 基于顯式證據推理的few-shot關系抽取CoT
基于顯式證據推理的few-shot關系抽取CoT
摘要
Few-shot關系提取涉及使用有限數量的注釋樣本識別文本中兩個特定實體之間的關系類型。通過應用元學習和神經圖技術,已經出現了對這個問題的各種解決方案,這些技術通常需要訓練過程進行調整。
最近,上下文學習策略已被證明在沒有訓練的情況下顯示出顯著的結果。很少有研究利用上下文學習進行zero-shot信息提取。不幸的是,推理的證據在思維鏈提示的構建過程中沒有被考慮或隱式建模。
本文提出了一種使用大型語言模型進行Few-shot關系提取的新方法,稱為CoT-ER,具有顯式證據推理的思維鏈。特別是,CoT-ER首先誘導大型語言模型使用特定任務和概念級知識生成證據。然后將此證據明確納入思維鏈提示以進行關系提取。實驗結果表明,在FewRel 1.0和FewRel 2.0數據集上,與完全監督(具有100%訓練數據)的最先進方法相比,本文的CoT-ER方法(具有0%訓練數據)實現了具有競爭力的性能。
簡介
關系提取(Relation Extraction, RE)旨在基于上下文語義信息識別兩個給定實體之間的關系。
當標記的數據不足時,RE模型的性能往往會顯著下降。few-shot關系提取任務需要使用有限數量的注釋訓練數據。最近,許多研究人員通過使用元學習和神經圖技術來解決這個問題,通過在大型數據集上對模型進行元訓練或結合外部知識,取得了令人滿意的結果。
近年來,預訓練的LLMs,如GPT系列模型,已經顯示出顯著的上下文學習(LLM可以有效地執行各種任務,而無需參數優化,這一概念被稱為上下文學習)能力,在許多NLP任務中取得了出色的結果。在上下文學習的范式中,LLM在許多NLP任務中表現出與標準的完全監督方法相比的競爭性能,即使只提供了幾個示例作為提示中的few-shot示例。
思維鏈(Chain-of-Thought, CoT)提示方法在數學問題和常識推理中從LLM引出令人印象深刻的推理能力。在RE任務中,存在指導LLM確定關系標簽的推理過程。然而,缺乏填補這一空白的研究。盡管GPT-RE引入了一種標簽誘導推理方法,通過提示LLM僅基于給定的標簽生成合適的推理過程。與特定的few-shot示例檢索方法相比,自動生成推理過程的性能改進微乎其微。
本文為FSRE(Few-shot Relation Extraction, FSRE)任務提出了一種新的思想鏈提示方法:具有顯式證據推理的思想鏈,與FewRel 1.0和FewRel 2.0上的最先進結果相比,獲得了具有競爭力的結果。本文的方法采用三步推理方法來解決上述問題。在第一步和第二步中,CoT-ER要求LLM輸出與頭部和尾部實體相對應的概念級實體,這是RE特定推理的基礎。在第三步中,CoT-ER提示LLM提取相關的上下文跨度作為明確建立這兩個實體之間特定關系的證據。通過將頭部實體、尾部實體和關系標簽組合成連貫的句子,LLM可以更語義地確定兩個給定實體之間的關系標簽,解決了提示方法中關系標簽的語義模糊問題。下圖展示了Auto-CoT和CoT-ER之間的差異。
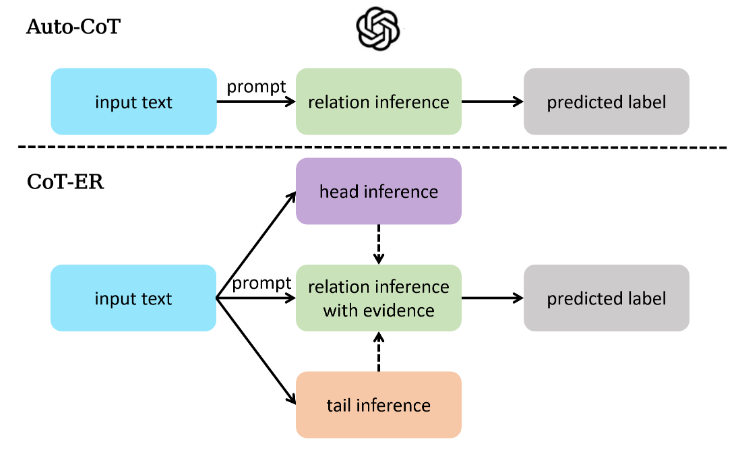
相關工作
Few-shot Relation Extraction
few-shot關系提取旨在基于有限數量的注釋數據預測給定實例中指示的頭部和尾部實體之間的語義關系。FewRel是Han等人引入的一個大規模數據集,是第一個在關系提取中探索few-shot學習的數據集。許多方法在缺乏訓練數據的情況下,結合外部知識來提高性能。FSRE的另一條研究路線僅依賴于輸入文本和提供的關系描述信息,而不包含外部知識。以前的大多數方法通常采用復雜的神經網絡設計或引入外部知識,這在現實場景中可能是勞動密集型的。
In-context Learning
GPT-3在上下文學習(In-context Learning, ICL)中已成為NLP中的一種新范式,與微調模型相比,它在各種任務中表現出了競爭力。通過將相關文本信息納入提示中,將先驗知識引入LLM要容易得多。此外,ICL是一種無需訓練的方法,直接提示LLM,這意味著它是一種現成的方法,只需在提示中進行一些演示即可輕松應用于各種任務。
最近,大多數研究人員專注于ICL的示例設計,以提高NLP任務的性能,并逐漸發展為兩類。演示設計的第一類試圖通過從數據集中選擇實例并對所選演示實例進行排序來尋求提示中的少量示例的最佳安排。另一類示例設計旨在發現一種有效的提示方法,以釋放LLM的潛力。此外,有研究人員通過在給出答案之前手動添加中間推理步驟,揭示了LLM的推理能力,這被稱為思維鏈。
盡管CoT提示方法在許多NLP任務中取得了很好的結果,但它仍然缺乏對RE的相關探索。因此,本文提出了一種新的CoT提示法CoT-ER來填補這一空白。
CoT-ER
本文提出的CoT-ER的概述如下圖所示,它由3個組件組成:
- Human-Instructed Reasoning Module:旨在通過用人工注釋數據提示LLM,將推理過程與支持集中的每個實例相關聯。
- Similarity Based KNN Retrieval Module:基于相似性的KNN檢索模塊將根據與查詢實例的相似性從支持集中選擇具有推理過程的實例,這些實例在最終提示中被視為few-shot示例。
- Inference Module:推理模塊通過最終提示指示LLM來預測查詢實例的關系標簽,最終提示將任務指令、few-shot示例和關于實例的問題連接起來。
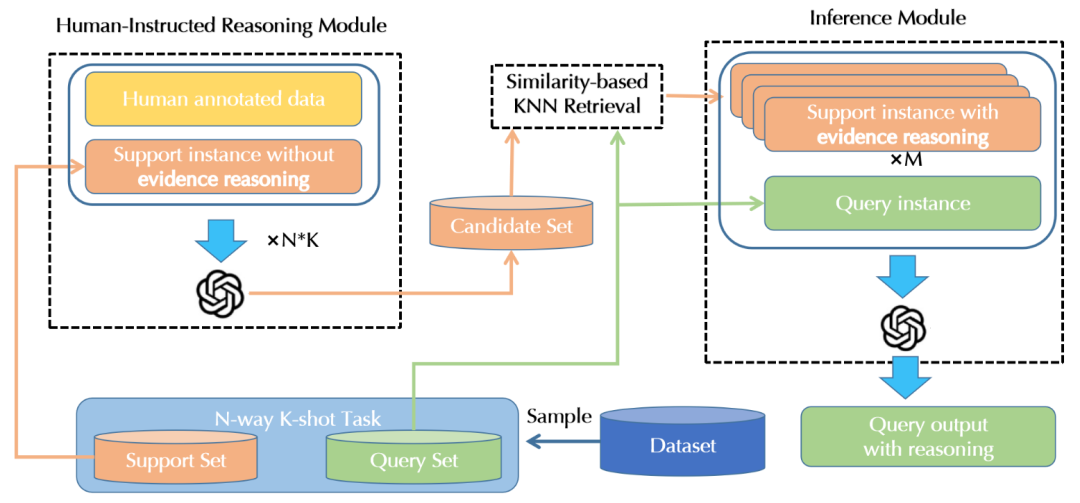
Human-Instructed Reasoning Module
由于LLM具有上下文學習的能力,本文提出了一種人工指導的方法來指導LLM使用最少的注釋數據執行準確的推理。
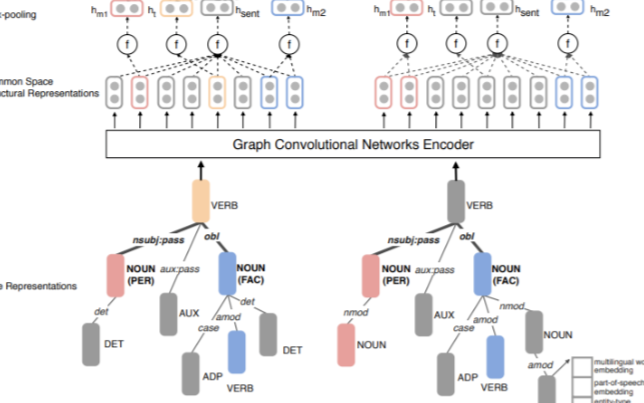
CoT-ER設計:為了充分利用LLM中存儲的知識并促進逐步推理,引入了一種新的具有概念級知識和明確證據的三步推理框架。在步驟1中,LLM推斷與頭部實體相關的概念級知識,而步驟2對尾部實體進行同樣的操作。通過這些步驟,LLM可以很容易地排除概念實體不正確的選項。步驟3:為了找出在給定的上下文中哪一個關系標簽最適合這對實體,明確強調相關的文本跨度作為證據,然后構建一個連貫的表達式,將兩個實體和關系標簽結合在一起。為了進一步說明三步推理過程,下圖中的幾個shot示例演示了該推理過程的模板。

CoT-ER生成:為數據集中的每個關系類注釋了一個CoT-ER推理示例作為種子示例。然后,設計了一個適當的提示,使用注釋的示例作為few-shot示例演示,以指導LLM為每個支持實例生成類似的推理步驟。每個具有CoT-ER推理步驟的支持實例都將附加到候選集合中。上圖顯示了為人工指導推理模塊設計的類似提示。
Retrieval Module
有研究表明,基于相似性選擇few-shot示例會大大改善上下文學習。由于LLM的輸入tokens有限,在給定N路K-Shot任務的情況下,單個提示可能無法容納所有支持實例。在本文中,遵循基于相似性的方法來選擇few-shot示例。為了獲得特定關系的相似性表示,首先通過合并實體級信息,將輸入文本重構為“上下文:[文本]給定上下文,“[頭部實體]”和“[尾部實體]”之間的關系是什么?”。然后,利用GPT系列模型“text-embedding-ad-002”作為編碼器來獲得語義嵌入。隨后,計算候選集合中的每個實例與查詢實例之間的歐幾里得距離。最后,基于候選集合中的M個實例到查詢實例的較低歐幾里得距離,選擇它們作為few-shot示例。
Inference Module
為了創建最終提示,只需將一條任務指令、few-shot示例和一個針對查詢實例定制的問題連接起來,使用具有CoT-ER推理的支持實例作為few-shot示例。值得注意的是,LLM在一般情況下有很強的錯誤輸出NULL的傾向。本文中強制LLM選擇所提供的關系標簽之一,因為沒有考慮FewRel數據集中的“無上述”場景示例。
實驗
Datasets
有兩個標準的few-shot關系提取數據集:FewRel 1.0和FewRel 2.0。
- FewRel 1.0由維基百科構建,維基百科由70000個句子組成,注釋有100個關系標簽,這100個關系標記被分為64/16/20個部分,用于訓練/驗證/測試集。
- FewRel2.0通過引入醫學領域的額外驗證和測試集擴展了FewRel 1.0,其中包括分別具有1000個實例的10個關系標簽和具有1500個實例的15個關系標簽。
實驗細節
在現實場景中,直接使用固定的、手動注釋的示例執行RE任務是合理的,作為每個關系標簽的少量鏡頭演示。為此,通過從預先確定的人工注釋CoT-ER數據集中選擇few-shot示例來評估性能,該數據集表示為手動CoT-ER。在此設置中,few-shot示例獨立于支持集,這意味著LLM將使用較少的注釋數據執行RE任務。相反,Auto-CoT-ER利用自動生成的CoT-ER推理過程作為人工指導推理模塊中描述的支持集的few-shot示例。
對比模型
本文考慮FSRE任務的兩類方法。
100% 訓練數據的方法:MTB、CP、HCPR、FAEA、GTPN、GM_GEN和KEFDA。通常,這些方法在FewRel 1.0訓練集上訓練模型,并在FewRel 1.0、2.0驗證和測試集上評估其性能。
0% 訓練數據的方法:應用Vanilla-ICL和Auto-CoT作為基線提示格式化方法。這些方法利用一些示例作為演示,并提示LLM執行NLP任務。Vanilla-ICL設計了一個直接結合文本和關系標簽的模板,例如“上下文:[文本],給定上下文,[頭部實體]和[尾部實體]之間的關系就是[關系標簽]”。Auto-CoT通過自動生成的推理步驟擴展了Vanilla-ICL。
在整個實驗中,注意到是否要求LLM在最后的回答階段進行推理可能會導致不一致的結果,如下表所示。此外,利用預先訓練的BERT基本模型6和GPT系列模型text-embedding-ada-002作為編碼器,直接獲得輸入文本的表示。對于每個N路K-shot任務,我們通過對屬于該類的K instance進行平均來獲得每個類的原型。然后,將查詢實例的預測標簽分配給其原型與查詢實例具有最接近歐幾里得距離的類。將這兩種方法稱為Bert-proto和GPT-proto。
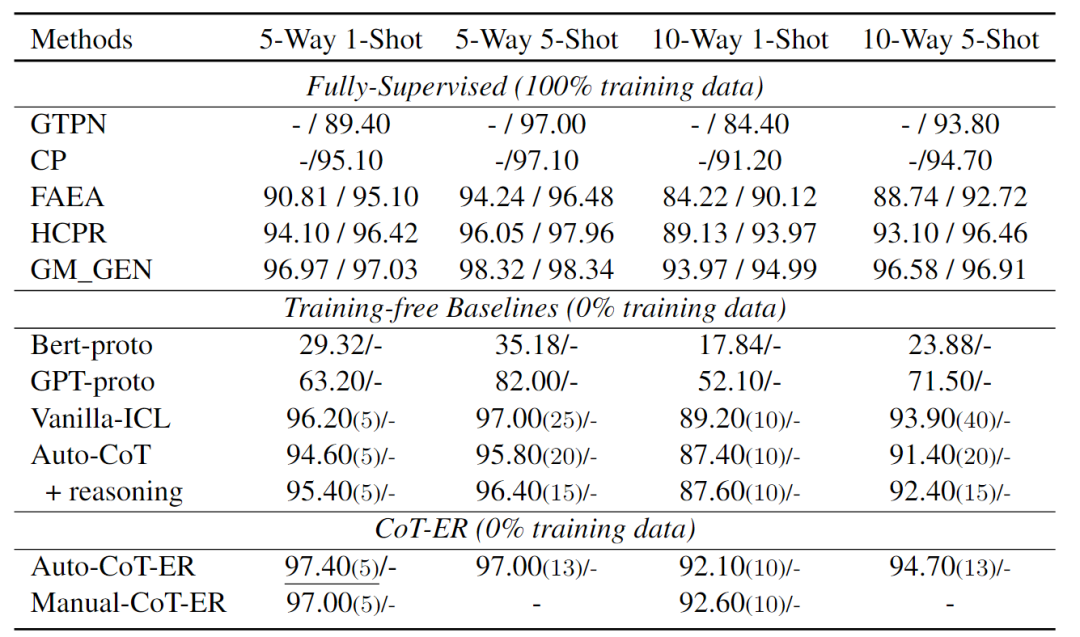
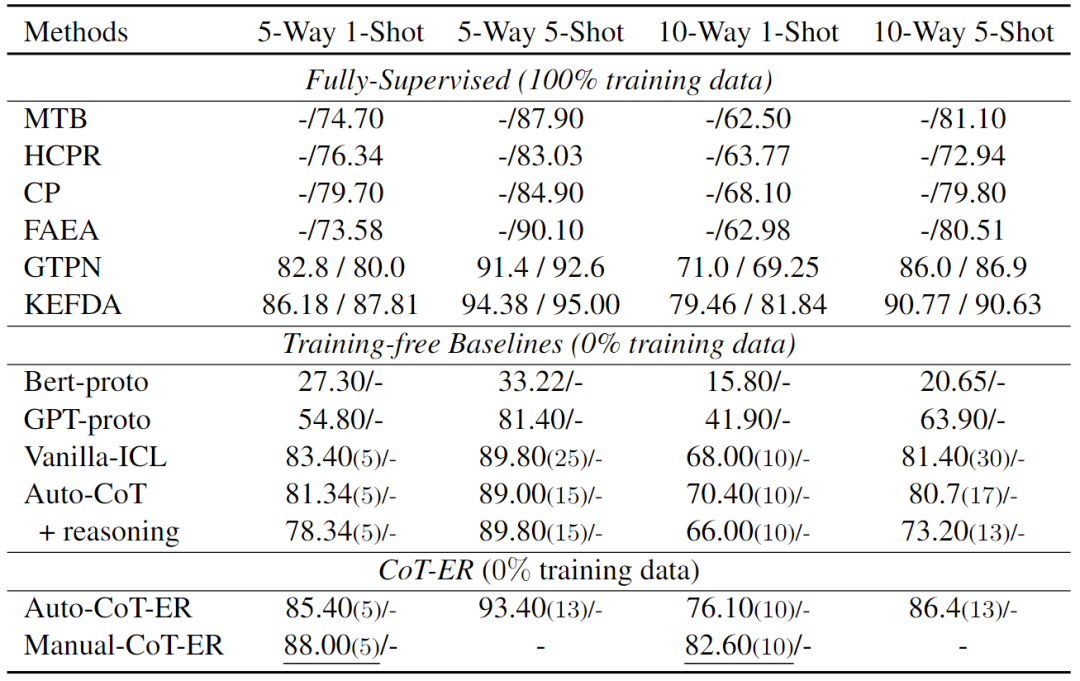
結果與分析
結果
- 與Vanilla-ICL相比,在few-shot場景中,Auto-CoT沒有表現出顯著的改進。這可能歸因于推理過程的低質量,以及由于最大token限制,few-shot演示中的實例數量減少。此外,當涉及到在最終答案中生成推理過程時,具有推理的Auto-CoT優于在FewRel 1.0上直接生成關系標簽的版本。然而,在FewRel 2.0上得出了相反的結論。原因可能為:FewRel 1.0從維基百科中提取實例,通常需要常識來進行推理,而FewRel 2.0需要醫學相關專業知識,與常識相比,在預訓練語料庫中所占比例較小。因此,LLM在執行醫學領域的推理任務時遇到困難。
- 手動CoT-ER和Auto-CoT-ER都優于無訓練基線,在few-shot演示中使用的實例更少。表明有必要設計一種針對RE任務的特定CoT提示方法,以便在few-shot場景中獲得更好的性能。
- CoT-ER提示方法在FewRel 1.0和FewRel 2.0上都比最先進的完全監督方法具有競爭力,并以最少的人工超過了大多數完全監督方法。這表明,當提供高質量的關系信息和精心設計的推理過程時,GPT系列LLM有可能擊敗以前的完全監督方法。
消融CoT-ER
合并實體信息是否對CoT-ER有顯著好處?本文進行了消融實驗,以證明三步推理過程的必要性。在這個實驗中,去掉了第一步和第二步,并將性能與Auto-CoT reasoning進行了比較。出于公平考慮,使用Auto-CoT-ER實現了這個實驗,它還采用了LLM自動生成的推理過程。由于最大輸入和輸出token的限制,將消融實驗的few-shot演示中的實例數量設置為13。結果如下圖所示。
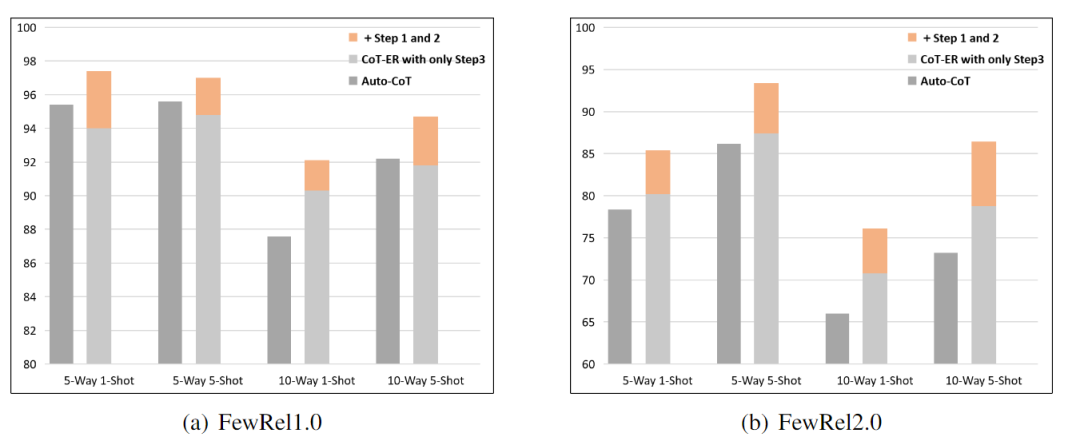
結果表明:
- 除第一步和第二步后,Auto-CoT-ER的性能顯著下降,在FewRel 1.0和FewRel 2.0上的精度分別降低了3.4、2.2、1.8、2.9和5.2、6、5.3、7.6。這意味著實體類型的更高層次抽象,特別是概念級實體,有利于LLM在few-shot場景中執行RE任務。
- CoT-ER的第三步是將支持實例與Auto-CoT相比更簡單的推理過程配對,但它在某些具有挑戰性的場景中實現了卓越的性能。這一發現表明,關系標簽提供的語義信息比低質量的推理信息更有利于LLM。
CoT-ER穩定性實驗
本文對提出的CoT-ER進行了兩項穩定性實驗。
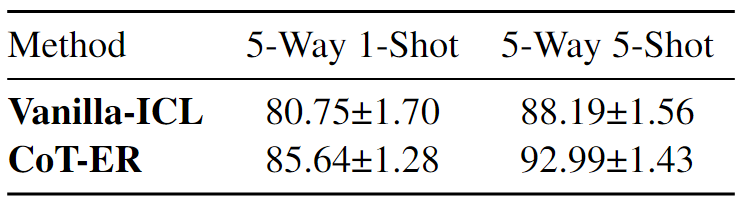
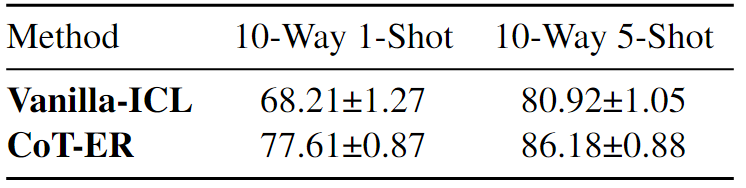
- Different Random Seeds for Task Sampling:由于“text-davinci-003”的成本很高,本文對數量相對較少的查詢進行了采樣測試,特別是每個N路K-Shot任務的查詢數量為100×N。為此,使用8個隨機種子對CoT-ER和Vanilla-ICL進行了評估,用于N路K-Shot任務采樣。下表中顯示了FewRel 2.0的平均值±標準偏差的實驗結果。值得注意的是,CoT-ER在所有N路K-shot設置中始終以較低的標準差優于Vanilla-ICL。
- Different Number of Few-shot Instances:為了研究所選演示數量如何有助于CoT-ER的性能,在5-Way,5-Shot 設置下進行了實驗。單個提示在最壞的情況下可以保持13個CoT-ER推理演示,而所有支持實例(25)都可以附加到Vanilla-ICL中的提示。結果如下表所示。

觀察到CoT-ER和Vanilla-ICL都可以受益于更多的few-shot示例,然而,隨著示例數量的增加,Vanilla-ICL的性能迅速下降。CoT-ER可以有效地利用來自提供實例的信息,即使實例數量減少,也能保持強大的性能。這表明當few-shot實例的數量發生變化時,CoT-ER表現出比Vanilla-ICL更大的穩定性。
下表展示了CoT-ER和Auto-CoT方法的案例分析。

結論
本文探索了LLM上下文內學習在few-shot關系提取方面的潛力。為了提高低質量自動生成推理過程所帶來的總體性能,引入了CoT-ER,這是一種專門用于few-shot關系提取的提示方法。核心思想是促使LLM使用存儲在其預訓練階段的特定任務和概念級別的知識來生成證據。LLM將在RE任務中使用這些證據,并促進推理過程。此外,設計了一種標簽描述技術,通過將實體和關系標簽集成到一個連貫的表達式中。該技術解決了關系標簽的語義歧義,這是在上下文學習中使用關系提取時遇到的常見挑戰。FewRel 1.0和FewRel 2.0的實驗結果優于所有無訓練基線,證明了本文提出的方法的有效性。此外,實現與最先進的完全監督方法相當的結果表明,上下文學習范式有望成為few-shot關系提取任務的新解決方案。
盡管CoT-ER在FewRel 1.0和FewRel 2.0上取得了不錯的結果,但仍有未來改進的潛力。由于最大長度的限制,本文提出的方法在處理較大的數據集時并沒有充分利用所有實例。盡管采用了基于相似性的KNN檢索來為few-shot演示選擇優越的實例,結果發現,與其他在有大量候選集可用時表現良好的方法相比,它在few-shot設置中并不有效。由于通過GPT-3的API使用合理所需ICL的成本很高,本文尚未在具有更長最大輸入token和更大規模的高級LLM上評估CoT-ER。有限的預算也限制了種子示例構建的優化。可以通過更具信息性和適當的設計來提高性能。
-
語言模型
+關注
關注
0文章
520瀏覽量
10268 -
nlp
+關注
關注
1文章
488瀏覽量
22033 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:EMNLP2023 | 基于顯式證據推理的few-shot關系抽取CoT
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于將 CLIP 用于下游few-shot圖像分類的方案
深度學習:遠程監督在關系抽取中的應用
NLP:關系抽取到底在乎什么
NLP事件抽取綜述之挑戰與展望
細解讀關系抽取SOTA論文
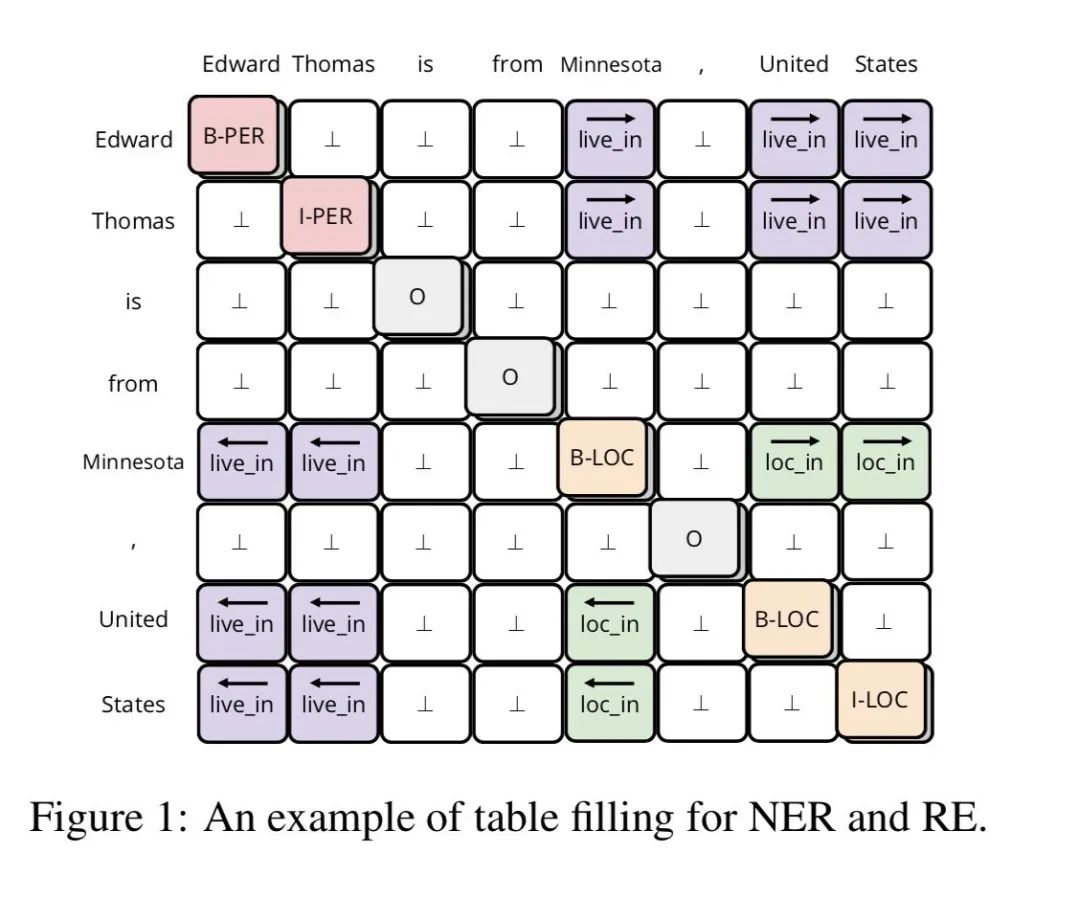
樣本量極少可以訓練機器學習模型嗎?
Zero-shot-CoT是multi-task的方法
實體關系抽取模型CasRel
介紹兩個few-shot NER中的challenge
Few-shot NER的三階段
基于GLM-6B對話模型的實體屬性抽取項目實現解析
邁向多模態AGI之開放世界目標檢測
基于多任務預訓練模塊化提示





 工商網監
工商網監
評論