 進程寫文件會丟失數據嗎
進程寫文件會丟失數據嗎
進程寫文件(使用緩沖 IO)過程中,寫一半的時候,進程發生了崩潰,會丟失數據嗎?
答案,是不會的。
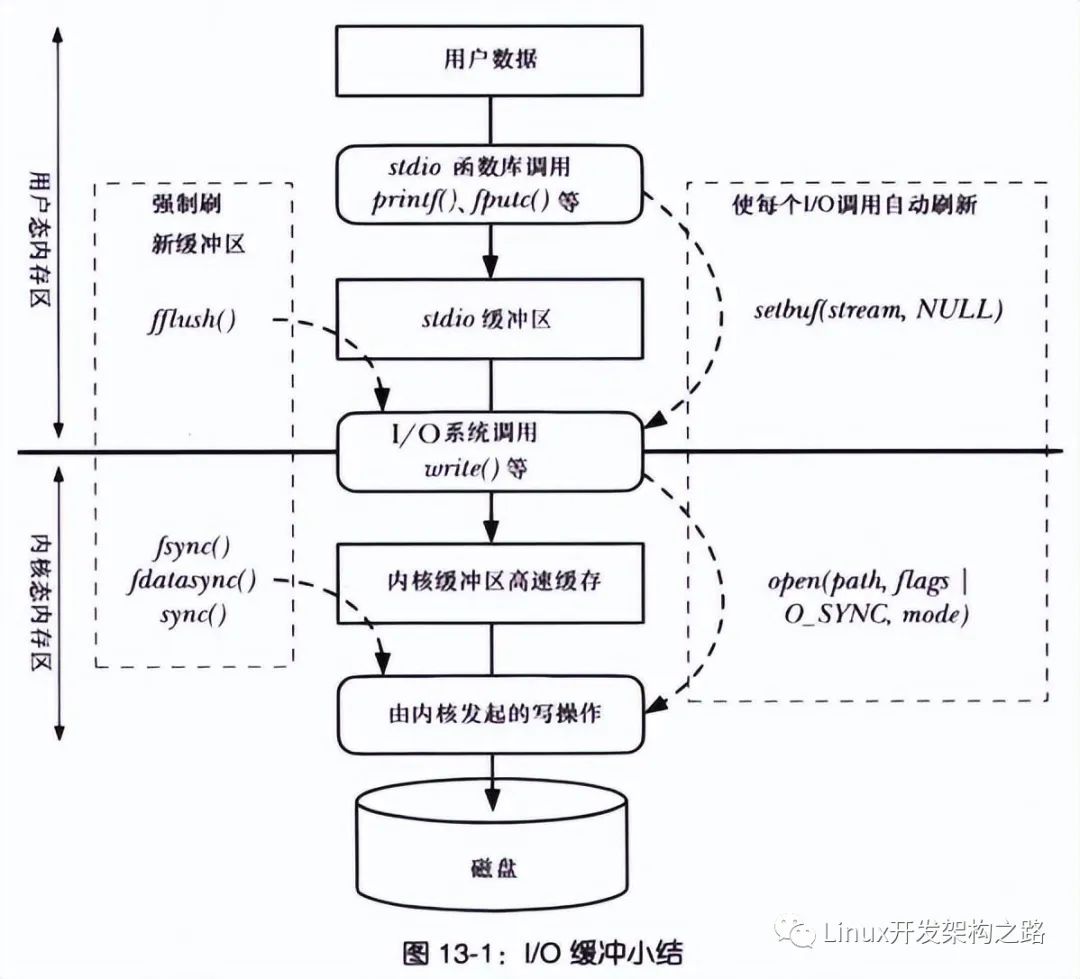
因為進程在執行 write (使用緩沖 IO)系統調用的時候,實際上是將文件數據寫到了內核的 page cache,它是文件系統中用于緩存文件數據的緩沖,所以即使進程崩潰了,文件數據還是保留在內核的 page cache,我們讀數據的時候,也是從內核的 page cache 讀取,因此還是依然讀的進程崩潰前寫入的數據。
內核會找個合適的時機,將 page cache 中的數據持久化到磁盤。但是如果 page cache 里的文件數據,在持久化到磁盤化到磁盤之前,系統發生了崩潰,那這部分數據就會丟失了。
當然, 我們也可以在程序里調用 fsync 函數,在寫文文件的時候,立刻將文件數據持久化到磁盤,這樣就可以解決系統崩潰導致的文件數據丟失的問題。
- Page Cache
1.1 Page Cache 是什么?
為了理解 Page Cache,我們不妨先看一下 Linux 的文件 I/O 系統,如下圖所示:
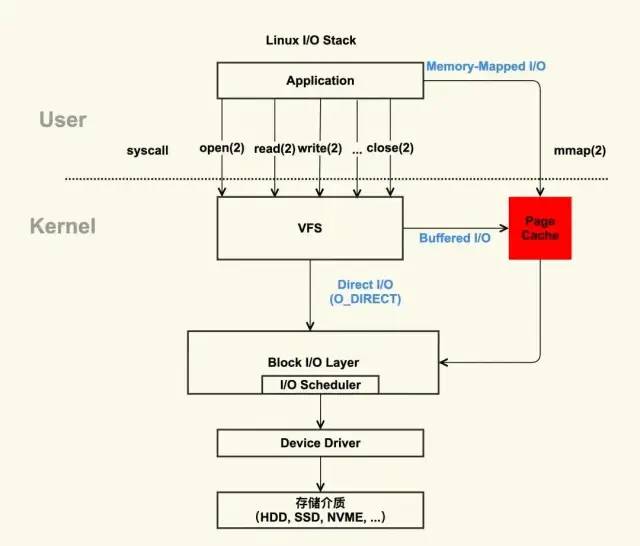
Figure1. Linux 文件 I/O 系統
上圖中,紅色部分為 Page Cache。可見 Page Cache 的本質是由 Linux 內核管理的內存區域。我們通過 mmap 以及 buffered I/O 將文件讀取到內存空間實際上都是讀取到 Page Cache 中。
1.2 如何查看系統的 Page Cache?
通過讀取 /proc/meminfo 文件,能夠實時獲取系統內存情況:
$ cat /proc/meminfo
...
Buffers: 1224 kB
Cached: 111472 kB
SwapCached: 36364 kB
Active: 6224232 kB
Inactive: 979432 kB
Active(anon): 6173036 kB
Inactive(anon): 927932 kB
Active(file): 51196 kB
Inactive(file): 51500 kB
...
Shmem: 10000 kB
...
SReclaimable: 43532 kB
...
根據上面的數據,你可以簡單得出這樣的公式(等式兩邊之和都是 112696 KB):
Buffers + Cached + SwapCached = Active(file) + Inactive(file) + Shmem + SwapCached
兩邊等式都是 Page Cache,即:
Page Cache = Buffers + Cached + SwapCached
通過閱讀 1.4 以及 1.5 小節,就能夠理解為什么 SwapCached 與 Buffers 也是 Page Cache 的一部分。
1.3 page 與 Page Cache
page 是內存管理分配的基本單位, Page Cache 由多個 page 構成。page 在操作系統中通常為 4KB 大小(32bits/64bits),而 Page Cache 的大小則為 4KB 的整數倍。
另一方面,并不是所有 page 都被組織為 Page Cache。
Linux 系統上供用戶可訪問的內存分為兩個類型[2],即:
- File-backed pages:文件備份頁也就是 Page Cache 中的 page,對應于磁盤上的若干數據塊;對于這些頁最大的問題是臟頁回盤;
- Anonymous pages:匿名頁不對應磁盤上的任何磁盤數據塊,它們是進程的運行是內存空間(例如方法棧、局部變量表等屬性);
為什么 Linux 不把 Page Cache 稱為 block cache,這不是更好嗎?
這是因為從磁盤中加載到內存的數據不僅僅放在 Page Cache 中,還放在 buffer cache 中。例如通過 Direct I/O 技術的磁盤文件就不會進入 Page Cache 中。當然,這個問題也有 Linux 歷史設計的原因,畢竟這只是一個稱呼,含義隨著 Linux 系統的演進也逐漸不同。
下面比較一下 File-backed pages 與 Anonymous pages 在 Swap 機制下的性能。
內存是一種珍惜資源,當內存不夠用時,內存管理單元(Memory Mangament Unit)需要提供調度算法來回收相關內存空間。內存空間回收的方式通常就是 swap,即交換到持久化存儲設備上。
File-backed pages(Page Cache)的內存回收代價較低。Page Cache 通常對應于一個文件上的若干順序塊,因此可以通過順序 I/O 的方式落盤。另一方面,如果 Page Cache 上沒有進行寫操作(所謂的沒有臟頁),甚至不會將 Page Cache 回盤,因為數據的內容完全可以通過再次讀取磁盤文件得到。
Page Cache 的主要難點在于臟頁回盤,這個內容會在第二節進行詳細說明。
Anonymous pages 的內存回收代價較高。這是因為 Anonymous pages 通常隨機地寫入持久化交換設備。另一方面,無論是否有寫操作,為了確保數據不丟失,Anonymous pages 在 swap 時必須持久化到磁盤。
1.4 Swap 與缺頁中斷
Swap 機制指的是當物理內存不夠用,內存管理單元(Memory Mangament Unit,MMU)需要提供調度算法來回收相關內存空間,然后將清理出來的內存空間給當前內存申請方。
Swap 機制存在的本質原因是 Linux 系統提供了虛擬內存管理機制,每一個進程認為其獨占內存空間,因此所有進程的內存空間之和遠遠大于物理內存。所有進程的內存空間之和超過物理內存的部分就需要交換到磁盤上。
操作系統以 page 為單位管理內存,當進程發現需要訪問的數據不在內存時,操作系統可能會將數據以頁的方式加載到內存中。上述過程被稱為缺頁中斷,當操作系統發生缺頁中斷時,就會通過系統調用將 page 再次讀到內存中。
但主內存的空間是有限的,當主內存中不包含可以使用的空間時,操作系統會從選擇合適的物理內存頁驅逐回磁盤,為新的內存頁讓出位置,選擇待驅逐頁的過程在操作系統中叫做頁面替換(Page Replacement),替換操作又會觸發 swap 機制。
如果物理內存足夠大,那么可能不需要 Swap 機制,但是 Swap 在這種情況下還是有一定優勢:對于有發生內存泄漏幾率的應用程序(進程),Swap 交換分區更是重要,這可以確保內存泄露不至于導致物理內存不夠用,最終導致系統崩潰。但內存泄露會引起頻繁的 swap,此時非常影響操作系統的性能。
Linux 通過一個 swappiness 參數來控制 Swap 機制[2]:這個參數值可為 0-100,控制系統 swap 的優先級:
- 高數值:較高頻率的 swap,進程不活躍時主動將其轉換出物理內存。
- 低數值:較低頻率的 swap,這可以確保交互式不因為內存空間頻繁地交換到磁盤而提高響應延遲。
最后,為什么 Buffers 也是 Page Cache 的一部分?
這是因為當匿名頁(Inactive(anon) 以及 Active(anon))先被交換(swap out)到磁盤上后,然后再加載回(swap in)內存中,由于讀入到內存后原來的 Swap File 還在,所以 SwapCached 也可以認為是 File-backed page,即屬于 Page Cache。這個過程如 Figure 2 所示。
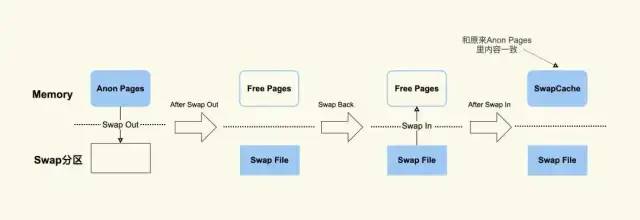
Figure2. 匿名頁的被交換后也是 Page Cache
1.5 Page Cache 與 buffer cache
執行 free 命令,注意到會有兩列名為 buffers 和 cached,也有一行名為 “-/+ buffers/cache”。
~ free -m
total used free shared buffers cached
Mem: 128956 96440 32515 0 5368 39900
-/+ buffers/cache: 51172 77784
Swap: 16002 0 16001
其中,cached 列表示當前的頁緩存(Page Cache)占用量,buffers 列表示當前的塊緩存(buffer cache)占用量。用一句話來解釋:Page Cache 用于緩存文件的頁數據,buffer cache 用于緩存塊設備(如磁盤)的塊數據。頁是邏輯上的概念,因此 Page Cache 是與文件系統同級的;塊是物理上的概念,因此 buffer cache 是與塊設備驅動程序同級的。
其中,cached 列表示當前的頁緩存(Page Cache)占用量,buffers 列表示當前的塊緩存(buffer cache)占用量。用一句話來解釋:Page Cache 用于緩存文件的頁數據,buffer cache 用于緩存塊設備(如磁盤)的塊數據。頁是邏輯上的概念,因此 Page Cache 是與文件系統同級的;塊是物理上的概念,因此 buffer cache 是與塊設備驅動程序同級的。
Page Cache 與 buffer cache 的共同目的都是加速數據 I/O:寫數據時首先寫到緩存,將寫入的頁標記為 dirty,然后向外部存儲 flush,也就是緩存寫機制中的 write-back(另一種是 write-through,Linux 默認情況下不采用);讀數據時首先讀取緩存,如果未命中,再去外部存儲讀取,并且將讀取來的數據也加入緩存。操作系統總是積極地將所有空閑內存都用作 Page Cache 和 buffer cache,當內存不夠用時也會用 LRU 等算法淘汰緩存頁。
在 Linux 2.4 版本的內核之前,Page Cache 與 buffer cache 是完全分離的。但是,塊設備大多是磁盤,磁盤上的數據又大多通過文件系統來組織,這種設計導致很多數據被緩存了兩次,浪費內存。所以在 2.4 版本內核之后,兩塊緩存近似融合在了一起:如果一個文件的頁加載到了 Page Cache,那么同時 buffer cache 只需要維護塊指向頁的指針就可以了。只有那些沒有文件表示的塊,或者繞過了文件系統直接操作(如dd命令)的塊,才會真正放到 buffer cache 里。因此,我們現在提起 Page Cache,基本上都同時指 Page Cache 和 buffer cache 兩者,本文之后也不再區分,直接統稱為 Page Cache。
下圖近似地示出 32-bit Linux 系統中可能的一種 Page Cache 結構,其中 block size 大小為 1KB,page size 大小為 4KB。
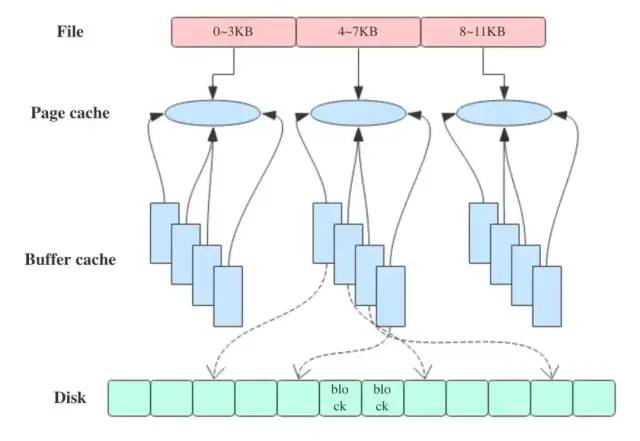
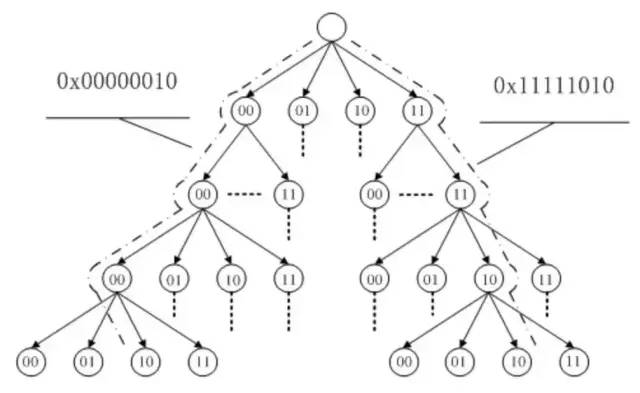
Page Cache 中的每個文件都是一棵基數樹(radix tree,本質上是多叉搜索樹),樹的每個節點都是一個頁。根據文件內的偏移量就可以快速定位到所在的頁,如下圖所示。關于基數樹的原理可以參見英文維基,這里就不細說了。
1.6 Page Cache 與預讀
操作系統為基于 Page Cache 的讀緩存機制提供預讀機制(PAGE_READAHEAD),一個例子是:
- 用戶線程僅僅請求讀取磁盤上文件 A 的 offset 為 0-3KB 范圍內的數據,由于磁盤的基本讀寫單位為 block(4KB),于是操作系統至少會讀 0-4KB 的內容,這恰好可以在一個 page 中裝下。
- 但是操作系統出于局部性原理[3]會選擇將磁盤塊 offset [4KB,8KB)、[8KB,12KB) 以及 [12KB,16KB) 都加載到內存,于是額外在內存中申請了 3 個 page;
下圖代表了操作系統的預讀機制:
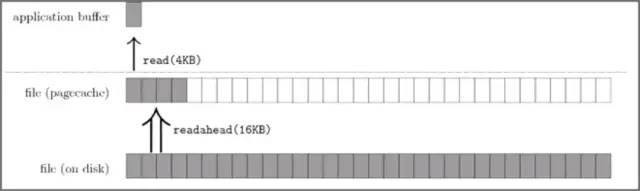
Figure.操作系統的預讀機制;
上圖中,應用程序利用 read 系統調動讀取 4KB 數據,實際上內核使用 readahead 機制完成了 16KB 數據的讀取。
- Page Cache 與文件持久化的一致性&可靠性
現代 Linux 的 Page Cache 正如其名,是對磁盤上 page(頁)的內存緩存,同時可以用于讀/寫操作。任何系統引入緩存,就會引發一致性問題:內存中的數據與磁盤中的數據不一致,例如常見后端架構中的 Redis 緩存與 MySQL 數據庫就存在一致性問題。
Linux 提供多種機制來保證數據一致性,但無論是單機上的內存與磁盤一致性,還是分布式組件中節點 1 與節點 2 、節點 3 的數據一致性問題,理解的關鍵是 trade-off:吞吐量與數據一致性保證是一對矛盾。
首先,需要我們理解一下文件的數據。文件 = 數據 + 元數據。元數據用來描述文件的各種屬性,也必須存儲在磁盤上。因此,我們說保證文件一致性其實包含了兩個方面:數據一致+元數據一致。
文件的元數據包括:文件大小、創建時間、訪問時間、屬主屬組等信息。
我們考慮如下一致性問題:如果發生寫操作并且對應的數據在 Page Cache 中,那么寫操作就會直接作用于 Page Cache 中,此時如果數據還沒刷新到磁盤,那么內存中的數據就領先于磁盤,此時對應 page 就被稱為 Dirty page。
當前 Linux 下以兩種方式實現文件一致性:
- Write Through(寫穿):向用戶層提供特定接口,應用程序可主動調用接口來保證文件一致性;
- Write back(寫回):系統中存在定期任務(表現形式為內核線程),周期性地同步文件系統中文件臟數據塊,這是默認的 Linux 一致性方案;
上述兩種方式最終都依賴于系統調用,主要分為如下三種系統調用:

上述三種系統調用可以分別由用戶進程與內核進程發起。下面我們研究一下內核線程的相關特性。
- 創建的針對回寫任務的內核線程數由系統中持久存儲設備決定,為每個存儲設備創建單獨的刷新線程;
- 關于多線程的架構問題,Linux 內核采取了 Lighthttp 的做法,即系統中存在一個管理線程和多個刷新線程(每個持久存儲設備對應一個刷新線程)。管理線程監控設備上的臟頁面情況,若設備一段時間內沒有產生臟頁面,就銷毀設備上的刷新線程;若監測到設備上有臟頁面需要回寫且尚未為該設備創建刷新線程,那么創建刷新線程處理臟頁面回寫。而刷新線程的任務較為單調,只負責將設備中的臟頁面回寫至持久存儲設備中。
- 刷新線程刷新設備上臟頁面大致設計如下:
- 每個設備保存臟文件鏈表,保存的是該設備上存儲的臟文件的 inode 節點。所謂的回寫文件臟頁面即回寫該 inode 鏈表上的某些文件的臟頁面;
- 系統中存在多個回寫時機,第一是應用程序主動調用回寫接口(fsync,fdatasync 以及 sync 等),第二管理線程周期性地喚醒設備上的回寫線程進行回寫,第三是某些應用程序/內核任務發現內存不足時要回收部分緩存頁面而事先進行臟頁面回寫,設計一個統一的框架來管理這些回寫任務非常有必要。
Write Through 與 Write back 在持久化的可靠性上有所不同:
- Write Through 以犧牲系統 I/O 吞吐量作為代價,向上層應用確保一旦寫入,數據就已經落盤,不會丟失;
- Write back 在系統發生宕機的情況下無法確保數據已經落盤,因此存在數據丟失的問題。不過,在程序掛了,例如被 kill -9,Page Cache 中的數據操作系統還是會確保落盤;
- Page Cache 的優劣勢
3.1 Page Cache 的優勢
1.加快數據訪問
如果數據能夠在內存中進行緩存,那么下一次訪問就不需要通過磁盤 I/O 了,直接命中內存緩存即可。
由于內存訪問比磁盤訪問快很多,因此加快數據訪問是 Page Cache 的一大優勢。
2.減少 I/O 次數,提高系統磁盤 I/O 吞吐量
得益于 Page Cache 的緩存以及預讀能力,而程序又往往符合局部性原理,因此通過一次 I/O 將多個 page 裝入 Page Cache 能夠減少磁盤 I/O 次數, 進而提高系統磁盤 I/O 吞吐量。
3.2 Page Cache 的劣勢
page cache 也有其劣勢,最直接的缺點是需要占用額外物理內存空間,物理內存在比較緊俏的時候可能會導致頻繁的 swap 操作,最終導致系統的磁盤 I/O 負載的上升。
Page Cache 的另一個缺陷是對應用層并沒有提供很好的管理 API,幾乎是透明管理。應用層即使想優化 Page Cache 的使用策略也很難進行。因此一些應用選擇在用戶空間實現自己的 page 管理,而不使用 page cache,例如 MySQL InnoDB 存儲引擎以 16KB 的頁進行管理。
Page Cache 最后一個缺陷是在某些應用場景下比 Direct I/O 多一次磁盤讀 I/O 以及磁盤寫 I/O。
-
數據
+關注
關注
8文章
7002瀏覽量
88942 -
緩沖
+關注
關注
0文章
52瀏覽量
17819 -
磁盤
+關注
關注
1文章
375瀏覽量
25201 -
系統調用
+關注
關注
0文章
28瀏覽量
8324
發布評論請先 登錄
相關推薦
Linux進程退出之方法論
LabView隊列操作程序數據會丟失,請問有什么好的改進方法減少數據的丟失呢?
請問文件怎么會丟失呢?
CAN轉LWIP會丟失數據
微軟Windows 10修復補丁KB4532693會導致文件丟失
查看Linux文件占用進程寫數據

SQL Server數據庫文件丟失的數據恢復案例
數據庫數據恢復—Sql Server數據庫文件丟失的數據恢復案例





 工商網監
工商網監
評論