 什么情況下需要布隆過濾器
什么情況下需要布隆過濾器
什么情況下需要布隆過濾器?
先來看幾個比較常見的例子
字處理軟件中,需要檢查一個英語單詞是否拼寫正確
在 FBI,一個嫌疑人的名字是否已經在嫌疑名單上
在網絡爬蟲里,一個網址是否被訪問過
yahoo, gmail等郵箱垃圾郵件過濾功能
這幾個例子有一個共同的特點:如何判斷一個元素是否存在一個集合中?
常規思路
數組
鏈表
樹、平衡二叉樹、Trie
Map (紅黑樹)
哈希表
雖然上面描述的這幾種數據結構配合常見的排序、二分搜索可以快速高效的處理絕大部分判斷元素是否存在集合中的需求。但是當集合里面的元素數量足夠大,如果有500萬條記錄甚至1億條記錄呢?這個時候常規的數據結構的問題就凸顯出來了。數組、鏈表、樹等數據結構會存儲元素的內容,一旦數據量過大,消耗的內存也會呈現線性增長,最終達到瓶頸。有的同學可能會問,哈希表不是效率很高嗎?查詢效率可以達到O(1)。但是哈希表需要消耗的內存依然很高。使用哈希表存儲一億 個垃圾 email 地址的消耗?哈希表的做法:首先,哈希函數將一個email地址映射成8字節信息指紋;考慮到哈希表存儲效率通常小于50%(哈希沖突);因此消耗的內存:8 * 2 * 1億 字節 = 1.6G 內存,普通計算機是無法提供如此大的內存。這個時候,布隆過濾器(Bloom Filter)就應運而生。在繼續介紹布隆過濾器的原理時,先講解下關于哈希函數的預備知識。
哈希函數
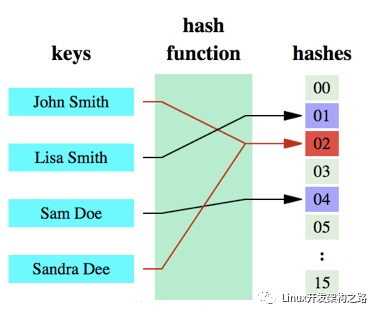
哈希函數的概念是:將任意大小的數據轉換成特定大小的數據的函數,轉換后的數據稱為哈希值或哈希編碼。下面是一幅示意圖:
什么是布隆過濾器?本質上布隆過濾器( BloomFilter )是一種數據結構,比較巧妙的概率型數據結構(probabilistic data structure),特點是高效地插入和查詢,可以用來告訴你 “某樣東西一定不存在或者可能存在”。
相比于傳統的 Set、Map 等數據結構,它更高效、占用空間更少,但是缺點是其返回的結果是概率性的,而不是確切的。
布隆過濾器原理
布隆過濾器內部維護一個bitArray(位數組), 開始所有數據全部置 0 。當一個元素過來時,能過多個哈希函數(hash1,hash2,hash3…)計算不同的在哈希值,并通過哈希值找到對應的bitArray下標處,將里面的值 0 置為 1 。需要說明的是,布隆過濾器有一個誤判率的概念,誤判率越低,則數組越長,所占空間越大。誤判率越高則數組越小,所占的空間越小。
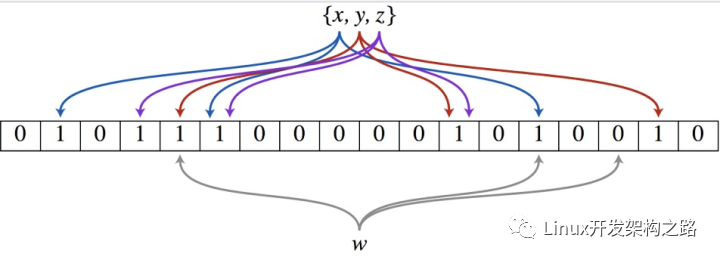
以上圖為例,具體的操作流程:假設集合里面有3個元素{x, y, z},哈希函數的個數為3。首先將位數組進行初始化,將里面每個位都設置位0。對于集合里面的每一個元素,將元素依次通過3個哈希函數進行映射,每次映射都會產生一個哈希值,這個值對應位數組上面的一個點,然后將位數組對應的位置標記為1。查詢W元素是否存在集合中的時候,同樣的方法將W通過哈希映射到位數組上的3個點。如果3個點的其中有一個點不為1,則可以判斷該元素一定不存在集合中。反之,如果3個點都為1,則該元素可能存在集合中。注意:此處不能判斷該元素是否一定存在集合中,可能存在一定的誤判率。可以從圖中可以看到:假設某個元素通過映射對應下標為4,5,6這3個點。雖然這3個點都為1,但是很明顯這3個點是不同元素經過哈希得到的位置,因此這種情況說明元素雖然不在集合中,也可能對應的都是1,這是誤判率存在的原因。## 為什么不直接使用hashtable
Hash table的存儲效率一般只有50%,為了避免碰撞的問題,一般哈希存儲到一半的時候都采取內存翻倍或者其他措施,所以很耗費內存。
Hash面臨的問題就是沖突。假設 Hash 函數是良好的,如果我們的位陣列長度為 m個點,那么如果我們想將沖突率降低到例如 1%, 這個散列表就只能容納 m/100 個元素。解決方法較簡單, 使用k>1的布隆過濾器,即k個函數將每個元素改為對應于k個bits,因為誤判度會降低很多,并且如果參數k和m選取得好,一半的m可被置為1。
布隆過濾器的設計一般會由用戶決定增加元素的個數n和誤差率p,后面的所有參數都由系統來設計。
1.首先根據傳入的n和p計算需要的內存大小m bits:

2.再由m,n得到hash function個數k:

布隆過濾器添加元素
將要添加的元素給k個哈希函數
得到對應于位數組上的k個位置
將這k個位置設為1
布隆過濾器查詢元素
將要查詢的元素給k個哈希函數
得到對應于位數組上的k個位置
如果k個位置有一個為0,則肯定不在集合中
如果k個位置全部為1,則可能在集合中
下圖是Bloomfilter誤判率表:

為每個URL分配兩個字節就可以達到千分之幾的沖突。比較保守的實現是,為每個URL分配4個字節,項目和位數比是1∶32,誤判率是0.00000021167340。對于5000萬數量級的URL,布隆過濾器只占用200MB的空間。
c++代碼:
定義布隆濾波器的結構體
uint8_t cInitFlag; //初始化標志
uint8_t cResv[3];
uint32_t dwMaxItems; //n - BloomFilter中最大元素個數 (輸入量)
double dProbFalse; //p - 假陽概率(誤判率) (輸入量,比如萬分之一:0.00001)
uint32_t dwFilterBits; //m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特數
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函數個數
uint32_t dwSeed; // MurmurHash的種子偏移量
uint32_t dwCount; // Add()的計數,超過MAX_BLOOMFILTER_N則返回失敗
uint32_t dwFilterSize; // dwFilterBits / BYTE_BITS
unsigned char *pstFilter; // BloomFilter存儲指針,使用malloc分配
uint32_t *pdwHashPos; // 存儲上次hash得到的K個bit位置數組(由bloom_hash填充)
}BaseBloomFilter;
定義寫入文件的結構體
uint32_t dwMagicCode; // 文件頭部標識,填充 __MGAIC_CODE__
uint32_t dwSeed;
uint32_t dwCount;
uint32_t dwMaxItems; // n - BloomFilter中最大元素個數 (輸入量)
double dProbFalse; // p - 假陽概率 (輸入量,比如萬分之一:0.00001)
uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特數
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函數個數
uint32_t dwResv[6];
uint32_t dwFileCrc; // (未使用)整個文件的校驗和
uint32_t dwFilterSize; // 后面Filter的Buffer長度
}BloomFileHead;
根據傳入的元素個數n和誤差率p, 計算布隆濾波器的內存大小m bits和hash function個數k:
/**
* n - Number of items in the filter
* p - Probability of false positives, float between 0 and 1 or a number indicating 1-in-p
* m - Number of bits in the filter
* k - Number of hash functions
*
* f = ln(2) × ln(1/2) × m / n = (0.6185) ^ (m/n)
* m = -1*n*ln(p)/((ln(2))^2) = -1*n*ln(p)/(ln(2)*ln(2)) = -1*n*ln(p)/(0.69314718055995*0.69314718055995))
* = -1*n*ln(p)/0.4804530139182079271955440025
* k = ln(2)*m/n
**/
uint32_t m, k, m2;
m =(uint32_t) ceil(-1.0 * n * log(p) / 0.480453);
m = (m - m % 64) + 64; // 8字節對齊
double double_k = (0.69314 *m /n);
k = round(double_k);
*pm = m;
*pk = k;
return;
}
初始化bloomfilter, 根據size分配內存:
* @brief 初始化布隆過濾器
* @param pstBloomfilter 布隆過濾器實例
* @param dwSeed hash種子
* @param dwMaxItems 存儲容量
* @param dProbFalse 允許的誤判率
* @return 返回值
* -1 傳入的布隆過濾器為空
* -2 hash種子錯誤或誤差>=1
*/
inline int InitBloomFilter(BaseBloomFilter *pstBloomfilter, uint32_t dwSeed, uint32_t dwMaxItems, double dProbFalse){
if(pstBloomfilter == NULL)
return -1;
if(dProbFalse <=0 || dProbFalse >= 1)
return -2;
//檢查是否重復Init, 釋放內存
if(pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if(pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
memset(pstBloomfilter, 0, sizeof(pstBloomfilter));
//初始化內存結構,并計算BloomFilter需要的空間
pstBloomfilter->dwMaxItems = dwMaxItems;
pstBloomfilter->dProbFalse = dProbFalse;
pstBloomfilter->dwSeed = dwSeed;
//計算 m, k
_CalcBloomFilterParam(pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse,
&pstBloomfilter->dwFilterBits, &pstBloomfilter->dwHashFuncs);
//分配BloomFilter的存儲空間
pstBloomfilter->dwFilterSize = pstBloomfilter->dwFilterBits / BYTE_BITS;
pstBloomfilter->pstFilter = (unsigned char *)malloc(pstBloomfilter->dwFilterSize);
if(NULL == pstBloomfilter->pstFilter)
return -100;
//哈希結果數組,每個哈希函數一個
pstBloomfilter->pdwHashPos = (uint32_t*)malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if(NULL == pstBloomfilter->pdwHashPos)
return -200;
printf("Init BloomFilter(n=%u, p=%e, m=%u, k=%d), malloc() size=%.6fMB, items:bits=1:%0.1lfn",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024,
pstBloomfilter->dwFilterBits*1.0/pstBloomfilter->dwMaxItems);
// 初始化BloomFilter的內存
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
return 0;
}
釋放內存:
inline int FreeBloomFilter(BaseBloomFilter * pstBloomfilter){
if(pstBloomfilter == NULL)
return -1;
pstBloomfilter->cInitFlag = 0;
pstBloomfilter->dwCount=0;
free(pstBloomfilter->pstFilter);
pstBloomfilter->pstFilter = NULL;
free(pstBloomfilter->pdwHashPos);
pstBloomfilter->pdwHashPos = NULL;
return 0;
}
ResetBloom filter:
inline int RealResetBloomFilter(BaseBloomFilter *pstBloomfilter){
if (pstBloomfilter == NULL)
return -1;
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
pstBloomfilter->dwCount = 0;
return 0;
}
計算hash函數,這里使用的是MurmurHash2:
{
const uint64_t m = 0xc6a4a7935bd1e995;
const int r = 47;
uint64_t h = seed ^ (len * m);
const uint64_t * data = (const uint64_t *)key;
const uint64_t * end = data + (len/8);
while(data != end)
{
uint64_t k = *data++;
k *= m;
k ^= k >> r;
k *= m;
h ^= k;
h *= m;
}
const uint8_t * data2 = (const uint8_t*)data;
switch(len & 7)
{
case 7: h ^= ((uint64_t)data2[6]) << 48;
case 6: h ^= ((uint64_t)data2[5]) << 40;
case 5: h ^= ((uint64_t)data2[4]) << 32;
case 4: h ^= ((uint64_t)data2[3]) << 24;
case 3: h ^= ((uint64_t)data2[2]) << 16;
case 2: h ^= ((uint64_t)data2[1]) << 8;
case 1: h ^= ((uint64_t)data2[0]);
h *= m;
};
h ^= h >> r;
h *= m;
h ^= h >> r;
return h;
}
計算多少個hash函數:
FORCE_INLINE void bloom_hash(BaseBloomFilter *pstBloomfilter, const void * key, int len){
int i;
uint32_t dwFilterBits = pstBloomfilter->dwFilterBits;
uint64_t hash1 = MurmurHash2_x64(key, len, pstBloomfilter->dwSeed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
pstBloomfilter->pdwHashPos[i] = (hash1 + i*hash2) % dwFilterBits;
}
return;
}
向Bloomfilter新增元素:
// 成功返回0,當添加數據超過限制值時返回1提示用戶
FORCE_INLINE int BloomFilter_Add(BaseBloomFilter *pstBloomfilter, const void * key, int len){
if((pstBloomfilter == NULL) || (key == NULL) || (len<=0))
return -1;
int i;
if(pstBloomfilter->cInitFlag != 1){
memset(pstBloomfilter->pstFilter,0 , pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag =1;
}
bloom_hash(pstBloomfilter, key, len);
for(i=0;i<(int)pstBloomfilter->dwHashFuncs; ++i){
SETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]);
}
pstBloomfilter->dwCount++;
if(pstBloomfilter->dwCount <= pstBloomfilter->dwMaxItems)
return 0;
else
return 1;
}
查詢元素:
if((pstBloomfilter == NULL) || (key == NULL) || (len<=0))
return -1;
int i;
bloom_hash(pstBloomfilter, key, len);
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
// 如果有任意bit不為1,說明key不在bloomfilter中
// 注意: GETBIT()返回不是0|1,高位可能出現128之類的情況
if (GETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]) == 0)
return 1;
}
return 0;
}
把bloomfilter保存在文件里:
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
pFile = fopen(szFileName, "wb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// 先寫入文件頭
stFileHeader.dwMagicCode = __MGAIC_CODE__;
stFileHeader.dwSeed = pstBloomfilter->dwSeed;
stFileHeader.dwCount = pstBloomfilter->dwCount;
stFileHeader.dwMaxItems = pstBloomfilter->dwMaxItems;
stFileHeader.dProbFalse = pstBloomfilter->dProbFalse;
stFileHeader.dwFilterBits = pstBloomfilter->dwFilterBits;
stFileHeader.dwHashFuncs = pstBloomfilter->dwHashFuncs;
stFileHeader.dwFilterSize = pstBloomfilter->dwFilterSize;
iRet = fwrite((const void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fwrite(head)");
return -21;
}
// 接著寫入BloomFilter的內容
iRet = fwrite(pstBloomfilter->pstFilter, 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fwrite(data)");
return -31;
}
fclose(pFile);
return 0;
}
讀取文件的bloomfilter:
inline int LoadBloomFilterFromFile(BaseBloomFilter *pstBloomfilter, char *szFileName)
{
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
if (pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if (pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
//
pFile = fopen(szFileName, "rb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// 讀取并檢查文件頭
iRet = fread((void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fread(head)");
return -21;
}
if ((stFileHeader.dwMagicCode != __MGAIC_CODE__)
|| (stFileHeader.dwFilterBits != stFileHeader.dwFilterSize*BYTE_BITS))
return -50;
// 初始化傳入的 BaseBloomFilter 結構
pstBloomfilter->dwMaxItems = stFileHeader.dwMaxItems;
pstBloomfilter->dProbFalse = stFileHeader.dProbFalse;
pstBloomfilter->dwFilterBits = stFileHeader.dwFilterBits;
pstBloomfilter->dwHashFuncs = stFileHeader.dwHashFuncs;
pstBloomfilter->dwSeed = stFileHeader.dwSeed;
pstBloomfilter->dwCount = stFileHeader.dwCount;
pstBloomfilter->dwFilterSize = stFileHeader.dwFilterSize;
pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize);
if (NULL == pstBloomfilter->pstFilter)
return -100;
pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if (NULL == pstBloomfilter->pdwHashPos)
return -200;
// 將后面的Data部分讀入 pstFilter
iRet = fread((void*)(pstBloomfilter->pstFilter), 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fread(data)");
return -31;
}
pstBloomfilter->cInitFlag = 1;
printf("Load BloomFilter(n=%u, p=%f, m=%u, k=%d), malloc() size=%.2fMBn",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024);
fclose(pFile);
return 0;
}
完整的代碼:
#include
#include
#include
#include
#include
#define MAX_ITEMS 6000000 // 設置最大元素個數
#define ADD_ITEMS 10000 // 添加測試元素
#define P_ERROR 0.0001// 設置誤差
#define __BLOOMFILTER_VERSION__ "1.1"
#define __MGAIC_CODE__ (0x01464C42)
/**
* BloomFilter使用例子:
* static BaseBloomFilter stBloomFilter = {0};
*
* 初始化BloomFilter(最大100000元素,不超過0.00001的錯誤率):
* InitBloomFilter(&stBloomFilter, 0, 100000, 0.00001);
* 重置BloomFilter:
* ResetBloomFilter(&stBloomFilter);
* 釋放BloomFilter:
* FreeBloomFilter(&stBloomFilter);
*
* 向BloomFilter中新增一個數值(0-正常,1-加入數值過多):
* uint32_t dwValue;
* iRet = BloomFilter_Add(&stBloomFilter, &dwValue, sizeof(uint32_t));
* 檢查數值是否在BloomFilter內(0-存在,1-不存在):
* iRet = BloomFilter_Check(&stBloomFilter, &dwValue, sizeof(uint32_t));
*
* (1.1新增) 將生成好的BloomFilter寫入文件:
* iRet = SaveBloomFilterToFile(&stBloomFilter, "dump.bin")
* (1.1新增) 從文件讀取生成好的BloomFilter:
* iRet = LoadBloomFilterFromFile(&stBloomFilter, "dump.bin")
**/
#define FORCE_INLINE __attribute__((always_inline))
#define BYTE_BITS (8)
#define MIX_UINT64(v) ((uint32_t)((v>>32)^(v)))
#define SETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] |= (1<<(n%BYTE_BITS)))
#define GETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] &= (1<<(n%BYTE_BITS)))
using namespace std;
#pragma pack(1)
typedef struct{
uint8_t cInitFlag; //初始化標志
uint8_t cResv[3];
uint32_t dwMaxItems; //n - BloomFilter中最大元素個數 (輸入量)
double dProbFalse; //p - 假陽概率(誤判率) (輸入量,比如萬分之一:0.00001)
uint32_t dwFilterBits; //m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特數
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函數個數
uint32_t dwSeed; // MurmurHash的種子偏移量
uint32_t dwCount; // Add()的計數,超過MAX_BLOOMFILTER_N則返回失敗
uint32_t dwFilterSize; // dwFilterBits / BYTE_BITS
unsigned char *pstFilter; // BloomFilter存儲指針,使用malloc分配
uint32_t *pdwHashPos; // 存儲上次hash得到的K個bit位置數組(由bloom_hash填充)
}BaseBloomFilter;
//BloomFilter 文件頭部定義
typedef struct{
uint32_t dwMagicCode; // 文件頭部標識,填充 __MGAIC_CODE__
uint32_t dwSeed;
uint32_t dwCount;
uint32_t dwMaxItems; // n - BloomFilter中最大元素個數 (輸入量)
double dProbFalse; // p - 假陽概率 (輸入量,比如萬分之一:0.00001)
uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特數
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函數個數
uint32_t dwResv[6];
uint32_t dwFileCrc; // (未使用)整個文件的校驗和
uint32_t dwFilterSize; // 后面Filter的Buffer長度
}BloomFileHead;
#pragma pack()
// 計算BloomFilter的參數m,k
static inline void _CalcBloomFilterParam(uint32_t n, double p, uint32_t *pm, uint32_t *pk){
/**
* n - Number of items in the filter
* p - Probability of false positives, float between 0 and 1 or a number indicating 1-in-p
* m - Number of bits in the filter
* k - Number of hash functions
*
* f = ln(2) × ln(1/2) × m / n = (0.6185) ^ (m/n)
* m = -1*n*ln(p)/((ln(2))^2) = -1*n*ln(p)/(ln(2)*ln(2)) = -1*n*ln(p)/(0.69314718055995*0.69314718055995))
* = -1*n*ln(p)/0.4804530139182079271955440025
* k = ln(2)*m/n
**/
uint32_t m, k, m2;
m =(uint32_t) ceil(-1.0 * n * log(p) / 0.480453);
m = (m - m % 64) + 64; // 8字節對齊
double double_k = (0.69314 *m /n);
k = round(double_k);
*pm = m;
*pk = k;
return;
}
// 根據目標精度和數據個數,初始化BloomFilter結構
/**
* @brief 初始化布隆過濾器
* @param pstBloomfilter 布隆過濾器實例
* @param dwSeed hash種子
* @param dwMaxItems 存儲容量
* @param dProbFalse 允許的誤判率
* @return 返回值
* -1 傳入的布隆過濾器為空
* -2 hash種子錯誤或誤差>=1
*/
inline int InitBloomFilter(BaseBloomFilter *pstBloomfilter, uint32_t dwSeed, uint32_t dwMaxItems, double dProbFalse){
if(pstBloomfilter == NULL)
return -1;
if(dProbFalse <=0 || dProbFalse >= 1)
return -2;
//檢查是否重復Init, 釋放內存
if(pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if(pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
memset(pstBloomfilter, 0, sizeof(pstBloomfilter));
//初始化內存結構,并計算BloomFilter需要的空間
pstBloomfilter->dwMaxItems = dwMaxItems;
pstBloomfilter->dProbFalse = dProbFalse;
pstBloomfilter->dwSeed = dwSeed;
//計算 m, k
_CalcBloomFilterParam(pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse,
&pstBloomfilter->dwFilterBits, &pstBloomfilter->dwHashFuncs);
//分配BloomFilter的存儲空間
pstBloomfilter->dwFilterSize = pstBloomfilter->dwFilterBits / BYTE_BITS;
pstBloomfilter->pstFilter = (unsigned char *)malloc(pstBloomfilter->dwFilterSize);
if(NULL == pstBloomfilter->pstFilter)
return -100;
//哈希結果數組,每個哈希函數一個
pstBloomfilter->pdwHashPos = (uint32_t*)malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if(NULL == pstBloomfilter->pdwHashPos)
return -200;
printf("Init BloomFilter(n=%u, p=%e, m=%u, k=%d), malloc() size=%.6fMB, items:bits=1:%0.1lfn",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024,
pstBloomfilter->dwFilterBits*1.0/pstBloomfilter->dwMaxItems);
// 初始化BloomFilter的內存
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
return 0;
}
//釋放bloomfilter
inline int FreeBloomFilter(BaseBloomFilter * pstBloomfilter){
if(pstBloomfilter == NULL)
return -1;
pstBloomfilter->cInitFlag = 0;
pstBloomfilter->dwCount=0;
free(pstBloomfilter->pstFilter);
pstBloomfilter->pstFilter = NULL;
free(pstBloomfilter->pdwHashPos);
pstBloomfilter->pdwHashPos = NULL;
return 0;
}
//重置bloomfilter
inline int ResetBloomFilter(BaseBloomFilter *pstBloomfilter){
if(pstBloomfilter == NULL)
return -1;
pstBloomfilter->cInitFlag =0;
pstBloomfilter->dwCount =0;
return 0;
}
inline int RealResetBloomFilter(BaseBloomFilter *pstBloomfilter){
if (pstBloomfilter == NULL)
return -1;
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
pstBloomfilter->dwCount = 0;
return 0;
}
FORCE_INLINE uint64_t MurmurHash2_x64 ( const void * key, int len, uint32_t seed )
{
const uint64_t m = 0xc6a4a7935bd1e995;
const int r = 47;
uint64_t h = seed ^ (len * m);
const uint64_t * data = (const uint64_t *)key;
const uint64_t * end = data + (len/8);
while(data != end)
{
uint64_t k = *data++;
k *= m;
k ^= k >> r;
k *= m;
h ^= k;
h *= m;
}
const uint8_t * data2 = (const uint8_t*)data;
switch(len & 7)
{
case 7: h ^= ((uint64_t)data2[6]) << 48;
case 6: h ^= ((uint64_t)data2[5]) << 40;
case 5: h ^= ((uint64_t)data2[4]) << 32;
case 4: h ^= ((uint64_t)data2[3]) << 24;
case 3: h ^= ((uint64_t)data2[2]) << 16;
case 2: h ^= ((uint64_t)data2[1]) << 8;
case 1: h ^= ((uint64_t)data2[0]);
h *= m;
};
h ^= h >> r;
h *= m;
h ^= h >> r;
return h;
}
// 雙重散列封裝,k個函數函數, 比如要20個
FORCE_INLINE void bloom_hash(BaseBloomFilter *pstBloomfilter, const void * key, int len){
int i;
uint32_t dwFilterBits = pstBloomfilter->dwFilterBits;
uint64_t hash1 = MurmurHash2_x64(key, len, pstBloomfilter->dwSeed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
// k0 = (hash1 + 0*hash2) % dwFilterBits; // dwFilterBits bit向量的長度
// k1 = (hash1 + 1*hash2) % dwFilterBits;
pstBloomfilter->pdwHashPos[i] = (hash1 + i*hash2) % dwFilterBits;
}
return;
}
// 向BloomFilter中新增一個元素
// 成功返回0,當添加數據超過限制值時返回1提示用戶
FORCE_INLINE int BloomFilter_Add(BaseBloomFilter *pstBloomfilter, const void * key, int len){
if((pstBloomfilter == NULL) || (key == NULL) || (len<=0))
return -1;
int i;
if(pstBloomfilter->cInitFlag != 1){
memset(pstBloomfilter->pstFilter,0 , pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag =1;
}
bloom_hash(pstBloomfilter, key, len);
for(i=0;i<(int)pstBloomfilter->dwHashFuncs; ++i){
SETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]);
}
pstBloomfilter->dwCount++;
if(pstBloomfilter->dwCount <= pstBloomfilter->dwMaxItems)
return 0;
else
return 1;
}
FORCE_INLINE int BloomFilter_Check(BaseBloomFilter *pstBloomfilter, const void * key, int len){
if((pstBloomfilter == NULL) || (key == NULL) || (len<=0))
return -1;
int i;
bloom_hash(pstBloomfilter, key, len);
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
// 如果有任意bit不為1,說明key不在bloomfilter中
// 注意: GETBIT()返回不是0|1,高位可能出現128之類的情況
if (GETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]) == 0)
return 1;
}
return 0;
}
inline int SaveBloomFilterToFile(BaseBloomFilter *pstBloomfilter, char *szFileName){
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
pFile = fopen(szFileName, "wb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// 先寫入文件頭
stFileHeader.dwMagicCode = __MGAIC_CODE__;
stFileHeader.dwSeed = pstBloomfilter->dwSeed;
stFileHeader.dwCount = pstBloomfilter->dwCount;
stFileHeader.dwMaxItems = pstBloomfilter->dwMaxItems;
stFileHeader.dProbFalse = pstBloomfilter->dProbFalse;
stFileHeader.dwFilterBits = pstBloomfilter->dwFilterBits;
stFileHeader.dwHashFuncs = pstBloomfilter->dwHashFuncs;
stFileHeader.dwFilterSize = pstBloomfilter->dwFilterSize;
iRet = fwrite((const void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fwrite(head)");
return -21;
}
// 接著寫入BloomFilter的內容
iRet = fwrite(pstBloomfilter->pstFilter, 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fwrite(data)");
return -31;
}
fclose(pFile);
return 0;
}
// 從文件讀取生成好的BloomFilter
inline int LoadBloomFilterFromFile(BaseBloomFilter *pstBloomfilter, char *szFileName)
{
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
if (pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if (pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
//
pFile = fopen(szFileName, "rb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// 讀取并檢查文件頭
iRet = fread((void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fread(head)");
return -21;
}
if ((stFileHeader.dwMagicCode != __MGAIC_CODE__)
|| (stFileHeader.dwFilterBits != stFileHeader.dwFilterSize*BYTE_BITS))
return -50;
// 初始化傳入的 BaseBloomFilter 結構
pstBloomfilter->dwMaxItems = stFileHeader.dwMaxItems;
pstBloomfilter->dProbFalse = stFileHeader.dProbFalse;
pstBloomfilter->dwFilterBits = stFileHeader.dwFilterBits;
pstBloomfilter->dwHashFuncs = stFileHeader.dwHashFuncs;
pstBloomfilter->dwSeed = stFileHeader.dwSeed;
pstBloomfilter->dwCount = stFileHeader.dwCount;
pstBloomfilter->dwFilterSize = stFileHeader.dwFilterSize;
pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize);
if (NULL == pstBloomfilter->pstFilter)
return -100;
pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if (NULL == pstBloomfilter->pdwHashPos)
return -200;
// 將后面的Data部分讀入 pstFilter
iRet = fread((void*)(pstBloomfilter->pstFilter), 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fread(data)");
return -31;
}
pstBloomfilter->cInitFlag = 1;
printf("Load BloomFilter(n=%u, p=%f, m=%u, k=%d), malloc() size=%.2fMBn",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024);
fclose(pFile);
return 0;
}
int main()
{
printf(" test bloomfiltern");
static BaseBloomFilter stBloomFilter = {0};
InitBloomFilter(&stBloomFilter, 0, MAX_ITEMS, P_ERROR);
char url[128] = {0};
for(int i = 0; i < ADD_ITEMS; i++){
sprintf(url, "https://0voice.com/%d.html", i);
if(0 == BloomFilter_Add(&stBloomFilter, (const void*)url, strlen(url))){
// printf("add %s success", url);
}else{
printf("add %s failed", url);
}
memset(url, 0, sizeof(url));
}
// 4. check url exist or not
char* str = "https://0voice.com/0.html";
if (0 == BloomFilter_Check(&stBloomFilter, (const void*)str, strlen(str)) ){
printf("https://0voice.com/0.html existn");
}
char* str2 = "https://0voice.com/10001.html";
if (0 != BloomFilter_Check(&stBloomFilter, (const void*)str2, strlen(str2)) ){
printf("https://0voice.com/10001.html not existn");
}
char * file = "testBloom.txt";
if(SaveBloomFilterToFile(&stBloomFilter, file) == 0)
printf("file save in %sn", file);
else
printf("file can't exitn");
//cout << "Hello world!" << endl;
if(0 == LoadBloomFilterFromFile(&stBloomFilter, file))
printf("read successn");
else
printf("read failuren");
FreeBloomFilter(&stBloomFilter);
getchar();
return 0;
}
-
函數
+關注
關注
3文章
4327瀏覽量
62569 -
數據結構
+關注
關注
3文章
573瀏覽量
40123 -
過濾器
+關注
關注
1文章
428瀏覽量
19593
發布評論請先 登錄
相關推薦
一文理解布隆過濾器和布谷鳥過濾器
一種隱私保護的可逆布魯姆過濾器PPIBF設計
過濾器的作用
如何使用計數型布隆過濾器進行可排序密文檢索的方法概述
解密高效空氣過濾器的性能及要求
過濾器的應用有哪些
Google在Play商店中推出搜索過濾器
絲扣Y過濾器
絲扣Y過濾器及過濾器測試原理簡介
漢克森過濾器系列介紹


一文解析布隆過濾器設計原理








 工商網監
工商網監
評論