


一、 粘包問題概述
1、描述背景
采用TCP協議進行網絡數據傳送的軟件設計中,普遍存在粘包問題。這主要是由于現代操作系統的網絡傳輸機制所產生的。我們知道,網絡通信采用的套接字(socket)技術,其實現實際是由系統內核提供一片連續緩存(流緩沖)來實現應用層程序與網卡接口之間的中轉功能。多個數據包被連續存儲于連續的緩存中,在對數據包進行讀取時由于無法確定發生方的發送邊界,而采用某一估測值大小來進行數據讀出,若雙方的size不一致時就會使數據包的邊界發生錯位,導致讀出錯誤的數據分包,進而曲解原始數據含義。
2、粘包的概念
粘包問題的本質就是數據讀取邊界錯誤所致,通過下圖可以形象地理解其現象。
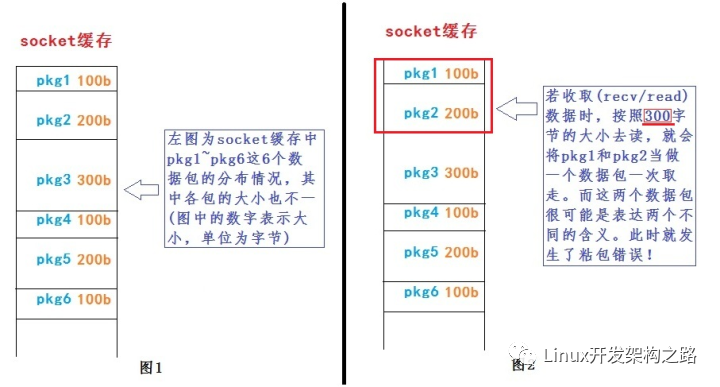
如圖1所示,當前的socket緩存中已經有6個數據分組到達,其大小如圖中數字。而應用程序在對數據進行收取時(如圖2),采用了300字節的要求去讀取,則會誤將pkg1和pkg2一起收走當做一個包來處理。而實際上,很可能pkg1是一個文本文件的內容,而pkg2則可能是一個音頻內容,這風馬牛不相及的兩個數據包卻被揉進一個包進行處理,顯然有失妥當。嚴重時可能因為丟了pkg2而導致軟件陷入異常分支產生烏龍事件。
因此,粘包問題必須引起所有軟件設計者(項目經理)的高度重視!
那么,或許會有讀者發問,為何不讓接收程序按照100字節來讀取呢?我想如果您了解一些TCP編程的話就不會有這樣的問題。網絡通信程序中,數據包通常是不能確定大小的,尤其在軟件設計階段無法真的做到確定為一個固定值。比如聊天軟件客戶端若采用TCP傳輸一個用戶名和密碼到服務端進行驗證登陸,我想這個數據包不過是幾十字節,至多幾百字節即可發送完畢,而有時候要傳輸一個很大的視頻文件,即使分包發送也應該一個包在幾千字節吧。(據說,某國電信平臺的MW中見到過一次發送1.5萬字節的電話數據)這種情況下,發送數據的分包大小無法固定,接收端也就無法固定。所以一般采用一個較為合理的預估值進行輪詢接收。(網卡的MTU都是1500字節,因此這個預估值一般為MTU的1~3倍)。
相信讀者對粘包問題應該有了初步認識了。
二、粘包回避設計
設計方案一:定長發送
在進行數據發送時采用固定長度的設計,也就是無論多大數據發送都分包為固定長度(為便于描述,此處定長為記為LEN),也就是發送端在發送數據時都以LEN為長度進行分包。這樣接收方都以固定的LEN進行接收,如此一來發送和接收就能一一對應了。分包的時候不一定能完整的恰好分成多個完整的LEN的包,最后一個包一般都會小于LEN,這時候最后一個包可以在不足的部分填充空白字節。
當然,這種方法會有缺陷。1.最后一個包的不足長度被填充為空白部分,也即無效字節序。那么接收方可能難以辨別這無效的部分,它本身就是為了補位的,并無實際含義。這就為接收端處理其含義帶來了麻煩。當然也有解決辦法,可以通過增添標志位的方法來彌補,即在每一個數據包的最前面增加一個定長的報頭,然后將該數據包的末尾標記一并發送。接收方根據這個標記確認無效字節序列,從而實現數據的完整接收。2.在發送包長度隨機分布的情況下,會造成帶寬浪費。比如發送長度可能為 1,100,1000,4000字節等等,則都需要按照定長最大值即4000來發送,數據包小于4000字節的其他包也會被填充至4000,造成網絡負載的無效浪費。
綜上,此方案適在發送數據包長度較為穩定(趨于某一固定值)的情況下有較好的效果。
設計方案二:尾部標記序列
在每個要發送的數據包的尾部設置一個特殊的字節序列,此序列帶有特殊含義,跟字符串的結束符標識”?”一樣的含義,用來標示這個數據包的末尾,接收方可對接收的數據進行分析,通過尾部序列確認數據包的邊界。
這種方法的缺陷較為明顯:1.接收方需要對數據進行分析,甄別尾部序列。2.尾部序列的確定本身是一個問題。什么樣的序列可以向”?”一樣來做一個結束符呢?這個序列必須是不具備通常任何人類或者程序可識別的帶含義的數據序列,就像“?”是一個無效字符串內容,因而可以作為字符串的結束標記。那普通的網絡通信中,這個序列是什么呢?我想一時間很難找到恰當的答案。
設計方案三:頭部標記分步接收
這個方法是作者有限學識里最好的辦法了。它既不損失效率,還完美解決了任何大小的數據包的邊界問題。
這個方法的實現是這樣的,定義一個用戶報頭,在報頭中注明每次發送的數據包大小。接收方每次接收時先以報頭的size進行數據讀取,這必然只能讀到一個報頭的數據,從報頭中得到該數據包的數據大小,然后再按照此大小進行再次讀取,就能讀到數據的內容了。這樣一來,每個數據包發送時都封裝一個報頭,然后接收方分兩次接收一個包,第一次接收報頭,根據報頭大小第二次才接收數據內容。(此處的data[0]的本質是一個指針,指向數據的正文部分,也可以是一篇連續數據區的起始位置。因此可以設計成data[user_size],這樣的話。)
下面通過一個圖來展現設計思想。

由圖看出,數據發送多了封裝報頭的動作;接收方將每個包的接收拆分成了兩次。
這方案看似精妙,實則也有缺陷:1.報頭雖小,但每個包都需要多封裝sizeof(_data_head)的數據,積累效應也不可完全忽略。2.接收方的接收動作分成了兩次,也就是進行數據讀取的操作被增加了一倍,而數據讀取操作的recv或者read都是系統調用,這對內核而言的開銷是一個不能完全忽略的影響,對程序而言性能影響可忽略(系統調用的速度非常快)。
優點:避免了程序設計的復雜性,其有效性便于驗證,對軟件設計的穩定性要求來說更容易達標。綜上,方案三乃上策!
補充:
什么時候需要考慮粘包問題?
1:如果利用tcp每次發送數據,就與對方建立連接,然后雙方發送完一段數據后,就關閉連接,這樣就不會出現粘包問題(因為只有一種包結構,類似于http協議)。關閉連接主要要雙方都發送close連接(參考tcp關閉協議)。如:A需要發送一段字符串給B,那么A與B建立連接,然后發送雙方都默認好的協議字符如"hello give me sth abour yourself",然后B收到報文后,就將緩沖區數據接收,然后關閉連接,這樣粘包問題不用考慮到,因為大家都知道是發送一段字符。
2:如果發送數據無結構,如文件傳輸,這樣發送方只管發送,接收方只管接收存儲就ok,也不用考慮粘包
3:如果雙方建立連接,需要在連接后一段時間內發送不同結構數據,如連接后,有好幾種結構:
1)"hello give me sth abour yourself"
2)"Don't give me sth abour yourself"
那這樣的話,如果發送方連續發送這個兩個包出去,接收方一次接收可能會是"hello give me sth abour yourselfDon't give me sth abour yourself" 這樣接收方就傻了,到底是要干嘛?不知道,因為協議沒有規定這么詭異的字符串,所以要處理把它分包,怎么分也需要雙方組織一個比較好的包結構,所以一般可能會在頭加一個數據長度之類的包,以確保接收。
粘包出現原因:在流傳輸中出現,UDP不會出現粘包,因為它有消息邊界
1 發送端需要等緩沖區滿才發送出去,造成粘包 2 接收方不及時接收緩沖區的包,造成多個包接收
解決辦法:
為了避免粘包現象,可采取以下幾種措施。
- 一是對于發送方引起的粘包現象,用戶可通過編程設置來避免,TCP提供了強制數據立即傳送的操作指令push,TCP軟件收到該操作指令后,就立即將本段數據發送出去,而不必等待發送緩沖區滿;
- 二是對于接收方引起的粘包,則可通過優化程序設計、精簡接收進程工作量、提高接收進程優先級等措施,使其及時接收數據,從而盡量避免出現粘包現象;
- 三是由接收方控制,將一包數據按結構字段,人為控制分多次接收,然后合并,通過這種手段來避免粘包。
以上提到的三種措施,都有其不足之處。第一種編程設置方法雖然可以避免發送方引起的粘包,但它關閉了優化算法,降低了網絡發送效率,影響應用程序的性能,一般不建議使用。第二種方法只能減少出現粘包的可能性,但并不能完全避免粘包,當發送頻率較高時,或由于網絡突發可能使某個時間段數據包到達接收方較快,接收方還是有可能來不及接收,從而導致粘包。第三種方法雖然避免了粘包,但應用程序的效率較低,對實時應用的場合不適合。
為什么基于TCP的通訊程序需要進行封包和拆包
TCP是個"流"協議,所謂流,就是沒有界限的一串數據.大家可以想想河里的流水,是連成一片的,其間是沒有分界線的.但一般通訊程序開發是需要定義一個個相互獨立的數據包的,比如用于登陸的數據包,用于注銷的數據包.由于TCP"流"的特性以及網絡狀況,在進行數據傳輸時會出現以下幾種情況.
假設我們連續調用兩次send分別發送兩段數據data1和data2,在接收端有以下幾種接收情況(當然不止這幾種情況,這里只列出了有代表性的情況). A.先接收到data1,然后接收到data2. B.先接收到data1的部分數據,然后接收到data1余下的部分以及data2的全部. C.先接收到了data1的全部數據和data2的部分數據,然后接收到了data2的余下的數據. D.一次性接收到了data1和data2的全部數據.
對于A這種情況正是我們需要的,不再做討論.對于B,C,D的情況就是大家經常說的"粘包",就需要我們把接收到的數據進行拆包,拆成一個個獨立的數據包.為了拆包就必須在發送端進行封包.
另:對于UDP來說就不存在拆包的問題,因為UDP是個"數據包"協議,也就是兩段數據間是有界限的,在接收端要么接收不到數據要么就是接收一個完整的一段數據,不會少接收也不會多接收.
為什么會出現B.C.D的情況
"粘包"可發生在發送端也可發生在接收端.
1.由Nagle算法造成的發送端的粘包:Nagle算法是一種改善網絡傳輸效率的算法.簡單的說,當我們提交一段數據給TCP發送時,TCP并不立刻發送此段數據,而是等待一小段時間,看看在等待期間是否還有要發送的數據,若有則會一次把這兩段數據發送出去.這是對Nagle算法一個簡單的解釋,詳細的請看相關書籍.象C和D的情況就有可能是Nagle算法造成的.
2.接收端接收不及時造成的接收端粘包:TCP會把接收到的數據存在自己的緩沖區中,然后通知應用層取數據.當應用層由于某些原因不能及時的把TCP的數據取出來,就會造成TCP緩沖區中存放了幾段數據.
怎樣封包和拆包
最初遇到"粘包"的問題時,我是通過在兩次send之間調用sleep來休眠一小段時間來解決.這個解決方法的缺點是顯而易見的,使傳輸效率大大降低,而且也并不可靠.后來就是通過應答的方式來解決,盡管在大多數時候是可行的,但是不能解決象B的那種情況,而且采用應答方式增加了通訊量,加重了網絡負荷. 再后來就是對數據包進行封包和拆包的操作.
封包: 封包就是給一段數據加上包頭,這樣一來數據包就分為包頭和包體兩部分內容了(以后講過濾非法包時封包會加入"包尾"內容).包頭其實上是個大小固定的結構體,其中有個結構體成員變量表示包體的長度,這是個很重要的變量,其他的結構體成員可根據需要自己定義.根據包頭長度固定以及包頭中含有包體長度的變量就能正確的拆分出一個完整的數據包.
對于拆包目前我最常用的是以下兩種方式. 1.動態緩沖區暫存方式.之所以說緩沖區是動態的是因為當需要緩沖的數據長度超出緩沖區的長度時會增大緩沖區長度. 大概過程描述如下: A,為每一個連接動態分配一個緩沖區,同時把此緩沖區和SOCKET關聯,常用的是通過結構體關聯. B,當接收到數據時首先把此段數據存放在緩沖區中. C,判斷緩存區中的數據長度是否夠一個包頭的長度,如不夠,則不進行拆包操作. D,根據包頭數據解析出里面代表包體長度的變量. E,判斷緩存區中除包頭外的數據長度是否夠一個包體的長度,如不夠,則不進行拆包操作. F,取出整個數據包.這里的"取"的意思是不光從緩沖區中拷貝出數據包,而且要把此數據包從緩存區中刪除掉.刪除的辦法就是把此包后面的數據移動到緩沖區的起始地址.
這種方法有兩個缺點.1.為每個連接動態分配一個緩沖區增大了內存的使用.2.有三個地方需要拷貝數據,一個地方是把數據存放在緩沖區,一個地方是把完整的數據包從緩沖區取出來,一個地方是把數據包從緩沖區中刪除.第二種拆包的方法會解決和完善這些缺點.
前面提到過這種方法的缺點.下面給出一個改進辦法, 即采用環形緩沖.但是這種改進方法還是不能解決第一個缺點以及第一個數據拷貝,只能解決第三個地方的數據拷貝(這個地方是拷貝數據最多的地方).第2種拆包方式會解決這兩個問題. 環形緩沖實現方案是定義兩個指針,分別指向有效數據的頭和尾.在存放數據和刪除數據時只是進行頭尾指針的移動.
2.利用底層的緩沖區來進行拆包 由于TCP也維護了一個緩沖區,所以我們完全可以利用TCP的緩沖區來緩存我們的數據,這樣一來就不需要為每一個連接分配一個緩沖區了.另一方面我們知道recv或者wsarecv都有一個參數,用來表示我們要接收多長長度的數據.利用這兩個條件我們就可以對第一種方法進行優化. 對于阻塞SOCKET來說,我們可以利用一個循環來接收包頭長度的數據,然后解析出代表包體長度的那個變量,再用一個循環來接收包體長度的數據. 相關代碼如下:
char PackageHead[1024];
char PackageContext[1024*20];
int len;
PACKAGE_HEAD *pPackageHead;
while( m_bClose == false )
{
memset(PackageHead,0,sizeof(PACKAGE_HEAD));
len = m_TcpSock.ReceiveSize((char*)PackageHead,sizeof(PACKAGE_HEAD));
if( len == SOCKET_ERROR )
{
break;
}
if(len == 0)
{
break;
}
pPackageHead = (PACKAGE_HEAD *)PackageHead;
memset(PackageContext,0,sizeof(PackageContext));
if(pPackageHead- >nDataLen >0)
{
len = m_TcpSock.ReceiveSize((char*)PackageContext,pPackageHead- >nDataLen);
}
}
m_TcpSock是一個封裝了SOCKET的類的變量,其中的ReceiveSize用于接收一定長度的數據,直到接收了一定長度的數據或者網絡出錯才返回.
int winSocket::ReceiveSize( char* strData, int iLen )
{
if( strData == NULL )
return ERR_BADPARAM;
char *p = strData;
int len = iLen;
int ret = 0;
int returnlen = 0;
while( len > 0)
{
ret = recv( m_hSocket, p+(iLen-len), iLen-returnlen, 0 );
if ( ret == SOCKET_ERROR || ret == 0 )
{
return ret;
}
len -= ret;
returnlen += ret;
}
return returnlen;
}
對于非阻塞的SOCKET,比如完成端口,我們可以提交接收包頭長度的數據的請求,當 GetQueuedCompletionStatus返回時,我們判斷接收的數據長度是否等于包頭長度,若等于,則提交接收包體長度的數據的請求,若不等于則提交接收剩余數據的請求.當接收包體時,采用類似的方法.
-
操作系統
+關注
關注
37文章
7168瀏覽量
125770 -
緩存
+關注
關注
1文章
246瀏覽量
27280 -
數據包
+關注
關注
0文章
269瀏覽量
25019 -
TCP通信
+關注
關注
0文章
146瀏覽量
4567
發布評論請先 登錄
嵌入式TCP/IP協議單片機技術在網絡通信中的應用
lwip tcp丟包的原因?
labview通信中如果有通信協議,如何處理通信中傳輸的協議數據?
tcp通信中,在不知道tcp讀取字節數多少的情況下,應該如何設定tcp讀取的字節數?
為什么stm32107lwip+modbus tcp通信中會提示傳輸id錯誤?
TCP/IP協議單片機在網絡通信中的數據傳輸技術
TCP粘包到底是什么
【推薦】TCP為何粘包?粘包問題如何解決?

tcp丟包究竟會帶來多大的性能問題
TCP粘包和拆包產生的原因






 工商網監
工商網監

評論