") C++內(nèi)存管理問題
C++內(nèi)存管理問題
寫服務(wù)端的,內(nèi)存是一個(gè)繞不過的問題,而用C++寫的,這個(gè)問題就顯得更嚴(yán)重。進(jìn)程的內(nèi)存持續(xù)上漲,有可能是正常的內(nèi)存占用,也有可能是內(nèi)存碎片,而C++寫的,還有可能是內(nèi)存泄漏,那就需要一些方法來檢測(cè)到底是哪些問題引起的
1. 內(nèi)存占用
首先從top這個(gè)指令說起
Tasks: 80 total, 1 running, 79 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.7 sy, 0.0 ni, 92.7 id, 6.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2052544 total, 1453600 free, 162408 used, 436536 buff/cache
KiB Swap: 782332 total, 782332 free, 0 used. 1708652 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
179 root 20 0 0 0 0 S 0.3 0.0 0:00.27 [jbd2/dm-0-+
493 mongodb 20 0 1102144 78548 36688 S 0.3 3.8 0:26.07 /usr/bin/mo+
636 mysql 20 0 653808 75932 15548 S 0.3 3.7 0:03.55 /usr/sbin/m+
與進(jìn)程內(nèi)存相關(guān)的兩個(gè)指標(biāo):VIRT Virtual Memory,虛擬內(nèi)存、RES Resident Memory,常駐內(nèi)存,通常叫物理內(nèi)存。虛擬內(nèi)存,是指整個(gè)進(jìn)程申請(qǐng)的內(nèi)存,包括程序本身的占內(nèi)存、new或者malloc分配的內(nèi)存等等。物理內(nèi)存,就是這個(gè)進(jìn)程在主板上內(nèi)存條那里占用了多少內(nèi)存。那為什么會(huì)有虛擬內(nèi)存這個(gè)東西,C++不是可以操作硬件么,為什么不直接使用物理內(nèi)存?這得簡單了解一下操作系統(tǒng)的內(nèi)存管理。
現(xiàn)代的計(jì)算機(jī)都會(huì)同時(shí)運(yùn)行N個(gè)程序,有N多個(gè)進(jìn)程,這些進(jìn)程都是獨(dú)立在運(yùn)行。如果直接使用物理內(nèi)存,那就會(huì)產(chǎn)生一個(gè)問題,進(jìn)程A申請(qǐng)了內(nèi)存,進(jìn)程B也要申請(qǐng)一塊內(nèi)存,但進(jìn)程B并不知道進(jìn)程A的存在,就沒法保證進(jìn)程B使用的內(nèi)存進(jìn)程A沒在用。因此linux下使用內(nèi)核來管理這些資源,所有進(jìn)程都只是向內(nèi)核申請(qǐng),由內(nèi)核管理物理內(nèi)存。而一個(gè)進(jìn)程,可能多次申請(qǐng)、釋放內(nèi)存,或者程序直接當(dāng)?shù)魶]有釋放內(nèi)存,內(nèi)核為了解決這些復(fù)雜的問題,用一個(gè)列表維護(hù)了進(jìn)程分配的內(nèi)存,這就叫虛擬內(nèi)存,然后把虛擬內(nèi)存映射到物理內(nèi)存,這就完成了整個(gè)內(nèi)存的管理。而且,內(nèi)核對(duì)內(nèi)存的映射做了優(yōu)化,用到時(shí)才映射,如下面的圖中,進(jìn)程A的new2這塊內(nèi)存分配了以后,一直沒使用,也就不會(huì)映射到物理內(nèi)存。有很多程序,利用了這個(gè)特性。例如,在socket收發(fā)時(shí),我們可以分配很大的一塊內(nèi)存(比如16M),避免頻繁分配緩沖區(qū),但實(shí)際這個(gè)socket可能收到的數(shù)據(jù)塊最大只有16k,那內(nèi)核是不會(huì)直接映射16M物理內(nèi)存的,這樣既方便了我們寫程序,但又沒浪費(fèi)物理內(nèi)存。
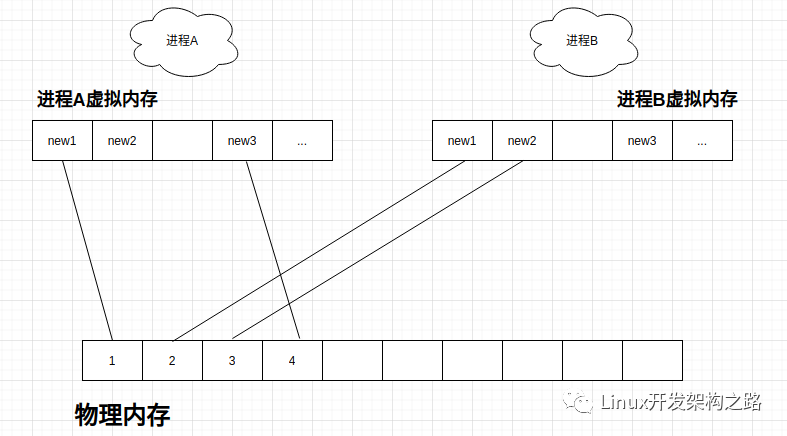
下面寫個(gè)程序來驗(yàn)證這個(gè)問題
#include < cstring >
#include < iostream >
int main()
{
#define PAUSE(msg) std::cout < < msg < < std::endl; std::cin > > p
char p;
size_t size = 1024 * 1024 *100;
char *l = new char[size];
PAUSE("new");
memset(l, 1, size / 2);
PAUSE("using half large");
memset(l, 1, size);
PAUSE("using whole large");
delete []l;
PAUSE("del");
return 0;
}
在每次暫停時(shí),top的輸出結(jié)果(RES 1588 54328 105600 3348),說明memset的時(shí)候,內(nèi)核才會(huì)映射物理內(nèi)存。
new
進(jìn)程號(hào) USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND
25295 root 20 0 108280 1588 1436 S 0.0 0.0 0:00.00 ./a.out
using half large
25295 root 20 0 108280 54328 3096 S 0.0 0.7 0:00.05 ./a.out
using whole large
25295 root 20 0 108280 105600 3156 S 0.0 1.4 0:00.12 ./a.out
del
25295 root 20 0 5876 3348 3156 S 0.0 0.0 0:00.13 ./a.out
所以,通過top查看進(jìn)程內(nèi)存時(shí),如果發(fā)現(xiàn)VIRT占用很大,說明這個(gè)程序用new或者malloc等分配了很多內(nèi)存,但如果RES不是很大,那就不要慌,可能這只是程序的一個(gè)緩存優(yōu)化(當(dāng)然也有可能是寫這個(gè)程序的人用new分配內(nèi)存時(shí)很不合理,分配的值遠(yuǎn)大于使用值),實(shí)際程序運(yùn)行占用的物理內(nèi)存并不大。但如果RES也很高,那可能就有點(diǎn)慌了。
2. 內(nèi)存泄漏
內(nèi)存泄漏是導(dǎo)致進(jìn)程內(nèi)存持續(xù)上漲最常見的原因,而這是C++中常見但不好處理的問題,一個(gè)維護(hù)多年的大項(xiàng)目,代碼不知道由多少個(gè)人寫的,想找出哪個(gè)指針的內(nèi)存沒釋放,談何容易。解決這個(gè)問題沒有什么通用快捷的辦法,只能根據(jù)實(shí)際業(yè)務(wù)處理。
第一,從業(yè)務(wù)上,能不能重現(xiàn)內(nèi)存泄漏。例如我們做游戲的,假如玩家不停地登錄,就會(huì)導(dǎo)致內(nèi)存不斷上漲,那說明問題就在登錄流程,把整個(gè)流程拆分,一個(gè)個(gè)屏蔽測(cè)試,最終找出問題。
第二,從部署上,能不能定位內(nèi)存泄漏。例如,最近更新了一個(gè)版本,發(fā)現(xiàn)內(nèi)存占用變得很高,那就可以確定,是這個(gè)版本的修改出了問題。一個(gè)版本的代碼量終究是有限的,查找起來也比較容易。
第三,使用valgrind memcheck。如果能夠復(fù)現(xiàn)內(nèi)存泄漏,但無法定位是哪個(gè)邏輯,那可以用valgrind memcheck。復(fù)現(xiàn)內(nèi)存泄漏,這個(gè)通常比較難實(shí)現(xiàn),一般是線下測(cè)試無法復(fù)現(xiàn),線上用戶量大,運(yùn)行久了才會(huì)復(fù)現(xiàn),而valgrind會(huì)導(dǎo)致程序運(yùn)行很慢,無法支撐線上測(cè)試,因此這個(gè)選項(xiàng)通常不太適用于線上。
第四,使用Visual Leak Detector。valgrind是linux下的,如果程序可以跨平臺(tái),或者只在win下,那么可以試試這個(gè),這個(gè)和valgrind一樣,需要復(fù)現(xiàn)泄漏才能得到堆棧,因此也是用于線下調(diào)試比較多。
第五,重載new、delete。像我之前的博客里寫的,可以簡單地加個(gè)計(jì)數(shù),用于平時(shí)預(yù)防泄漏,也可更深入一些,記錄內(nèi)存的分配,得到內(nèi)存漏泄的堆棧,但是這個(gè)是否能支撐線上debug,我持懷疑態(tài)度。
第六,使用自己的內(nèi)存分配函數(shù),每一個(gè)內(nèi)存分配,都使用自己的函數(shù),每一個(gè)STL的容器,都傳入自己的分配器,然后分別記錄這些內(nèi)存分配的大小。這個(gè)方法看起來很不現(xiàn)實(shí),但我確實(shí)見過在實(shí)際的項(xiàng)目中使用,對(duì)內(nèi)存統(tǒng)計(jì)、查找有很大的幫助,而且支持在線上debug。查找內(nèi)存,只需要打印下每個(gè)分配器分配的內(nèi)存大小基本上可以得到結(jié)論是哪個(gè)分配器出問題。唯一的問題是它增加了開發(fā)難度,而且不能像valgrind那樣不需要修改原程序即可使用。
第七,使用valgrind massif。valgrind memcheck需要復(fù)現(xiàn)內(nèi)存泄漏,所以不容易找出問題。它會(huì)定時(shí)記錄分配內(nèi)存的各個(gè)堆棧以及分配內(nèi)存的量,當(dāng)出現(xiàn)內(nèi)存泄漏時(shí),根據(jù)分配內(nèi)存的量檢查下各個(gè)堆棧,應(yīng)該是可以找到問題的。massif也會(huì)導(dǎo)致程序運(yùn)行慢,但比memcheck要快,能不能在線上debug,這個(gè)依然得看具體情況
第八,使用第三方內(nèi)存分配器,如jemalloc。并不是說使用第三方內(nèi)存分配器就解決問題了,而是jemalloc自帶了一大堆工具,其中jeprof可以得到內(nèi)存的大小以及堆棧等信息,對(duì)查找內(nèi)存泄漏有很大幫助。不過開啟prof后,效率如何,能不能在線上使用,我倒是沒測(cè)試過。
3. 內(nèi)存碎片
假如找不到內(nèi)存泄漏,也許本來就沒有內(nèi)存泄漏,這時(shí)不妨考慮下內(nèi)存碎片的問題。這里以linux下的ptmalloc為例(其他的分配器我就不懂了),說下內(nèi)存分配。假如一個(gè)進(jìn)程,依次分配了內(nèi)存塊m1(1k)、m2(10b)、
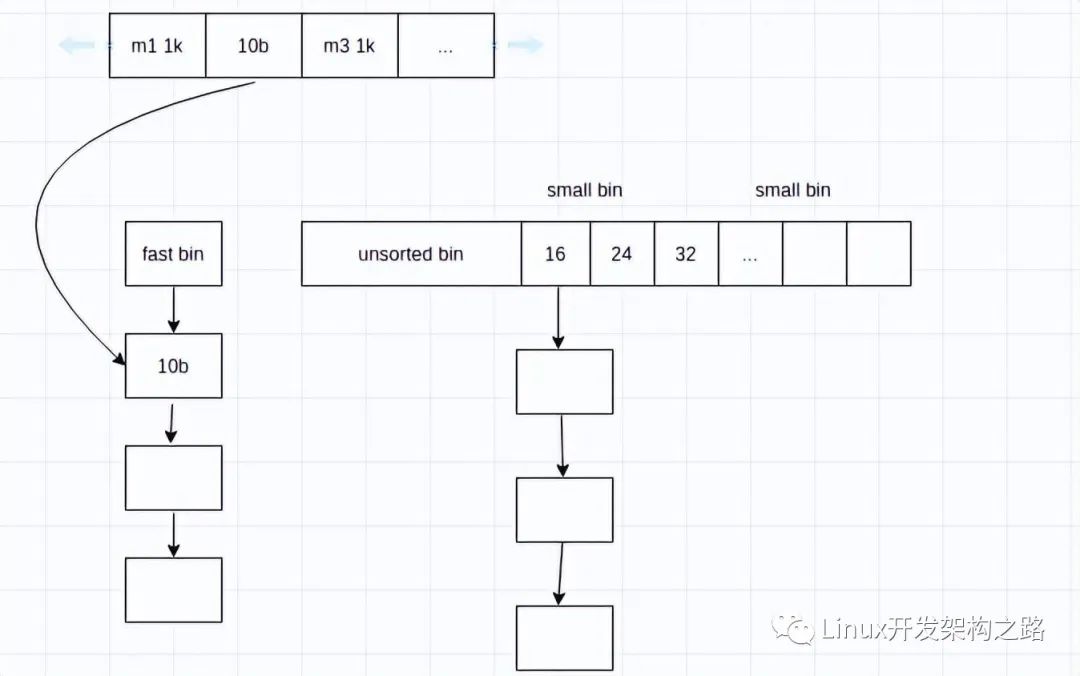
m3(1k),然后釋放了m2,那整個(gè)內(nèi)存看起來是這樣子的:
我們可以看到,m1、m2、m3是按順序分配的,當(dāng)m2被釋放時(shí),那中間就空了一塊了。那空的這一塊怎么辦,是把它還給系統(tǒng)了嗎?這個(gè)問題就很復(fù)雜了,涉及到ptmalloc的整個(gè)分配機(jī)制,這里不打算詳細(xì)說,建議看華庭(莊明強(qiáng)) - ptmalloc2源代碼分析。簡單來講,就是ptmalloc會(huì)暫把釋放的內(nèi)存按大小用鏈表存起來,比如10b的,放到fast bin那個(gè)鏈表,大一點(diǎn)的,放small bin的第一個(gè)鏈表,再大一點(diǎn),放small bin的第二個(gè)鏈表,... 放進(jìn)去的內(nèi)存,直到第再次用到時(shí)取出。
隨著程序運(yùn)行,放進(jìn)鏈表的內(nèi)存可能會(huì)越來越多,但是卻很少取出(可能是程序釋放后沒有再申請(qǐng),也可能是申請(qǐng)的大小和鏈表里的大小不合適,比如鏈表里有個(gè)10b的,但是程序申請(qǐng)了1k),那這些小內(nèi)存就會(huì)越來越多,進(jìn)程占用的內(nèi)存也會(huì)越來越多,但實(shí)際使用的內(nèi)存不多。那如何檢測(cè)這種情況呢?
方法一,使用
malloc_stats。malloc_stats是一個(gè)glibc的函數(shù),因此可以在gdb調(diào)用
gdb -p 16021
call malloc_stats()
Arena 0:
system bytes = 1359872
in use bytes = 954224
Arena 1:
system bytes = 135168
in use bytes = 3488
Arena 2:
system bytes = 135168
in use bytes = 20784
Arena 3:
system bytes = 139264
in use bytes = 120080
Total (incl. mmap):
system bytes = 1769472
in use bytes = 1098576
max mmap regions = 0
max mmap bytes = 0
- Arena N表示多個(gè)分配域,一般一個(gè)線程一個(gè)
- system bytes 當(dāng)前申請(qǐng)的內(nèi)存總數(shù)
- in use bytes 當(dāng)前使用的內(nèi)存總數(shù)
- max mmap regions 使用mmap分配了多少塊內(nèi)存(大內(nèi)存用mmap分配,大于128K,可由M_MMAP_THRESHOLD選項(xiàng)調(diào)節(jié))
- max mmap bytes 使用mmap分配了多少內(nèi)存
這里,system bytes減去in use bytes就可以得到當(dāng)前進(jìn)程緩存了多少內(nèi)存。不過malloc_stats是一個(gè)很老的接口了,里面的變量都是用的int,如果你的程序占用內(nèi)存比較大,這里可能會(huì)溢出。
方法二,使用使用malloc_info
gdb -p 16021
call malloc_info(0, stdout)
< malloc version="1" >
< heap nr="0" >
< sizes >
< size from="17" to="32" total="3104" count="97"/ >
< size from="33" to="48" total="11136" count="232"/ >
< size from="49" to="64" total="12288" count="192"/ >
< size from="65" to="80" total="14640" count="183"/ >
< size from="81" to="96" total="4896" count="51"/ >
< size from="97" to="112" total="1232" count="11"/ >
< size from="113" to="128" total="7296" count="57"/ >
< size from="33" to="33" total="13299" count="403"/ >
< size from="97" to="97" total="97" count="1"/ >
< size from="7281" to="7281" total="7281" count="1"/ >
< size from="32833" to="32833" total="32833" count="1"/ >
< unsorted from="145" to="8753" total="166107" count="155"/ >
< /sizes >
< total type="fast" count="823" size="54592"/ >
< total type="rest" count="561" size="219617"/ >
< system type="current" size="1359872"/ >
< system type="max" size="1376256"/ >
< aspace type="total" size="1359872"/ >
< aspace type="mprotect" size="1359872"/ >
< /heap >
< heap nr="1" >
< sizes >
< size from="33" to="48" total="48" count="1"/ >
< unsorted from="4673" to="4705" total="9378" count="2"/ >
< /sizes >
< total type="fast" count="1" size="48"/ >
< total type="rest" count="2" size="9378"/ >
< system type="current" size="135168"/ >
< system type="max" size="135168"/ >
< aspace type="total" size="135168"/ >
< aspace type="mprotect" size="135168"/ >
< /heap >
< heap nr="2" >
< sizes >
< size from="33" to="48" total="48" count="1"/ >
< size from="113" to="128" total="128" count="1"/ >
< size from="65" to="65" total="65" count="1"/ >
< unsorted from="81" to="3233" total="10054" count="6"/ >
< /sizes >
< total type="fast" count="2" size="176"/ >
< total type="rest" count="7" size="10119"/ >
< system type="current" size="135168"/ >
< system type="max" size="135168"/ >
< aspace type="total" size="135168"/ >
< aspace type="mprotect" size="135168"/ >
< /heap >
< heap nr="3" >
< sizes >
< size from="65" to="80" total="80" count="1"/ >
< /sizes >
< total type="fast" count="1" size="80"/ >
< total type="rest" count="0" size="0"/ >
< system type="current" size="139264"/ >
< system type="max" size="139264"/ >
< aspace type="total" size="139264"/ >
< aspace type="mprotect" size="139264"/ >
< /heap >
< total type="fast" count="827" size="54896"/ >
< total type="rest" count="570" size="239114"/ >
< total type="mmap" count="0" size="0"/ >
< system type="current" size="1769472"/ >
< system type="max" size="1785856"/ >
< aspace type="total" size="1769472"/ >
< aspace type="mprotect" size="1769472"/ >
< /malloc >
- nr即arena,通常一個(gè)線程一個(gè)
- 上面說了,大小在一定范圍內(nèi)的內(nèi)存,會(huì)放到一個(gè)鏈表里,這就是其中一個(gè)鏈表。from是內(nèi)存下限,to是上限,上面的意思是內(nèi)存分配在 [17,32]范圍內(nèi)的空閑內(nèi)存總共有97個(gè),占3104字節(jié)內(nèi)存。在這個(gè)區(qū)間內(nèi)的內(nèi)存申請(qǐng)都會(huì)被對(duì)齊為32,故total = to * count
- 即fastbin這鏈表當(dāng)前有2個(gè)空閑內(nèi)存塊,大小為176
除fastbin以外,所有鏈表空閑的內(nèi)存數(shù)量,以及內(nèi)存大小。因此fast和rest加起來,應(yīng)該和當(dāng)前arena里所有的size一致,如
< heap nr="2" >
< sizes >
< size from="33" to="48" total="48" count="1"/ >
< size from="113" to="128" total="128" count="1"/ >
< size from="65" to="65" total="65" count="1"/ >
< unsorted from="81" to="3233" total="10054" count="6"/ >
< /sizes >
< total type="fast" count="2" size="176"/ >
< total type="rest" count="7" size="10119"/ >
前兩個(gè)to大小為48和128為fast bin,數(shù)量為2,剩下的都為rest,與下面的fast和reset對(duì)應(yīng)。
- 使用mmap分配的當(dāng)前在使用塊數(shù)(count)和當(dāng)前在用的內(nèi)存大小(size)(低版本glibc無此字段,如centos6上的glibc 2.12)
- 當(dāng)前已經(jīng)申請(qǐng)的內(nèi)存大小
- 歷史上申請(qǐng)的內(nèi)存大小(包括已經(jīng)歸還給操作系統(tǒng)的)
- total和mprotect看源碼沒看出是什么東西
到這里可以看到,假如一個(gè)進(jìn)程fast和reset里的數(shù)量很多,那么說明這個(gè)進(jìn)程其實(shí)緩存了很多內(nèi)存。另外這里都是直接用gdb attach到一個(gè)進(jìn)程直接調(diào)用函數(shù),打印到stdout。如果需要查看的程序被關(guān)掉了stdout或者重定向了stdout(很多服務(wù)器進(jìn)程都這么做),那可能看不見了,或者信息不是打印到當(dāng)前終端。
4. 內(nèi)存利用率
如果一個(gè)進(jìn)程占用的內(nèi)存遠(yuǎn)高于預(yù)期,但沒有持續(xù)上漲,還需要考慮下是不是內(nèi)存使用率的問題。當(dāng)使用new分配一塊內(nèi)存時(shí),系統(tǒng)需要為這次分配記錄大小、地址,分配的內(nèi)存也需要對(duì)齊,假如分配的內(nèi)存很小(比如說1b),那系統(tǒng)最終需要消耗的內(nèi)存是遠(yuǎn)大于1b的。比如
#include < cstring >
#include < iostream >
int main()
{
#define PAUSE(msg) std::cout < < msg < < std::endl; std::cin > > p
char p = NULL;
size_t total = 0;
while (total < 1024 * 1024 * 1024)
{
size_t size = rand() % 16;
total += size;
char *p = new char[size];
}
PAUSE("pause");
這個(gè)程序每次分配小于16字節(jié)的內(nèi)存,直到總分配量到1G,然而,在我的系統(tǒng)里(ubuntu 20.04),這個(gè)程序跑起來占用的內(nèi)存就多得多
進(jìn)程號(hào) USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND
4174 root 20 0 4479488 4.3g 1616 S 0.0 59.0 0:15.97 ./a.out
已經(jīng)達(dá)到了4.3G,顯然內(nèi)存利用率只有1/4不到。你也許會(huì)說這種分配小內(nèi)存的情況不多,但其實(shí)不是的。舉個(gè)例子,做關(guān)鍵字搜索時(shí),會(huì)用到二叉搜索樹,每一個(gè)樹的節(jié)點(diǎn)對(duì)應(yīng)一個(gè)字符,比如"abcd“就需要分配4個(gè)節(jié)點(diǎn),但是每個(gè)節(jié)點(diǎn)其實(shí)很小。假如關(guān)鍵字很多(上百萬還是很常見的),那這個(gè)問題就比較嚴(yán)重。這時(shí)候就應(yīng)該使用valgrind massif來看下,到底是哪個(gè)地方分配的內(nèi)存,然后根據(jù)邏輯優(yōu)化即可。
-
程序
+關(guān)注
關(guān)注
117文章
3785瀏覽量
81004 -
C++
+關(guān)注
關(guān)注
22文章
2108瀏覽量
73622 -
內(nèi)存管理
+關(guān)注
關(guān)注
0文章
168瀏覽量
14134 -
進(jìn)程
+關(guān)注
關(guān)注
0文章
203瀏覽量
13960
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Linux C++程序內(nèi)存管理的理論基礎(chǔ)
一文詳解Linux C++內(nèi)存管理
深入C++內(nèi)存管理
Visual C++ 6.0程序設(shè)計(jì)--內(nèi)存管理
C++內(nèi)存泄漏
C++設(shè)計(jì)高校學(xué)籍管理設(shè)計(jì)與實(shí)驗(yàn)
C++內(nèi)存泄漏分析方法
干貨 | 嵌入式C語言的內(nèi)存管理
C++內(nèi)存管理技術(shù)的詳細(xì)資料說明
C++內(nèi)存管理的詳細(xì)資料講解
C++內(nèi)存管理詳細(xì)介紹
C++內(nèi)存管理全景指南
百度工程師帶你探秘C++內(nèi)存管理
C++內(nèi)存管理operator new和placement new
嵌入式C++內(nèi)存管理的應(yīng)用程序





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論