

關于多進程和多線程,教科書上最經典的一句話是“進程是資源分配的最小單位,線程是CPU調度的最小單位”,這句話應付考試基本上夠了,但如果在工作中遇到類似的選擇問題,那就沒有這么簡單了,選的不好,會讓你深受其害。
經常在網絡上看到有的XDJM問“多進程好還是多線程好?”、“Linux下用多進程還是多線程?”等等期望一勞永逸的問題,我只能說:沒有最好,只有更好。根據實際情況來判斷,哪個更加合適就是哪個好。
我們按照多個不同的維度,來看看多線程和多進程的對比(注:因為是感性的比較,因此都是相對的,不是說一個好得不得了,另外一個差的無法忍受)。
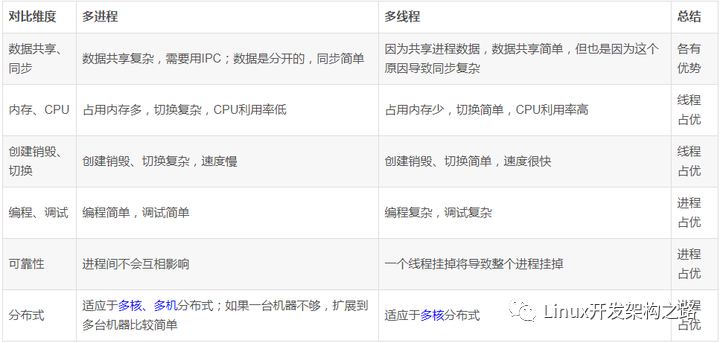
看起來比較簡單,優勢對比上是“線程 3.5 v 2.5 進程”,我們只管選線程就是了?
呵呵,有這么簡單我就不用在這里浪費口舌了,還是那句話,沒有絕對的好與壞,只有哪個更加合適的問題。我們來看實際應用中究竟如何判斷更加合適。
1)需要頻繁創建銷毀的優先用線程
原因請看上面的對比。
這種原則最常見的應用就是Web服務器了,來一個連接建立一個線程,斷了就銷毀線程,要是用進程,創建和銷毀的代價是很難承受的
2)需要進行大量計算的優先使用線程
所謂大量計算,當然就是要耗費很多CPU,切換頻繁了,這種情況下線程是最合適的。
這種原則最常見的是圖像處理、算法處理。
3)強相關的處理用線程,弱相關的處理用進程
什么叫強相關、弱相關?理論上很難定義,給個簡單的例子就明白了。
一般的Server需要完成如下任務:消息收發、消息處理。“消息收發”和“消息處理”就是弱相關的任務,而“消息處理”里面可能又分為“消息解碼”、“業務處理”,這兩個任務相對來說相關性就要強多了。因此“消息收發”和“消息處理”可以分進程設計,“消息解碼”、“業務處理”可以分線程設計。
當然這種劃分方式不是一成不變的,也可以根據實際情況進行調整。
4)可能要擴展到多機分布的用進程,多核分布的用線程
原因請看上面對比。
5)都滿足需求的情況下,用你最熟悉、最拿手的方式
至于“數據共享、同步”、“編程、調試”、“可靠性”這幾個維度的所謂的“復雜、簡單”應該怎么取舍,我只能說:沒有明確的選擇方法。但我可以告訴你一個選擇原則:如果多進程和多線程都能夠滿足要求,那么選擇你最熟悉、最拿手的那個。
需要提醒的是:雖然我給了這么多的選擇原則,但實際應用中基本上都是“進程+線程”的結合方式,千萬不要真的陷入一種非此即彼的誤區。
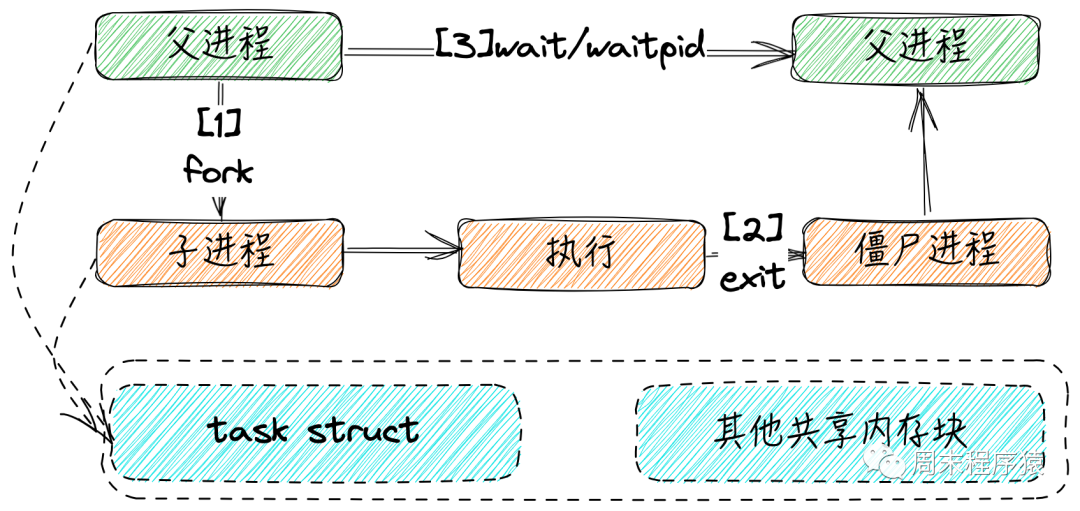
1、進程與線程
進程是程序執行時的一個實例,即它是程序已經執行到課中程度的數據結構的匯集。從內核的觀點看,進程的目的就是擔當分配系統資源(CPU時間、內存等)的基本單位。
線程是進程的一個執行流,是CPU調度和分派的基本單位,它是比進程更小的能獨立運行的基本單位。一個進程由幾個線程組成(擁有很多相對獨立的執行流的用戶程序共享應用程序的大部分數據結構),線程與同屬一個進程的其他的線程共享進程所擁有的全部資源。
"進程——資源分配的最小單位,線程——程序執行的最小單位"
進程有獨立的地址空間,一個進程崩潰后,在保護模式下不會對其它進程產生影響,而線程只是一個進程中的不同執行路徑。線程有自己的堆棧和局部變量,但線程沒有單獨的地址空間,一個線程死掉就等于整個進程死掉,所以多進程的程序要比多線程的程序健壯,但在進程切換時,耗費資源較大,效率要差一些。但對于一些要求同時進行并且又要共享某些變量的并發操作,只能用線程,不能用進程。
總的來說就是:進程有獨立的地址空間,線程沒有單獨的地址空間(同一進程內的線程共享進程的地址空間)。
使用多線程的理由之一是和進程相比,它是一種非常"節儉"的多任務操作方式。我們知道,在Linux系統下,啟動一個新的進程必須分配給它獨立的地址空間,建立眾多的數據表來維護它的代碼段、堆棧段和數據段,這是一種"昂貴"的多任務工作方式。而運行于一個進程中的多個線程,它們彼此之間使用相同的地址空間,共享大部分數據,啟動一個線程所花費的空間遠遠小于啟動一個進程所花費的空間,而且,線程間彼此切換所需的時間也遠遠小于進程間切換所需要的時間。據統計,總的說來,一個進程的開銷大約是一個線程開銷的30倍左右,當然,在具體的系統上,這個數據可能會有較大的區別。
使用多線程的理由之二是線程間方便的通信機制。對不同進程來說,它們具有獨立的數據空間,要進行數據的傳遞只能通過通信的方式進行,這種方式不僅費時,而且很不方便。線程則不然,由于同一進程下的線程之間共享數據空間,所以一個線程的數據可以直接為其它線程所用,這不僅快捷,而且方便。當然,數據的共享也帶來其他一些問題,有的變量不能同時被兩個線程所修改,有的子程序中聲明為static的數據更有可能給多線程程序帶來災難性的打擊,這些正是編寫多線程程序時最需要注意的地方。
除了以上所說的優點外,不和進程比較,多線程程序作為一種多任務、并發的工作方式,當然有以下的優點:
- 提高應用程序響應。這對圖形界面的程序尤其有意義,當一個操作耗時很長時,整個系統都會等待這個操作,此時程序不會響應鍵盤、鼠標、菜單的操作,而使用多線程技術,將耗時長的操作(time consuming)置于一個新的線程,可以避免這種尷尬的情況。
- 使多CPU系統更加有效。操作系統會保證當線程數不大于CPU數目時,不同的線程運行于不同的CPU上。
- 改善程序結構。一個既長又復雜的進程可以考慮分為多個線程,成為幾個獨立或半獨立的運行部分,這樣的程序會利于理解和修改。
在linux上編程采用多線程還是多進程的爭執由來已久,這種爭執最常見到在B/S通訊中服務端并發技術 的選型上,比如WEB服務器技術中,Apache是采用多進程的(perfork模式,每客戶連接對應一個進程,每進程中只存在唯一一個執行線 程)。
從Unix發展歷史看,伴隨著Unix的誕生多進程就出現了,而多線程很晚才被系統支持,例如Linux直到內核2.6,才支持符合Posix規范的NPTL線程庫。進程和線程的特點,也就是各自的優缺點如下:
進程優點:編程、調試簡單,可靠性較高。進程缺點:創建、銷毀、切換速度慢,內存、資源占用大。線程優點:創建、銷毀、切換速度快,內存、資源占用小。線程缺點:編程、調試復雜,可靠性較差。
上面的對比可以歸結為一句話:“線程快而進程可靠性高”。線程有個別名叫“輕量級進程”,在有的書籍資料上介紹線程可以十倍、百倍的效率快于進程;而進程之間不共享數據,沒有鎖問題,結構簡單,一個進程崩潰不像線程那樣影響全局,因此比較可靠。我相信這個觀點可以被大部分人所接受,因為和我們所接受的知識概念是相符的。
在寫這篇文章前,我也屬于這“大部分人”,這兩年在用C語言編寫的幾個C/S通訊程序中,因時間緊總是采用多進程并發技術,而且是比較簡單的現場為 每客戶fork()一個進程,當時總是擔心并發量增大時負荷能否承受,盤算著等時間充裕了將它改為多線程形式,或者改為預先創建進程的形式,直到最近在網上看到了一篇論文《Linux系統下多線程與多進程性能分析》才認真思考這個問題,我自己也做了實驗。
下面是得出結論的實驗步驟和過程,結論究竟是怎樣的?感興趣就一起看看吧。
實驗代碼使用論文中的代碼樣例,做了少量修改,值得注意的是這樣的區別:
論文實驗和我的實驗時間不同,論文所處的年代linux內核是2.4,我的實驗linux內核是2.6,2.6使用的線程庫是NPTL,2.4使用的是老的Linux線程庫(用進程模擬線程的那個LinuxThread)。論文實驗和我用的機器不同,論文描述了使用的環境:單cpu 機器基本配置為:celeron 2.0 GZ, 256M, Linux 9.2,內核 2.4.8。我的環境是:雙核 Intel(R) Xeon(R) CPU 5130 @ 2.00GHz(做實驗時,禁掉了一核),512MG內存,Red Hat Enterprise Linux ES release 4 (Nahant Update 4),內核2.6.9-42。
進程實驗代碼(fork.c):
#include
#include
#define P_NUMBER 255 //并發進程數量
#define COUNT 5 //每次進程打印字符串數
#define TEST_LOGFILE "logFile.log"
FILE *logFile=NULL;
char *s="hello linux?";
int main()
{
int i=0,j=0;
logFile=fopen(TEST_LOGFILE,"a+");//打開日志文件
for(i=0;i {
if(fork()==0)//創建子進程,if(fork()==0){}這段代碼是子進程運行區間
{
for(j=0;j {
printf("[%d]%sn",j,s);//向控制臺輸出
/*當你頻繁讀寫文件的時候,Linux內核為了提高讀寫性能與速度,會將文件在內存中進行緩存,這部分內存就是Cache Memory(緩存內存)。可能導致測試結果不準,所以在此注釋*/
//fprintf(logFile,"[%d]%sn",j,s);//向日志文件輸出,
}
exit(0);//子進程結束
}
}
for(i=0;i {
wait(0);
}
printf("Okayn");
return 0;
};i++)>;j++)
;i++)
線程實驗代碼(thread.c):
#include
#include
#include
#define P_NUMBER 255//并發線程數量
#define COUNT 5 //每線程打印字符串數
#define TEST_LOG "logFile.log"
FILE *logFile=NULL;
char *s="hello linux?";
print_hello_linux()//線程執行的函數
{
int i=0;
for(i=0;i {
printf("[%d]%sn",i,s);//想控制臺輸出
/*當你頻繁讀寫文件的時候,Linux內核為了提高讀寫性能與速度,會將文件在內存中進行緩存,這部分內存就是Cache Memory(緩存內存)。可能導致測試結果不準,所以在此注釋*/
//fprintf(logFile,"[%d]%sn",i,s);//向日志文件輸出
}
pthread_exit(0);//線程結束
}
int main()
{
int i=0;
pthread_t pid[P_NUMBER];//線程數組
logFile=fopen(TEST_LOG,"a+");//打開日志文件
for(i=0;i pthread_create(&pid[i],NULL,(void *)print_hello_linux,NULL);//創建線程
for(i=0;i pthread_join(pid[i],NULL);//回收線程
printf("Okayn");
return 0;
};i++)
;i++)
;i++)
兩段程序做的事情是一樣的,都是創建“若干”個進程/線程,每個創建出的進程/線程打印“若干”條“hello linux”字符串到控制臺和日志文件,兩個“若干”由兩個宏 P_NUMBER和COUNT分別定義,程序編譯指令如下:
gcc -o fork fork.c
gcc -lpthread -o thread thread.c
實驗通過time指令執行兩個程序,抄錄time輸出的掛鐘時間(real時間):
time ./fork
time ./thread
每批次的實驗通過改動宏 P_NUMBER和COUNT來調整進程/線程數量和打印次數,每批次測試五輪,得到的結果如下:
一、重復論文實驗步驟
(注:本文平均值算法采用的是去掉一個最大值去掉一個最小值,然后平均)




本輪實驗是為了和論文作對比,因此將進程/線程數量限制在255個,論文也是測試了255個進程/線程分別進行5次,10 次,50 次,100 次,500 次……10000 次打印的用時,論文得出的結果是:任務量較大時,多進程比多線程效率高;而完成的任務量較小時,多線程比多進程要快,重復打印 600 次時,多進程與多線程所耗費的時間相同。
雖然我的實驗直到1000打印次數時,多進程才開始領先,但考慮到使用的是NPTL線程庫的緣故,從而可以證實了論文的觀點。從我的實驗數據看,多線程和多進程兩組數據非常接近,考慮到數據的提取具有瞬間性,因此可以認為他們的速度是相同的。
是不是可以得出這樣的結論:多線程創建、銷毀速度快,而多線程切換速度快,這個結論我們會在第二個試驗中繼續試圖驗證
當前的網絡環境中,我們更看中高并發、高負荷下的性能,縱觀前面的實驗步驟,最長的實驗周期不過2分鐘多一點,因此下面的實驗將向兩個方向延伸,第一,增加并發數量,第二,增加每進程/線程的工作強度。
二、增加并發數量的實驗
下面的實驗打印次數不變,而進程/線程數量逐漸增加。在實驗過程中多線程程序在后四組(線程數350,500,800,1000)的測試中都出現了“段錯誤”,出現錯誤的原因和多線程預分配線程棧有關。
實驗中的計算機CPU是32位,尋址最大范圍是4GB(2的32次方),Linux是按照3GB/1GB的方式來分配內存,其中1GB屬于所有進程共享的內核空間,3GB屬于用戶空間(進程虛擬內存空間)。Linux2.6的默認線程棧大小是8M(通過ulimit -a查看),對于多線程,在創建線程的時候系統會為每一個線程預分配線程棧地址空間,也就是8M的虛擬內存空間。線程數量太多時,線程棧累計的大小將超過進程虛擬內存空間大小(計算時需要排除程序文本、數據、共享庫等占用的空間),這就是實驗中出現的“段錯誤”的原因。
Linux2.6的默認線程棧大小可以通過 ulimit -s 命令查看或修改,我們可以計算出線程數的最大上線: (1024102410243) / (10241024*8) = 384,實際數字應該略小與384,因為還要計算程序文本、數據、共享庫等占用的空間。在當今的稍顯繁忙的WEB服務器上,突破384的并發訪問并不是稀 罕的事情,要繼續下面的實驗需要將默認線程棧的大小減小,但這樣做有一定的風險,比如線程中的函數分配了大量的自動變量或者函數涉及很深的棧幀(典型的是 遞歸調用),線程棧就可能不夠用了。可以配合使用POSIX.1規定的兩個線程屬性guardsize和stackaddr來解決線程棧溢出問 題,guardsize控制著線程棧末尾之后的一篇內存區域,一旦線程棧在使用中溢出并到達了這片內存,程序可以捕獲系統內核發出的告警信號,然后使用 malloc獲取另外的內存,并通過stackaddr改變線程棧的位置,以獲得額外的棧空間,這個動態擴展棧空間辦法需要手工編程,而且非常麻煩。
有兩種方法可以改變線程棧的大小,使用 ulimit -s 命令改變系統默認線程棧的大小,或者在代碼中創建線程時通過pthread_attr_setstacksize函數改變棧尺寸,在實驗中使用的是第一種,在程序運行前先執行ulimit指令將默認線程棧大小改為1M:
ulimit -s 1024
time ./thread





【實驗結論】
當線程/進程逐漸增多時,執行相同任務時,線程所花費時間相對于進程有下降的趨勢(本人懷疑后兩組數據受系統其他瓶頸的影響),這是不是進一步驗證了多線程創建、銷毀速度快,而多進程切換速度快。
三、增加每進程/線程的工作強度的實驗
這次將程序打印數據增大,原來打印字符串為:
現在修改為每次打印256個字節數據:
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef
1234567890abcdef?";


【實驗結論】
從上面的實驗比對結果看,即使Linux2.6使用了NPTL線程庫,多線程比較多進程在效率上沒有任何的優勢,在線程數增大時多線程程序還出現了運行錯誤,實驗可以得出下面的結論:
在Linux2.6上,多線程并不比多進程速度快,考慮到線程棧的問題,多進程在并發上有優勢。
四、多進程和多線程在創建和銷毀上的效率比較
預先創建進程或線程可以節省進程或線程的創建、銷毀時間,在實際的應用中很多程序使用了這樣的策略,比如Apapche預先創建進程、Tomcat 預先創建線程,通常叫做進程池或線程池。在大部分人的概念中,進程或線程的創建、銷毀是比較耗時的,在stevesn的著作《Unix網絡編程》中有這樣 的對比圖(第一卷 第三版 30章 客戶/服務器程序設計范式):
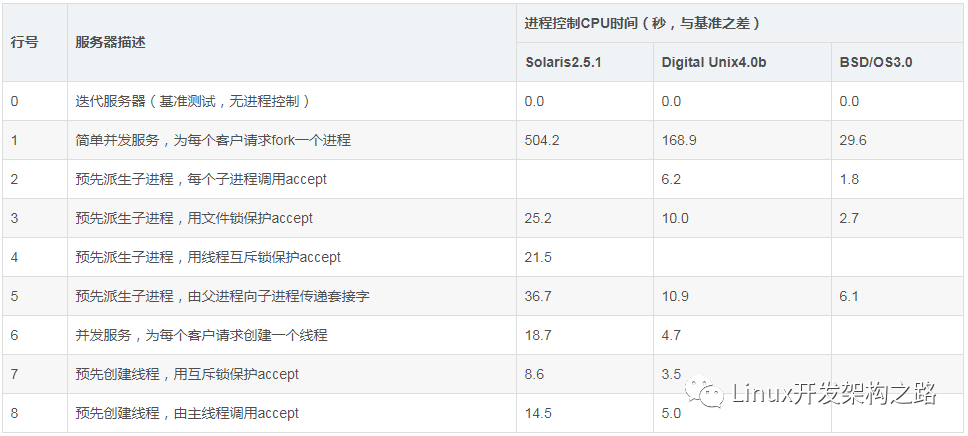
stevens已駕鶴西去多年,但《Unix網絡編程》一書仍具有巨大的影響力,上表中stevens比較了三種服務器上多進程和多線程的執行效 率,因為三種服務器所用計算機不同,表中數據只能縱向比較,而橫向無可比性,stevens在書中提供了這些測試程序的源碼(也可以在網上下載)。書中介 紹了測試環境,兩臺與服務器處于同一子網的客戶機,每個客戶并發5個進程(服務器同一時間最多10個連接),每個客戶請求從服務器獲取4000字節數據, 預先派生子進程或線程的數量是15個。
第0行是迭代模式的基準測試程序,服務器程序只有一個進程在運行(同一時間只能處理一個客戶請求),因為沒有進程或線程的調度切換,因此它的速度是 最快的,表中其他服務模式的運行數值是比迭代模式多出的差值。迭代模式很少用到,在現有的互聯網服務中,DNS、NTP服務有它的影子。第1~5行是多進 程服務模式,期中第1行使用現場fork子進程,2~5行都是預先創建15個子進程模式,在多進程程序中套接字傳遞不太容易(相對于多線 程),stevens在這里提供了4個不同的處理accept的方法。6~8行是多線程服務模式,第6行是現場為客戶請求創建子線程,7~8行是預先創建 15個線程。表中有的格子是空白的,是因為這個系統不支持此種模式,比如當年的BSD不支持線程,因此BSD上多線程的數據都是空白的。
從數據的比對看,現場為每客戶fork一個進程的方式是最慢的,差不多有20倍的速度差異,Solaris上的現場fork和預先創建子進程的最大差別是504.2 :21.5,但我們不能理解為預先創建模式比現場fork快20倍,原因有兩個:
- stevens的測試已是十幾年前的了,現在的OS和CPU已起了翻天覆地的變化,表中的數值需要重新測試。
- stevens沒有提供服務器程序整體的運行計時,我們無法理解504.2 :21.5的實際運行效率,有可能是1504.2 : 1021.5,也可能是100503.2 : 100021.5,20倍的差異可能很大,也可能可以忽略。
因此我寫了下面的實驗程序,來計算在Linux2.6上創建、銷毀10萬個進程/線程的絕對用時。
創建10萬個進程(forkcreat.c):
#include
#include
#include
#include
#include
#include
#include
int count;//子進程創建成功數量
int fcount;//子進程創建失敗數量
int scount;//子進程回收數量
/*信號處理函數–子進程關閉收集*/
void sig_chld(int signo)
{
pid_t chldpid;//子進程id
int stat;//子進程的終止狀態
//子進程回收,避免出現僵尸進程
while((chldpid=wait(&stat)>0))
{
scount++;
}
}
int main()
{
//注冊子進程回收信號處理函數
signal(SIGCHLD,sig_chld);
int i;
for(i=0;i<100000;i++)//fork()10萬個子進程
{
pid_t pid=fork();
if(pid==-1)//子進程創建失敗
{
fcount++;
}
else if(pid>0)//子進程創建成功
{
count++;
}
else if(pid==0)//子進程執行過程
{
exit(0);
}
}
printf("count:%d fount:%d scount:%dn",count,fcount,scount);
}
創建10萬個線程(pthreadcreat.c):
#include
int count=0;//成功創建線程數量
void thread(void)
{
//啥也不做
}
int main(void)
{
pthread_t id;//線程id
int i,ret;
for(i=0;i<100000;i++)//創建10萬個線程
{
ret=pthread_create(&id,NULL,(void *)thread,NULL);
if(ret!=0)
{
printf("Create pthread error!n");
return(1);
}
count++;
pthread_join(id,NULL);
}
printf("count:%dn",count);
}

從數據可以看出,多線程比多進程在效率上有10多倍的優勢,但不能讓我們在使用哪種并發模式上定性,這讓我想起多年前政治課上的一個場景:在講到優越性時,面對著幾個對此發表質疑評論的調皮男生,我們的政治老師發表了高見,“不能只橫向地和當今的發達國家比,你應該縱向地和過去中國幾十年的發展歷史 比”。政治老師的話套用在當前簡直就是真理,我們看看,即使是在賽揚CPU上,創建、銷毀進程/線程的速度都是空前的,可以說是有質的飛躍的,平均創建銷毀一個進程的速度是0.18毫秒,對于當前服務器幾百、幾千的并發量,還有預先派生子進程/線程的必要嗎?
預先派生子進程/線程比現場創建子進程/線程要復雜很多,不僅要對池中進程/線程數量進行動態管理,還要解決多進程/多線程對accept的“搶” 問題,在stevens的測試程序中,使用了“驚群”和“鎖”技術。即使stevens的數據表格中,預先派生線程也不見得比現場創建線程快,在 《Unix網絡編程》第三版中,新作者參照stevens的測試也提供了一組數據,在這組數據中,現場創建線程模式比預先派生線程模式已有了效率上的優勢。因此我對這一節實驗下的結論是:
預先派生進程/線程的模式(進程池、線程池)技術,不僅復雜,在效率上也無優勢,在新的應用中可以放心大膽地為客戶連接請求去現場創建進程和線程。
我想,這是fork迷們最愿意看到的結論了。
五、雙核系統重復論文實驗步驟




【實驗結論】
雙核處理器在完成任務量較少時,沒有系統其他瓶頸因素影響時基本上是單核的兩倍,在任務量較多時,受系統其他瓶頸因素的影響,速度明顯趨近于單核的速度。
六、并發服務的不可測性
看到這里,你會感覺到我有挺進程、貶線程的論調,實際上對于現實中的并發服務具有不可測性,前面的實驗和結論只可做參考,而不可定性。
結束語
本篇文章比較了Linux系統上多線程和多進程的運行效率,在實際應用時還有其他因素的影響,比如網絡通訊時采用長連接還是短連接,是否采用 select、poll,這些都可能影響到并發模式的選型。
-
cpu
+關注
關注
68文章
11031瀏覽量
215924 -
Linux系統
+關注
關注
4文章
603瀏覽量
28288 -
C語言
+關注
關注
180文章
7630瀏覽量
140182 -
Web服務器
+關注
關注
0文章
138瀏覽量
24747 -
多線程
+關注
關注
0文章
279瀏覽量
20296
發布評論請先 登錄
請問如何在Python中實現多線程與多進程的協作?
多線程和多進程的區別
python多線程和多進程對比
LINUX系統下多線程與多進程性能分析
linux多線程編程技術
如何選好多線程和多進程

多進程與多線程的基本概念
淺談Linux網絡編程中的多進程和多線程
關于Python多進程和多線程詳解
你還是分不清多進程和多線程嗎?一文搞懂!
Python中多線程和多進程的區別





 工商網監
工商網監

評論