 HBM的未來
HBM的未來
01.HBM
高帶寬內存(HBM)正在成為超大規模廠商的首選內存,但其在主流市場的最終命運仍然存在疑問。雖然它在數據中心中已經很成熟,并且由于人工智能/機器學習的需求導致使用量不斷增加,但其基本設計固有的缺陷阻礙了更廣泛的采用。另一方面,HBM 提供結構緊湊的 2.5D 結構尺寸,可大幅減少延遲。
Rambus產品營銷高級總監 Frank Ferro 在 Rambus 設計展會上發表演講時表示:“HBM 的優點在于,可以在可變的范圍內獲得所有這些帶寬,并且表示獲得了非常好的功耗。”
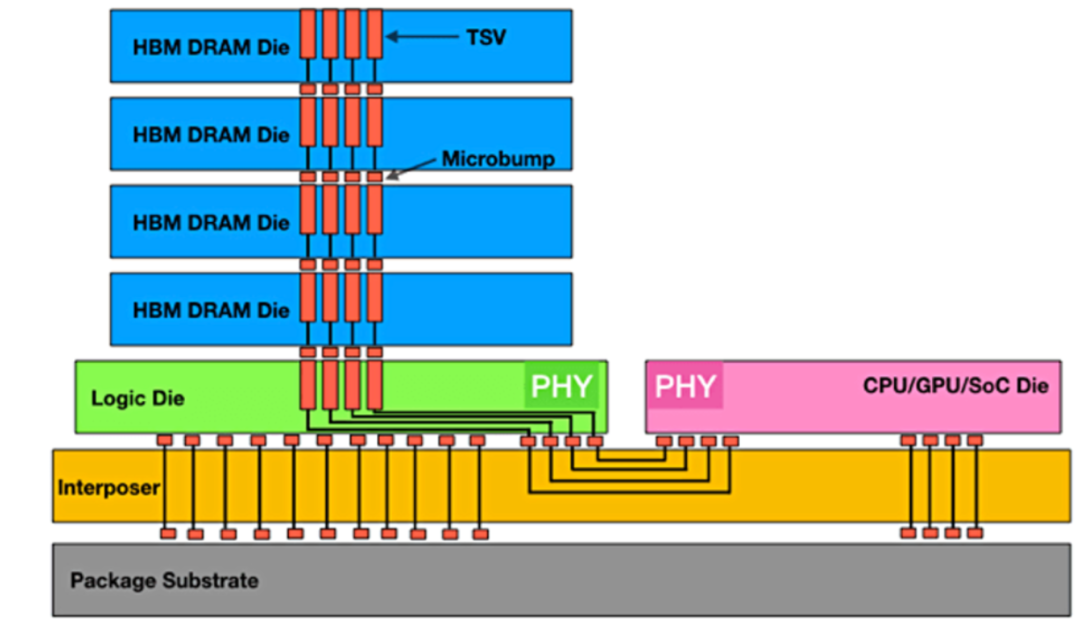
圖1:實現最大數據吞吐量的HBM堆棧
“目前困擾高帶寬內存的問題之一是成本,”Cadence IP 團隊產品營銷總監 Marc Greenberg 說道。“3D 成本相當高,相當于有一個邏輯芯片位于芯片的底部,這是你必須支付的額外硅片。然后是硅層,它位于CPU或GPU以及HBM內存的下面。然后,你需要一個更大的封裝,等等。目前現存的HBM切割了消費者領域,并更早放置在服務器機房或數據中心,存在許多系統成本。相比之下,GDDR6等圖形內存雖然無法提供與HBM一樣多的性能,但成本卻顯著降低。GDDR6的單位成本性能實際上比 HBM 好,但 GDDR6 器件的最大帶寬與 HBM 的最大帶寬不匹配。”
Greenberg表示,這些差異為公司選擇 HBM 提供了令人信服的理由,即使它可能不是他們的第一選擇。“HBM 提供充足的帶寬,并且每比特傳輸的能量極低。使用 HBM 是因為你必須這樣做,因為沒有其他解決方案可以為你提供所需的帶寬或所需的功率。”
而且 HBM 只會變得越來越快。“我們預計 HBM3 Gen2 的帶寬將提高 50%,”美光計算產品事業部副總裁兼總經理 Praveen Vaidyanathan 說道。“從美光的角度來看,我們預計 HBM3 Gen2產品將在2024財年實現量產。在2024日歷年初,我們預計隨著時間的流逝,它將開始為收入做出貢獻。此外,我們預測美光的HBM3將貢獻比DRAM更高利潤。”
盡管如此,成本因素可能會像許多設計團隊一樣考慮更有性價比的替代方案。
Greenberg指出:“如果有任何方法可以將大問題解析為更小的部分,你可能會發現它提高了成本效益。例如,面對一個巨大的問題并且必須在一個硬件上執行所有這些操作,而且我必須在那里使用 HBM,也許我可以將其中斷兩個部分。讓兩個進程任務運行,另外一部分可能連接到 DDR6。如果我能夠將問題闡釋為更小的部分,那么我可能會以更小成本完成相同數量的計算。但如果你需要那么大的帶寬,那么 HBM 就是你唯一的選擇。”
另一個主要缺點是HBM 的 2.5D 結構會積聚熱量,而其放置在接近 CPU 和 GPU 的位置會加劇這種情況。事實上,在嘗試給出不良設計的理論樣本時,很難想出比當前樣本更糟糕的東西,當前布局將 HBM及其熱敏 DRAM 堆棧放置在計算密集型熱源附近,導致散熱很難處理。
“最大的挑戰是數據,”Greenberg說。“你有一個CPU,根據定義它會生成大量數據。你通過這個接口每秒T bits,即使每次消耗只有皮焦耳熱,但每秒都會執行十億次計算,因此你的CPU會非常熱。它不僅僅是移動周圍的數據。它也必須進行計算。最重要的是最不喜歡熱的半導體組件,即DRAM。85 ℃左右它開始忘記東西,125℃左右則心不在焉。這是兩個完全不同的事情。”
還有一個可取之處。“擁有2.5D堆棧的優勢在于,CPU很熱,但可以間隔一定物理距離把HBM位于CPU旁邊,這樣會犧牲延時性能。”他說。
但是Synopsys 內存接口 IP 解決方案產品線總監 Brett Murdock說道,“在延遲和熱量之間的權衡中,延遲是不能變的。我沒有看到任何人犧牲延遲,我希望他們推動物理團隊尋找更多好的冷卻方式,或者更好的放置方式,以保持較低的延遲。”
02.HBM和AI
雖然很容易想象計算是 AI/ML 最密集的部分,但如果沒有良好的內存架構,這一切都不會發生。需要內存來存儲和檢索數萬億次計算。事實上,在某種程度上添加更多 CPU 并不會提高系統性能,因為內存帶寬無法支持它們。這就是臭名昭著的“內存墻”瓶頸。
Quadric首席營銷官 Steve Roddy 表示,從最廣泛的定義來看,學習機器只是曲線函數。“在訓練運行的每次迭代中,你都在努力越來越接近曲線的最佳函數。這是一個XY圖,就像高中幾何課一樣。大型語言模型基本上是同一件事,但是是100億維,而不是2維。”
因此,計算相對簡單,但內存架構可能非常驚人。
Roddy 解釋說:“其中一些模型擁有 1000 億字節的數據,對于每次重新訓練迭代,你都必須通過數據中心的背板從磁盤上取出 1000 億字節的數據并放入計算箱中。”“在兩個月的訓練過程中,你必須將這組巨大的內存值來回移動數百萬次。限制因素是數據的移入和移出,這就是為什么人們對 HBM 或光學互連從內存傳輸到計算結構的東西感興趣。所有這些都是人們投入數億美元風險投資的地方,因為如果你能進行每周距離或時間,你就可以最大程度地簡化每周訓練過程,無論是切斷電源還是加快速度。”
由于所有這些原因,高帶寬內存被認為是 AI/ML 的首選內存。“它提供了一些訓練算法所需的最大帶寬,”Rambus 的 Ferro 說。“從可以擁有多個內存堆棧從角度來看,它是可配置的,這提供了非常高的帶寬。”
這就是人們對 HBM 如此感興趣的原因。Synopsys的大多數客戶都是人工智能客戶,所以他們正在 LPDDR5X 接口和 HBM 接口之間進行一項重大的基本權衡。他們忽略了成本。他們真的很渴望 HBM。這是他們對技術的渴望,因為通過HBM能夠在一個 SoC 周圍創建可以足夠大的帶寬量。現在,他們可以在SoC 周圍放置了 6 個 HBM 堆棧。
然而,人工智能的需求如此之高,以至于HBM減少延遲的前沿特征又推動了下一代HBM的發展。
“延遲正在成為一個真正的問題,”Ferro說。“在 HBM 的前兩代中,我沒有聽到任何人抱怨延遲。現在我們一直收到有關延遲的問題。”
Ferro 建議,抓住當前的限制,了解數據結構極其重要。“它可能是連續的數據,例如視頻或語音識別。也可能是事務性的,就像財務數據一樣,可能非常隨機。如果你知道數據是隨機的,那么設置內存接口的方式將與流式傳輸視頻不同。這些是基本問題,但也有層次的問題。我要在內存中使用的字長是多少?內存的塊大小是多少?這個了解得越多,你設計系統的效率就越大。如果你了解了,那么你可以定制處理器,從而最大限度地提高計算能力和內存帶寬。我們看到越來越多的 ASIC 式 SoC 正在瞄準特定的目標市場剖析市場,以實現更高效的處理。”
降低 HBM 成本將是一項挑戰。由于將 TSV 放置在晶圓上的成本很高,因此加工成本已經明顯高于標準 DRAM。這使得它無法擁有像標準 DRAM 一樣大的市場。由于市場較小,規模經濟導致成本在一個自給自足的過程中更高。體積越小,成本越高,但成本越高,使用的體積就越少。沒有簡單的方法可以解決這個問題。盡管如此,HBM 已經是一個成熟的 JEDEC 標準產品,這是一種獨特的 DRAM 技術形式,能夠以比 SRAM 低得多的成本提供極高的帶寬。它還可以通過封裝提供比 SRAM 更高的密度。它會隨著時間的推移而改進,就像 DRAM 一樣。隨著接口的成熟,預計會看到更多巧妙的技巧來提高其速度。
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238253 -
機器學習
+關注
關注
66文章
8406瀏覽量
132562 -
HBM
+關注
關注
0文章
379瀏覽量
14744
原文標題:HBM的未來
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
HBM4到來前夕,HBM熱出現兩極分化
HBM3E量產后,第六代HBM4要來了!

特斯拉也在搶購HBM 4

繼HBM上車之后,移動HBM有望用在手機上
HBM上車?HBM2E被用于自動駕駛汽車
美光志在HBM市場:計劃未來兩年大幅提升市占率
中國AI芯片和HBM市場的未來
臺積電準備生產HBM4基礎芯片
三星電子組建HBM4獨立團隊,力爭奪回HBM市場領導地位
HBM供應商議價提前,2025年HBM產能產值或超DRAM 3分
英偉達CEO贊譽三星HBM內存,計劃采購
從兩會看AI產業飛躍,HBM需求預示存儲芯片新機遇

HBM、HBM2、HBM3和HBM3e技術對比

深度解析HBM內存技術






 工商網監
工商網監
評論