

微軟 Ignite 2023 技術大會發(fā)布的新工具和資源包括 OpenAIChatAPI 的 TensorRT-LLM 封裝接口、RTX 驅(qū)動的性能改進 DirectMLforLlama2、其他熱門 LLM
Windows PC 上的 AI 標志著科技史上的關鍵時刻,它將徹底改變玩家、創(chuàng)作者、主播、上班族、學生乃至普通 PC 用戶的體驗。
AI 為 1 億多臺采用 RTX GPU 的 Windows PC 和工作站提高生產(chǎn)力帶來前所未有的機會。NVIDIA RTX 技術使開發(fā)者更輕松地創(chuàng)建 AI 應用,從而改變?nèi)藗兪褂糜嬎銠C的方式。
在微軟 Ignite 2023 技術大會上發(fā)布的全新優(yōu)化、模型和資源將更快地幫助開發(fā)者提供新的終端用戶體驗。
TensorRT-LLM 是一款提升 AI 推理性能的開源軟件,它即將發(fā)布的更新將支持更多大語言模型,在 RTX GPU 8GB 及以上顯存的 PC 和筆記本電腦上使要求嚴苛的 AI 工作負載更容易完成。
Tensor RT-LLM for Windows 即將通過全新封裝接口與 OpenAI 廣受歡迎的聊天 API 兼容。這將使數(shù)以百計的開發(fā)者項目和應用能在 RTX PC 的本地運行,而非云端運行,因此用戶可以在 PC 上保留私人和專有數(shù)據(jù)。
定制的生成式 AI 需要時間和精力來維護項目。特別是跨多個環(huán)境和平臺進行協(xié)作和部署時,該過程可能會異常復雜和耗時。
AI Workbench 是一個統(tǒng)一、易用的工具包,允許開發(fā)者在 PC 或工作站上快速創(chuàng)建、測試和定制預訓練生成式 AI 模型和 LLM。它為開發(fā)者提供一個單一平臺,用于組織他們的 AI 項目,并根據(jù)特定用戶需求來調(diào)整模型。
這使開發(fā)者能夠進行無縫協(xié)作和部署,快速創(chuàng)建具有成本效益、可擴展的生成式 AI 模型。加入搶先體驗名單,成為首批用戶以率先了解不斷更新的功能,并接收更新信息。
為支持 AI 開發(fā)者,NVIDIA 與微軟發(fā)布 DirectML 增強功能以加速最熱門的基礎 AI 模型之一的 Llama 2。除了全新性能標準,開發(fā)者現(xiàn)在有更多跨供應商部署可選。
便攜式 AI
2023 年 10 月,NVIDIA 發(fā)布 TensorRT-LLM for Windows —— 一個用于加速大語言模型(LLM)推理的庫。
本月底發(fā)布的 TensorRT-LLM v0.6.0 更新將帶來至高達 5 倍的推理性能提升,并支持更多熱門的 LLM,包括全新 Mistral 7B 和 Nemotron-3 8B。這些 LLM 版本將可在所有采用 8GB 及以上顯存的 GeForce RTX 30系列和 40系列 GPU 上運行,從而使最便攜的 Windows PC 設備也能獲得快速、準確的本地運行 LLM 功能。
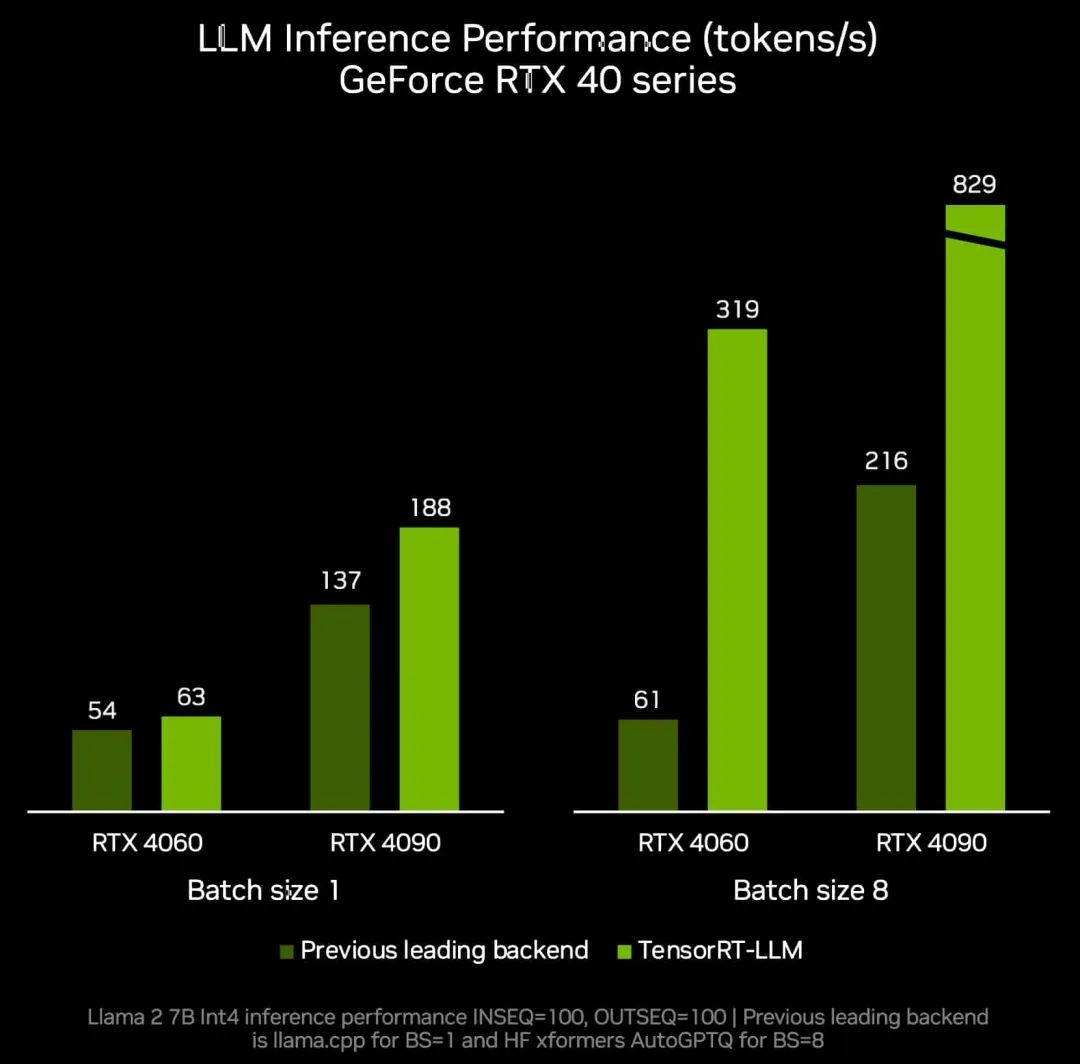
TensorRT-LLM v0.6.0
帶來至高達 5 倍推理性能提升
新發(fā)布的 TensorRT-LLM 可在/NVIDIA/TensorRT-LLMGitHub 代碼庫中下載安裝,新調(diào)優(yōu)的模型將在ngc.nvidia.com提供。
從容對話
世界各地的開發(fā)者和愛好者將 OpenAI 的聊天 API 廣泛用于各種應用——從總結網(wǎng)頁內(nèi)容、起草文件和電子郵件,到分析和可視化數(shù)據(jù)以及創(chuàng)建演示文稿。
這類基于云的 AI 面臨的一大挑戰(zhàn)是它們需要用戶上傳輸入數(shù)據(jù),因此對于私人或?qū)S袛?shù)據(jù)以及處理大型數(shù)據(jù)集來說并不實用。
為應對這一挑戰(zhàn),NVIDIA 即將啟用 TensorRT-LLM for Windows,通過全新封裝接口提供與 OpenAI 廣受歡迎的 ChatAPI 類似的 API 接口,為開發(fā)者帶來類似的工作流,無論他們設計的模型和應用要在 RTX PC 的本地運行,還是在云端運行。只需修改一兩行代碼,數(shù)百個 AI 驅(qū)動的開發(fā)者項目和應用現(xiàn)在就能從快速的本地 AI 中受益。用戶可將數(shù)據(jù)保存在 PC 上,不必擔心將數(shù)據(jù)上傳到云端。
使用由 TensorRT-LLM 驅(qū)動的
Microsoft VS Code 插件 Continue.dev 編碼助手
此外,最重要的一點是這些項目和應用中有很多都是開源的,開發(fā)者可以輕松利用和擴展它們的功能,從而加速生成式 AI 在 RTX 驅(qū)動的 Windows PC 上的應用。
該封裝接口可與所有對 TensorRT-LLM 進行優(yōu)化的 LLM (如,Llama 2、Mistral 和 NV LLM)配合使用,并作為參考項目在 GitHub 上發(fā)布,同時發(fā)布的還有用于在 RTX 上使用 LLM 的其他開發(fā)者資源。
模型加速
開發(fā)者現(xiàn)可利用尖端的 AI 模型,并通過跨供應商 API 進行部署。NVIDIA 和微軟一直致力于增強開發(fā)者能力,通過 DirectML API 在 RTX 上加速 Llama。
在 10 月宣布的為這些模型提供最快推理性能的基礎上,這一跨供應商部署的全新選項使將 AI 引入 PC 變得前所未有的簡單。
開發(fā)者和愛好者可下載最新的 ONNX 運行時并按微軟的安裝說明進行操作,同時安裝最新 NVIDIA 驅(qū)動(將于 11 月 21 日發(fā)布)以獲得最新優(yōu)化體驗。
這些新優(yōu)化、模型和資源將加速 AI 功能和應用在全球 1 億臺 RTX PC 上的開發(fā)和部署,一并加入 400 多個合作伙伴的行列,他們已經(jīng)發(fā)布了由 RTX GPU 加速的 AI 驅(qū)動的應用和游戲。
隨著模型易用性的提高,以及開發(fā)者將更多生成式 AI 功能帶到 RTX 驅(qū)動的 Windows PC 上,RTX GPU 將成為用戶利用這一強大技術的關鍵。
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
原文標題:點亮未來:TensorRT-LLM 更新加速 AI 推理性能,支持在 RTX 驅(qū)動的 Windows PC 上運行新模型
文章出處:【微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3900瀏覽量
92854
原文標題:點亮未來:TensorRT-LLM 更新加速 AI 推理性能,支持在 RTX 驅(qū)動的 Windows PC 上運行新模型
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型
使用NVIDIA推理平臺提高AI推理性能

新品| LLM630 Compute Kit,AI 大語言模型推理開發(fā)平臺

NVIDIA推出面向RTX AI PC的AI基礎模型
在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

解鎖NVIDIA TensorRT-LLM的卓越性能
Arm KleidiAI助力提升PyTorch上LLM推理性能
NVIDIA TensorRT-LLM Roadmap現(xiàn)已在GitHub上公開發(fā)布

TensorRT-LLM低精度推理優(yōu)化

開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論