 【FlashAttention-V4,非官方】FlashDecoding++
【FlashAttention-V4,非官方】FlashDecoding++
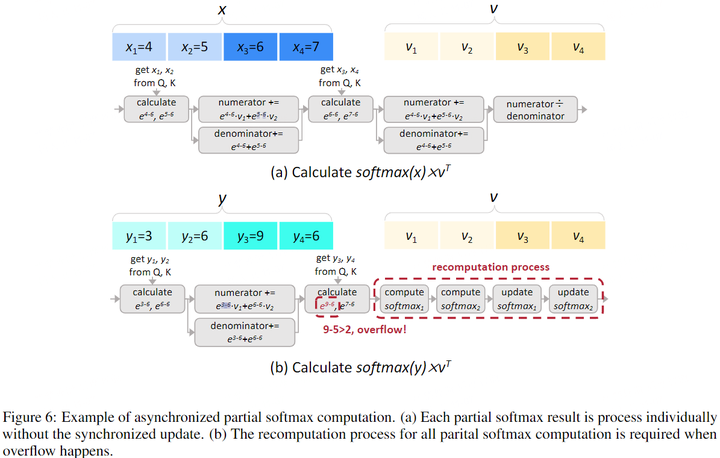
為了提高softmax并行性,之前方法(FlashAttention、FlashDecoding)將計算過程拆分,各自計算partial softmax結果,最后需要通過同步操作來更新partial softmax結果。例如FlashAttention每次計算partial softmax結果都會更新之前的結果,而FlashDecoding是在最后統一更新所有partial softmax結果。
本文在A100 GPU上分析了輸入長度為1024的情況,這種同步partial softmax更新操作占Llama2-7B推理的注意力計算的18.8%。(本文沒說是FlashAttention還是FlashDecoding的結果,個人認為FlashDecoding的同步更新代價并不大,應該遠小于18.8%)
這是LLM推理加速的第一個挑戰。此外,本文還提出了兩個挑戰:
在解碼階段,Flat GEMM操作的計算資源未得到充分利用。這是由于解碼階段是按順序生成token(一次只生成一個token),GEMM操作趨于flat-shape,甚至batch size等1時變成了GEMV(General Matrix-Vector Multiplication),具體看論文Figure 2。當batch size較小時(e.g., 8),cublas和cutlass會將矩陣填充zeros以執行更大batchsize(e.g., 64)的GEMM,導致計算利用率不足50%。
動態輸入和固定硬件配置影響了LLM推理的性能。例如,當batch size較小時,LLM推理的解碼過程是memory-bounded,而當batch size較大時是compute-bounded。
針對這3個問題,本文分別提出了對應優化方法:
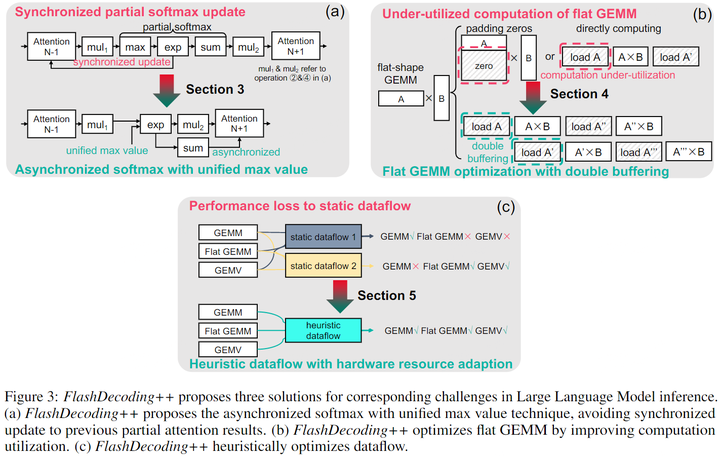
Asynchronized softmax with unified max value.FlashDecoding++為分塊softmax計算設置了一個共享的最大值。這樣可以獨立計算partial softmax,無需同步更新。
Flat GEMM optimization with double buffering.FlashDecoding++只將矩陣大小填充到8,對比之前針對flat-shaped GEMM設計的為64,提高了計算利用率。論文指出,具有不同shape的flat GEMMs面臨的瓶頸也不同,于是進一步利用雙緩沖等技術提高kernel性能。
Heuristic dataflow with hardware resource adaption.FlashDecoding++同時考慮了動態輸入和硬件配置,針對LLM推理時數據流進行動態kernel優化。
下圖展示了以上3種方法的示意圖:
2. Backgrounds
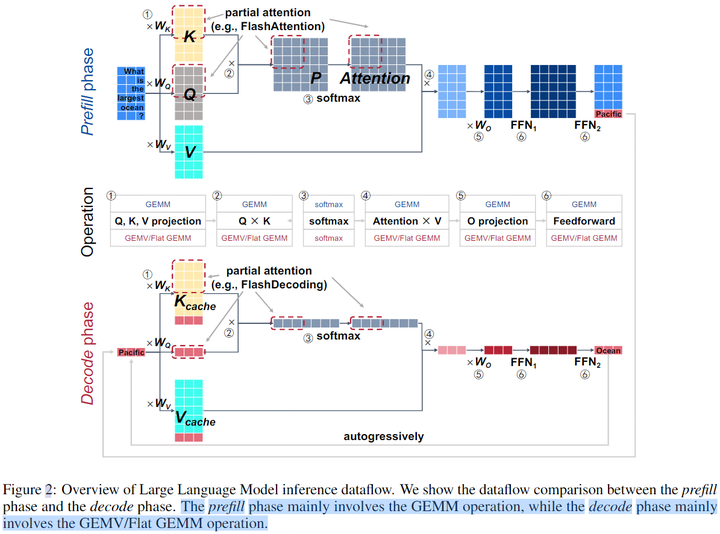
LLM推理中的主要操作如下圖所示:linear projection(①和⑤)、attention(②、③和④)和feedforward network(⑥)。為簡單起見,這里忽略了position embedding、non-linear activation、mask等操作。本文將LLM推理時對Prompt的處理過程稱為prefillphase,第二階段預測過程稱為decodephase。這兩個階段的算子基本一致,主要是輸入數據的shape是不同的。由于decodephase一次只處理一個令牌(batch size=1,或batch size很小),因此輸入矩陣是flat-shape matrices(甚至是vectors),參見下圖Decode phase部分中和KV Cache拼接的紅色向量。
LLM推理中的另一個問題就是Softmax算子,其需要計算并存儲所有全局數據,并且數據量隨著數據長度成平方增長,存在內存消耗高和低并行性等問題。一般計算流程如下:
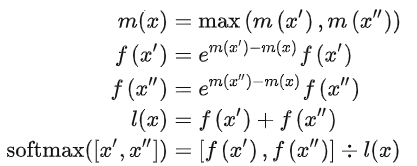
3. Asynchronized Softmax with Unified Maximum Value如下
圖b所示,FlashAttention和FlashDecoding對softmax操作進行了分塊處理,但是塊與塊之間需要進行同步(主要是局部最大值)。本文發現這種同步操作的開銷約為20%。因此,作者希望去除同步操作,也就是獨立計算出partial softmax結果。



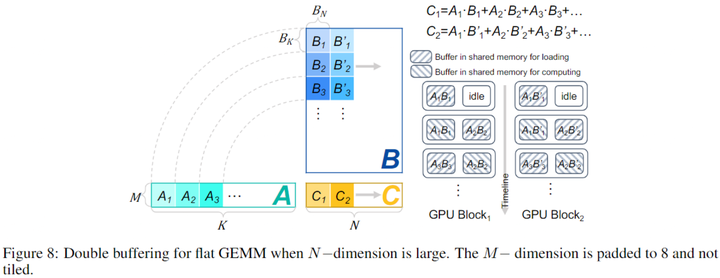
4. Flat GEMM Optimization with Double Buffering
Decoding階段的過程主要由GEMV(batch size=1)或flat GEMM(batch size>1)。GEMV/GEMM運算可以用M、N、K來表示,其中兩個相乘矩陣的大小分別為M × K和K × N。一般LLM推理引擎利用Tensor Core使用cuBLAS和CUTLASS等庫來加速。盡管Tensor Core適合處理M = 8的GEMM,但這些庫為了隱藏memory latency,通常將M維度平鋪到64。然而,decodephase的GEMV或flat GEMM的M通遠小于64,于是填充0到64,導致計算利用率低下。
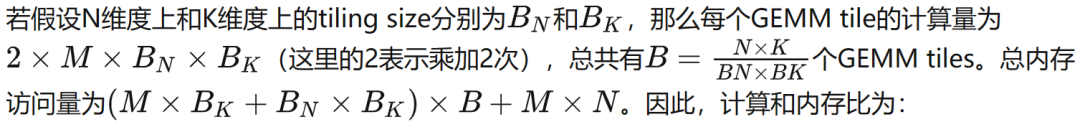
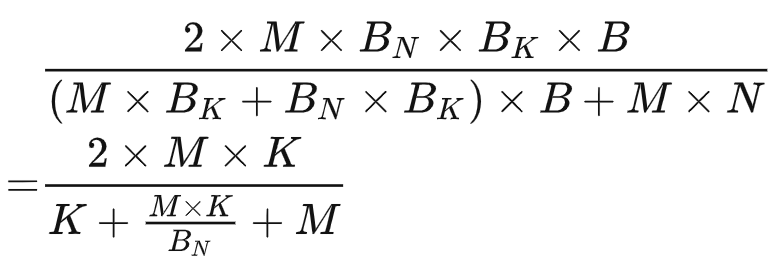



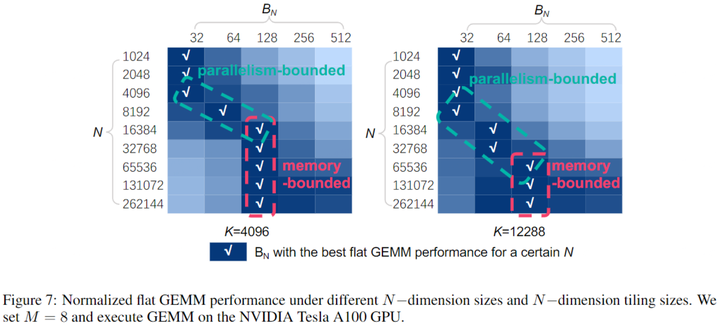
為了隱藏memory access latency,本文引入了double buffering技術。具體來說就是在共享內存中分配兩個buffer,一個buffer用于執行當前tile的GEMM計算,同時另一個buffer則加載下一個tile GEMM所需的數據。這樣計算和內存訪問是重疊的,本文在N較大時采取這種策略,下圖為示意圖。
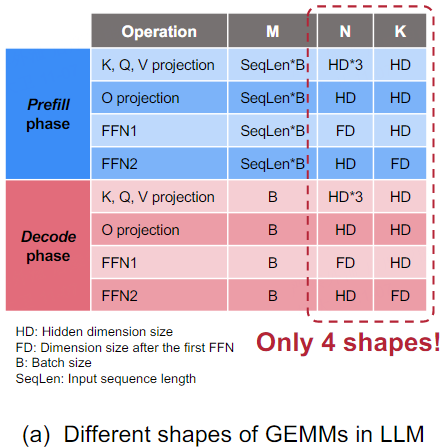
5. Heuristic Dataflow with Hardware Resource Adaption
影響LLM推理性能的因素有很多:(a)動態輸入。batch size和輸入序列長度的變化造成了工作負載變化。(b)模型多樣性。主要指模型結構和模型大小。(c)GPU能力不同。例如內存帶寬、緩存大小和計算能力。(d)工程優化。
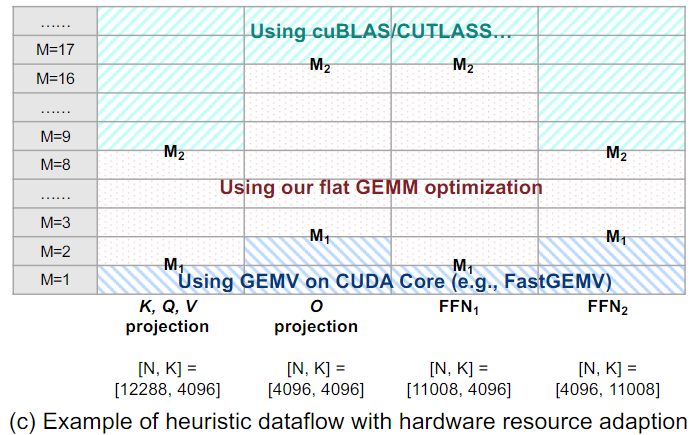
雖然這些因素構建了一個很大的搜索空間,但LLM中不同layer的同質性大大減少了算子優化的搜索空間。例如,prefillphase和decodephase中有4個GEMV/GEMM操作(K、Q、V投影、O投影、2個FFN),都可以表示為[M, K]和N x K,對應了四種[N, K]組合,如下圖所示。此外,prefillphase的M與輸入序列長度和batch size有關,decodephase的M只與batch size有關。
本文根據不同的M, K, N選取FastGEMV、flat GEMM(本文方法)、CUTLASS。
個人總結
這篇文章沒有FlashAttention和FlashDecoding驚艷,個人覺得FlashDecoding的同步處理代價不大,而且本文中動態調整softmax方法也引入了判斷、終止和分支跳轉等操作。另一個Double Buffering就是內存優化常用的乒乓buffer,也沒什么新東西。
不過話說回來,如今在tranformer架構不變的情況,LLM加速只能靠這些工程手段去優化,的確也有不錯效果。還是很有價值的。
-
數據
+關注
關注
8文章
7006瀏覽量
88946 -
gpu
+關注
關注
28文章
4729瀏覽量
128897 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:【FlashAttention-V4,非官方】FlashDecoding++
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
谷歌終止官方支持?RISC-V坎坷的安卓適配之路

TDC芯片數據手冊及官方參考例程
MHMF082A1V4-操作手冊 - PANATERM Ver6.0 松下

MHMF042A1V4-操作手冊 - PANATERM Ver6.0 松下
DS-AN3V PB30 CN-V4-開環霍爾電流傳感器
TYPC USB作為DEVICE使用的話,VBUS需要接5V電壓嗎?
X-CUBE-CRYPTOLIB V4庫文件無法添加,鏈接錯誤的原因?
將stm32_eth_lib的以太網程序移植到非官方版開發板一直不成功怎么解決?
3.5V 至 36V 輸入、1V 至 20V 輸出、4A 電源模塊LMZM33604數據表






 工商網監
工商網監
評論