") Python網(wǎng)絡(luò)爬蟲Selenium的簡單使用
Python網(wǎng)絡(luò)爬蟲Selenium的簡單使用
Python網(wǎng)絡(luò)爬蟲-Selenium
想要學(xué)習(xí)爬蟲,如果比較詳細的了解web開發(fā)的前端知識會更加容易上手,時間不夠充裕,僅僅了解html的相關(guān)知識也是夠用的。
準備工作:
使用它肯定先要安裝它,對于Selenium的安裝推薦使用pip,十分方便。因為我使用的是谷歌瀏覽器,使用前需要先配置相應(yīng)的ChromeDriver,在此放出對應(yīng)谷歌瀏覽器對應(yīng)的80版本的ChromeDriver。地址 :點擊下載提取碼:sz2s
至于如何去安裝配置,網(wǎng)絡(luò)上有很多教程,在此不做贅述。
簡要功能:
使用Selenium可以驅(qū)動瀏覽器執(zhí)行特定操作,如點擊,下拉等等,同時也能直接抓取網(wǎng)頁源代碼,即做到可見即可爬。
1.訪問頁面
通過下面這幾行代碼可以實現(xiàn)瀏覽器的驅(qū)動并獲取網(wǎng)頁源碼,非常便捷。
from selenium import webdriver
browser = webdriver.Chrome() #聲明瀏覽器對象
browser.get('https://www.baidu.com')
print(browser.page_source) #打印網(wǎng)頁源碼
browser.close() #關(guān)閉瀏覽器
2.查找節(jié)點
selenium可以驅(qū)動瀏覽器完成各種操作,但進行模擬點擊,填寫表單時,我們總要知道這些輸入框,點擊按鈕在哪里,所以需要獲取相對的節(jié)點。總共有其中尋找節(jié)點的方法,在此給出一個非常全面的學(xué)習(xí)查找節(jié)點的教程。
=單個節(jié)點=
下面以百度首頁為例。通過查找源碼,我們可以發(fā)現(xiàn)對應(yīng)搜索文本框的class,name,id等屬性名。
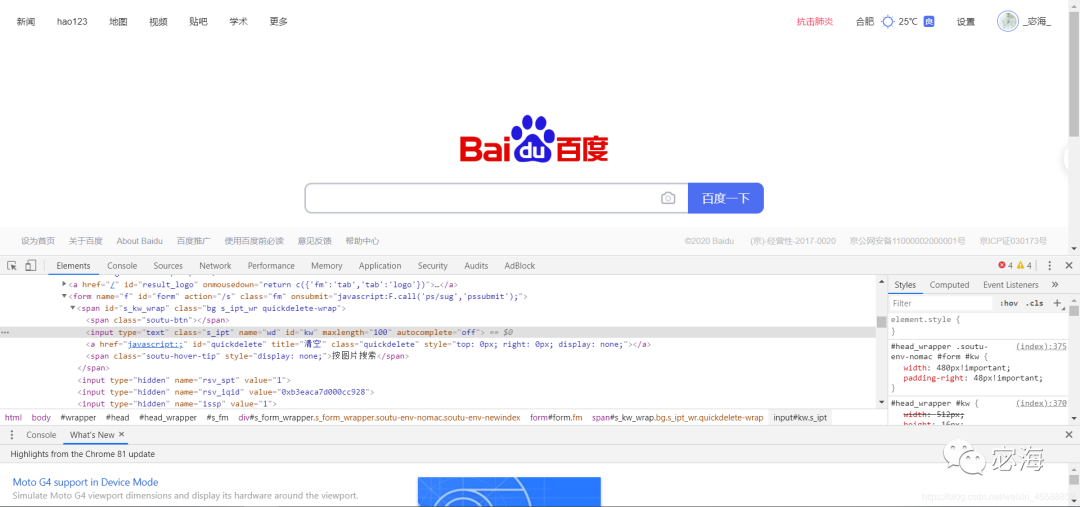
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw') #獲取搜索框位置
input.send_keys('Python') #輸入內(nèi)容
運行代碼得到如下內(nèi)容,此時我們只是輸入,并未進行其他操作。

=多個節(jié)點=
如果查找目標在網(wǎng)頁中只有一個,使用find_element()方法就可了。如果有多個,舉個例子,如查找多個滿足條件的節(jié)點,通過html基本知識我們可以知道元素對應(yīng)的id名是唯一的,像是其他的class等可以多次出現(xiàn),其中對應(yīng)的滿足條件的倘若還用一開始的方法便只能得到第一個節(jié)點的內(nèi)容,后面就不能得到,因此可以使用find_elements()。
3.節(jié)點交互
意思就是讓瀏覽器模擬執(zhí)行一些動作,常用的有:輸入文字用send_keys(),清空文字用clear(),點擊用click()。放個小實例。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
time.sleep(1) #等待時間設(shè)置為1秒,方便查看
input.clear() #清空搜索框
input.send_keys('LOL')
button = browser.find_element_by_id('su')
button.click() #模擬點擊
4.獲取節(jié)點信息
因為selenium的page_source屬性可以直接獲取網(wǎng)頁源碼,接著就可以直接使用解析庫(如正則表達式,Beautiful Soup等)直接提取信息,不過Selenium已經(jīng)直接提供了選擇節(jié)點的方法了,返回的是WebElement類型,它也有相關(guān)的方法提取節(jié)點信息,如文本,屬性等。這也是使用它進行一點簡單的爬蟲非常方便的原因,代碼十分簡潔。
=提取屬性=
使用get_attribute()方法,但前提需要先選中節(jié)點,同樣以百度首頁為實例,打印出百度logo的屬性。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('s_lg_img')
print(input)
print(input.get_attribute("class"))
'''打印結(jié)果
< selenium.webdriver.remote.webelement.WebElement (session="6013549f22f653cf081e0564da8315da", element="a924de49-358c-42e1-8c29-09bf0dd8d3c3") >
index-logo-src
'''
=獲取文本值=
每個WebElement節(jié)點都有text屬性,直接調(diào)用這個屬性就可以獲得節(jié)點內(nèi)的內(nèi)容,這相當于Beautiful Soup中的get_text()方法。這里打開百度首頁,獲取搜索按鈕的百度一下文本。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('su')
print(input.text)
=獲取id、位置、標簽名和大小=
id屬性獲取節(jié)點id
location屬性可以獲取該節(jié)點在頁面中的相對位置
tag_name屬性獲取標簽名稱
size屬性獲取節(jié)點大小,就是寬高
5.延時等待
當我們進行網(wǎng)絡(luò)爬蟲時,請求的東西或許不會第一時間出現(xiàn),此時就會拋出時間異常,因此我們需要加上延時等待避免程序中斷。這里面分為顯式等待和隱式等待,具體詳細教程參考鏈接: link.
6.異常處理
進行爬蟲難免會遇到異常,如超時,節(jié)點未找到等錯誤,此時用try except語句捕獲異常,可以避免程序因此中斷。
關(guān)于Selenium其他的函數(shù)如對網(wǎng)頁節(jié)點進行拖拽,切換標簽頁,前進與后退,選項卡管理以及對cookies相關(guān)的操作等不做詳細說明,上面的知識足以進行簡單的爬蟲了,像是各大網(wǎng)頁的文本值都可以很簡單的抓取下來,可以做一點簡單的數(shù)據(jù)分析。當然這僅對初學(xué)者是這樣的,后期稍微深入會遇到需要這些函數(shù)的操作,對于小白這些就夠了。
-
python
+關(guān)注
關(guān)注
56文章
4793瀏覽量
84634 -
異常中斷
+關(guān)注
關(guān)注
0文章
9瀏覽量
1223
發(fā)布評論請先 登錄
相關(guān)推薦
IP地址數(shù)據(jù)信息和爬蟲攔截的關(guān)聯(lián)
如何使用Python構(gòu)建LSTM神經(jīng)網(wǎng)絡(luò)模型
Python編程:處理網(wǎng)絡(luò)請求的代理技術(shù)
詳細解讀爬蟲多開代理IP的用途,以及如何配置!
使用Python進行Ping測試





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論