選)
可以很明顯的看到一個趨勢——隨著并發度增加,自旋鎖的性能急劇下降,由無并發時的與cas性能幾乎一樣到最后與cas將近7倍的效率差。而mutex和cas情況下,隨著并發度增加,性能影響并不大,下面將前面的測試數據重新組織一下方便對比:

添加圖片注釋,不超過 140 字(可選)
可以看到總數據量不變的情況下,并發協程數對mutex和cas的影響非常小,基本在波動范圍以內。相較之下自旋鎖就比較慘了。
總結
**根據上面的結果來說的話,當實際競爭特別小的時候,可以考慮用自旋鎖;而并發大的時候,用無鎖隊列這種結構有很大潛在優勢。**之所以說潛在的是因為我也僅僅是簡單的實現某種結構,肯定有考慮不全的地方,我寫這個無鎖例子主要用于測試,也沒打算用于實際場景中。但是我盡量保證了同樣的代碼結構下,最大化各個鎖結構對性能的影響。總的來說,本文測試結果僅作參考,希望能有拋磚引玉的效果。
最后,再附上源碼地址:https://github.com/HandsomeRosin/lockfree
更新:
針對自旋鎖效率低下的問題我仔細想了想,應該是原子操作cas耗時的問題(畢竟在無并發情況下,cas和真正不加鎖還是有很大的性能差距)。于是對自旋鎖的代碼進行了微調,減少了CAS的調用次數:(被注釋掉的是原本的代碼邏輯)
// for !atomic.CompareAndSwapInt32(&spin.mutex, unlocked, locked) {}
BEGINING:
for spin.mutex != unlocked {}
if !atomic.CompareAndSwapInt32(&spin.mutex, unlocked, locked) {
goto BEGINING
}
}
事實證明,這樣做效率確實提高了約1/4,不過還是改變不了它的大趨勢(與cas和mutex的性能差距依舊巨大),所以就沒更新前面的測試數據了。
不過這也佐證了CAS也是比較耗時的一個操作,平時還是不能肆意使用。
-
數據
+關注
關注
8文章
7067瀏覽量
89110 -
源碼
+關注
關注
8文章
643瀏覽量
29244 -
函數
+關注
關注
3文章
4333瀏覽量
62691 -
CAS
+關注
關注
0文章
34瀏覽量
15213
發布評論請先 登錄
相關推薦
《有鎖》/《無鎖》/《簽約》/《解鎖》/《越獄》/《激活》專
AWorks軟件設計,郵箱、消息隊列和自旋鎖使用方法
智能鎖按鍵出現無反應或禁止操作的原因坤坤智能鎖告訴你
關于CAS等原子操作介紹 無鎖隊列的鏈表實現方法
怎么設計實現一個無鎖高并發的環形連續內存緩沖隊列
發燒友實測 | i.MX8MP 編譯DPDK源碼實現rte_ring無鎖環隊列進程間通信

無源智能鎖的應用前景

新品上架——無源智能把手鎖
無鎖CAS如何實現各種無鎖的數據結構





 工商網監
工商網監
評論