 STL內容介紹
STL內容介紹
1 什么是STL?
STL(Standard Template Library),即標準模板庫,是一個具有工業強度的,高效的C++程序庫。它被容納于C++標準程序庫(C++ Standard Library)中,是ANSI/ISO C++標準中最新的也是極具革命性的一部分。該庫包含了諸多在計算機科學領域里所常用的基本數據結構和基本算法。為廣大C++程序員們提供了一個可擴展的應用框架,高度體現了軟件的可復用性。
STL的一個重要特點是數據結構和算法的分離。盡管這是個簡單的概念,但這種分離確實使得STL變得非常通用。例如,由于STL的sort()函數是完全通用的,你可以用它來操作幾乎任何數據集合,包括鏈表,容器和數組;
STL另一個重要特性是它不是面向對象的。為了具有足夠通用性,STL主要依賴于模板而不是封裝,繼承和虛函數(多態性)——OOP的三個要素。你在STL中找不到任何明顯的類繼承關系。這好像是一種倒退,但這正好是使得STL的組件具有廣泛通用性的底層特征。另外,由于STL是基于模板,內聯函數的使用使得生成的代碼短小高效;
從邏輯層次來看,在STL中體現了泛型化程序設計的思想,引入了諸多新的名詞,比如像需求(requirements),概念(concept),模型(model),容器(container),算法(algorithmn),迭代子(iterator)等。與OOP(object-oriented programming)中的多態(polymorphism)一樣,泛型也是一種軟件的復用技術;
從實現層次看,整個STL是以一種類型參數化的方式實現的,這種方式基于一個在早先C++標準中沒有出現的語言特性--模板(template)。
2 STL內容介紹
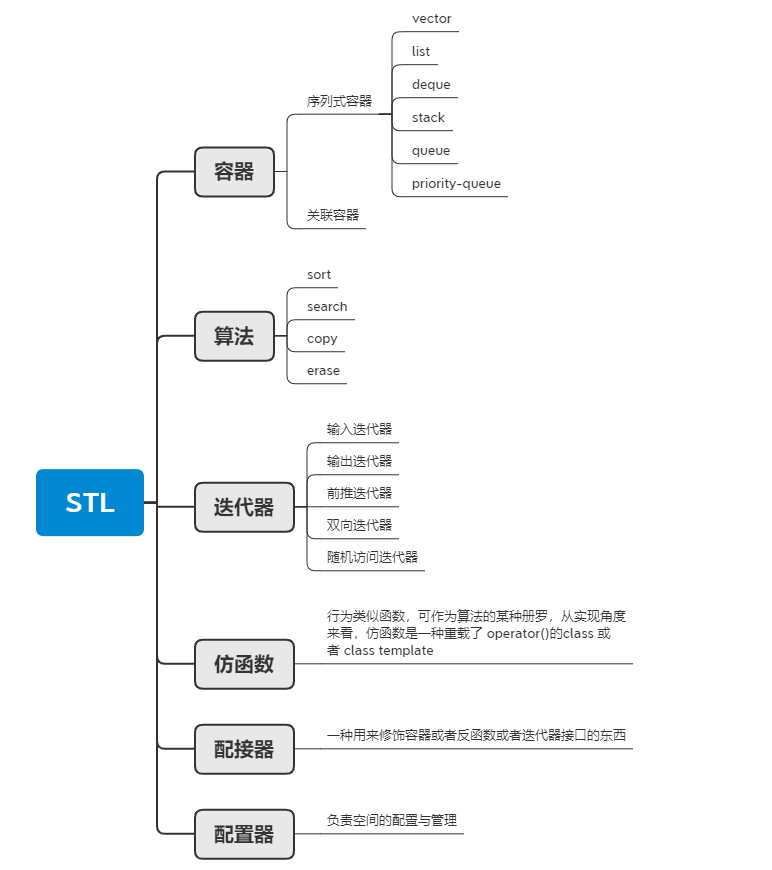
STL中六大組件:
容器(Container),是一種數據結構,如list,vector,和deques ,以模板類的方法提供。為了訪問容器中的數據,可以使用由容器類輸出的迭代器;
迭代器(Iterator),提供了訪問容器中對象的方法。例如,可以使用一對迭代器指定list或vector中的一定范圍的對象。迭代器就如同一個指針。事實上,C++的指針也是一種迭代器。但是,迭代器也可以是那些定義了operator*()以及其他類似于指針的操作符地方法的類對象;
算法(Algorithm),是用來操作容器中的數據的模板函數。例如,STL用sort()來對一個vector中的數據進行排序,用find()來搜索一個list中的對象,函數本身與他們操作的數據的結構和類型無關,因此他們可以在從簡單數組到高度復雜容器的任何數據結構上使用;
仿函數(Functor)
適配器(Adaptor)
分配器(allocator)
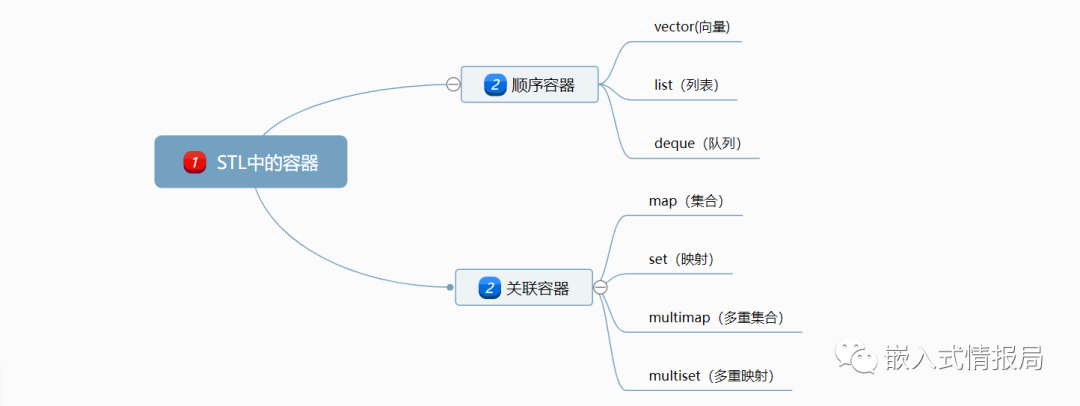
2.1 容器
STL中的容器有隊列容器和關聯容器,容器適配器(congtainer adapters:stack,queue,priority queue),位集(bit_set),串包(string_package)等等。
(1)序列式容器(Sequence containers),每個元素都有固定位置--取決于插入時機和地點,和元素值無關,vector、deque、list;
Vector:將元素置于一個動態數組中加以管理,可以隨機存取元素(用索引直接存取),數組尾部添加或移除元素非常快速。但是在中部或頭部安插元素比較費時;
Deque:是“double-ended queue”的縮寫,可以隨機存取元素(用索引直接存取),數組頭部和尾部添加或移除元素都非常快速。但是在中部或頭部安插元素比較費時;
List:雙向鏈表,不提供隨機存取(按順序走到需存取的元素,O(n)),在任何位置上執行插入或刪除動作都非常迅速,內部只需調整一下指針;
(2)關聯式容器(Associated containers),元素位置取決于特定的排序準則,和插入順序無關,set、multiset、map、multimap等。
Set/Multiset:內部的元素依據其值自動排序,Set內的相同數值的元素只能出現一次,Multisets內可包含多個數值相同的元素,內部由二叉樹實現,便于查找;
Map/Multimap:Map的元素是成對的鍵值/實值,內部的元素依據其值自動排序,Map內的相同數值的元素只能出現一次,Multimaps內可包含多個數值相同的元素,內部由二叉樹實現,便于查找;
容器類自動申請和釋放內存,無需new和delete操作。
2.2 STL迭代器
Iterator(迭代器)模式又稱Cursor(游標)模式,用于提供一種方法順序訪問一個聚合對象中各個元素, 而又不需暴露該對象的內部表示。或者這樣說可能更容易理解:Iterator模式是運用于聚合對象的一種模式,通過運用該模式,使得我們可以在不知道對象內部表示的情況下,按照一定順序(由iterator提供的方法)訪問聚合對象中的各個元素。
迭代器的作用:能夠讓迭代器與算法不干擾的相互發展,最后又能無間隙的粘合起來,重載了*,++,==,!=,=運算符。用以操作復雜的數據結構,容器提供迭代器,算法使用迭代器;常見的一些迭代器類型:iterator、const_iterator、reverse_iterator和const_reverse_iterator.
2.3 算法
函數庫對數據類型的選擇對其可重用性起著至關重要的作用。舉例來說,一個求方根的函數,在使用浮點數作為其參數類型的情況下的可重用性肯定比使用整型作為它的參數類性要高。而C++通過模板的機制允許推遲對某些類型的選擇,直到真正想使用模板或者說對模板進行特化的時候,STL就利用了這一點提供了相當多的有用算法。它是在一個有效的框架中完成這些算法的——你可以將所有的類型劃分為少數的幾類,然后就可以在模版的參數中使用一種類型替換掉同一種類中的其他類型。
STL提供了大約100個實現算法的模版函數,比如算法for_each將為指定序列中的每一個元素調用指定的函數,stable_sort以你所指定的規則對序列進行穩定性排序等等。只要我們熟悉了STL之后,許多代碼可以被大大的化簡,只需要通過調用一兩個算法模板,就可以完成所需要的功能并大大地提升效率。
算法部分主要由頭文件,和組成。
是所有STL頭文件中最大的一個(盡管它很好理解),它是由一大堆模版函數組成的,可以認為每個函數在很大程度上都是獨立的,其中常用到的功能范圍涉及到比較、交換、查找、遍歷操作、復制、修改、移除、反轉、排序、合并等等。
體積很小,只包括幾個在序列上面進行簡單數學運算的模板函數,包括加法和乘法在序列上的一些操作。
中則定義了一些模板類,用以聲明函數對象。
STL中算法大致分為四類:
- 非可變序列算法:指不直接修改其所操作的容器內容的算法。
- 可變序列算法:指可以修改它們所操作的容器內容的算法。
- 排序算法:對序列進行排序和合并的算法、搜索算法以及有序序列上的集合操作。
- 數值算法:對容器內容進行數值計算。
以下對所有算法進行細致分類并標明功能:
<一>查找算法(13個):判斷容器中是否包含某個值
adjacent_find: 在iterator對標識元素范圍內,查找一對相鄰重復元素,找到則返回指向這對元素的第一個元素的 ForwardIterator。否則返回last。重載版本使用輸入的二元操作符代替相等的判斷。
binary_search: 在有序序列中查找value,找到返回true。重載的版本實用指定的比較函數對象或函數指針來判斷相等。
count: 利用等于操作符,把標志范圍內的元素與輸入值比較,返回相等元素個數。
count_if: 利用輸入的操作符,對標志范圍內的元素進行操作,返回結果為true的個數。
equal_range: 功能類似equal,返回一對iterator,第一個表示lower_bound,第二個表示upper_bound。
find: 利用底層元素的等于操作符,對指定范圍內的元素與輸入值進行比較。當匹配時,結束搜索,返回該元素的 一個InputIterator。
find_end: 在指定范圍內查找"由輸入的另外一對iterator標志的第二個序列"的最后一次出現。找到則返回最后一對的第一 個ForwardIterator,否則返回輸入的"另外一對"的第一個ForwardIterator。重載版本使用用戶輸入的操作符代 替等于操作。
find_first_of: 在指定范圍內查找"由輸入的另外一對iterator標志的第二個序列"中任意一個元素的第一次出現。重載版本中使 用了用戶自定義操作符。
find_if: 使用輸入的函數代替等于操作符執行find。
lower_bound: 返回一個ForwardIterator,指向在有序序列范圍內的可以插入指定值而不破壞容器順序的第一個位置。重載函 數使用自定義比較操作。
upper_bound: 返回一個ForwardIterator,指向在有序序列范圍內插入value而不破壞容器順序的最后一個位置,該位置標志 一個大于value的值。重載函數使用自定義比較操作。
search: 給出兩個范圍,返回一個ForwardIterator,查找成功指向第一個范圍內第一次出現子序列(第二個范圍)的位 置,查找失敗指向last1。重載版本使用自定義的比較操作。
search_n: 在指定范圍內查找val出現n次的子序列。重載版本使用自定義的比較操作。
<二>排序和通用算法(14個):提供元素排序策略
inplace_merge: 合并兩個有序序列,結果序列覆蓋兩端范圍。重載版本使用輸入的操作進行排序。
merge: 合并兩個有序序列,存放到另一個序列。重載版本使用自定義的比較。
nth_element: 將范圍內的序列重新排序,使所有小于第n個元素的元素都出現在它前面,而大于它的都出現在后面。重 載版本使用自定義的比較操作。
partial_sort: 對序列做部分排序,被排序元素個數正好可以被放到范圍內。重載版本使用自定義的比較操作。
partial_sort_copy: 與partial_sort類似,不過將經過排序的序列復制到另一個容器。
partition: 對指定范圍內元素重新排序,使用輸入的函數,把結果為true的元素放在結果為false的元素之前。
random_shuffle: 對指定范圍內的元素隨機調整次序。重載版本輸入一個隨機數產生操作。
reverse: 將指定范圍內元素重新反序排序。
reverse_copy: 與reverse類似,不過將結果寫入另一個容器。
rotate: 將指定范圍內元素移到容器末尾,由middle指向的元素成為容器第一個元素。
rotate_copy: 與rotate類似,不過將結果寫入另一個容器。
sort: 以升序重新排列指定范圍內的元素。重載版本使用自定義的比較操作。
stable_sort: 與sort類似,不過保留相等元素之間的順序關系。
stable_partition: 與partition類似,不過不保證保留容器中的相對順序。
<三>刪除和替換算法(15個)
copy: 復制序列
copy_backward: 與copy相同,不過元素是以相反順序被拷貝。
iter_swap: 交換兩個ForwardIterator的值。
remove: 刪除指定范圍內所有等于指定元素的元素。注意,該函數不是真正刪除函數。內置函數不適合使用remove和 remove_if函數。
remove_copy: 將所有不匹配元素復制到一個制定容器,返回OutputIterator指向被拷貝的末元素的下一個位置。
remove_if: 刪除指定范圍內輸入操作結果為true的所有元素。
remove_copy_if: 將所有不匹配元素拷貝到一個指定容器。
replace: 將指定范圍內所有等于vold的元素都用vnew代替。
replace_copy: 與replace類似,不過將結果寫入另一個容器。
replace_if: 將指定范圍內所有操作結果為true的元素用新值代替。
replace_copy_if: 與replace_if,不過將結果寫入另一個容器。
swap: 交換存儲在兩個對象中的值。
swap_range: 將指定范圍內的元素與另一個序列元素值進行交換。
unique: 清除序列中重復元素,和remove類似,它也不能真正刪除元素。重載版本使用自定義比較操作。
unique_copy: 與unique類似,不過把結果輸出到另一個容器。
<四>排列組合算法(2個):提供計算給定集合按一定順序的所有可能排列組合
next_permutation: 取出當前范圍內的排列,并重新排序為下一個排列。重載版本使用自定義的比較操作。
prev_permutation: 取出指定范圍內的序列并將它重新排序為上一個序列。如果不存在上一個序列則返回false。重載版本使用 自定義的比較操作。
<五>算術算法(4個)
accumulate: iterator對標識的序列段元素之和,加到一個由val指定的初始值上。重載版本不再做加法,而是傳進來的 二元操作符被應用到元素上。
partial_sum: 創建一個新序列,其中每個元素值代表指定范圍內該位置前所有元素之和。重載版本使用自定義操作代 替加法。
inner_product: 對兩個序列做內積(對應元素相乘,再求和)并將內積加到一個輸入的初始值上。重載版本使用用戶定義 的操作。
adjacent_difference: 創建一個新序列,新序列中每個新值代表當前元素與上一個元素的差。重載版本用指定二元操作計算相 鄰元素的差。
<六>生成和異變算法(6個)
fill: 將輸入值賦給標志范圍內的所有元素。
fill_n: 將輸入值賦給first到first+n范圍內的所有元素。
for_each: 用指定函數依次對指定范圍內所有元素進行迭代訪問,返回所指定的函數類型。該函數不得修改序列中的元素。
generate: 連續調用輸入的函數來填充指定的范圍。
generate_n: 與generate函數類似,填充從指定iterator開始的n個元素。
transform: 將輸入的操作作用與指定范圍內的每個元素,并產生一個新的序列。重載版本將操作作用在一對元素上,另外一 個元素來自輸入的另外一個序列。結果輸出到指定容器。
<七>關系算法(8個)
equal: 如果兩個序列在標志范圍內元素都相等,返回true。重載版本使用輸入的操作符代替默認的等于操 作符。
includes: 判斷第一個指定范圍內的所有元素是否都被第二個范圍包含,使用底層元素的<操作符,成功返回 true。重載版本使用用戶輸入的函數。
lexicographical_compare: 比較兩個序列。重載版本使用用戶自定義比較操作。
max: 返回兩個元素中較大一個。重載版本使用自定義比較操作。
max_element: 返回一個ForwardIterator,指出序列中最大的元素。重載版本使用自定義比較操作。
min: 返回兩個元素中較小一個。重載版本使用自定義比較操作。
min_element: 返回一個ForwardIterator,指出序列中最小的元素。重載版本使用自定義比較操作。
mismatch: 并行比較兩個序列,指出第一個不匹配的位置,返回一對iterator,標志第一個不匹配元素位置。 如果都匹配,返回每個容器的last。重載版本使用自定義的比較操作。
<八>集合算法(4個)
set_union: 構造一個有序序列,包含兩個序列中所有的不重復元素。重載版本使用自定義的比較操作。
set_intersection: 構造一個有序序列,其中元素在兩個序列中都存在。重載版本使用自定義的比較操作。
set_difference: 構造一個有序序列,該序列僅保留第一個序列中存在的而第二個中不存在的元素。重載版本使用 自定義的比較操作。
set_symmetric_difference: 構造一個有序序列,該序列取兩個序列的對稱差集(并集-交集)。
<九>堆算法(4個)
make_heap: 把指定范圍內的元素生成一個堆。重載版本使用自定義比較操作。
pop_heap: 并不真正把最大元素從堆中彈出,而是重新排序堆。它把first和last-1交換,然后重新生成一個堆。可使用容器的 back來訪問被"彈出"的元素或者使用pop_back進行真正的刪除。重載版本使用自定義的比較操作。
push_heap: 假設first到last-1是一個有效堆,要被加入到堆的元素存放在位置last-1,重新生成堆。在指向該函數前,必須先把 元素插入容器后。重載版本使用指定的比較操作。
sort_heap: 對指定范圍內的序列重新排序,它假設該序列是個有序堆。重載版本使用自定義比較操作。
2.4 仿函數
2.4.1 概述
仿函數(functor),就是使一個類的使用看上去象一個函數。其實現就是類中實現一個operator(),這個類就有了類似函數的行為,就是一個仿函數類了。
有些功能的的代碼,會在不同的成員函數中用到,想復用這些代碼。
1)公共的函數,可以,這是一個解決方法,不過函數用到的一些變量,就可能成為公共的全局變量,再說為了復用這么一片代碼,就要單立出一個函數,也不是很好維護。
2)仿函數,寫一個簡單類,除了那些維護一個類的成員函數外,就只是實現一個operator(),在類實例化時,就將要用的,非參數的元素傳入類中。
2.4.2 仿函數(functor)在編程語言中的應用
1)C語言使用函數指針和回調函數來實現仿函數,例如一個用來排序的函數可以這樣使用仿函數
#include < stdio.h >
#include < stdlib.h >
//int sort_function( const void *a, const void *b);
int sort_function( const void *a, const void *b)
{
return *(int*)a-*(int*)b;
}
int main()
{
int list[5] = { 54, 21, 11, 67, 22 };
qsort((void *)list, 5, sizeof(list[0]), sort_function);//起始地址,個數,元素大小,回調函數
int x;
for (x = 0; x < 5; x++)
printf("%in", list[x]);
return 0;
}
2)在C++里,我們通過在一個類中重載括號運算符的方法使用一個函數對象而不是一個普通函數。
#include < iostream >
#include < algorithm >
using namespace std;
template< typename T >
class display
{
public:
void operator()(const T &x)
{
cout < < x < < " ";
}
};
int main()
{
int ia[] = { 1,2,3,4,5 };
for_each(ia, ia + 5, display< int >());
system("pause");
return 0;
}
2.4.3 仿函數在STL中的定義
要使用STL內建的仿函數,必須包含頭文件。而頭文件中包含的仿函數分類包括
1)算術類仿函數
加:plus
減:minus
乘:multiplies
除:divides
模取:modulus
否定:negate
例子:
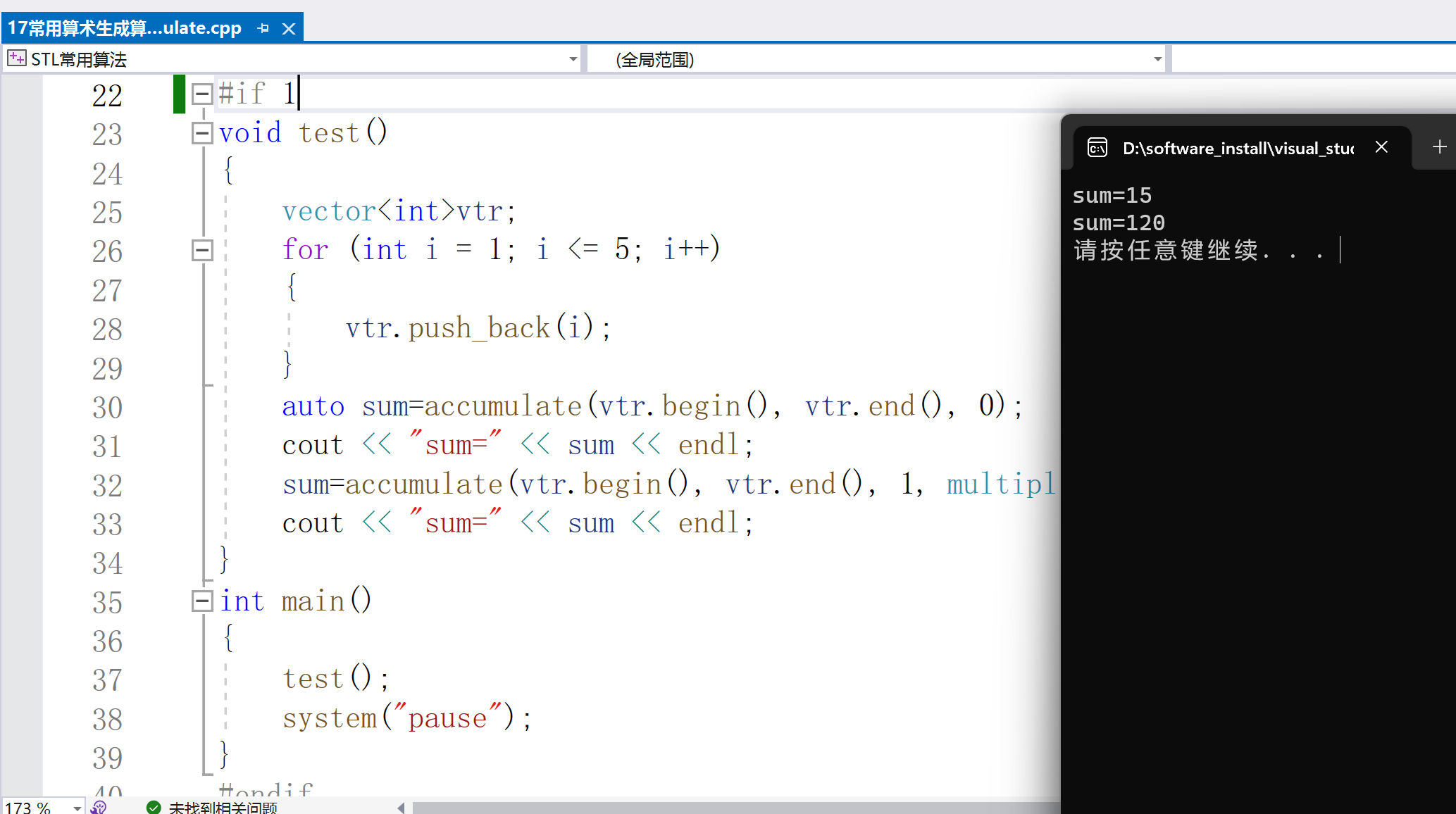
#include < iostream >
#include < numeric >
#include < vector >
#include < functional >
using namespace std;
int main()
{
int ia[] = { 1,2,3,4,5 };
vector< int > iv(ia, ia + 5);
//120
cout < < accumulate(iv.begin(), iv.end(), 1, multiplies< int >()) < < endl;
//15
cout < < multiplies< int >()(3, 5) < < endl;
modulus< int > modulusObj;
cout < < modulusObj(3, 5) < < endl; // 3
system("pause");
return 0;
}
2)關系運算類仿函數
等于:equal_to
不等于:not_equal_to
大于:greater
大于等于:greater_equal
小于:less
小于等于:less_equal
從大到小排序:
#include < iostream >
#include < algorithm >
#include< functional >
#include < vector >
using namespace std;
template < class T >
class display
{
public:
void operator()(const T &x)
{
cout < < x < < " ";
}
};
int main()
{
int ia[] = { 1,5,4,3,2 };
vector< int > iv(ia, ia + 5);
sort(iv.begin(), iv.end(), greater< int >());
for_each(iv.begin(), iv.end(), display< int >());
system("pause");
return 0;
}
3)邏輯運算仿函數
邏輯與:logical_and
邏輯或:logical_or
邏輯否:logical_no
除了使用STL內建的仿函數,還可使用自定義的仿函數,具體實例見文章3.4.7.2小結
2.5 容器適配器
標準庫提供了三種順序容器適配器:queue(FIFO隊列)、priority_queue(優先級隊列)、stack(棧)
什么是容器適配器
適配器是使一種事物的行為類似于另外一種事物行為的一種機制”,適配器對容器進行包裝,使其表現出另外一種行為。例 如,stack >實現了棧的功能,但其內部使用順序容器vector來存儲數據。(相當于是vector表現出 了棧的行為)。
容器適配器
要使用適配器,需要加入一下頭文件:
#include //stack
#include //queue、priority_queue
- 定義適配器
1、初始化
stack stk(dep);
2、覆蓋默認容器類型
stack > stk;
- 使用適配器
2.5.1 stack
stack< int > s;
stack< int, vector< int > > stk; //覆蓋基礎容器類型,使用vector實現stk
s.empty(); //判斷stack是否為空,為空返回true,否則返回false
s.size(); //返回stack中元素的個數
s.pop(); //刪除棧頂元素,但不返回其值
s.top(); //返回棧頂元素的值,但不刪除此元素
s.push(item); //在棧頂壓入新元素item
實例:括號匹配
#include< iostream >
#include< cstdio >
#include< string >
#include< stack >
using namespace std;
int main()
{
string s;
stack< char > ss;
while (cin > > s)
{
bool flag = true;
for (char c : s) //C++11新標準,即遍歷一次字符串s
{
if (c == '(' || c == '{' || c == '[')
{
ss.push(c);
continue;
}
if (c == '}')
{
if (!ss.empty() && ss.top() == '{')
{
ss.pop();
continue;
}
else
{
flag = false;
break;
}
}
if (!ss.empty() && c == ']')
{
if (ss.top() == '[')
{
ss.pop();
continue;
}
else
{
flag = false;
break;
}
}
if (!ss.empty() && c == ')')
{
if (ss.top() == '(')
{
ss.pop();
continue;
}
else
{
flag = false;
break;
}
}
}
if (flag) cout < < "Match!" < < endl;
else cout < < "Not Match!" < < endl;
}
}
2.5.2 queue & priority_queue
queue< int > q; //priority_queue< int > q;
q.empty(); //判斷隊列是否為空
q.size(); //返回隊列長度
q.push(item); //對于queue,在隊尾壓入一個新元素
//對于priority_queue,在基于優先級的適當位置插入新元素
//queue only:
q.front(); //返回隊首元素的值,但不刪除該元素
q.back(); //返回隊尾元素的值,但不刪除該元素
//priority_queue only:
q.top(); //返回具有最高優先級的元素值,但不刪除該元素
3 常用容器用法介紹
3.1 vector
3.1.1 基本函數實現
1.構造函數
- vector():創建一個空vector
- vector(int nSize):創建一個vector,元素個數為nSize
- vector(int nSize,const t& t):創建一個vector,元素個數為nSize,且值均為t
- vector(const vector&):復制構造函數
- vector(begin,end):復制[begin,end)區間內另一個數組的元素到vector中
2.增加函數
- void push_back(const T& x):向量尾部增加一個元素X
- iterator insert(iterator it,const T& x):向量中迭代器指向元素前增加一個元素x
- iterator insert(iterator it,int n,const T& x):向量中迭代器指向元素前增加n個相同的元素x
- iterator insert(iterator it,const_iterator first,const_iterator last):向量中迭代器指向元素前插入另一個相同類型向量的[first,last)間的數據
3.刪除函數
- iterator erase(iterator it):刪除向量中迭代器指向元素
- iterator erase(iterator first,iterator last):刪除向量中[first,last)中元素
- void pop_back():刪除向量中最后一個元素
- void clear():清空向量中所有元素
4.遍歷函數
- reference at(int pos):返回pos位置元素的引用
- reference front():返回首元素的引用
- reference back():返回尾元素的引用
- iterator begin():返回向量頭指針,指向第一個元素
- iterator end():返回向量尾指針,指向向量最后一個元素的下一個位置
- reverse_iterator rbegin():反向迭代器,指向最后一個元素
- reverse_iterator rend():反向迭代器,指向第一個元素之前的位置
5.判斷函數
- bool empty() const:判斷向量是否為空,若為空,則向量中無元素
6.大小函數
- int size() const:返回向量中元素的個數
- int capacity() const:返回當前向量張紅所能容納的最大元素值
- int max_size() const:返回最大可允許的vector元素數量值
7.其他函數
- void swap(vector&):交換兩個同類型向量的數據
- void assign(int n,const T& x):設置向量中第n個元素的值為x
- void assign(const_iterator first,const_iterator last):向量中[first,last)中元素設置成當前向量元素
8.看著清楚
1.push_back 在數組的最后添加一個數據
2.pop_back 去掉數組的最后一個數據
.at-Domain Parked 得到編號位置的數據
4.begin 得到數組頭的指針
5.end 得到數組的最后一個單元+1的指針
6.front 得到數組頭的引用
7.back 得到數組的最后一個單元的引用
8.max_size 得到vector最大可以是多大
9.capacity 當前vector分配的大小
10.size 當前使用數據的大小
11.resize 改變當前使用數據的大小,如果它比當前使用的大,者填充默認值
12.reserve 改變當前vecotr所分配空間的大小
13.erase 刪除指針指向的數據項
14.clear 清空當前的vector
15.rbegin 將vector反轉后的開始指針返回(其實就是原來的end-1)
16.rend 將vector反轉構的結束指針返回(其實就是原來的begin-1)
17.empty 判斷vector是否為空
18.swap 與另一個vector交換數據
3.1.2 基本用法
#include < vector >
using namespace std;
3.1.3 簡單介紹
- Vector<類型>標識符
- Vector<類型>標識符(最大容量)
- Vector<類型>標識符(最大容量,初始所有值)
- Int i[5]={1,2,3,4,5}
- Vector<類型>vi(I,i+2);//得到i索引值為3以后的值
- Vector< vector< int> >v; 二維向量//這里最外的<>要有空格。否則在比較舊的編譯器下無法通過
3.1.4 實例
3.1.4.1 pop_back()&push_back(elem)實例在容器最后移除和插入數據
#include < string.h >
#include < vector >
#include < iostream >
using namespace std;
int main()
{
vector< int >obj;//創建一個向量存儲容器 int
for(int i=0;i< 10;i++) // push_back(elem)在數組最后添加數據
{
obj.push_back(i);
cout<
輸出結果為:
0,1,2,3,4,5,6,7,8,9,
0,1,2,3,4,
3.1.4.2 clear()清除容器中所有數據
#include < string.h >
#include < vector >
#include < iostream >
using namespace std;
int main()
{
vector< int >obj;
for(int i=0;i< 10;i++)//push_back(elem)在數組最后添加數據
{
obj.push_back(i);
cout<
輸出結果為:
0,1,2,3,4,5,6,7,8,9,
3.1.4.3 排序
#include < string.h >
#include < vector >
#include < iostream >
#include < algorithm >
using namespace std;
int main()
{
vector< int >obj;
obj.push_back(1);
obj.push_back(3);
obj.push_back(0);
sort(obj.begin(),obj.end());//從小到大
cout< "從小到大:"<
輸出結果為:
從小到大:
0,1,3,
從大到小:
3,1,0,
1.注意 sort 需要頭文件 #include
2.如果想 sort 來降序,可重寫 sort
bool compare(int a,int b)
{
return a< b; //升序排列,如果改為return a >b,則為降序
}
int a[20]={2,4,1,23,5,76,0,43,24,65},i;
for(i=0;i< 20;i++)
cout< < a[i]< < endl;
sort(a,a+20,compare);
3.1.4.4 訪問(直接數組訪問&迭代器訪問)
#include < string.h >
#include < vector >
#include < iostream >
#include < algorithm >
using namespace std;
int main()
{
//順序訪問
vector< int >obj;
for(int i=0;i< 10;i++)
{
obj.push_back(i);
}
cout< "直接利用數組:";
for(int i=0;i< 10;i++)//方法一
{
cout<
輸出結果為:
直接利用數組:0 1 2 3 4 5 6 7 8 9
利用迭代器:0 1 2 3 4 5 6 7 8 9
3.1.4.5 二維數組兩種定義方法(結果一樣)
方法一
#include < string.h >
#include < vector >
#include < iostream >
#include < algorithm >
using namespace std;
int main()
{
int N=5, M=6;
vector< vector< int > > obj(N); //定義二維動態數組大小5行
for(int i =0; i< obj.size(); i++)//動態二維數組為5行6列,值全為0
{
obj[i].resize(M);
}
for(int i=0; i< obj.size(); i++)//輸出二維動態數組
{
for(int j=0;j< obj[i].size();j++)
{
cout<
方法二
#include < string.h >
#include < vector >
#include < iostream >
#include < algorithm >
using namespace std;
int main()
{
int N=5, M=6;
vector< vector< int > > obj(N, vector< int >(M)); //定義二維動態數組5行6列
for(int i=0; i< obj.size(); i++)//輸出二維動態數組
{
for(int j=0;j< obj[i].size();j++)
{
cout<
輸出結果為:
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
3.2 deque
所謂的deque是”double ended queue”的縮寫,雙端隊列不論在尾部或頭部插入元素,都十分迅速。而在中間插入元素則會比較費時,因為必須移動中間其他的元素。雙端隊列是一種隨機訪問的數據類型,提供了在序列兩端快速插入和刪除操作的功能,它可以在需要的時候改變自身大小,完成了標準的C++數據結構中隊列的所有功能。
Vector是單向開口的連續線性空間,deque則是一種雙向開口的連續線性空間。deque對象在隊列的兩端放置元素和刪除元素是高效的,而向量vector只是在插入序列的末尾時操作才是高效的。deque和vector的最大差異,一在于deque允許于常數時間內對頭端進行元素的插入或移除操作,二在于deque沒有所謂的capacity觀念,因為它是動態地以分段連續空間組合而成,隨時可以增加一段新的空間并鏈接起來。換句話說,像vector那樣“因舊空間不足而重新配置一塊更大空間,然后復制元素,再釋放舊空間”這樣的事情在deque中是不會發生的。也因此,deque沒有必要提供所謂的空間預留(reserved)功能。
雖然deque也提供Random Access Iterator,但它的迭代器并不是普通指針,其復雜度和vector不可同日而語,這當然涉及到各個運算層面。因此,除非必要,我們應盡可能選擇使用vector而非deque。對deque進行的排序操作,為了最高效率,可將deque先完整復制到一個vector身上,將vector排序后(利用STL的sort算法),再復制回deque。
deque是一種優化了的對序列兩端元素進行添加和刪除操作的基本序列容器。通常由一些獨立的區塊組成,第一區塊朝某方向擴展,最后一個區塊朝另一方向擴展。它允許較為快速地隨機訪問但它不像vector一樣把所有對象保存在一個連續的內存塊,而是多個連續的內存塊。并且在一個映射結構中保存對這些塊以及順序的跟蹤。
3.2.1 聲明deque容器
#include< deque > // 頭文件
deque< type > deq; // 聲明一個元素類型為type的雙端隊列que
deque< type > deq(size); // 聲明一個類型為type、含有size個默認值初始化元素的的雙端隊列que
deque< type > deq(size, value); // 聲明一個元素類型為type、含有size個value元素的雙端隊列que
deque< type > deq(mydeque); // deq是mydeque的一個副本
deque< type > deq(first, last); // 使用迭代器first、last范圍內的元素初始化deq
3.2.2 deque的常用成員函數
deque< int > deq;
- deq[ ]:用來訪問雙向隊列中單個的元素。
- deq.front():返回第一個元素的引用。
- deq.back():返回最后一個元素的引用。
- deq.push_front(x):把元素x插入到雙向隊列的頭部。
- deq.pop_front():彈出雙向隊列的第一個元素。
- deq.push_back(x):把元素x插入到雙向隊列的尾部。
- deq.pop_back():彈出雙向隊列的最后一個元素。
3.2.3 deque的一些特點
- 支持隨機訪問,即支持[ ]以及at(),但是性能沒有vector好。
- 可以在內部進行插入和刪除操作,但性能不及list。
- deque兩端都能夠快速插入和刪除元素,而vector只能在尾端進行。
- deque的元素存取和迭代器操作會稍微慢一些,因為deque的內部結構會多一個間接過程。
- deque迭代器是特殊的智能指針,而不是一般指針,它需要在不同的區塊之間跳轉。
- deque可以包含更多的元素,其max_size可能更大,因為不止使用一塊內存。
- deque不支持對容量和內存分配時機的控制。
- 在除了首尾兩端的其他地方插入和刪除元素,都將會導致指向deque元素的任何pointers、references、iterators失效。不過,deque的內存重分配優于vector,因為其內部結構顯示不需要復制所有元素。
- deque的內存區塊不再被使用時,會被釋放,deque的內存大小是可縮減的。不過,是不是這么做以及怎么做由實際操作版本定義。
- deque不提供容量操作:capacity()和reverse(),但是vector可以。
3.2.4 實例
#include< iostream >
#include< stdio.h >
#include< deque >
using namespace std;
int main(void)
{
int i;
int a[10] = { 0,1,2,3,4,5,6,7,8,9 };
deque< int > q;
for (i = 0; i <= 9; i++)
{
if (i % 2 == 0)
q.push_front(a[i]);
else
q.push_back(a[i]);
} /*此時隊列里的內容是: {8,6,4,2,0,1,3,5,7,9}*/
q.pop_front();
printf("%dn", q.front()); /*清除第一個元素后輸出第一個(6)*/
q.pop_back();
printf("%dn", q.back()); /*清除最后一個元素后輸出最后一個(7)*/
deque< int >::iterator it;
for (it = q.begin(); it != q.end(); it++) {
cout < < *it < < 't';
}
cout < < endl;
system("pause");
return 0;
}
輸出結果:
3.3 list
3.3.1 list定義
List是stl實現的雙向鏈表,與向量(vectors)相比, 它允許快速的插入和刪除,但是隨機訪問卻比較慢。使用時需要添加頭文件
#include
3.3.2 list定義和初始化
listlst1; //創建空list
list lst2(5); //創建含有5個元素的list
listlst3(3,2); //創建含有3個元素的list
listlst4(lst2); //使用lst2初始化lst4
listlst5(lst2.begin(),lst2.end()); //同lst4
3.3.3 list常用操作函數
Lst1.assign() 給list賦值
Lst1.back() 返回最后一個元素
Lst1.begin() 返回指向第一個元素的迭代器
Lst1.clear() 刪除所有元素
Lst1.empty() 如果list是空的則返回true
Lst1.end() 返回末尾的迭代器
Lst1.erase() 刪除一個元素
Lst1.front() 返回第一個元素
Lst1.get_allocator() 返回list的配置器
Lst1.insert() 插入一個元素到list中
Lst1.max_size() 返回list能容納的最大元素數量
Lst1.merge() 合并兩個list
Lst1.pop_back() 刪除最后一個元素
Lst1.pop_front() 刪除第一個元素
Lst1.push_back() 在list的末尾添加一個元素
Lst1.push_front() 在list的頭部添加一個元素
Lst1.rbegin() 返回指向第一個元素的逆向迭代器
Lst1.remove() 從list刪除元素
Lst1.remove_if() 按指定條件刪除元素
Lst1.rend() 指向list末尾的逆向迭代器
Lst1.resize() 改變list的大小
Lst1.reverse() 把list的元素倒轉
Lst1.size() 返回list中的元素個數
Lst1.sort() 給list排序
Lst1.splice() 合并兩個list
Lst1.swap() 交換兩個list
Lst1.unique() 刪除list中相鄰重復的元素
3.3.4 List使用實例
3.3.4.1 迭代器遍歷list
for(list< int >::const_iteratoriter = lst1.begin();iter != lst1.end();iter++)
{
cout< iter;
}
cout<
3.3.4.2 綜合實例1
#include < iostream >
#include < list >
#include < numeric >
#include < algorithm >
using namespace std;
typedef list< int > LISTINT;
typedef list< int > LISTCHAR;
void main()
{
//用LISTINT創建一個list對象
LISTINT listOne;
//聲明i為迭代器
LISTINT::iterator i;
listOne.push_front(3);
listOne.push_front(2);
listOne.push_front(1);
listOne.push_back(4);
listOne.push_back(5);
listOne.push_back(6);
cout < < "listOne.begin()--- listOne.end():" < < endl;
for (i = listOne.begin(); i != listOne.end(); ++i)
cout < < *i < < " ";
cout < < endl;
LISTINT::reverse_iterator ir;
cout < < "listOne.rbegin()---listOne.rend():" < < endl;
for (ir = listOne.rbegin(); ir != listOne.rend(); ir++) {
cout < < *ir < < " ";
}
cout < < endl;
int result = accumulate(listOne.begin(), listOne.end(), 0);
cout < < "Sum=" < < result < < endl;
cout < < "------------------" < < endl;
//用LISTCHAR創建一個list對象
LISTCHAR listTwo;
//聲明i為迭代器
LISTCHAR::iterator j;
listTwo.push_front('C');
listTwo.push_front('B');
listTwo.push_front('A');
listTwo.push_back('D');
listTwo.push_back('E');
listTwo.push_back('F');
cout < < "listTwo.begin()---listTwo.end():" < < endl;
for (j = listTwo.begin(); j != listTwo.end(); ++j)
cout < < char(*j) < < " ";
cout < < endl;
j = max_element(listTwo.begin(), listTwo.end());
cout < < "The maximum element in listTwo is: " < < char(*j) < < endl;
system("pause");
}
輸出結果
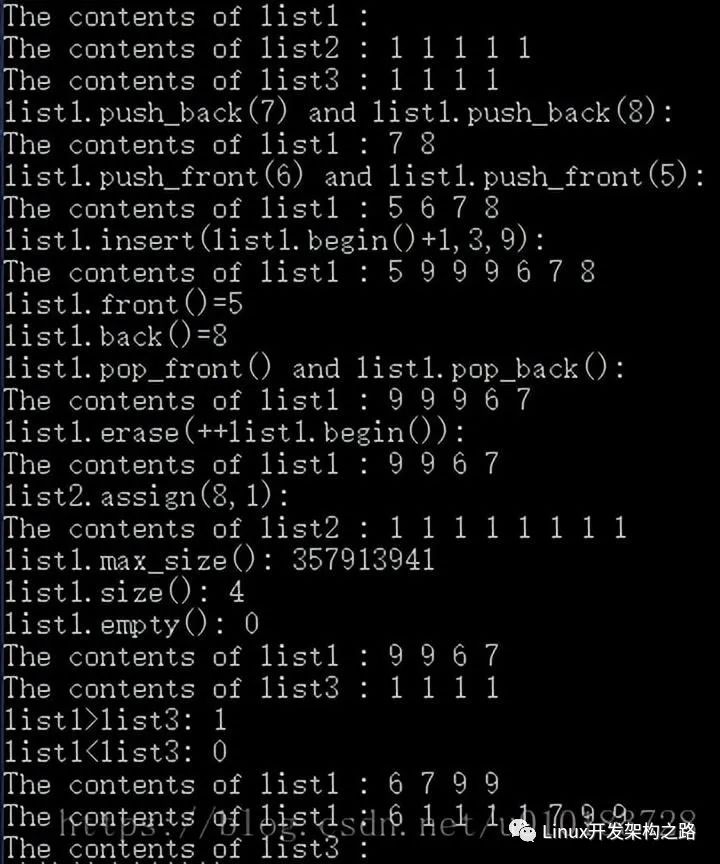
3.3.4.3 綜合實例2
#include < iostream >
#include < list >
using namespace std;
typedef list< int > INTLIST;
//從前向后顯示list隊列的全部元素
void put_list(INTLIST list, char *name)
{
INTLIST::iterator plist;
cout < < "The contents of " < < name < < " : ";
for (plist = list.begin(); plist != list.end(); plist++)
cout < < *plist < < " ";
cout < < endl;
}
//測試list容器的功能
void main(void)
{
//list1對象初始為空
INTLIST list1;
INTLIST list2(5, 1);
INTLIST list3(list2.begin(), --list2.end());
//聲明一個名為i的雙向迭代器
INTLIST::iterator i;
put_list(list1, "list1");
put_list(list2, "list2");
put_list(list3, "list3");
list1.push_back(7);
list1.push_back(8);
cout < < "list1.push_back(7) and list1.push_back(8):" < < endl;
put_list(list1, "list1");
list1.push_front(6);
list1.push_front(5);
cout < < "list1.push_front(6) and list1.push_front(5):" < < endl;
put_list(list1, "list1");
list1.insert(++list1.begin(), 3, 9);
cout < < "list1.insert(list1.begin()+1,3,9):" < < endl;
put_list(list1, "list1");
//測試引用類函數
cout < < "list1.front()=" < < list1.front() < < endl;
cout < < "list1.back()=" < < list1.back() < < endl;
list1.pop_front();
list1.pop_back();
cout < < "list1.pop_front() and list1.pop_back():" < < endl;
put_list(list1, "list1");
list1.erase(++list1.begin());
cout < < "list1.erase(++list1.begin()):" < < endl;
put_list(list1, "list1");
list2.assign(8, 1);
cout < < "list2.assign(8,1):" < < endl;
put_list(list2, "list2");
cout < < "list1.max_size(): " < < list1.max_size() < < endl;
cout < < "list1.size(): " < < list1.size() < < endl;
cout < < "list1.empty(): " < < list1.empty() < < endl;
put_list(list1, "list1");
put_list(list3, "list3");
cout < < "list1 >list3: " < < (list1 > list3) < < endl;
cout < < "list1< list3: " < < (list1 < list3) < < endl;
list1.sort();
put_list(list1, "list1");
list1.splice(++list1.begin(), list3);
put_list(list1, "list1");
put_list(list3, "list3");
system("pause");
}
輸出結果:
3.4 map/multimap
map和multimap都需要#include,唯一的不同是,map的鍵值key不可重復,而multimap可以,也正是由于這種區別,map支持[ ]運算符,multimap不支持[ ]運算符。在用法上沒什么區別。
C++中map提供的是一種鍵值對容器,里面的數據都是成對出現的,如下圖:每一對中的第一個值稱之為關鍵字(key),每個關鍵字只能在map中出現一次;第二個稱之為該關鍵字的對應值。

Map是STL的一個關聯容器,它提供一對一(其中第一個可以稱為關鍵字,每個關鍵字只能在map中出現一次,第二個可能稱為該關鍵字的值)的數據 處理能力,由于這個特性,它完成有可能在我們處理一對一數據的時候,在編程上提供快速通道。這里說下map內部數據的組織,map內部自建一顆紅黑樹(一 種非嚴格意義上的平衡二叉樹),這顆樹具有對數據自動排序的功能,所以在map內部所有的數據都是有序的。
3.4.1 基本操作函數
begin() 返回指向map頭部的迭代器
clear() 刪除所有元素
count() 返回指定元素出現的次數
empty() 如果map為空則返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊條目的迭代器對
erase() 刪除一個元素
find() 查找一個元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比較元素key的函數
lower_bound() 返回鍵值>=給定元素的第一個位置
max_size() 返回可以容納的最大元素個數
rbegin() 返回一個指向map尾部的逆向迭代器
rend() 返回一個指向map頭部的逆向迭代器
size() 返回map中元素的個數
swap() 交換兩個map
upper_bound() 返回鍵值>給定元素的第一個位置
value_comp() 返回比較元素value的函數
3.4.2 聲明
//頭文件
#include< map >
map< int, string > ID_Name;
// 使用{}賦值是從c++11開始的,因此編譯器版本過低時會報錯,如visual studio 2012
map< int, string > ID_Name = {
{ 2015, "Jim" },
{ 2016, "Tom" },
{ 2017, "Bob" } };
3.4.3 迭代器
共有八個獲取迭代器的函數:* begin, end, rbegin,rend* 以及對應的 * cbegin, cend, crbegin,crend*。
二者的區別在于,后者一定返回 const_iterator,而前者則根據map的類型返回iterator 或者 const_iterator。const情況下,不允許對值進行修改。如下面代碼所示:
map< int,int >::iterator it;
map< int,int > mmap;
const map< int,int > const_mmap;
it = mmap.begin(); //iterator
mmap.cbegin(); //const_iterator
const_mmap.begin(); //const_iterator
const_mmap.cbegin(); //const_iterator
返回的迭代器可以進行加減操作,此外,如果map為空,則 begin = end。

3.4.4 插入操作
3.4.4.1 用insert插入pair數據
//數據的插入--第一種:用insert函數插入pair數據
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
mapStudent.insert(pair< int, string >(1, "student_one"));
mapStudent.insert(pair< int, string >(2, "student_two"));
mapStudent.insert(pair< int, string >(3, "student_three"));
map< int, string >::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<
3.4.4.2 用insert函數插入value_type數據
//第二種:用insert函數插入value_type數據,下面舉例說明
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
mapStudent.insert(map< int, string >::value_type (1, "student_one"));
mapStudent.insert(map< int, string >::value_type (2, "student_two"));
mapStudent.insert(map< int, string >::value_type (3, "student_three"));
map< int, string >::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<
3.4.4.3 用insert函數進行多個插入
insert共有4個重載函數:
// 插入單個鍵值對,并返回插入位置和成功標志,插入位置已經存在值時,插入失敗
pair< iterator,bool > insert (const value_type& val);
//在指定位置插入,在不同位置插入效率是不一樣的,因為涉及到重排
iterator insert (const_iterator position, const value_type& val);
// 插入多個
void insert (InputIterator first, InputIterator last);
//c++11開始支持,使用列表插入多個
void insert (initializer_list< value_type > il);
下面是具體使用示例:
#include < iostream >
#include < map >
int main()
{
std::map< char, int > mymap;
// 插入單個值
mymap.insert(std::pair< char, int >('a', 100));
mymap.insert(std::pair< char, int >('z', 200));
//返回插入位置以及是否插入成功
std::pair< std::map< char, int >::iterator, bool > ret;
ret = mymap.insert(std::pair< char, int >('z', 500));
if (ret.second == false) {
std::cout < < "element 'z' already existed";
std::cout < < " with a value of " < < ret.first- >second < < 'n';
}
//指定位置插入
std::map< char, int >::iterator it = mymap.begin();
mymap.insert(it, std::pair< char, int >('b', 300)); //效率更高
mymap.insert(it, std::pair< char, int >('c', 400)); //效率非最高
//范圍多值插入
std::map< char, int > anothermap;
anothermap.insert(mymap.begin(), mymap.find('c'));
// 列表形式插入
anothermap.insert({ { 'd', 100 }, {'e', 200} });
return 0;
}
3.4.4.4 用數組方式插入數據
//第三種:用數組方式插入數據,下面舉例說明
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
mapStudent[1] = "student_one";
mapStudent[2] = "student_two";
mapStudent[3] = "student_three";
map< int, string >::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<
以上三種用法,雖然都可以實現數據的插入,但是它們是有區別的,當然了第一種和第二種在效果上是完成一樣的,用insert函數插入數據,在數據的 插入上涉及到集合的唯一性這個概念,即當map中有這個關鍵字時,insert操作是插入數據不了的,但是用數組方式就不同了,它可以覆蓋以前該關鍵字對 應的值,用程序說明
mapStudent.insert(map::value_type (1, "student_one"));
mapStudent.insert(map::value_type (1, "student_two"));
上面這兩條語句執行后,map中1這個關鍵字對應的值是“student_one”,第二條語句并沒有生效,那么這就涉及到我們怎么知道insert語句是否插入成功的問題了,可以用pair來獲得是否插入成功,程序如下
pair::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(map::value_type (1, "student_one"));
我們通過pair的第二個變量來知道是否插入成功,它的第一個變量返回的是一個map的迭代器,如果插入成功的話Insert_Pair.second應該是true的,否則為false。
下面給出完成代碼,演示插入成功與否問題
//驗證插入函數的作用效果
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
pair< map< int, string >::iterator, bool > Insert_Pair;
Insert_Pair = mapStudent.insert(pair< int, string >(1, "student_one"));
if(Insert_Pair.second == true)
cout< "Insert Successfully"<
大家可以用如下程序,看下用數組插入在數據覆蓋上的效果
//驗證數組形式插入數據的效果
#include < map >
#include < string >
#include < iostream >
using namespace std;
int main()
{
map< int, string > mapStudent;
mapStudent[1] = "student_one";
mapStudent[1] = "student_two";
mapStudent[2] = "student_three";
map< int, string >::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<
3.4.5 查找、刪除、交換
查找
// 關鍵字查詢,找到則返回指向該關鍵字的迭代器,否則返回指向end的迭代器
// 根據map的類型,返回的迭代器為 iterator 或者 const_iterator
iterator find (const key_type& k);
const_iterator find (const key_type& k) const;
刪除
// 刪除迭代器指向位置的鍵值對,并返回一個指向下一元素的迭代器
iterator erase( iterator pos )
// 刪除一定范圍內的元素,并返回一個指向下一元素的迭代器
iterator erase( const_iterator first, const_iterator last );
// 根據Key來進行刪除, 返回刪除的元素數量,在map里結果非0即1
size_t erase( const key_type& key );
// 清空map,清空后的size為0
void clear();
交換
// 就是兩個map的內容互換
void swap( map& other );
3.4.6 容量
// 查詢map是否為空
bool empty();
// 查詢map中鍵值對的數量
size_t size();
// 查詢map所能包含的最大鍵值對數量,和系統和應用庫有關。
// 此外,這并不意味著用戶一定可以存這么多,很可能還沒達到就已經開辟內存失敗了
size_t max_size();
// 查詢關鍵字為key的元素的個數,在map里結果非0即1
size_t count( const Key& key ) const; //
3.4.7 排序
map中的元素是自動按Key升序排序,所以不能對map用sort函數;
這里要講的是一點比較高深的用法了,排序問題,STL中默認是采用小于號來排序的,以上代碼在排序上是不存在任何問題的,因為上面的關鍵字是int 型,它本身支持小于號運算,在一些特殊情況,比如關鍵字是一個結構體或者自定義類,涉及到排序就會出現問題,因為它沒有小于號操作,insert等函數在編譯的時候過 不去,下面給出兩個方法解決這個問題。
3.4.7.1 小于號 < 重載
#include < iostream >
#include < string >
#include < map >
using namespace std;
typedef struct tagStudentinfo
{
int niD;
string strName;
bool operator < (tagStudentinfo const& _A) const
{ //這個函數指定排序策略,按niD排序,如果niD相等的話,按strName排序
if (niD < _A.niD) return true;
if (niD == _A.niD)
return strName.compare(_A.strName) < 0;
return false;
}
}Studentinfo, *PStudentinfo; //學生信息
int main()
{
int nSize; //用學生信息映射分數
map< Studentinfo, int >mapStudent;
map< Studentinfo, int >::iterator iter;
Studentinfo studentinfo;
studentinfo.niD = 1;
studentinfo.strName = "student_one";
mapStudent.insert(pair< Studentinfo, int >(studentinfo, 90));
studentinfo.niD = 2;
studentinfo.strName = "student_two";
mapStudent.insert(pair< Studentinfo, int >(studentinfo, 80));
for (iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout < < iter- >first.niD < < ' ' < < iter- >first.strName < < ' ' < < iter- >second < < endl;
return 0;
}
3.4.7.2 仿函數的應用,這個時候結構體中沒有直接的小于號重載
//第二種:仿函數的應用,這個時候結構體中沒有直接的小于號重載,程序說明
#include < iostream >
#include < map >
#include < string >
using namespace std;
typedef struct tagStudentinfo
{
int niD;
string strName;
}Studentinfo, *PStudentinfo; //學生信息
class sort
{
public:
bool operator() (Studentinfo const &_A, Studentinfo const &_B) const
{
if (_A.niD < _B.niD)
return true;
if (_A.niD == _B.niD)
return _A.strName.compare(_B.strName) < 0;
return false;
}
};
int main()
{
//用學生信息映射分數
map< Studentinfo, int, sort >mapStudent;
map< Studentinfo, int >::iterator iter;
Studentinfo studentinfo;
studentinfo.niD = 1;
studentinfo.strName = "student_one";
mapStudent.insert(pair< Studentinfo, int >(studentinfo, 90));
studentinfo.niD = 2;
studentinfo.strName = "student_two";
mapStudent.insert(pair< Studentinfo, int >(studentinfo, 80));
for (iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout < < iter- >first.niD < < ' ' < < iter- >first.strName < < ' ' < < iter- >second < < endl;
system("pause");
}
3.4.8 unordered_map
在c++11標準前,c++標準庫中只有一種map,但是它的底層實現并不是適合所有的場景,如果我們需要其他適合的map實現就不得不使用比如boost庫等三方的實現,在c++11中加了一種map unordered_map,unordered_set,他們的實現有什么不同呢?
map底層采用的是紅黑樹的實現查詢的時間復雜度為O(logn),看起來并沒有unordered_map快,但是也要看實際的數據量,雖然unordered_map的查詢從算法上分析比map快,但是它有一些其它的消耗,比如哈希函數的構造和分析,還有如果出現哈希沖突解決哈希沖突等等都有一定的消耗,因此unordered_map的效率在很大的程度上由它的hash函數算法決定,而紅黑樹的效率是一個穩定值。
unordered_map的底層采用哈希表的實現,查詢的時間復雜度為是O(1)。所以unordered_map內部就是無序的,數據是按散列函數插入到槽里面去的,數據之間無順序可言,如果我們不需要內部有序,這種實現是沒有問題的。unordered_map屬于關聯式容器,采用std::pair保存key-value形式的數據。用法與map一致。特別的是,STL中的map因為是有序的二叉樹存儲,所以對key值需要有大小的判斷,當使用內置類型時,無需重載operator < ;但是用用戶自定義類型的話,就需要重載operator < 。 unoredered_map全程使用不需要比較元素的key值的大小,但是,對于元素的==要有判斷,又因為需要使用hash映射,所以,對于非內部類型,需要程序員為其定義這二者的內容,對于內部類型,就不需要了。unordered庫使用“桶”來存儲元素,散列值相同的被存儲在一個桶里。當散列容器中有大量數據時,同一個桶里的數據也會增多,造成訪問沖突,降低性能。為了提高散列容器的性能,unordered庫會在插入元素是自動增加桶的數量,不需要用戶指定。但是,用戶也可以在構造函數或者rehash()函數中,指定最小的桶的數量。
還有另外一點從占用內存上來說因為unordered_map才用hash結構會有一定的內存損失,它的內存占用回高于map。
最后就是她們的場景了,首先如果你需要對map中的數據排序,就首選map,他會把你的數據按照key的自然排序排序(由于它的底層實現紅黑樹機制所以會排序),如果不需要排序,就看你對內存和cpu的選擇了,不過一般都會選擇unordered_map,它的查找效率會更高。
至于使用方法和函數,兩者差不多,由于篇幅限制這里不再贅述,unordered_multimap用法亦可類推。
3.5 set/multiset
std::set 是關聯容器,含有 Key 類型對象的已排序集。用比較函數compare進行排序。搜索、移除和插入擁有對數復雜度。 set 通常以紅黑樹實現。
set容器內的元素會被自動排序,set與map不同,set中的元素即是鍵值又是實值,set不允許兩個元素有相同的鍵值。不能通過set的迭代器去修改set元素,原因是修改元素會破壞set組織。當對容器中的元素進行插入或者刪除時,操作之前的所有迭代器在操作之后依然有效。
由于set元素是排好序的,且默認為升序,因此當set集合中的元素為結構體或自定義類時,該結構體或自定義類必須實現運算符‘<’的重載。
multiset特性及用法和set完全相同,唯一的差別在于它允許鍵值重復。
set和multiset的底層實現是一種高效的平衡二叉樹,即紅黑樹(Red-Black Tree)。
3.5.1 set常用成員函數
- begin()--返回指向第一個元素的迭代器
- clear()--清除所有元素
- count()--返回某個值元素的個數
- empty()--如果集合為空,返回true
- end()--返回指向最后一個元素的迭代器
- equal_range()--返回集合中與給定值相等的上下限的兩個迭代器
- erase()--刪除集合中的元素
- find()--返回一個指向被查找到元素的迭代器
- get_allocator()--返回集合的分配器
- insert()--在集合中插入元素
- lower_bound()--返回指向大于(或等于)某值的第一個元素的迭代器
- key_comp()--返回一個用于元素間值比較的函數
- max_size()--返回集合能容納的元素的最大限值
- rbegin()--返回指向集合中最后一個元素的反向迭代器
- rend()--返回指向集合中第一個元素的反向迭代器
- size()--集合中元素的數目
- swap()--交換兩個集合變量
- upper_bound()--返回大于某個值元素的迭代器
- value_comp()--返回一個用于比較元素間的值的函數
3.5.2 代碼示例
以下代碼涉及的內容:
1、set容器中,元素類型為基本類型,如何讓set按照用戶意愿來排序?
2、set容器中,如何讓元素類型為自定義類型?
3、set容器的insert函數的返回值為什么類型?
#include < iostream >
#include < string >
#include < set >
using namespace std;
/* 仿函數CompareSet,在test02使用 */
class CompareSet
{
public:
//從大到小排序
bool operator()(int v1, int v2)
{
return v1 > v2;
}
//從小到大排序
//bool operator()(int v1, int v2)
//{
// return v1 < v2;
//}
};
/* Person類,用于test03 */
class Person
{
friend ostream &operator< const Person &person);
public:
Person(string name, int age)
{
mName = name;
mAge = age;
}
public:
string mName;
int mAge;
};
ostream &operator< const Person &person)
{
out < < "name:" < < person.mName < < " age:" < < person.mAge < < endl;
return out;
}
/* 仿函數ComparePerson,用于test03 */
class ComparePerson
{
public:
//名字大的在前面,如果名字相同,年齡大的排前面
bool operator()(const Person &p1, const Person &p2)
{
if (p1.mName == p2.mName)
{
return p1.mAge > p2.mAge;
}
return p1.mName > p2.mName;
}
};
/* 打印set類型的函數模板 */
template< typename T >
void PrintSet(T &s)
{
for (T::iterator iter = s.begin(); iter != s.end(); ++iter)
cout < < *iter < < " ";
cout < < endl;
}
void test01()
{
//set容器默認從小到大排序
set< int > s;
s.insert(10);
s.insert(20);
s.insert(30);
//輸出set
PrintSet(s);
//結果為:10 20 30
/* set的insert函數返回值為一個對組(pair)。
對組的第一個值first為set類型的迭代器:
1、若插入成功,迭代器指向該元素。
2、若插入失敗,迭代器指向之前已經存在的元素
對組的第二個值seconde為bool類型:
1、若插入成功,bool值為true
2、若插入失敗,bool值為false
*/
pair< set< int >::iterator, bool > ret = s.insert(40);
if (true == ret.second)
cout < < *ret.first < < " 插入成功" < < endl;
else
cout < < *ret.first < < " 插入失敗" < < endl;
}
void test02()
{
/* 如果想讓set容器從大到小排序,需要給set容
器提供一個仿函數,本例的仿函數為CompareSet
*/
set< int, CompareSet > s;
s.insert(10);
s.insert(20);
s.insert(30);
//打印set
PrintSet(s);
//結果為:30,20,10
}
void test03()
{
/* set元素類型為Person,當set元素類型為自定義類型的時候
必須給set提供一個仿函數,用于比較自定義類型的大小,
否則無法通過編譯
*/
set< Person,ComparePerson > s;
s.insert(Person("John", 22));
s.insert(Person("Peter", 25));
s.insert(Person("Marry", 18));
s.insert(Person("Peter", 36));
//打印set
PrintSet(s);
}
int main(void)
{
//test01();
//test02();
//test03();
return 0;
}
multiset容器的insert函數返回值為什么?
#include < iostream >
#include < set >
using namespace std;
/* 打印set類型的函數模板 */
template< typename T >
void PrintSet(T &s)
{
for (T::iterator iter = s.begin(); iter != s.end(); ++iter)
cout < < *iter < < " ";
cout < < endl;
}
void test(void)
{
multiset< int > s;
s.insert(10);
s.insert(20);
s.insert(30);
//打印multiset
PrintSet(s);
/* multiset的insert函數返回值為multiset類型的迭代器,
指向新插入的元素。multiset允許插入相同的值,因此
插入一定成功,因此不需要返回bool類型。
*/
multiset< int >::iterator iter = s.insert(10);
cout < < *iter < < endl;
}
int main(void)
{
test();
return 0;
}
3.5.3 unordered_set
C++ 11中出現了兩種新的關聯容器:unordered_set和unordered_map,其內部實現與set和map大有不同,set和map內部實現是基于RB-Tree,而unordered_set和unordered_map內部實現是基于哈希表(hashtable),由于unordered_set和unordered_map內部實現的公共接口大致相同,所以本文以unordered_set為例。
unordered_set是基于哈希表,因此要了解unordered_set,就必須了解哈希表的機制。哈希表是根據關鍵碼值而進行直接訪問的數據結構,通過相應的哈希函數(也稱散列函數)處理關鍵字得到相應的關鍵碼值,關鍵碼值對應著一個特定位置,用該位置來存取相應的信息,這樣就能以較快的速度獲取關鍵字的信息。比如:現有公司員工的個人信息(包括年齡),需要查詢某個年齡的員工個數。由于人的年齡范圍大約在[0,200],所以可以開一個200大小的數組,然后通過哈希函數得到key對應的key-value,這樣就能完成統計某個年齡的員工個數。而在這個例子中,也存在這樣一個問題,兩個員工的年齡相同,但其他信息(如:名字、身份證)不同,通過前面說的哈希函數,會發現其都位于數組的相同位置,這里,就涉及到“沖突”。準確來說,沖突是不可避免的,而解決沖突的方法常見的有:開發地址法、再散列法、鏈地址法(也稱拉鏈法)。而unordered_set內部解決沖突采用的是----鏈地址法,當用沖突發生時把具有同一關鍵碼的數據組成一個鏈表。下圖展示了鏈地址法的使用:

使用unordered_set需要包含#include頭文件,同unordered_map類似,用法沒有什么太大的區別,參考set/multiset。
除此之外unordered_multiset也是一種可選的容器。
-
C++
+關注
關注
22文章
2108瀏覽量
73618 -
STL
+關注
關注
0文章
86瀏覽量
18319 -
數據結構
+關注
關注
3文章
573瀏覽量
40123 -
程序設計
+關注
關注
3文章
261瀏覽量
30391
發布評論請先 登錄
相關推薦
STL130N6F7 MOS管
STL130N6F7 MOS管
STL130N6F7 MOS管現貨
X-CUBE-STL與ARM的STL的區別是什么?
effective stl中文版下載pdf
C++ STL的概念及舉例
PLC控制系統設計教程: 加熱爐送料系統——仿STL指令的編程方式梯形圖舉例
基于STL曲面網格重建算法


STL的概述






 工商網監
工商網監
評論