") c++線程中鎖的基本類型和用法
c++線程中鎖的基本類型和用法
線程之間的鎖有:互斥鎖、條件鎖、自旋鎖、讀寫鎖、遞歸鎖。一般而言,鎖的功能與性能成反比。不過我們一般不使用遞歸鎖(C++標準庫提供了std::recursive_mutex),所以這里就不推薦了。
互斥鎖(Mutex)
互斥鎖用于控制多個線程對他們之間共享資源互斥訪問的一個信號量。也就是說是為了避免多個線程在某一時刻同時操作一個共享資源。例如線程池中的有多個空閑線程和一個任務隊列。任何是一個線程都要使用互斥鎖互斥訪問任務隊列,以避免多個線程同時訪問任務隊列以發(fā)生錯亂。
在某一時刻,只有一個線程可以獲取互斥鎖,在釋放互斥鎖之前其他線程都不能獲取該互斥鎖。如果其他線程想要獲取這個互斥鎖,那么這個線程只能以阻塞方式進行等待。
頭文件:< mutex >
類型:std::mutex
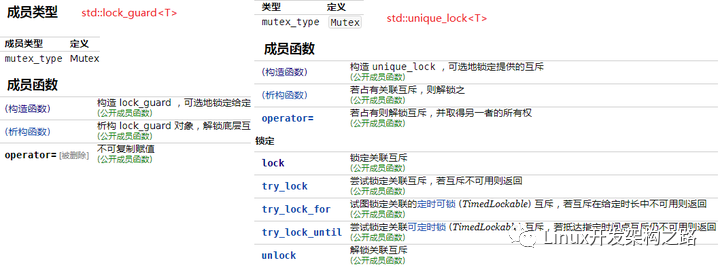
用法:在C++中,通過構造std::mutex的實例創(chuàng)建互斥元,調用成員函數(shù)lock()來鎖定它,調用unlock()來解鎖,不過一般不推薦這種做法,標準C++庫提供了std::lock_guard和unique_lock類模板,都是RAII風格,它們是在定義時獲得鎖,在析構時釋放鎖。它們的主要區(qū)別在于unique_lock鎖機制更加靈活,可以再需要的時候進行l(wèi)ock或者unlock調用,不非得是析構或者構造時。std::mutex和std::lock _ guard。都聲明在< mutex >頭文件中。
#include
#include
std::list some_list;
std::mutex some_mutex;
void add_to_list(int new_value)
{
std::lock_guard guard(some_mutex);
some_list.push_back(new_value);
}
以下情況會出現(xiàn)死鎖:
int i = 0;
void fun0()
{
while (i < 100)
{
lock_guard g0(m0); //線程0加鎖0
lock_guard g1(m1); //線程0加鎖1
cout << "thread 0 running..." << endl;
}
return;
}
void fun1()
{
while (i < 100)
{
lock_guard g1(m1); //線程1加鎖1
lock_guard g0(m0); //線程1加鎖0
cout << "thread 1 running... "<< i << endl;
}
return;
}
int main()
{
thread p0(fun0);
thread p1(fun1);
p0.join();
p1.join();
return 0;
}
死鎖:死鎖是指兩個或兩個以上的進程(線程)在運行過程中因爭奪資源而造成的一種僵局,若無外力作用,這些進程(線程)都將無法向前推進。
解決死鎖的方法:
1、順序加鎖
int i = 0;
void fun0()
{
while (i < 100)
{
lock_guard g0(m0); //線程0加鎖0
lock_guard g1(m1); //線程0加鎖1
cout << "thread 0 running..." << endl;
}
return;
}
void fun1()
{
while (i < 100)
{
lock_guard g0(m0); //線程1加鎖0
lock_guard g1(m1); //線程1加鎖1
cout << "thread 1 running... "<< i << endl;
}
return;
}
int main()
{
thread p0(fun0);
thread p1(fun1);
p0.join();
p1.join();
return 0;
}
2、同時上鎖(需要用到lock函數(shù))++
int i = 0;
void fun0()
{
while (i < 100)
{
lock(m0,m1);
lock_guard g0(m0, adopt_lock);
lock_guard g1(m1, adopt_lock);
cout << "thread 0 running..." << endl;
}
return;
}
void fun1()
{
while (i < 100)
{
lock(m0,m1);
lock_guard g0(m0, adopt_lock);
lock_guard g1(m1, adopt_lock);
cout << "thread 1 running... "<< i << endl;
}
return;
}
int main()
{
thread p0(fun0);
thread p1(fun1);
p0.join();
p1.join();
return 0;
}
注意到這里的lock_guard中多了第二個參數(shù)adopt_lock,這個參數(shù)表示在調用lock_guard時,已經(jīng)加鎖了,防止lock_guard在對象生成時構造函數(shù)再次lock()。
條件鎖
當需要死循環(huán)判斷某個條件成立與否時【true or false】,我們往往需要開一個線程死循環(huán)來判斷,這樣非常消耗CPU。使用條件變量,可以讓當前線程wait,釋放CPU,如果條件改變時,我們再notify退出線程,再次進行判斷。
條件鎖就是所謂的條件變量,某一個線程因為某個條件未滿足時可以使用條件變量使該程序處于阻塞狀態(tài)。一旦條件滿足以“信號量”的方式喚醒一個因為該條件而被阻塞的線程(常和互斥鎖配合使用),喚醒后,需要檢查變量,避免虛假喚醒。最為常見就是在線程池中,起初沒有任務時任務隊列為空,此時線程池中的線程因為“任務隊列為空”這個條件處于阻塞狀態(tài)。一旦有任務進來,就會以信號量的方式喚醒一個線程來處理這個任務。
頭文件:< condition_variable >
類型:std::condition_variable(只和std::mutex一起工作) 和 std::condition_variable_any(符合類似互斥元的最低標準的任何東西一起工作)。

C++標準庫在< condition_variable >中提供了條件變量,借由它,一個線程可以喚醒一個或多個其他等待中的線程。
想要修改共享變量(即“條件”)的線程必須:
- 獲得一個std::mutex
- 當持有鎖的時候,執(zhí)行修改動作
- 對std::condition_variable執(zhí)行notify_one或notify_all(當做notify動作時,不必持有鎖)
即使共享變量是原子性的,它也必須在mutex的保護下被修改,這是為了能夠將改動正確發(fā)布到正在等待的線程。
任意要等待std::condition_variable的線程必須:
- 獲取std::unique_lockstd::mutex,這個mutex正是用來保護共享變量(即“條件”)的
- 執(zhí)行wait, wait_for或者wait_until. 這些等待動作原子性地釋放mutex,并使得線程的執(zhí)行暫停
- 當獲得條件變量的通知,或者超時,或者一個虛假的喚醒,那么線程就會被喚醒,并且獲得mutex. 然后線程應該檢查條件是否成立,如果是虛假喚醒,就繼續(xù)等待。
【注:所謂虛假喚醒,就是因為某種未知的罕見的原因,線程被從等待狀態(tài)喚醒了,但其實共享變量(即條件)并未變?yōu)閠rue。因此此時應繼續(xù)等待】
std::mutex mu;
std::condition_variable cond;
void function_1() //生產(chǎn)者
{
int count = 10;
while (count > 0)
{
std::unique_lock locker(mu);
q.push_front(count);
locker.unlock();
cond.notify_one(); // Notify one waiting thread, if there is one.
std::this_thread::sleep_for(std::chrono::seconds(1));
count--;
}
}
void function_2() //消費者
{
int data = 0;
while (data != 1)
{
std::unique_lock locker(mu);
while (q.empty())
cond.wait(locker); // Unlock mu and wait to be notified
data = q.back();
q.pop_back();
locker.unlock();
std::cout << "t2 got a value from t1: " << data << std::endl;
}
}
int main()
{
std::thread t1(function_1);
std::thread t2(function_2);
t1.join();
t2.join();
return 0;
}
上面的代碼有三個注意事項:
1.在function_2中,在判斷隊列是否為空的時候,使用的是while(q.empty()),而不是if(q.empty()),這是因為wait()從阻塞到返回,不一定就是由于notify_one()函數(shù)造成的,還有可能由于系統(tǒng)的不確定原因喚醒(可能和條件變量的實現(xiàn)機制有關),這個的時機和頻率都是不確定的,被稱作偽喚醒。如果在錯誤的時候被喚醒了,執(zhí)行后面的語句就會錯誤,所以需要再次判斷隊列是否為空,如果還是為空,就繼續(xù)wait()阻塞;
2.在管理互斥鎖的時候,使用的是std::unique_lock而不是std::lock_guard, 而且事實上也不能使用std::lock_guard。這需要先解釋下wait()函數(shù)所做的事情,可以看到,在wait()函數(shù)之前,使用互斥鎖保護了,如果wait的時候什么都沒做,豈不是一直持有互斥鎖?那生產(chǎn)者也會一直卡住,不能夠將數(shù)據(jù)放入隊列中了。所以,wait()函數(shù)會先調用互斥鎖的unlock()函數(shù),然后再將自己睡眠,在被喚醒后,又會繼續(xù)持有鎖,保護后面的隊列操作。lock_guard沒有l(wèi)ock和unlock接口,而unique_lock提供了,這就是必須使用unique_lock的原因;
3.使用細粒度鎖,盡量減小鎖的范圍,在notify_one()的時候,不需要處于互斥鎖的保護范圍內,所以在喚醒條件變量之前可以將鎖unlock()。

自旋鎖
假設我們有一個兩個處理器core1和core2計算機,現(xiàn)在在這臺計算機上運行的程序中有兩個線程:T1和T2分別在處理器core1和core2上運行,兩個線程之間共享著一個資源。
首先我們說明互斥鎖的工作原理,互斥鎖是是一種sleep-waiting的鎖。假設線程T1獲取互斥鎖并且正在core1上運行時,此時線程T2也想要獲取互斥鎖(pthread_mutex_lock),但是由于T1正在使用互斥鎖使得T2被阻塞。當T2處于阻塞狀態(tài)時,T2被放入到等待隊列中去,處理器core2會去處理其他任務而不必一直等待(忙等)。也就是說處理器不會因為線程阻塞而空閑著,它去處理其他事務去了。
而自旋鎖就不同了,自旋鎖是一種busy-waiting的鎖。也就是說,如果T1正在使用自旋鎖,而T2也去申請這個自旋鎖,此時T2肯定得不到這個自旋鎖。與互斥鎖相反的是,此時運行T2的處理器core2會一直不斷地循環(huán)檢查鎖是否可用(自旋鎖請求),直到獲取到這個自旋鎖為止。
從“自旋鎖”的名字也可以看出來,如果一個線程想要獲取一個被使用的自旋鎖,那么它會一致占用CPU請求這個自旋鎖使得CPU不能去做其他的事情,直到獲取這個鎖為止,這就是“自旋”的含義。
當發(fā)生阻塞時,互斥鎖可以讓CPU去處理其他的任務;而自旋鎖讓CPU一直不斷循環(huán)請求獲取這個鎖。通過兩個含義的對比可以我們知道“自旋鎖”是比較耗費CPU的。
#include
#include
#include
#include
std::atomic_flag lock = ATOMIC_FLAG_INIT;
void f(int n)
{
for (int cnt = 0; cnt < 100; ++cnt) {
while (lock.test_and_set(std::memory_order_acquire)) // 獲得鎖
; // 自旋
std::cout << "Output from thread " << n << 'n';
lock.clear(std::memory_order_release); // 釋放鎖
}
}
int main()
{
std::vector v;
for (int n = 0; n < 10; ++n) {
v.emplace_back(f, n);
}
for (auto& t : v) {
t.join();
}
}
說明:atomic是C++標準程序庫中的一個頭文件,定義了C++11標準中的一些表示線程、并發(fā)控制時原子操作的類與方法等。此頭文件主要聲明了兩大類原子對象:std::atomic和std::atomic_flag。
1、atomic_flag類:是一種簡單的原子布爾類型,只支持兩種操作:test_and_set(flag=true)和clear(flag=false)。
2、std::atomic類模板:std::atomic既不可復制亦不可移動。atomic對int、char、bool等數(shù)據(jù)結構進行了原子性封裝,在多線程環(huán)境中,對std::atomic對象的訪問不會造成競爭-冒險。利用std::atomic可實現(xiàn)數(shù)據(jù)結構的無鎖設計。
所謂的原子操作,取的就是“原子是最小的、不可分割的最小個體”的意義,它表示在多個線程訪問同一個全局資源的時候,能夠確保所有其他的線程都不在同一時間內訪問相同的資源。也就是他確保了在同一時刻只有唯一的線程對這個資源進行訪問。這有點類似互斥對象對共享資源的訪問的保護,但是原子操作更加接近底層,因而效率更高。使用原子操作能大大的提高程序的運行效率。
#include
#include
#include
#include
std::atomic count(0);
void threadFun()
{
for (int i = 0; i < 10000; i++)
count++;
}
int main(void)
{
clock_t start_time = clock();
// 啟動多個線程
std::vector threads;
for (int i = 0; i < 10; i++)
threads.push_back(std::thread(threadFun));
for (auto&thad : threads)
thad.join();
// 檢測count是否正確 10000*10 = 100000
std::cout << "count number:" << count << std::endl;
clock_t end_time = clock();
std::cout << "耗時:" << end_time - start_time << "ms" << std::endl;
return 0;
}
讀寫鎖
先看看互斥鎖,它只有兩個狀態(tài),要么是加鎖狀態(tài),要么是不加鎖狀態(tài)。假如現(xiàn)在一個線程a只是想讀一個共享變量 i,因為不確定是否會有線程去寫它,所以我們還是要對它進行加鎖。但是這時又有一個線程b試圖去讀共享變量 i,發(fā)現(xiàn)被鎖定了,那么b不得不等到a釋放了鎖后才能獲得鎖并讀取 i 的值,但是兩個讀取操作即使是同時發(fā)生的,也并不會像寫操作那樣造成競爭,因為它們不修改變量的值。所以我們期望在多個線程試圖讀取共享變量的時候,它們可以立刻獲取因為讀而加的鎖,而不是需要等待前一個線程釋放。
讀寫鎖可以解決上面的問題。它提供了比互斥鎖更好的并行性。因為以讀模式加鎖后,當有多個線程試圖再以讀模式加鎖時,并不會造成這些線程阻塞在等待鎖的釋放上。
讀寫鎖是多線程同步的另外一個機制。在一些程序中存在讀操作和寫操作問題,對某些資源的訪問會存在兩種可能情況,一種情況是訪問必須是排他的,就是獨占的意思,這種操作稱作寫操作,另外一種情況是訪問方式是可以共享的,就是可以有多個線程同時去訪問某個資源,這種操作稱為讀操作。這個問題模型是從對文件的讀寫操作中引申出來的。把對資源的訪問細分為讀和寫兩種操作模式,這樣可以大大增加并發(fā)效率。讀寫鎖比互斥鎖適用性更高,并行性也更高。
需要注意的是,這里只是說并行效率比互斥高,并不是速度一定比互斥鎖快,讀寫鎖更復雜,系統(tǒng)開銷更大。并發(fā)性好對于用戶體驗非常重要,假設互斥鎖需要0.5秒,使用讀寫鎖需要0.8秒,在類似學生管理系統(tǒng)的軟件中,可能90%的操作都是查詢操作。如果突然有20個查詢請求,使用的是互斥鎖,則最后的查詢請求被滿足需要10秒,估計沒人接收。使用讀寫鎖時,因為讀鎖能多次獲得,所以20個請求中,每個請求都能在1秒左右被滿足,用戶體驗好的多。
讀寫鎖特點
1 如果一個線程用讀鎖鎖定了臨界區(qū),那么其他線程也可以用讀鎖來進入臨界區(qū),這樣可以有多個線程并行操作。這個時候如果再用寫鎖加鎖就會發(fā)生阻塞。寫鎖請求阻塞后,后面繼續(xù)有讀鎖來請求時,這些后來的讀鎖都將會被阻塞。這樣避免讀鎖長期占有資源,防止寫鎖饑餓。
2 如果一個線程用寫鎖鎖住了臨界區(qū),那么其他線程無論是讀鎖還是寫鎖都會發(fā)生阻塞。
頭文件:boost/thread/shared_mutex.cpp
類型:boost::shared_lock
用法:你可以使用boost::shared_ mutex的實例來實現(xiàn)同步,而不是使用std::mutex的實例。對于更新操作,std::lock_guard< boost::shared _mutex>和 std::unique _lock< boost::shared _mutex>可用于鎖定,以取代相應的std::mutex特化。這確保了獨占訪問,就像std::mutex那樣。那些不需要更新數(shù)據(jù)結構的線程能夠轉而使用 boost::shared _lock< boost::shared _mutex>來獲得共享訪問。這與std::unique _lock用起來正是相同的,除了多個線程在同一時間,同一boost::shared _mutex上可能會具有共享鎖。唯一的限制是,如果任意一個線程擁有一個共享鎖,試圖獲取獨占鎖的線程會被阻塞,知道其他線程全都撤回它們的鎖。同樣的,如果一個線程具有獨占鎖,其他線程都不能獲取共享鎖或獨占鎖,直到第一個線程撤回它的鎖。
簡單的說:
shared_lock是read lock。被鎖后仍允許其他線程執(zhí)行同樣被shared_lock的代碼。這是一般做讀操作時的需要。
unique_lock是write lock。被鎖后不允許其他線程執(zhí)行被shared_lock或unique_lock的代碼。在寫操作時,一般用這個,可以同時限制unique_lock的寫和share_lock的讀。
遞歸鎖
std::recursive_mutex 與 std::mutex 一樣,也是一種可以被上鎖的對象,但是和 std::mutex 不同的是,std::recursive_mutex 允許同一個線程對互斥量多次上鎖(即遞歸上鎖),來獲得對互斥量對象的多層所有權,std::recursive_mutex 釋放互斥量時需要調用與該鎖層次深度相同次數(shù)的 unlock(),可理解為 lock() 次數(shù)和 unlock() 次數(shù)相同,除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同。
例如函數(shù)a需要獲取鎖mutex,函數(shù)b也需要獲取鎖mutex,同時函數(shù)a中還會調用函數(shù)b。如果使用std::mutex必然會造成死鎖。但是使用std::recursive_mutex就可以解決這個問題。
1. C++中使用的鎖:mutex
鎖,是生活中應用十分廣泛的一種工具。鎖的本質屬性是為事物提供“訪問保護”,例如:大門上的鎖,是為了保護房子免于不速之客的到訪;自行車的鎖,是為了保護自行車只有owner才可以使用;保險柜上的鎖,是為了保護里面的合同和金錢等重要東西……
在c++等高級編程語言中,鎖也是用來提供“訪問保護”的,不過被保護的東西不再是房子、自行車、金錢,而是內存中的各種變量。此外,計算機領域對于“鎖”有個響亮的名字——mutex(互斥量),學過操作系統(tǒng)的同學對這個名字肯定很熟悉。
Mutex,互斥量,就是互斥訪問的量。這種東東只在多線程編程中起作用,在單線程程序中是沒有什么用處的。從c++11開始,c++提供了std::mutex類型,對于多線程的加鎖操作提供了很好的支持。下面看一個簡單的例子,對于mutex形成一個直觀的認識。
Demo1——無鎖的情況
假定有一個全局變量counter,啟動兩個線程,每個都對該變量自增10000次,最后輸出該變量的值。在第一個demo中,我們不加鎖,代碼文件保存為:mutex_demo1_no_mutex.cpp
#include
#include
#include
#include
#include
int counter = 0;
void increase(int time) {
for (int i = 0; i < time; i++) {
// 當前線程休眠1毫秒
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter++;
}
}
int main(int argc, char** argv) {
std::thread t1(increase, 10000);
std::thread t2(increase, 10000);
t1.join();
t2.join();
std::cout << "counter:" << counter << std::endl;
return 0;
}
為了顯示多線程競爭導致結果不正確的現(xiàn)象,在每次自增操作的時候都讓當前線程休眠1毫秒
對應 CMakeLists.txt
cmake_minimum_required(VERSION 3.0.0)
# 聲明一個 cmake 工程
project(HelloMutex)
# 設置編譯模式
set(CMAKE_BUILD_TYPE "Debug")
# 語法:add_executable( 程序名 源代碼文件 )
add_executable(${PROJECT_NAME} mutex_demo1_no_mutex.cpp)
if(WIN32)
set(PLATFROM_LIBS Ws2_32 mswsock iphlpapi ntdll)
else(WIN32)
set(PLATFROM_LIBS pthread ${CAMKE_DL_LIBS})
endif(WIN32)
# 將庫文件鏈接到可執(zhí)行程序上
target_link_libraries(${PROJECT_NAME} ${PLATFROM_LIBS})
如果沒有多線程編程的相關經(jīng)驗,我們可能想當然的認為最后的counter為20000,如果這樣想的話,那就大錯特錯了。下面是兩次實際運行的結果:
counter:19997
[root@2d129aac5cc5 demo]# ./mutex_demo1_no_mutex
counter:19996
出現(xiàn)上述情況的原因是:自增操作"counter++"不是原子操作,而是由多條匯編指令完成的。多個線程對同一個變量進行讀寫操作就會出現(xiàn)不可預期的操作。以上面的demo1作為例子:假定counter當前值為10,線程1讀取到了10,線程2也讀取到了10,分別執(zhí)行自增操作,線程1和線程2分別將自增的結果寫回counter,不管寫入的順序如何,counter都會是11,但是線程1和線程2分別執(zhí)行了一次自增操作,我們期望的結果是12!!!!!
輪到mutex上場。
Demo2——加鎖的情況
定義一個std::mutex對象用于保護counter變量。對于任意一個線程,如果想訪問counter,首先要進行"加鎖"操作,如果加鎖成功,則進行counter的讀寫,讀寫操作完成后釋放鎖(重要!!!);如果“加鎖”不成功,則線程阻塞,直到加鎖成功。
#include
#include
#include
#include
#include
int counter = 0;
std::mutex mtx; // 保護counter
void increase(int time) {
for (int i = 0; i < time; i++) {
mtx.lock();
// 當前線程休眠1毫秒
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter++;
mtx.unlock();
}
}
int main(int argc, char** argv) {
std::thread t1(increase, 10000);
std::thread t2(increase, 10000);
t1.join();
t2.join();
std::cout << "counter:" << counter << std::endl;
return 0;
}
上述代碼保存文件為:mutex_demo2_with_mutex.cpp。先來看幾次運行結果:
counter:20000
[root@2d129aac5cc5 demo]# ./mutex_demo2_with_mutex
counter:20000
[root@2d129aac5cc5 demo]# ./mutex_demo2_with_mutex
counter:20000
這次運行結果和我們預想的一致,原因就是“利用鎖來保護共享變量”,在這里共享變量就是counter(多個線程都能對其進行訪問,所以就是共享變量啦)。
簡單總結一些std::mutex:
- 對于std::mutex對象,任意時刻最多允許一個線程對其進行上鎖
- mtx.lock():調用該函數(shù)的線程嘗試加鎖。如果上鎖不成功,即:其它線程已經(jīng)上鎖且未釋放,則當前線程block。如果上鎖成功,則執(zhí)行后面的操作,操作完成后要調用mtx.unlock()釋放鎖,否則會導致死鎖的產(chǎn)生
- mtx.unlock():釋放鎖
- std::mutex還有一個操作:mtx.try_lock(),字面意思就是:“嘗試上鎖”,與mtx.lock()的不同點在于:如果上鎖不成功,當前線程不阻塞。
2. lock_guard
雖然std::mutex可以對多線程編程中的共享變量提供保護,但是直接使用std::mutex的情況并不多。因為僅使用std::mutex有時候會發(fā)生死鎖。回到上邊的例子,考慮這樣一個情況:假設線程1上鎖成功,線程2上鎖等待。但是線程1上鎖成功后,拋出異常并退出,沒有來得及釋放鎖,導致線程2“永久的等待下去”(線程2:我的心在等待永遠在等待……),此時就發(fā)生了死鎖。給一個發(fā)生死鎖的 :
Demo3——死鎖的情況(僅僅為了演示,不要這么寫代碼哦)
為了捕捉拋出的異常,我們重新組織一下代碼,代碼保存為:mutex_demo3_dead_lock.cpp。
#include
#include
#include
#include
#include
int counter = 0;
std::mutex mtx; // 保護counter
void increase_proxy(int time, int id) {
for (int i = 0; i < time; i++) {
mtx.lock();
// 線程1上鎖成功后,拋出異常:未釋放鎖
if (id == 1) {
throw std::runtime_error("throw excption....");
}
// 當前線程休眠1毫秒
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter++;
mtx.unlock();
}
}
void increase(int time, int id) {
try {
increase_proxy(time, id);
}
catch (const std::exception& e){
std::cout << "id:" << id << ", " << e.what() << std::endl;
}
}
int main(int argc, char** argv) {
std::thread t1(increase, 10000, 1);
std::thread t2(increase, 10000, 2);
t1.join();
t2.join();
std::cout << "counter:" << counter << std::endl;
return 0;
}
執(zhí)行后,結果如下圖所示:
id:1, throw excption....
程序并沒有退出,而是永遠的“卡”在那里了,也就是發(fā)生了死鎖。
那么這種情況該怎么避免呢?這個時候就需要std::lock_guard登場了。std::lock_guard只有構造函數(shù)和析構函數(shù)。簡單的來說:當調用構造函數(shù)時,會自動調用傳入的對象的lock()函數(shù),而當調用析構函數(shù)時,自動調用unlock()函數(shù)(這就是所謂的RAII,讀者可自行搜索)。我們修改一下demo3。
Demo4——避免死鎖,lock_guard
demo4保存為:mutex_demo4_lock_guard.cpp
#include
#include
#include
#include
#include
int counter = 0;
std::mutex mtx; // 保護counter
void increase_proxy(int time, int id) {
for (int i = 0; i < time; i++) {
// std::lock_guard對象構造時,自動調用mtx.lock()進行上鎖
// std::lock_guard對象析構時,自動調用mtx.unlock()釋放鎖
std::lock_guard lk(mtx);
// 線程1上鎖成功后,拋出異常:未釋放鎖
if (id == 1) {
throw std::runtime_error("throw excption....");
}
// 當前線程休眠1毫秒
std::this_thread::sleep_for(std::chrono::milliseconds(1));
counter++;
}
}
void increase(int time, int id) {
try {
increase_proxy(time, id);
}
catch (const std::exception& e){
std::cout << "id:" << id << ", " << e.what() << std::endl;
}
}
int main(int argc, char** argv) {
std::thread t1(increase, 10000, 1);
std::thread t2(increase, 10000, 2);
t1.join();
t2.join();
std::cout << "counter:" << counter << std::endl;
return 0;
}
執(zhí)行上述代碼,結果為:
id:1, throw excption....
counter:10000
結果符合預期。所以,推薦使用std::mutex和std::lock_guard搭配使用,避免死鎖的發(fā)生。
3. std::lock_guard的第二個構造函數(shù)
實際上,std::lock_guard有兩個構造函數(shù),具體的(參考:cppreference):
lock_guard( mutex_type& m, std::adopt_lock_t t ); (2) (since C++11)
lock_guard( const lock_guard& ) = delete; (3) (since C++11)
在demo4中我們使用了第1個構造函數(shù),第3個為拷貝構造函數(shù),定義為刪除函數(shù)。這里我們來重點說一下第2個構造函數(shù)。
第2個構造函數(shù)有兩個參數(shù),其中第二個參數(shù)類型為:std::adopt_lock_t。這個構造函數(shù)假定:當前線程已經(jīng)上鎖成功,所以不再調用lock()函數(shù),這里不再給出具體的例子。
-
參數(shù)
+關注
關注
11文章
1832瀏覽量
32197 -
函數(shù)
+關注
關注
3文章
4329瀏覽量
62576 -
C++
+關注
關注
22文章
2108瀏覽量
73627 -
線程
+關注
關注
0文章
504瀏覽量
19676
發(fā)布評論請先 登錄
相關推薦
C和C++中const的用法比較
C語言的數(shù)據(jù)基本類型分為哪幾種
C語言數(shù)據(jù)的基本類型
Vulkan API 基本類型介紹
Vulkan API 基本類型 小結

C++可移植性及多線程
C++入門之表達式
C++入門之string
C++的引用和指針
javascript基本類型有哪些
C++中實現(xiàn)類似instanceof的方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論