


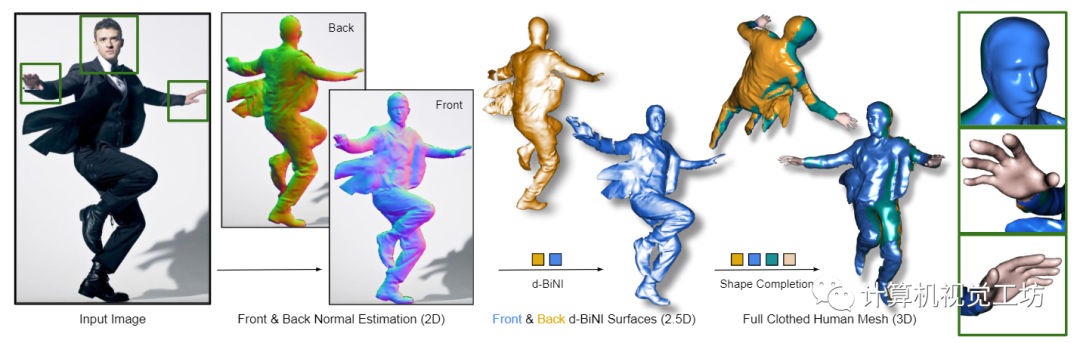
圖1所示。從彩色圖像進(jìn)行人體數(shù)字化。ECON結(jié)合了自由形式隱式表示的最佳方面,以及明確的擬人化正則化,以推斷高保真度的3D人類,即使是寬松的衣服或具有挑戰(zhàn)性的姿勢(shì)。
0.筆者個(gè)人體會(huì)
這篇文章討論了單圖像的穿著人類重建問題。
隱式方法可以用來表示任意3D穿著人類形狀,因?yàn)樗灰蕾囉谕負(fù)浣Y(jié)構(gòu),因此具有更高的靈活性。這種方法的缺點(diǎn)是難以擴(kuò)展到多種服裝樣式,限制了其在真實(shí)場(chǎng)景中的應(yīng)用。
相比之下,顯式方法則使用網(wǎng)格或深度圖或點(diǎn)云來重建3D人類。這些方法主要關(guān)注于估計(jì)或回歸最小穿著的3D身體網(wǎng)格,而忽略了衣服。為了考慮穿著人類的形狀,另一類工作通過添加3D偏移量到身體網(wǎng)格上來進(jìn)行建模。這種方法與當(dāng)前的動(dòng)畫管道兼容,因?yàn)樗鼈兝^承了從統(tǒng)計(jì)身體模型中得出的層次化骨架和權(quán)重。然而,這種方法對(duì)于寬松的衣服來說不夠靈活,因?yàn)樗鼈兣c身體拓?fù)浣Y(jié)構(gòu)有很大的不同,例如衣服和裙子。為了增加拓?fù)潇`活性,一些方法通過識(shí)別服裝類型并使用適當(dāng)?shù)哪P蛠碇亟ㄋ5牵@種方法很難擴(kuò)展到多種服裝樣式,限制了其在真實(shí)場(chǎng)景中的泛化能力。
這篇文章介紹了穿著人類重建的最新進(jìn)展和挑戰(zhàn),通過將隱式方法和顯式方法相結(jié)合實(shí)現(xiàn)了更好的單圖穿衣人重建。這里也推薦「3D視覺工坊」新課程《徹底搞透視覺三維重建:原理剖析、代碼講解、及優(yōu)化改進(jìn)》。
1.摘要
深度學(xué)習(xí)、藝術(shù)家策劃的掃描和隱式功能(IF)的結(jié)合,使從圖像中創(chuàng)建詳細(xì)的、有衣的3D人體成為可能。然而,現(xiàn)有的方法還遠(yuǎn)遠(yuǎn)不夠完美。基于隱式功能(IF)的方法恢復(fù)了自由幾何形狀,但會(huì)產(chǎn)生無實(shí)體的肢體或退化的形狀,以實(shí)現(xiàn)新穎的姿勢(shì)或衣服。為了增加這些情況的魯棒性,現(xiàn)有工作使用顯式的參數(shù)化的身體模型來約束表面重建,但這限制了自由形狀表面的恢復(fù),例如偏離身體的寬松衣服。我們想要的是一種結(jié)合隱式表示和顯式體正則化的最佳特性的方法。為此,我們做了兩個(gè)關(guān)鍵的觀察:(1)目前的網(wǎng)絡(luò)比全3d表面更擅長(zhǎng)推斷詳細(xì)的2D地圖,(2)參數(shù)化模型可以被看作是將詳細(xì)的表面斑塊拼接在一起的“畫布”。基于這些,我們的方法ECON有三個(gè)主要步驟:(1)它推斷出一個(gè)穿著衣服的人的正面和背面的詳細(xì)2D法線圖。(2)從中,它恢復(fù)2.5D前后表面,稱為d-BiNI,這些表面同樣詳細(xì),但不完整,并在SMPL-X的幫助下相互注冊(cè)這些w.r.t.,在從照片恢復(fù)的SMPL-X身體面片的幫助下該方法通過在d-BiNI表面之間“修復(fù)”丟失的幾何形狀,可以推斷出高保真的3D人物,即使在穿著寬松的衣服和擺出具有挑戰(zhàn)性的姿勢(shì)時(shí)也能做到。根據(jù)在CAPE和Renderpeople數(shù)據(jù)集上的定量評(píng)估,這超過了以前的方法。此外,感知研究還表明,ECON的感知現(xiàn)實(shí)主義也明顯更好。
2.算法解析
給定RGB圖像,ECON首先估計(jì)前后法線貼圖(第2.1節(jié)),然后將它們轉(zhuǎn)換為前后部分表面(第2.2節(jié)),最后在IF-Nets+(第2.3節(jié))的幫助下“繪制”缺失的幾何形狀。參見圖3中的ECON概述。
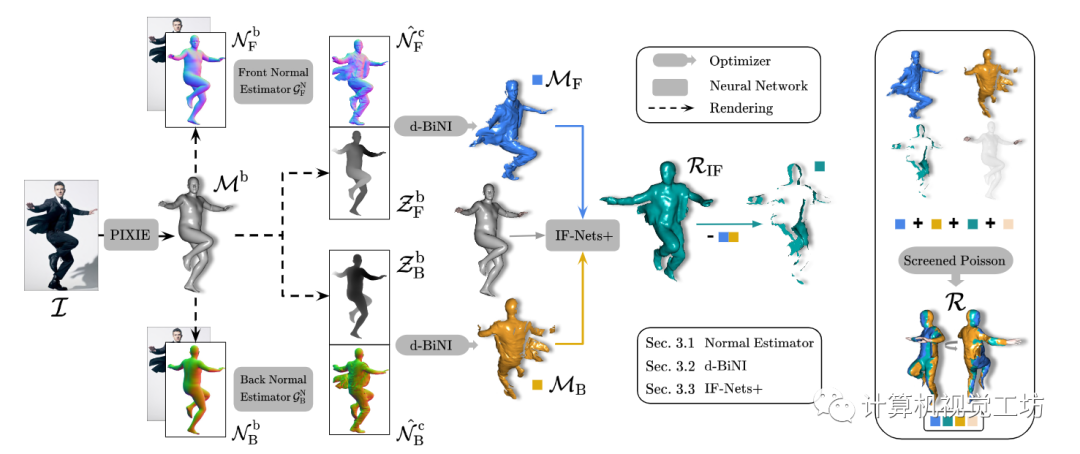
圖3。概述。ECON以RGB圖像I和SMPL-X主體M'作為輸入。在渲染的前后車身法線圖像N的條件下,ECON首先預(yù)測(cè)前后服裝法線圖N,這兩個(gè)圖,連同車身深度圖2,被饋送到d-BiNI優(yōu)化器中,以產(chǎn)生前后表面{Mr, MB)。基于這樣的局部曲面,和身體估計(jì)M’。IF-Nets+隱式完成Rir。可選的Face或hands來自M’,經(jīng)過篩選的泊松將一切結(jié)合為最終的水密R。
2.1.詳細(xì)法線圖預(yù)測(cè)
在大量RGB圖像和法線圖像對(duì)的訓(xùn)練下,使用圖像到圖像的轉(zhuǎn)換網(wǎng)絡(luò)可以從RGB圖像中準(zhǔn)確地估計(jì)出“前”法線映射 ,如PIFuHD或ICON。這兩種方法還可以從圖像中推斷出一個(gè)“反向”法線貼圖 。但是,缺少圖像線索會(huì)導(dǎo)致 過于光滑。為了解決這個(gè)問題,我們對(duì)ICON的背面正常預(yù)測(cè)器 進(jìn)行了微調(diào),增加了額外的MRF損失,通過最小化特征空間中預(yù)測(cè)的 和ground truth (GT) 之間的差異來增強(qiáng)局部細(xì)節(jié)。
為了指導(dǎo)法線貼圖預(yù)測(cè)并使其對(duì)各種身體姿態(tài)具有魯棒性,ICON訓(xùn)練了法線映射預(yù)測(cè)模塊,在身體法線貼圖 ,從估計(jì)的身體 中渲染。因此,準(zhǔn)確地對(duì)齊估計(jì)的身體和衣服輪廓是很重要的。除了ICON中使用的和外,我們還在額外的損失項(xiàng)中應(yīng)用2D身體標(biāo)志來進(jìn)一步優(yōu)化從PIXIE或PyMAF-X推斷的SMPL-X身體M。
2.2.前后表面重建
現(xiàn)在我們將覆蓋的法線貼圖提升到2.5D表面。我們期望這些2.5D表面滿足三個(gè)條件:(1)高頻表面細(xì)節(jié)與預(yù)測(cè)的覆蓋法線圖一致;(2)低頻表面變化(包括不連續(xù)面)與SMPL-X的一致;(3)前后輪廓的深度彼此接近。
與PIFuHD或ICON訓(xùn)練神經(jīng)網(wǎng)絡(luò)從法線圖回歸隱式表面不同,我們使用變分法正交積分方法,對(duì)深度與法線的關(guān)系進(jìn)行顯式建模。具體的,我們利用粗略先驗(yàn)、深度圖和輪廓一致性,對(duì)最近提出的雙向正常集成(BiNI)方法進(jìn)行定制,用于全身網(wǎng)格重建。
為了滿足這三個(gè)條件,我們提出了一種深度感知輪廓一致的雙邊法向積分(d-BiNI)方法,對(duì)前后服裝深度圖進(jìn)行聯(lián)合優(yōu)化
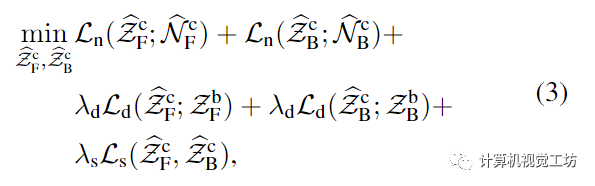
通過Eq.(3),我們做出了兩個(gè)超出BiNI的技術(shù)貢獻(xiàn)。首先,我們使用先前從SMPL-X體網(wǎng)格中渲染的粗深度來正則化BiNI:這解決了將前后表面以連貫的方式放在一起形成一個(gè)完整的身體的關(guān)鍵問題。其次,我們使用輪廓一致性項(xiàng)來鼓勵(lì)前后輪廓邊界處的深度值相同,在域中計(jì)算(圖4):
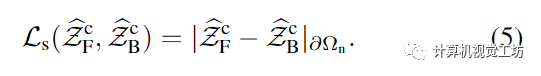
該項(xiàng)提高了重建的前后衣深圖的物理一致性。
2.3.人形補(bǔ)全
對(duì)于沒有自我遮擋的簡(jiǎn)單身體姿勢(shì),如FACSMILE和Moduling Humans中所做的那樣,以直接的方式合并前后d-BiNI表面,可以產(chǎn)生完整的3D服裝掃描。然而,通常會(huì)導(dǎo)致自咬合,從而導(dǎo)致大部分表面缺失。在這種情況下,泊松表面重建(PSR)會(huì)導(dǎo)致斑點(diǎn)狀偽影。
使用SMPL-X ()完成PSR。“填充”缺失表面的一種簡(jiǎn)單方法是利用估計(jì)的SMPL-X體。我們從中移除前后攝像頭可見的三角形。剩下的三角形“湯”包含側(cè)視圖邊界和遮擋區(qū)域。我們將PSR應(yīng)用于和d-BiNI曲面{}的并集,得到一個(gè)水密重建r。雖然避免了四肢或側(cè)面的缺失,但由于SMPL-X與實(shí)際的衣服或頭發(fā)之間的差異,它不能為原來缺失的衣服和頭發(fā)表面產(chǎn)生一致的表面;見圖5中的。
使用IF-Nets+ ()進(jìn)行繪畫。為了提高重建的一致性,我們使用學(xué)習(xí)的隱函數(shù)(IF)模型來“補(bǔ)繪”給定的前后缺失的幾何形狀d-BiNI表面。具體來說,我們將通用形狀補(bǔ)全方法IF-Nets定制為SMPL-X引導(dǎo)的方法,稱為IF-Nets+。IF-Nets從缺乏的3D輸入(如不完整的3D人體形狀或低分辨率體素網(wǎng)格)完成3D形狀。受Li等人[44]的啟發(fā),我們通過在體素化的SMPL-X身體上調(diào)節(jié)IF-Nets來處理姿態(tài)變化。IF-Nets+以體素化的正面和背面地真深度圖()和體素化(估計(jì)的)的身體網(wǎng)格()作為輸入進(jìn)行訓(xùn)練,并使用地真3D形狀進(jìn)行監(jiān)督。在訓(xùn)練過程中,為了對(duì)遮擋的魯棒性,我們隨機(jī)屏蔽。在推理過程中,我們將估計(jì)的和輸入IF-Nets+中以獲得占用場(chǎng),并從中提取入畫網(wǎng)格,并使用Marching cubes。
用 ()完成PSR。為了獲得我們最終的網(wǎng)格R,我們應(yīng)用PSR來縫合(1)d-BiNI表面,(2)來自Rir的側(cè)面和閉塞的三角形湯紋,以及(3)從估計(jì)的SMPL-X裁剪的臉或手,(3)的必要性源于的手/臉重建不佳,見圖6的差異。該方法表示為。
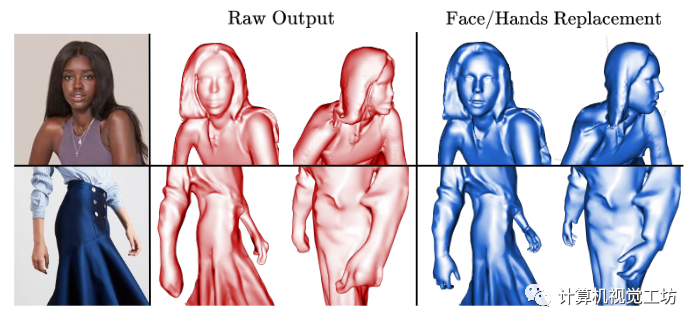
圖6。臉部和手部細(xì)節(jié)。原始重建的臉和手可以換成SMPL-X身體的臉和手。
值得注意的是,盡管已經(jīng)是一個(gè)完整的人體網(wǎng)格,但由于輸入的有損體素化和Marching cubes算法的有限分辨率,它在某種程度上平滑了的細(xì)節(jié),這些細(xì)節(jié)是通過d-BiNI優(yōu)化的(見圖5中的 vs )。雖然更好地保留了d-BiNI的細(xì)節(jié),但的側(cè)視圖和遮擋部分在泊松步驟中被融合。
3.實(shí)驗(yàn)
在實(shí)驗(yàn)方面,作者將ECON與身體不可知論方法(即PIFu和PIFuHD)和身體感知方法(即PaMIR和ICON)進(jìn)行比較,見表1。
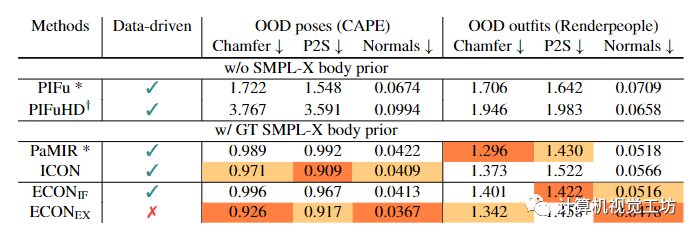
表1 對(duì)技術(shù)水平的評(píng)估。
為了公平比較,作者使用ICON中的PIFu和PaMIR的重新實(shí)現(xiàn),因?yàn)樗鼈兙哂邢嗤木W(wǎng)絡(luò)設(shè)置和輸入數(shù)據(jù)。的性能與ICON相當(dāng),并且在包含偏離分布(OOD)姿勢(shì)(CAPE)的圖像上優(yōu)于其他方法,距離誤差低于1cm。在分發(fā)套件(Renderpeople)方面,的表現(xiàn)與PaMIR相當(dāng),比PIFuHD要好得多。當(dāng)涉及到法線測(cè)量的高頻細(xì)節(jié)時(shí),在兩個(gè)數(shù)據(jù)集上都達(dá)到了SOTA的性能。
為評(píng)估野外圖像上的ECON。測(cè)試圖像分為三類:“具有挑戰(zhàn)性的姿勢(shì)”、“寬松的衣服”和“時(shí)尚圖像”。挑戰(zhàn)性姿勢(shì)和寬松服裝的例子如圖9所示。

圖9。野外圖像的定性結(jié)果。我們展示了8個(gè)從圖像中重建詳細(xì)的穿衣服的3D人的例子:(a)具有挑戰(zhàn)性的姿勢(shì)和(b)寬松的衣服。對(duì)于每個(gè)例子,我們都顯示了輸入圖像以及重建的3D人體的兩個(gè)視圖(正面和旋轉(zhuǎn))。我們的方法對(duì)姿勢(shì)變化具有魯棒性,可以很好地推廣到寬松的衣服,并包含詳細(xì)的幾何形狀。
參與者被要求在基線方法和ECON之間選擇他們認(rèn)為更現(xiàn)實(shí)的重建方法。我們?cè)诒?中計(jì)算了每個(gè)基線優(yōu)于ECON的可能性。這里也推薦「3D視覺工坊」新課程《徹底搞透視覺三維重建:原理剖析、代碼講解、及優(yōu)化改進(jìn)》。
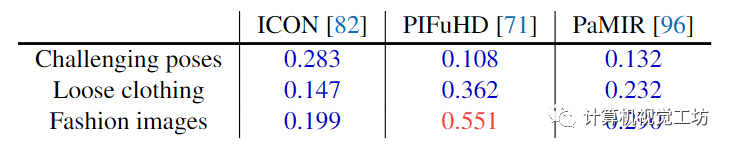
表2。知覺的研究。數(shù)字表示參與者更喜歡重建競(jìng)爭(zhēng)方法而不是ECON重建野外圖像的可能性。0.5的值表示相同的偏好。值< 0.5有利于ECON,而值< 0.5有利于競(jìng)爭(zhēng)對(duì)手。
感知研究的結(jié)果證實(shí)了表1中的定量評(píng)估。對(duì)于“具有挑戰(zhàn)性的姿勢(shì)”圖像,ECON明顯優(yōu)于PIFuHD,并且優(yōu)于ICON。對(duì)于穿著寬松衣服的人的圖像,ECON比ICON更受歡迎和優(yōu)于PIFuHD。
最后在消融實(shí)驗(yàn)里作者將d-BiNI和BiNI,IF-Nets+和IF-Nets進(jìn)行了比較,實(shí)驗(yàn)結(jié)果如下表所示:

表3。BiNI和d-BiNI。BiNI曲面與d-BiNI曲面w.r.t.重建精度和優(yōu)化速度的比較。

同時(shí)作者也比較了比較了IF-Nets+和IF-Nets在遮擋情況下的幾何“補(bǔ)繪”,結(jié)果如圖5所示:
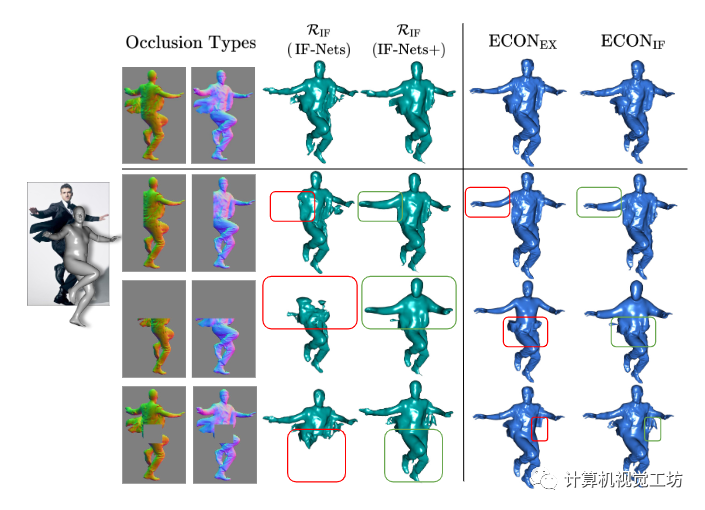
圖5。“補(bǔ)繪”缺失的幾何圖形。我們通過屏蔽正常圖像來模擬不同的遮擋情況,并呈現(xiàn)不同設(shè)計(jì)選擇的中間和最終3D重建。雖然IF-Nets遺漏了某些身體部位,但I(xiàn)F-Nets+產(chǎn)生了一個(gè)合理的整體形狀。由于經(jīng)過學(xué)習(xí)的形狀分布,ECONir產(chǎn)生的服裝表面比ECONEx更一致。
4.展望
雖然ECON在單圖人體三維重建上達(dá)到了一個(gè)全新的高度,但是從單個(gè)圖像中恢復(fù)SMPL-X體(或類似模型)仍然是一個(gè)開放的問題,并沒有完全解決。任何故障都可能導(dǎo)致ECON故障,如圖8-A和圖8-B所示。由于合成數(shù)據(jù)變得足夠逼真,它們與真實(shí)數(shù)據(jù)的領(lǐng)域差距顯著縮小,可以預(yù)見,這種限制將被消除。ECON的重建質(zhì)量主要依賴于預(yù)測(cè)法線圖的準(zhǔn)確性。較差的法線貼圖會(huì)導(dǎo)致前后表面過近甚至相交,如圖8-C和圖8-D所示。
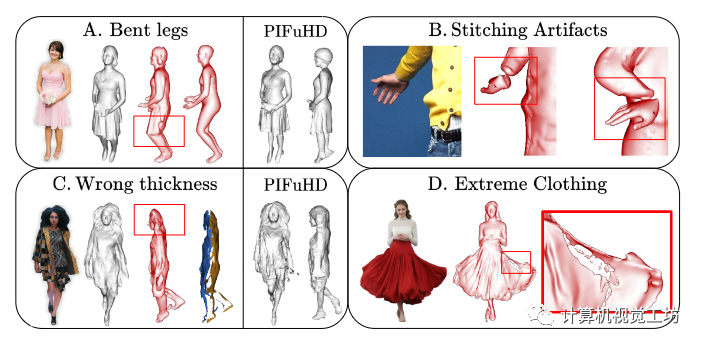
圖8。ECON的失敗案例。(A-B)恢復(fù)SMPL-X體結(jié)果的失效,例如,彎曲的腿或錯(cuò)誤的肢體姿勢(shì),估計(jì)會(huì)為ECON提供錯(cuò)誤的幾何形狀。擴(kuò)展導(dǎo)致ECON故障。(C-D)法線映射中的失效
未來的工作。除了解決上述限制之外,其他幾個(gè)方向?qū)?shí)際應(yīng)用也很有用。目前,ECON只重建三維幾何。人們還可以恢復(fù)底層骨骼和皮膚權(quán)重,以獲得完全可動(dòng)畫的化身。此外,生成后視紋理將產(chǎn)生完全紋理的頭像。從恢復(fù)的幾何圖形中分離服裝、發(fā)型或配飾,將使模擬、合成、編輯和轉(zhuǎn)移這些樣式成為可能。ECON的重建,連同它下面的SMPL-X體,可以在學(xué)習(xí)神經(jīng)化身之前作為3D形狀使用。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103785 -
算法
+關(guān)注
關(guān)注
23文章
4713瀏覽量
95505 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122837
原文標(biāo)題:CVPR2023 Highlight | ECON:最新單圖穿衣人三維重建SOTA算法
文章出處:【微信號(hào):3D視覺工坊,微信公眾號(hào):3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
怎樣去設(shè)計(jì)一種基于RGB-D相機(jī)的三維重建無序抓取系統(tǒng)?
如何去開發(fā)一款基于RGB-D相機(jī)與機(jī)械臂的三維重建無序抓取系統(tǒng)
基于紋理映射的醫(yī)學(xué)圖像三維重建
MC三維重建算法的二義性消除研究
一種新穎實(shí)用的基于視覺導(dǎo)航的三維重建算法
基于FPGA的醫(yī)學(xué)圖像三維重建系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
透明物體的三維重建研究綜述

NVIDIA Omniverse平臺(tái)助力三維重建服務(wù)協(xié)同發(fā)展
深度學(xué)習(xí)背景下的圖像三維重建技術(shù)進(jìn)展綜述
如何使用純格雷碼進(jìn)行三維重建?
NerfingMVS:引導(dǎo)優(yōu)化神經(jīng)輻射場(chǎng)實(shí)現(xiàn)室內(nèi)多視角三維重建
三維重建:從入門到入土
如何實(shí)現(xiàn)整個(gè)三維重建過程
基于光學(xué)成像的物體三維重建技術(shù)研究





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論