") 【嵌入式AI簡(jiǎn)報(bào)20231117期】面對(duì)未來(lái)AI的三大挑戰(zhàn)!
【嵌入式AI簡(jiǎn)報(bào)20231117期】面對(duì)未來(lái)AI的三大挑戰(zhàn)!
AI 簡(jiǎn)報(bào) 20231117期
1.面對(duì)未來(lái)的AI:三大挑戰(zhàn)
當(dāng)AI如ChatGPT在2022年末突然嶄露頭角時(shí),不僅展現(xiàn)了AI的驚人進(jìn)步,還描繪出了一個(gè)充滿(mǎn)可能性的未來(lái),重新定義著我們的工作、學(xué)習(xí)和娛樂(lè)方式。盡管AI的潛力對(duì)許多人來(lái)說(shuō)顯而易見(jiàn),但其中隱藏了一些棘手的倫理和風(fēng)險(xiǎn)問(wèn)題。
應(yīng)對(duì)這些風(fēng)險(xiǎn)就像解開(kāi)一幅巨大的拼圖,這幅拼圖定義著我們的時(shí)代。因此,許多AI領(lǐng)域的專(zhuān)家正積極倡導(dǎo)制定一些基本規(guī)則,以確保AI的使用受到約束。畢竟,AI的應(yīng)用不僅僅是口號(hào),它已經(jīng)變得至關(guān)重要。
我們正在深入究專(zhuān)家們的見(jiàn)解,解開(kāi)圍繞他們的道德困境,并研究如何影響人工智能和其他技術(shù)的未來(lái)。
“倫理與偏見(jiàn)
人工智能系統(tǒng)需要使用數(shù)據(jù)進(jìn)行訓(xùn)練。但數(shù)據(jù)集往往是由有偏見(jiàn)或不準(zhǔn)確的人制作的。因此,人工智能系統(tǒng)會(huì)使偏見(jiàn)長(zhǎng)期存在。在招聘實(shí)踐和刑事司法中尤其如此,管理這些偏見(jiàn)可能很困難。
IEEE高級(jí)會(huì)員Kayne McGladrey表示:“我們可以手動(dòng)或自動(dòng)審計(jì)軟件代碼中的隱私缺陷。同樣,我們可以審計(jì)軟件代碼的安全缺陷。但是,我們目前無(wú)法審計(jì)軟件代碼是否存在道德缺陷或偏見(jiàn),即將出臺(tái)的大部分法規(guī)將對(duì)人工智能模型的結(jié)果進(jìn)行歧視性篩選。”
“改變工作方式
隨著生成人工智能的興起,公司正在重新構(gòu)想如何完成工作。雖然很少有人認(rèn)為需要?jiǎng)?chuàng)造力和判斷力的工作可以完全自動(dòng)化,但人工智能可以提供幫助。例如,當(dāng)作家陷入困境時(shí),生成型人工智能可以提供對(duì)話(huà)想法。它不能充當(dāng)你的律師,但一個(gè)好的律師可以利用生成人工智能來(lái)撰寫(xiě)動(dòng)議的初稿,或進(jìn)行研究。
IEEE會(huì)員Todd Richmond說(shuō):“我們需要共同弄清楚什么是“人類(lèi)的努力”,我們?cè)敢獍咽裁唇唤o算法,比如制作音樂(lè)、電影、行醫(yī)等。”
在全球技術(shù)領(lǐng)袖的調(diào)查(https://transmitter.ieee.org/impact-of-technology-2024/)中,其中50%的受訪(fǎng)者表示,將AI整合到現(xiàn)有工作流程中存在困難,是他們對(duì)于在2024年使用生成式AI的前三大擔(dān)憂(yōu)之一。
“準(zhǔn)確性和過(guò)度依賴(lài)性
生成型人工智能可以”自信”地闡述事實(shí),但問(wèn)題是這些事實(shí)并不總是準(zhǔn)確的。對(duì)于所有形式的人工智能,很難弄清楚該軟件究竟是如何得出結(jié)論的。
在調(diào)查中,59%的受訪(fǎng)者表示,“過(guò)度依賴(lài)人工智能和其潛在的不準(zhǔn)確性”是他們組織中人工智能使用的首要問(wèn)題。
部分問(wèn)題在于訓(xùn)練數(shù)據(jù)本身可能不準(zhǔn)確。
IEEE終身會(huì)士Paul Nikolich說(shuō):“驗(yàn)證訓(xùn)練數(shù)據(jù)很困難,因?yàn)閬?lái)源不可用,且訓(xùn)練數(shù)據(jù)量巨大。”
人工智能可能越來(lái)越多地被用于關(guān)鍵任務(wù)、拯救生命的應(yīng)用。
“在我們使用人工智能系統(tǒng)之前,我們必須相信這些人工智能系統(tǒng)將安全且按預(yù)期運(yùn)行,”IEEE會(huì)士Houbing Song說(shuō)。
在2024年及以后,預(yù)計(jì)將大力確保人工智能結(jié)果更加準(zhǔn)確,用于訓(xùn)練人工智能模型的數(shù)據(jù)是干凈的。
2. 李飛飛團(tuán)隊(duì)新作:腦控機(jī)器人做家務(wù),讓腦機(jī)接口具備少樣本學(xué)習(xí)能力
原文:https://mp.weixin.qq.com/s/TwvfHMKZNBpsFirM2PuO-Q
未來(lái)也許只需動(dòng)動(dòng)念頭,就能讓機(jī)器人幫你做好家務(wù)。斯坦福大學(xué)的吳佳俊和李飛飛團(tuán)隊(duì)近日提出的 NOIR 系統(tǒng)能讓用戶(hù)通過(guò)非侵入式腦電圖裝置控制機(jī)器人完成日常任務(wù)。
NOIR 能將你的腦電圖信號(hào)解碼為機(jī)器人技能庫(kù)。它現(xiàn)在已能完成例如烹飪壽喜燒、熨衣服、磨奶酪、玩井字游戲,甚至撫摸機(jī)器狗等任務(wù)。這個(gè)模塊化的系統(tǒng)具備強(qiáng)大的學(xué)習(xí)能力,可以應(yīng)對(duì)日常生活中復(fù)雜多變的任務(wù)。
大腦與機(jī)器人接口(BRI)堪稱(chēng)是人類(lèi)藝術(shù)、科學(xué)和工程的集大成之作。我們已經(jīng)在不勝枚舉的科幻作品和創(chuàng)意藝術(shù)中見(jiàn)到它,比如《黑客帝國(guó)》和《阿凡達(dá)》;但真正實(shí)現(xiàn) BRI 卻非易事,需要突破性的科學(xué)研究,創(chuàng)造出能與人類(lèi)完美協(xié)同運(yùn)作的機(jī)器人系統(tǒng)。
對(duì)于這樣的系統(tǒng),一大關(guān)鍵組件是機(jī)器與人類(lèi)通信的能力。在人機(jī)協(xié)作和機(jī)器人學(xué)習(xí)過(guò)程中,人類(lèi)傳達(dá)意圖的方式包括動(dòng)作、按按鈕、注視、面部表情、語(yǔ)言等等。而通過(guò)神經(jīng)信號(hào)直接與機(jī)器人通信則是最激動(dòng)人心卻也最具挑戰(zhàn)性的前景。
近日,斯坦福大學(xué)吳佳俊和李飛飛領(lǐng)導(dǎo)的一個(gè)多學(xué)科聯(lián)合團(tuán)隊(duì)提出了一種通用型的智能 BRI 系統(tǒng) NOIR(Neural Signal Operated Intelligent Robots / 神經(jīng)信號(hào)操控的智能機(jī)器人)。

論文地址:https://openreview.net/pdf?id=eyykI3UIHa
項(xiàng)目網(wǎng)站:https://noir-corl.github.io/
該系統(tǒng)基于非侵入式的腦電圖(EEG)技術(shù)。據(jù)介紹,該系統(tǒng)依據(jù)的主要原理是分層式共享自治(hierarchical shared autonomy),即人類(lèi)定義高層級(jí)目標(biāo),而機(jī)器人通過(guò)執(zhí)行低層級(jí)運(yùn)動(dòng)指令來(lái)實(shí)現(xiàn)目標(biāo)。該系統(tǒng)納入了神經(jīng)科學(xué)、機(jī)器人學(xué)和機(jī)器學(xué)習(xí)領(lǐng)域的新進(jìn)展,取得了優(yōu)于之前方法的進(jìn)步。該團(tuán)隊(duì)總結(jié)了所做出的貢獻(xiàn)。
首先,NOIR 是通用型的,可用于多樣化的任務(wù),也易于不同社區(qū)使用。研究表明,NOIR 可以完成多達(dá) 20 種日常活動(dòng);相較之下,之前的 BRI 系統(tǒng)通常是針對(duì)一項(xiàng)或少數(shù)幾項(xiàng)任務(wù)設(shè)計(jì)的,或者就僅僅是模擬系統(tǒng)。此外,只需少量培訓(xùn),普通人群也能使用 NOIR 系統(tǒng)。
其次,NOIR 中的 I 表示這個(gè)機(jī)器人系統(tǒng)是智能的(intelligent),具備自適應(yīng)能力。該機(jī)器人配備了一個(gè)多樣化的技能庫(kù),讓其無(wú)需密集的人類(lèi)監(jiān)督也能執(zhí)行低層級(jí)動(dòng)作。使用參數(shù)化的技能原語(yǔ),比如 Pick (obj-A) 或 MoveTo (x,y),機(jī)器人可以很自然地取得、解讀和執(zhí)行人類(lèi)的行為目標(biāo)。
此外,NOIR 系統(tǒng)還有能力在協(xié)作過(guò)程中學(xué)習(xí)人類(lèi)想達(dá)成的目標(biāo)。研究表明,通過(guò)利用基礎(chǔ)模型的最新進(jìn)展,該系統(tǒng)甚至能適應(yīng)很有限的數(shù)據(jù)。這能顯著提升系統(tǒng)的效率。
NOIR 的關(guān)鍵技術(shù)貢獻(xiàn)包括一個(gè)模塊化的解碼神經(jīng)信號(hào)以獲知人類(lèi)意圖的工作流程。要知道,從神經(jīng)信號(hào)解碼出人類(lèi)意圖目標(biāo)是極具挑戰(zhàn)性的。為此,該團(tuán)隊(duì)的做法是將人類(lèi)意圖分解為三大組分:要操控的物體(What)、與該物體交互的方式(How)、交互的位置(Where)。他們的研究表明可以從不同類(lèi)型的神經(jīng)數(shù)據(jù)中解碼出這些信號(hào)。這些分解后的信號(hào)可以自然地對(duì)應(yīng)于參數(shù)化的機(jī)器人技能,并且可以有效地傳達(dá)給機(jī)器人。
在 20 項(xiàng)涉及桌面或移動(dòng)操作的家庭活動(dòng)(包括制作壽喜燒、熨燙衣物、玩井字棋、摸機(jī)器狗狗等)中,三名人類(lèi)受試者成功地使用了 NOIR 系統(tǒng),即通過(guò)他們的大腦信號(hào)完成了這些任務(wù)!

實(shí)驗(yàn)表明,通過(guò)以人類(lèi)為師進(jìn)行少樣本機(jī)器人學(xué)習(xí),可以顯著提升 NOIR 系統(tǒng)的效率。這種使用人腦信號(hào)協(xié)作來(lái)構(gòu)建智能機(jī)器人系統(tǒng)的方法潛力巨大,可用于為人們(尤其是殘障人士)開(kāi)發(fā)至關(guān)重要的輔助技術(shù),提升他們的生活品質(zhì)。
NOIR 系統(tǒng)
這項(xiàng)研究力圖解決的挑戰(zhàn)包括:1. 如何構(gòu)建適用于各種任務(wù)的通用 BRI 系統(tǒng)?2. 如何解碼來(lái)自人腦的相關(guān)通信信號(hào)?3. 如何提升機(jī)器人的智能和適應(yīng)能力,從而實(shí)現(xiàn)更高效的協(xié)作?圖 2 給出了該系統(tǒng)的概況。
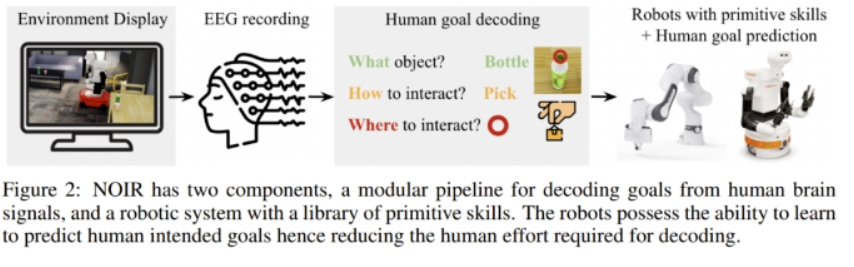
在這個(gè)系統(tǒng)中,人類(lèi)作為規(guī)劃智能體,做的是感知、規(guī)劃以及向機(jī)器人傳達(dá)行為目標(biāo);而機(jī)器人則要使用預(yù)定義的原語(yǔ)技能實(shí)現(xiàn)這些目標(biāo)。
為了實(shí)現(xiàn)打造通用 BRI 系統(tǒng)的總體目標(biāo),需要將這兩種設(shè)計(jì)協(xié)同集成到一起。為此,該團(tuán)隊(duì)提出了一種全新的大腦信號(hào)解碼工作流程,并為機(jī)器人配備了一套參數(shù)化的原始技能庫(kù)。最后,該團(tuán)隊(duì)使用少樣本模仿學(xué)習(xí)技術(shù)讓機(jī)器人具備了更高效的學(xué)習(xí)能力。
大腦:模塊化的解碼工作流程
如圖 3 所示,人類(lèi)意圖會(huì)被分解成三個(gè)組分:要操控的物體(What)、與該物體交互的方式(How)、交互的位置(Where)。
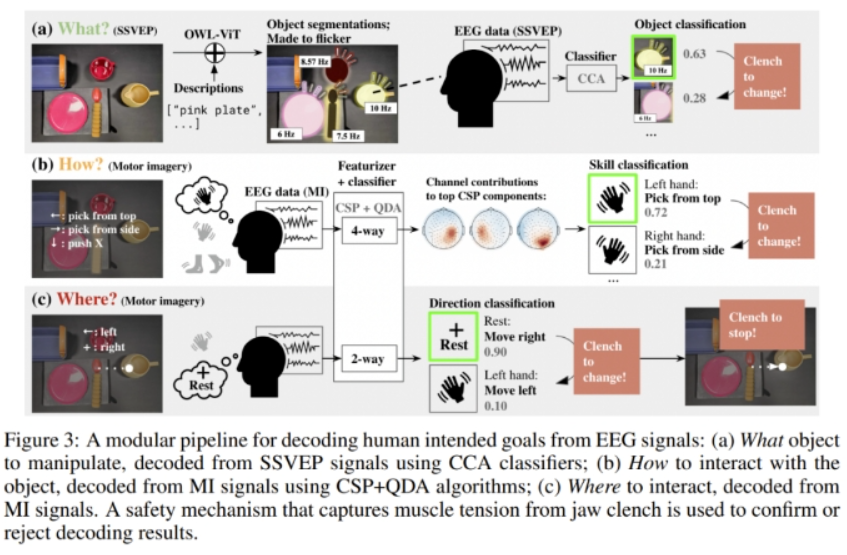
要從腦電圖信號(hào)解碼出具體的用戶(hù)意圖,難度可不小,但可以通過(guò)穩(wěn)態(tài)視覺(jué)誘發(fā)電位(SSVEP)和運(yùn)動(dòng)意象(motor imagery)來(lái)完成。簡(jiǎn)單來(lái)說(shuō),這個(gè)過(guò)程包括:
-
選取具有穩(wěn)態(tài)視覺(jué)誘發(fā)電位(SSVEP)的物體
-
通過(guò)運(yùn)動(dòng)意象(MI)選擇技能和參數(shù)
-
通過(guò)肌肉收緊來(lái)選擇確認(rèn)或中斷
機(jī)器人:參數(shù)化的原語(yǔ)技能
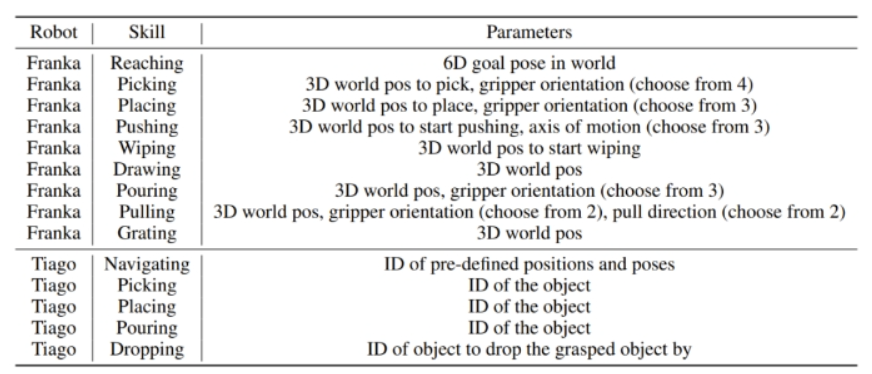
參數(shù)化的原語(yǔ)技能可以針對(duì)不同的任務(wù)進(jìn)行組合和復(fù)用,從而實(shí)現(xiàn)復(fù)雜多樣的操作。此外,對(duì)人類(lèi)而言,這些技能非常直觀(guān)。人類(lèi)和智能體都無(wú)需了解這些技能的控制機(jī)制,因此人們可以通過(guò)任何方法實(shí)現(xiàn)這些技能,只要它們是穩(wěn)健的且能適應(yīng)多樣化的任務(wù)。
該團(tuán)隊(duì)在實(shí)驗(yàn)中使用了兩臺(tái)機(jī)器人:一臺(tái)是用于桌面操作任務(wù)的 Franka Emika Panda 機(jī)械臂,另一臺(tái)是用于移動(dòng)操作任務(wù)的 PAL Tiago 機(jī)器人。下表給出了這兩臺(tái)機(jī)器人的原語(yǔ)技能。
使用機(jī)器人學(xué)習(xí)實(shí)現(xiàn)高效的 BRI
上述的模塊化解碼工作流程和原語(yǔ)技能庫(kù)為 NOIR 奠定了基礎(chǔ)。但是,這種系統(tǒng)的效率還能進(jìn)一步提升。機(jī)器人應(yīng)當(dāng)能在協(xié)作過(guò)程中學(xué)習(xí)用戶(hù)的物品、技能和參數(shù)選擇偏好,從而在未來(lái)能預(yù)測(cè)用戶(hù)希望達(dá)成的目標(biāo),實(shí)現(xiàn)更好的自動(dòng)化,也讓解碼更簡(jiǎn)單容易。由于每一次執(zhí)行時(shí),物品的位置、姿態(tài)、排列和實(shí)例可能會(huì)有所不同,因此就需要學(xué)習(xí)和泛化能力。另外,學(xué)習(xí)算法應(yīng)當(dāng)具有較高的樣本效率,因?yàn)槭占祟?lèi)數(shù)據(jù)的成本很高。
該團(tuán)隊(duì)為此采用了兩種方法:基于檢索的少樣本物品和技能選取、單樣本技能參數(shù)學(xué)習(xí)。
基于檢索的少樣本物品和技能選取。該方法可以學(xué)習(xí)所觀(guān)察狀態(tài)的隱含表征。給定一個(gè)觀(guān)察到的新?tīng)顟B(tài),它會(huì)在隱藏空間中找到最相似的狀態(tài)以及對(duì)應(yīng)的動(dòng)作。圖 4 給出了該方法的概況。
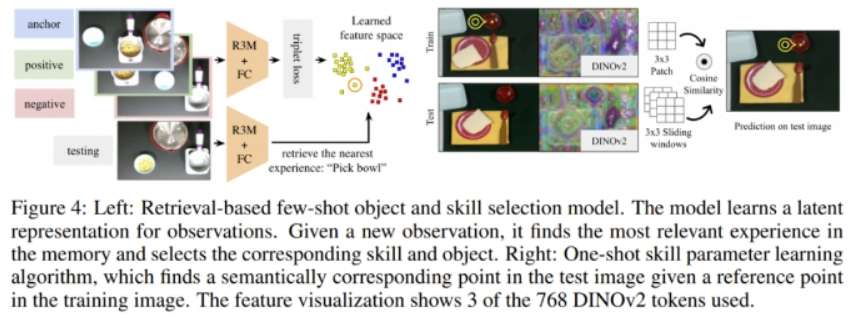
在任務(wù)執(zhí)行期間,由圖像和人類(lèi)選擇的「物品 - 技能」對(duì)構(gòu)成的數(shù)據(jù)點(diǎn)會(huì)被記錄下來(lái)。這些圖像首先會(huì)被一個(gè)預(yù)訓(xùn)練的 R3M 模型編碼,以提取出對(duì)機(jī)器人操控任務(wù)有用的特征,然后再讓它們通過(guò)一些可訓(xùn)練的全連接層。這些層的訓(xùn)練使用了帶三元組損失的對(duì)比學(xué)習(xí),這會(huì)鼓勵(lì)帶有同樣「物品 - 技能」標(biāo)簽的圖像在隱藏空間中處于更相近的位置。所學(xué)習(xí)到的圖像嵌入和「物品 - 技能」標(biāo)簽會(huì)被存儲(chǔ)到內(nèi)存中。
在測(cè)試期間,模型會(huì)檢索隱藏空間中最近的數(shù)據(jù)點(diǎn),然后將與該數(shù)據(jù)點(diǎn)關(guān)聯(lián)的「物品 - 技能」對(duì)建議給人類(lèi)。
單樣本技能參數(shù)學(xué)習(xí)。參數(shù)選取需要人類(lèi)大量參與,因?yàn)檫@個(gè)過(guò)程需要通過(guò)運(yùn)動(dòng)意象(MI)進(jìn)行精準(zhǔn)的光標(biāo)操作。為了減少人類(lèi)的工作量,該團(tuán)隊(duì)提出了一種學(xué)習(xí)算法,可以根據(jù)給定的用作光標(biāo)控制起始點(diǎn)的「物品 - 技能」對(duì)來(lái)預(yù)測(cè)參數(shù)。假設(shè)用戶(hù)已經(jīng)成功定位了拿起一個(gè)杯子把手的精確關(guān)鍵點(diǎn),那么未來(lái)還需要再次指定這個(gè)參數(shù)嗎?最近 DINOv2 等基礎(chǔ)模型取得了不少進(jìn)展,已經(jīng)可以找到相應(yīng)的語(yǔ)義關(guān)鍵點(diǎn),從而無(wú)需再次指定參數(shù)。
相比于之前的工作,這里提出的新算法是單樣本的并且預(yù)測(cè)的是具體的 2D 點(diǎn),而非語(yǔ)義片段。如圖 4 所示,給定一張訓(xùn)練圖像(360 × 240)和參數(shù)選擇 (x, y),模型預(yù)測(cè)不同的測(cè)試圖像中語(yǔ)義上對(duì)應(yīng)的點(diǎn)。該團(tuán)隊(duì)具體使用的是預(yù)訓(xùn)練的 DINOv2 模型來(lái)獲取語(yǔ)義特征。
實(shí)驗(yàn)和結(jié)果
任務(wù)。實(shí)驗(yàn)選取的任務(wù)來(lái)自 BEHAVIOR 和 Activities of Daily Living 基準(zhǔn),這兩個(gè)基準(zhǔn)能在一定程度上體現(xiàn)人類(lèi)的日常需求。圖 1 展示了實(shí)驗(yàn)任務(wù),其中包含 16 個(gè)桌面任務(wù)和 4 個(gè)移動(dòng)操作任務(wù)。
下面展示了制作三明治和護(hù)理新冠病人的實(shí)驗(yàn)過(guò)程示例。
實(shí)驗(yàn)流程。實(shí)驗(yàn)過(guò)程中,用戶(hù)待在一個(gè)隔離房間中,保持靜止,在屏幕上觀(guān)看機(jī)器人,單純依靠大腦信號(hào)與機(jī)器人溝通。
系統(tǒng)性能。表 1 總結(jié)了兩個(gè)指標(biāo)下的系統(tǒng)性能:成功之前的嘗試次數(shù)和成功時(shí)完成任務(wù)的時(shí)間。
盡管這些任務(wù)跨度長(zhǎng),難度大,但 NOIR 還是得到了非常鼓舞人心的結(jié)果:平均而言,只需嘗試 1.83 次就能完成任務(wù)。
解碼準(zhǔn)確度。解碼大腦信號(hào)的準(zhǔn)確度是 NOIR 系統(tǒng)成功的一大關(guān)鍵。表 2 總結(jié)了不同階段的解碼準(zhǔn)確度。可以看到,基于 SSVEP 的 CCA(典型相關(guān)分析)能達(dá)到 81.2% 的高準(zhǔn)確度,也就是說(shuō)物品選取大體上是準(zhǔn)確的。
物品和技能選取結(jié)果。那么,新提出的機(jī)器人學(xué)習(xí)算法能否提升 NOIR 的效率呢?研究者首先對(duì)物品和技能選取學(xué)習(xí)進(jìn)行了評(píng)估。為此,他們?yōu)?MakePasta 任務(wù)收集了一個(gè)離線(xiàn)數(shù)據(jù)集,其中每一對(duì)「物品 - 技能」都有 15 個(gè)訓(xùn)練樣本。給定一張圖像,當(dāng)同時(shí)預(yù)測(cè)出了正確的物品和技能時(shí),就認(rèn)為該預(yù)測(cè)是正確的。結(jié)果見(jiàn)表 3。使用 ResNet 的簡(jiǎn)單圖像分類(lèi)模型能實(shí)現(xiàn) 0.31 的平均準(zhǔn)確度,而基于預(yù)訓(xùn)練 ResNet 骨干網(wǎng)絡(luò)使用新方法時(shí)卻能達(dá)到顯著更高的 0.73,這凸顯出了對(duì)比學(xué)習(xí)和基于檢索的學(xué)習(xí)的重要性。
單樣本參數(shù)學(xué)習(xí)的結(jié)果。研究者基于預(yù)先收集的數(shù)據(jù)集將新算法與多個(gè)基準(zhǔn)進(jìn)行了比較。表 4 給出了預(yù)測(cè)結(jié)果的 MSE 值。
他們還在 SetTable 任務(wù)上展現(xiàn)了參數(shù)學(xué)習(xí)算法在實(shí)際任務(wù)執(zhí)行中的有效性。圖 5 給出了控制光標(biāo)移動(dòng)方面所節(jié)省的人類(lèi)工作量。
3. 微軟深夜連甩三大炸彈!Bing Chat更名Copilot,自研芯片問(wèn)世,還加入GPTs功能
原文:https://mp.weixin.qq.com/s/jZs_yHPVjo_OggzWClMXpQ
就在剛剛,微軟正式對(duì)外重磅宣布:
從今天起,Bing Chat全線(xiàn)更名——Copilot。
和ChatGPT一樣,現(xiàn)在的微軟Copilot也擁有自己的專(zhuān)屬網(wǎng)站。
但與之不同的是,像GPT-4、DALL·E 3這樣的功能,在Copilot上統(tǒng)統(tǒng)都是免費(fèi)的!
要想使用這一切,你只需要做的就是登錄微軟賬號(hào)(而ChatGPT則需要訂閱會(huì)員)。 a
就連OpenAI上周王炸推出的自定義GPT,也被微軟塞了進(jìn)來(lái),并取名為——Copilot Studio。
而圍繞新品牌Copilot,微軟的大動(dòng)作還不止于此。
例如流傳已久的自研芯片,今天終于亮相了——2款高端定制芯片,Azure Maia 100和Azure Cobalt 100。
據(jù)外媒推測(cè),尤其是像Maia 100這種AI芯片,很可能就是要用在Copilot品牌下的一些新功能。
除此之外,打工人最關(guān)心的Office,這次也是塞滿(mǎn)了Copilot。
總而言之,縱觀(guān)整場(chǎng)微軟Ignite大會(huì),“Copilot”可謂是貫穿了所有。
正如外媒的評(píng)價(jià):
微軟可以叫“Copilot公司”了。
一切皆可Copilot
對(duì)于Bing Chat更名為Copilot,微軟CEO納德拉在現(xiàn)場(chǎng)將此高度總結(jié)為:
Copilot無(wú)所不在。
現(xiàn)在,無(wú)論是在微軟的Edge、谷歌的Chrome、蘋(píng)果的Safari,亦或是移動(dòng)端,均可使用Copilot。
不過(guò)需要強(qiáng)調(diào)的一點(diǎn)是,雖然Copilot只需要登錄微軟賬號(hào)就可以免費(fèi)使用,但像Microsoft 365等其它產(chǎn)品的Copilot依舊是付費(fèi)的。
對(duì)于類(lèi)似OpenAI GPTs的Copilot Studio,從微軟的介紹來(lái)看,它還是有一點(diǎn)不同。
Copilot Studio的主要設(shè)計(jì)目的其實(shí)是擴(kuò)展Microsoft 365 Copilot。
在該應(yīng)用中,大伙可以用它自定義包含不同數(shù)據(jù)集、自動(dòng)化流程的Copilot。
由此一來(lái),我們就可以將這些自定義AI助手更專(zhuān)注地連接到公司的關(guān)鍵業(yè)務(wù)系統(tǒng)中(是的,主要面向企業(yè)用戶(hù)),然后就像與人聊天一樣方便地獲取其中信息。
它可以是網(wǎng)站上幫助用戶(hù)回答產(chǎn)品問(wèn)題的Copilot,也可以是季度收益發(fā)布中的Copilot。
對(duì)于這項(xiàng)新功能,最重磅的一點(diǎn)還是:
OpenAI GPTs居然也被直接塞了進(jìn)來(lái),大伙在構(gòu)建自定義Copilot時(shí),也能用上它的功能
最后,Copilot系列除了以上這些,微軟還發(fā)布了Copilot for Azure,一個(gè)專(zhuān)門(mén)通過(guò)聊天方式簡(jiǎn)化日常IT管理的AI。
首款5nm自研AI芯片
在圍繞Copilot的一系列重磅炸彈放出之時(shí),微軟的自研芯片也終于來(lái)了。
一共兩款。
Azure芯片部門(mén)副總裁透露,Maia 100已在其Bing和Office AI產(chǎn)品上測(cè)試。
以及劃重點(diǎn):OpenAI也在試用。這意味著ChatGPT等模型的云訓(xùn)練和推理都將可能基于該芯片。
第二款叫Cobalt 100,是一款64位、128計(jì)算核心的CPU,基于ARM指令集架構(gòu),對(duì)標(biāo)英特爾和AMD同類(lèi)處理器。
Cobalt 100也被設(shè)計(jì)為專(zhuān)門(mén)用于云計(jì)算,相比微軟Azure一直在用的其他基于ARM的芯片,可帶來(lái)40%功耗下降。
目前,它已開(kāi)始為Microsoft Teams等應(yīng)用提供支持。
微軟介紹,這兩款芯片全部由臺(tái)積電生產(chǎn),將在明年初在微軟的幾個(gè)數(shù)據(jù)中心首次公開(kāi)亮相。
以及它們都還只是各自系列中的頭陣產(chǎn)品,言外之意,后面還會(huì)繼續(xù)研發(fā)上新。
現(xiàn)在,微軟也終于在谷歌TPU和亞馬遜Graviton之后,擁有了自研AI芯片——三大云巨頭也“齊活”了。
Office更新:降價(jià)了
最最后,圍繞微軟Office一系列套件的AI產(chǎn)品Copilot for Microsoft 365也更新了n多功能(沒(méi)在大會(huì)上宣布,直接官網(wǎng)通知)。
主要思想就是更加個(gè)性化、更強(qiáng)的數(shù)學(xué)和分析能力以及全面打通協(xié)作。
譬如在Word和PowerPoint中,我們可以設(shè)置更多寫(xiě)作格式、風(fēng)格、語(yǔ)氣的偏好,獲得更為量身定制的文檔和PPT,更像你本人(親自創(chuàng)作的)。
在Excel中,則能用自然語(yǔ)言解鎖更多復(fù)雜的數(shù)學(xué)分析。
在Team中,可以直接將大伙的頭腦風(fēng)暴轉(zhuǎn)為可視化白板,如果你想專(zhuān)門(mén)看看某位同事說(shuō)了什么,直接使用“Quote xx”命令即可呈現(xiàn)Copilot為你記錄的全部發(fā)言。
當(dāng)然,最最值得關(guān)注的更新還是降價(jià)了。
現(xiàn)在每月只需50美元即可享受企業(yè)服務(wù),比之前少了20刀。
4. 中文最強(qiáng)開(kāi)源大模型來(lái)了!130億參數(shù),0門(mén)檻商用,來(lái)自昆侖萬(wàn)維
原文:https://mp.weixin.qq.com/s/MKu6eusxyCXw3fLhgbcp0A
開(kāi)源最徹底的大模型來(lái)了——130億參數(shù),無(wú)需申請(qǐng)即可商用。
不僅如此,它還附帶著把全球最大之一的中文數(shù)據(jù)集也一并開(kāi)源了出來(lái):600G、1500億tokens!
這就是來(lái)自昆侖萬(wàn)維的Skywork-13B系列,包含兩大版本:
-
Skywork-13B-Base:該系列的基礎(chǔ)模型,在多種基準(zhǔn)評(píng)測(cè)中都拔得頭籌的那種。
-
Skywork-13B-Math:該系列的數(shù)學(xué)模型,數(shù)學(xué)能力在GSM8K評(píng)測(cè)上得分第一。
在各大權(quán)威評(píng)測(cè)benchmark上,如C-Eval、MMLU、CMMLU、GSM8K,可以看到Skywork-13B在中文開(kāi)源模型中處于前列,在同等參數(shù)規(guī)模下為最優(yōu)水平。
而Skywork-13B系列之所以能取得如此亮眼的成績(jī),部分原因離不開(kāi)剛才我們提到的數(shù)據(jù)集。
畢竟清洗好的中文數(shù)據(jù)對(duì)于大模型來(lái)說(shuō)可謂是至關(guān)重要,幾乎從某種程度上決定了其性能。
但昆侖萬(wàn)維能將如此“至寶”無(wú)償?shù)亟o奉獻(xiàn)出來(lái),不難看出它對(duì)于構(gòu)建開(kāi)源社區(qū)、服務(wù)開(kāi)發(fā)者的滿(mǎn)滿(mǎn)誠(chéng)意。
除此之外,昆侖萬(wàn)維Skywork-13B此次還配套了“輕量版”大模型,是在消費(fèi)級(jí)顯卡中就能部署和推理的那種!
Skywork-13B下載地址(Model Scope):
https://modelscope.cn/organization/skywork
Skywork-13B下載地址(Github):
https://github.com/SkyworkAI/Skywork
接下來(lái),我們進(jìn)一步來(lái)看下Skywork-13B系列更多的能力。
無(wú)需申請(qǐng)即可商用
Skywork-13B系列大模型擁有130億參數(shù)、3.2萬(wàn)億高質(zhì)量多語(yǔ)言訓(xùn)練數(shù)據(jù)。
由此,模型在生成、創(chuàng)作、數(shù)學(xué)推理等任務(wù)上提升明顯。
首先在中文語(yǔ)言建模困惑度評(píng)測(cè)中,Skywork-13B系列大模型超越了目前所有中文開(kāi)源模型。
在科技、金融、政務(wù)、企業(yè)服務(wù)、文創(chuàng)、游戲等領(lǐng)域均表現(xiàn)出色。
另外,Skywork-13B-Math專(zhuān)長(zhǎng)數(shù)學(xué)任務(wù),進(jìn)行過(guò)數(shù)學(xué)能力強(qiáng)化訓(xùn)練,在GSM8K等數(shù)據(jù)集中取得了同等規(guī)模模型最佳效果。
與此同時(shí),昆侖萬(wàn)維還開(kāi)源了數(shù)據(jù)集Skypile/Chinese-Web-Text-150B。其數(shù)據(jù)是通過(guò)精心過(guò)濾的數(shù)據(jù)處理流程從中文網(wǎng)頁(yè)中篩選而來(lái)。
由此,開(kāi)發(fā)者可以最大程度借鑒技術(shù)報(bào)告中大模型預(yù)訓(xùn)練的過(guò)程和經(jīng)驗(yàn),深度定制模型參數(shù),進(jìn)行針對(duì)性訓(xùn)練與優(yōu)化 。
除此之外,Skywork-13B還公開(kāi)了模型使用的評(píng)估方法、數(shù)據(jù)配比研究和訓(xùn)練基礎(chǔ)設(shè)施調(diào)優(yōu)方案等。
而Skywork-13B的一系列開(kāi)源,無(wú)需申請(qǐng)即可商用!
用戶(hù)在下載模型并同意遵守《Skywork模型社區(qū)許可協(xié)議》后,不用再次申請(qǐng)商業(yè)授權(quán)。
授權(quán)流程也取消了對(duì)行業(yè)、公司規(guī)模、用戶(hù)數(shù)量等方面限制。
昆侖萬(wàn)維會(huì)如此徹底開(kāi)源其實(shí)也并不意外。
昆侖萬(wàn)維董事長(zhǎng)兼CEO方漢是最早參與到開(kāi)源生態(tài)建設(shè)的老兵了,也是中文Linux開(kāi)源最早的推動(dòng)者之一。
在今年ChatGPT趨勢(shì)剛剛興起時(shí),他就多次公開(kāi)發(fā)聲、強(qiáng)調(diào)開(kāi)源的重要性:
代碼開(kāi)源可助力中國(guó)版ChatGPT彎道超車(chē)。
所以也就不難理解Skywork-13B系列大模型的推出了。
而在短短2個(gè)月后,昆侖萬(wàn)維又將最新的大模型、最新的數(shù)據(jù)集,一并發(fā)布且開(kāi)源,可以說(shuō)它的一切動(dòng)作不僅在于快,更是在于敢。
那么接下來(lái)的問(wèn)題是——為什么要這么做?
其實(shí),對(duì)于AIGC這一板塊,昆侖萬(wàn)維早在2020年便已經(jīng)開(kāi)始涉足,早早的準(zhǔn)備和技術(shù)積累就是它能夠在大熱潮來(lái)臨之際快速跟進(jìn)的原因之一。
據(jù)了解,昆侖萬(wàn)維目前已形成AI大模型、AI搜索、AI游戲、AI音樂(lè)、AI動(dòng)漫、AI社交六大AI業(yè)務(wù)矩陣。
至于不遺余力的將開(kāi)源這事做好做大,一方面是源于企業(yè)的基因。
昆侖萬(wàn)維董事長(zhǎng)兼CEO方漢是最早參與到開(kāi)源生態(tài)建設(shè)的開(kāi)源老兵,也是中文Linux開(kāi)源最早的推動(dòng)者之一,開(kāi)源的精神和AIGC技術(shù)的發(fā)展早已在昆侖萬(wàn)維戰(zhàn)略中完美融合。
正如方漢此前所言:
昆侖天工之所以選擇開(kāi)源,因?yàn)槲覀儓?jiān)信開(kāi)源是推動(dòng)AIGC生態(tài)發(fā)展的土壤和重要力量。昆侖萬(wàn)維致力于在AIGC模型算法方面的技術(shù)創(chuàng)新和開(kāi)拓,致力于推進(jìn)開(kāi)源AIGC算法和模型社區(qū)的發(fā)展壯大,致力于降低AIGC技術(shù)在各行各業(yè)的使用和學(xué)習(xí)門(mén)檻。
沒(méi)錯(cuò),降低門(mén)檻,便是其堅(jiān)持開(kāi)源的另一大原因。
從昆侖萬(wàn)維入局百模大戰(zhàn)以來(lái)的種種動(dòng)作中,也很容易看到它正在踐行著讓天工用起來(lái)更簡(jiǎn)單、更絲滑。
總而言之,昆侖萬(wàn)維目前已然是處于國(guó)產(chǎn)大模型的第一梯隊(duì),甚至說(shuō)是立于金字塔尖都不足為過(guò)。
那么在更大力度的開(kāi)源加持之下,天工大模型還將有怎樣驚艷的表現(xiàn),是值得期待一波了。
5. 最強(qiáng)大模型訓(xùn)練芯片H200發(fā)布!141G大內(nèi)存,AI推理最高提升90%,還兼容H100
原文:https://mp.weixin.qq.com/s/IYPpzHgXuYHGrO-BRgyWhw
英偉達(dá)老黃,帶著新一代GPU芯片H200再次炸場(chǎng)。
官網(wǎng)毫不客氣就直說(shuō)了,“世界最強(qiáng)GPU,專(zhuān)為AI和超算打造”。
聽(tīng)說(shuō)所有AI公司都抱怨內(nèi)存不夠?這回直接141GB大內(nèi)存,與H100的80GB相比直接提升76%。作為首款搭載HBM3e內(nèi)存的GPU,內(nèi)存帶寬也從3.35TB/s提升至4.8TB/s,提升43%。
對(duì)于AI來(lái)說(shuō)意味著什么?來(lái)看測(cè)試數(shù)據(jù)。在HBM3e加持下,H200讓Llama-70B推理性能幾乎翻倍,運(yùn)行GPT3-175B也能提高60%。
最強(qiáng)AI芯片只能當(dāng)半年
除內(nèi)存大升級(jí)之外,H200與同屬Hopper架構(gòu)的H100相比其他方面基本一致。
臺(tái)積電4nm工藝,800億晶體管,NVLink 4每秒900GB的高速互聯(lián),都被完整繼承下來(lái)。
甚至峰值算力也保持不變,數(shù)據(jù)一眼看過(guò)去,還是熟悉的FP64 Vector 33.5TFlops、FP64 Tensor 66.9TFlops。
對(duì)于內(nèi)存為何是有零有整的141GB,AnandTech分析HBM3e內(nèi)存本身的物理容量為144GB,由6個(gè)24GB的堆棧組成。
出于量產(chǎn)原因,英偉達(dá)保留了一小部分作為冗余,以提高良品率。
僅靠升級(jí)內(nèi)存,與2020年發(fā)布的A100相比,H200就在GPT-3 175B的推理上加速足足18倍。
H200預(yù)計(jì)在2024年第2季度上市,但最強(qiáng)AI芯片的名號(hào)H200只能擁有半年。
同樣在2024年的第4季度,基于下一代Blackwell架構(gòu)的B100也將問(wèn)世,具體性能還未知,圖表暗示了會(huì)是指數(shù)級(jí)增長(zhǎng)。
多家超算中心將部署GH200超算節(jié)點(diǎn)
除了H200芯片本身,英偉達(dá)此次還發(fā)布了由其組成的一系列集群產(chǎn)品。
首先是HGX H200平臺(tái),它是將8塊H200搭載到HGX載板上,總顯存達(dá)到了1.1TB,8位浮點(diǎn)運(yùn)算速度超過(guò)32P(10^15) FLOPS,與H100數(shù)據(jù)一致。
HGX使用了英偉達(dá)的NVLink和NVSwitch高速互聯(lián)技術(shù),可以以最高性能運(yùn)行各種應(yīng)用負(fù)載,包括175B大模型的訓(xùn)練和推理。
HGX板的獨(dú)立性質(zhì)使其能夠插入合適的主機(jī)系統(tǒng),從而允許使用者定制其高端服務(wù)器的非GPU部分。

接下來(lái)是Quad GH200超算節(jié)點(diǎn)——它由4個(gè)GH200組成,而GH200是H200與Grace CPU組合而成的。
Quad GH200節(jié)點(diǎn)將提供288 Arm CPU內(nèi)核和總計(jì)2.3TB的高速內(nèi)存。
通過(guò)大量超算節(jié)點(diǎn)的組合,H200最終將構(gòu)成龐大的超級(jí)計(jì)算機(jī),一些超級(jí)計(jì)算中心已經(jīng)宣布正在向其超算設(shè)備中集成GH200系統(tǒng)。
據(jù)英偉達(dá)官宣,德國(guó)尤利希超級(jí)計(jì)算中心將在Jupiter超級(jí)計(jì)算機(jī)使用GH200超級(jí)芯片,包含的GH200節(jié)點(diǎn)數(shù)量達(dá)到了24000塊,功率為18.2兆瓦,相當(dāng)于每小時(shí)消耗18000多度電。
該系統(tǒng)計(jì)劃于2024年安裝,一旦上線(xiàn),Jupiter將成為迄今為止宣布的最大的基于Hopper的超級(jí)計(jì)算機(jī)。
Jupiter大約將擁有93(10^18) FLOPS的AI算力、1E FLOPS的FP64運(yùn)算速率、1.2PB每秒的帶寬,以及10.9PB的LPDDR5X和另外2.2PB的HBM3內(nèi)存。
除了Jupiter,日本先進(jìn)高性能計(jì)算聯(lián)合中心、德克薩斯高級(jí)計(jì)算中心、伊利諾伊大學(xué)香檳分校國(guó)家超級(jí)計(jì)算應(yīng)用中心等超算中心也紛紛宣布將使用GH200對(duì)其超算設(shè)備進(jìn)行更新升級(jí)。
那么,AI從業(yè)者都有哪些嘗鮮途徑可以體驗(yàn)到GH200呢?
上線(xiàn)之后,GH200將可以通過(guò)Lambda、Vultr等特定云服務(wù)提供商進(jìn)行搶先體驗(yàn),Oracle和CoreWeave也宣布了明年提供GH200實(shí)例的計(jì)劃,亞馬遜、谷歌云、微軟Azure同樣也將成為首批部署GH200實(shí)例的云服務(wù)提供商。
英偉達(dá)自身,也會(huì)通過(guò)其N(xiāo)VIDIA LaunchPad平臺(tái)提供對(duì)GH200的訪(fǎng)問(wèn)。
硬件制造商方面,華碩、技嘉等廠(chǎng)商計(jì)劃將于今年年底開(kāi)始銷(xiāo)售搭載GH200的服務(wù)器設(shè)備。
6. 干貨分享~最新Yolo系列模型的部署、精度對(duì)齊與int8量化加速
原文:https://mp.weixin.qq.com/s/f2nPgwX2g-H8-8M8TXd38w
分享下朋友的一系列關(guān)于YOLO部署的干貨,純白嫖,來(lái)源請(qǐng)看原文鏈接。
本文寫(xiě)于2023-11-02晚
若需轉(zhuǎn)載請(qǐng)聯(lián)系 haibintian@foxmail.com
大家好,我是海濱。寫(xiě)這篇文章的目的是為宣傳我在23年初到現(xiàn)在完成的一項(xiàng)工作---Yolo系列模型在TensorRT上的部署與量化加速,目前以通過(guò)視頻的形式在B站發(fā)布(不收費(fèi),只圖一個(gè)一劍三連)。
麻雀雖小但五臟俱全,本項(xiàng)目系統(tǒng)介紹了YOLO系列模型在TensorRT上的量化方案,工程型較強(qiáng),我們給出的工具可以實(shí)現(xiàn)不同量化方案在Yolo系列模型的量化部署,無(wú)論是工程實(shí)踐還是學(xué)術(shù)實(shí)驗(yàn),相信都會(huì)對(duì)你帶來(lái)一定的幫助。
B站地址(求關(guān)注和三連):https://www.bilibili.com/video/BV1Ds4y1k7yr/
Github開(kāi)源地址(求star):https://github.com/thb1314/mmyolo_tensorrt/
當(dāng)時(shí)想做這個(gè)的目的是是為了總結(jié)一下目標(biāo)檢測(cè)模型的量化加速到底會(huì)遇到什么坑,只是沒(méi)想到不量化坑都會(huì)很多。
比如即使是以FP32形式推理,由于TensorRT算子參數(shù)的一些限制和TRT和torch內(nèi)部實(shí)現(xiàn)的不同,導(dǎo)致torch推理結(jié)果會(huì)和TensorRT推理結(jié)果天然的不統(tǒng)一,至于為什么不統(tǒng)一這里賣(mài)個(gè)關(guān)子大家感興趣可以看下視頻。
下面說(shuō)一下我們這個(gè)項(xiàng)目做了哪些事情
-
YOLO系列模型在tensorrt上的部署與精度對(duì)齊
該項(xiàng)目詳細(xì)介紹了Yolo系列模型在TensorRT上的FP32的精度部署,基于mmyolo框架導(dǎo)出各種yolo模型的onnx,在coco val數(shù)據(jù)集上對(duì)齊torch版本與TensorRT版本的精度。
在此過(guò)程中我們發(fā)現(xiàn),由于TopK算子限制和NMS算子實(shí)現(xiàn)上的不同,我們無(wú)法完全對(duì)齊torch和yolo模型的精度,不過(guò)這種風(fēng)險(xiǎn)是可解釋且可控的。
-
詳解TensorRT量化的三種實(shí)現(xiàn)方式
TensorRT量化的三種實(shí)現(xiàn)方式包括trt7自帶量化、dynamic range api,trt8引入的QDQ算子。
Dynamic range api會(huì)在采用基于MQbench框架做PTQ時(shí)講解。
TensorRT引入的QDQ算子方式在針對(duì)Yolo模型的PTQ和QAT方式時(shí)都有詳細(xì)的闡述,當(dāng)然這個(gè)過(guò)程也沒(méi)有那么順利。
在基于PytorchQuantization導(dǎo)出的含有QDQ節(jié)點(diǎn)的onnx時(shí),我們發(fā)現(xiàn)盡管量化版本的torch模型精度很高,但是在TensorRT部署時(shí)精度卻很低,TRT部署收精度損失很?chē)?yán)重,通過(guò)可視化其他量化形式的engine和問(wèn)題engine進(jìn)行對(duì)比,我們發(fā)現(xiàn)是一些層的int8量化會(huì)出問(wèn)題,由此找出問(wèn)題量化節(jié)點(diǎn)解決。
-
詳解MQbench量化工具包在TensorRT上的應(yīng)用
我們研究了基于MQbench框架的普通PTQ算法和包括Adaround高階PTQ算法,且啟發(fā)于Adaround高階PTQ算法。
我們將torch版本中的HistogramObserver引入到MQBench中,activation采用HistogramObserver weight采用MinMaxObserver,在PTQ過(guò)程中,weight的校準(zhǔn)前向傳播一次,activation的校準(zhǔn)需要多次 因此我們將weight的PTQ過(guò)程和activation的PTQ過(guò)程分開(kāi)進(jìn)行,加速PTQ量化。實(shí)踐證明,我們采用上述配置的分離PTQ量化在yolov8上可以取得基本不掉點(diǎn)的int8量化精度。
-
針對(duì)YoloV6這種難量化模型,分別采用部分量化和QAT來(lái)彌補(bǔ)量化精度損失
在部分量化階段,我們采用量化敏感層分析技術(shù)來(lái)判斷哪些層最需要恢復(fù)原始精度,給出各種metric的量化敏感層實(shí)現(xiàn)。
在QAT階段,不同于原始Yolov6論文中蒸餾+RepOPT的方式,我們直接采用上述部分量化后的模型做出初始模型進(jìn)行finetune,結(jié)果發(fā)現(xiàn)finetune后的模型依然取得不錯(cuò)效果。
-
針對(duì)旋轉(zhuǎn)目標(biāo)檢測(cè),我們同樣給出一種端到端方案,最后的輸出就是NMS后的結(jié)果。通過(guò)將TensorRT中的EfficientNMS Plugin和mmcv中旋轉(zhuǎn)框iou計(jì)算的cuda實(shí)現(xiàn)相結(jié)合,給出EfficientNMS for rotated box版本,經(jīng)過(guò)簡(jiǎn)單驗(yàn)證我們的TRT版本與Torch版本模型輸出基本對(duì)齊。
以上就是我們這個(gè)項(xiàng)目做的事情,歡迎各位看官關(guān)注b站和一劍三連。同時(shí),如果各位有更好的想法也歡迎給我們的git倉(cāng)庫(kù)提PR。
7. 領(lǐng)域大模型落地的一些思考
原文:https://mp.weixin.qq.com/s/s-r-CL6qbrhnjdlcLYGrkw
一、常說(shuō)通用模型的領(lǐng)域化可能是偽命題,那么領(lǐng)域大模型的通用化是否也是偽命題。
自訓(xùn)練模型開(kāi)始,就一直再跟Leader Battle這個(gè)問(wèn)題,領(lǐng)域大模型需不需要有通用化能力。就好比華為盤(pán)古大模型“只做事不作詩(shī)”的slogan,是不是訓(xùn)練的領(lǐng)域大模型可以解決固定的幾個(gè)任務(wù)就可以了。
個(gè)人的一些拙見(jiàn)是,如果想快速的將領(lǐng)域大模型落地,最簡(jiǎn)單的是將系統(tǒng)中原有能力進(jìn)行升級(jí),即大模型在固定的某一個(gè)或某幾個(gè)任務(wù)上的效果超過(guò)原有模型。
以Text2SQL任務(wù)舉例,之前很多系統(tǒng)中的方法是通過(guò)抽取關(guān)鍵要素&拼接方式來(lái)解決,端到端解決的并不是很理想,那么現(xiàn)在完全可以用大模型SQL生成的能力來(lái)解決。在已有產(chǎn)品上做升級(jí),是代價(jià)最小的落地方式。就拿我司做的大模型來(lái)說(shuō),在解決某領(lǐng)域SQL任務(wù)上效果可以達(dá)到90%+,同比現(xiàn)有開(kāi)源模型&開(kāi)放API高了不少。
當(dāng)然還有很多其他任務(wù)可以升級(jí),例如:D2QA、D2SPO、Searh2Sum等等等。
二、領(lǐng)域大模型落地,任務(wù)場(chǎng)景要比模型能力更重要。
雖說(shuō)在有產(chǎn)品上做升級(jí),是代價(jià)最小的落地方式,但GPT4、AutoGPT已經(jīng)把人們胃口調(diào)的很高,所有人都希望直接提出一個(gè)訴求,大模型直接解決。但這對(duì)現(xiàn)有領(lǐng)域模型是十分困難的,所以在哪些場(chǎng)景上來(lái)用大模型是很關(guān)鍵的,并且如何將模型進(jìn)行包裝,及時(shí)在模型能力不足的情況下,也可以讓用戶(hù)有一個(gè)很好的體驗(yàn)。
現(xiàn)在很多人的疑惑是,先不說(shuō)有沒(méi)有大模型,就算有了大模型都不知道在哪里使用,在私有領(lǐng)域都找不到一個(gè)Special場(chǎng)景。
所以最終大模型的落地,拼的不是模型效果本身,而是一整套行業(yè)解決方案,“Know How”成為了關(guān)鍵要素。
三、大多數(shù)企業(yè)最終落地的模型規(guī)格限制在了13B。
由于國(guó)情,大多數(shù)企業(yè)最終落地的方案應(yīng)該是本地化部署,那么就會(huì)涉及硬件設(shè)備的問(wèn)題。我并不絕的很有很多企業(yè)可以部署的起100B級(jí)別的模型,感覺(jué)真實(shí)部署限制在了10B級(jí)別。即使現(xiàn)在很多方法(例如:llama.cpp)可以對(duì)大模型進(jìn)行加速,但100B級(jí)別的模型就算加速了,也是龐大資源消耗。
我之前說(shuō)過(guò)“沒(méi)有體驗(yàn)過(guò)33B模型的人,只會(huì)覺(jué)得13B就夠”,更大的模型一定要搞,但不影響最后落地的是10B級(jí)別。
———————End———————
新生態(tài),創(chuàng)未來(lái) | 2023RT-Thread 開(kāi)發(fā)者大會(huì)開(kāi)啟報(bào)名
邀請(qǐng)你參加 2023 RT-Thread 開(kāi)發(fā)者大會(huì)的六大理由
1、刷新RT-Thread最新技術(shù)動(dòng)態(tài)和產(chǎn)業(yè)服務(wù)能力
2、聆聽(tīng)行業(yè)大咖分享,洞察產(chǎn)業(yè)趨勢(shì)
3、豐富的技術(shù)和產(chǎn)品展示,前沿技術(shù)發(fā)展和應(yīng)用
4、絕佳的實(shí)踐機(jī)會(huì):AIOT、MPU、RISC-V...
5、精美伴手禮人手一份開(kāi)發(fā)板盲盒和免費(fèi)午餐
6、黑科技滿(mǎn)點(diǎn)~滴水湖地鐵口安排無(wú)人車(chē)接送至?xí)?chǎng)
立刻掃碼報(bào)名吧

-
RT-Thread
+關(guān)注
關(guān)注
31文章
1285瀏覽量
40089
原文標(biāo)題:【嵌入式AI簡(jiǎn)報(bào)20231117期】面對(duì)未來(lái)AI的三大挑戰(zhàn)!
文章出處:【微信號(hào):RTThread,微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第二章AI for Science的技術(shù)支撐學(xué)習(xí)心得
AMD分析嵌入式邊緣AI的發(fā)展
嵌入式系統(tǒng)的未來(lái)趨勢(shì)有哪些?
開(kāi)啟全新AI時(shí)代 智能嵌入式系統(tǒng)快速發(fā)展——“第六屆國(guó)產(chǎn)嵌入式操作系統(tǒng)技術(shù)與產(chǎn)業(yè)發(fā)展論壇”圓滿(mǎn)結(jié)束
恩智浦加速嵌入式AI創(chuàng)新應(yīng)用開(kāi)發(fā)
AI普及給嵌入式設(shè)計(jì)人員帶來(lái)新挑戰(zhàn)

嵌入式軟件開(kāi)發(fā)與AI整合

EVASH Ultra EEPROM:助力ChatGPT等AI應(yīng)用的嵌入式存儲(chǔ)解決方案
AI引爆邊緣計(jì)算變革,塑造嵌入式產(chǎn)業(yè)新未來(lái)AI引爆邊緣計(jì)算變革,塑造嵌入式產(chǎn)業(yè)新未來(lái)——2024研華嵌入式

AI與開(kāi)源力推嵌入式系統(tǒng)創(chuàng)新升級(jí)
五項(xiàng)功能可提升邊緣端嵌入式AI性能
AMD Versal SoC刷新邊緣AI性能,單芯片方案驅(qū)動(dòng)嵌入式系統(tǒng)

AMD Versal SoC全新升級(jí)邊緣AI性能,單芯片方案驅(qū)動(dòng)嵌入式系統(tǒng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論