 glibc的內存分配回收策略
glibc的內存分配回收策略
Linux內存空間簡介
32位Linux平臺下進程虛擬地址空間分布如下圖:
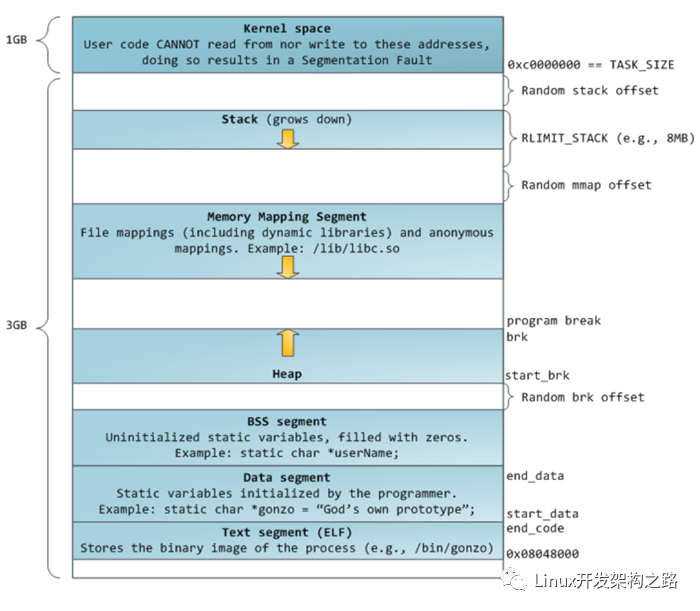
進程虛擬地址空間分布
圖中,0xC0000000開始的最高1G空間是內核地址空間,剩下3G空間是用戶態空間。用戶態空間從上到下依次為stack棧(向下增長)、mmap(匿名文件映射區)、Heap堆(向上增長)、bss數據段、數據段、只讀代碼段。
其中,Heap區是程序的動態內存區,同時也是C++內存泄漏的溫床。malloc、free均發生在這個區域。本文將簡單介紹下glibc在動態內存管理方面的機制,拋磚引玉,希望能和大家多多交流。
Linux提供了如下幾個系統調用,用于內存分配:
brk()/sbrk() // 通過移動Heap堆頂指針brk,達到增加內存目的
mmap()/munmap() // 通過文件影射的方式,把文件映射到mmap區
這兩種方式分配的都是虛擬內存,沒有分配物理內存。在第一次訪問已分配的虛擬地址空間的時候,發生缺頁中斷,操作系統負責分配物理內存,然后建立虛擬內存和物理內存之間的映射關系。
那么,既然brk、mmap提供了內存分配的功能,直接使用brk、mmap進行內存管理不是更簡單嗎,為什么需要glibc呢?我們知道,系統調用本身會產生軟中斷,導致程序從用戶態陷入內核態,比較消耗資源。試想,如果頻繁分配回收小塊內存區,那么將有很大的性能耗費在系統調用中。因此,為了減少系統調用帶來的性能損耗,glibc采用了內存池的設計,增加了一個代理層,每次內存分配,都優先從內存池中尋找,如果內存池中無法提供,再向操作系統申請。
一切計算機的問題都可以通過加層的方式解決。
glibc的內存分配回收策略
glibc中malloc內存分配邏輯如下是:

malloc
- 分配內存 < DEFAULT_MMAP_THRESHOLD,走__brk,從內存池獲取,失敗的話走brk系統調用
- 分配內存 > DEFAULT_MMAP_THRESHOLD,走__mmap,直接調用mmap系統調用
其中,DEFAULT_MMAP_THRESHOLD默認為128k,可通過mallopt進行設置。重點看下小塊內存(size > DEFAULT_MMAP_THRESHOLD)的分配,glibc使用的內存池如下圖示:

內存池
內存池保存在bins這個長128的數組中,每個元素都是一雙向個鏈表。其中:
- bins[0]目前沒有使用
- bins[1]的鏈表稱為unsorted_list,用于維護free釋放的chunk。
- bins[2,63)的區間稱為small_bins,用于維護<512字節的內存塊,其中每個元素對應的鏈表中的chunk大小相同,均為index*8。
- bins[64,127)稱為large_bins,用于維護>512字節的內存塊,每個元素對應的鏈表中的chunk大小不同,index越大,鏈表中chunk的內存大小相差越大,例如: 下標為64的chunk大小介于[512, 512+64),下標為95的chunk大小介于[2k+1,2k+512)。同一條鏈表上的chunk,按照從小到大的順序排列。
chunk數據結構

chunk結構
glibc在內存池中查找合適的chunk時,采用了最佳適應的伙伴算法。舉例如下:
1、如果分配內存<512字節,則通過內存大小定位到smallbins對應的index上(floor(size/8))
- 如果smallbins[index]為空,進入步驟3
- 如果smallbins[index]非空,直接返回第一個chunk
2、如果分配內存>512字節,則定位到largebins對應的index上
- 如果largebins[index]為空,進入步驟3
- 如果largebins[index]非空,掃描鏈表,找到第一個大小最合適的chunk,如size=12.5K,則使用chunk B,剩下的0.5k放入unsorted_list中
3、遍歷unsorted_list,查找合適size的chunk,如果找到則返回;否則,將這些chunk都歸類放到smallbins和largebins里面
4、index++從更大的鏈表中查找,直到找到合適大小的chunk為止,找到后將chunk拆分,并將剩余的加入到unsorted_list中
5、如果還沒有找到,那么使用top chunk
6、或者,內存<128k,使用brk;內存>128k,使用mmap獲取新內存
top chunk 如下圖示: top chunk是堆頂的chunk,堆頂指針brk位于top chunk的頂部。移動brk指針,即可擴充top chunk的大小。當top chunk大小超過128k(可配置)時,會觸發malloc_trim操作,調用sbrk(-size)將內存歸還操作系統。

chunk分布圖
free釋放內存時,有兩種情況:
- chunk和top chunk相鄰,則和top chunk合并
- chunk和top chunk不相鄰,則直接插入到unsorted_list中
內存碎片
以上圖chunk分布圖為例,按照glibc的內存分配策略,我們考慮下如下場景(假設brk其實地址是512k):
- malloc 40k內存,即chunkA,brk = 512k + 40k = 552k
- malloc 50k內存,即chunkB,brk = 552k + 50k = 602k
- malloc 60k內存,即chunkC,brk = 602k + 60k = 662k
- free chunkA。
此時,由于brk = 662k,而釋放的內存是位于[512k, 552k]之間,無法通過移動brk指針,將區域內內存交還操作系統,因此,在[512k, 552k]的區域內便形成了一個內存空洞 ---- 內存碎片。按照glibc的策略,free后的chunkA區域由于不和top chunk相鄰,因此,無法和top chunk 合并,應該掛在unsorted_list鏈表上。
glibc實現的一些重要結構
glibc中用于維護空閑內存的結構體是malloc_state,其主要定義如下:
struct malloc_state {
mutex_t mutex; // 并發編程下鎖的競爭
mchunkptr top; // top chunk
unsigned int binmap[BINMAPSIZE]; // bitmap,加快bins中chunk判定
mchunkptr bins[NBINS * 2 - 2]; // bins,上文所述
mfastbinptr fastbinsY[NFASTBINS]; // fastbins,類似bins,維護的chunk更小(80字節的chunk鏈表)
...
}
static struct malloc_state main_arena; // 主arena
多線程下的競爭搶鎖
并發條件下,main_arena引發的競爭將會成為限制程序性能的瓶頸所在,因此glibc采用了多arena機制,線程A分配內存時獲取main_arena鎖成功,將在main_arena所管理的內存中分配;此時線程B獲取main_arena失敗,glibc會新建一個arena1,此次內存分配從arena1中進行。這種策略,一定程度上解決了多線程下競爭的問題;但是隨著arena的增多,內存碎片出現的可能性也變大了。例如,main_arena中有10k、20k的空閑內存,線程B要獲取20k的空閑內存,但是獲取main_arena鎖失敗,導致留下20k的碎片,降低了內存使用率。
普通arena的內部結構:

普通arena結構
- 一個arena由多個Heap構成
- 每個Heap通過mmap獲得,最大為1M,多個Heap間可能不相鄰
- Heap之間有prev指針指向前一個Heap
- 最上面的Heap,也有top chunk
每個Heap里面也是由chunk組成,使用和main_arena完全相同的管理方式管理空閑chunk。多個arena之間是通過鏈表連接的。如下圖:

arena鏈表
main arena和普通arena的區別 main_arena是為一個使用brk指針的arena,由于brk是堆頂指針,一個進程中只可能有一個,因此普通arena無法使用brk進行內存分配。普通arena建立在mmap的機制上,內存管理方式和main_arena類似,只有一點區別,普通arena只有在整個arena都空閑時,才會調用munmap把內存還給操作系統。
一些特殊情況的分析
根據上文所述,glibc在調用malloc_trim時,需要滿足如下2個條件:
1. size(top chunk) > 128K
2. brk = top chunk- >base + size(top chunk)
假設,brk指針上面的空間已經被占用,無法通過移動brk指針獲得新的地址空間,此時main_arena就無法擴容了嗎?glibc的設計考慮了這樣的特殊情況,此時,glibc會換用mmap操作來獲取新空間(每次最少MMAP_AS_MORECORE_SIZE<1M>)。這樣,main_arena和普通arena一樣,由非連續的Heap塊構成,不過這種情況下,glibc并未將這種mmap空間表示為Heap,因此,main_arena多個塊之間是沒有聯系的,這就導致了main_arena從此無法歸還給操作系統,永遠保留在空閑內存中了。如下圖示:

main_arena無法回收
顯而易見,此時根本不可能滿足調用malloc_trim的條件2,即:brk !== top chunk->base + size(top chunk),因為此時brk處于堆頂,而top chunk->base > brk.
#include < stdlib.h >
#include < stdio.h >
#include < string.h >
#include < unistd.h >
#include < sys/mman.h >
#include < malloc.h >
#define ARRAY_SIZE 127
char cmd[1024];
void print_info()
{
struct mallinfo mi = mallinfo();
system(cmd);
printf("theap_malloc_total=%lu heap_free_total=%lu heap_in_use=%lun
tmmap_total=%lu mmap_count=%lun", mi.arena, mi.fordblks, mi.uordblks, mi.hblkhd, mi.hblks);
}
int main(int argc, char** argv)
{
char** ptr_arr[ARRAY_SIZE];
int i;
char* mmap_var;
pid_t pid;
pid = getpid();
sprintf(cmd, "ps aux | grep %lu | grep -v grep", pid);
/* mmap占據堆頂后1M的地址空間 */
mmap_var = mmap((void*)sbrk(0) + 1024*1024, 127*1024, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
printf("before mallocn");
print_info();
/* 分配內存,總大小超過1M,導致main_arena被拆分 */
for( i = 0; i < ARRAY_SIZE; i++) {
ptr_arr[i] = malloc(i * 1024);
}
printf("nafter mallocn");
print_info();
/* 釋放所有內存,觀察內存使用是否改變 */
for( i = 0; i < ARRAY_SIZE; i++) {
free(ptr_arr[i]);
}
printf("nafter freen");
print_info();
munmap(mmap_var, 127*1024);
return 1;
}

異常運行
作為對比,去除掉brk上面的mmap區再次運行后結果如下:

正常運行
可以看出,異常情況下(brk無法擴展),free的內存沒有歸還操作系統,而是留在了main_arena的unsorted_list了;而正常情況下,由于滿足執行malloc_trim的條件,因此,free后,調用了sbrk(-size)把內存歸還了操作系統,main_arena內存響應減少。
-
數據
+關注
關注
8文章
7004瀏覽量
88944 -
內存
+關注
關注
8文章
3019瀏覽量
74008 -
程序
+關注
關注
117文章
3785瀏覽量
81005 -
C++
+關注
關注
22文章
2108瀏覽量
73623 -
Glibc
+關注
關注
0文章
9瀏覽量
7500
發布評論請先 登錄
相關推薦
C語言既然可以自動為變量分配內存,為什么還要用動態分配內存呢?
Linux內存系統: Linux 內存分配算法
淺析cache控制器的分配策略與替換策略
一種基于Buddy算法思想、高可靠性的內存管理策略
進程虛擬內存布局以及進程的虛擬內存分配釋放流程,涉及的代碼
Linux內存的分配管理與內存回收基本框架
jemalloc分配機制的介紹及其優化實踐


轉載 golang內存分配






 工商網監
工商網監
評論